3、【AI】【Agent】本地模型(硬件参数)
本文探讨了本地运行AI大模型的关键技术指标,重点解析了模型参数规模(如3.8B、7B等)、量化格式(如Q5_K_M)和性能表现的关系。作者通过实测数据展示了不同规模模型在CPU上的推理速度和内存占用情况,指出7B~13B量级模型适合主流开发者使用。文章详细解释了量化技术的原理(如将16位浮点数压缩为5位整数),并对比了不同量化级别在文件大小、内存占用和精度上的差异,推荐Q5_K_M作为CPU推理的
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【AI】【Agent】LLM 连接(本地模型)
分析了对 Agent 是个没有灵魂的机器人,需要 LLM 大模型作为大脑,才能有灵魂,接着分析了 Agent 与 LLM 连接的两种方式,一种是连接本地模型,另一种是连接联网连接一些顶级的闭源模型(需要付费),然后讨论了本地连接的两种方式,最后分析了本地硬件参数,下面继续
Agent
上篇 blog 提到了查看到 CPU 参数如下
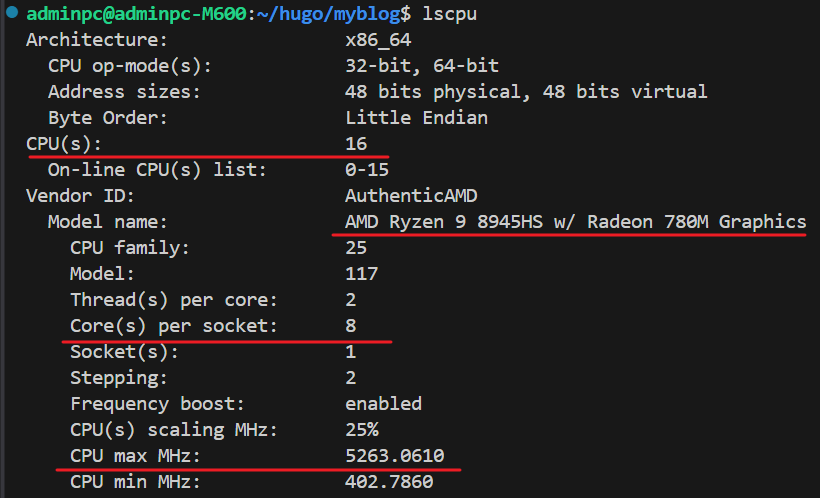
从 lscpu 输出来看,这里的短板是没有独立 NVIDIA GPU,只有 Radeon 780M 入门级核显,这意味着无法使用 CUDA 加速(Ollama / llama.cpp 在 AMD GPU 上运行的话,仍然依赖 CPU 配合),不过好在这里的 CPU 本身够强,可以流畅运行 7B~13B 级别的量化模型,类似配置的模型参考如下
| 模型 | 量化 | 推理速度(CPU) | 内存占用 |
|---|---|---|---|
| Phi-3-mini(3.8B) | Q5_K_M | 80~120 tokens/s | ~4GB |
| CodeLlama-7B | Q5_K_M | 40~60 tokens/s | ~6GB |
| DeepSeek-Coder-6.7B | Q5_K_M | 35~50 tokens/s | ~6GB |
| Llama-3-8B | Q5_K_M | 30~45 tokens/s | ~6.5GB |
7B 这个速度,对于写代码,分析文档,生成报告来说足够使用
OK,这里的表格里面提到了三个关键的概念:xxB,Q5_K_M,tokens,这三个概念是理解大模型性能和部署的核心,下面来详细分析下
首先是每个大模型后面跟着的后缀,比如上面提到的 Phi-3-mini(3.8B),CodeLlama-7B,DeepSeek-Coder-6.7B,Llama-3-8B,这里的 B 指的是 Billion(十亿),指的是模型的参数数量,比如:
- 3.8B = 38 亿个参数
- 7B = 70 亿个参数
- 6.7B = 67 亿个参数
- 8B = 80 亿个参数
这里参数指的是模型内部的可调旋钮,决定大模型如何从输入生成输出,参数越多,模型就越聪明,能记住更多知识,处理更复杂的逻辑,但参数越多,需要的内存和算力也就越大,常见的模型规模对比如下
| 规模 | 代表模型 | 能力 | 适合场景 |
|---|---|---|---|
| 1B~3B | Phi-2,TinyLlama | 基础问答,简单代码 | 低配电脑 |
| 7B~8B | Llama-3-8B,CodeLlama-7B | 强大编程,推理 | 主流开发者首选 |
| 13B~34B | CodeLlama-34B,Qwen-32B | 接近 GPT-4 | 高性能工作站 |
| 70B+ | Llama-3-70B,Qwen-Max(闭源) | 顶级能力 | 云端/API |
OK,然后是 Q5_K_M,这个是模型量化的格式名称,属于 llama.cpp 项目定义的标准,对于原始模型参数来说,使用的是 16 位浮点数(FP16)进行存储,内存占用大,而量化可以把参数压缩成更小的数字(比如 5 位整数),就可以节省内存,并加速推理,但代价就是会损失轻微的参数精度(不过 Q5 级别几乎无感)
Q5_K_M 各部分含义如下:
Q:Quantized(量化)5:平均每个权重用 5 bits 进行存储(原始是 16 bits)_K_M:一种高级分组策略(K表示 per-channel,M表示中等压缩速率),可以在速度,体积,精度之间取得最佳平衡
以 7B 模型为例,量化后的模型大小对比如下:
| 格式 | 文件大小 | 内存占用 | 速度 | 精度 |
|---|---|---|---|---|
| FP16(原始) | ~14GB | >14GB | 快 | ⭐⭐⭐⭐⭐ |
| Q5_K_M | ~5.5GB | ~6GB | ⚡快 | ⭐⭐⭐⭐☆ |
| Q4_K_M | ~4.5GB | ~5GB | 更快 | ⭐⭐⭐☆☆ |
| Q2_K | ~2.5GB | ~3GB | 极快 | ⭐⭐☆☆☆ |
Q5_K_M 是目前 CPU 推理的黄金标准,可以看到上面表格里都是这个量化格式
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【AI】【Agent】tokens 介绍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)