GigaBrain-0.5M*:一个基于世界模型强化学习的VLA
26年2月来自极佳科技的论文“GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning”。直接根据当前观测结果预测多步动作块的视觉-语言-动作(VLA)模型由于场景理解受限和未来预测能力较弱而面临固有的局限性。相比之下,在网络规模视频语料库上预训练的视频世界模型展现出强大的时空推理能力和准确的未
26年2月来自极佳科技的论文“GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning”。
直接根据当前观测结果预测多步动作块的视觉-语言-动作(VLA)模型由于场景理解受限和未来预测能力较弱而面临固有的局限性。相比之下,在网络规模视频语料库上预训练的视频世界模型展现出强大的时空推理能力和准确的未来预测能力,使其成为增强VLA学习的理想基础。因此,提出GigaBrain-0.5M*,一个通过基于世界模型强化学习训练的VLA模型。GigaBrain-0.5M基于GigaBrain-0.5构建,后者在超过10,000小时的机器人操作数据上进行预训练,其中间版本目前在国际RoboChallenge基准测试中排名第一。GigaBrain-0.5M进一步通过RAMP(基于世界模型条件策略的强化学习)集成基于世界模型的强化学习,从而实现强大的跨任务适应能力。实证结果表明,RAMP 相较于 RECAP 基线系统取得显著的性能提升,在包括衣物折叠、纸箱打包和意式浓缩咖啡制作等高难度任务上,性能提升幅度约为 30%。更重要的是,GigaBrain-0.5M* 展现出可靠的长时程执行能力,能够持续无故障地完成复杂的操控任务。
策略模型的世界模型
世界建模领域的最新突破(Agarwal,2025;Alhaija ,2025;Assran ,2025;Jang ,2025;Jiang ,2025;Kong ,2024;Liao ,2025;Wang ,2025)加速了生成数据在具身人工智能系统中弥合模拟与现实差距方面的应用(Zhu ,2024)。在自动驾驶中,利用世界模型生成极端情况数据(Gao ,2023,2024;Hu ,2023;Ren ,2025;Russell ,2025;Wang ,2024;Zhao ,2025)并构建交通状况(Ni ,2024,2025;Zhao ,2024,2025)。在具身机器人领域,诸如(Team et al., 2025)等技术利用世界模型生成的样本,涵盖纹理多样的场景(Dong et al., 2025; Liu et al., 2025; Yuan et al., 2025)、多视角渲染(Xu et al., 2025)以及以自我为中心的平移(Li et al., 2025),来丰富VLA模型的训练数据。另一种范式是通过世界模型预测未来的视觉轨迹(例如,DreamGen (Jang et al., 2025) 和 ViDAR Feng et al. (2025)),然后通过逆动力学模型(IDM)推断可执行的运动指令。此类流程的有效性关键取决于生成序列的视觉保真度和物理合理性。除了数据生成之外,新方法还致力于探索世界模型与策略学习之间更紧密的整合。例如,(Bi et al., 2025; Cen et al., 2025; Li et al., 2026, 2025; Pai et al., 2025; Wang et al., 2024)等方法将预测性世界模型的潜表征与策略网络融合,以提高样本效率和泛化能力。更具挑战性的是,(Kim et al., 2026)等框架完全绕过显式的策略网络,直接将世界模型预测映射到行动序列。
视觉-语言-动作模型的强化学习
模仿学习策略由于分布偏移而遭受累积误差的影响(Ross,2011),其性能本质上受限于演示数据的质量。尽管DAgger及其变体(Jang,2022;Kelly,2019)通过在线专家干预缓解这一问题,但它们仍然依赖于持续的人工监督,并且缺乏自主策略改进机制。为了克服模仿学习的局限性,强化学习已被广泛应用于机器人策略优化。传统方法采用在线策略算法(Schulman,2017)或离线策略方法(Kalashnikov,2018)通过环境交互来优化策略。最近的研究将这些范式扩展到视觉-语言-动作模型,例如通过直接策略梯度优化(Lu,2025;Tan,2025)或在冻结骨干网络上进行残差策略学习(Guo,2025)。然而,由于训练不稳定和样本效率低下,将策略梯度方法扩展到VLA仍然面临挑战。一种新兴的研究方向是通过将动作生成与价值信号挂钩来规避显式的策略梯度计算,包括基于奖励的策略(Kumar,2019)和基于优势的策略(Kuba,2023;Wu,2023)。最近,Intelligence(2025)提出了一个通过优势为条件策略带经验和纠正的RL(RECAP)框架,证明基于优势的强化学习能够使VLA通过机器人自带数据采集在下游任务上取得优异性能。
GigaBrain-0.5M
在 VLA 模型 GigaBrain-0.5 的基础上,推出 GigaBrain-0.5M*,这是一个增强的策略模型,它集成基于世界模型的强化学习:RAMP(通过世界模型条件策略进行强化学习)。如图所示:它基于多模态、机器人操作和网络视频数据进行预训练,能够通过人机交互(HIL)部署实现自我改进,从而生成多样化的训练数据以进行持续训练。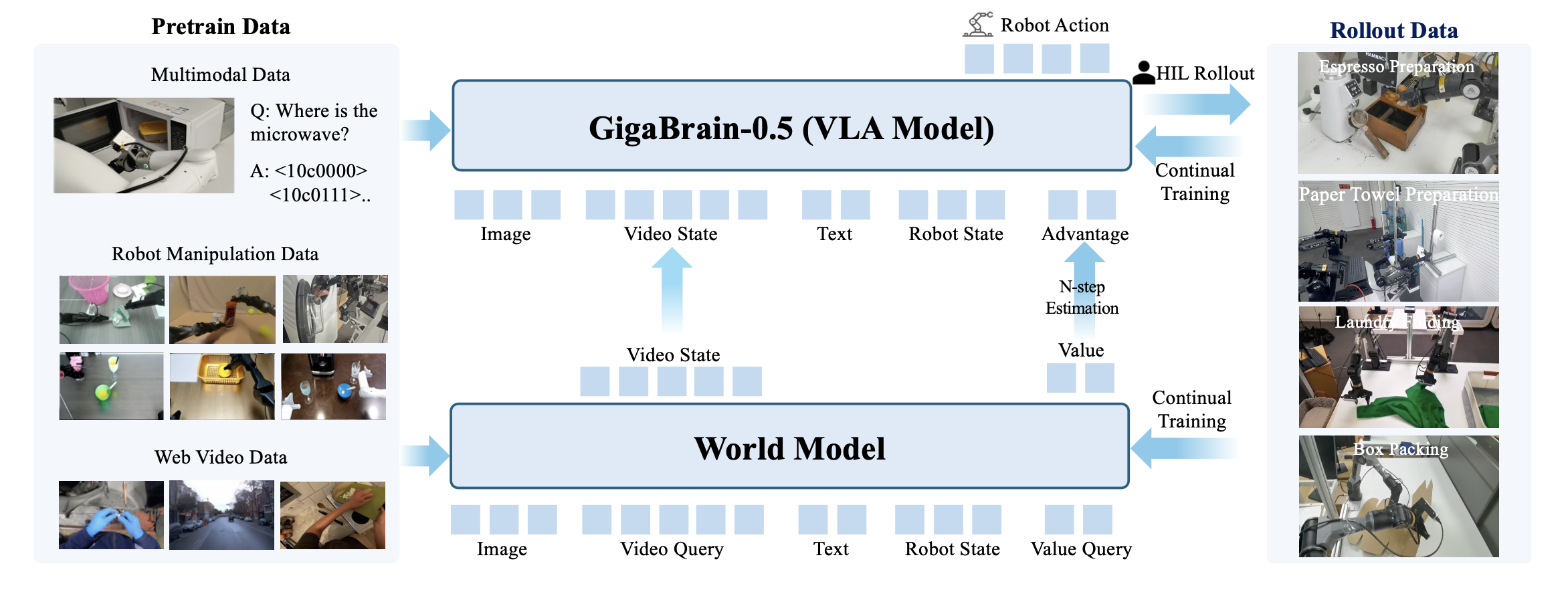
RAMP 公式
为了推导出能够利用世界模型潜变量的可扩展训练目标,将 KL 正则化强化学习框架扩展到增强状态空间 S = (o, z, 𝑙),其中 z 表示世界模型提取的潜表示。目标是在最大化预期收益的同时,通过 KL 散度约束策略 𝜋 不偏离参考策略 𝜋_ref(·|S)。
为了缓解直接估计指数优势项带来的数值不稳定性,引入二元改进指标𝐼,并假设观察到改进事件的概率𝑝(𝐼 |𝑎, S)与该行动的指数优势成正比。通过应用贝叶斯定理,将这个难以处理的优势项重新表述为条件概率的比值。将此比率代回最优策略方程,即可将 𝜋ˆ 重新表示为无条件分布和条件改进分布的组合。因此,对神经网络 𝜋_𝜃 进行参数化,使其同时拟合这些分布,最终训练目标是最小化一个加权负对数似然函数。
明确地将潜状态 𝑧 纳入此目标并非仅仅出于结构上的选择,而是出于理论上的必然性。为了论证这一设计的合理性,从概率的角度考察方法 RAMP 与现有方法(例如 RECAP (Intelligence et al., 2025))之间的关系。从概率建模的角度来看,从理论上建立 RAMP 和 RECAP 之间的内在联系,并证明 RECAP 本质上是 RAMP 的一个退化特例,其中忽略关于未来潜状态的信息。具体而言,RECAP 的策略形式 𝜋(𝑎|𝑜, 𝐼) 在数学上等价于 RAMP 策略 𝜋(𝑎|𝑜, z, 𝐼) 在潜未来状态 z 上的边际分布。
这意味着 RECAP 有效地学习了一种平均策略,该策略必须在没有具体指导的情况下,隐式地整合和权衡所有可能的未来演化。相比之下,RAMP 通过显式地以世界模型的预测 z 为条件,消除了这种不确定性,从而将问题从对未来的平均猜测转化为针对特定物理状态的精确规划。此外,从信息论的角度来看,引入时空潜变量 z 为动作生成提供显著的信息增益。RECAP 仅依赖于稀疏的二元优势信号 (𝐼 ∈ {0, 1}) 进行粗略的信用分配,而 RAMP 利用 z 注入密集的几何结构和物理动力学先验,从而显著降低动作生成的条件熵 𝐻(𝑎|o,z,𝐼) ≤ 𝐻(𝑎|o,𝐼)。
RAMP实现
RAMP使VLA模型能够通过在整个训练生命周期中融入世界模型指导来学习经验。从大规模离线预训练到在自主部署数据上进行多轮迭代微调,方法实现策略的逐步改进。如图所示,该流程分为四个阶段: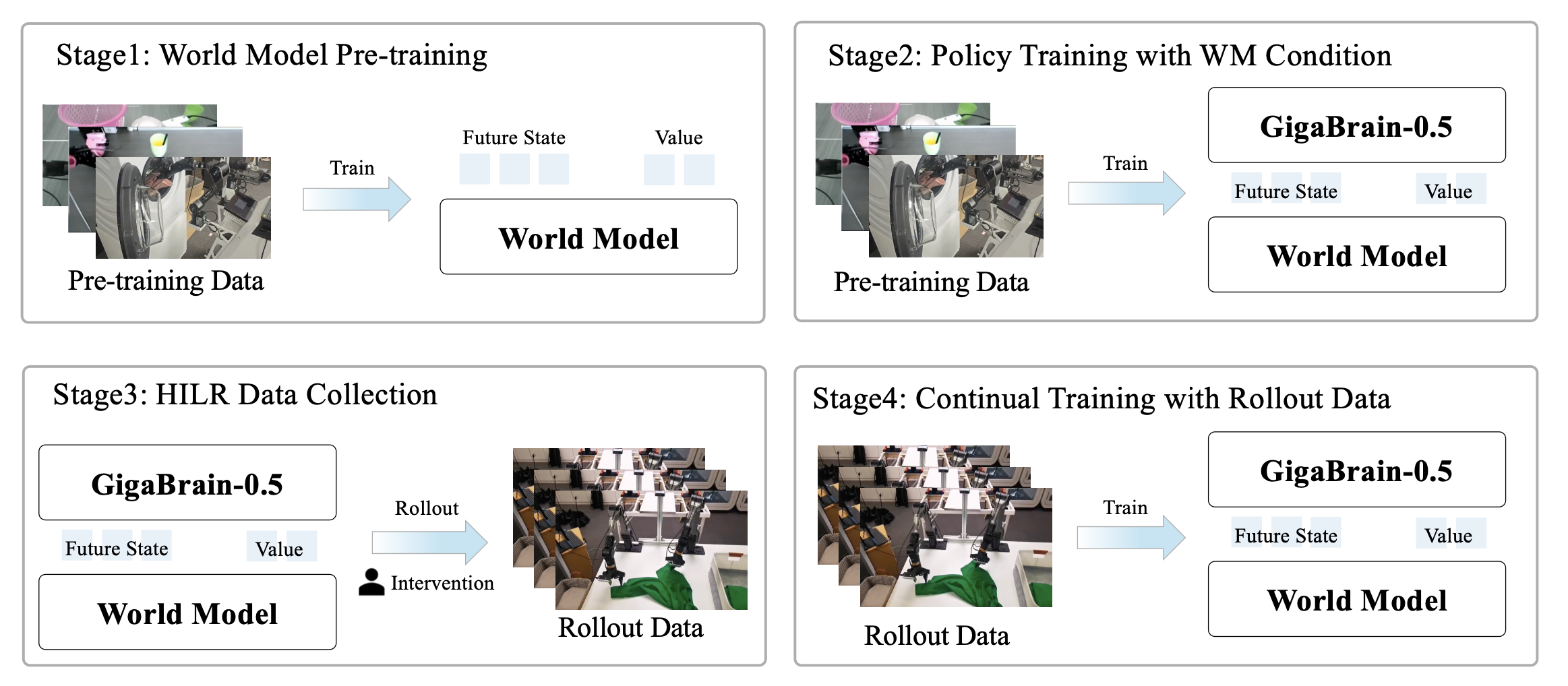
阶段1:世界模型预训练。初始阶段建立一个世界模型𝒲_𝜑,该模型能够联合预测未来的视觉状态和价值估计。借鉴Intelligence(2025)的方法,从episode级成功标签中导出稀疏奖励,使得价值函数对应于负的预期完成步骤数。
这种稀疏奖励机制鼓励策略在优先考虑任务完成而非部分完成的同时,尽可能缩短执行时间。遵循潜帧注入策略(Kim et al., 2026),将值信号嵌入为一个额外的潜帧,该潜帧与视觉潜状态连接后再输入到世界模型中。这种方法无需对底层扩散transformer进行任何架构修改。具体来说,首先使用预训练的VAE将未来的视觉观测值{o_𝑡+𝑖},i ∈ {12,24,36,48},编码为时空视觉潜值z_𝑡。同时,标量和低维辅助信号,包括当前值估计值𝑣_𝑡和本体感觉状态p_𝑡,通过空间平铺(tiling)投影Ψ(·)进行转换。该投影将低维向量复制到空间维度上,以匹配视觉潜变量的形状。
这种统一的表示方法使得世界模型能够在一次前向传播中联合推理视觉动态、任务进度(通过值)和机器人运动学。
采用 Wan2.2(Wang,2025)作为世界模型 𝒲_𝜑 的主干架构。该模型通过流匹配(Lipman,2022)进行训练。通过将未来的视觉状态和值估计视为时间上扩展的视频帧,DiT 主干架构自然地利用其时空自注意机制来建模当前观察、动作和未来任务结果之间的关系。
其利用 4K 小时的真实机器人操作数据来训练世界模型,数据分布如图所示: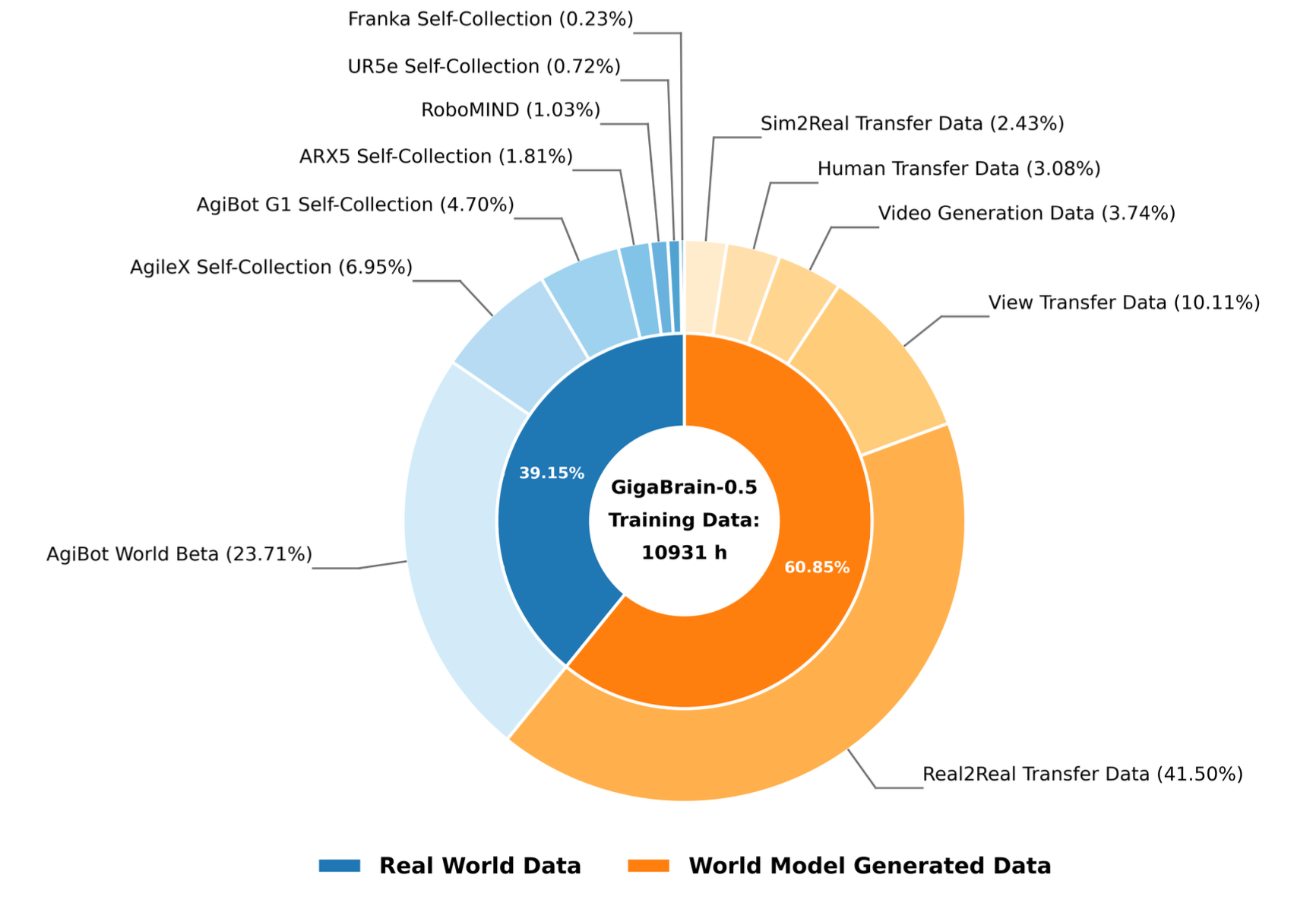
阶段 2:基于世界模型条件化的策略训练。第二阶段从预训练的 GigaBrain-0.5 检查点初始化策略,并利用世界模型条件化对其进行进一步微调。具体来说,策略接收由世界模型 𝒲_𝜑 预测的两个辅助信号:(1)未来状态token z_future,以及(2)价值估计 𝑣_𝑡。未来状态token通过轻量级多层感知器 (MLP) 进行投影,使其维度与策略的视觉编码器输出对齐。价值估计使用 𝑛 步时间差分(TD)估计转换为动作优势。
为了在保留偏好结构的同时简化条件化过程,将优势离散化为一个二元指标 𝐼 = 1(︀𝐴(s_𝑡 , 𝑎_𝑡 ) > 𝜖)︀,其中 𝜖 为阈值。然后,训练策略,使其能够根据元组 (𝐼,z) 生成条件动作,方法是前面定义的监督式微调目标。
为了防止过度依赖合成世界模型信号并确保灵活部署,在训练过程中采用两种互补策略。首先,世界模型在推理过程中仅执行一次去噪步骤,以最大限度地减少计算开销。其次,实现随机注意掩码,在训练过程中以概率 𝑝 = 0.2 随机抑制世界模型token。这使得策略即使在世界模型输入部分或完全不可用时也能保持稳健的性能,从而实现一种绕过世界模型条件化的高效推理模式。
阶段 3:人机协同部署数据采集。在第三阶段,部署策略,通过人机协同部署来采集轨迹。由此产生的数据集包含自主执行和专家干预的混合数据。与传统的远程操作相比,自主部署显著缩小了动作分布的差距,因为该策略在其自身分布范围内生成动作,而不是模仿人类演示,从而为VLA学习提供了更有效的监督信号。然而,自主执行不可避免地会遇到需要人工纠正的故障模式。为了减轻人工干预引入的时间不连续性,开发一款人机协同部署数据采集软件,该软件能够自动检测并消除干预边界处的过渡伪影。这种平滑机制确保了整个轨迹的时间一致性,生成了一个干净、连续的数据集,这有助于在后续训练阶段进行稳定的策略更新,同时保留专家纠正的教学价值。
阶段 4:使用部署数据进行持续训练。在此阶段,用精心整理的HILR数据集对策略进行微调,以掌握由自主执行和专家修正等多种因素共同作用而产生的复杂长时程行为。至关重要的是,为了防止优势值趋近于零(𝐴(s_𝑡, 𝑎_𝑡) ≈ 0),用HILR数据集和基础数据联合训练世界模型𝒲_𝜑。在策略训练中,与第二阶段一致,对优势指标𝐼和未来潜token变量 z_future应用掩码概率为𝑝 = 0.2的随机注意掩码。这种正则化有两个目的:(1)通过强制策略对缺失的条件输入保持鲁棒性,防止策略过度依赖世界模型信号;(2)确保预训练和微调阶段在架构和训练上的一致性,避免推理时出现分布偏移。这个部署-标注-训练循环,以迭代方式运行,形成一个自我改进的闭环:随着策略的改进,其自主部署会涵盖越来越复杂和成功的行为,进而为后续迭代生成更高质量的训练数据。
推理。在部署过程中,通过将优势指标固定为 I = 1 来强制执行乐观控制策略。对于潜条件 z,随机掩码实现的架构解耦支持两种灵活的执行模式:(1)高效模式,其中绕过世界模型以最大化推理频率。在这种设置下,注意掩码配置为使未来的潜token对策略不可见,迫使其仅基于当前观测值采取行动;(2)标准模式,其中世界模型主动生成 z 以提供密集的预测指导。在这种设置下,注意掩码允许完全可见预测的未来状态,使策略能够利用前瞻性上下文进行复杂的长期规划。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)