超越大型语言模型:构建人工智能代理的核心框架
构建一个真正有能力的 AI 智能体,远不只是给大型语言模型(LLM)写提示词而已。即便先进的 LLM 能生成文本、甚至生成代码,要编排一个完整的智能体系统,仍然需要一整套配套的框架与工具生态。在这篇文章中,我们将探讨开发者除了 LLM 本身之外还需要的关键组件——以便创建能够自主行动、与外部系统集成、记住信息、并在复杂环境中安全运行的 AI 智能体。我们将覆盖:为什么编排框架(如 LangChai
一、构建真正有能力的 AI 智能体:远不止给大模型写提示词
构建一个真正有能力的 AI 智能体,远不只是给大型语言模型(LLM)写提示词而已。即便先进的 LLM 能生成文本、甚至生成代码,要编排一个完整的智能体系统,仍然需要一整套配套的框架与工具生态。在这篇文章中,我们将探讨开发者除了 LLM 本身之外还需要的关键组件——以便创建能够自主行动、与外部系统集成、记住信息、并在复杂环境中安全运行的 AI 智能体。我们将覆盖:为什么编排框架(如 LangChain)对工具集成至关重要;向量数据库在检索增强生成(RAG)与记忆中的作用;以及为什么需要 MCP 网关来管理多智能体通信、控制流与统一的工具访问。过程中,我们会介绍 Peta——它是一个将这些模块串联起来的平台示例,用来支撑稳健的智能体工作流;我们会聚焦它“能让什么成为可能”以及它“对开发者为何有用”,而不是把文章写成销售话术。
二、关键组件全景:编排框架、向量数据库/RAG、MCP 网关与 Peta 示例
1、编排框架:让工具使用与工作流集成成为可能
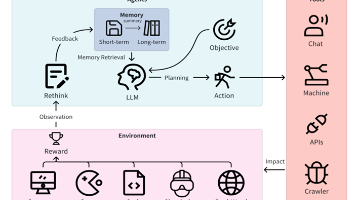
仅靠 LLM 是在真空中工作的——要构建一个能“做事”的智能体(检索数据、调用 API、执行代码等),你需要一个编排层。像 LangChain 这样的框架正是为此成为必备组件。以 LangChain 为例,它提供预构建的智能体架构,并几乎能与任何模型或外部工具集成,让开发者能够把 LLM 与现实世界的动作与数据源无缝连接起来。在实践中,这意味着你不必为智能体可能用到的每一次 API 调用或函数调用都手写定制逻辑,而可以利用 LangChain 的抽象(agents、tools、chains)来替你管理。此类框架承担了工具集成的重活:让智能体决定用哪个工具、何时使用;执行工具;并把结果送回模型的推理循环中。
为什么这个编排层如此重要?把它想成把 AI 的自然语言推理与具体操作连接起来的“胶水”。LLM 单靠自己可以判断它需要查找信息,但如果没有编排器,它并没有办法真的去做一次网页搜索或查询数据库。编排框架通过把模型的意图桥接到真实 API 与函数来填补这个缺口。它们也为多步骤工作流提供结构,使智能体能够把任务拆成子任务、按顺序或按条件调用工具、并在步骤之间保持状态。简言之,它们把一个孤立的 LLM 变成一个完整应用。正如一位编排领域专家所说:把复杂的多步骤问题交给单一智能体会撞上一个“复杂度天花板”——框架让我们能把多个专门化步骤(甚至多个智能体)组合起来,以突破这一限制。对开发者而言,使用成熟框架能省下巨量工作:你可以开箱即用地获得连接数据库、调用 Web 服务、解析输出、管理对话记忆等能力,而不必重复造轮子。
值得注意的是,LangChain 只是一个例子——其他如微软的 AutoGen、谷歌的智能体框架(ADK)、LangGraph 以及各类开源项目,也提供类似的编排能力。它们都服务于一个共同目标:协调 AI 模型、它的工具,以及用户目标之间的流程。借助这些框架,你可以把注意力放在智能体的高层逻辑上,而把工具使用、错误处理、动作链式执行这些“机械部分”交给框架。其结果是:比任何单一的 LLM 提示词都更具适应性、也更强大的智能体。
2、向量数据库与 RAG:赋予智能体记忆与知识
高效 AI 智能体的另一个支柱是记忆系统。现实任务往往需要超出单轮提示-回复的上下文——智能体可能需要回忆上周对话里的某个事实,或从外部语料库中提取领域知识。这正是向量数据库变得关键的地方。在现代智能体架构中,向量数据库(如 Pinecone、Weaviate、Qdrant)充当智能体的长期记忆与知识库。它们把信息存储为高维向量(embedding),这些向量表示内容的语义含义,而不是精确关键词。这使智能体能够进行语义搜索——按“意义”找到相关信息,即使措辞不同——也能做相似度匹配来检索上下文相关条目。实际上,向量存储让 AI 智能体以一种接近人类回忆的方式来记住与检索信息(按“意义”与联想来找东西)。
检索增强生成(Retrieval-Augmented Generation,RAG)在此基础上进一步放大智能体能力。使用 RAG 时,当智能体需要超出其内置知识的信息,它会查询向量数据库以检索相关文档或事实,并在生成回复之前把这些内容注入到 LLM 的上下文中。这种方法带来多个显著好处:它减少幻觉(回答可以被检索到的事实“落地”);提供更及时的信息(因为向量数据库可以持续更新最新数据);甚至能实现来源引用(因为智能体知道自己的回答引用了哪些文档)。根据 OpenAI 的说法,使用 RAG 来补充 LLM,相比单独使用模型可以将事实性错误降低最多约 30%——这能显著提升可靠性。
对开发者来说,实现 RAG 意味着你的智能体不再被训练数据或上下文窗口所限制。你可以把公司的文档或知识库放进向量数据库,当智能体收到查询时,它就能取回最相关的片段并纳入推理。这为智能体提供了一种长期记忆。事实上,复杂智能体常常区分短期记忆(最近对话或任务状态,可能保存在临时存储或内存中)与长期记忆(持久化的向量存储,累积知识)。向量数据库擅长后者——它们是 AI 记忆的骨干,使智能体能够跨会话维持上下文,并在过去交互的基础上持续构建能力。
当然,强记忆也意味着更大的责任:开发者必须考虑如何更新或裁剪向量记忆(避免知识变化引发语义漂移);如何处理隐私(长期存储用户数据会带来合规问题);以及如何确保检索结果相关(因为朴素语义搜索有时会检索到“擦边”的片段)。尽管如此,把 LLM 与高质量向量数据库结合,已经成为打造更博学、更具上下文意识、且更准确智能体的成熟配方——远胜过仅凭提示词。
3、MCP 网关:统一智能体、工具与外部系统
当你把更多工具、数据源、甚至多个智能体纳入 AI 系统时,会出现另一个挑战:如何可靠且安全地管理这些交互?这正是 MCP 网关(MCP Gateway)概念变得必要的地方。MCP 指 Model Context Protocol(模型上下文协议),它是一项新兴标准,用来定义 AI 智能体(作为客户端)如何以一致方式与工具或服务(作为服务器)通信——本质上是一种面向 AI 集成的“USB-C 接口”。MCP 网关是一种集中式基础设施组件,利用该协议把你的智能体通过一个统一接口连接到它们需要的外部 API、数据库与服务。
更直观地说,MCP 网关像是专为 AI 智能体打造的 API 网关,但它有重要差异。传统 API 网关通常是无状态路由器;相比之下,MCP 网关是有状态且会话感知的,专为 AI 工作流独特的双向通信模式而设计。它知道智能体可能会有多轮对话或多步骤的工具调用序列,并能在这些调用之间维持上下文(这是普通 HTTP 网关做不到的)。它不会让每个智能体直接与每个工具做集成(那很快会变成 N×M 的意大利面式混乱连接),而是把所有智能体-工具交互都汇聚到网关:网关再把请求安全地路由到合适的工具或服务,并把结果返回给智能体,同时沿途执行策略或做必要的变换。
为什么需要 MCP 网关?设想你有 N 个智能体与 M 个工具——如果没有网关,你潜在就需要构建并维护 N×M 个集成点,并且每个智能体都要分别处理每个工具的认证、错误处理与日志记录。这种“N×M 集成问题”会迅速变得不可控且高风险。每新增一个工具可能就要更新多个智能体;每新增一个智能体又会复制一套连接工具的重复代码。集中式网关通过作为单一集成枢纽来解决这一点:每个智能体只需与网关对话,网关再连接任意工具(因此新增一个工具只需更新网关一次,而不是更新每个智能体)。这大幅简化了智能体系统的开发与维护。
更进一步,MCP 网关还能开箱即用地提供关键的企业级收益。由于所有流量都通过同一个“卡口”,你可以实现集中式安全与治理——例如:在一个地方统一处理认证、API key、加密、限流与访问控制。智能体不再持有敏感凭据;网关可以代表智能体注入凭据(在 Peta 部分会展开),从而防止凭据蔓延或泄露。它也意味着你能获得统一可观测性:不必再从大量智能体与服务中拼凑日志,网关可以记录每一次请求与响应,提供跨工具的完整执行轨迹。开发与运维团队可以在一个地方监控时延、失败、使用模式,甚至做缓存以优化成本。事实上,对任何严肃的生产级 AI 智能体部署而言,MCP 网关都被视为“关键基础设施”,它充当控制平面来管理多工具系统的安全、监控与运维复杂度。
另一个优势是让智能体访问工具的方式保持一致。借助标准协议(MCP)与网关,你可以把智能体逻辑与外部 API 的细节解耦。智能体只需发起 MCP 调用(很多时候以自然语言形式表达意图),无需知道背后到底是调用 REST API、执行 SQL 查询还是触发云函数——网关负责翻译与执行。这让你的智能体更模块化,也更易扩展。它甚至为多智能体通信打开了空间:由于工具以统一方式暴露,一个智能体可以通过网关把另一个智能体当作“工具”来调用,从而在受控接口下实现智能体到智能体的协作。总之,MCP 网关提供了一张统一的“织物层”,把 AI 系统的所有部分(智能体、工具、数据)连接在一起,并以可扩展、可管理的方式运转。它是编排包含多个活动部件的复杂工作流的骨干,确保当你的智能体生态增长时,系统仍然安全、可观测、可维护,而不是堕入集成混乱。
4、Peta:面向智能体工作流与编排的一体化平台示例
为了让上述概念更具体,我们来看一个实践中如何把这些模块拼到一起的例子。Peta(peta.io)是一个体现我们讨论过许多理念的平台:它把编排、记忆集成、MCP 网关与工作流管理组合成一个连贯产品。它的目标不是再做一个框架或单点工具,而是为 AI 智能体提供端到端基础设施。它甚至把自己定位为“一套完整的 MCP 基础设施——网关、控制平面与桌面审批一体化”。换句话说,Peta 不只是连接 AI 与 API 的管道;它也是保护 secret 的 vault、管理与监控智能体的仪表板,甚至是人类监督智能体动作的前端界面。对那些在构建复杂智能体(例如访问敏感客户数据或执行关键操作)的开发者来说,Peta 提供了大量“缺失拼图”,用来安全、规模化地把系统跑起来。
**安全的工具访问与执行:**Peta 的核心是 Peta Core,它充当零信任的 MCP 网关与运行时。智能体对外部工具的每一次请求都必须经过 Peta Core,它会执行安全策略并处理凭据。值得注意的是,Peta 内置了加密的 secret vault(API key、token、密码等),并且只在需要时即时注入凭据。智能体本身永远看不到真实 secret;它拿到的只是临时 token 或句柄。比如智能体要访问数据库,它会通过 Peta 调用数据库工具——Peta Core 会从 vault 中取出数据库密码并附加到请求上,但智能体的提示词或记忆中不会出现该密码。这种设计确保即便智能体被攻破或日志被泄露,真实凭据也不会躺在对话记录里。这在防泄露与贯彻最小权限原则方面是巨大的收益。Peta Core 还会智能地管理工具连接器(MCP servers)的执行:当智能体需要时按需拉起连接器服务,空闲时再拆掉。这种弹性方式意味着你不必为几十个集成服务 24/7 常驻“以防万一”——Peta 可以维持 warm pool 或按需启动,从而可能显著降低基础设施成本(有案例在不常驻工具服务器的情况下实现了最高约 70% 的成本节省)。对开发者来说,这种动态编排是透明的——你只需调用工具,Peta 会确保连接器存在并按需扩展。
**集中控制与监控:**Peta 提供一个 Web Console 作为智能体的“指挥中心”。在这里,你可以注册与配置工具、设置集成,更关键的是定义策略与权限。你是否想强制某个智能体只能以只读方式使用 “GitHub” 工具?或要求智能体对生产数据库的任何操作都必须经过特别审批?Peta 的 Console 允许你更容易地实现这类细粒度访问控制(RBAC/ABAC)。你可以在一个地方管理 API 凭据,发放或撤销智能体访问 token,而无需改动智能体代码。Console 还提供实时可见性:你能看到每次工具调用的日志,跟踪使用指标(工具调用次数、时延、错误等),甚至设置预算或限流。所有智能体-工具交互都会以完整上下文写入防篡改的审计日志,这对调试与合规极其关键。比如某个智能体的一连串 API 调用导致了意外结果,你可以在 Console 里逐步追踪每一步,理解“为什么会这样”。在企业场景中,这些日志还能进入 SIEM 系统做安全监控;平台也被设计为帮助对齐合规标准(Peta 团队强调其特性面向 SOC 2、HIPAA、GDPR 等需求——因为企业必须证明他们能控制 AI 的行为)。本质上,Peta 把 AI 智能体当作需要和人类用户、微服务一样接受监督与治理的一等实体,并通过统一界面提供这套能力。
**人工在环与工作流管理:**Peta 的一个亮点是,它把人工审批工作流直接整合进智能体操作里。Peta 提供名为 Peta Desk 的桌面应用,主要有两个用途。第一,它让 AI 客户端连接 Peta 变得很简单——例如非技术用户安装 Peta Desk 后,它可以自动配置其 ChatGPT 界面通过 Peta 网关路由,并携带合适的凭据。这降低了最终用户使用“由安全基础设施支撑的智能体”的门槛(无需手动摆弄 JSON 配置或 API 端点)。第二,也是更重要的:Peta Desk 为实时审查与批准智能体动作提供 UI。你可以在 Peta 策略里把某些动作标记为“敏感”——例如智能体要给所有客户群发邮件,或要发起超过 1000 美元的退款。当智能体触发这些动作时,Peta 会暂停执行并标记为需要人工审批。相关负责人会在 Peta Desk(或集成渠道如 Slack、邮件)收到通知,看到请求动作细节:哪个智能体发起、动作是什么(如“向 John Doe 发起 1200 美元退款”)、可能还有原因或智能体的理由、以及必要数据(为隐私起见会遮蔽敏感信息)。人类可以点击 Approve 或 Deny。若批准,Peta 执行动作并告知智能体成功;若拒绝,Peta 告知智能体被阻止,智能体可优雅处理(比如道歉或升级给人工客服)。全过程端到端无缝发生,并被完整记录。这种人工在环能力对于“既要智能体效率、又要人类在高风险决策中保持判断权”的场景至关重要,它建立了信任:你的 AI 不会在没有人 sanity-check 的情况下抹库或花钱。本质上,Peta 让智能体能融入真实业务工作流:AI 做重活,但关键时刻让人类拍板。
**智能体间通信与多智能体生态:**由于 Peta 作为所有交互的集中枢纽,它也自然支持更复杂的多智能体生态。如果你有多个分工不同的智能体(比如“Analyzer”负责处理数据,“Reporter”负责对外汇报),它们都可以通过 Peta 接入。这意味着它们共享同一平台来交换信息或协调任务,同时 Peta 的日志会记录它们的相互协作。一个智能体的输出可以通过 Peta 存储(或缓存),另一个智能体之后按需获取。Peta 的设计甚至支持按需部署子智能体或特定工具的专用智能体——例如为某个工作流临时拉起一个专门子智能体——并置于主系统的统一管控之下。每个智能体都能被分配到受限权限,Peta 调解全部交互,避免冲突或未授权动作。实践中,这能给多智能体环境带来秩序:不是让智能体各自野蛮访问各种 API(可能互相踩踏或重复劳动),而是让所有流量经过受控网关流动。开发者既能获得模块化、专精化智能体的好处,又能维持整体系统的可监督性与一致性。
**结论:**面向 2026 及更远未来构建 AI 智能体的开发者,必须以“系统”而非“单一模型”的视角来思考。LLM 是强大的推理引擎,但要把它变成有效智能体,你需要周边框架:用于工具使用与工作流逻辑的编排;用于记忆与知识的向量存储;以及用于集成、安全与规模化的网关基础设施。像 LangChain 这样的框架降低了连接工具与构建多步骤推理链的门槛,让你不必把这些集成硬编码。向量数据库与 RAG 技术确保智能体能在正确时间拿到正确信息,并在短暂上下文窗口之外记住重要内容。而当你的智能体从玩具项目成长为拥有许多工具(甚至多个智能体协作)的关键系统时,MCP 网关会成为保持系统可管理、安全、可观测的关键支点。Peta 的例子展示了这些模块如何汇聚:一个平台可以编排复杂工作流、管理凭据与审批、并连接你需要的任何工具或 API——它实际上为 AI 智能体提供了“操作系统”。即便你不使用像 Peta 这样的全能产品,它所体现的原则也值得遵循:把 AI 智能体当作生产环境中的重要服务来对待——提供合适的基础设施、护栏与记忆。通过超越“只用 LLM”的范式、拥抱为智能体而生的框架、数据库与网关,你将能够构建不仅聪明,而且可执行、可靠、安全的 AI 系统。对开发者而言,这意味着从“玩提示词”走向“工程化解决方案”,真正把复杂任务在现实世界中卸载与自动化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)