4、【AI】【Agent】tokens 介绍
本文探讨了大模型中的关键概念"token",解释了其在中文和英文中的不同处理方式(1个汉字≈1-2 tokens,1个英文单词≈1-3 tokens)。通过具体示例展示了文本和代码的token拆分过程,并区分了输入token和输出token(tokens/s)的概念。文章对比了不同参数量的模型(如Phi-3-mini、CodeLlama-7B等)在相同硬件条件下的推理速度,指出
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【AI】【Agent】本地模型(硬件参数)
分析了 lscpu 命令输出的 CPU 参数,以及在该 CPU 下能运行的量化模型配置,其中提到了量化模型配置中三个关键概念:B,Q5_K_M,tokens,并解释了其中的 B,Q5_K_M,下面继续分析
Agent
上篇 blog 分析了 B 和 Q5_K_M 概念的含义,下面再分析下 tokens
token 本意指实物凭证,随着技术演进,逐渐由了抽象符号的意思,在数字领域形成安全令牌和加密通证等概念,说到底,其精髓还在凭证的抽象概念里

在大模型的语境里,token 代表大模型处理文本的最小单位(当然,大模型处理 token 是收费的,也算一种间接的付费凭证),不是字,也不是词,而是子词(subword)或符号,通常情况下
- 中文:1 个汉字 ≈ 1~2 个
token - 英文:1 个单词 ≈ 1~3 个
token(比如 unhappiness → [“un”,“happi”,“ness”])
举个例子,输入句子
你好,世界!
可能被拆成 tokens
["你", "好", ",", "世", "界", "!"]
一共有 6 个 tokens,而输入代码
def hello(): print("Hello")
则可能被拆成
["def", " hello", "(", "):", " print", "(", "\"", "Hello", "\"", ")"]
一共有 10 个 tokens
OK,注意,上面说的指的是输入 tokens,而之前表格里列举的推理速度(tokens/s),则指的是输出 tokens,tokens/s 在这里衡量的是模型生成速度,80 tokens/s 相当于每秒输出 40~80 个汉字,或 50~100 个英文单词,对比人类的打字速度(约为 5~10 tokens/s),AI 要快上 8~16 倍
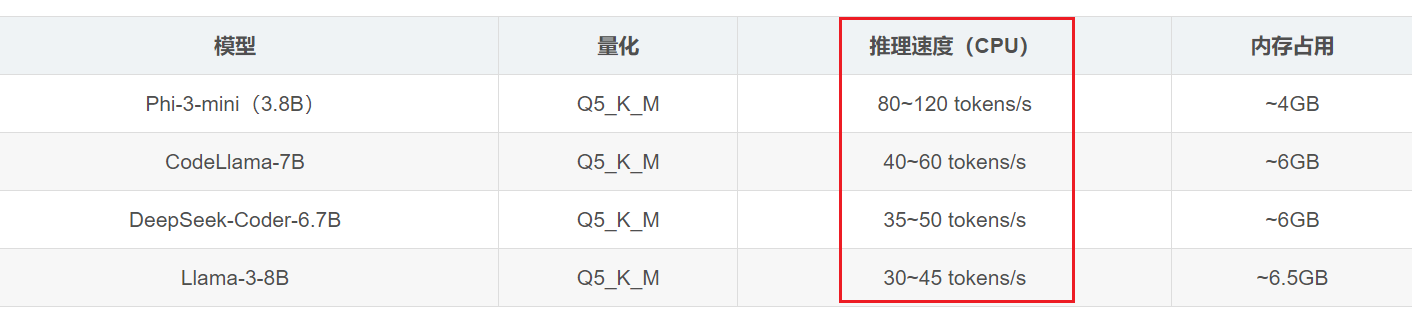
表格中的 Phi-3-mini 的推理速度可以达到 80~120 tokens/s,相当于每秒写 2~3 行的 Python 代码,非常流畅
OK,最后把表格提炼完再总结下
| 模型 | 参数量 | 量化格式 | 速度 | 内存 | 说明 |
|---|---|---|---|---|---|
| Phi-3-mini(3.8B) | 38亿 | Q5_K_M | 80~120 t/s | ~4GB | 小而快,微软优化极好 |
| CodeLlama-7B | 70亿 | Q5_K_M | 40~60 t/s | ~6GB | 通用代码模型 |
| DeepSeek-Coder-6.7B | 67亿 | Q5_K_M | 35~50 t/s | ~6GB | 中文代码更强 |
| Llama-3-8B | 80亿 | Q5_K_M | 30~45 t/s | ~6.5GB | 通用开源 |
另外,从表格中,还可以看到,参数量越大,tokens 速度越小,这个特点非常有代表性,在相同硬件,相同量化格式(都是 Q5_K_M)下,参数量越大,tokens 生成速度越慢,其背后是计算机体系结构和大模型推理原理的直接体现
其核心原因一句话总结:每生成一个 token,模型都要遍历所有参数做一次计算,参数越多,计算量就越大,速度自然也就越慢
举个形象点的例子,就像
- 让一个小学生背 10 个单词,速度很快
- 但让一个博士背 10000 个专业术语,虽然博士很聪明,但时间就要久一点
而大模型生成文本是逐个 token 自回归(autogressive)的过程,比如
输入: "写一个"
↓
模型计算 → 输出: "Python"
↓
输入变成: "写一个 Python"
↓
模型计算 → 输出: "函数"
↓
...

可以看到,token 自回归的过程中,其生成的每一个 token 都会被重新作为输入,再经过模型计算,生成出新的 token,这里每一步的核心操作在于,对每个新生成出来的 token,模型都要执行一遍:
- 加载所有参数(从内存到 CPU 缓存)
- 做矩阵乘法 + 激活函数(计算量 ∝ 参数数量,∝ 是数学和物理中常用的符号,表示正比于)
- 采样下一个
token继续作为输入
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【AI】【Agent】tokens生成速度

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)