如何在没有什么基础的情况下用ai(比如豆包)编程做nlp——一个给小白的实战案例参考
这篇文章为编程新手和NLP初学者提供了一个简单的中文文本处理实战指南。作者通过复现一篇经济学论文中的NLP部分,详细演示了从PDF到文本转换、中文分词、词库构建(使用jieba和nltk)、词库清洗到情感值计算的全流程。文章特别强调了在实际操作中可能遇到的常见问题(如环境配置、词库匹配错误等)及解决方法,并分享了使用AI辅助编程的经验。
摘要
这篇文章为编程新手和NLP初学者提供了一个简单的中文文本处理实战指南。作者通过复现一篇经济学论文中的NLP部分,详细演示了从PDF到文本转换、中文分词、词库构建(使用jieba和nltk)、词库清洗到情感值计算的全流程。文章特别强调了在实际操作中可能遇到的常见问题(如环境配置、词库匹配错误等)及解决方法,并分享了使用AI辅助编程的经验。
这篇文章适合以下这两种人观看:
1.没有什么编程经验,想使用ai辅助编程的人2.没做过nlp,想看看简单的nlp的具体步骤的人
前言
自然语言处理(Nature Language Process)是近年编程技术在经济学领域比较常见,近年也比较火的应用。本次我们的练习是使用python和中文素材,模仿Journal of International Economics的一篇论文其中nlp的部分,这部分处理对于完全没接触过的人看起来有点复杂,但其实在毫无编程基础的情况下,我们也可以做出来。
论文链接:Supply chain risk: Changes in supplier composition and vertical integration - ScienceDirect
这篇文章使用的是传统的词典匹配法,目前自然语言处理比较前沿的做法是使用LLM,但对于小白,个人感觉能复现这篇文章已经是不错的了。如果你和我一样是一个就读于商科的本科生,这个对于你的参营论文或者是毕业论文已经完全够用了。如果你是一个非统计学或码类专业的学生,只是想把这个作为你文章的一个亮点的话,那么你是一个硕士生也完全够用。
另外我问了一些本校毕业论文涉及到nlp的博士学长学姐,很多人做的内容也没有比这个复杂特别多(当然他们的主业不是研究这个,也只是一个部分而已)
当然,说“完全没有”基础可能有点标题党了,你至少需要知道Pycharm(或者VScode)之类的编程软件是怎么用的,对于导入路径、导出路径至少要知道应该怎么填,并且要会安装外部包,懂得看哪个是函数,哪个是宏(便于你理解程序的逻辑,以debug)。
另外一个帖子提供了我在使用ai辅助编程中总结的一些经验,如果你也正在面对一个需要编程的任务并且觉得毫无头绪,或许这两篇帖子可以给你一个参考。毕竟我能做的话你肯定也能做,因为题主的C语言这门课只考了80分出头。
使用ai辅助编程中总结的一些经验:
好的,如果你需要的话,可以往下看:
正文
一、确定工作步骤
首先我们需要详细地读完论文,然后确定文章进行nlp的步骤。这一部分是非常重要的,无论是对于复现文章,还是对于第一次做nlp的新手。文章的链接我已经贴在前面,大家可以自己看,这里不再赘述,直接列出:
1.构建词库:找到两本比较权威的参考书,将这两个参考书中的关键词提取出来,构成供应链词库和金融词库,这里简称为S(supply)和F(finance)库。
2.清洗词库:在S库中删去在F库中也出现的词,获得一个纯净的S库,这里成为ps(pure supply)库。
3.下载年报,根据下列公式进行计算。这篇文章实际上计算了两个情感值,一个是情绪值,还有一个是类似“风险感知值”的一个东西,我们就挑一个来练习一下就好了,公式如下:
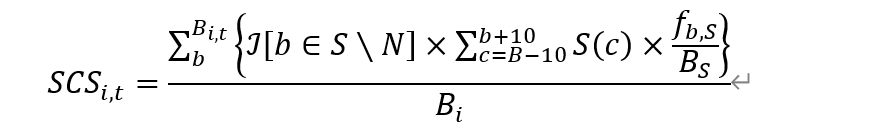
这个公式里面每个字母的含义在文章中有详细的说明,大概在10-13页,这里就不细说了,后面我会用简单的话解释一下。
二、开始处理
虽然我们在前面已经写出了三个步骤,但这是非常粗糙的,在每个具体环节,我们需要先看清楚、想清楚我们每一步要做什么。
1.构建词库
使用jieba和nltk将《财务会计》《供应链管理》两本书进行分词,提取双词组(bigrams)。
因为我是要做中文的nlp,所以就随便找了两本类似的中文教材。
根据论文,我们可以知道他们使用了nltk这个库,那么对于这个没听过的东西,我们可以首先在csdn和ai上搜索一下这个库,看看具体是做什么用的,有哪些关键参数(比如说nltk需要设置停止词),有什么效果,这有助于我们给出详细的编程目标,帮助我们写出更好的ai指令,之后的处理中也如法炮制。
nltk和jieba是nlp非常常见的一个函数,jieba他可以把文本划分成一个个词,但只能直接读取字符,但我们拿到的书肯定是以pdf出现的,那么我们就先要要把pdf处理成txt。
pdf转成txt有两种情况,一种是pdf是文字版的,一种是pdf是纯图片的。如果是文字版,可以直接用PyPDF2来转为txt,如果是图片版的就要安装Tesseract OCR引擎来识别。我比较推荐大家先用PyPDF2试一下,因为Tesseract OCR识别起来非常费时间,这本几百页的书让我的电脑跑了2个多小时。
很遗憾,经过三个小时的运行,我的PyPDF2被判定为不合格。因此我安装了Tesseract OCR,下面是我使用的安装教程,非常详细,推荐给大家:
我们需要先使用jieba对文本进行分词,然后用nltk生成Biagrams,nltk处理中文很容易产生一堆无意义的词,我个人试下来感觉主要是因为在使用nltk之前没有清洗好文本。在使用jieba之前,我们需要去除标点符号、数字、字母,在jieba分好词之后,我们再去除单个字符、人名、介词等无意义的词语,最后才能使用nltk生成Bigrams。
这个链接中详细写出了jieba如何给词语进行分类,参考这个表格你可以选择删去哪些对于你的词库无用的词,如果你第一次用jieba,我非常推荐你看一下。
下面是我去除的词性,以及设置的停用词列表,大家可以参考:
def filter_words(text):
words_with_pos = pseg.cut(text)
# 要过滤的词性集合
pos_to_filter = {"m", "p", "c", "nr", "nrf", "nrj","ud","uj","uv","df"}
filtered_words = []
for word, flag in words_with_pos:
# 过滤单个字、指定词性的词
if len(word) > 1 and flag not in pos_to_filter:
filtered_words.append(word)
return filtered_words最后我们让nltk生成Bigrams,计算词频,并且储存在excel中。以下是我最后得到的关于供应链的Bigrams,大家可以看到效果还是不错的,并且这些是还没有经过人工清洗的。
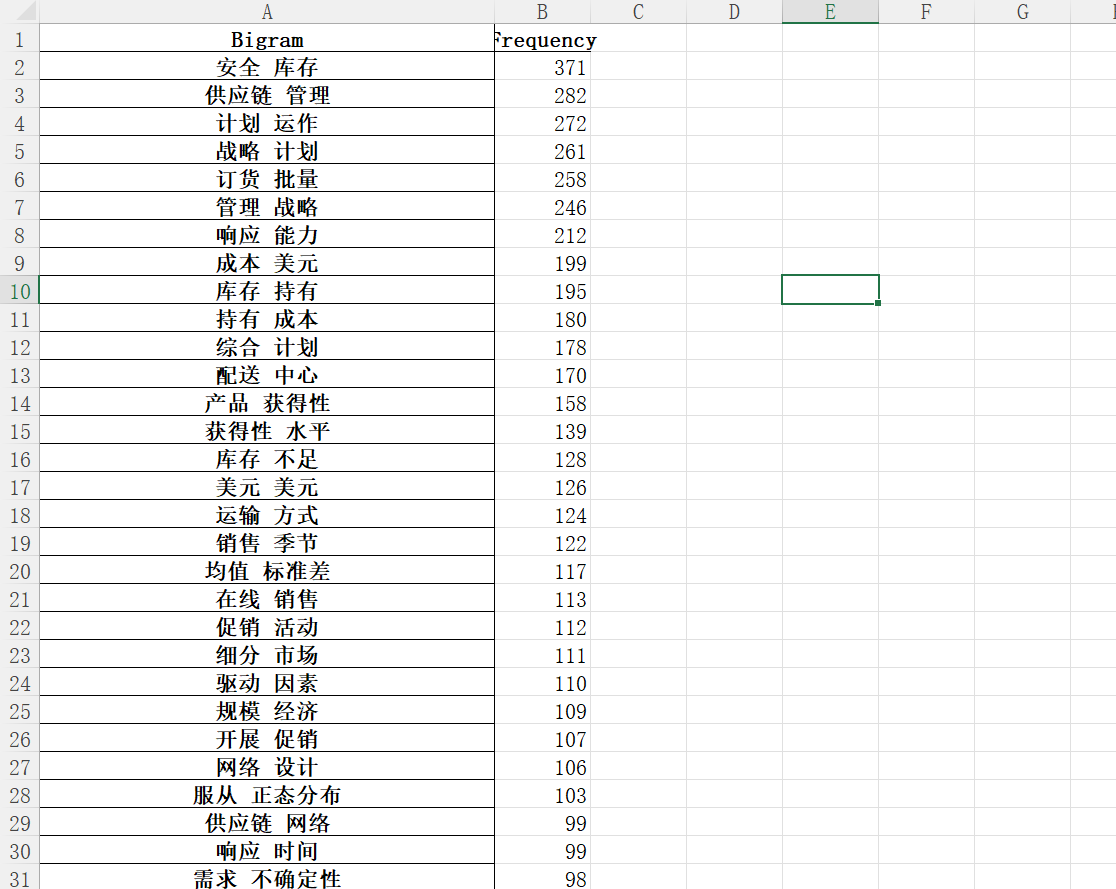
我问了一个统计系做LLM的学姐,她表示现在一般还是要生成bigrams的,但我也有看到一些论文只用了单个词进行匹配(比如库存、管理这样),所以用单个词组成的词库应该也可以,而且在匹配的时候会比较简单一点。但我个人感觉单个词组成的词库有些词单独出现的时候意义不明,比如这样: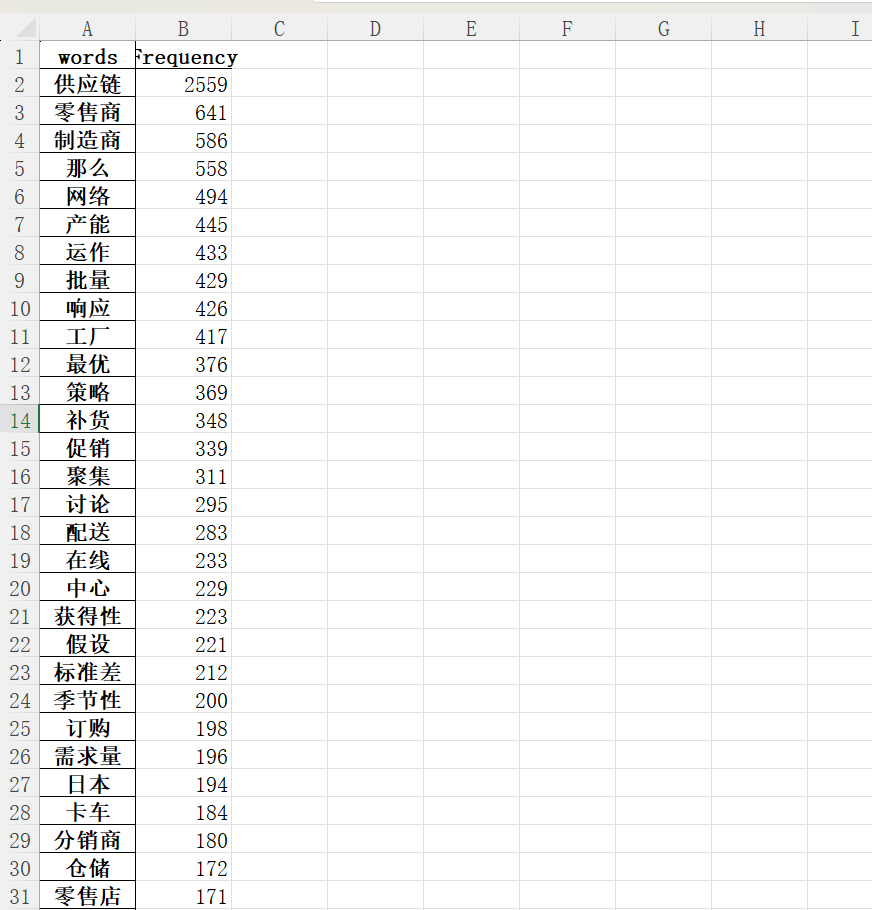
2.清洗词库:
这步比较简单,就不说了。
3.计算情感值:
这一步就碰到了程序不报错,但是跑出的结果全是0的情况,浪费了我很多时间。我用各种方式修改了程序,试图寻找bug,并且最后因为没招了就又人工码了好几次代码,终于跑出了结果。但我也不太清楚具体是哪一步解决了bug,但可以确定的是问题出在词库的匹配上面,我最后的方案是将词库导入后存为词典,并且把分好词的文章存为json格式,或许这种方式在匹配的过程中比较不容易出问题。
(1)下载年报,这一部分参考如下链接即可:
Python高速下载分析巨潮资讯网年度报告PDF版(一)_年报下载。python-CSDN博客
(2)按照第一步预处理的方法, 运用jieba对企业年报进行分词,清洗。注意,由于这篇文章在匹配的过程中是采用遍历的方式逐个匹配的,所以我把这些内容储存为了json格式。
(3)下载消极、积极情绪词库,这部分使用知网词库、哈工大词库都行,反正咱们随便下一个,和前面的词库一起导入之后以字典形式储存。
#导入ps词库(我是用excel储存的)
def read_excel_library(file_path):
try:
df = pd.read_excel(file_path)
# 将 words 列作为键,Frequency 列作为值,转换为字典
return dict(zip(df['words'], df['Frequency']))
except FileNotFoundError:
print(f"错误:未找到文件 {file_path}。")
return {}
except Exception as e:
print(f"读取 Excel 文件 {file_path} 时出错:{e}")
return {}
# 读取消极和积极词库
def read_sentiment_word_libraries():
try:
with open('optimistic.json', 'r', encoding='utf-8') as f:
positive_words = json.load(f)
#optimistic就是积极词库
with open('pessimistic.json', 'r', encoding='utf-8') as f:
negative_words = json.load(f)
return negative_words, positive_words
except FileNotFoundError:
print("错误:未找到消极或积极词库文件。")
#用于检查是否出错了
return [], [](4)计算情感值。到这一步我们又要给出一个ai指令,并在此基础上进行修改。下面我们有两种选择:
一:是直接把公式贴给ai,跟他解释每个变量的意义,让他写一个程序
二:用通俗易懂的话跟他解释这个情感值是怎么算的,比如我给出的这个公式的含义其实就是:遍历txt文件中的每一个Biagram,如果这个词和ps库中的词相同,则遍历其前后10个词,如果出现n个消极词库中的词,则该词得分-n,如果出现n个积极词库中的词,则该词得分-n。最后根据这个核心词在ps词库中记录的频率分配一个权重(这个词在ps词库中记录的频率越高,意味着他在供应链参考书这本书里面出现的频率越高,也就是越可能与供应链话题紧密相关,因此可以给一个更高的权重)。
这两个方式我们都可以试一下,因为ai毕竟是一个类似黑箱的东西,我们也不确定怎么给命令可能更不容易写错。但你自己肯定是要清楚这个公式用人话是怎么解释的,因为这可以方便你检查程序是否有错。
这个程序有点长,就不完整放在这里了,下面这段只是用于计算这个公式的值的主函数。我当时主要就是从这个主函数里面查出问题的。大家可以看到这个函数是有很多括号嵌套的,我让他在每一步计算后都给一个return,看看目前的值是多少,看看是到哪一步变成0了。然后就这样一步一步尝试,逐步排除是哪一个参数计算的时候出了问题,最后发现是ps词库的问题。
def calculate_scsentiment(tokens, S_dict, N_dict, negative_words, positive_words):
# 计算词数量,token是被处理的这个reports里的所有词
total_tokens = len(tokens)
word_list = 0
if total_tokens == 0:
return 0 # 返回数值 0
numerator = 0.0
B_S = sum(S_dict.values()) # 计算S库的总频率
for i, token in enumerate(tokens):
if token in S_dict: # 改为检查token是否在S字典中
word_list += 1
context_start = max(0, i - 20)
context_end = min(len(tokens), i + 20)
context_tokens = tokens[context_start:context_end]
net_sentiment = 0.0
for c in context_tokens:
if c in negative_words:
net_sentiment -= 1
if c in positive_words:
net_sentiment += 1
# 从S字典中获取该token的频率值
f_token_S = S_dict.get(token, 0)
numerator += net_sentiment * (f_token_S / B_S if B_S > 0 else 0)
if word_list == 0:
word_list = 1
return ( numerator / word_list )*100最后:能跑就是好程序
我在做这个nlp的过程中,建好的环境崩坏了一次,anaconda也用不了,问了一圈学计算机的同学都没解决,然后就把所有程序都放在了pycharm自带的唯一的虚拟环境里,这个不太好,还是一个工程放一个环境比较好,但后面一直没出问题,朋友说“程序能跑就别乱动”,遵循这个准则一直把这个工程就这样干完了。
大家有问题欢迎在评论区交流~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)