开源微信公众号文章智能分类下载器(基于本地Ollama模型)
用户可以在页面配置公众号授权API、分类下载路径、Ollama服务、分类规则等,系统会调用Ollama服务配置的本地大模型,对选择的公众号的历史文章按照分类规则执行下载和分类任务,同时记录文章的标题、url链接等信息。
·
微信公众号文章智能分类下载器
用户可以在页面配置公众号授权API、分类下载路径、Ollama服务、分类规则等,系统会调用Ollama服务配置的本地大模型,对选择的公众号的历史文章按照分类规则执行下载和分类任务,同时记录文章的标题、url链接等信息。
项目链接
-
GitHub
环境要求
- Python 3.8+ (推荐 3.8-3.10)
- Ollama (确保启用服务并至少下载了一个以上的大模型)
安装和配置
1. 环境设置
# 创建conda环境 (推荐使用Python 3.8-3.10)
conda create -n wechat_downloader python=3.10 -y
# 激活环境
conda activate wechat_downloader
# 安装依赖
pip install -r requirements.txt
2. Ollama安装和配置
# 安装Ollama (访问 https://ollama.ai)
# 下载并安装适合的模型,例如:
ollama pull qwen3:8b
使用方法
启动服务
# 激活环境
conda activate wechat_downloader
# 启动Web服务
python src/app.py
访问 http://localhost:5000 打开Web界面
-
本项目的微信公众号下载功能调用的是“wechat-article-exporter”项目的API,该项目包含完善的微信公众号文章下载功能,如果仅需批量下载公众号文章,可以直接前往:公众号文章下载
-
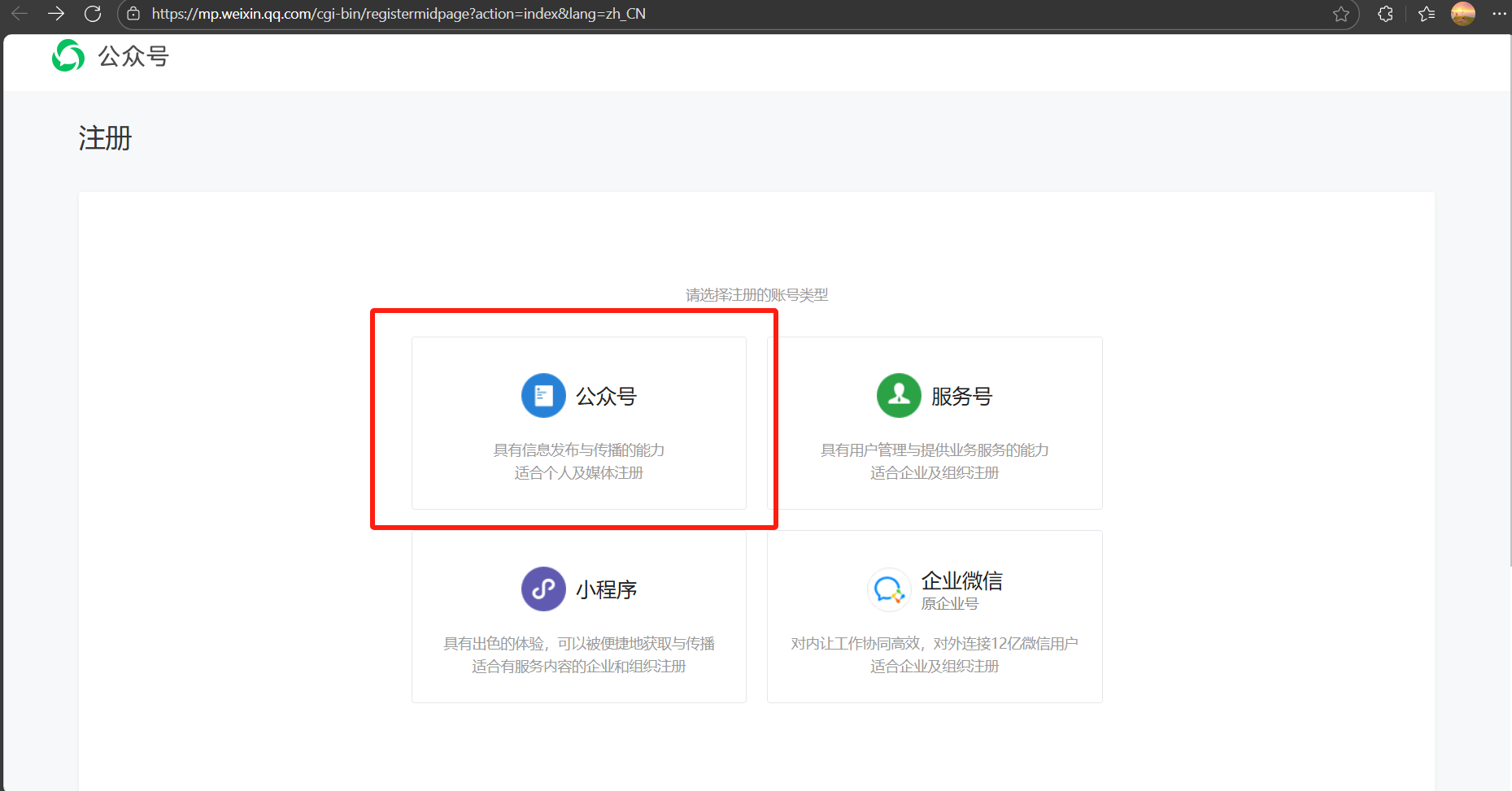
如果需要批量分类下载功能,请使用本项目,您需要先前往以下网址注册一个“微信公众账号”:https://mp.weixin.qq.com/cgi-bin/registermidpage?action=index&lang=zh_CN
- 注册完毕后前往以下地址点击“开始授权”扫码登录:https://exporter.wxdown.online/dashboard/api
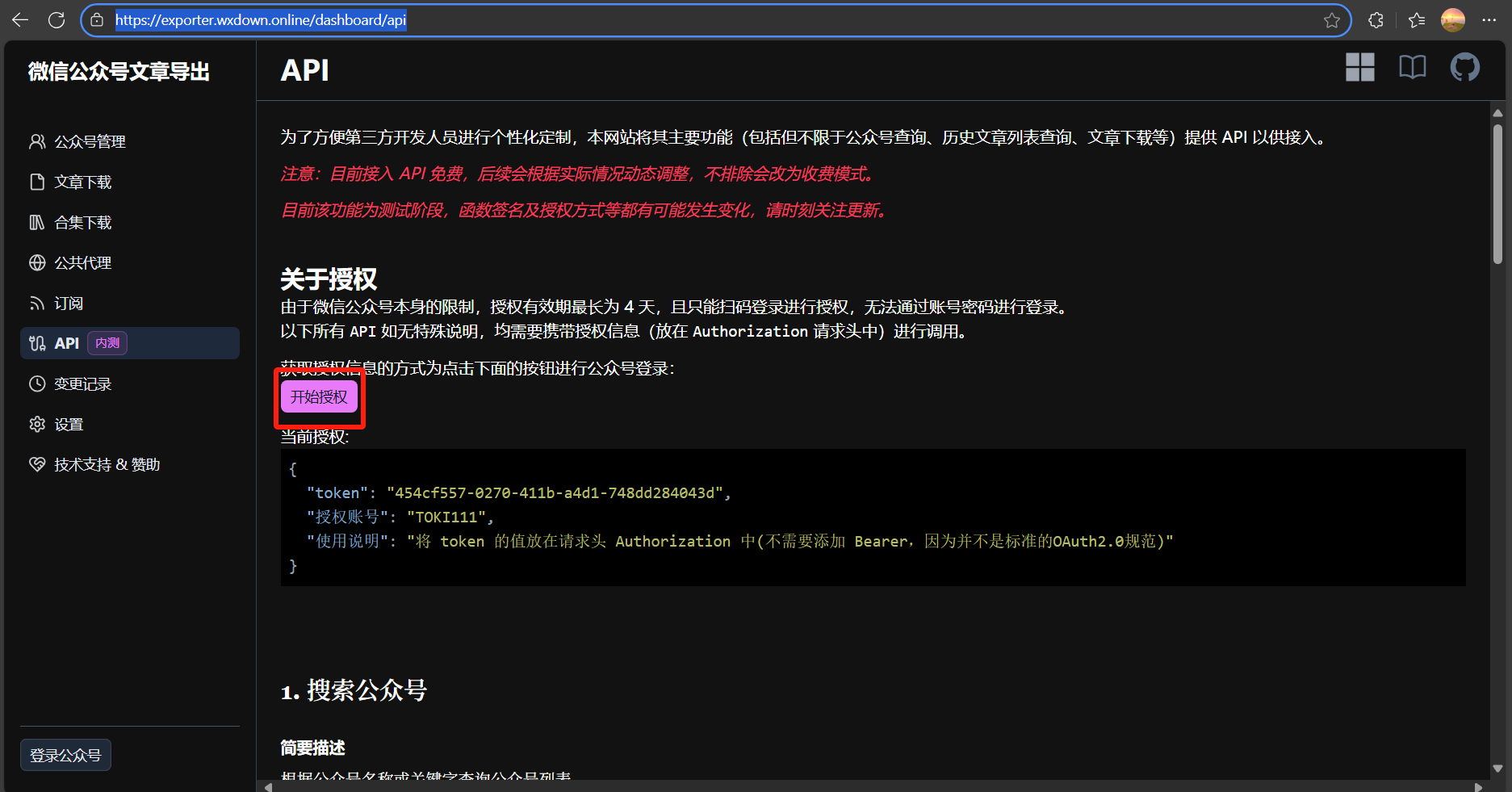
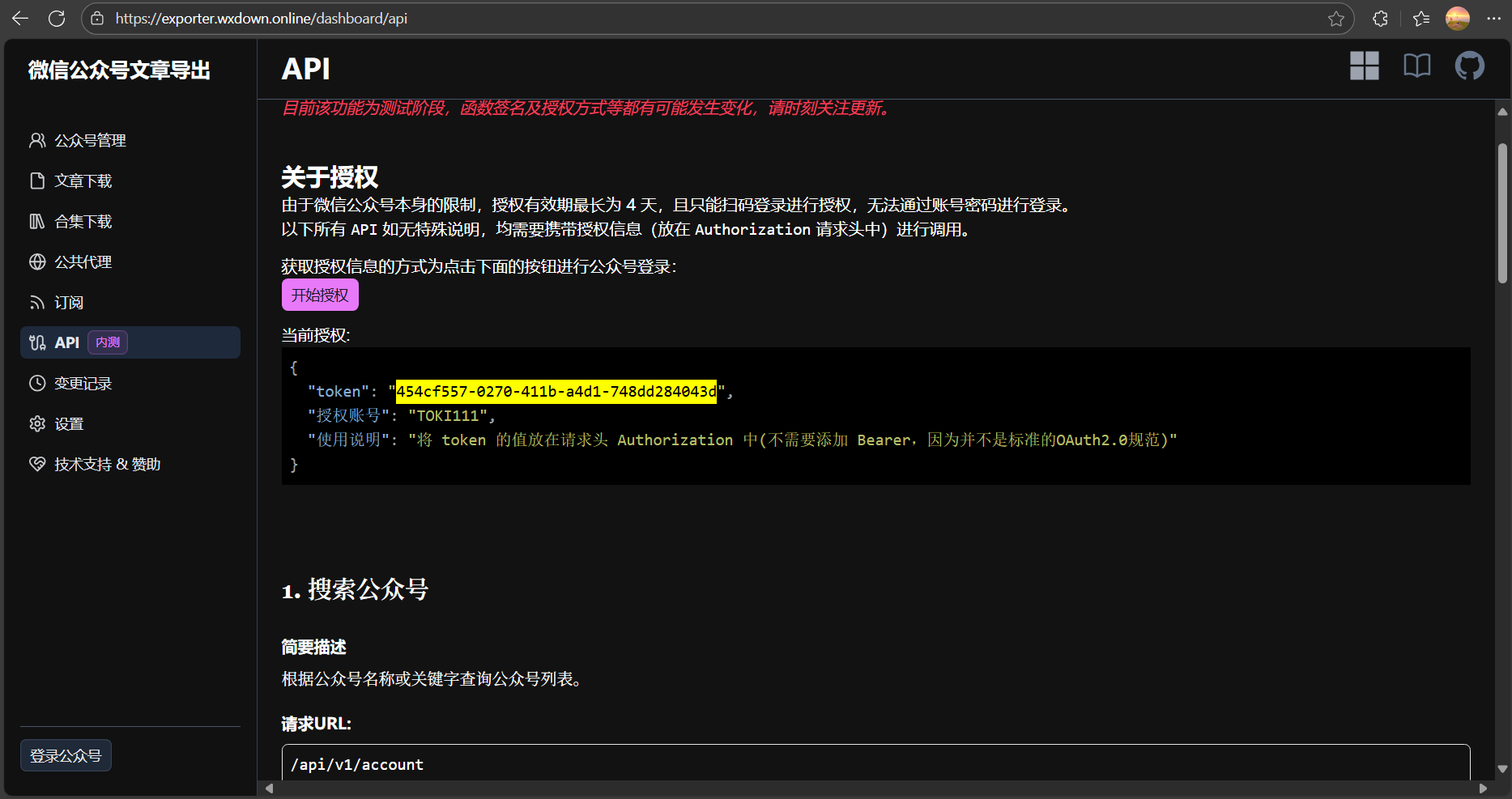
- 复制“token”
- 运行本项目的“app.py",等待程序完全启动后进入以下网址:http://localhost:5000/
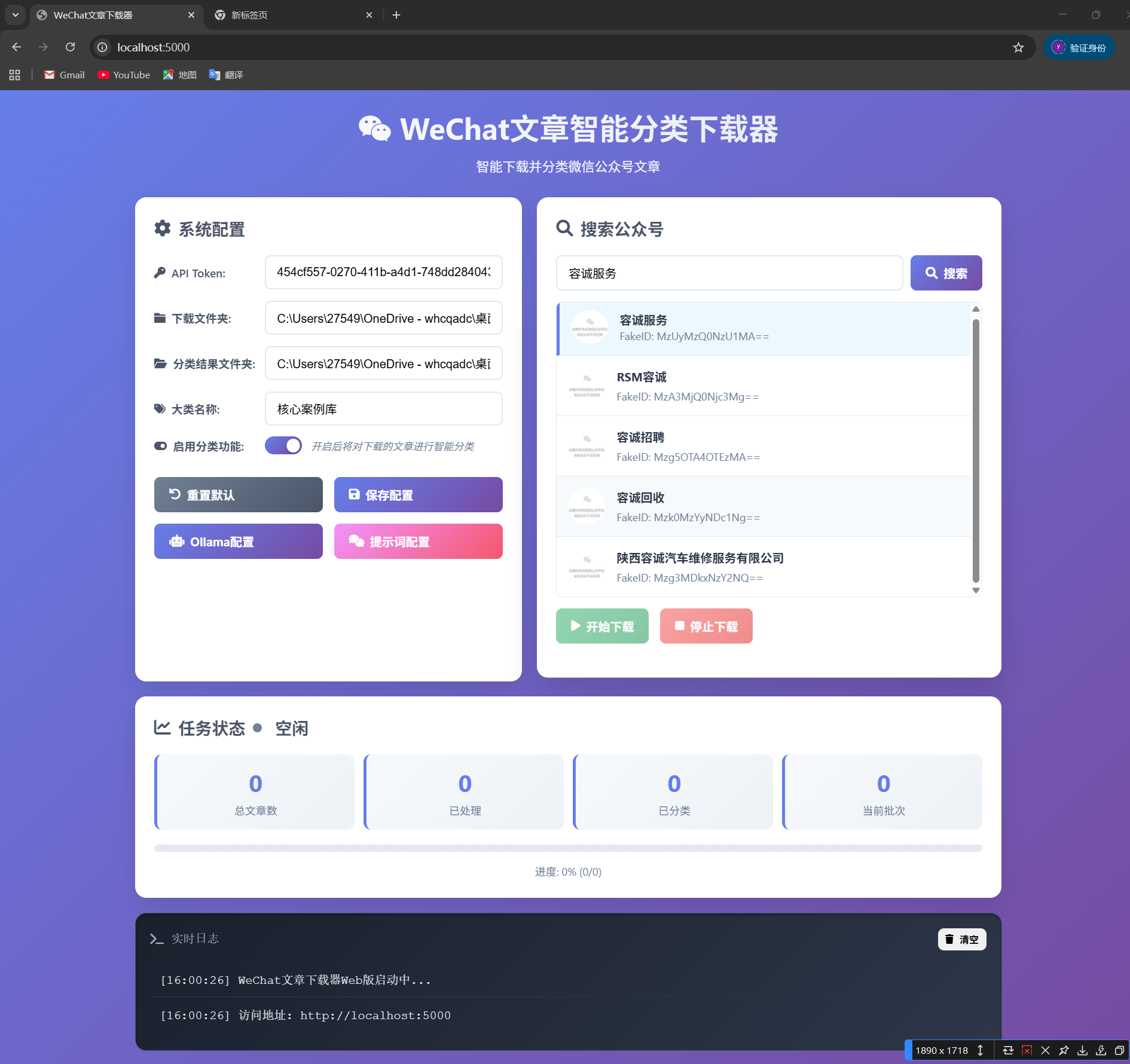
- 将前文扫码登录复制的“token”输入到本系统的“API Token”处。
- 直接下载:用户需要自定义“下载文件夹”路径,关闭“启用分类功能”,搜索并选择公众号,点击开始下载,系统会在“下载文件夹”路径下创建以公众号名称命名的文件夹,并批量下载其历史文章(HTML格式)转换成Markdown格式保存。
- 分类下载:完成上述操作后,打开“启用分类功能”,用户需要自定义“分类结果文件夹”和公众号所属“大类名称”。完成后进入“Ollama配置”:
- Ollama配置:用户需要在此处定义本地大模型相关配置参数,其中还包括输入模型的“最大摘要长度”(截取文章前多少字输入模型),以及文章“最小字符数阈值”(少于多少字符就过滤)。“最大摘要字符数”建议保持默认,过长的文章摘要可能导致模型对分类提示词不敏感。
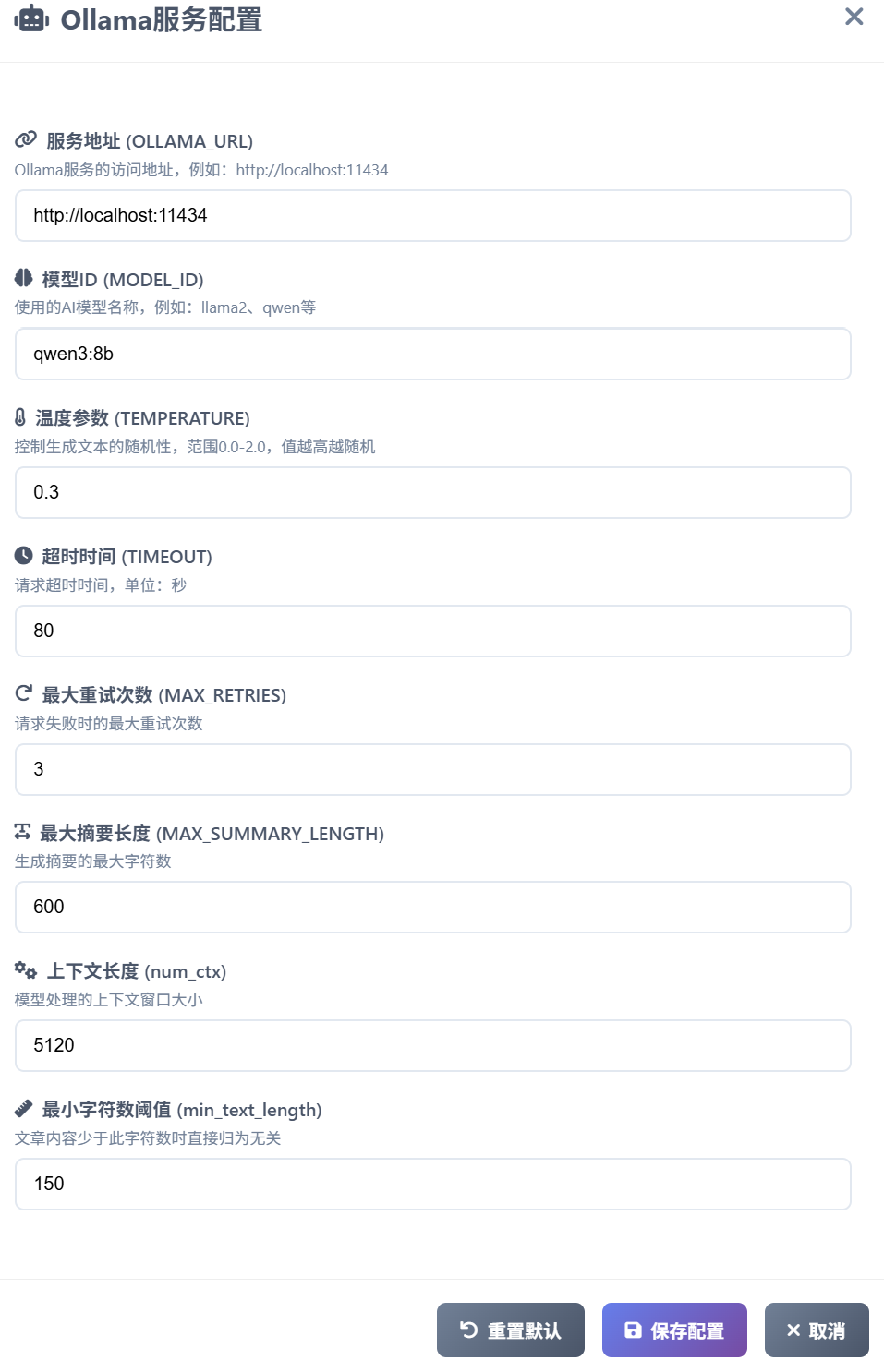
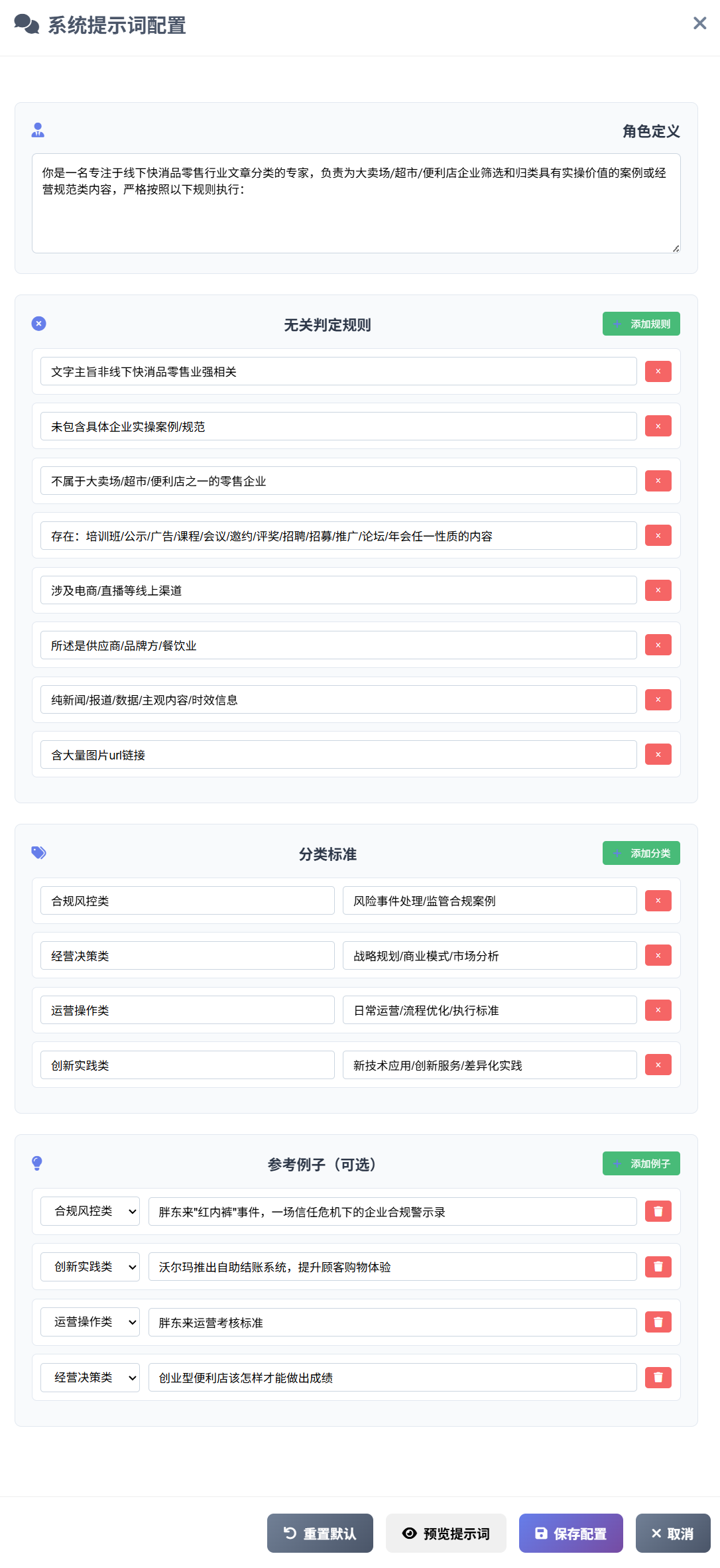
- 提示词配置:系统针对分类提示词做了标准化处理,在后端保存了通用的规则定义提示词。用户可以自定义角色、无关判定规则的数量和标准、分类类别的数量和标准(类别名称和描述),点击“预览提示词”系统会自动在后端拼接形成完整的分类提示词:

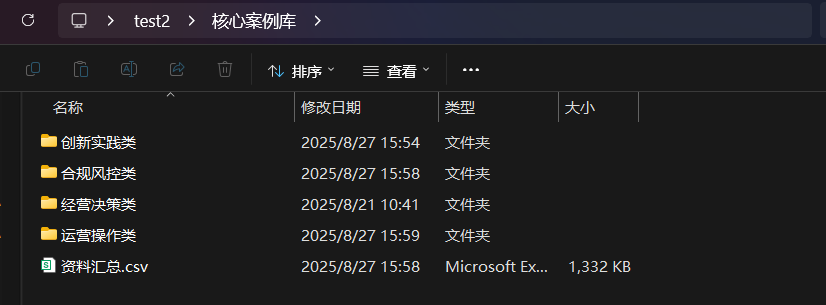
- 完成上述操作后,搜索并选择公众号,点击“开始下载”,系统会在用户定义的分类结果路径下创建“大类名称”文件夹,并在该文件夹中创建用户在 “分类标准”中定义的类别名称文件夹:
- 系统每下载一篇文章会自动转化成Markdown格式保存到“下载文件夹”并执行一次分类,若触发了“分类标准”,则复制到对应的分类文件夹。若触发“无关”则删除原文档。系统会分批次执行下载和分类,每批文章数量由wechat-article-exporter项目的api返回的结果决定(20-40篇不等)。每批次执行完成后,系统会将该批次的文章信息保存在该路径下创建的“资料汇总.csv”文档中,内容如下图所示:
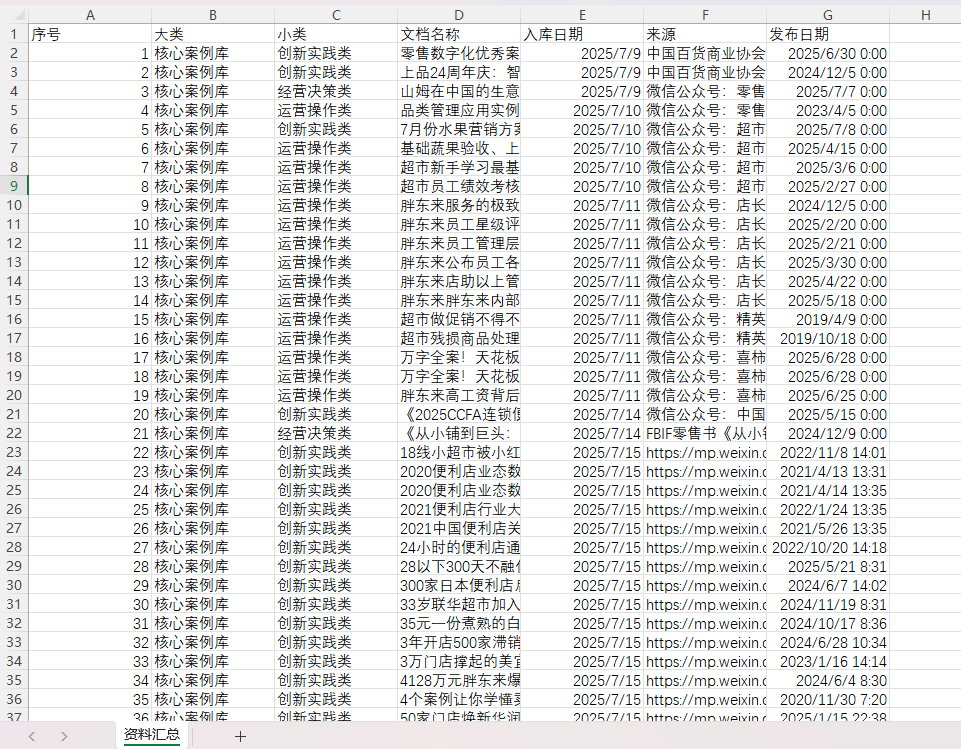
- 其中:“大类”的名称取决于用户在主页面定义的“大类名称”,“小类”的名称取决于用户在提示词配置中定义的“分类标准”的类别名称。
分类规则
系统默认是对线下快消品零售行业(大卖场/超市/便利店)的文章进行分类:
-
合规风控类: 风险事件处理、监管合规案例
-
经营决策类: 战略调整、发展经营决策案例
-
运营操作类: 标准化流程、执行细则
-
创新实践类: 新技术应用、商业模式创新案例
-
无关: 不符合行业要求或无实操价值的内容
-
可以按照需求在前端自行修改提示词配置和Ollama模型配置
技术架构
- 后端: Flask + SocketIO
- 前端: HTML5 + CSS3 + JavaScript
- AI分类: Ollama本地模型
- 数据处理: Pandas + BeautifulSoup
- 输出文件格式: Markdown、CSV
项目结构
Trae Project/
├── src/
│ ├── app.py # Flask Web应用主程序
│ ├── WeChat.py # 微信API接口和下载功能
│ ├── Classification.py # AI分类功能
│ ├── Remove.py # 文件清理工具
│ ├── config/ # 配置文件目录
│ │ ├── app_config.json
│ │ ├── ollama_config.json
│ │ └── prompt_config.json
│ └── templates/
│ └── index.html # Web界面模板
├── docs/ # 文档目录
├── requirements.txt # 项目依赖
└── README.md # 项目说明
配置文件
项目会自动创建配置文件:
src/config/app_config.json- 基础配置(API Token、文件夹路径)src/config/ollama_config.json- AI模型配置src/config/prompt_config.json- 分类提示词配置
注意事项
- 依赖版本兼容性: 最好按照README中的安装步骤执行
- Python版本: 推荐使用Python 3.8-3.10,避免使用过新或过旧的版本
- API权限: 确保拥有合法的微信文章下载API访问权限
- Ollama服务: 需要在本地运行Ollama服务(默认端口11434)
- 网络环境: 确保网络连接稳定,项目已配置禁用代理,避免触发限制导致下载失败
- 分类结果仅供参考,建议人工审核和筛选
- 本项目仅供学习和研究使用,不涉及任何商业用途
许可证
本项目仅供学习和研究使用,请遵守相关法律法规和平台使用条款。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)