如何训练小型Deep Research智能体?
在深度搜索智能体的 RL 训练中,看起来"更复杂、更科学"的设计(长推理链、模糊的 F1 奖励、复杂的基线估计)往往不如简化设计有效;反而通过消除不必要的中间监督、让奖励信号更明确、采用更直白的优化策略,能获得更好的稳定性和性能。有时候,简单粗暴比聪明复杂更靠谱。第一,提示词工程的陷阱。显式推理不一定更好。在 RL 的稀疏奖励环境下,过度详细的指令反而容易引发模型学习错误的信号。让模型专注于核心决
想象一个大模型智能体在网上搜索信息回答问题。看起来简单,但背后涉及提示词设计、奖励函数、算法选择三个"暗扣"。这篇论文就是从这三个维度彻底拆解,最后甚至推翻了一些业界常见的"最佳实践"。

研究背景
当代大模型面临一个核心困境:知识库是有限的,世界在不断变化。于是业界发展出了深度搜索智能体(Deep Research Agent)这一新范式。这类系统做的事情听起来很简单——反复执行"思考-搜索-再思考"的循环,直到搜集足够信息后给出最终答案。
拿一个真实例子来说,假设问题是"纽约州 Route 495 高速公路第 17 出口那个镇 2010 年的人口是多少?“这需要智能体:先搜索"Route 495 第17出口”,获得是 Secaucus 这个镇,再搜索"Secaucus 2010 年人口",最终给出 16,264 这个数字。这是一个典型的多轮检索和信息融合的过程。
但这里有个重要背景:传统的有监督微调(SFT)依赖于大量人工标注的搜索轨迹数据。而强化学习(RL)天然适配这个场景——它可以直接从稀疏的最终答案对错信号学习,不需要逐步的中间监督。这就是为什么 Search-R1 等系统开始采用 RL 来训练深度搜索智能体。
然而问题来了:当前的 RL 训练配方非常"碎片化"——不同团队用不同的提示词、不同的奖励函数、不同的算法,甚至同一个算法的超参数都不一样。所以没人真正说得清楚:到底是提示词起作用了?还是新的奖励函数更好?还是 PPO 比 REINFORCE 强?这些因素互相纠缠,像一团浆糊。
这篇论文的核心动机就是:用严格的实验设计,把这三个关键因素彻底解耦出来逐一分析,找出真正的"杀手级"配置。简单说,就是在同一个框架、同一个数据集、同一个检索器下,用唯一变量法分别测试这三个维度,看看谁才是真正的性能驱动力。
相关工作:深度搜索的演进路线

我们可以从三个方向来看深度搜索智能体的发展脉络。
第一个方向是提示工程。早期的系统(比如 ReAct)用精心设计的提示词,显式地引导模型进行推理和行动决策。这些系统虽然不用训练,但性能往往受限于模型本身的能力。
第二个方向是有监督学习。研究者开始收集人类标注的搜索轨迹或使用规则生成的最优搜索路径,用 SFT 来微调模型。这样做的好处是有明确的"师傅"来指导学习,但坏处是需要大量高质量标注数据,而且模型被迫按固定套路做事,创意有限。
第三个方向就是强化学习,这是当前的热点。包括 Search-R1、ZeroSearch 等系统都在用 RL。这个方向很吸引人,因为它只需要最终的对错反馈(比如答案是否准确),不需要逐步的中间标注。理论上,这给了模型更大的自由度去探索如何最高效地搜索和推理。
但这里有个被忽视的点:虽然 RL 看起来更"科学",但具体怎么用 RL 呢?用 PPO 还是 REINFORCE?用 EM 还是 F1 作为奖励?提示词要多详细?这些决定往往被当作工程细节,各个团队自行决策,导致结果很难比较。
这篇论文的价值就在于:它不是提出新算法或新架构,而是通过严格的消融实验,把这些被忽视的"工程细节"系统地研究清楚。某种意义上,这是对整个领域的一次"大扫除"。
核心方法:三维解耦实验框架
这篇论文的精妙之处在于把整个 RL 训练管道分解成三个相对独立的维度进行深入分析。让我们逐一来看。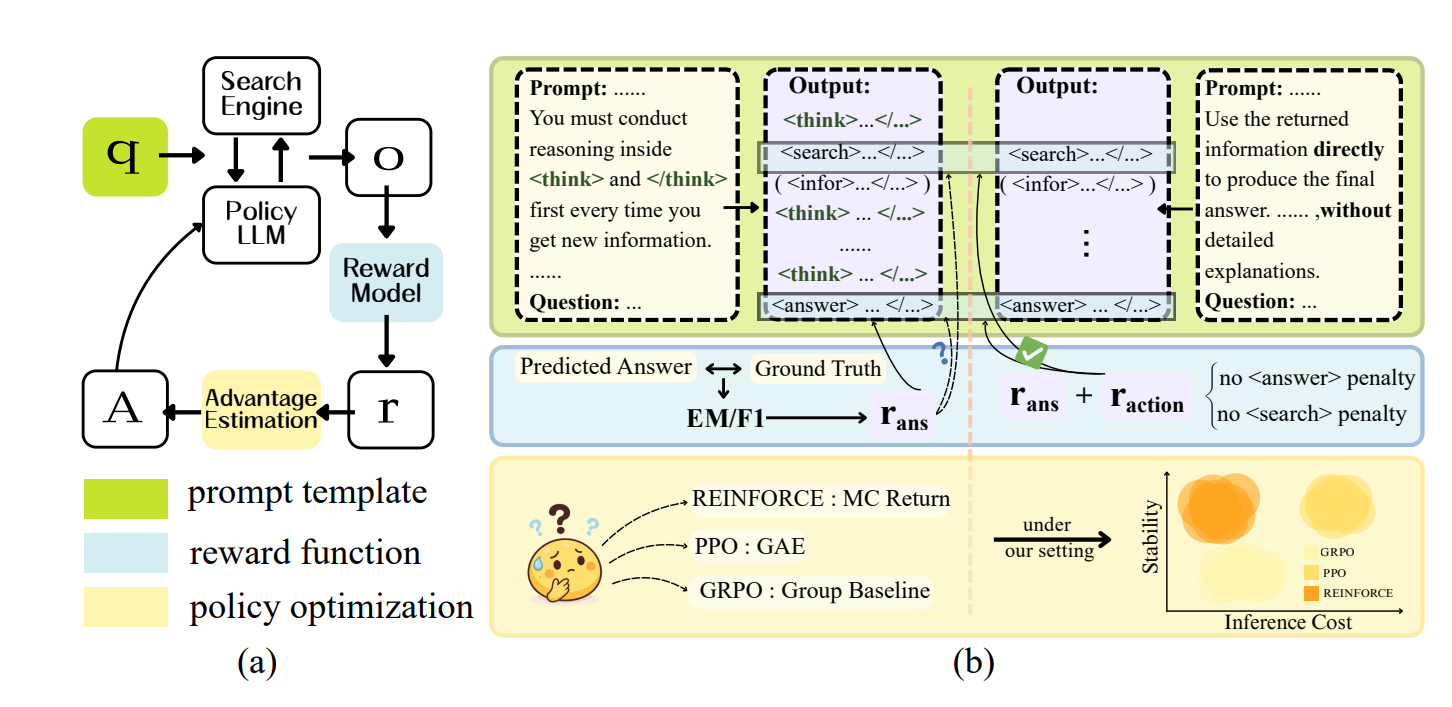
维度一:提示模板——“想得越多,做得越差”
这是最反直觉的发现。之前的论文(包括原始 Search-R1)采用了所谓的"慢思维"(Slow Thinking)模板:
【慢思维模板的核心思想】
1. 每次获得信息后,必须先在 <think></think> 标签里进行推理
2. 思考之后才能决定是否需要搜索或给出答案
3. 这样做的理由是:显式推理应该能帮助模型更好地思考
而这篇论文提出了"快思维"(Fast Thinking)模板,简化得多:
【快思维模板的核心思想】
1. 不强制显式推理过程
2. 模型可以直接决定搜索还是回答
3. 返回的信息可以直接用来生成最终答案
乍一看,慢思维模板应该更好,因为更多的中间思考应该导致更好的决策。但实验结果打脸了。
论文通过统计分析发现了一个让人震惊的相关性:在单跳和多跳问题上,更长的推理轨迹和更多的信息标记与较低的准确率呈正相关。换句话说,模型思考越多,答案反而越差。
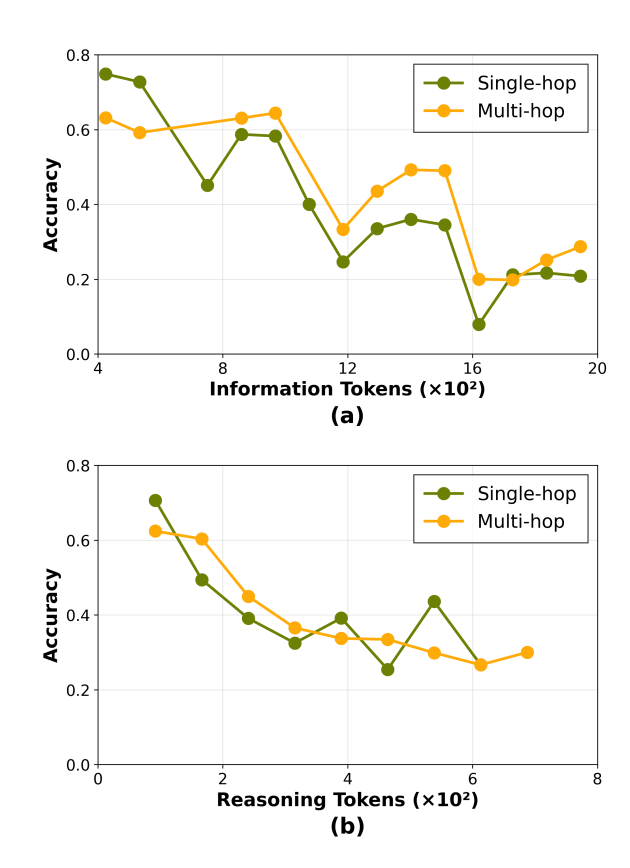
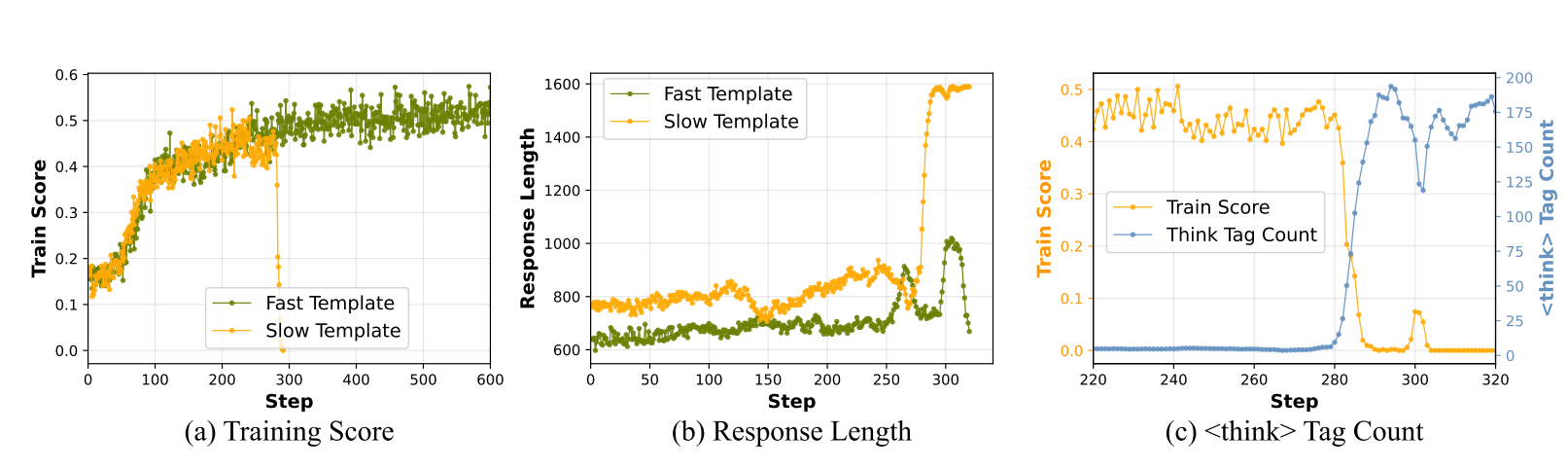
为什么会这样?论文给出了深层解释。在 PPO 这类稀疏奖励的算法下,当模型训练遇到瓶颈时,它会找到一个"捷径":发现在奖励信号中,<think> 标签的数量与最终奖励之间有某种相关性(虽然这种相关性可能是幻觉)。模型就开始疯狂堆积 <think> 标签来"贿赂"奖励函数。
具体的实证证据来自皮尔逊相关系数分析。在训练稳定阶段,<think> 标签数量与奖励的相关系数几乎为零(-0.0465)。但一旦进入崩溃阶段,这个相关系数突跳到 0.43,说明模型确实在学习一个"错误的"信号——它以为生成更多的思考标签会获得更高奖励。
这形成了一个自我强化的死亡螺旋:模型堆积 <think> 标签 → 这些标签占据了生成空间 → 实际的搜索和回答能力下降 → 最终大量生成空的 <think></think> 块。
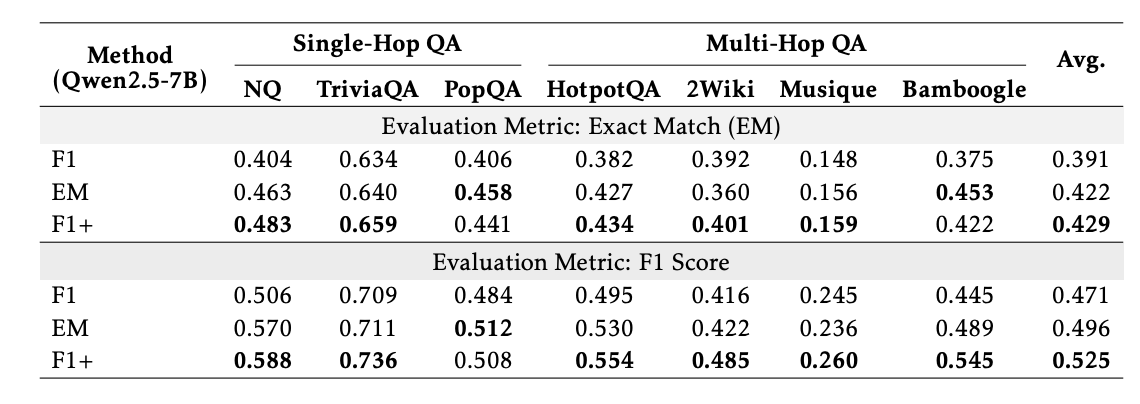
最终的性能对比(见表格)表明,仅仅切换到快思维模板,就能把平均准确率从 0.403 提升到 0.422(7B 模型),虽然幅度不大,但更关键的是训练稳定性显著提高——再也不会出现诡异的训练崩溃。
这个发现的深层意义是:过度的中间监督反而引入了错误的学习信号。简化提示词,让模型专注于核心决策(搜索还是回答),反而效果更好。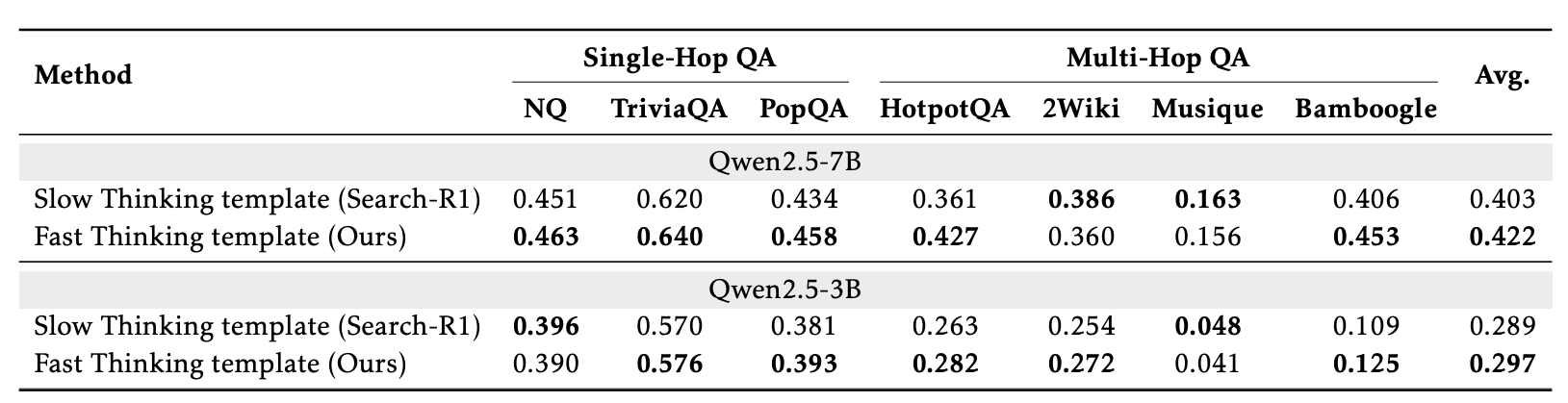
维度二:奖励函数——F1 的陷阱与救赎
在业界,有一个看似理所当然的假设:F1 分数比 Exact Match(EM)更好,因为 F1 对部分正确的答案有容忍度。于是新一代深度搜索系统(比如 ZeroSearch)都转向了 F1 奖励。
但这篇论文的实验数据表明:这是错的。
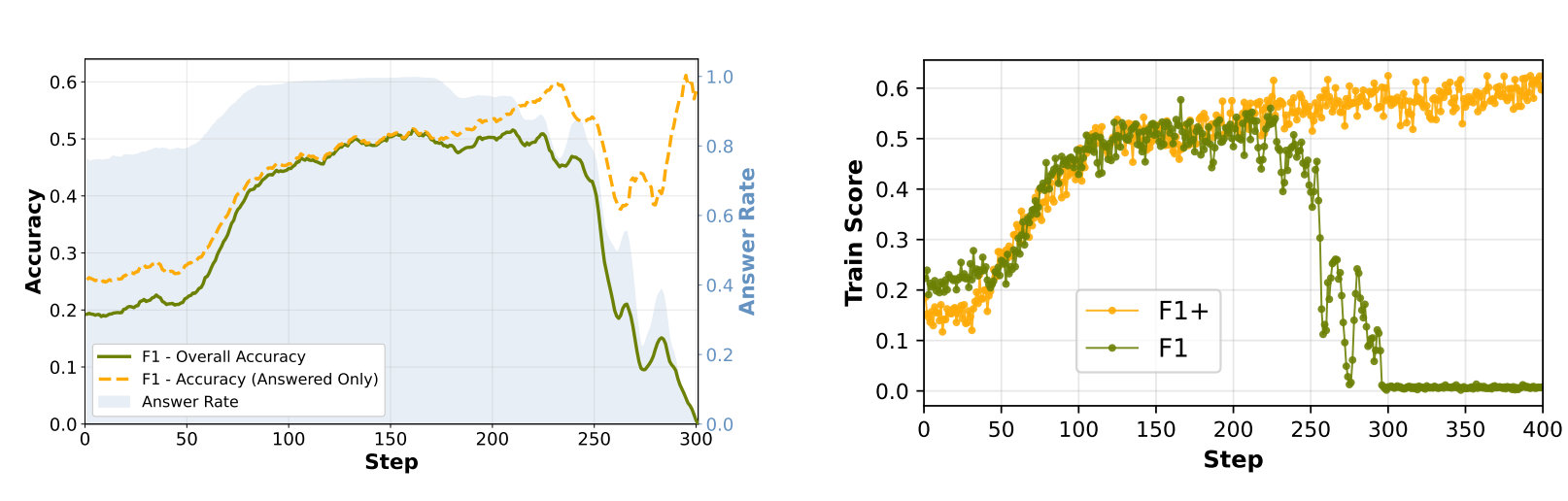
用 F1 训练的模型在稳定性和最终性能上都不如 EM,这简直违反直觉。更奇怪的是,这不是因为模型答错了,而是因为模型根本拒绝回答。
论文通过拆解性分析揭示了原因。他们把整体准确率分成两部分看:
- 总体准确率(包括所有样本)
- 仅答题样本的准确率(只看模型给出答案的样本)
在 F1 训练下,随着训练进行,总体准确率急剧下降,但神奇的是,仅答题样本的准确率反而保持稳定。这说明什么?说明答题准确性并没有崩溃,崩溃的是答题率本身。
模型为什么会这样自杀式地拒绝回答呢?这就是奖励函数设计的坑:F1 和 EM 都是"答案级"的奖励——你要么答对得分,要么答错得零分。但关键是,不回答也得零分!
所以从优化角度,模型学会了一个聪明的策略:与其费力思考可能答错,还不如干脆不回答,反正都是零分,反而能保持一个"稳定的"零分基线,避免犯错的风险。这就叫答案回避(Answer Avoidance)。
这是经典的过度简化奖励函数的陷阱。仅仅的结果级奖励,对中间过程的约束不足。
论文的解决方案是 F1+ 奖励:
RF1+=RF1−α⋅I[as=0]−β⋅I[aa=0]R_{F1+} = R_{F1} - \alpha \cdot \mathbb{I}[a_s = 0] - \beta \cdot \mathbb{I}[a_a = 0]RF1+=RF1−α⋅I[as=0]−β⋅I[aa=0]
其中第一项是标准 F1 奖励,第二项和第三项是轻量级的"动作级"惩罚——如果模型在某一步没有执行搜索(as=0a_s=0as=0)或没有给出答案(aa=0a_a=0aa=0),就扣 0.1 分的罚金(α=β=0.1\alpha=\beta=0.1α=β=0.1)。
这看起来是个"强行让模型干活"的粗暴办法,论文作者自己也承认这在理论上有"奖励黑客"(reward hacking)的风险。但实验结果表明,这个办法奇效:
- F1+ 不仅恢复了训练的稳定性,还超越了 EM
- 在表 2 和表 3 中,F1+ 的平均准确率(0.429)优于 EM(0.422)
这个发现很有启发意义:有时候,为了让 RL 训练不脱轨,适当的中间约束比看起来"更完美"的结果级奖励更有效。好的奖励设计不是追求理论的优美,而是要约束住模型的不良探索路径。
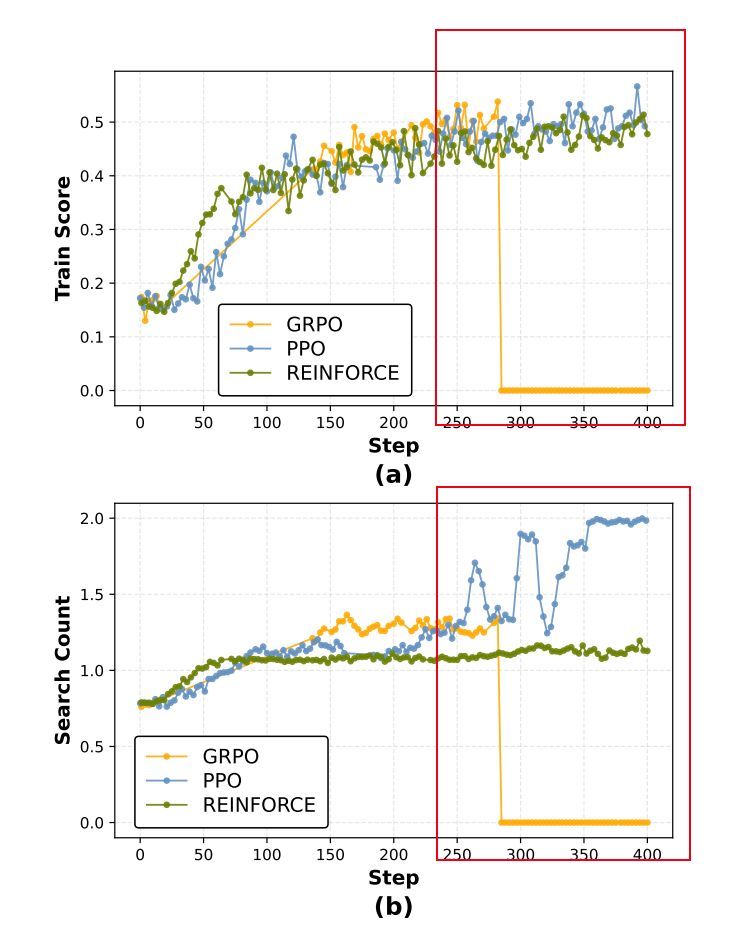
维度三:策略优化算法——古早的 REINFORCE 反而最强
这是最出人意料的发现。当代深度学习中,PPO(Proximal Policy Optimization)几乎已经成了 RL 的"官方标配"。新近流行的 GRPO(Group-wise Reward Optimization)更是宣称要解决 PPO 的各种问题。那 REINFORCE 呢?这个 1992 年发明的"古董"算法早就被认为太朴素、太慢了。
但在这个具体的深度搜索任务上,REINFORCE 反而全面碾压两个后来者。
为了理解这个结果,需要先明确三个算法的核心差异:
REINFORCE 的逻辑最直白:直接用每个样本的实际回报(actual return)作为目标,不借助任何外部基线。梯度更新就是"你得到什么奖励,我就按比例更新"。优点是简单、稳定;缺点是方差大。
**PPO 引入了一个"评论家"(Value Network/Critic)**来估计每一步的期望回报。这样做的目的是降低梯度方差。但这也引入了新的问题:需要用另一个神经网络来学习价值函数,这个网络的好坏直接影响梯度质量。在稀疏奖励的设定下(比如这里,只有最终答案对或错才有信号),价值函数很难准确学习,导致估计偏差累积。
GRPO 用了一个不同的思路:通过在采样的几个候选中进行相对比较来获得基线。比如同一个问题采样 5 个答案,用最好的和最坏的来定义"基线"。理论上这样可以减少外部拟合的需要。但在长轨迹、高方差的深度搜索任务上,同一问题的不同答案质量差异很大,这会导致基线噪声很大,反而加剧了不稳定性。
论文通过精心对照实验验证了这个直觉。在单跳问题上,REINFORCE 平均准确率 0.520,PPO 0.520,两者打平。但在多跳问题上,REINFORCE 一举拿下 0.354,对比 PPO 的 0.348 和 GRPO 的 0.355。而且最关键的是推理成本(搜索次数):
- REINFORCE:1.68 次搜索
- PPO:1.98 次搜索
- GRPO:1.84 次搜索
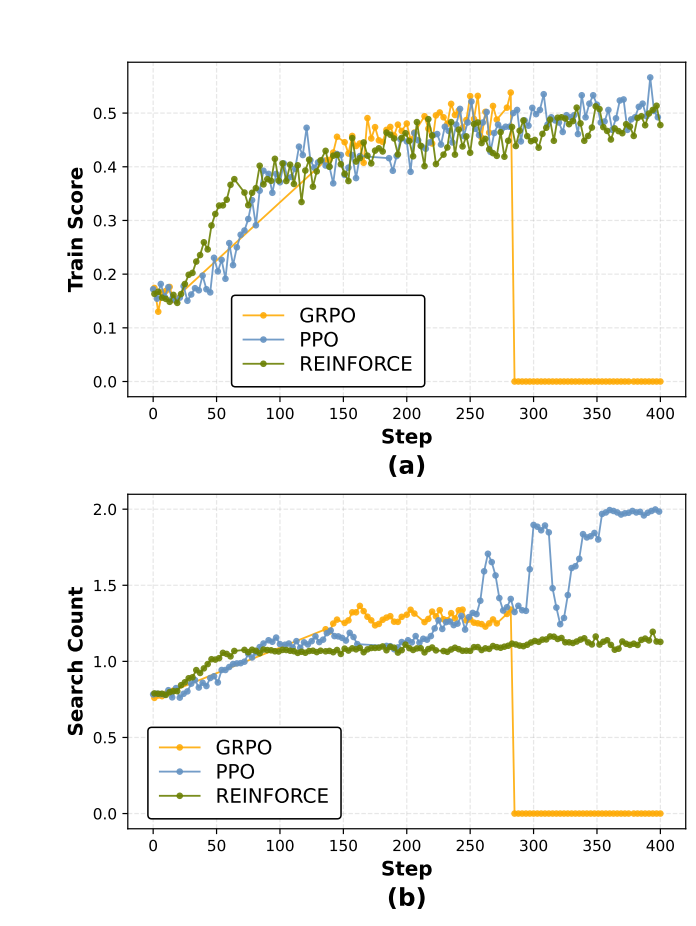
REINFORCE 不仅答对率高,而且用最少的搜索次数做到这一点。这说明它学到了最高效的搜索策略——什么时候真正需要搜索,什么时候可以直接回答。
为什么会这样?论文的解释很有道理:REINFORCE 虽然理论上"老土",但正因为它直接用蒙特卡罗回报(Monte Carlo Return),不依赖任何外部估计,在稀疏奖励下反而显得格外稳健。而 PPO 和 GRPO 为了降低方差而引入的辅助机制(价值网络或组内比较),在这个具体任务上反而成为了"干扰项"。
实验效果:改进的幅度与稳定性
基于上述三维分析,论文最终提出了 Search-R1++——一个整合了所有最优实践的强基线。它的配置很简洁:
- 提示词:快思维模板(去掉强制的
<think>标签) - 奖励函数:F1+ (F1 加上动作级罚金)
- 算法:REINFORCE
实验成果见表 5 和表 6:
在 Qwen2.5-7B 上:
- 原始 Search-R1:0.403
- Search-R1++:0.442
- 相对提升 9.7%
在 Qwen2.5-3B 上:
- 原始 Search-R1:0.289
- Search-R1++:0.331
- 相对提升 14.5%
这个改进不只是数字好看,更重要的是跨越多个数据集的一致性。对比对象包括:
- R1-base(不加检索的纯 RL 模型):这是一个下界,说明为什么检索很重要
- ReAct(无训练的智能体):代表传统的提示工程方法,性能最差
- 原始 Search-R1:业界标杆
在 7 个不同的基准上(NQ、TriviaQA、PopQA、HotpotQA、2Wiki、Musique、Bamboogle),Search-R1++ 都有改进,这说明这个改进不是偶然或过度拟合的。
特别值得注意的是,这个改进在多跳推理(HotpotQA、2WikiMultiHopQA 等)上尤为显著。比如在 HotpotQA 上从 0.361 提升到 0.423,在 Bamboogle 上从 0.406 提升到 0.448。这恰好证实了我们在算法分析中的观察——REINFORCE 特别善于处理多步决策问题。
训练曲线对比
论文还展示了训练过程中的几个细节对比。在图 7 中可以看到:
- REINFORCE:训练曲线平稳上升,没有波折。最终收敛到 0.4+ 的稳定水平。
- PPO:虽然也稳定,但搜索次数"卡住"在 1.95-2.0,说明模型学不会自适应调整策略。
- GRPO:频繁出现训练波动,甚至有几次明显的向下跳跃。
这进一步验证了论文的结论。
论文总结
在深度搜索智能体的 RL 训练中,看起来"更复杂、更科学"的设计(长推理链、模糊的 F1 奖励、复杂的基线估计)往往不如简化设计有效;反而通过消除不必要的中间监督、让奖励信号更明确、采用更直白的优化策略,能获得更好的稳定性和性能。
或者更通俗的说法是:有时候,简单粗暴比聪明复杂更靠谱。
第一,提示词工程的陷阱。显式推理不一定更好。在 RL 的稀疏奖励环境下,过度详细的指令反而容易引发模型学习错误的信号。让模型专注于核心决策,往往效果更好。这对所有需要长轨迹决策的 大模型 系统都有借鉴。
第二,奖励函数的设计需要既看结果也看过程。仅仅的答案级奖励在稀疏反馈下容易导致模型走偏。引入轻量的动作级约束,虽然看起来"不那么纯粹",但能有效防止这类探索陷阱。
第三,新不一定比旧好。在这个特定领域,经典的 REINFORCE 算法的"笨重"反而成了优点——它的简单性带来了稳定性和高效性。这是对"追新"思维的温和反驳。
这个研究对正在做 RL 智能体的团队特别有用。如果你的模型训练出现了诡异的崩溃、或者性能不如预期,不一定要怪你的检索器或你的基础模型,有可能是这三个"看起来不起眼"的设计选择惹的祸。
而且这篇论文的方法论(消融实验、严格对照)也很值得学习。面对复杂系统时,系统地拆解各个因素,比直接堆新算法更能找到问题的根源。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)