2、【AI】【Agent】LLM 连接(本地模型)
本文探讨了AI Agent的实现架构与本地部署方案。文章指出Agent本质是LLM大模型的代理执行器,需通过连接大模型才能运作。部署方式分为联网使用闭源模型(如GPT-4)和本地部署开源模型两种方案。重点分析了本地部署的两种实现路径:基于Docker的Ollama方案和原生Linux方案,并详细介绍了评估本地硬件(CPU架构、核心数、指令集等)的关键指标。作者以AMD Ryzen 9处理器为例,解
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【AI】【Agent】项目简介
分析了 Agent 的定义,以及 Agent 与传统 Chatbot 的区别,以及 Agent 的典型架构(简化),以及部署 AI Agent 是否需要联网,下面继续
Agent
对于 AI Agent 的实现部署,还需要补一张图
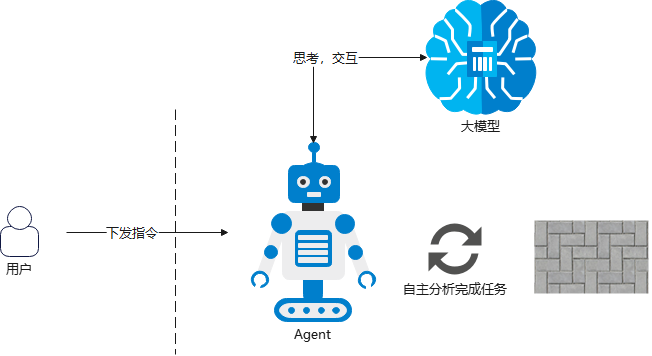
这里可以看到,对 Agent 相对来说,只是个没有灵魂的机器人,它可以做事儿,但必须得有个大脑,而这个大脑就是 LLM 大模型
其实 Agent 的本身翻译是代理,也就是说,这些都是 LLM 大模型的代理,它们可以通过与大模型交互,接收到大模型的指令之后,依照指令去执行动作(如果是 Chatbot 聊天机器人,就是直接打印大模型的回复)

OK,了解到这一层后,下面就先来分析下如何建立与大模型的连接,与大模型连接有两种方式,一种是本地模型直接与 Agent 进行连接(不需要联网),另一种是直接利用 GPT-4,Claude 3.5,Qwen-Max,DeepSeek 等顶级的闭源模型(需要联网和付费)
本地模型
下面先说本地模型的连接,搭建本地模型也有两种方式
第一种是利用 Docker 的一键部署优势,上面运行 Ollama,Agent 通过 Ollama 和 LLM 大模型进行交互
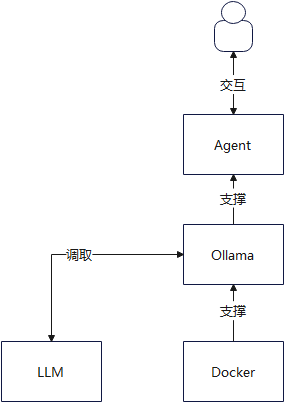
另外一种就是直接在 Linux 上跑了,不通过 Docker(其实 Docker 本质上内部也是运行的 Linux 内核),由 Linux 来支撑 Ollama
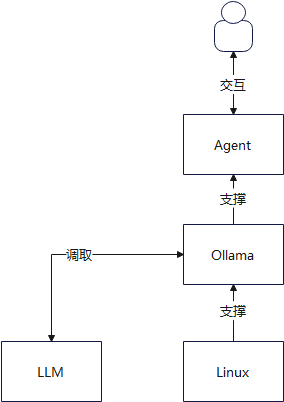
两种方式在架构上都差不多,上层都保持不变,而且两者对本地硬件需求是一致的,在 Linux 系统下,判断电脑能否运行 LLM 大模型,关键要看 CPU,内存(RAM),GPU(显卡)和存储四项,看能否支持运行像 Phi-3,CodeLlama,Qwen 等主流开源大模型
本地硬件
CPU
先查看 CPU 型号与核心数,在终端输入
lscpu
重点关注
- Architecture:x86_64(主流)还是 aarch64(ARM 服务器)
- CPU(s):逻辑核心数(建议 ≥ 4)
- Model name:CPU 型号(比如 Intel i7-12700,AMD Ryzen 9 5900X 等就不错)
大模型推理对 CPU 要求不高,但多核有助于加速量化模型(比如 llama.cpp)
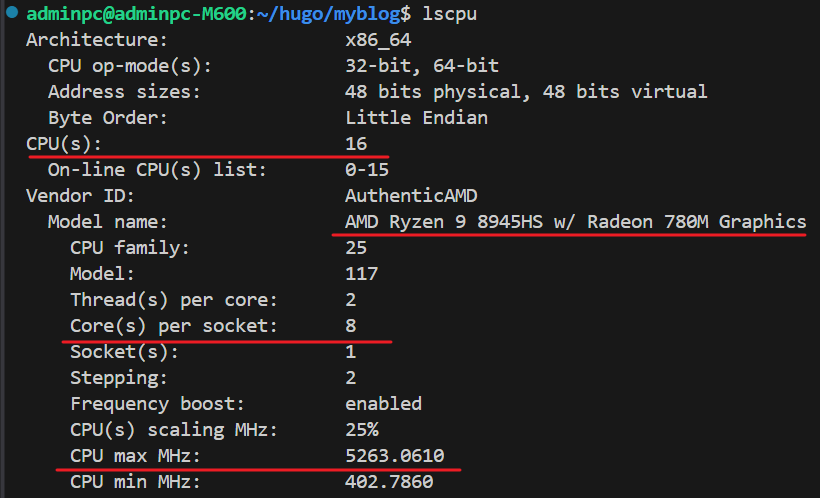
比如这里可以看到 CPU 的一些核心信息
- 型号:AMD Ryzen 9 8945HS,已经很强,高于推荐 AMD Ryzen 9 5900X
- 架构:Zen 4(2023 年最新一代)
- 核心/线程:8 核 16 线程
- 最高频率:5.26 GHz,已经非常高
- 集成显卡:Radeon 780M(性能接近入门独显),是短板
- 支持指令集:AVX512,AVX2,FMA,SHA-NI 等 AI 加速关键指令
该 CPU 常见于高端轻薄本,或移动工作站,主要讲究的是便携,效率,其各个指标对运行 LLM 大模型的意义总结如下
| 能力 | 评价 |
|---|---|
| 多线程推理 | ⭐⭐⭐⭐⭐ 16 线程已经可以高效并行处理 llama.cpp / Ollama 的 CPU 推理 |
| 高频加速 | ⭐⭐⭐⭐⭐ 5.26GHz 高频可显著提升 token 的生成速度 |
| AI 指令集 | ⭐⭐⭐⭐ 支持 AVX2/FMA,虽然没有专用 NPU,但比老 CPU 快 2~3 倍,也足够了 |
| 内存带宽 | 也就是内存读写速度,取决于配置的 RAM 类型(推荐 DDR5/LPDDR5x),一般 ≥ 50GB/s |
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【AI】【Agent】本地模型(硬件参数)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)