一文读懂 n-grams:大模型出现前,语言模型就靠它
在深度学习时代之前,让机器理解人类语言是一个巨大的挑战。早期的AI系统面对文本时,就像一个完全不懂中文的外国人看一本中文小说——每个字都认识,但组合起来就懵了。
什么是n-grams语言模型?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
一、为什么需要统计语言模型
在深度学习时代之前,让机器理解人类语言是一个巨大的挑战。早期的AI系统面对文本时,就像一个完全不懂中文的外国人看一本中文小说——每个字都认识,但组合起来就懵了。
第一个问题是词汇的不确定性。 同一个发音可能对应多个词,比如"shi"可以是"是"、“事”、“市”、"试"等等。如果只看单个词,根本无法确定正确含义。
第二个问题是语义的上下文依赖。 语言的理解高度依赖上下文。比如"苹果很好吃"和"苹果发布了新手机"中的"苹果"完全是两个概念。没有上下文,机器无法判断。
为了解决这些问题,研究者们想到了一个朴素但有效的思路:用统计规律来捕捉语言的模式。既然人类说话写字有一定的习惯和规律,那么通过分析大量文本,就能发现哪些词经常一起出现,哪些组合更合理。
这就是n-grams语言模型诞生的背景——它不试图理解语言的深层含义,而是通过统计"词与词之间的共现规律"来预测和生成语言。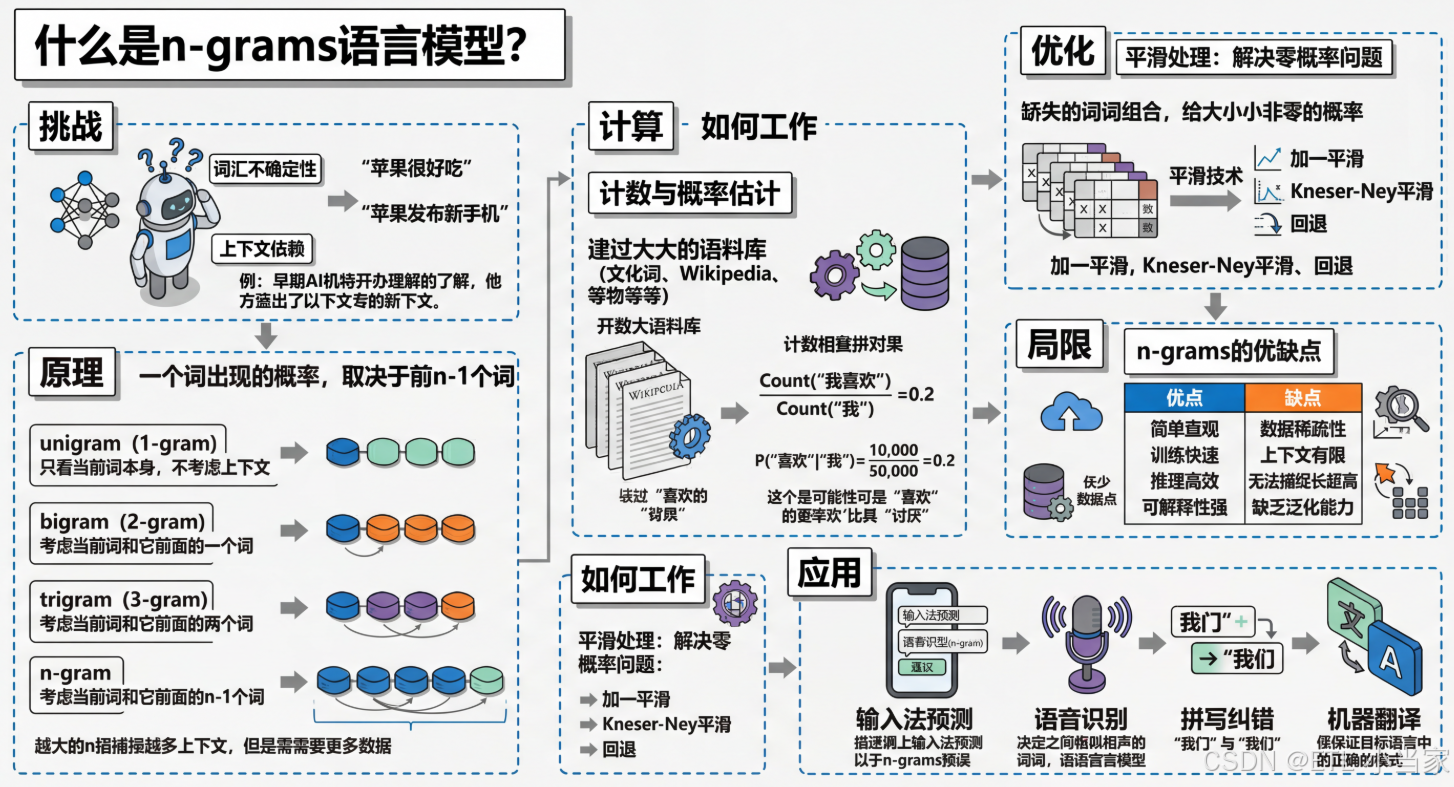
二、什么是n-grams语言模型
n-grams语言模型是一种基于统计的简单但有效的语言建模方法。它的核心思想非常直观:一个词出现的概率,取决于它前面的若干个词。
这里的"n"表示考虑的词的数量:
- unigram (1-gram):只考虑当前词本身,不考虑上下文
- bigram (2-gram):考虑当前词和它前面的一个词
- trigram (3-gram):考虑当前词和它前面的两个词
- n-gram:考虑当前词和它前面的n-1个词
举个例子,假设我们要计算句子"我喜欢吃苹果"的概率。
用bigram模型的话,我们会这样计算:
- P(“我”) × P(“喜欢”|“我”) × P(“吃”|“喜欢”) × P(“苹果”|“吃”)
用trigram模型的话,则是:
- P(“我”) × P(“喜欢”|“我”) × P(“吃”|“我喜欢”) × P(“苹果”|“喜欢吃”)
可以看到,n越大,模型能捕捉的上下文信息就越多,但也需要更多的数据来准确估计概率。
三、n-grams是如何工作的
3.1 计数与概率估计
n-grams模型的训练过程其实很简单:数数。
假设我们有一个巨大的语料库(比如所有维基百科文章),我们遍历整个语料库,统计每种n-gram出现的次数。
比如统计bigram:
- “我喜欢” 出现了 10,000 次
- “我讨厌” 出现了 2,000 次
- “我” 总共出现了 50,000 次
那么我们可以估计:
- P(“喜欢”|“我”) = 10,000 / 50,000 = 0.2
- P(“讨厌”|“我”) = 2,000 / 50,000 = 0.04
这样,当模型看到"我"这个词时,就知道接下来更可能是"喜欢"而不是"讨厌"。
3.2 平滑处理:解决零概率问题
现实中的问题是:不可能在训练数据中看到所有的词组合。比如"我爱吃榴莲"可能在训练数据中一次都没出现过,但这并不意味着这个句子不合理。
如果直接用最大似然估计,未出现的n-gram概率就是0,这会导致整个句子的概率变成0,显然不合理。
所以n-grams模型需要平滑技术,给未见过的组合分配一个小的非零概率。常见的平滑方法包括:
- 加一平滑(Laplace smoothing):给每个计数都加1
- Kneser-Ney平滑:更 sophisticated 的方法,考虑低阶n-gram的信息
- 回退(backoff):如果高阶n-gram没出现过,就退回到低阶n-gram
3.3 存储与检索
训练好的n-grams模型本质上就是一个巨大的查找表。对于每个可能的(n-1)-gram前缀,存储所有可能的下一个词及其概率。
比如前缀"我喜欢"对应的可能是:
- “吃”:概率 0.3
- “看”:概率 0.2
- “玩”:概率 0.15
- …其他词
这种结构虽然简单,但在实际应用中非常高效。
四、n-grams的优缺点
| 优点 | 缺点 |
|---|---|
| 简单直观:原理容易理解,实现简单 | 数据稀疏性:高阶n-gram在训练数据中很少出现 |
| 训练快速:只需要统计计数,不需要复杂的优化 | 上下文有限:只能捕捉固定长度的上下文(通常n≤5) |
| 推理高效:查表操作,速度很快 | 无法捕捉长距离依赖:超过n个词的距离就无法建模 |
| 可解释性强:每个概率都有明确的统计意义 | 缺乏泛化能力:无法理解语义相似性(如"猫"和"狗") |
五、n-grams的实际应用
尽管现在有了更强大的神经网络语言模型,n-grams在很多场景中仍然有用:
5.1 输入法预测
早期的输入法(如Google拼音、搜狗输入法)大量使用bigram和trigram模型来预测用户想输入的下一个词。当你输入"今天天",输入法会根据"今天"这个bigram,推荐"天气"、"天空"等常见搭配。
5.2 语音识别
在语音识别中,声学模型负责将声音转换成可能的词序列,而语言模型(通常是n-grams)负责选择最可能的词序列。比如声学模型可能输出"shi jian"对应多个候选:“时间”、“事件”、“世间”,语言模型会根据上下文选择概率最高的那个。
5.3 拼写纠错
拼写纠错系统会计算修正后的句子的n-gram概率,选择概率最高的修正方案。比如"我门去吃饭"会被纠正为"我们去吃饭",因为"我们"的bigram概率远高于"我门"。
5.4 机器翻译
早期的统计机器翻译系统使用n-grams作为目标语言模型,确保翻译结果符合目标语言的表达习惯。
六、为什么早期要依赖统计规律
6.1 计算资源的限制
在2000年代,深度学习还没有普及,GPU计算能力有限。训练复杂的神经网络既昂贵又耗时。相比之下,n-grams只需要CPU和内存,训练和推理都非常快。
6.2 数据驱动的务实选择
在缺乏对语言深层理解的情况下,统计规律是最可靠的指导。虽然n-grams不能理解语义,但它能捕捉到人类语言使用的真实模式。正如著名语言学家J.R. Firth所说:“You shall know a word by the company it keeps”(通过一个词的伙伴来认识它)。
6.3 理论基础扎实
n-grams有坚实的概率论基础,可以严格证明其收敛性和一致性。在机器学习理论还不成熟的年代,这种可证明的可靠性非常重要。
6.4 工程实践的成功
从1990年代到2010年代初,n-grams在语音识别、机器翻译等实际应用中取得了巨大成功。IBM的统计机器翻译系统、Google的早期语音识别系统都基于n-grams,这些成功案例进一步巩固了统计方法的地位。
七、从n-grams到现代语言模型
n-grams虽然简单有效,但它的局限性也很明显。随着计算能力的提升和深度学习的发展,研究者们开始探索更强大的语言建模方法:
- 神经网络语言模型(2003):Bengio等人首次用神经网络替代n-grams,能够学习词的分布式表示
- RNN/LSTM(2010s):能够处理变长序列,捕捉更长的依赖关系
- Transformer(2017):通过自注意力机制,彻底解决了长距离依赖问题
但n-grams的精神依然存在:语言是有规律的,而这些规律可以通过数据学习。现代大语言模型本质上也是在学习更复杂、更抽象的语言规律,只是方式更加智能和高效。
今天,当我们享受ChatGPT流畅对话的时候,不妨回想一下那些简单的n-grams——它们是通往现代AI语言理解之路的第一块基石。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)