吴恩达、斯坦福都在说的这件事,测试人早就懂了
这条路,本质上就是一条「测试逻辑回归主线」。01科技Benchmark:像极了只跑 Happy Path 的测试过去几年,AI 行业最重要的评价方式,是 Benchmark。刷分、排名、对比,一套走得非常顺。问题是,这套东西对真正的落地越来越不管用。为什么?
这两年,AI 行业有一个很明显的变化。
大家不再天天问“模型有多强”“参数有多大”“又破了哪个榜”,而是开始反复讨论一件以前不太性感的事:
它到底靠不靠谱?值不值得用?出了问题谁负责?
有意思的是,这些问题,测试同行一点都不陌生。
最近一段时间,吴恩达、斯坦福、谷歌云几乎在同一时间,抛出了多份报告和观点,核心指向非常一致:
AI 正在从「能力展示」,走向「评估、验证和可控」。
如果你是做测试、质量、测评出身的,看到这句话,大概率会有种熟悉感:
这不就是我们干了十几年的事吗?
今天这篇文章,我想换一个视角——
不用 AI 黑话,不聊模型细节,而是用测试人的语言,拆一条正在发生的演进路径:
从 Benchmark,到图灵-AGI,再到 Agent,最后落在 Skill
这条路,本质上就是一条「测试逻辑回归主线」。
01
科技Benchmark:像极了只跑 Happy Path 的测试

过去几年,AI 行业最重要的评价方式,是 Benchmark。
AIME、GPQA、SWE-bench……
刷分、排名、对比,一套走得非常顺。
问题是,这套东西对真正的落地越来越不管用。
为什么?
因为它太像我们最熟悉的一种测试状态:
用固定用例,跑固定路径,只看结果对不对。
模型是不是“会做这道题”,
和它能不能在真实业务里稳定干活,是两回事。
你一定见过类似场景:
-
接口单测全绿 ✔
-
功能测试也过 ✔
-
一上线:
-
异常链路没兜住
-
多系统联动出问题
-
数据脏了,回滚成本爆炸
-
AI 的 Benchmark,本质也是这样的问题:
-
题目固定
-
路径可预期
-
模型可以被“对题训练”
分数越来越高,但风险并没有同步下降。
于是,行业开始意识到:
只测“会不会解题”,不等于“能不能干活”。
02
图灵-AGI:一场超长周期的端到端验收测试
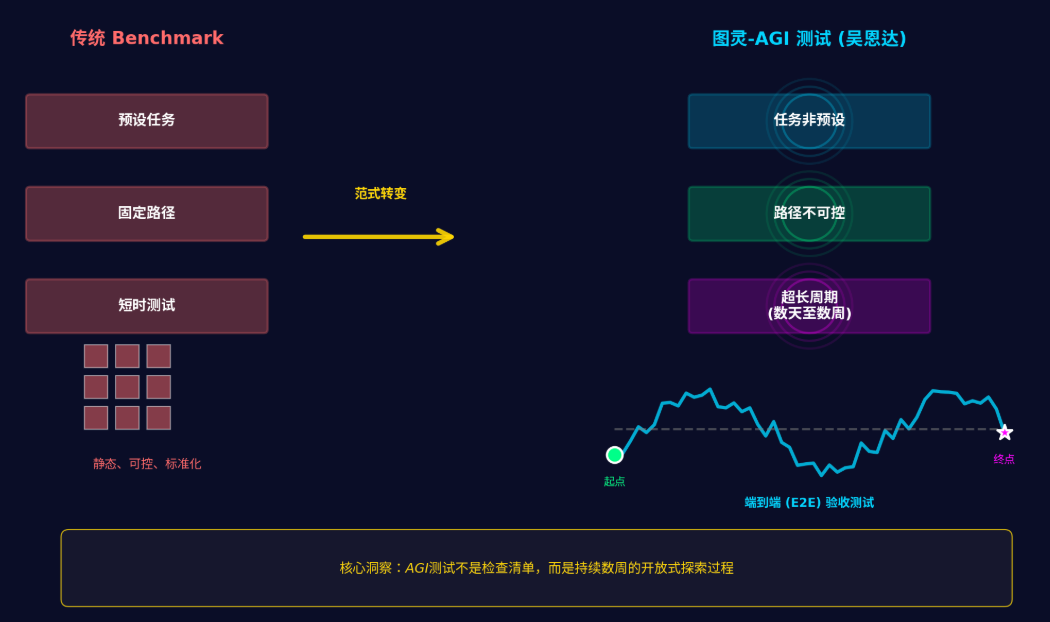
在这个背景下,吴恩达提出了一个很有意思的概念:
图灵-AGI 测试。
它和传统 Benchmark 最大的不同在于三点:
-
任务不是预设的
-
路径不可控、会不断变化
-
测试周期可能持续数天甚至数周
换成测试人的语言,这是什么?
这就是一场极其严格的端到端验收测试(E2E)。
不是测你会不会答题,而是看你能不能:
-
接住不断变化的需求
-
在多轮反馈中修正方向
-
最终交付一个“人能用、敢用”的结果
你会发现,这和我们做系统验收时关注的东西高度一致:
-
中途翻车怎么办?
-
异常谁兜底?
-
最终结果是否稳定可复现?
吴恩达甚至说过一句“反直觉”的话:
如果现在所有 AI 都通不过这个测试,那反而是件好事。
这句话放在测试语境里,翻译一下就是:
暴露问题,远比虚假的通过率重要。
03
从“测模型”,到“测 人 + AI + 流程”
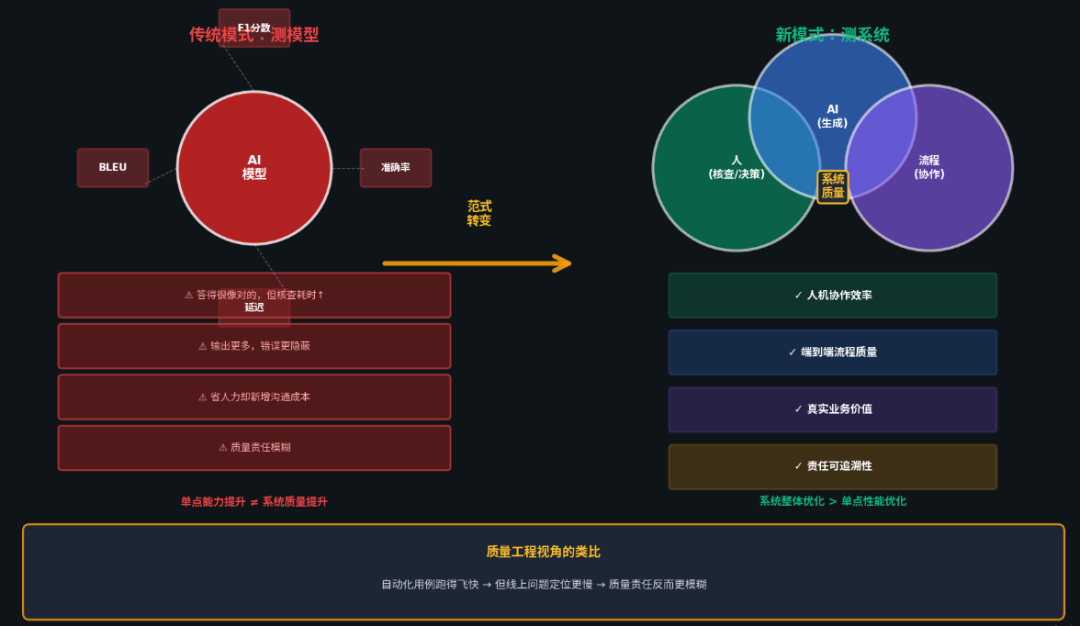
更有意思的变化,来自学界和企业的共识。
Stanford HAI在多份报告中反复强调一件事:
不能只评估模型能力,
必须评估 人 + AI + 流程 这个整体系统。
这句话,几乎是为质量工程量身定做的。
因为现实中,AI 的问题往往不在“答得不对”,而在:
-
答得很像对的,但人要花更多时间核查
-
输出更多,但错误更隐蔽
-
看似省人力,却引入新的沟通和兜底成本
这是不是很像:
-
自动化用例跑得飞快
-
但线上问题定位更慢
-
质量责任反而更模糊
单点能力提升,并不等于系统质量提升。
这一刻,AI 行业正式撞上了测试行业的老问题。
04
Agent:终于不再是“一次输入一次输出”
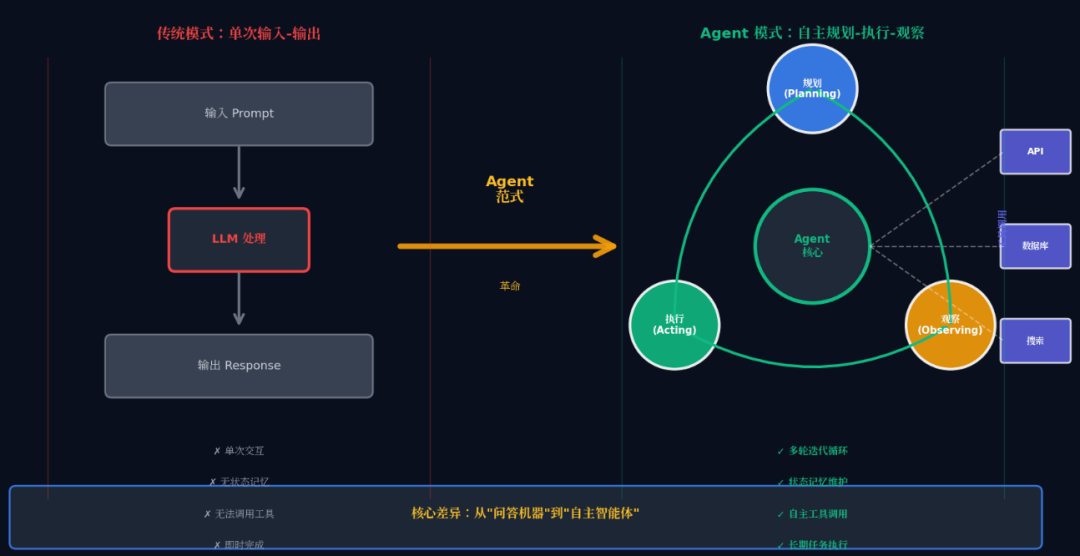
于是,技术路径开始转向 Agent。
不再是“问一句、回一句”的工具,而是:
-
理解目标
-
拆解任务
-
调用工具
-
在一个流程里把事做完
很多企业已经把 Agent 投入生产,但真正跑出 ROI 的,并不是最复杂的多 Agent 系统,而是:
流程清晰、边界明确、责任可追溯的 Agent。
听起来是不是有点耳熟?
没错,这和我们做系统测试时的经验一模一样:
-
系统不是越复杂越好
-
能测清楚、能定位、能兜底,才是真的可用
05
Skill:测试人最熟悉的那个“最小可控单元”
真正让这一切开始“像测试行业”的,是 Skill 的出现。
在 Agent 体系里,Skill 不是玄学,而是:
-
边界清楚
-
可调用
-
可监控
-
可复用
-
可失败、可回放
一次搜索、一次判断、一次校验、一次执行,都是一个 Skill。
这对测试人来说意味着什么?
测试对象终于不再是一个模糊的“智能体”,
而是一组可验证的能力单元。
你不再问:
“这个 Agent 靠不靠谱?”
而是问:
-
哪个 Skill 在什么条件下会失败?
-
失败是否被正确兜底?
-
是否影响下游流程?
-
是否可回归、可复现?
这,就是测试思维。
06
为什么说:测试的价值,正在被 AI 行业重新验证
回头看这条路径:
-
Benchmark → 功能测试
-
图灵-AGI → 端到端验收
-
Agent → 系统测试
-
Skill → 可测试最小单元
你会发现,AI 行业并没有发明一套全新的评估逻辑。
它只是,在经历一轮轮“翻车”之后,
重新走回了测试人早就走过的那条路。
区别只在于:
以前是我们向业务解释“为什么要测这么多”;
现在是 AI 行业自己发现——不测,根本不敢用。
当 AI 开始算 ROI、算风险、算责任边界时,
测试不再只是成本中心,而是:
系统是否值得信任的最后一道防线。
07
最后
很多人问:
AI 会不会让测试消失?
但真正发生的事情,可能正相反。
当世界从“能不能做到”,走向“能不能放心用”,
测试思维,正在重新成为稀缺能力。
只不过这一次,
被验证的,不只是代码,
而是整个由 AI 驱动的系统。
而这,正是测试最擅长的事情。
当世界从「能不能做到」走向「能不能放心用」,测试人手里握着的,或许正是 AI 时代最稀缺的那张门票。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)