论AIOps(智能运维)在大型分布式系统中的应用
【摘要】2024年,作者作为核心架构师主导了某大型分布式服务平台的AIOps智能化改造。面对日均千万级请求和PB级数据处理压力,传统运维手段已无法应对告警风暴、故障定位困难等挑战。项目通过构建统一观测数据湖,引入时间序列异常检测、知识图谱根因分析等AI算法,实现了智能告警降噪、精准异常检测和快速故障定位。改造后系统告警准确率提升80%,平均故障恢复时间缩短30%,有效保障了99.99%的高可用性。
【摘要】
2024年06月,我作为核心架构师参与了某大型分布式服务平台的重构与升级工作。该平台采用微服务架构,部署于多云环境,支撑着日均千万级的用户请求与PB级的数据处理。随着业务规模的指数级增长,系统组件日益复杂,传统基于规则和阈值的运维手段面临着海量告警噪声、故障定位(RCA)耗时过长、以及被动响应等严峻挑战,严重影响了系统的可用性(SLA)。 为此,我们在运维体系中引入了AIOps(智能运维)能力。通过构建统一的观测数据湖,利用时间序列异常检测算法实现精准告警,采用基于知识图谱的根因分析技术加速故障定位,并结合决策树模型实现部分故障的自动化修复。本文将详细阐述该系统的架构设计,并重点论述AIOps在智能告警降噪、多维指标异常检测及故障根因分析等方面的具体应用。实践证明,AIOps的引入使系统告警准确率提升了80%,平均故障恢复时间(MTTR)降低了30%,有效保障了系统的高可用性。
【正文】(约 2000-2500 字)
一、 项目背景与运维挑战
写作指导: 简要介绍项目,重点铺垫“为什么需要AI”。不要只写业务,要写系统架构的复杂性如何导致了传统运维失效。
1. 项目概况 (在此处描述你的项目,例如:该系统是一个基于K8s容器化部署的自动驾驶数据闭环平台,涉及数据采集、清洗、仿真等多个环节,拥有数百个微服务实例...)
2. 面临的痛点 在项目初期,我们采用了主流的DevOps工具链(如Prometheus+Grafana+ELK),但在实际运行中遇到了以下瓶颈:
-
告警风暴: 静态阈值难以适应动态流量,导致每天产生数千条告警,运维人员疲于应对,重要告警容易被淹没。
-
故障定位难: 微服务调用链复杂,一个底层服务的抖动可能引发上层多个服务的连锁反应,依靠人工查看日志排查根因往往需要数小时。
-
被动响应: 往往是用户投诉后才发现问题,缺乏预测性维护能力。
基于上述问题,我们决定在现有DevOps体系之上,融合机器学习算法,构建AIOps智能运维平台。
二、 AIOps 架构设计
写作指导: 展示你对架构的理解。AIOps通常分为三层:数据层(观察)、模型层(分析)、应用层(执行)。
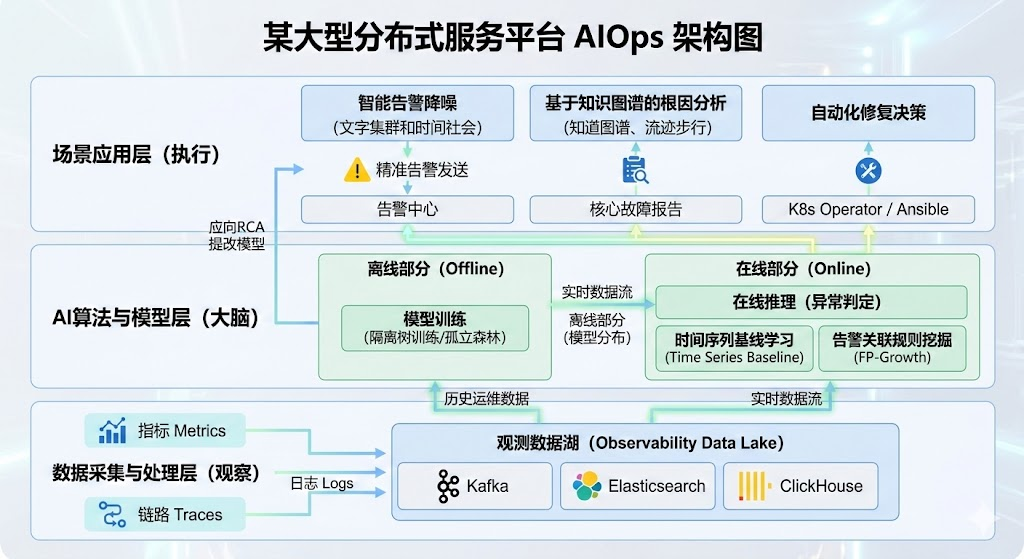
我们将AIOps体系设计为三个核心层次:
-
数据采集与处理层(观察): 统一收集Metrics(指标)、Logs(日志)、Traces(链路追踪)三类数据,清洗后存入Kafka和Elasticsearch/ClickHouse,形成运维大数据湖。
-
AI算法与模型层(大脑): 包含离线训练与在线推理两部分。离线部分利用历史数据训练异常检测模型(如孤立森林);在线部分实时消费数据流进行推理。
-
场景应用层(执行): 对接告警中心和自动化运维平台(K8s Operator),实现智能告警、根因分析和自动愈合。
三、 AIOps 的关键应用实践
写作指导: 这是论文最核心的部分,建议选取 2-3 个具体点深入展开。以下是三个高分切入点:
1. 基于无监督学习的智能异常检测(解决“阈值难配”问题) 传统的CPU使用率超过80%即告警的策略过于僵化。
-
做法: 我们引入了无监督学习算法和时间序列预测算法。
-
细节: 系统会对关键指标(如API响应时间、吞吐量)学习其历史模式(基线)。例如,每天上午9点是业务高峰,CPU升高是正常的;但如果在凌晨3点CPU突然升高,即使未达80%阈值,算法也会判定为“偏离基线”的异常。
-
效果: 实现了动态阈值,有效识别了“隐性故障”。
2. 基于聚类与关联分析的告警降噪(解决“告警风暴”问题)
-
做法: 针对海量告警,我们应用了文本聚类算法和时间窗口关联分析。
-
细节: 当数据库发生抖动时,可能会瞬间引发数百个上层服务的超时告警。AIOps平台将同一时间窗口内、拓扑结构相关联的告警聚合为一个“故障事件”。利用FP-Growth算法挖掘告警之间的强关联规则。
-
效果: 将原本离散的100条告警压缩为1个核心故障报告,运维人员只需处理这一个核心事件,极大降低了干扰。
3. 基于知识图谱与调用链的根因分析(RCA)(解决“排查慢”问题)
-
做法: 构建系统的拓扑图,结合调用链(Trace)数据。
-
细节: 当检测到异常时,算法会自动沿着服务调用拓扑图进行随机游走或加权传播,结合各节点的健康度评分,计算出可能性最大的“故障源节点”。例如,前端响应慢,系统自动分析出是由于后端某Redis节点延迟增高导致的,并直接给出证据链。
-
效果: 将平均故障定位时间(MTTI)从小时级缩短至分钟级。
四、 实施效果与反思
写作指导: 摆数据证明成功,同时展现架构师的谦虚和长远眼光(提一点不足或未来计划)。
1. 实施效果 项目上线半年后,系统运维效率显著提升:
-
告警收敛率达到90%以上。
-
核心业务可用性从99.9%提升至99.99%。
-
运维团队从“救火队员”转型为“架构优化者”。
2. 遇到的问题与改进 在实践中我们也发现,AIOps模型的训练极其依赖高质量的数据。初期由于日志格式不规范,导致模型准确率低。后期我们制定了严格的日志规范,并引入了数据治理流程,才解决了这一问题。 此外,目前我们的自动愈合仍主要集中在重启服务、扩容等简单操作,未来计划引入强化学习,实现更复杂的故障自愈决策。
【结尾】(约 300 字)
综上所述,AIOps是应对大规模分布式系统运维挑战的必然选择。通过在本项目中引入数据驱动的AI能力,我们成功解决了传统运维手段在时效性和准确性上的瓶颈。 作为系统架构师,我深刻体会到,AIOps不仅仅是引入几个算法,更是一场工程化的变革。它要求架构必须具备高度的可观测性,数据必须规范化。未来,随着大模型(LLM)在运维领域的应用,AIOps将向着更加自然语言交互、更加智能化的方向发展,我将持续关注并实践这一前沿技术。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)