MySQL必会性能分析命令,建议收藏
大家好呀!
今天给大家介绍下MySQL中最常见的,也是必须要会的几个性能分析命令。
这些命令的话不仅在面试中可能考到,在工作上也常常用到。
主要包含的命令有 explain、anaylze、show index、show processlist 和 slow log。
如果你正为 SQL 执行慢而头疼,或者不知道索引到底生效没,那这篇文章一定要看到最后。
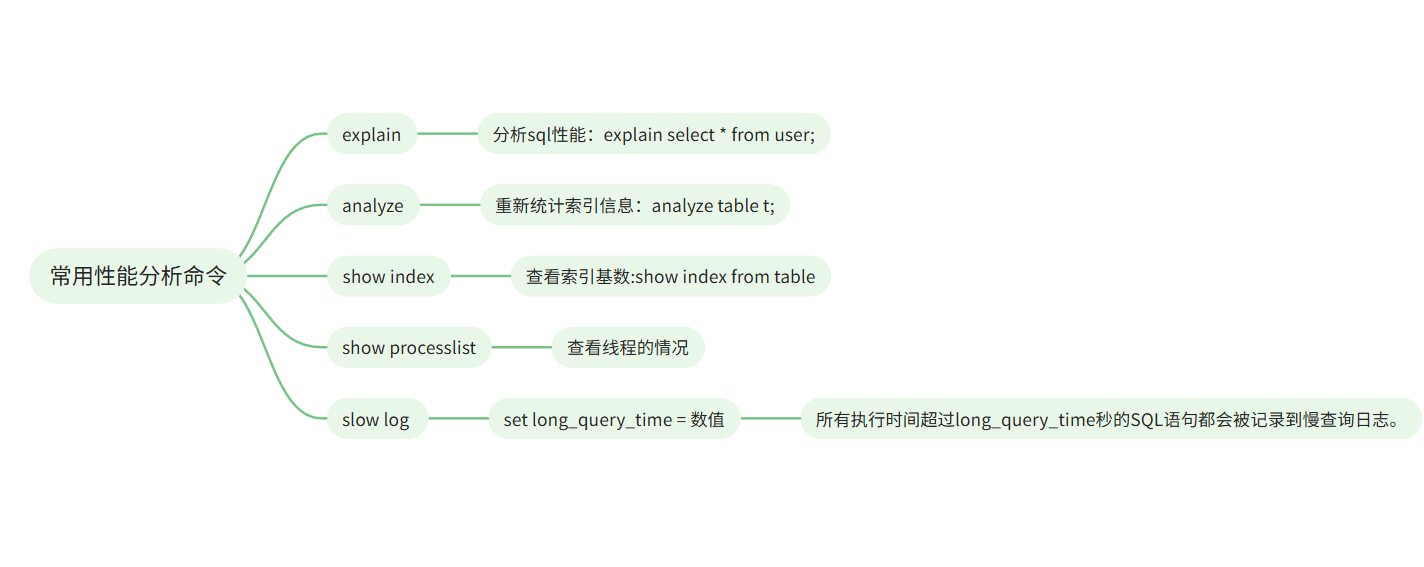
1、explain
在 MySQL 调优里,explain 绝对是我们的首选工具,也是我们最常用的,最常问的。
使用起来非常简单,你只需要在执行的 sql 语句前加上这个单词,MySQL 就会展示出它预估的执行计划。
explain sql语句
例如:explain select * from t_user;
执行结果如下:
mysql> explain select * from t_user;
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | t_user | NULL | ALL | NULL | NULL | NULL | NULL | 7 | 100.00 | NULL |
+----+-------------+--------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
在这一堆返回结果里,我们看一下各个字段的含义:
- id:1 这是查询的序列号。 目前只有一个查询,所以是 1。 如果有子查询或者嵌套,你会看到多个 id,数字越大优先级越高。
- select_type:SIMPLE 代表这是一个简单的查询。 它不包含子查询(Subquery)或者联合查询(UNION)。
- table:t_user 这个很好理解,就是你正在查的这张表。
- partitions:NULL 代表你没有用到分区表。 现在大部分项目里,这个字段基本都是 NULL。
- type:ALL 代表“全表扫描”。 意思是 MySQL 没找到任何捷径,只能把整张表从头到尾扫一遍。 在数据量大的时候,这就是性能杀手。
- possible_keys:NULL MySQL 觉得在这个查询中,没有任何索引可以派上用场。 因为写的是 select * 且没有 where 条件。
- key:NULL 实际使用的索引。 既然没有可选的索引,实际用的自然也是 NULL。
- key_len:NULL 如果使用了索引,这里会显示索引字段的长度。 现在没用索引,所以是 NULL。
- ref:NULL 显示索引的哪一列被使用了。 没走索引,自然也是 NULL。
- rows:7 MySQL 预估要扫描 7 行数据才能拿到结果。 你现在的表里应该一共就 7 条数据,所以它扫了全部。
- filtered:100.00 代表经过过滤后,符合条件的行数占扫描行数的百分比。 你没有写
where过滤,所以 100% 的数据都返回了。 - Extra:NULL 一些额外的提示信息。 比如是否用了临时表、是否用了文件排序等。
虽然 EXPLAIN 输出了这么多,但重点关注 type,key,rows 就行。
2、analyze
有时候mysql会选错索引,这主要是因为索引统计信息计算的不准确,进而导致数据库优化器对查询代价的错误预估。
那么这边可以用 analyze 重新统计索引信息。
为什么会不准?
上面的扫描行数rows是根据采样估计的值,并不是真正要扫描的行数。那么估计的不准,就可能导致mysql选错索引。
analyze table 表名;
例如:
mysql> analyze table t_user;
+-----------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+-----------------+---------+----------+----------+
| testdb.t_user | analyze | status | OK |
+-----------------+---------+----------+----------+
1 row in set (0.04 sec)
返回 OK 就代表统计信息已经更新完毕。
执行完之后,再跑一遍 explain ,MySQL 就会基于最新的统计信息重新选择索引,很多时候"莫名其妙走错索引"的问题就这样解决了。
mysql选错索引还有可能是sql语句本身的问题,例如对条件字段做函数操作,隐式类型转换,隐式字符编码转换等,这边不展开了。
3、show index
做性能分析必然想知道一张表上到底建了哪些索引?这里可以用 show index 一眼就能看清楚。
show index from 表名;
例如:
mysql> show index from t_user;
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| t_user | 0 | PRIMARY | 1 | id | A | 7 | NULL | NULL | | BTREE | | | YES | NULL |
| t_user | 1 | idx_phone | 1 | phone | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL |
| t_user | 1 | phone | 1 | phone | A | 7 | NULL | NULL | YES | BTREE | | | YES | NULL |
+--------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
3 rows in set (0.01 sec)
几个关键字段解释一下:
- Key_name:索引的名称,
PRIMARY代表主键索引。 - Non_unique:0 表示唯一索引,1 表示普通索引(允许重复值)。
- Column_name:该索引对应的列名。
- Seq_in_index:联合索引中,该列排在第几位(从 1 开始)。非常重要,联合索引的列顺序直接影响能不能命中。
- Cardinality:基数,代表该列中不重复值的预估数量。这个值越大,说明区分度越高,索引效果越好。如果 Cardinality 很低(比如性别字段只有男/女),建索引意义就不大了。
- Index_type:索引类型,InnoDB 默认都是
BTREE。
💡Cardinality 的值是估算值,不是精确值。
4、show processlist
当数据库突然变慢,或者感觉有什么 SQL “卡住了”,第一时间就应该跑这个命令,看看当前数据库里都在跑些什么。
show processlist;
例如:
mysql> show processlist;
+----+-----------------+------------------+----------+---------+------+------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+------------------+----------+---------+------+------------------------+------------------+
| 5 | event_scheduler | localhost | NULL | Daemon | 3508 | Waiting on empty queue | NULL |
| 9 | root | 127.0.0.1:43610 | testdb | Query | 0 | init | show processlist |
| 10 | root | 172.17.0.1:52642 | NULL | Sleep | 3205 | | NULL |
+----+-----------------+------------------+----------+---------+------+------------------------+------------------+
3 rows in set (0.00 sec)
字段含义:
- Id:连接的唯一标识,如果要手动干掉某个连接,就用
kill Id命令。 - User:当前连接使用的数据库用户名。
- Host:客户端的 IP 和端口,可以看出请求来自哪台机器。
- db:当前连接使用的数据库。
- Command:当前执行的命令类型,常见的有
Query(执行查询)、Sleep(连接空闲中)。 - Time:该命令已经执行了多少秒。重点关注这个字段,如果某条 SQL 的
Time值很大,说明它卡了很久,需要重点排查。 - State:当前的状态,比如
Sending data、Locked等。如果看到大量Locked,说明有锁等待问题。 - Info:正在执行的 SQL 语句内容(可能会截断,看完整的可以用
show full processlist)。
show processlist只显示前 100 条,如果连接数很多,建议用show full processlist获取完整信息
5、slow log
前面几个命令,都是我们主动去排查某一条 SQL 的。但如果想被动地捕获系统里所有执行慢的 SQL,就要靠慢查询日志了。
第一步:查看当前慢查询日志的配置
show variables like '%slow_query%';
show variables like 'long_query_time';
mysql> show variables like '%slow_query%';
+---------------------+--------------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_query_log | OFF |
| slow_query_log_file | /var/lib/mysql/2be4983ea86a-slow.log |
+---------------------+--------------------------------------+
2 rows in set (0.01 sec)
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.00 sec)
这里几个参数的意思如下:
- slow_query_log:是否开启慢查询日志,ON 为开启,OFF 为关闭。
- slow_query_log_file:慢查询日志保存的文件路径。
- long_query_time:超过这个时间(单位:秒)的 SQL 才会被记录,默认是 10 秒,一般建议调成 1~2 秒。对于我们临时测试而言,可以调成0秒,方便观察每条语句的详细执行信息。
第二步:临时开启慢查询日志(重启后失效)
set global slow_query_log = 'ON';
set global long_query_time = 0; //之后的连接生效
set session long_query_time = 0; //让当前连接就生效
mysql> set global slow_query_log = 'ON';
Query OK, 0 rows affected (0.03 sec)
mysql> set session long_query_time = 0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like '%slow_query%';
+---------------------+--------------------------------------+
| Variable_name | Value |
+---------------------+--------------------------------------+
| slow_query_log | ON |
| slow_query_log_file | /var/lib/mysql/2be4983ea86a-slow.log |
+---------------------+--------------------------------------+
2 rows in set (0.01 sec)
mysql> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 0.000000 |
+-----------------+-----------+
1 row in set (0.01 sec)
第三步:分析慢查询日志
我们打开日志文件:
cat /var/lib/mysql/2be4983ea86a-slow.log
# Time: 2026-03-01T08:39:58.839308Z
# User@Host: root[root] @ [127.0.0.1] Id: 9
# Query_time: 0.000484 Lock_time: 0.000004 Rows_sent: 1 Rows_examined: 1
SET timestamp=1772354398;
select * from t_user where phone="13789097853";
- Query_time:SQL 实际执行耗时,超过 long_query_time 才会被记录。
- Rows_examined:MySQL 扫描了多少行。这个值如果远远大于 Rows_sent(实际返回行数),说明索引没用好,做了大量无效扫描。
日志文件里内容多了之后,人工看会很吃力。
这时候可以用 MySQL 自带的 mysqldumpslow工具来汇总分析:
# 查看耗时最长的 Top 10 SQL
mysqldumpslow -s t -t 10 /var/lib/mysql/2be4983ea86a-slow.log
小结
| 命令 | 作用 | 使用场景 |
|---|---|---|
| explain | 查看 SQL 执行计划 | 分析单条 SQL 有没有走索引 |
| analyze | 重新统计索引信息 | MySQL 选错索引时修正统计数据 |
| show index | 查看表的索引结构 | 确认索引建了哪些、区分度如何 |
| show processlist | 查看当前所有连接和正在执行的 SQL | 数据库卡顿时排查长时间运行的语句 |
| show log | 记录执行超时的 SQL | 长期监控,捕获慢 SQL |
欢迎大家的关注

如果你觉得有帮助,不妨动动发财的小手【转发/点赞一波】,你的支持是我持续分享最大的动力~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)