从零理解 GraphCodeBERT 与 Sentence-BERT
本文介绍了Transformer及其衍生模型BERT、Sentence-BERT和GraphCodeBERT的核心原理与应用。Transformer通过自注意力机制实现并行处理,成为大模型基础架构。BERT在此基础上采用双向编码器和预训练任务(MLM和NSP),提升语言理解能力。Sentence-BERT通过孪生网络结构优化句子向量表示,实现高效语义相似度计算。GraphCodeBERT则专为代码
📖 目录
- 地基:什么是 Transformer?
- 砖块:什么是 BERT?
- 分支一:Sentence-BERT —— 让句子"可以比较"
- 分支二:GraphCodeBERT —— 让AI"读懂代码"
- 总结对比与应用场景
1. 地基:什么是 Transformer?
💡 一句话总结:Transformer 是一种"所有词同时互相看"的神经网络架构,是当今几乎所有大模型(GPT、BERT、LLaMA等)的底座。
1.1 为什么需要 Transformer?
在 Transformer 出现之前,处理文本主要靠:
- RNN(循环神经网络):像逐字读信一样,一个字一个字地处理,速度慢,且容易"忘了前面说了啥"。
- CNN(卷积神经网络):像拿放大镜只能看固定大小的局部区域,难以捕捉长距离关系。
2017年,Google 发表了论文 “Attention Is All You Need”,提出 Transformer 架构,核心创新是:
自注意力机制(Self-Attention):让每个词都能直接"看到"句子中的所有其他词,一次性并行处理整句话。
1.2 Transformer 长什么样?
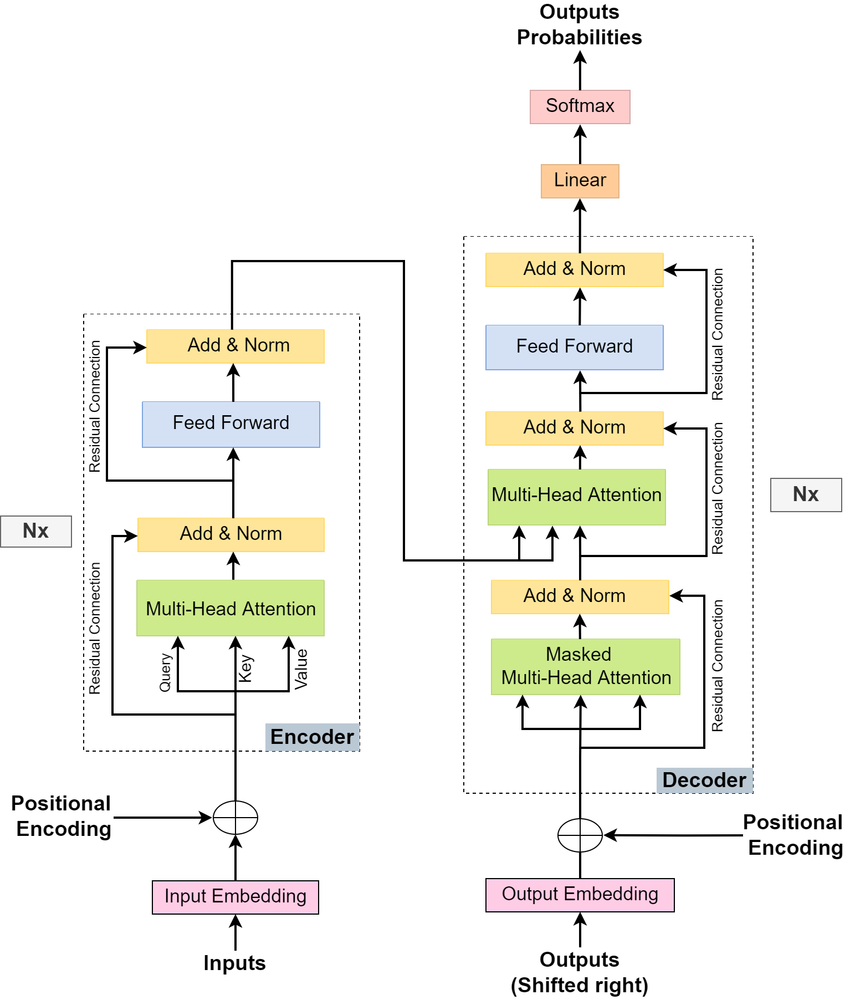
▲ 经典 Transformer 架构图(来源:Vaswani et al., 2017)
Transformer 由 编码器(Encoder) 和 解码器(Decoder) 两大部分组成:
1.3 自注意力机制——核心中的核心
用一个生活化例子来解释:
🍕 类比:自注意力像"披萨师傅撒料"
假设你在读句子:“苹果股价上涨,因为它发布了革命性AI芯片。”
- 每个词生成三组向量:Query(我想知道什么)、Key(我能提供什么信息)、Value(我的实际内容)
- “苹果"的 Query 会和所有词的 Key 做匹配,发现和"发布”"芯片"最相关
- 最终输出 = 根据相关度加权求和,让"苹果"理解自己指的是公司而非水果

(此图仅供理解,内部的词关联不一定对。)
1.4 小结:Transformer 的关键点
| 特性 | 说明 |
|---|---|
| 并行计算 | 所有词同时处理,不像RNN逐个读 |
| 自注意力 | 任意两个词之间可以直接建立联系 |
| 位置编码 | 用数学函数告诉模型"词在哪个位置" |
| 可堆叠 | 多层编码器/解码器叠加,逐层提取更深层特征 |
2. 砖块:什么是 BERT?
💡 一句话总结:BERT = 只用 Transformer 的编码器部分 + 双向理解上下文 + 两种预训练任务
2.1 BERT 的核心理念
BERT(Bidirectional Encoder Representations from Transformers)由 Google 在 2018 年发布,它做了一件事:
用海量无标注文本"预训练"一个模型,学会"理解语言",然后再用少量标注数据"微调"做具体任务。
这就像一个人先读了几千本书(预训练),掌握了语言的精髓,然后只需要做几道练习题(微调)就能成为某个领域的专家。
2.2 为什么说 BERT 是"双向"的?
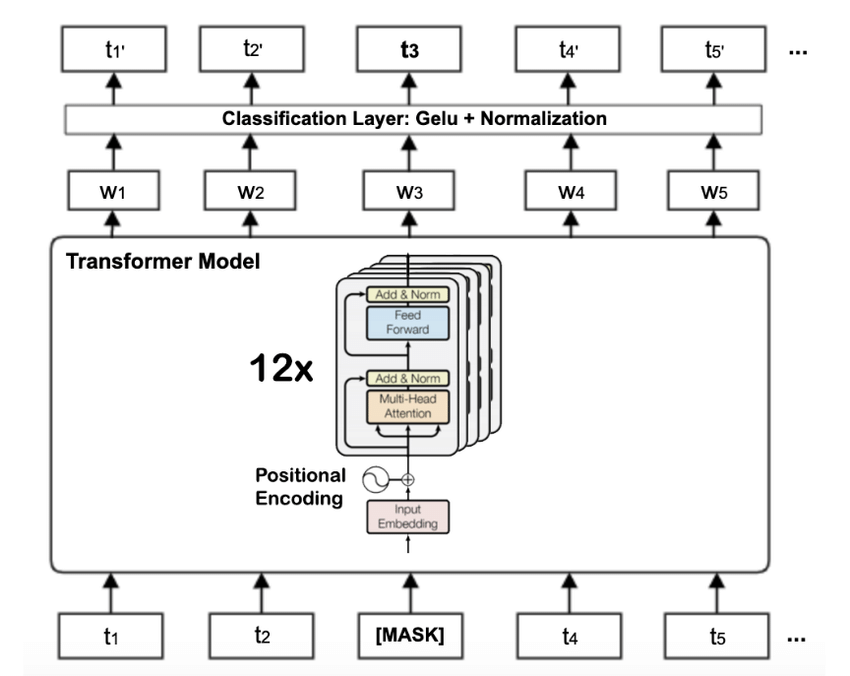
▲ BERT-base 由12层 Transformer 编码器堆叠而成
之前的语言模型(如 GPT-1)是 单向 的——只能从左到右读句子。而 BERT 同时从两个方向 理解每个词:
传统(GPT): 我 → 爱 → 吃 → 苹果 (只看前面的词来理解"苹果")
BERT: 我 ← 爱 → 吃 ← 苹果 (同时看前后所有词来理解"苹果")
2.3 BERT 的两个预训练任务
| 任务 | 做什么 | 学到什么 |
|---|---|---|
| MLM(掩码语言模型) | 随机遮住15%的词,让模型猜 | 词与上下文的关系 |
| NSP(下一句预测) | 给两个句子,判断是否连续 | 句子之间的关系 |
2.4 BERT 的输入三件套
BERT 的输入由三种 Embedding 相加而成:
最终输入 = Token Embedding(词向量)
+ Segment Embedding(区分句子A/B)
+ Position Embedding(位置信息)
2.5 BERT 的两个版本
| 版本 | 层数(L) | 隐藏维度(H) | 注意力头(A) | 参数量 |
|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 1.1亿 |
| BERT-large | 24 | 1024 | 16 | 3.4亿 |
2.6 小结:BERT 的关键点
🎯 BERT 就是一个 “超强语言理解引擎”:它通过海量文本学会了理解语言,然后可以通过微调适配各种任务(分类、问答、命名实体识别等)。
3. 分支一:Sentence-BERT —— 让句子"可以比较"
3.1 BERT 有什么问题?
BERT 很强,但有个尴尬的问题:
❌ BERT 生成的句子向量不适合直接比较相似度!
为什么呢?有两个原因:
原因1:BERT的向量空间是"歪的"
BERT 输出的词向量呈锥形分布——高频词(如"的"“了”)聚集在锥形的尖端,低频词散布在尾部。这导致用这些向量算相似度效果很差。
原因2:BERT比较两句话太慢了
如果要从10000个句子中找最相似的,BERT 需要把每对句子都输入模型做一次推理:
BERT方式:10000 × 9999 / 2 = 约5000万次 → 约65小时 🐢
3.2 Sentence-BERT 是什么?
Sentence-BERT(SBERT) 由 Reimers 和 Gurevych 在 2019 年提出,论文名为 “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks”。
💡 一句话总结:Sentence-BERT = 孪生BERT网络 + 对比学习微调 → 输出高质量句子向量
它解决了 BERT 的两大痛点:
- ✅ 输出的句子向量可以直接用余弦相似度比较
- ✅ 10000个句子只需编码10000次 → 约5秒 ⚡
3.3 核心架构:孪生网络(Siamese Network)
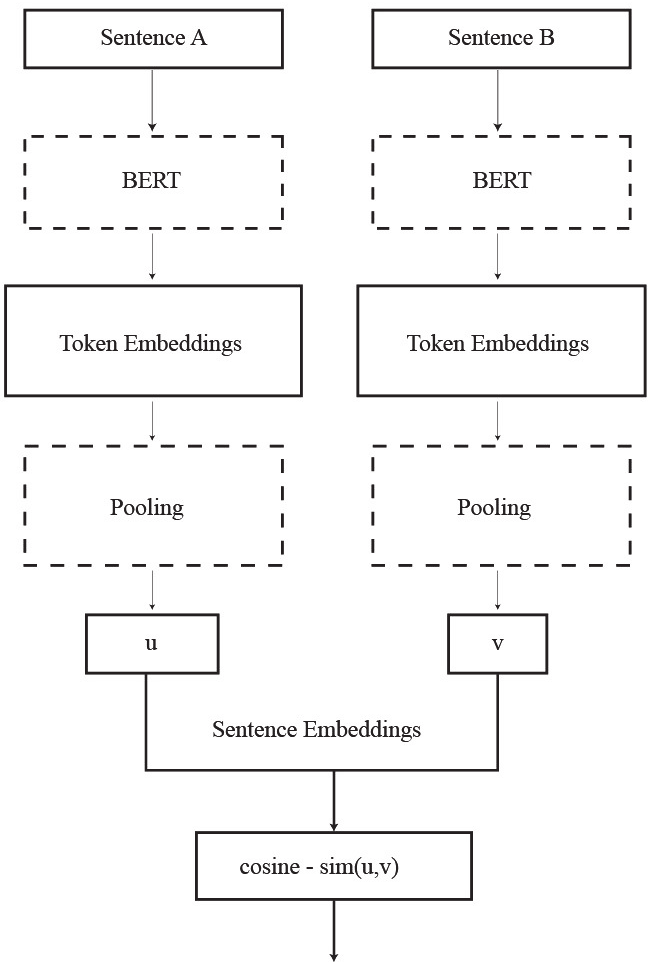
▲ Sentence-BERT 的孪生网络架构
关键设计解读:
| 组件 | 说明 |
|---|---|
| 孪生网络 | 两个BERT 共享完全相同的参数,分别输入句子A和句子B |
| 池化策略 | 对BERT最后一层所有token的向量取 均值池化(实验证明效果最好) |
| 向量拼接 | 将 u、v、|u-v| 三者拼接(3倍维度),输入全连接层 |
| 损失函数 | 根据标注数据类型选择:二分类用交叉熵,打分用MSE,三元组用Triplet Loss |
3.4 三种损失函数详解
Triplet Loss 直觉理解:
让"基准句"和"正例句"的距离尽量小,和"负例句"的距离尽量大。就像让你站在两个人中间:拉近朋友的手,推开陌生人。
3.5 效果有多惊艳?
| 场景 | BERT方式 | Sentence-BERT方式 |
|---|---|---|
| 10000句找最相似 | ~65小时 | ~5秒 |
| 句子编码方式 | 两句拼一起输入 | 每句独立编码 |
| 向量可复用? | ❌ 不可以 | ✅ 编码一次永久使用 |
| 适合大规模检索? | ❌ | ✅ 完美适合 |
代码示例:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
sentences = ['中午我想吃清蒸鲈鱼', '天气预报说明天下雨',
'食堂的餐饭不好吃', '我做了红烧鱼作为中午的饭菜']
embeddings = model.encode(sentences) # 输出 (4, 384) 的矩阵
# 直接用余弦相似度比较即可!
4. 分支二:GraphCodeBERT —— 让AI"读懂代码"
4.1 背景:代码 ≠ 普通文本
之前的预训练模型(包括 BERT)处理代码时,把代码当成 一串普通文字 来读:
v = max_value - min_value # 模型只看到一堆token,不懂变量之间的依赖关系
但代码有独特的 结构信息——变量之间存在数据依赖关系(“v 的值来自 max_value 和 min_value”)。忽略这些结构,就像只看歌词不听旋律。
4.2 进化路线:从 CodeBERT 到 GraphCodeBERT
| 模型 | 输入 | 理解能力 |
|---|---|---|
| BERT | 自然语言 | 文本语义 |
| CodeBERT | 自然语言 + 代码 | 双模态语义(但忽略代码结构) |
| GraphCodeBERT | 自然语言 + 代码 + 数据流图 | 双模态语义 + 代码结构语义 |
4.3 核心创新:数据流图(Data Flow Graph)
GraphCodeBERT 没有用复杂的 AST(抽象语法树),而是选择了更简洁的 数据流图: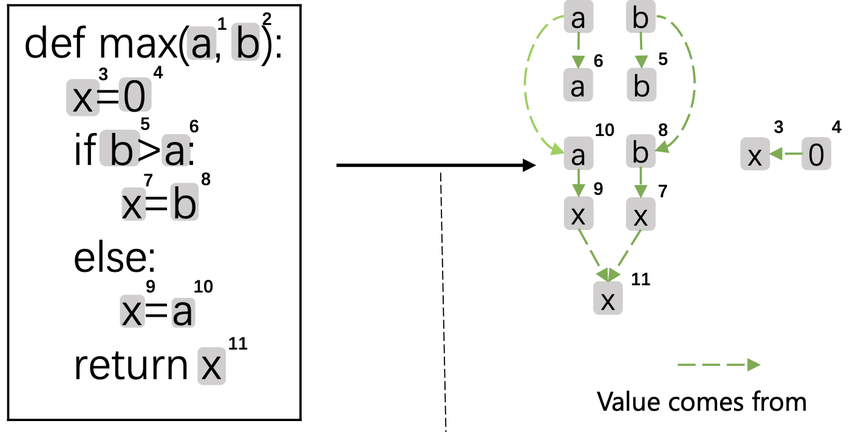
▲ GraphCodeBERT 使用的数据流图示例
数据流图 vs AST:
| 对比项 | AST(抽象语法树) | 数据流图(DFG) |
|---|---|---|
| 节点 | 所有语法元素 | 仅变量 |
| 边 | 父子语法关系 | "值从哪来"关系 |
| 复杂度 | 深层树形结构 | 扁平简洁的图 |
| 效率 | 较低 | 较高 |
举例说明:
x = 3
y = 5
z = x + y
对应的数据流图:
含义:z 的值来自 x 和 y。模型通过理解这种"值的流向"关系来理解代码的语义。
4.4 GraphCodeBERT 的架构
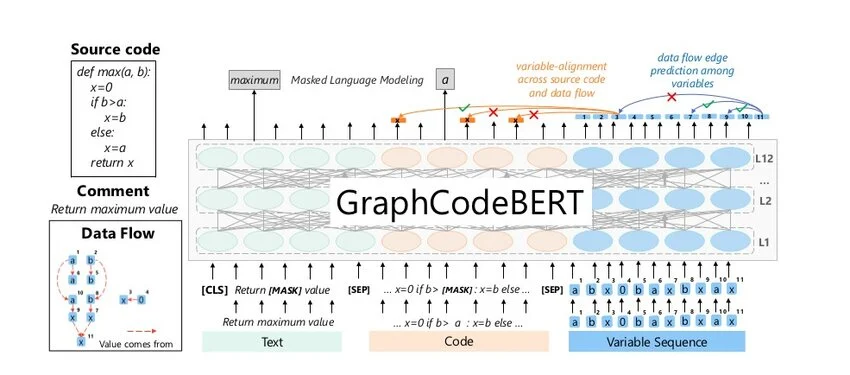
▲ GraphCodeBERT 的模型架构(Guo et al., 2021)
输入格式:
X = { [CLS], 注释文本W, [SEP], 源代码C, [SEP], 变量节点V }
4.5 三个预训练任务
GraphCodeBERT 在传统 MLM 基础上,新增了两个"结构感知"任务:
| 预训练任务 | 做什么 | 学到什么 |
|---|---|---|
| MLM | 猜被遮住的代码 token | 代码的文本语义 |
| Edge Prediction 🆕 | 猜数据流图中两个变量是否有边 | 变量之间的依赖关系 |
| Node Alignment 🆕 | 猜数据流节点对应的源码 token | 结构和代码的对齐关系 |
4.6 图引导掩码注意力(Graph-Guided Masked Attention)
这是 GraphCodeBERT 对标准 Transformer Attention 的改进:
普通 Attention:每个 token 可以看到所有其他 token
图引导注意力:数据流节点只能看到与自己有边连接的其他节点 + 对应的代码 token
这就像给注意力加上了"视野限制",让模型更专注于代码结构中真正相关的部分。
4.7 下游任务与效果
GraphCodeBERT 在 CodeSearchNet 数据集上预训练(2.3M 函数,6种编程语言),可以做以下任务:
| 任务 | 说明 | 效果 |
|---|---|---|
| 代码搜索 | 用自然语言搜索代码片段 | SOTA (2021) |
| 克隆检测 | 判断两段代码功能是否相同 | SOTA |
| 代码翻译 | 如 Java → C# | SOTA |
| 代码修复 | 自动修复有Bug的代码 | SOTA |
代码示例:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("microsoft/graphcodebert-base")
model = AutoModel.from_pretrained("microsoft/graphcodebert-base")
# 输入:自然语言 + 代码
nl = "return maximum value"
code = "def max(a,b): if a>b: return a else return b"
tokens = [tokenizer.cls_token] + tokenizer.tokenize(nl) + \
[tokenizer.sep_token] + tokenizer.tokenize(code) + [tokenizer.sep_token]
token_ids = tokenizer.convert_tokens_to_ids(tokens)
import torch
embeddings = model(torch.tensor(token_ids)[None, :])[0]
# 输出:每个 token 的上下文向量表示
5. 总结对比与应用场景
5.1 完整技术族谱
5.2 全面对比表
| 维度 | BERT | Sentence-BERT | GraphCodeBERT |
|---|---|---|---|
| 提出时间 | 2018 | 2019 | 2021 |
| 提出者 | UKP Lab (达姆施塔特工大) | Microsoft (MSRA) | |
| 基础架构 | Transformer 编码器 | 孪生 BERT 网络 | Transformer 编码器 + 图引导注意力 |
| 输入类型 | 自然语言 | 自然语言(句子对) | 自然语言 + 代码 + 数据流图 |
| 预训练任务 | MLM + NSP | 无额外预训练(微调BERT) | MLM + 边预测 + 节点对齐 |
| 输出 | 每个token的上下文向量 | 句子级别的向量 | 代码+注释的上下文向量 |
| 核心创新 | 双向理解上下文 | 孪生网络 + 对比学习 | 数据流图 + 图引导掩码注意力 |
| 典型应用 | 文本分类、问答、NER | 语义检索、文本聚类、问答匹配 | 代码搜索、克隆检测、代码翻译 |
| 参数量 | 110M / 340M | 与所用BERT相同 | 125M |
5.3 应用场景速查
5.4 一个统一的直觉理解
把这三个模型想象成三个"专才":
🧠 BERT = 语言学教授:精通语法和语义,可以做各种语言理解题
🔍 Sentence-BERT = 图书管理员:能快速给每本书贴上"语义标签"(向量),你说一句话,TA 能秒找到最相关的书
💻 GraphCodeBERT = 资深程序员 + 语言学教授:不仅读懂代码的文字,还理解变量之间的数据流动关系
📚 延伸阅读
| 资源 | 链接 |
|---|---|
| Transformer 论文 | Attention Is All You Need (Vaswani et al., 2017) |
| BERT 论文 | BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018) |
| Sentence-BERT 论文 | Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (Reimers et al., 2019) |
| GraphCodeBERT 论文 | GraphCodeBERT: Pre-training Code Representations with Data Flow (Guo et al., 2021, ICLR) |
| Hugging Face 模型库 | microsoft/graphcodebert-base、sentence-transformers/ |
📝 小结:从 Transformer 到 BERT,再到 Sentence-BERT 和 GraphCodeBERT,本质上是一条"通用 → 专精"的路线。Transformer 提供了强大的注意力机制地基;BERT 在此基础上学会了理解自然语言;Sentence-BERT 让句子向量变得可比较、可检索;GraphCodeBERT 则把理解能力延伸到了代码世界,并融入了代码独有的结构信息。理解了这条脉络,你就掌握了当今NLP与代码智能领域最核心的一组模型家族。🎉

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)