破除各种限制,手把手教你本地部署大语言模型,打造私人AI
随着 AI 应用的快速普及,它已经悄然融入了人们的日常生活。相信大家对 ChatGPT、豆包、元宝这些 AI 应用已经不再陌生,并且几乎离不开它们了。但是,随着这些商用 AI 的广泛应用,一些问题也随之而来。由于监管日益严格,商用大模型的“输出限制”越来越多,动不动就触发拦截;另一方面,很多人也担心自己的敏感信息(比如商业机密、个人敏感信息,或者一些不便于给别人知道的对话)被大厂收集导致隐私泄露。这就导致很多时候,虽然 AI 很智能,但在某些特定场景下却显得非常“鸡肋”。那么,在自己的电脑上本地部署一个完全受自己控制的大语言模型的需求对个人用户就变得非常迫切。本文就将一步一步教你在本地电脑上部署一个专属于你自己的AI。
第一步:认识并安装 Ollama
简单来说,Ollama 是一个开源的本地大模型运行框架。在过去,想要在自己的电脑上运行一个几十亿参数的大语言模型(LLM),你需要懂 Python、配置复杂的代码环境、处理各种让人头疼的报错。而 Ollama 的出现彻底打破了这个技术壁垒,它将极其复杂的底层逻辑进行了封装,让普通用户能够像安装普通电脑软件一样,轻松下载并运行各种顶级的开源大模型(如 deepseek、Qwen 、GLM等)。
因此要想在本地部署一个大语言模型,首先就需要在安装一下ollama这个软件。
1. 下载 Ollama
- 首先来到 Ollama 官网:https://ollama.com/
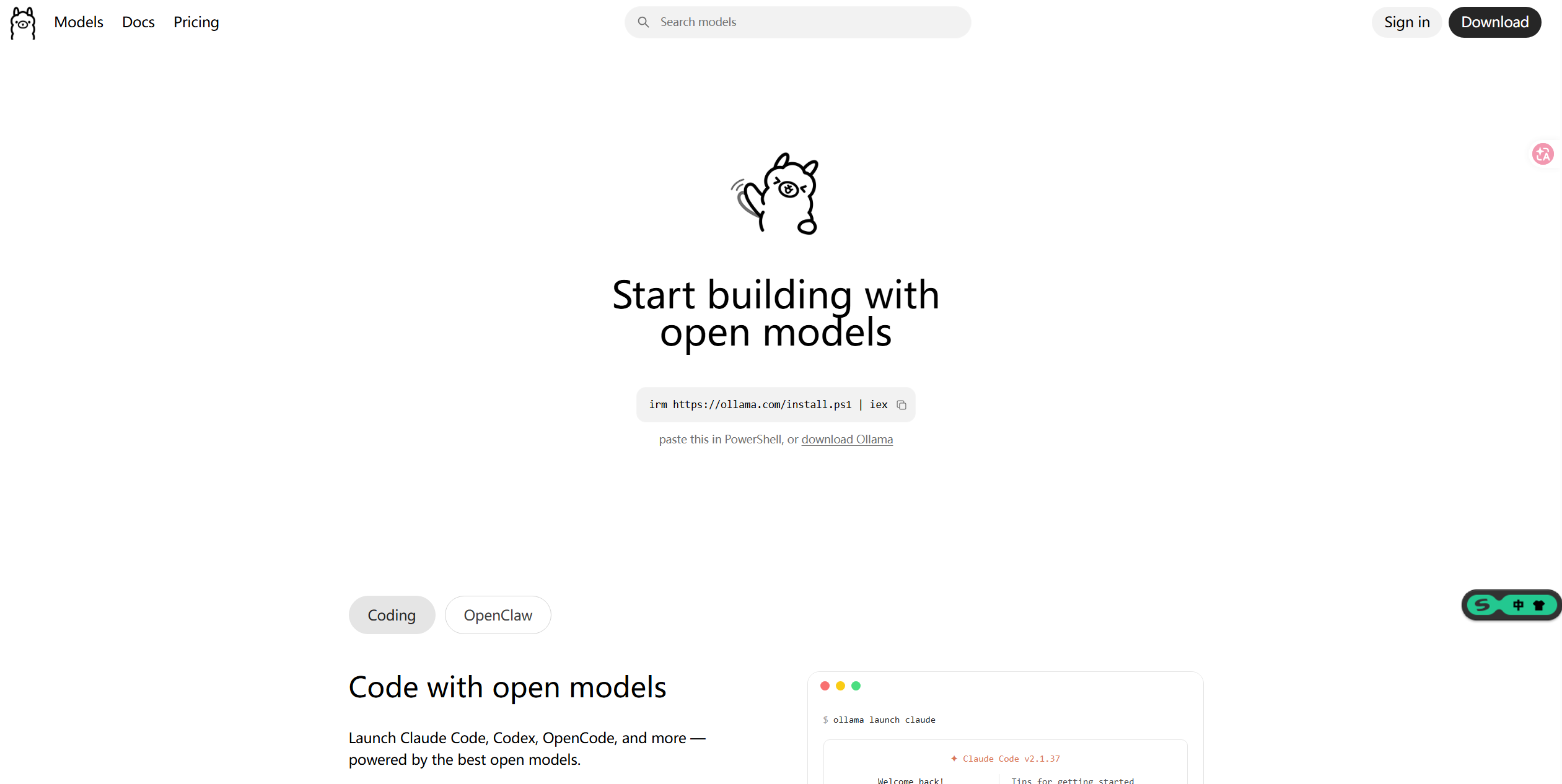
- 点击右上角的 Download 按钮,选择自己电脑对应的操作系统版本进行下载(本文将以 Windows 系统做演示)
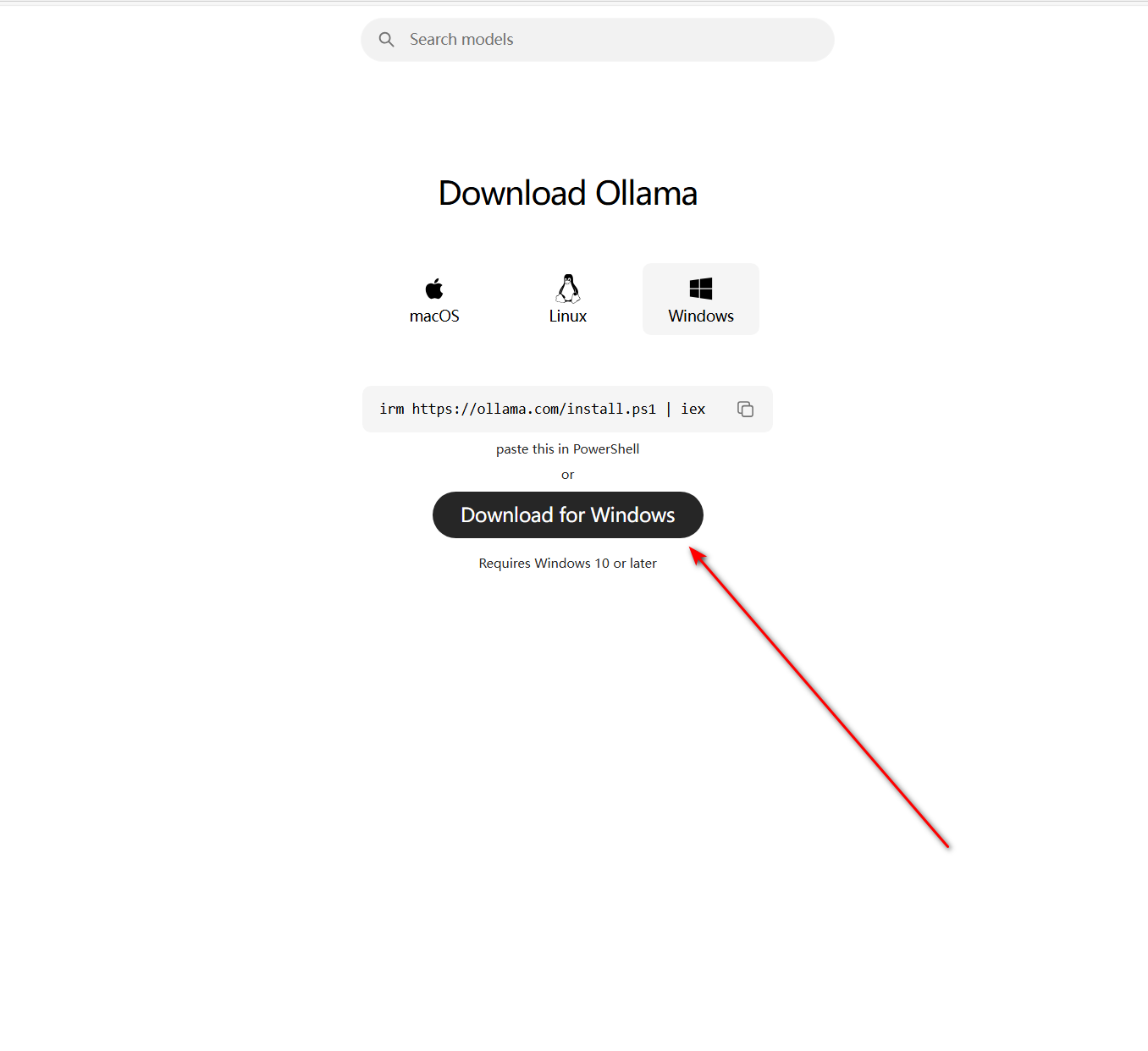
下载好后,点击 .exe 文件进行安装。程序默认会直接安装到 C 盘, 且在安装时无法更改,同时我也建议各位尽量不要用别的方式更改避免后续报错。
安装完成后打开ollama应用程序 点击settings按钮
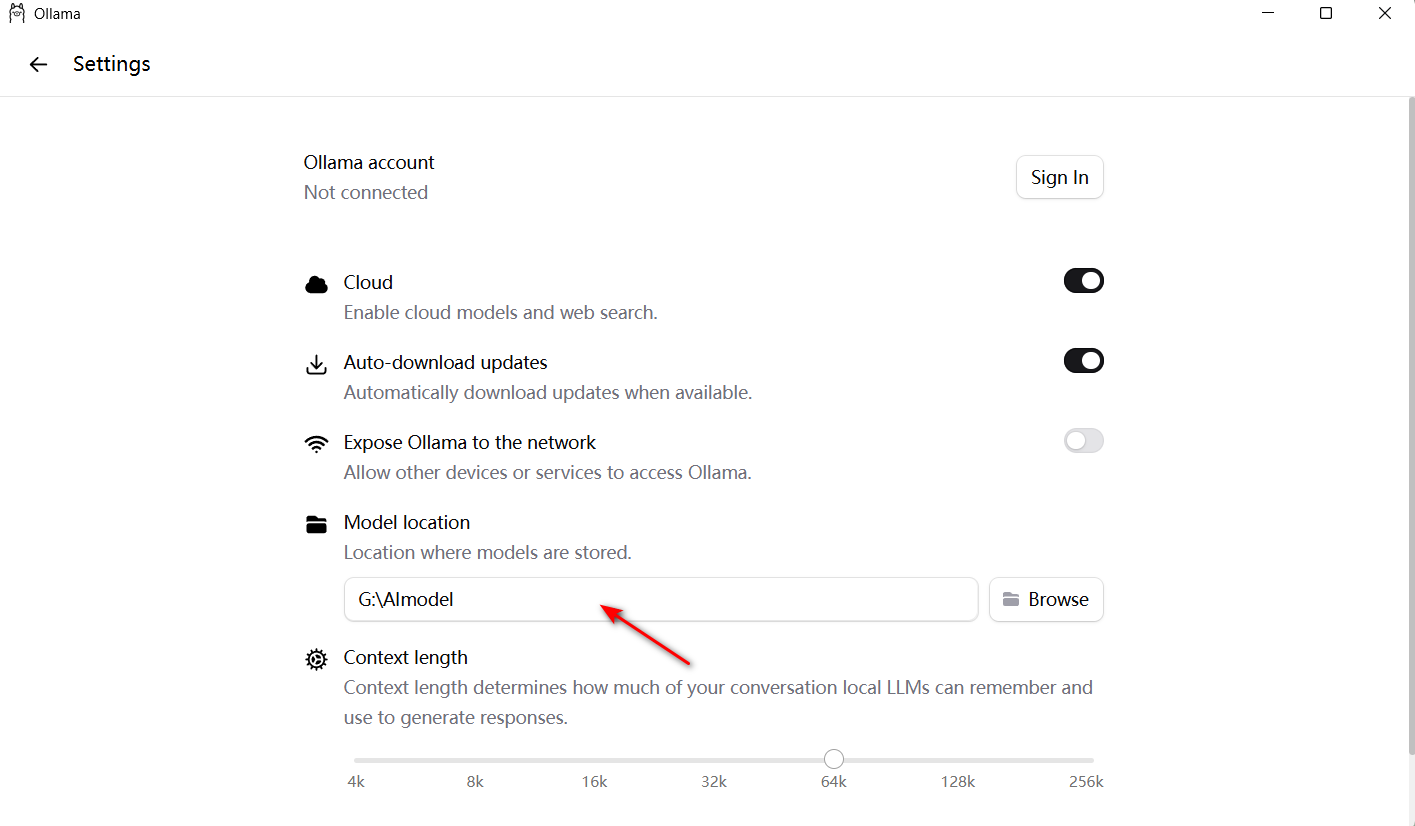
然后将Model location 改成除C盘以外的固态盘分区内,不然后续大模型都会装在你C盘里给你C盘撑爆(当然你C盘要是分了1T就当我没说)
第二步:下载开源大模型到本地
回到 Ollama 官网,点击顶部的 Models,你就能看到海量的开源大语言模型,比如 DeepSeek、Qwen(通义千问)、GLM 等等。我们这里以 DeepSeek-R1 模型为例给大家做演示。
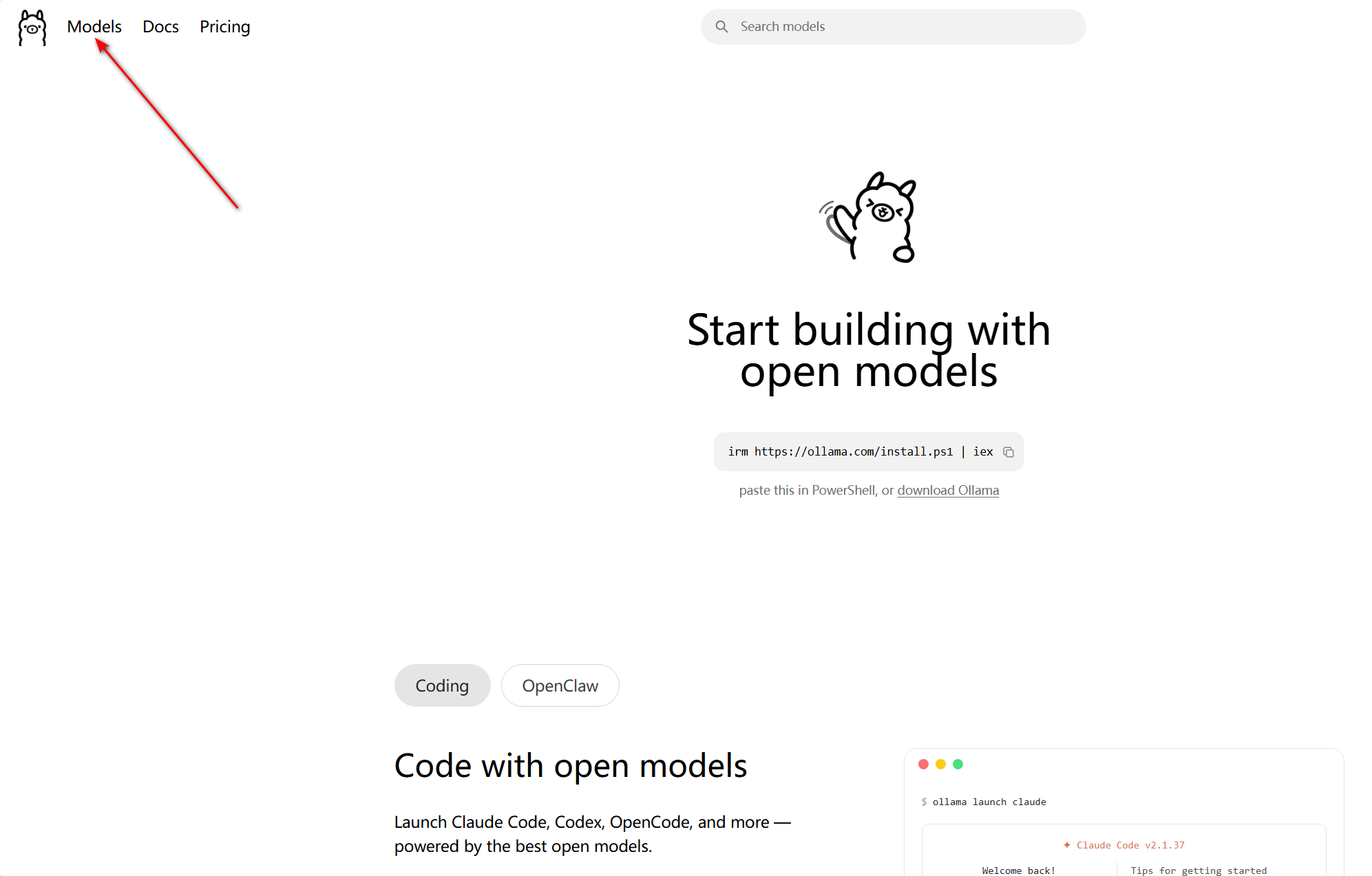
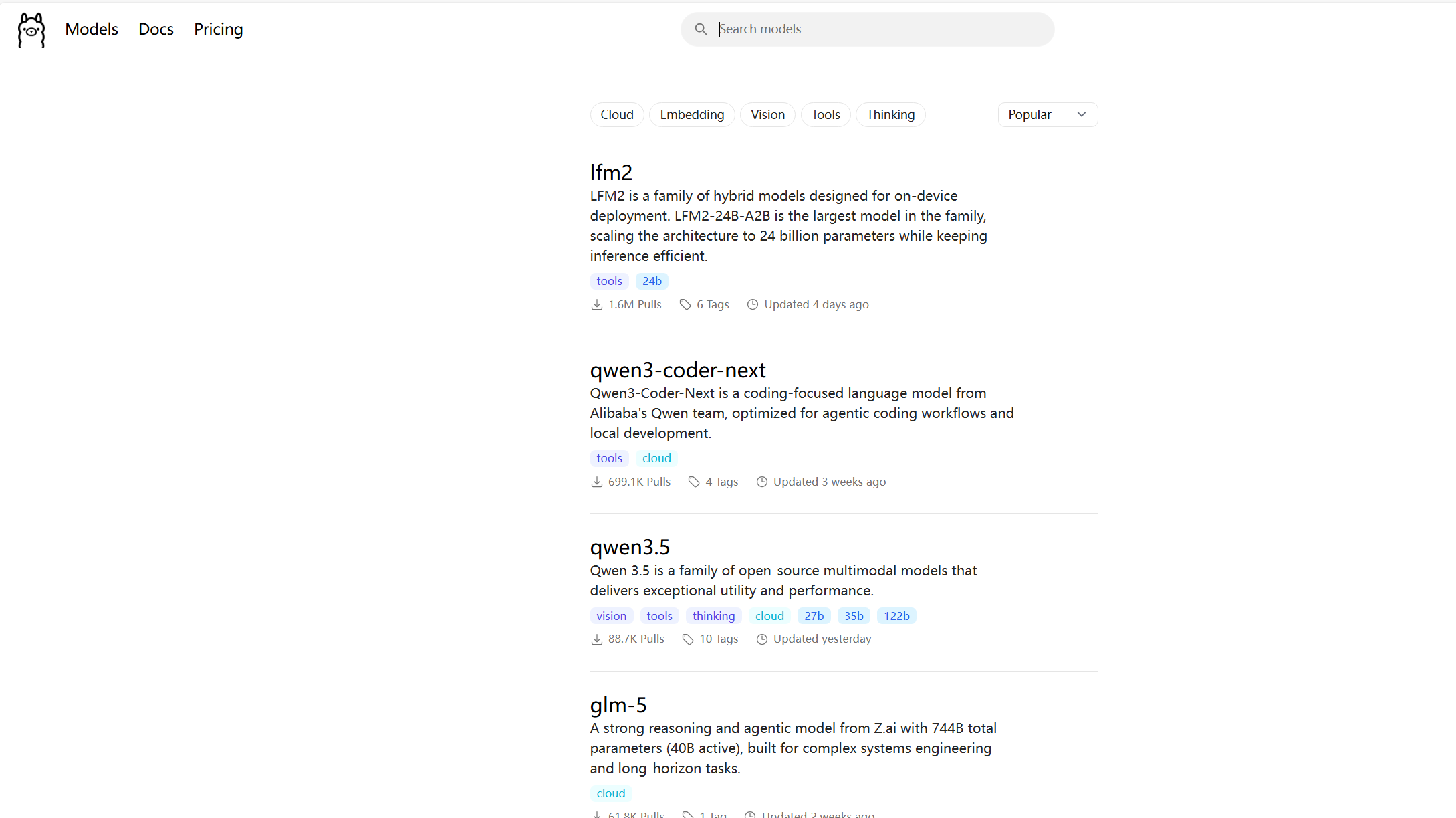
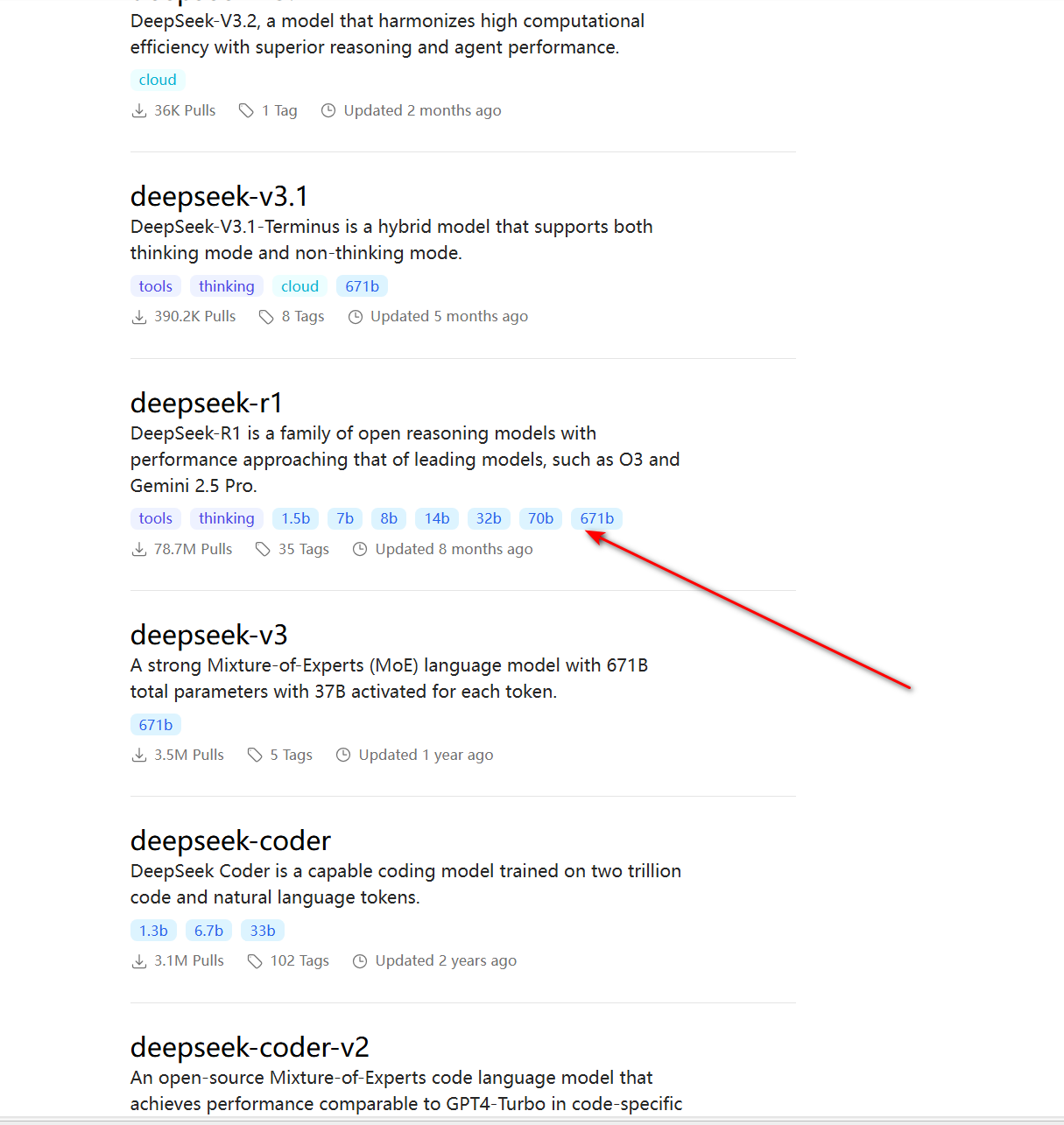
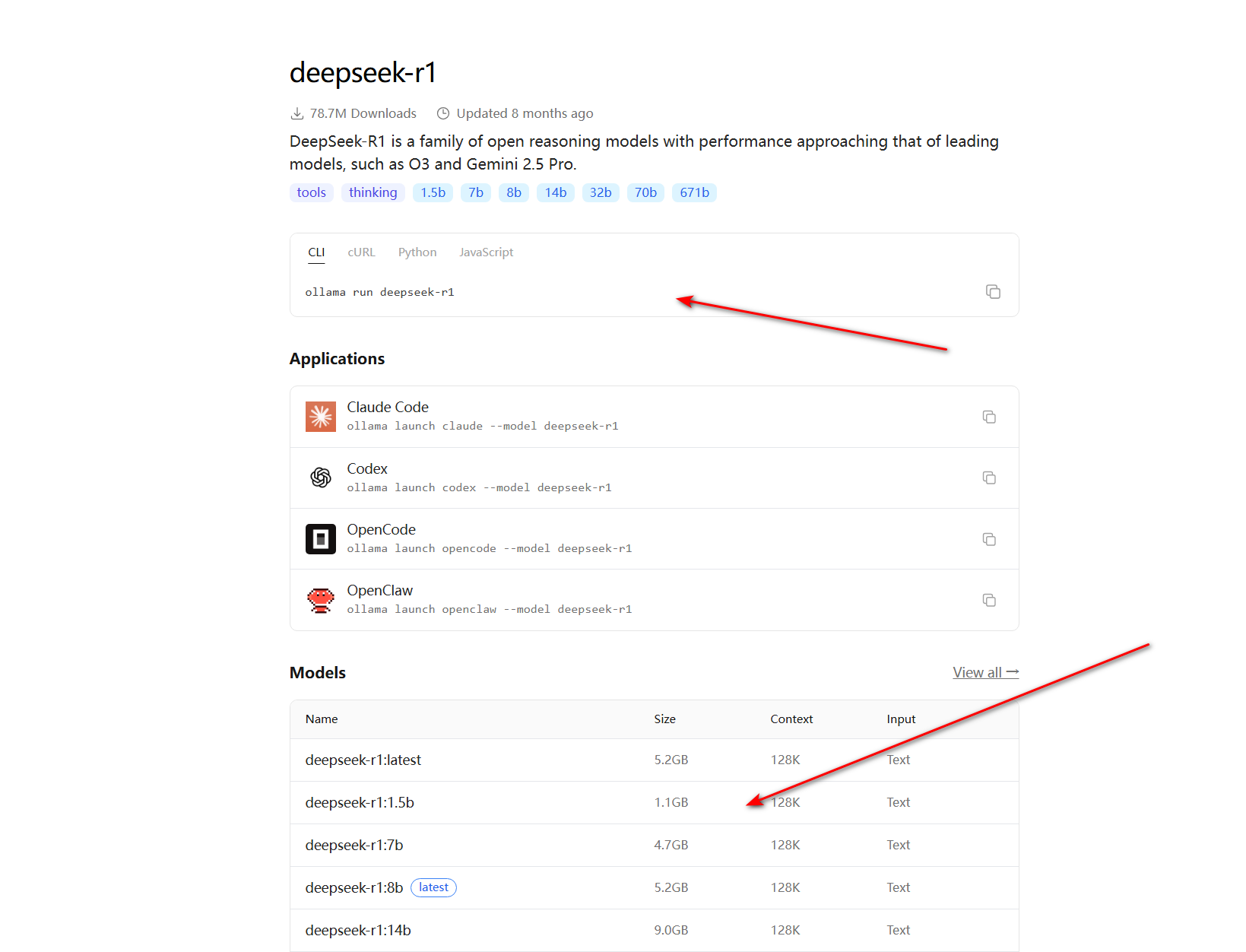
点击进去我们可以看到有不同版本的 deepseek R1 模型 以及下载安装该模型的命令代码
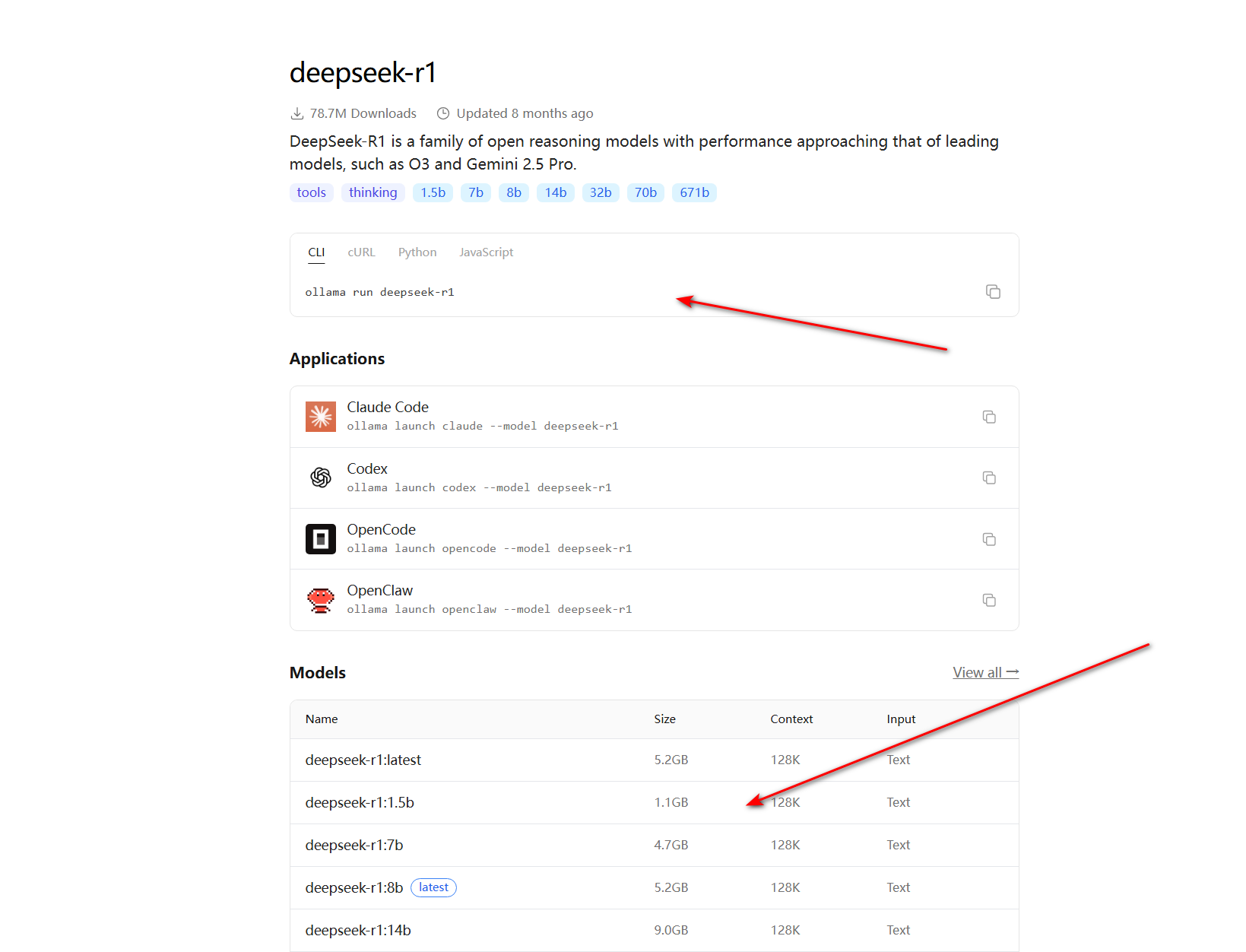
为什么同一个模型会有 7b、14b 等这么多版本?我们到底应该怎么选?
很多新手在这里会感到一头雾水,其实理解起来非常简单:这里的字母“b”代表的是英文 Billion(十亿)。 所谓的 7b,就是指这个模型包含了 70 亿个参数;14b 就是 140 亿个参数。你可以把“参数量”直接理解为这个 AI 大脑的“脑细胞数量”参数量越大(如 32b、70b): 模型的“脑细胞”越多,它就越聪明,逻辑推理能力越强,能处理更复杂的长文本和专业问题。但代价是,它非常“吃”你电脑的硬件资源(主要是运行内存和显卡的显存),如果你的电脑配置不够,强行运行会要么根本跑不动,要么一个简单的对话它会需要好几分钟才能给出回答。参数量越小(如 1.5b、7b): 模型相对轻量级,虽然在极其复杂的逻辑问题上可能不如大参数版本聪明,但它对普通电脑非常友好,运行速度极快,用来做日常的文本润色、简单的代码辅助或闲聊已经完全足够了。
这里给大家一些建议
7b 版本(入门首选): 如果你的电脑的内存是8-16GB,显存是4-8GB,建议你选择 7b(或更小参数)的版本。
14b - 32b 版本(进阶体验):如果你的电脑内存达到了 16GB 到 32GB,显存在12-16GB之间,那么你就可以尝试下载这个14b-32b区间段的版本,我自己电脑的配置是32G内存+16G显存,勉强能带的动32b的版本,但是体验并不好,更多的还是使用14b或27b的版本
那么如何查看自己电脑的配置呢?
点击电脑Windows 开始按钮搜索“设置” 进入设置页面
然后点击系统
然后点击 系统信息
然后 显卡这里的 16GB 就是你的显存容量 机带RAM 32GB 就是你的内存容量啦
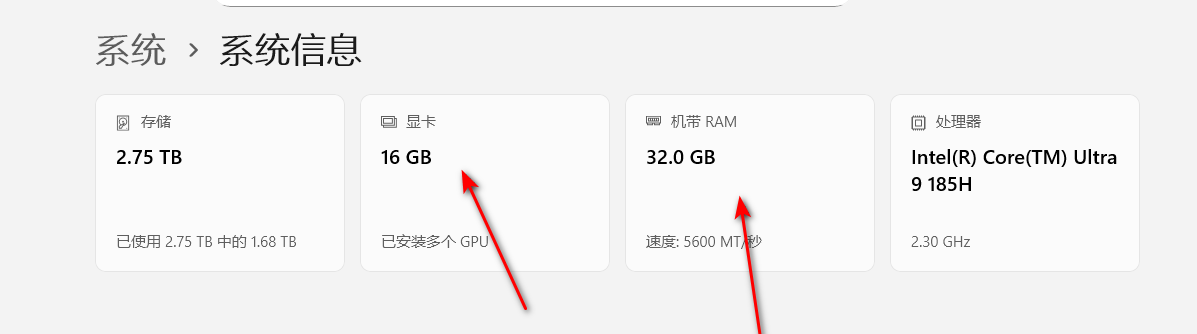
现在知道了你电脑的配置后 就可以选择适合的模型进行下载安装了。
执行下载与运行命令
首先我们 同时按键盘上的 Win + R 键,输入 cmd 按回车,调出黑色控制台窗口
这个时候我们就得去复制 这个 ollama run deepseek -r1 这个命令到控制台了,复制完后记得在后面加上 :模型参数 来指定具体模型
例如你要下载 7b 版本 那就是 ollama run deepseek-r1:7b 然后按回车 你就会看到模型开始下载啦

接下来请耐心等待模型下载,当屏幕上出现 success 时,就说明下载成功了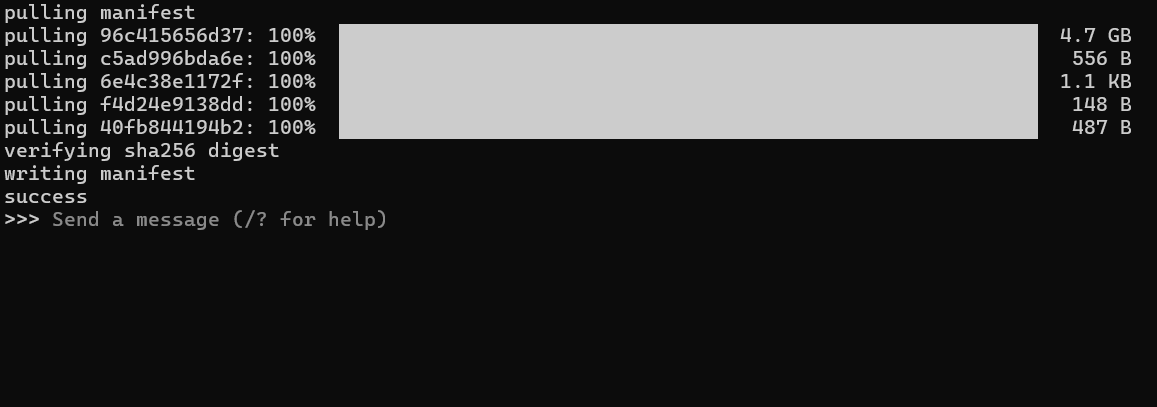
然后我们重新打来ollama 客户端 点击模型选择处,找到我们刚才下载的模型并选择 然后在旁边的输入框 就可以使用本地模型啦
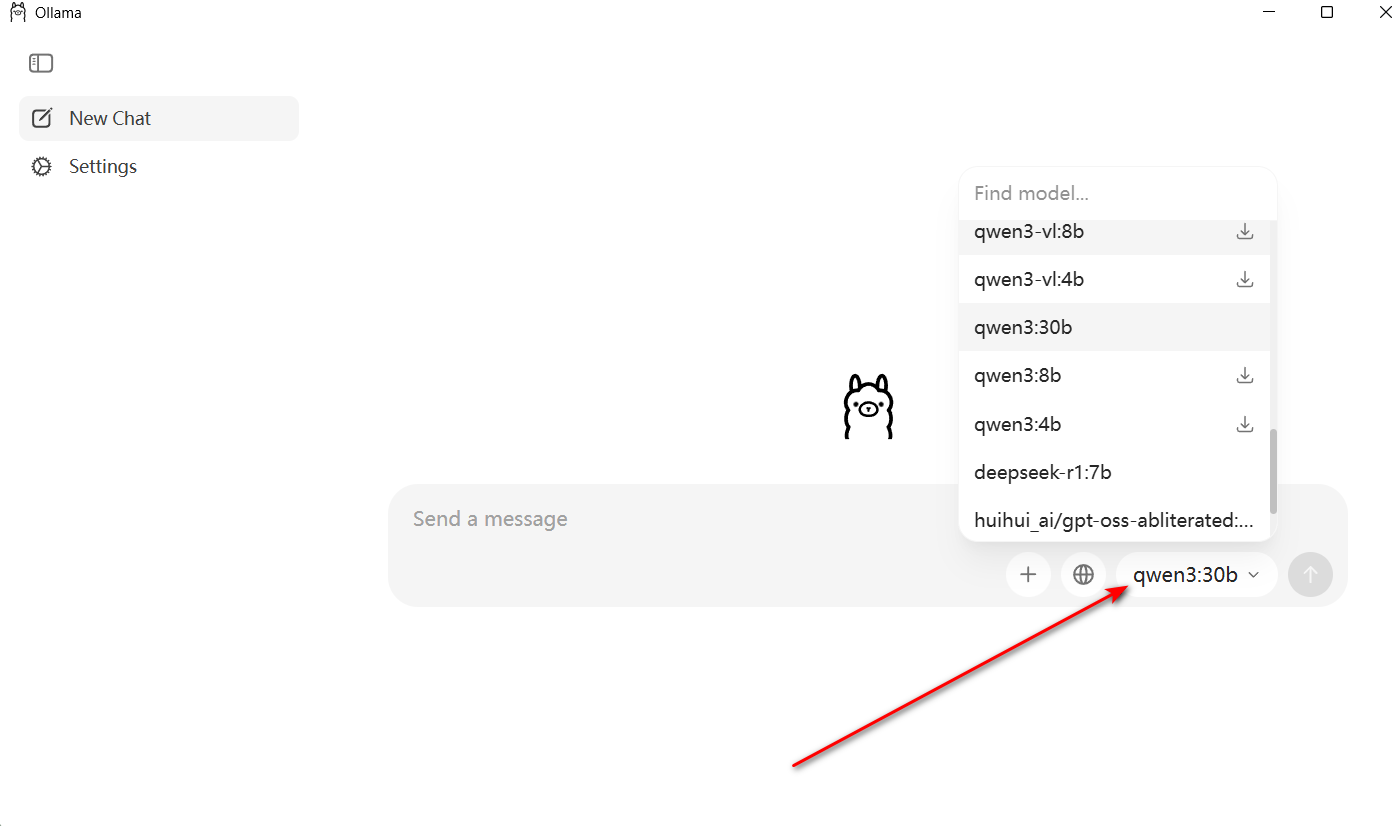
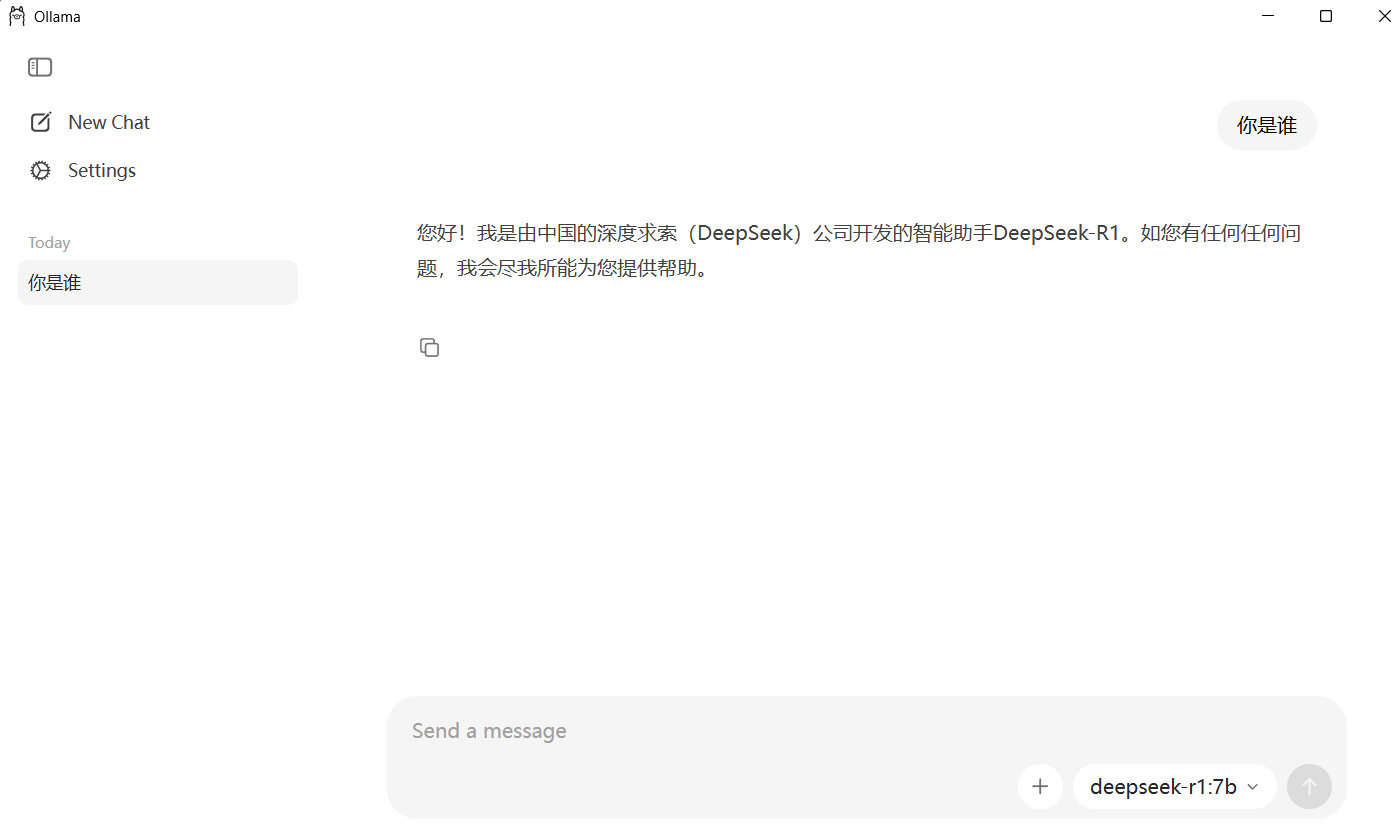
看到这里,相信你已经完整掌握了下载并安装开源大模型的方法。那么回到文章标题:如何解决AI模型的各种限制呢?
安装“破限版本”的AI大语言模型
我们要明白一件事情:即使是各大科技公司免费开源出来的大语言模型,在出厂训练时,也已经对它的输出做了严格的安全对齐和限制。这主要是为了避免大模型被不法分子滥用。那你可能就要说了:“那你前面吹了半天本地部署破限版本的AI 干啥,最后不还是做不到吗?”
朋友,我知道你很急,但是你先别急。
虽然官方原版有限制,但架不住开源社区里有一大批技术极客!他们为了学术研究或追求更自由的 AI 体验,会专门去对这些官方大模型进行“解除限制”的技术处理(常被称为“破限”),并将处理后的版本重新发布到开源社区供大家交流。
我们只需要下载这种“破限版本”就可以了。
那么该如何寻找破限版本的模型呢?
1.首先我们依旧来到 Ollama 官网的 Models 搜索界面。输入你想要找的模型名,这里以 Qwen 为例
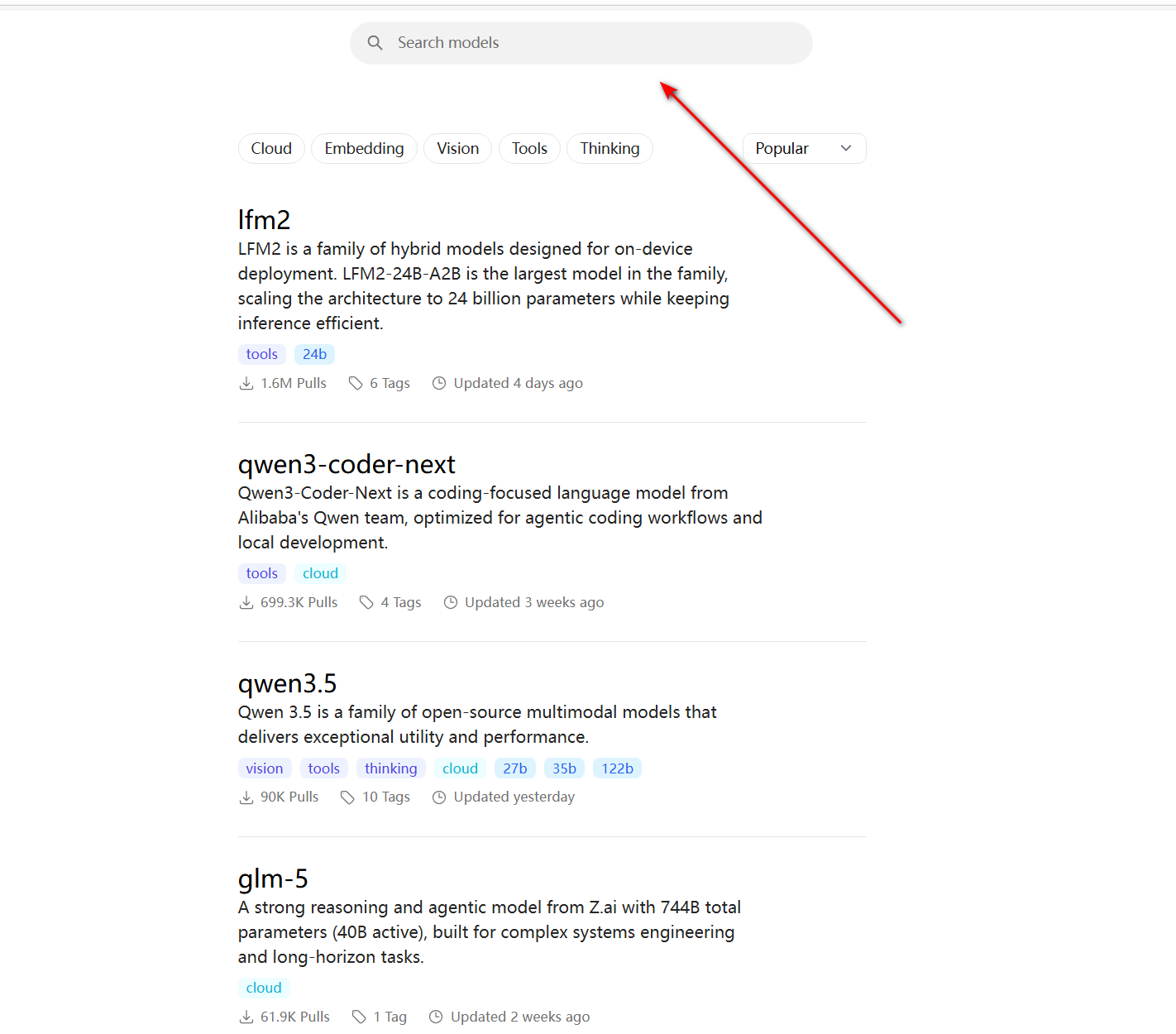
2.然后我们找到后缀带有abliterated 后缀字样的模型 这种的就是破限后的版本啦
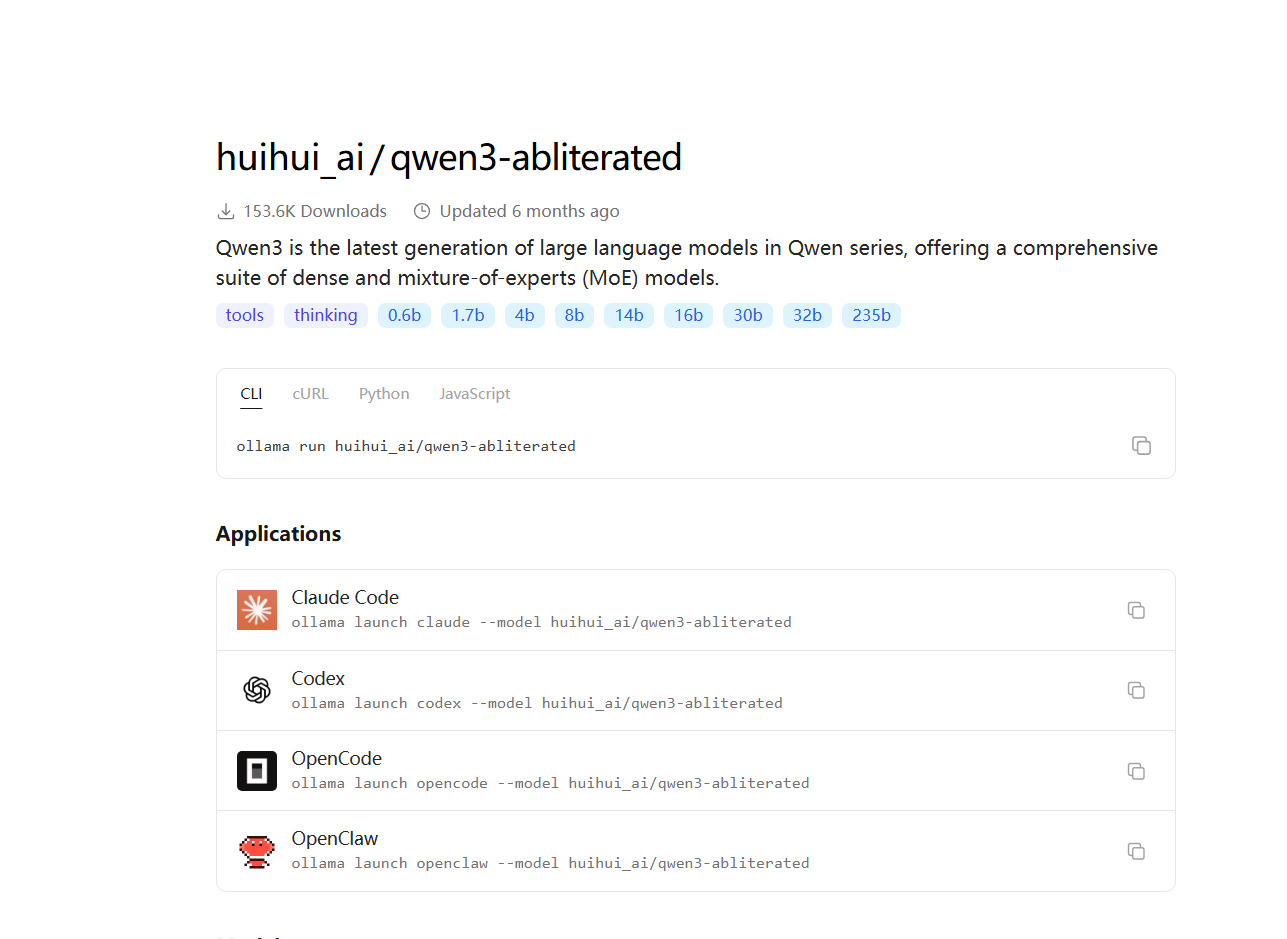
3.找到后,同样复制它的下载命令(例如 ollama run ...),在 cmd 控制台中运行下载。
至此,大功告成!现在,一个完全属于你、且去除了各种限制的私人本地 AI,就已经部署好了。
虽然我们通过本地部署获得了极大的自由,破除了很多不必要的束缚,但在这里还是要特别提醒大家:即便是本地部署的模型,也绝对不要用来从事任何违法乱纪或违背社会公序良俗的事情。 “本地部署”绝不是法外之地。技术本身是中立的,但使用技术的人必须有底线。AI 的安全、健康与合理使用,需要我们每一个人的共同维护。希望大家都能让 AI 成为提升自己工作和学习效率的利器,而不是用来做坏事的工具!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)