Skills 的设计哲学:Anthropic 如何用一个 Markdown 文件重新设计 AI 能力扩展
本文深入解析了Claude Skills的设计架构与核心理念。文章指出,传统AI系统提示词膨胀会挤占工作空间,而Skills采用渐进式披露机制,通过元数据常驻、正文按需加载和资源精准注入三层结构,实现"装备百种能力仅占2%上下文"的高效运作。Skills并非简单提示词管理工具,而是与MCP(数据连接层)、Subagent(上下文隔离层)共同构成Claude的三层能力体系:MCP
这不是一篇"什么是 Skills + 怎么安装"的教程。那类文章已经够多了。
这篇拆解的是:Skills 为什么被设计成现在这样——一个 Markdown 文件、三层渐进加载、与 MCP 和 Subagent 的分工——背后的架构逻辑是什么,对你的工作流意味着什么。
如果你已经在用 Claude,但总觉得 Skills 是"又一个提示词管理工具",这篇可能会改变你的看法。
赶时间? 直接看第 2 章(核心机制)和第 4 章(能力体系定位),这两章是全文骨架。想动手试?跳到第 6 章。
1. 一个你已经遇到过的问题
你给 Claude 写过一份详细的系统提示词吗?
一开始几百字,效果不错。然后你加了编码规范、加了 API 约定、加了错误处理策略、加了团队的命名风格……一个月后,系统提示词膨胀到三千字。
然后你发现一件尴尬的事:Claude 的实际工作空间变小了。
这就是 AI 工具化的根本矛盾——能力扩展和上下文效率在争夺同一块资源。你给 Claude 塞进去越多"怎么做"的指令,它能处理"做什么"的实际内容就越少。上下文窗口的总容量是有上限的,规则和内容在抢空间。
窗口在扩——128K、200K。但更大的窗口不是正确答案。指令增长的速度比窗口增长还快。你管的项目越多、标准越细,系统提示词就越长。这是一场你注定跑不赢的军备竞赛。
解法不是更大的窗口。是更聪明的加载。
一句话:把所有指令塞进系统提示是一条死路。能力越多,上下文越少,效率越低。Skills 的出发点就是解决这个矛盾。
2. 渐进式披露:Anthropic 给出的答案
Skills 的核心设计思想叫 Progressive Disclosure(渐进式披露)——不是一口气全给,而是需要什么给什么。
想象你入职一家新公司。HR 不会在第一天把 500 页员工手册甩你脸上。你会先拿到一张一页纸的目录——公司有什么制度、各自在手册第几章。遇到具体问题了,翻那一章看。需要查政策原文了,再翻附录。
Skills 的加载机制一模一样,分三层:
第一层:元数据常驻。 Claude 启动时,只加载每个 Skill 的 name 和 description——相当于手册目录。几十字的简短描述,占极少的上下文空间。Claude 因此知道"我有哪些能力可以用",但不占用宝贵的工作记忆。
第二层:正文按需加载。 当 Claude 判断某个任务匹配某个 Skill(通过 description 语义匹配),或者你手动用 /skill-name 调用,才加载该 Skill 的完整指令。相当于翻到手册的那一章。
第三层:资源精准注入。 Skill 文件夹里可以包含 references/、scripts/、examples/ 等支撑文件。只有 Skill 执行过程中需要时,才读取对应资源。相当于手册正文说"详见附录 C 的 API 规范",你才去翻附录。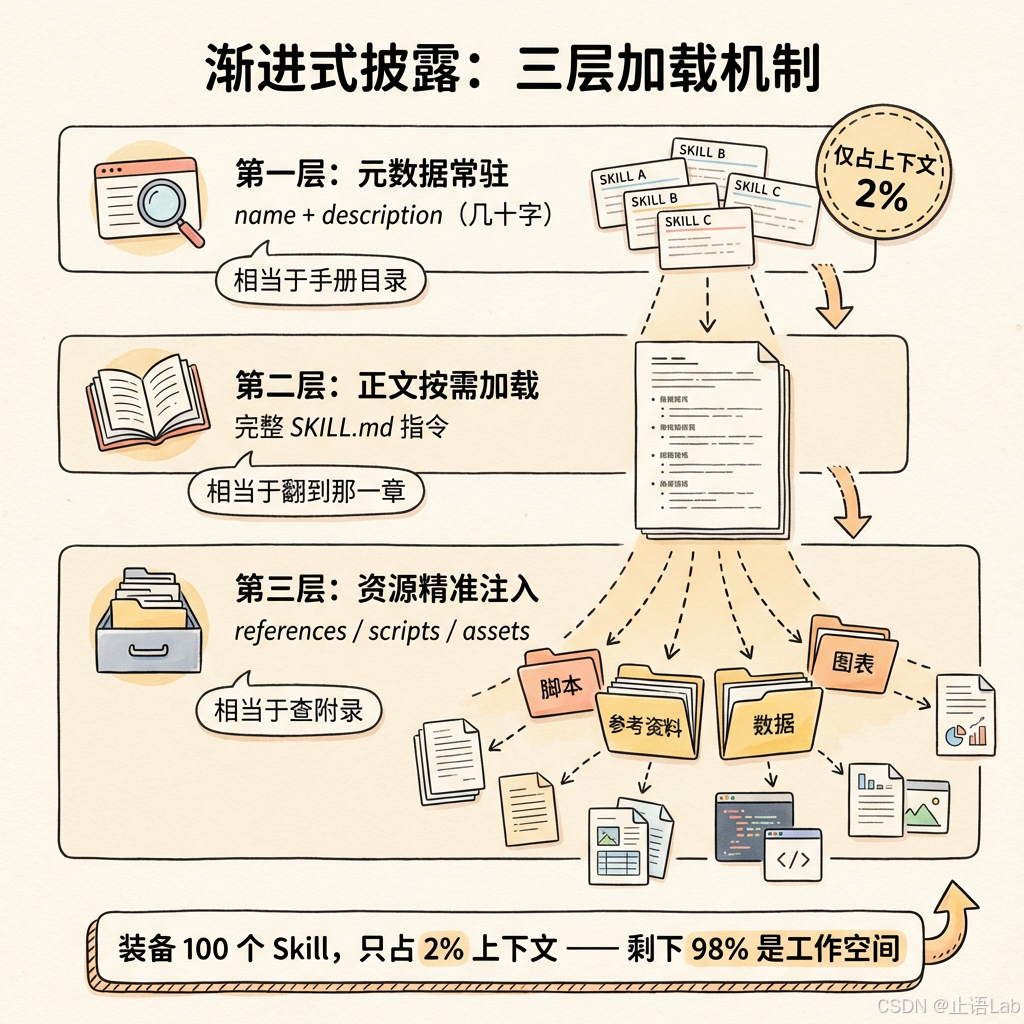
这套机制有一个关键数字:字符预算默认为上下文窗口的 2%(最低 16,000 字符)。 也就是说,你可以给 Claude 装备几十甚至上百个 Skill,但它们的描述信息总共只占上下文窗口的 2%。剩下 98% 都是实际工作空间。
对比一下"全塞进系统提示"的做法:10 个 Skill 各 300 字指令,光规则就占了 3000 字。而渐进式披露下,10 个 Skill 的描述可能只要 500 字。实际调用时才加载你需要的那一个。
这不是微调,是设计思路的根本转变。
划重点:Skills 的三层加载机制让 Claude 能"装备一百个能力但只占 2% 上下文"。关键在于区分"知道有什么"和"具体怎么做"——前者常驻,后者按需。
3. 一个 SKILL.md 的解剖
理解了为什么要渐进式加载,再看 Skills 的文件格式就清晰了——每个设计选择都在服务这套架构。
一个 Skill 就是一个文件夹,核心是一个 SKILL.md 文件。格式分两部分:YAML 元数据 + Markdown 指令。
---
name: code-review
description: 审查代码变更,检查架构合规性、安全漏洞和性能问题
allowed-tools: Read, Grep, Bash(git diff *)
context: fork
agent: Explore
---
## 代码审查流程
1. 获取待审查的变更(git diff)
2. 检查架构分层是否合规
3. 扫描安全风险
4. 评估性能影响
5. 生成结构化审查报告
逐个字段拆解设计意图。前四个是核心字段,后面的是高级控制——如果你只是想快速上手,看完前四个就够了。
description 是匹配引擎的入口。这不是给人看的注释,Claude 靠它判断"当前任务要不要调用这个 Skill"。写法有讲究:要包含用户可能的自然表述。写"审查代码变更"比写"code review skill"更容易被匹配到。
allowed-tools 是权限白名单。Skill 激活时,列表中的工具自动获得免确认权限。Bash(git diff *) 的意思是"只允许跑 git diff 相关的命令",精确到具体命令模式。安全和效率的折中。
加上 context: fork,Skill 就会在一个隔离的子上下文中运行,看不到你当前的对话历史。跑完后,摘要返回主对话。复杂 Skill 可能产生大量中间过程,不隔离的话会污染主对话的上下文——这个字段就是为此设计的。
agent 指定谁来执行。配合 context: fork 使用。内置选项有 Explore(擅长搜索和分析)、Plan(擅长规划)、general-purpose(通用型),你也可以指向 .claude/agents/ 里自定义的 Agent。Skill 不只是一段指令——它可以指定"派谁去执行"。
以上是核心字段。下面两个控制字段决定 Skill 的触发方式:
| 字段 | 值 | 效果 |
|---|---|---|
disable-model-invocation |
true |
Claude 不能自动调用,只能你手动 /name 触发 |
user-invocable |
false |
反过来——你不能手动调用,只有 Claude 自己判断要用时才触发 |
这两个字段组合起来,形成了一个精确的调用控制矩阵。你可以决定每个 Skill 是"AI 自主判断"、“人类手动触发"还是"仅后台知识”。
还有一个高级特性值得一提:!`command` 预处理。在 Skill 正文中写 !`gh pr diff`,Claude 不是收到这条命令——而是在加载 Skill 时就执行它,用输出结果替换占位符。Claude 看到的已经是真实数据。这让 Skill 能在加载时就注入动态上下文。
总结:SKILL.md 的每个字段都有明确的架构意图——
description驱动自动匹配,allowed-tools控制权限边界,context: fork实现上下文隔离,agent指定执行者。它是一套结构化的能力定义格式。
4. Skills 在 Claude 能力体系中的位置
这是本文最重要的部分。
很多人把 Skills 当成"MCP 的简化版"或"系统提示词的替代品"。这两个理解都不对。要准确定位 Skills,需要看 Claude 的整个能力架构。
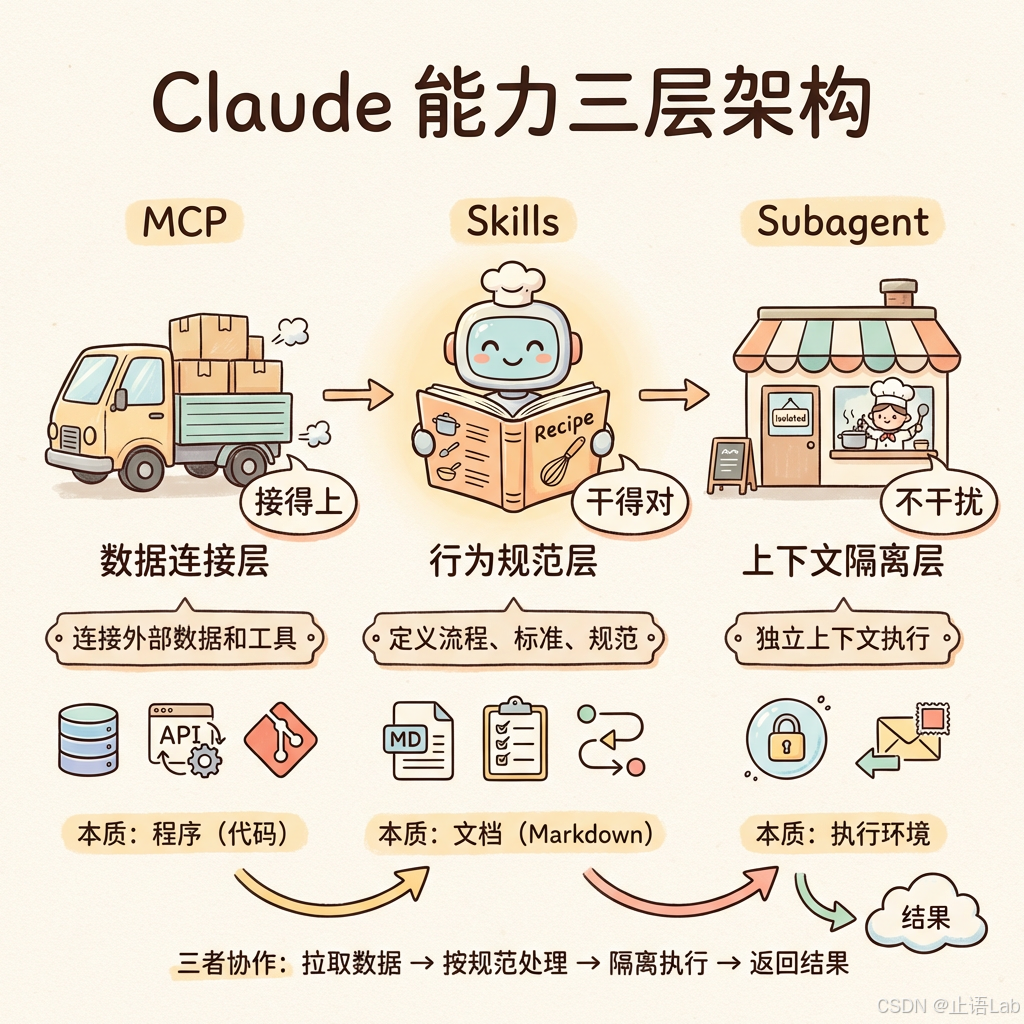
Claude 当前的能力扩展有三个层次,解决三个不同的问题:
MCP:数据连接层
Model Context Protocol(MCP) 解决的是"接得上"的问题——让 Claude 能读写外部数据源和工具。连数据库、调 API、访问文件系统、操作 Git。
类比:MCP 是餐厅的供应链。 它负责把食材(数据)从产地运到厨房。没有供应链,再好的厨师也做不出菜。
Anthropic 官方的说法是:
“MCP connects Claude to data and tools.”
MCP 不关心你拿到数据后怎么处理——那不是它的问题。
Skills:行为规范层
Skills 解决的是"干得对"的问题——教 Claude 按照特定流程、标准、规范来完成任务。
类比:Skills 是菜谱。 有了食材(MCP 连接的数据)还不够,你得告诉厨师用什么火候、放多少盐、先炒什么后放什么。Skills 封装的是过程性知识——不是数据,是操作标准。
Anthropic 的另一句官方表述精确地切开了这条分界线:
“MCP connects Claude to data, Skills teach Claude what to do with that data.”
MCP 把 GitHub PR 数据拿进来,Skills 定义代码审查该怎么做——先看架构、再看安全、最后看性能,按什么格式输出报告。两者解决不同层次的问题,不是替代关系。
Subagent:上下文隔离层
Subagent 解决的是"不干扰"的问题——让复杂任务在独立的上下文中执行,不污染主对话。
类比:分店厨师。 你在总店做主菜,但甜点太复杂了,交给分店的甜点师傅做。他有自己的厨房(独立上下文),做完把成品送回来。你不需要知道他的制作过程,也不会因为他的工作台乱了而影响你。
Subagent 的关键是上下文隔离——它看不到主对话的历史,跑完任务后只返回结果摘要。在 Skills 中,这通过 context: fork 字段触发;但 Subagent 也可以通过 Claude Code 的 Task 工具独立使用,不依赖 Skills。它是一种通用的执行模式,Skills 只是它的触发方式之一。
三层协作模型
把三者放在一起看:
| 层次 | 解决的问题 | 类比 | 形态 |
|---|---|---|---|
| MCP | 接得上(数据连接) | 供应链 | 协议 + 代码 |
| Skills | 干得对(行为规范) | 菜谱 | Markdown 文档 |
| Subagent | 不干扰(上下文隔离) | 分店厨师 | 执行环境 |
一个真实的工作流可能同时用到三者:
MCP 的本质是程序——代码、接口、协议。Skills 的本质是文档——规则、流程、经验沉淀。这是最根本的区别。MCP 需要写代码开发 Server,Skills 只需要写 Markdown。
这个设计选择不是偶然的。Anthropic 把能力扩展分成了"需要编程"和"不需要编程"两条路径:
- 需要外部数据/工具 → MCP(写代码)
- 需要行为规范/流程 → Skills(写文档)
- 需要执行隔离 → Subagent(配置字段)
三条路径职责分明,又可以组合。每个维度解决一个问题,不互相干扰。
关键判断:MCP 管"接得上",Skills 管"干得对",Subagent 管"不干扰"。三者分别解决数据连接、行为规范、上下文隔离三个不同层次的问题。不要把 Skills 当成轻量版 MCP,它们根本不在同一个维度上。
5. 从 Claude 专属到行业标准
Skills 一开始是 Claude 的专有功能(2025 年 10 月推出)。两个月后,Anthropic 做了一个值得关注的决定:2025 年 12 月 18 日,将 Agent Skills 格式捐赠给 Agentic AI Foundation(AAIF),变成开放标准。
想想 MCP 的路径——也是 Anthropic 先做、再开放。MCP 开放后,主流 AI 编码工具陆续接入了 MCP 生态。Agent Skills 正在走同一条路:GitHub Copilot 已经支持 .github/skills/ 目录(VS Code 官方文档确认),Cursor 支持 .cursor/skills/,OpenAI Codex、Goose、Amp、OpenCode 等工具也在跟进。
各家的支持程度不同——基础特性(YAML frontmatter + Markdown 指令 + $ARGUMENTS 参数)是通用的,但 Claude 的扩展特性(context: fork、disable-model-invocation 等)在其他工具中可能被忽略。和 Web 标准一样——HTML 规范是标准,但 Chrome 有自己的实验特性。
这意味着什么?你写的 Skill 文件不绑定 Claude。
Claude 官方文档的原话:
“Claude Code skills follow the Agent Skills open standard, which works across multiple AI tools. Claude Code extends the standard with additional features.”
对开发者来说,现实含义是:把过程性知识封装成 Skills,是一次投资多处复用的事。 你不是在给某个工具写插件——你是在把团队的操作标准变成一种可移植的资产。
重点:Agent Skills 已从 Claude 专有功能变成 AAIF 开放标准。GitHub Copilot、Cursor 等工具已支持基础特性。你写的 Skill 是可移植的资产,不是绑定某一个工具的脚本。
6. 五分钟验证:写一个最小 Skill
理论讲完了。用一个最简单的例子验证上面说的一切。
目标:写一个生成 commit message 的 Skill——几乎所有开发者都做这件事,足够简单又足够说明问题。
# 创建 Skill 目录
mkdir -p .claude/skills/commit-message
# 写入 SKILL.md
cat > .claude/skills/commit-message/SKILL.md << 'EOF'
---
name: commit-message
description: 根据暂存区变更生成规范的 commit message
allowed-tools: Bash(git *)
---
## 生成 Commit Message
根据 `git diff --cached` 的内容,生成符合 Conventional Commits 规范的 commit message。
规则:
- type 从 feat/fix/refactor/docs/test/chore 中选择
- scope 取变更的主要模块名
- subject 用中文,不超过 50 字
- 如果变更涉及多个模块,按影响范围从大到小列出
格式:
```
type(scope): subject
- 变更点 1
- 变更点 2
```
EOF
这个 Skill 的生命周期:
- 发现:Claude 启动时读取 description——“根据暂存区变更生成规范的 commit message”
- 匹配:你说"帮我写个 commit message",Claude 通过语义匹配激活这个 Skill
- 加载:完整的 SKILL.md 内容加载进上下文
- 执行:
allowed-tools: Bash(git *)自动授权 Claude 运行 git diff 等命令,不需要你逐次确认 - 完成:输出规范的 commit message
你也可以手动调用:/commit-message。
不到 40 行 Markdown。没有代码,没有依赖,没有部署。这就是 Skills 的全部——把你的过程性知识写成结构化文档,剩下的交给渐进式加载机制处理。
动手试试:创建一个 Skill 就是写一个 SKILL.md 文件。不需要编程。核心是把"你希望 Claude 怎么做某件事"写清楚。
7. 判断框架:你的场景该不该用 Skills
不是什么都该做成 Skill。以下是决策逻辑:
用 Skills 的信号:
- 你反复给 Claude 说同样的话——“帮我审代码的时候注意这几点”
- 团队中不同人给 Claude 的指令不一致,产出质量波动大
- 你的工作流有标准流程但不需要外部数据连接
不用 Skills 的信号:
- 任务是一次性的,没有复用价值
- 需要连接外部系统获取数据——那是 MCP 的活
- 流程太简单,一句话就能说清——没必要为此建个 Skill
Skills + MCP 搭配的信号:
- 需要外部数据,也需要标准化处理流程
- 比如:MCP 连接 Jira 拉需求 + Skill 定义需求分析和拆分标准

一个容易踩的坑:别把 Skills 当提示词模板库。如果你的 Skill 只是一段固定文本、没有流程逻辑,放在 CLAUDE.md 里反而更合适——那是全局配置的位置,每次都会加载。Skills 的价值在"按需加载",如果你的内容是"每次都需要",就不该放在 Skills 里。
决策原则:Skills 解决"重复性行为规范"问题。需要外部数据找 MCP,一次性任务直接说,两者都需要就搭配用。别把什么都塞进 Skills——"每次都需要"的内容属于 CLAUDE.md。
回到起点
开头说的那个根本矛盾——能力扩展和上下文效率争夺同一资源——Skills 的回答是渐进式披露。不是更大的盒子,是更聪明的收纳。
但 Skills 真正有意思的地方,不只是技术方案本身。
它选择了 Markdown 而不是代码作为能力定义的载体。 这意味着团队里的任何人——不只是工程师——都能创建、修改、复用 Skill。产品经理能写需求分析 Skill,测试工程师能写测试策略 Skill,技术写作者能写文档规范 Skill。
它选择了开放标准而不是专有格式。 你写的不是 Claude 插件,是一份跨工具的能力资产。
这两个选择合在一起,指向一个更大的判断:AI 工具化的下一步,不是"更强的模型",而是"更好的能力管理"。 Skills 是这个方向上一个设计精良的答案。
它值不值得你花时间?取决于你有没有重复的工作流需要标准化。如果有——几十行 Markdown,就是全部成本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)