从零解构Transformer:大模型到底是怎么训练与思考的?
在这个连街边大爷都在聊 DeepSeek 的时代,你肯定听过 Transformer 这个词。它是现代大语言模型的心脏,是目前人类创造出来的最接近“赛博魔法”的架构。但如果你去翻论文,迎面而来的就是各种极其反人类的矩阵公式。其实,剥开数学的外衣,它的底层逻辑不仅极其优雅,而且充满了人类社会的常识。今天咱们就搬个小板凳,从最底层的深度学习知识出发,一路推演到那些千亿参数的大模型到底是怎么运转的。
目录
💡 第四步:残差连接(Residual Connection)
引言:
在这个连街边大爷都在聊 ChatGPT 和 DeepSeek 的时代,你肯定听过 Transformer 这个词。它是现代大语言模型的心脏,是目前人类创造出来的最接近“赛博魔法”的架构。但如果你去翻论文,迎面而来的就是各种极其反人类的矩阵公式。其实,剥开数学的外衣,它的底层逻辑不仅极其优雅,而且充满了人类社会的常识。
今天咱们就搬个小板凳,从最底层的深度学习知识出发,一路推演到那些千亿参数的大模型到底是怎么运转的。
💡 第一步:大模型是如何“学习”的?
要理解高楼怎么盖,得先看看砖是怎么烧的。大模型之所以能拥有“智能”,并不是因为程序员在里面写了几亿个 if-else,而是靠深度学习中最核心的两个机制:损失函数(Loss)和反向传播(Backpropagation)。
你可以把刚出生的大模型想象成一个被蒙上眼睛、空降在连绵大山半山腰的盲人。它的目标是走到谷底,那个谷底就是错误率(Loss)最低的地方。一开始,模型脑子里的所有参数(也就是那些负责计算的矩阵)全都是随机生成的毫无意义的数字。当它用这些随机数字去预测“我吃”后面的词时,可能给出的答案是“石头”。这时候,系统就会啪地打它一下,告诉它错误率极高。

紧接着,微积分里的“导数”就派上用场了。模型虽然看不见,但它会用脚在周围探一探,也就是计算每个参数对当前错误率的“偏导数”。这就好比探明了前后左右哪个方向是下坡。
然后,一种叫“反向传播”的机制就像追责系统一样,顺着网络一层层倒推:刚才那个词预测错了,A矩阵要负30%的责任,B矩阵负70%。明确了责任和下坡的方向后,模型里的几千亿个参数就会同时、协同地朝着错误率下降的方向微微挪动一小步(这就是梯度下降)。
(注:这就是梯度下降的核心公式, 是参数,
是步伐大小/学习率,
是下坡的方向)
为了防止掉进半山腰的某个小坑里出不来,现代模型还会加上“动量”,就像推着铁球下山,靠惯性冲出局部陷阱(局部最优解)。经过几千万次这样的“试错、挨打、微调”,原本全是乱码的矩阵,就被硬生生逼出了规律,学会了人类的语言逻辑。
💡 第二步:Transformer的QKV 自注意力机制
搞懂了模型是怎么学习的,咱们终于可以推开 Transformer 的大门了。Transformer 里最名震江湖的招式,叫“QKV 自注意力机制”(Self-Attention)。
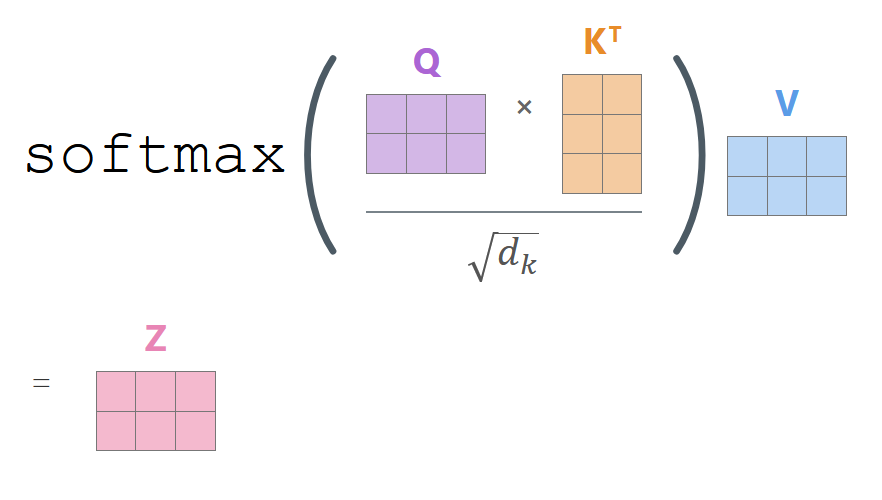
以前的 AI 读句子是一根筋,从左到右挨个看。而 Transformer 有上帝视角,它为了搞清楚一个词在具体语境里到底啥意思,玩了一手极其漂亮的“信息融合”。假设咱们输入了一句话:“我昨天买了一个苹果,它很甜。”当处理到“苹果”这个词时,模型其实不知道它是指手机还是水果。于是,词向量(比如一个1024维的数字)会分别乘上三个在训练中进化出来的不同矩阵,变身出三个分身矩阵:Q(Query查询)、K(Key键/标签)和 V(Value实际内容)。
QKV 三个矩阵并不是一开始就被赋予了灵魂,在模型刚刚开始训练的第一秒钟,Q、K、V 就只是三个装满了完全随机数字的矩阵。 它们根本不知道什么是“查询”,什么是“标签”,什么是“实际含义”。在经历几百万、几千万次的反向传播后,数学家和算法工程师们打开训练好的模型一看,发现:“哎?矩阵 1 总是倾向于提取词的缺失信息,矩阵 2 总是提取词的属性特征,矩阵 3 总是保留词的本体!”,于是,人类为了方便理解,给它们贴上了 Query、Key、Value 的标签。经过训练后的QKV 这三个分身的分工极其明确,用同一个词(比如“苹果”)通俗的话来讲他们的含义就像:
-
Q 就像是“苹果”举着牌子问:“我是宾语,谁是我的谓语动词?”
-
K 则是它贴在胸前的标签:“我是一个可食用的名词事物。“
-
V 则是这个词最原始的含义,就像打包好内容:[水果、甜、红色、圆形...])
补充一下,我们假设没有 Q 和 K,直接拿原始词向量 X 去点乘计算相似度,会发生什么? 数学上,向量 A 点乘向量 B,等于向量 B 点乘向量 A。这就是对称性。 这意味着在句子里,“苹果”对“吃”的注意力,会等于“吃”对“苹果”的注意力。
但人类的语言是不对称的! 在“我吃苹果”中:
-
“吃”(动词)非常需要寻找一个“苹果”(名词)来作为它的宾语,所以“吃”对“苹果”的关注度应该很高。
-
但“苹果”作为一个物品,它自己可能更关注形容它的词(比如“红色的苹果”),它对“吃”的关注度未必有那么高。
引入 Q 和 K 的本质,就是为了实现这种“不对称的指向性”:
-
Q 矩阵 :把词向量转换为“需求方/提问者”的角色。它提取的是这个词在当前语境下“缺什么信息”。
-
K 矩阵 :把词向量转换为“供应方/标签”的角色。它提取的是这个词“能为别人提供什么线索”。
因为 Q 和 K 是通过两套不同矩阵算出来的,这就完美模拟了语言中复杂的、单向的依赖关系。
但是,点乘算出来的分数往往会大得离谱,如果不加控制,后面的计算就会全部崩溃,出现“梯度消失”,导致模型死掉。所以工程师加了一个极其关键的工程补丁:把得分除以 (维度大小的平方根)。把膨胀的分数强行压缩回平稳范围后,再交给一个叫 Softmax 的函数去分配百分比权重。
(注:这就是 Transformer 最著名的自注意力公式,完美用数学表达了“吸收信息”的过程)
还是拿“我昨天买了一个苹果,它很甜。”举例,比如针对“它”这个词,Softmax 算出的权重可能是:苹果(0.7) + 甜(0.2) + 买(0.08) + 其他(0.02)。最后,拿着这些权重比例,去吸收对应词的 V(实际含义)。一通操作下来,“它”就不再是个空洞的代词,而是一个吸饱了全句上下文精华的“增强版词汇”。
💡 第三步:前馈神经网络(FFN)
从注意力层(Attention)开完“情报交流大会”出来后,每个词都带着一身别人的特征。但这还不够,它得把这些情报消化成自己的逻辑。于是,它走进了第二站:前馈神经网络(FFN)。这是一个经典的、带有非线性激活函数(比如 ReLU 或 GELU)的两层全连接神经网络。
什么是“非线性激活函数”?
如果在 FFN(前馈神经网络)里没有“非线性激活函数”,那么你堆叠 100 层 Transformer 也是白费力气,它会退化成一个单层模型。为什么?
先理解什么是“线性(Linear)”
在 Attention 里面用到的所有矩阵乘法(比如乘 QKV 矩阵),都是线性运算。 线性运算的本质就是“按比例缩放”和“相加”。数学上的公式是简单的 y=Wx+b。
-
线性的致命缺陷:如果你把几个线性操作套娃在一起,比如 y=
(
(
)),根据简单的代数结合律,它在数学上等价于 y=(
-
也就是说,三个矩阵乘在一起,其实等于一个全新的大矩阵。你串行堆叠 100 层线性网络,在数学上等同于只算了一层!它永远只能画出“直线”,无法理解世界上复杂的“转折”和“条件”。
为了让网络真正具备一层一层叠加深度的能力,数学家在每一层中间,强行插入了一个“非线性激活函数(Non-linear Activation Function)”。
它最经典的代表叫 ReLU(Rectified Linear Unit),它的逻辑简单得让人难以置信:
用大白话翻译就是:如果算出来的数字大于 0,就原样保留;如果小于 0,就直接变成 0。
现在的 Transformer 模型常用的是它更平滑的高级版本:GELU(高斯误差线性单元),但核心思想是一样的。
FFN(前馈神经网络)其实是一个“三明治结构”。激活函数只是夹在中间的那层“肉”,它的上下两面,是两块巨大的全连接矩阵(Linear 线性映射)。
在数学上,FFN 的完整公式是这样的:
你看,这里面有三个动作:
-
第一步:升维投影(乘矩阵
- 第 1 个新维度:它可能提取了
0.5 * 红色特征 + 0.8 * 甜味特征 + 0.9 * 水果特征。这个新维度代表了一个极度具体的概念:“熟透的红苹果”。 - 第 2 个新维度:它提取了
0.9 * 科技感特征 + 0.7 * 昂贵特征 - 1.0 * 水果特征(减号代表排斥)。这个新维度代表了:“高科技数码产品”。
- 第 1 个新维度:它可能提取了
-
第二步:逻辑过滤(ReLU 激活函数 max(0,...)) 这就是那堆非线性激活函数出场的地方。它对刚才展开的 4096 个维度,挨个进行审视:小于 0 的直接掐断变成 0,大于 0 的保留。
-
第三步:降维重组(乘矩阵
现在让我们用一个生动的例子来看看这个机制是如何运作的。假设现在输入的句子是:“苹果公司发布了新手机。”
当“苹果”这个词经过 Attention 层和别人的交流后,带着一身的情报进入了 FFN 层:
-
特征展开(W1 矩阵的作用): 矩阵 W1 经过训练,它的 4096 个维度就像 4096 个探测器。
-
第 50 号维度专门探测“是不是水果”。
-
第 800 号维度专门探测“是不是科技公司”。 此时,W1 结合上下文(比如看到了后面的“手机”,经过Attention层的处理,“苹果”的向量已经混入了“手机”的上下文特征),计算出:水果特征得分是
-5.2,科技公司特征得分是+8.5。
-
-
特征开关(ReLU 的作用): ReLU 开始工作了。
-
它看到第 50 维(水果特征)是
-5.2。ReLU 毫不犹豫:变成 0! (直接把“水果”这个概念从这个词的脑海里彻底抹杀,斩断了后续所有关于吃、酸甜的联想)。 -
它看到第 800 维(公司特征)是
+8.5。ReLU 说:保留 8.5!(激活了这个特征)。
-
-
逻辑的形成: 看到了吗?虽然 ReLU 只是简单的“遇负变零”,但它完美实现了一个高级的业务逻辑:“在这个语境下,屏蔽掉苹果的物理属性,只保留它的商业属性。”
如果你只有一个 ReLU,它确实什么都干不了。
但在大模型里,单层就有 4096 个这样的开关在同时运作,而模型有整整 100 层!
上百亿个这样的开关互相交织,有的负责屏蔽词性,有的负责反转情感,有的负责阻断语法错误。亿万个微小的“If-Else”叠加在一起,就涌现出了我们在 ChatGPT 身上看到的“逻辑推理能力”和“常识”。
打个比方,人脑里的单个神经元也只是简单地决定“放电”或“不放电”(类似 1 或 0),但几百亿个神经元连在一起,就能写出《红楼梦》,就能理解微积分。在Transformer中,Attention 负责把别人的信息拉过来,而 FFN(配合 ReLU)负责对这些信息进行果断的“取舍”和“提纯”。神经网络完美模拟了这种生物学奇迹。
一次 Attention 加上一次 FFN,算是一次完整的思考。但在大模型里,这种流水线要串行堆叠走上 100 层左右!每走一层,抽象程度就高一分。这种层层递进的抽象过程,导致我们难以直观理解中间每一层具体在做什么,这也是当下大模型可解释性差的核心原因。
💡 第四步:残差连接(Residual Connection)
这里就出了个要命的问题。如果你玩过100个人的“传话游戏”,就知道第一人说的“苹果”,传到最后可能变成了“宇宙”。在数十层 Attention + FFN 疯狂的升维度、降维、激活、抹杀过程中,模型很容易患上“失忆症”,忘了自己最初到底是个什么词。
例如模型在第 99 层的时候,突然遇到一个需要用到“苹果是水果”这个最基础物理属性的任务,它会发现:完蛋了,这个基础属性在第 30 层的某个 ReLU 里,已经被不小心变成 0(砍掉)了! 模型彻底“失忆”了。
在深度学习中,这叫“网络退化”和“梯度消失”。曾经,科学家们发现神经网络只要超过 20 层,越往下练,模型就越傻。
2015 年,微软研究院的何恺明(也就是后来 ResNet 的发明者)提出了一个极其天才、却又极其简单的解决方案:既然前面的层可能会把信息搞砸,那我就保留一条“直达通道”。在 Transformer 里,无论是 Attention 层还是 FFN 层,在输出最终结果之前,都会强制做一个加法:
也就是在每一层输出极其复杂的加工信息 之前,强行加上没加工前最原始的自己
。
没有残差连接时,每一层都在试图重新描绘整个世界,这太难了。有了残差连接后,每一层(F(x))的任务变了:它不再需要记住“苹果”长什么样,它只需要计算“当前的苹果,相比于上一层的苹果,还需要增加或删减什么细节?”(这就是“残差”这个词的由来,它只计算变化量)。
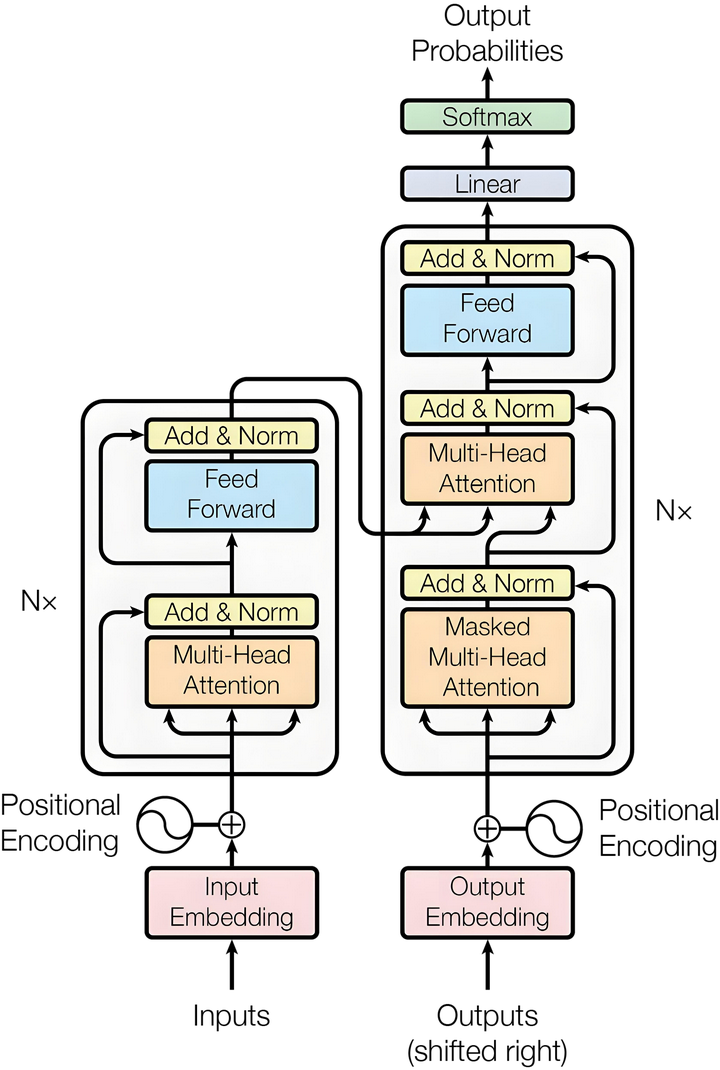
如果你现在去看那张著名的 Transformer 架构图,你会发现它的每一个 Attention 模块和 FFN 模块后面,都跟着一个黄色的框,上面写着:Add & Norm。
-
Add(加法):就是我们刚刚讲的残差连接(保住初心)。
-
Norm(归一化):就是把加完之后的数字,重新拉回到一个健康的比例范围内(防止数字越加越大,导致计算机溢出)。
总结我们的 Transformer 探秘之旅:
一个词(比如“苹果”),从进入 Transformer 的那一刻起,经历了怎样壮阔的旅行?
-
它先变成 1024 维的数字向量。
-
走进 Attention 模块,化身 QKV,和其他词开会,通过点乘评估缘分,通过 Softmax 分配注意力,融合全局语境。
-
走出来时,立刻和一个“残差连接”相加,保住自己的本体记忆,并进行一次 Norm 归一化整理着装。
-
接着走进 FFN 模块,被庞大的矩阵升维展开,被无数个 ReLU 开关进行严苛的逻辑过滤和折叠,提取出极度抽象的推理特征,然后再降维。
-
走出来时,再次和进入 FFN 前的自己做一个“残差连接”加法,稳固住刚刚顿悟的逻辑。
-
以上流程,完美无瑕地循环 100 次。
这就是大模型“思考”的全过程!它没有任何魔法,只有极其精妙的矩阵空间变换、冷酷的非线性开关,以及保障底线的残差加法。
💡 第五步:预训练与微调
带着这套完美的架构,大模型是怎么被喂出来的呢?这其实是一场极其漫长且昂贵的教育。
第一阶段叫“预训练”,就是填鸭式的“读万卷书”。这个阶段占据了 99% 的算力和时间。大批大批的互联网网页、书籍、维基百科和代码(通常高达数万亿个 Token)统统无脑往里倒,模型的任务只有一个:预测下一个词。为了能准确预测出“水往___流”的下一个词是“低处”,它被迫学会了物理常识;为了预测代码的下一个字符,它被迫学会了编程逻辑和语法。人类世界的知识体系,就这样被强行压缩到了千亿个矩阵参数中。
预训练出来的模型是个“书呆子”,你问它“怎么炒西红柿鸡蛋”,它可能会接着你的话补充“怎么炒青椒肉丝”,因为它以为你在写一本菜谱大全。所以必须进入第二阶段,让模型学懂规矩。
第二阶段:对齐与微调(SFT)和强化学习(RLHF)。此时需要极其高质量的人工标注数据人类准备了几万到几十万道极高质量的问答对,教会模型“我是个助手,我要回答问题,而不是续写文本”,同时通过人类反馈的强化学习(RLHF),让模型学会什么话该说,什么话(如脏话、危险言论)不能说。
蒸馏技术(Knowledge Distillation)。以前在小模型时代(比如 BERT 时代),“蒸馏”是很底层的数学操作:让学生模型(小)去模仿老师模型(大)输出的“概率分布(Soft Labels)”。 但在今天的大语言模型时代,蒸馏的逻辑变得极其直观,我们给Deepseek-R1输入几百万道极其复杂的逻辑题、代码题、伦理问答题,让它不仅给出答案,还要写出详细的思考过程。用大模型生成的极其详细的“思考过程”。接着,我们把这几百万条高质量的“问答对”和“思考过程”,作为教科书,拿去微调(SFT)一个只有 7B(70亿)参数的开源小模型。小模型原本可能连话都说不利索,但死记硬背了超级大模型几百万次的推理解答后,它突然“顿悟”了,学习到了超级大模型输出的概率分布。它不仅学会了怎么礼貌回答,甚至学会了超级大模型那种“一步步拆解问题”的逻辑推理能力。
所以,现在的蒸馏,本质上就是“用大模型生成的超级高质量的对话/推理数据,去取代极其昂贵的人工标注,在微调阶段把小模型喂出来”。
💡 第六步:自回归生成机制KV Cache机制
历经九九八十一难,大模型终于上线为你服务了。
在大模型的世界里,训练(Training)和推理(Inference)最大的区别在于:训练是“正着走一遍(预测),再反着走一遍(更新参数)”;而推理是“只正着走,不更新任何参数”。
但推理的计算量依然庞大得令人发指,这全是因为大模型特有的“打字机模式(自回归生成机制)”。我们来拆解一下,当你向 ChatGPT 发送一句话时,它的 100 层到底是怎么疯狂运转的:
当你输入提示词(Prompt):“苹果很” 时: 这三个字(或者说 Token)会作为一个整体,手牵着手进入 Transformer。 它们要老老实实地走过第 1 层的 Attention 开会、FFN 消化,然后进入第 2 层……一直走到第 100 层。 在第 100 层的出口,模型融合了所有的逻辑,预测出下一个概率最高的字是:“甜”。
生成了“甜”字,任务结束了吗?没有!如果你要求模型写一篇 1000 字的文章,这才是噩梦的开始。
为了生成下一个字,模型会把刚刚吐出来的“甜”字,拼接到原来的句子里,变成新的输入:“苹果很甜”。 然后,把这四个字重新塞回第 1 层,再次完整地走完 100 层! 走完后,预测出下一个字:“。”(句号)。 接着,变成“苹果很甜。”,再次从第 1 层走到第 100 层……
你看懂这个恐怖的逻辑了吗? 如果你让大模型写一篇 1000 字的文章,它不是走一次 100 层,而是把这 100 层反反复复地走了 1000 遍! 每生成一个字,都要把前面所有的上下文带上,从头再通关一次。这就是为什么大模型推理极其烧钱、而且生成速度是一个字一个字往外蹦的原因。
如果你是一个极其敏锐的人,听到上面的流程肯定会掀桌子:“这也太蠢了吧!‘苹果很’这三个字刚刚明明已经走过 100 层了,为什么生成下一个字的时候,还要带着它们从头再算一遍?”
科学家们也是这么想的。所以,他们在推理阶段引入了一个极其伟大的工程发明,叫 KV Cache(键值缓存)。
这是推理阶段独有的作弊技巧:
-
当“苹果很”第一次走过 100 层时,模型会把它们在每一层算出来的 K 矩阵(线索标签) 和 V 矩阵(实际内容),统统存进显卡的内存里(Cache)。
-
当新生成的“甜”字进入网络时,它不需要拉着前面的兄弟们重新算一遍。
-
“甜”字只需要自己孤身一人走进第 1 层,算出一个属于自己的 Q(查询向量)。然后,它直接去显存里查表,用自己的 Q 去匹配之前存好的“苹果很”的 K 和 V。
-
就这样,“甜”字自己一个人拿着 Q 走完了 100 层,而前面的词静静地躺在缓存里当“资料库”。
现在很多大模型 API(比如 Anthropic 的 Claude 4.6、OpenAI 的 GPT-5.2、DeepSeek-V3.2等)推出的“提示词缓存命中(Prompt Caching)”功能,它在底层卖的,就是我们刚刚聊的 KV Cache!
我们可以把大模型的算账逻辑拆开,看看为什么“命中缓存”能便宜那么多(通常会打个半折,甚至便宜 90%):
预填充:
假设你给某个模型的 API 发送了一本 10 万字的小说,加上一句提问:“主角最后死了吗?”
-
云端计算:此时服务器的 GPU 没有任何关于这本小说的记忆。它必须把这 10 万个词老老实实地拉进 Transformer,走完那极其庞大、充满几千亿次矩阵乘法的 100 层迷宫,一层一层地把这 10 万个词的 K 矩阵和 V 矩阵算出来。
-
计费逻辑:这个过程极其消耗算力(烧电、占显卡时间)。在工程上,这叫 Prefill(预填充) 阶段。因为模型付出了巨大的算力劳动,所以这部分的 Token 计费非常昂贵。
缓存命中:
现在,你紧接着又发了一条请求:“主角的师傅是谁?”(注意,前面那 10 万字的小说还是作为背景发了过去)。
-
云端计算:API 厂商的服务器非常聪明,它在内存里一对比,发现:“这 10 万字的小说,这哥们儿(或者别的用户)5 分钟前刚刚算过!这 10 万个词走完 100 层的 KV Cache 还在我的服务器硬盘/显存里躺着呢!”
-
跳过计算:服务器直接把算好的 KV Cache 调出来。GPU 完全不需要再去算那 10 万字的注意力矩阵了,它只需要单独把“主角的师傅是谁?”这 7 个字放进 100 层里,去和已经存好的 KV Cache 查表匹配就行了。
-
计费逻辑:既然省下了 99% 的算力计算(只消耗了读取内存的 I/O 带宽),那成本自然直线下降。所以 API 厂商就会给你一个极其良心的“缓存命中价(Cached Token Price)”。
这也是为什么现在很多 AI 程序员在写代码、做系统提示词时,会严格遵守一个“静态内容放前面,动态内容放最后”的原则:
-
他们会把几万字的 API 文档、几十条严格的系统规则,钉在对话的最上面(系统提示词)。
-
只要这部分前缀(Prefix)一个字都不改,大模型就会一直保留这部分的 KV Cache。
-
以后每次提问,哪怕带了几万字的背景,只要前面一模一样,就只收极低的缓存费。
代价是什么? 显存爆炸!大模型推理时,一多半的显卡内存不是用来装模型的权重(那些固定的 100 层 QKV 矩阵),而是用来临时存放这段对话里所有词的 KV 缓存。如果你给模型发了一篇 10 万字的长文,它光是存这些 KV Cache,就能瞬间把几张极其昂贵的 A100 显卡撑爆。
另外做一个小科普
如果你本地部署过一些小参数量的模型,在使用他们时,有时甚至会出现模型死循环的输出一句话,这是为什么呢?
根本原因在于大语言模型的“自回归生成机制(Autoregressive Generation)”和“概率坍缩”,模型生成文本是一步一步来的。它输出第一个词后,会把这个词塞回输入里,去预测第二个词。 比如现在的上下文是:[我, 昨天, 买, 了, 一个]。 模型预测下一个概率最高的词是:[苹果]。
当模型生成了 [苹果] 后,上下文变成了 [我, 昨天, 买, 了, 一个, 苹果]。 此时它需要预测下一个词。如果是一个参数量较小、训练不充分的模型,它的“长上下文掌控力”很弱。它可能只盯着最近的几个词 [一个, 苹果] 看,觉得接 [很甜] 的概率是 30%,接 [的, 苹果] 的概率是 40%。 如果它采用的是“贪心搜索(永远选概率最高的那个词)”,它就会输出 [的],接着又输出 [苹果]。
一旦变成了 [我, 昨天, 买, 了, 一个, 苹果, 的, 苹果],这个奇怪的句式在模型的概率分布里可能形成了一个死结。它再往下预测时,发现紧跟着 [的, 苹果] 后面最合理的词居然又是 [的, 苹果]。 于是,因为缺乏足够的参数容量去统筹全局,加上死板的解码策略,模型掉进了一个“概率的死胡同”,不断重复输出概率最高的局部词汇,这就是复读机现象的本质。
💡 第七步:模型温度(Temperature参数)
当历经100层、无数次查表后,来到大漏斗的最底端,模型手里依然只是一串毫无感情的浮点数。这时候,最后一个魔法“ Temperature(温度参数)”登场了。
模型会把这串数字转化为人类字典里所有汉字的概率分布。默认情况下,模型倾向于选概率最高的那个字。但是,如果你在应用调高 Temperature 的数值(比如调到 0.8)。
(注:T 即 Temperature,当 T 变大时,原本悬殊的概率分布会变得平缓,小概率词也有机会被抽中)
假设某段话中,原本选中概率只有 5% 的“脆”字,此时就会被拉高选中概率。于是,模型的话语变得更加灵动、更具创造力;反之,如果把温度降到极低,模型就会变成一个滴水不漏、极其严谨的答题机器。
结语:没有魔法,只有工程奇迹
这就是现代 Transformer 架构下大模型的全部生命历程。从随机初始化的混沌探索,到QKV机制的精准聚焦;从FFN的逻辑筛选,到残差连接的稳定保障;最后在预训练的洗礼和自回归的苦力活中,用一个温度参数为你呈现出屏幕上那一句句有温度的回答。没有任何魔法,有的只是极其精妙的数学美感,和无数工程师踩过无数坑后垒起的工程奇迹。
你看,这台世界上最复杂的内燃机,是不是也没有想象中那么神秘了?如果你以后在用 AI 写作或者敲代码时遇到它“胡言乱语”,不妨想象一下,可能是它在第 75 层的某个 ReLU 开关没接上,或者是温度参数太高让它热得有点晕了?这套逻辑,还有什么让你觉得意犹未尽的地方吗?我们可以在评论区深入聊聊!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)