《用“小明在喝水”32步学习Transformer大模型》【10 篇连载第四篇】
同时,8头×64维的切分设计(8×64=512)在保证总特征维度不变、信息无丢失的前提下,将大矩阵运算拆解为多个小矩阵并行运算,大幅提升了计算效率,适配大规模并行计算的工程需求。多头切分的唯一输入为上一环节生成的Q、K、V三元组矩阵,以“小明 在 喝水”3个Token的输入为例,该三元组具备标准化工程属性:三者均为3×512浮点型矩阵,行维度3对应序列长度,列维度512为综合特征维度;如何通过矩阵
(多头切分 · 512 维 → 8 头 × 64 维的底层逻辑)
开篇引入
在Transformer编码器的自注意力机制实现中,完成Q、K、V三元组矩阵生成后,多头切分是衔接后续单头注意力计算的关键前置步骤。很多学习者会困惑:为何不能直接对512维的Q、K、V做注意力计算?512维特征该如何科学拆分?拆分后的数据形态又会发生怎样的变化?这些问题的答案,正是理解Transformer多维度语义关联捕捉能力的核心,本篇将围绕512维到8头×64维的多头切分,拆解其设计逻辑、执行规则与工程价值。
核心原理
前置输入基础
多头切分的唯一输入为上一环节生成的Q、K、V三元组矩阵,以“小明 在 喝水”3个Token的输入为例,该三元组具备标准化工程属性:三者均为3×512浮点型矩阵,行维度3对应序列长度,列维度512为综合特征维度;在内存中以连续数据块形式存储,地址关联、标识统一;矩阵元素为标准化浮点值,无异常、无需额外预处理,可直接执行切分运算。
多头切分的设计初衷
单头注意力计算并非技术不可行,但存在核心性能缺陷——无法捕捉自然语言中多层级、多维度的复杂语义关联。以“小明 在 喝水”为例,其包含主谓语法关联、状谓修饰关联、整体语义完整性关联等多重关系,单头注意力仅能学习到综合化的关联权重,无法精准区分各维度关联。
多头切分的核心逻辑,是将512维高维特征拆分为多个低维子空间,让每个子空间(注意力头)专注捕捉一种特定层面的语义关联,最终融合所有头的计算结果,实现多维度语义关联的全面精准捕捉。同时,8头×64维的切分设计(8×64=512)在保证总特征维度不变、信息无丢失的前提下,将大矩阵运算拆解为多个小矩阵并行运算,大幅提升了计算效率,适配大规模并行计算的工程需求。
严格的切分执行规则
多头切分仅针对特征维度(列维度) 进行均匀、无偏差切分,Transformer经典设计为8头注意力机制,核心参数与执行步骤遵循行业通用标准,且对Q、K、V同步执行、规则完全一致,行维度(序列长度)全程保持不变。
- 核心参数定义:注意力头数h=8,模型总特征维度
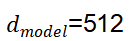 =512,单头特征维度
=512,单头特征维度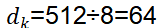 (硬性要求:必须能被h整除,避免维度残缺、信息丢失);
(硬性要求:必须能被h整除,避免维度残缺、信息丢失);
- 单矩阵切分:以Q矩阵为例,3×512的矩阵按“每64列为一个子矩阵”从左至右切分,得到8个3×64的子查询矩阵
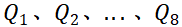 ;
;
- 三元组对称切分:K、V矩阵按相同规则切分,分别得到8个3×64的子键矩阵、子值矩阵,即
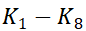 、
、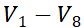 ;
;
- 独立头三元组建构:切分后形成8组相互独立、并行存在的注意力头三元组
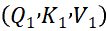 至
至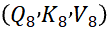 ,后续单头注意力计算仅能同头内Q、K、V匹配运算,确保各头语义捕捉的独立性。
,后续单头注意力计算仅能同头内Q、K、V匹配运算,确保各头语义捕捉的独立性。
切分后的内存数据形态
多头切分并非简单的维度拆分,而是将原本3×512的二维矩阵重塑为8×3×64的三维张量,Q、K、V分别存储为![]() 、
、![]() 、
、![]() 三个三维张量,各维度层级含义明确:第一维度8为注意力头数,对应8个独立语义捕捉子空间;第二维度3为序列长度,全程保持不变;第三维度64为单头特征维度,是单头注意力计算的核心运算维度。
三个三维张量,各维度层级含义明确:第一维度8为注意力头数,对应8个独立语义捕捉子空间;第二维度3为序列长度,全程保持不变;第三维度64为单头特征维度,是单头注意力计算的核心运算维度。
重塑后的三维张量具备三大工程属性:支持CPU/GPU多核心并行运算,提升计算效率;子矩阵维度均为3×64,确保后续![]() 矩阵乘法的列行维度精准匹配;切分过程完全可逆,后续可通过按列拼接还原为512维特征,与编码器后续网络层维度兼容。
矩阵乘法的列行维度精准匹配;切分过程完全可逆,后续可通过按列拼接还原为512维特征,与编码器后续网络层维度兼容。
边界分析
- 切分操作的核心边界:多头切分仅能对特征维度(列维度)进行操作,严禁对序列长度维度(行维度)做任何修改,否则会破坏Token的序列关联性,导致语义信息丢失;
- 头数与单头维度的设计边界:注意力头数的设定需兼顾语义捕捉效果与算力消耗,8头是Transformer经典论文的最优解;单头特征维度必须由总特征维度整除得到,若总维度无法被头数整除,需先对特征维度做维度映射调整,再执行切分,避免维度残缺;
- 计算执行的边界:单头注意力计算的核心边界为“同头匹配、异头隔离”,不同注意力头的Q、K、V严禁交叉计算,否则会破坏各头独立的语义捕捉逻辑,导致多维度语义关联捕捉失效;
- 数据形态的边界:三维张量的维度顺序为“注意力头数→序列长度→单头特征维度”,该顺序为工程实操的通用标准,不可随意调整,否则会导致后续张量运算的维度不匹配。
落地应用
多头的分工协作逻辑
8个注意力头通过“分工协作、各司其职”实现多维度语义关联捕捉,各头的具体捕捉方向由模型训练过程自动学习,非人工设定,以“小明 在 喝水”为例可做简化理解:
- 头1:专注捕捉主谓核心关联,重点计算“小明”与“喝水”的语义关联权重;
- 头2:专注捕捉状谓修饰关联,重点计算“在”与“喝水”的语义关联权重;
- 头3:专注捕捉全局语义关联,计算三个Token间的整体搭配与语义完整性关系;
- 头4-8:专注捕捉词性关联、词汇搭配、语义强弱等更细粒度的语义特征。
这种“分而治之、协同融合”的设计,让Transformer的自注意力机制相比单头注意力,能更全面、细致地理解自然语言的复杂语义,这也是Transformer在NLP任务中表现远超传统模型的核心原因之一。
工程实操的核心注意事项
- 内存存储优化:切分后的8组三元组需在内存中独立存储,且保证同头的Q、K、V地址相邻,提升后续并行计算的内存读取效率;
- 运算效率提升:利用CPU/GPU的多核心并行计算能力,对8个头的单头注意力计算同时执行,相比单头大矩阵运算,可将计算效率提升8倍左右;
- 结果兼容性保障:单头注意力计算完成后,需将8个3×64的结果矩阵按列拼接为3×512的矩阵,恢复为总特征维度,确保与编码器后续的前馈神经网络等模块维度兼容。
要点总结
- 核心输入:以3×512的Q、K、V三元组矩阵为唯一输入,矩阵维度统一、内存就绪、可直接执行切分运算;
- 设计核心:解决单头注意力无法捕捉多维度语义关联的缺陷,同时通过小矩阵并行运算提升算力效率,且保证总特征维度不变、信息无丢失;
- 执行规则:仅对512维特征维度均匀切分为8头,每头64维,行维度(序列长度3)全程不变,Q、K、V同步对称切分,形成8组独立的注意力头三元组;
- 形态变化:从3×512二维矩阵重塑为8×3×64三维张量,维度层级为“注意力头数→序列长度→单头特征维度”,支持并行运算且可逆向拼接;
- 核心价值:8个注意力头分工协作,各自捕捉不同层面、不同粒度的语义关联,大幅提升模型对自然语言复杂语义的理解能力。
记忆口诀:五一二维拆八头,每头六十四维走,序列三维恒不变,八组三元并行守。
下一篇预告:《单头注意力计算 · 3×64 矩阵如何算出关联权重》,深度讲解每组注意力头三元组
![]() 如何通过矩阵乘法、缩放、Softmax激活三大核心步骤,精准计算Token间的语义关联权重,完成单头注意力的核心运算。
如何通过矩阵乘法、缩放、Softmax激活三大核心步骤,精准计算Token间的语义关联权重,完成单头注意力的核心运算。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)