qKnow 知识平台核心能力解析 | 第 05 期:知识融合能力,让知识更准确、更简洁、更可信
本文解析qKnow知识平台核心能力之知识融合。该能力利用大模型语义理解,智能识别多源重复实体,构建“AI识别+人工把关”协同模式。核心功能包括实体归一化,统一别名与歧义;提供智能融合(人工确认)与自动融合(阈值对齐)双模式,支持属性时间优先级策略。系统每日全量扫描生成任务,提供详细决策依据,并实现全流程可追溯、可回滚,确保知识图谱准确、简洁且高效治理。
大家好!欢迎来到 qKnow 知识平台核心能力解析 系列的第 05 期。
在构建企业级知识图谱的过程中,多源异构数据带来的“脏、乱、杂”问题往往是最大的拦路虎。同一实体在不同系统中有着不同的写法、别名甚至冲突的属性,这不仅导致数据冗余,更严重影响知识检索的准确率。
今天,我们将深入解析 qKnow 平台的知识融合能力,看它如何利用大模型语义理解优势,通过“AI 识别 + 人工把关”的协同模式,打造准确、简洁、可追溯的高质量知识图谱。
🚀 核心亮点:大模型驱动的语义理解
传统的知识融合往往依赖严格的规则匹配,难以应对复杂的语义歧义。qKnow 引入了大模型语义理解技术,能够智能识别多源知识中重复或近似的实体与关系。
系统不仅能精准标记疑似冗余项,还能辅助人工进行高效判断与确认。这种“机器初筛、人工复核”的协同治理模式,既保证了处理效率,又确保了最终结果的准确性。
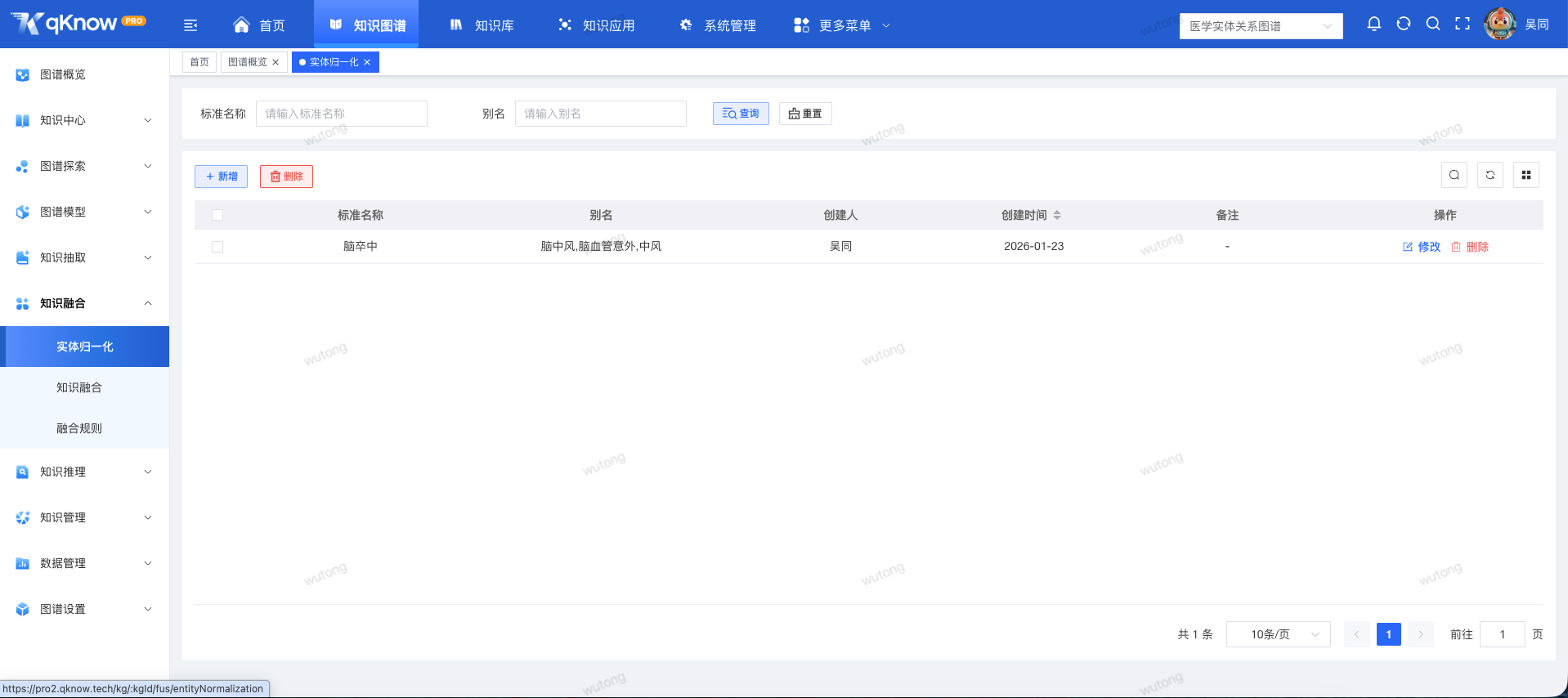
🔑 关键能力一:实体归一化
实体归一化是知识融合的基石。它的核心目标是将不同来源、不同写法、别名、简称或存在歧义的同一实体,统一映射到一个标准、唯一的规范实体上。
- 解决痛点:数据不一致、实体重复、语义歧义。
- 核心价值:让数据更干净、统一,为后续的知识融合、高精度检索及上层应用打下坚实基础。
场景示例:将“腾讯”、“Tencent”、“腾讯科技”、“鹅厂”自动识别并统一映射为标准实体“腾讯控股有限公司”。
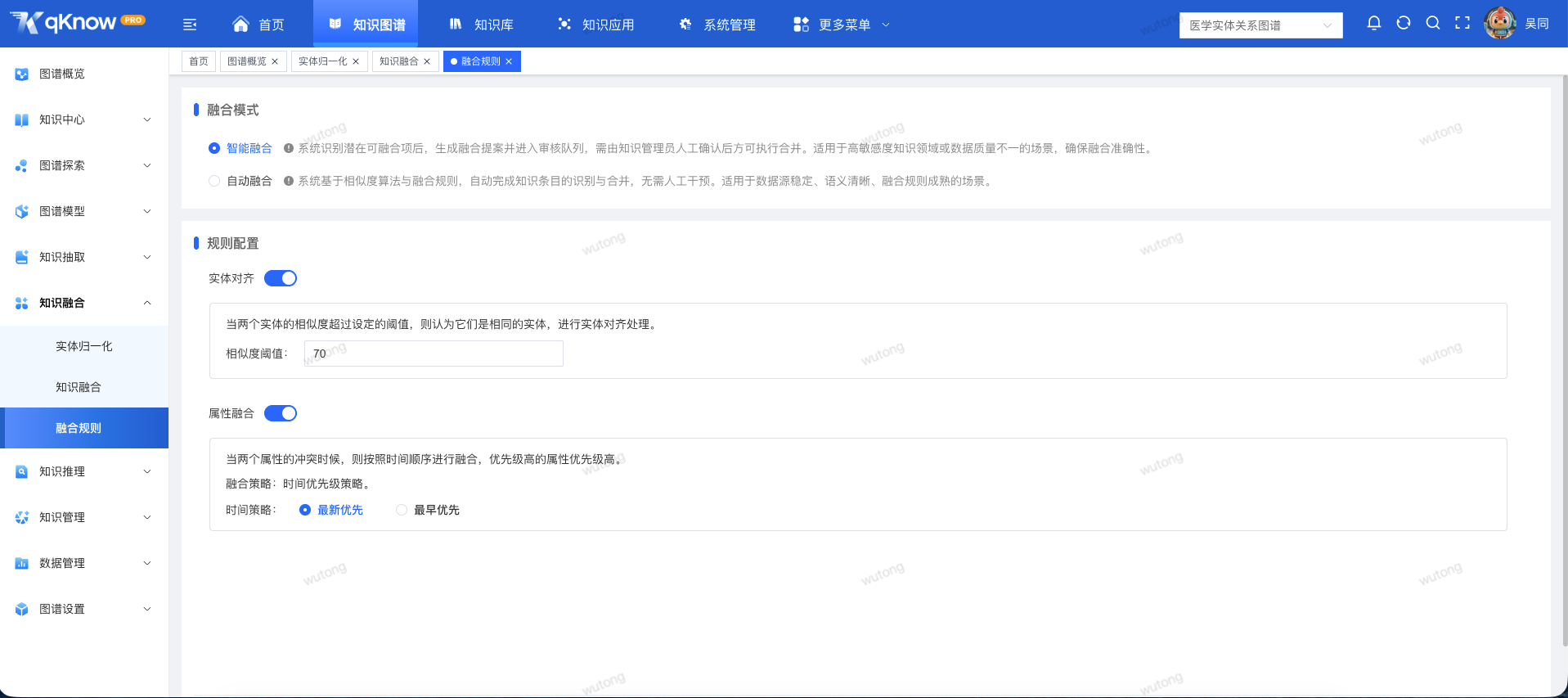
⚙️ 关键能力二:灵活的融合规则策略
为了适应不同业务场景对准确性和效率的差异化需求,qKnow 提供了智能融合与自动融合两种模式,并支持精细化的规则配置。
1. 双模融合机制
- 🤖 智能融合(人机协同):
系统先利用算法识别出潜在可融合的实体,生成融合记录清单。相关人员进行人工确认(是/否/不确定)后,再执行合并。- 适用场景:对数据准确性要求极高、业务逻辑复杂的场景。
- ⚡ 自动融合(无人干预):
系统依据相似度算法与预设规则,自动完成实体识别与合并,全程无需人工干预。- 适用场景:数据量大、容错率相对较高或需要快速清洗的场景。
2. 精细化规则配置
- 实体对齐:以相似度阈值为判断依据。当两个实体的语义相似度超过设定阈值时,系统自动判定为同一实体并执行对齐。
- 属性融合:针对属性冲突问题,采用时间优先级策略。系统可按业务需求,选择以“更新时间更晚”或“更新时间更早”的属性值为准,确保信息的时效性或历史一致性。
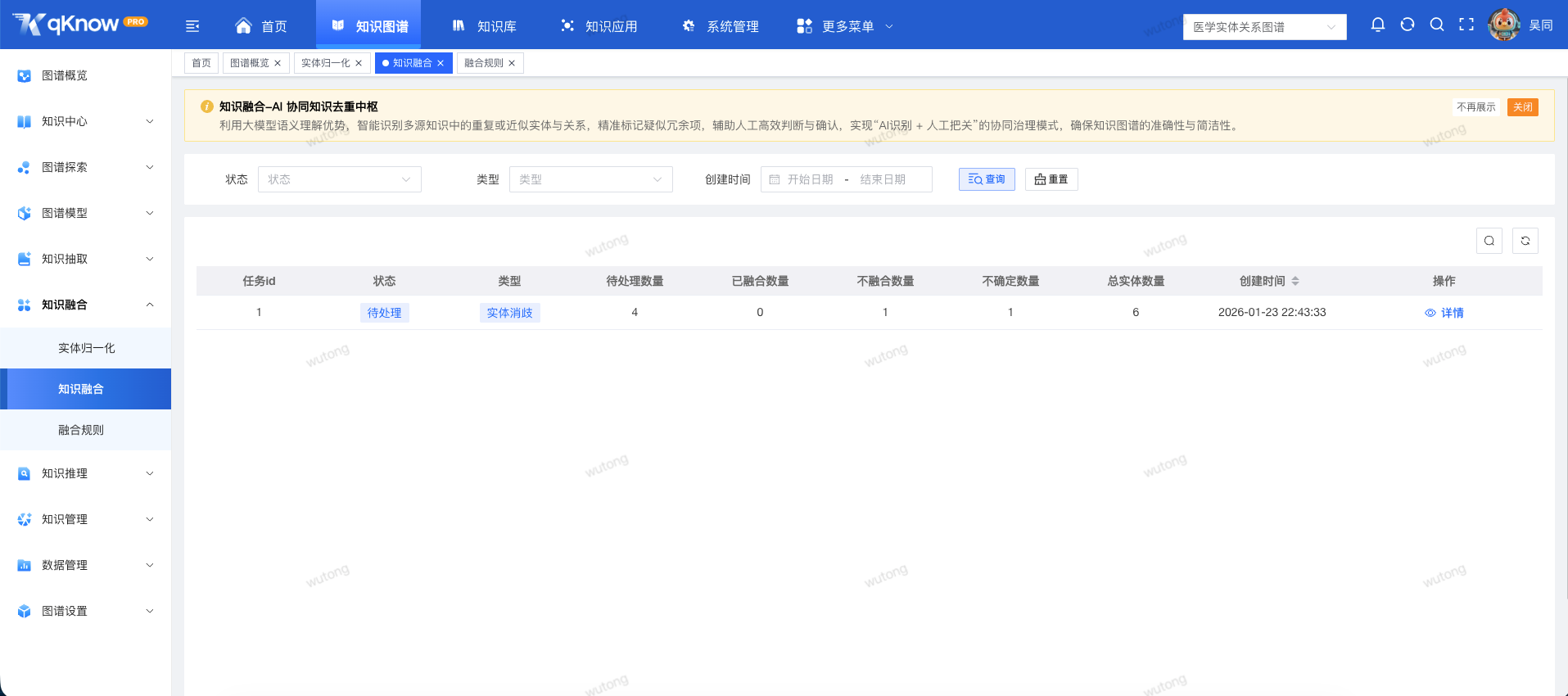
🛡️ 关键能力三:全流程可管控、可追溯
知识融合不仅仅是“合并”,更是一个严谨的数据治理过程。qKnow 提供了完善的流程化管理能力:
- 📅 每日全量扫描:系统每日自动对已发布实体进行全量扫描,依据预设策略智能识别符合合并条件的实体,自动生成融合任务清单。
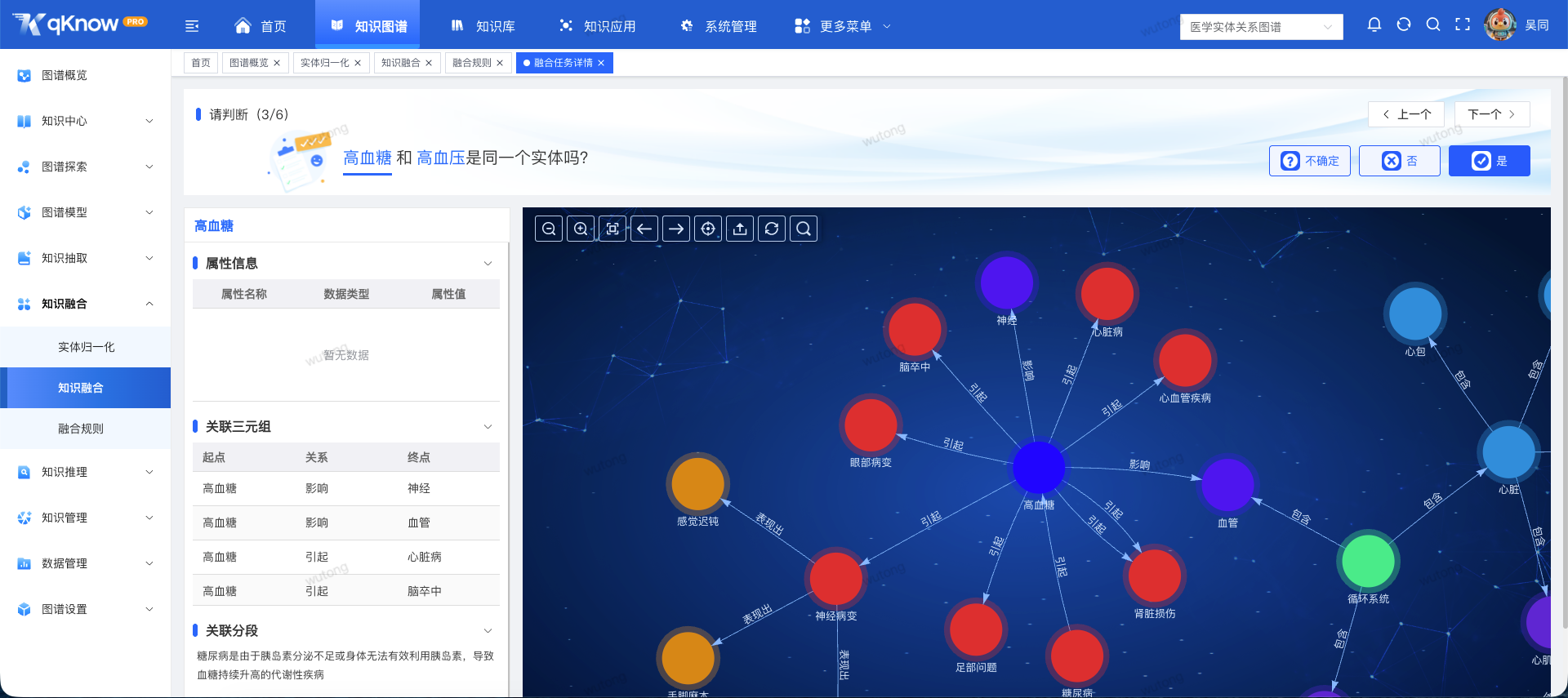
- 🔍 决策辅助信息:在处理候选融合实体时,操作人员可查看单实体的基本信息、关联三元组、数据来源等完整上下文信息,为“是、否、不确定”的判定提供全面依据。
- 🔄 可回溯与可回滚:
- 所有融合操作均生成可追溯的处理记录。
- 支持流程化处置,已处理完成的融合任务可按需撤回修正。
- 确保知识融合过程可管控、可追溯、可回滚,在提升效率的同时,牢牢守住数据准确性的底线。
💡 总结
qKnow 知识平台的知识融合能力,通过大模型语义理解与灵活规则引擎的结合,成功解决了多源数据整合中的难题。
从实体归一化的统一标准,到智能/自动双模融合的灵活策略,再到全流程可回溯的安全保障,qKnow 助力企业构建高质量的知识图谱,让数据真正转化为可复用、高价值的资产。
希望通过今天的解析,大家对知识融合有了更清晰的认识。如果您对 qKnow 平台感兴趣,或想深入了解其他核心能力,欢迎在评论区留言互动!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)