多模态大模型微调框架之Llama-factory
LlamaFactory是一个面向AI开发者的大模型训练与微调平台,提供从开发到部署的全流程解决方案。平台通过可视化界面和自动化工作流降低技术门槛,支持训练、导出、推理和评估等核心功能。安装使用uv工具即可完成,提供WebUI和命令行两种操作方式,支持LoRA、QLoRA等多种微调方法。平台兼容Alpaca和ShareGPT数据格式,并可通过国内镜像加速模型下载。典型工作流程包括准备模型与数据、配

LlamaFactory Online 是一个面向科研机构、企业研发团队或个人开发者快速构建和部署AI应用的一站式大模型训练与微调平台,致力于提供简单易用、高效灵活的全流程解决方案。平台以“低门槛、高效率、强扩展”为核心,通过集成化工具链、可视化操作界面与自动化工作流,显著降低大模型定制与优化的技术成本,助力用户快速实现模型从开发调试到生产部署的全周期闭环,功能示意如下所示。
官方文档:
https://llamafactory.readthedocs.io/zh-cn/latest/
安装
使用 uv 工具来安装 Llama-factory
下载工程
git clone --depth 1 https://github.com/hiyouga/LlamaFactory.git
uv 安装
cd LlamaFactory
uv sync
使用一条命令uv sync就完成 LlamaFactory 的安装,版本以及依赖版本等不会从错误
验证
打开 llamafactory 自带的web页面
uv run llamafactory-cli webui

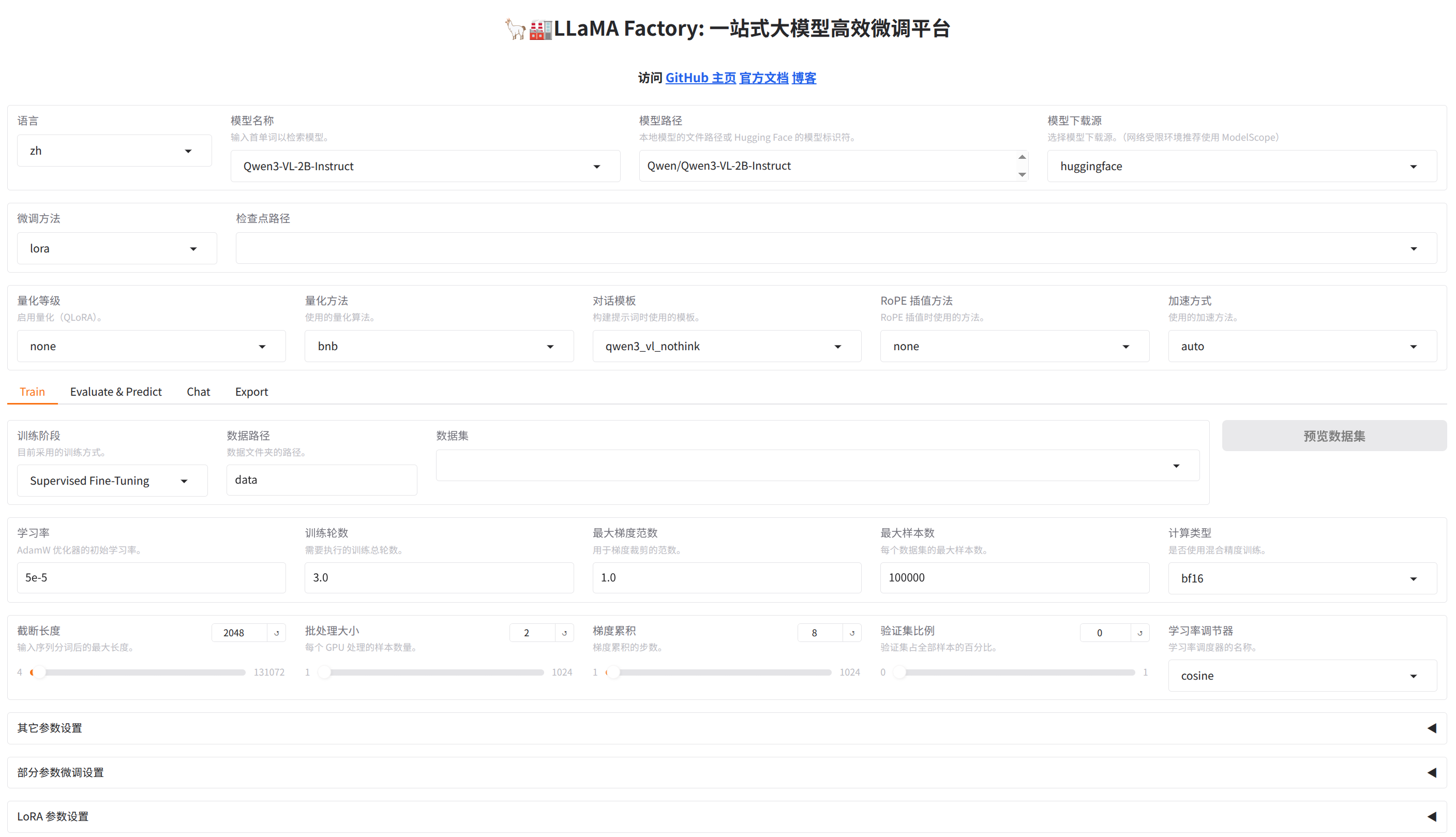
能正常打开这个页面就说明安装没有问题了
简单使用
llamafactory 的使用有两种模型,分别是web页面和命令行。这里就简单介绍一下命令行的使用。
基本功能的命令行使用包括:
- 训练
- 导出
- 推理
- 评估
命令行的通用使用方式是 llamafactory-cli + 任务 + 配置文件
任务类型主要通过任务来指定,如:
- train:训练
- export:导出
- chat:推理
- eval:评估
配置文件是yaml格式的文件,命名也很清晰,包括训练参数,任务配置参数。
在训练上,官方给了很多示例文件,比如 全量训练、lora微调、qlora微调等方法。

训练
uv run llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml
### examples/train_lora/llama3_lora_sft.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
stage: sft
do_train: true
finetuning_type: lora
lora_target: all
dataset: identity,alpaca_en_demo
template: llama3
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
导出:
llamafactory-cli export merge_config.yaml
### examples/merge_lora/llama3_lora_sft.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
finetuning_type: lora
### export
export_dir: models/llama3_lora_sft
export_size: 2
export_device: cpu
export_legacy_format: false
推理:
llamafactory-cli chat inference_config.yaml
### examples/inference/llama3.yaml
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
template: llama3
infer_backend: huggingface #choices: [huggingface, vllm]
评估
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml
### examples/train_lora/llama3_lora_eval.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft # 可选项
### method
finetuning_type: lora
### dataset
task: mmlu_test # mmlu_test, ceval_validation, cmmlu_test
template: fewshot
lang: en
n_shot: 5
### output
save_dir: saves/llama3-8b/lora/eval
### eval
batch_size: 4
微调 Qwen3 VL
模型准备
llamafactory-cli 可以自动下载模型,但是国内有时会超时,建议使用国内镜像网站。在命令行中执行如下:
export HF_ENDPOINT="https://hf-mirror.com"
选择一个指定的模型 Qwen/Qwen3-VL-2B-Instruct
数据准备
llamafactory 中数据集的配置集中在 data 下面的 dataset_info.json
"identity": {
"file_name": "identity.json"
},
"alpaca_en_demo": {
"file_name": "alpaca_en_demo.json"
},
"alpaca_zh_demo": {
"file_name": "alpaca_zh_demo.json"
},
"glaive_toolcall_en_demo": {
"file_name": "glaive_toolcall_en_demo.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"tools": "tools"
}
},
dataset_info.json 中json格式的文件,配置了需要使用的数据集。key 是数据集的名字,value 是具体参数。
例如:
数据集名称:alpaca_en_demo
数据集路径:alpaca_en_demo.json
具体数据集的格式,llamafactory 目前支持 alpaca 和sharegpt两种数据格式。
alpaca:
{
{
"instruction": "Describe a process of making crepes.",
"input": "",
"output": "Making crepes is an easy and delicious process! Enjoy!"
},
{
"instruction": "Transform the following sentence using a synonym: The car sped quickly.",
"input": "",
"output": "The car accelerated rapidly."
},
....
}
sharegpt:
{
{
"messages": [
{
"content": "<audio>What's that sound?",
"role": "user"
},
{
"content": "It is the sound of glass shattering.",
"role": "assistant"
}
],
"audios": [
"mllm_demo_data/1.mp3"
]
}
...
}
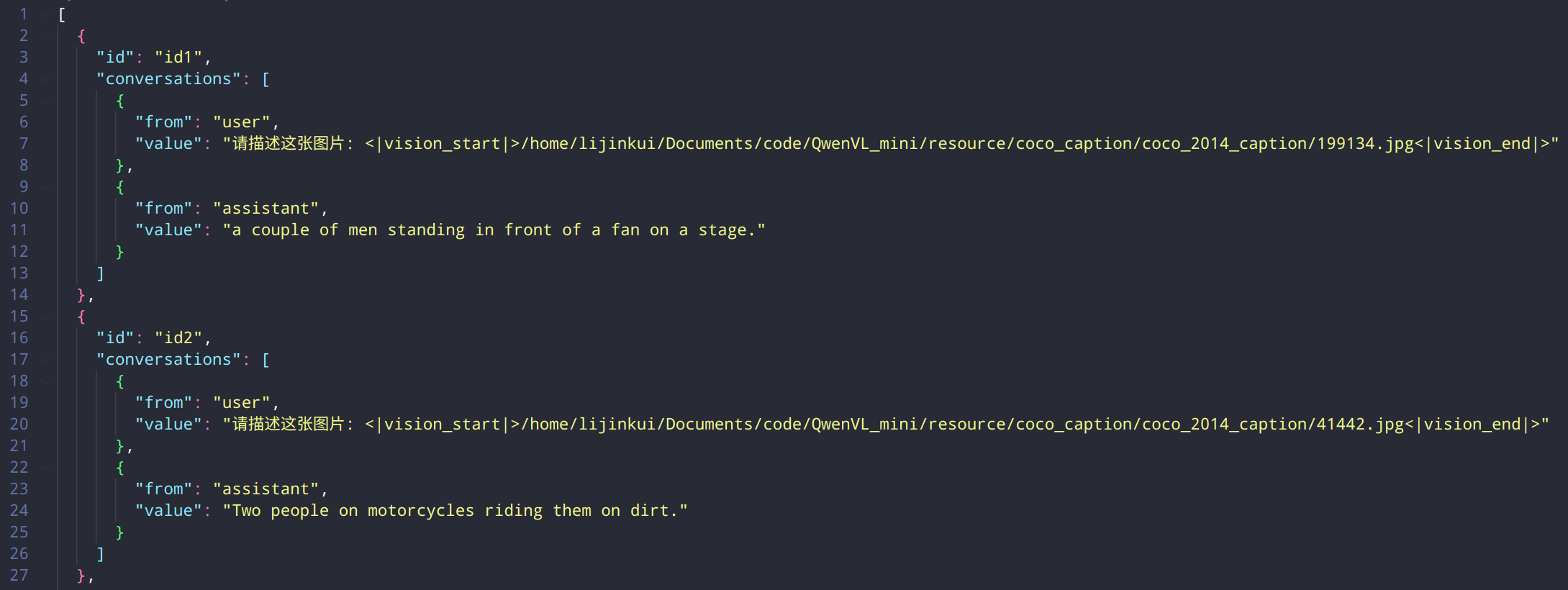
本次使用 coco-2014-caption,属于sharegpt格式,所以使用sharegpt格式来准备。
dataset_info.json 注册 coco数据集的配置项
"coco-400": {
"file_name": "coco-400.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"id": "id"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
coco 数据集的格式如下:
配置参数
微调就选择qlora的方式,根据工程给的示例文件去修改,选择的示例文件是:
### model
model_name_or_path: Qwen/Qwen3-4B-Instruct-2507
quantization_bit: 4 # choices: [8 (bnb/hqq/eetq), 4 (bnb/hqq), 3 (hqq), 2 (hqq)]
quantization_method: bnb # choices: [bnb, hqq, eetq]
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: identity,alpaca_en_demo
template: qwen3_nothink
cutoff_len: 2048
max_samples: 1000
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/qwen3-4b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
根据以上模板,修改成我们自身的参数,关键修改在于:
- 模型名称: model_name_or_path
- 数据集:dataset
- 模板:template 视觉大模型是qwen3_vl_nothink 语言大模型是qwen3_nothink,用错模板会报错
剩下的如训练批次、batch_size、梯度累计、学习率、保存路径、训练记录等都有设置,不再详说
### model
model_name_or_path: Qwen/Qwen3-VL-2B-Instruct
quantization_bit: 4 # choices: [8 (bnb/hqq/eetq), 4 (bnb/hqq), 3 (hqq), 2 (hqq)]
quantization_method: bnb # choices: [bnb, hqq, eetq]
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: coco-3000
template: qwen3_vl_nothink
cutoff_len: 2048
# max_samples: 1000
preprocessing_num_workers: 16
dataloader_num_workers: 4
### output
output_dir: saves/qwen3-2b-coco-3000/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]
### train
per_device_train_batch_size: 2
gradient_accumulation_steps: 4
learning_rate: 1e-5
num_train_epochs: 2
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
# val_size: 0.1
# per_device_eval_batch_size: 1
# eval_strategy: steps
# eval_steps: 500
### swanlab
use_swanlab: true
swanlab_project: llamafactory
swanlab_run_name: Qwen3-VL-2B-Instruct-llamafactory
启动训练
uv run llamafactory-cli train examples/train_qlora/qwen3-coco.yaml
➜ LlamaFactory git:(main) ✗ uv run llamafactory-cli train examples/train_qlora/qwen3-coco.yaml
[WARNING|2026-02-06 17:47:42] llamafactory.hparams.parser:148 >> We recommend enable `upcast_layernorm` in quantized training.
r Qwen3VLVideoProcessor {
"crop_size": null,
"data_format": "channels_first",
"default_to_square": true,
"device": null,
"do_center_crop": null,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"do_sample_frames": true,
"fps": 2,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"input_data_format": null,
"max_frames": 768,
"merge_size": 2,
"min_frames": 4,
"num_frames": null,
"pad_size": null,
"patch_size": 16,
"processor_class": "Qwen3VLProcessor",
"resample": 3,
"rescale_factor": 0.00392156862745098,
"return_metadata": false,
"size": {
"longest_edge": 25165824,
"shortest_edge": 4096
},
"temporal_patch_size": 2,
"video_metadata": null,
"video_processor_type": "Qwen3VLVideoProcessor"
}
[INFO|processing_utils.py:1116] 2026-02-06 17:47:50,292 >> loading configuration file processor_config.json from cache at None
[INFO|processing_utils.py:1199] 2026-02-06 17:47:50,543 >> Processor Qwen3VLProcessor:
- image_processor: Qwen2VLImageProcessorFast {
"crop_size": null,
"data_format": "channels_first",
"default_to_square": true,
"device": null,
"disable_grouping": null,
"do_center_crop": null,
"do_convert_rgb": true,
"do_normalize": true,
"do_pad": null,
"do_rescale": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_processor_type": "Qwen2VLImageProcessorFast",
"image_std": [
0.5,
0.5,
0.5
],
"input_data_format": null,
"max_pixels": null,
"merge_size": 2,
"min_pixels": null,
"pad_size": null,
"patch_size": 16,
"processor_class": "Qwen3VLProcessor",
"resample": 3,
"rescale_factor": 0.00392156862745098,
"return_tensors": null,
"size": {
"longest_edge": 16777216,
"shortest_edge": 65536
},
"temporal_patch_size": 2
}
- tokenizer: Qwen2TokenizerFast(name_or_path='Qwen/Qwen3-VL-2B-Instruct', vocab_size=151643, model_max_length=262144, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'eos_token': '<|im_end|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|im_start|>', '<|im_end|>', '<|object_ref_start|>', '<|object_ref_end|>', '<|box_start|>', '<|box_end|>', '<|quad_start|>', '<|quad_end|>', '<|vision_start|>', '<|vision_end|>', '<|vision_pad|>', '<|image_pad|>',
[INFO|trainer.py:2519] 2026-02-06 17:47:58,649 >> ***** Running training *****
[INFO|trainer.py:2520] 2026-02-06 17:47:58,649 >> Num examples = 600
[INFO|trainer.py:2521] 2026-02-06 17:47:58,649 >> Num Epochs = 2
[INFO|trainer.py:2522] 2026-02-06 17:47:58,649 >> Instantaneous batch size per device = 2
[INFO|trainer.py:2525] 2026-02-06 17:47:58,649 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:2526] 2026-02-06 17:47:58,649 >> Gradient Accumulation steps = 4
[INFO|trainer.py:2527] 2026-02-06 17:47:58,649 >> Total optimization steps = 150
[INFO|trainer.py:2528] 2026-02-06 17:47:58,651 >> Number of trainable parameters = 8,716,288
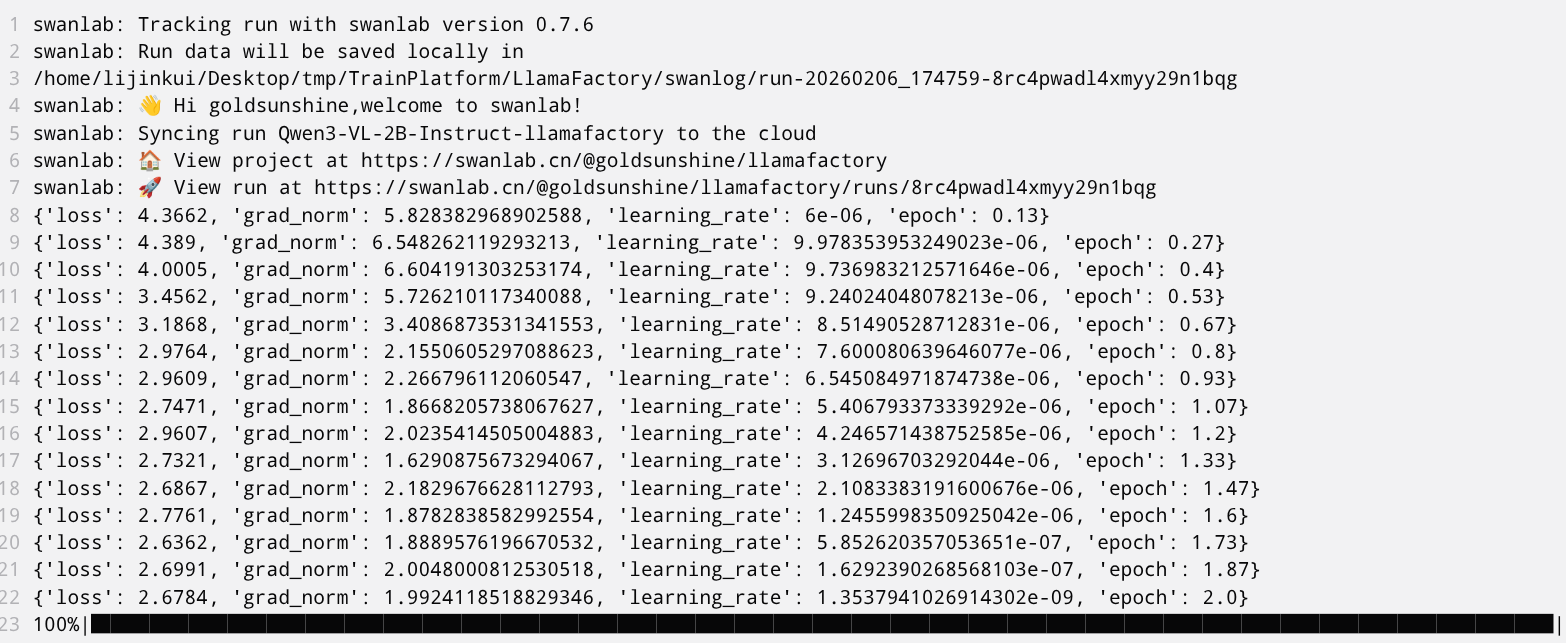
swanlab: swanlab version 0.7.7 is available! Upgrade: `pip install -U swanlab`
swanlab: Tracking run with swanlab version 0.7.6
swanlab: Run data will be saved locally in
/home/lijinkui/Desktop/tmp/TrainPlatform/LlamaFactory/swanlog/run-20260206_174759-8rc4pwadl4xmyy29n1bqg
swanlab: 👋 Hi goldsunshine,welcome to swanlab!
swanlab: Syncing run Qwen3-VL-2B-Instruct-llamafactory to the cloud
swanlab: 🏠 View project at https://swanlab.cn/@goldsunshine/llamafactory
swanlab: 🚀 View run at https://swanlab.cn/@goldsunshine/llamafactory/runs/8rc4pwadl4xmyy29n1bqg
{'loss': 4.3662, 'grad_norm': 5.828382968902588, 'learning_rate': 6e-06, 'epoch': 0.13}
{'loss': 4.389, 'grad_norm': 6.548262119293213, 'learning_rate': 9.978353953249023e-06, 'epoch': 0.27}
{'loss': 4.0005, 'grad_norm': 6.604191303253174, 'learning_rate': 9.736983212571646e-06, 'epoch': 0.4}
{'loss': 3.4562, 'grad_norm': 5.726210117340088, 'learning_rate': 9.24024048078213e-06, 'epoch': 0.53}
{'loss': 3.1868, 'grad_norm': 3.4086873531341553, 'learning_rate': 8.51490528712831e-06, 'epoch': 0.67}
{'loss': 2.9764, 'grad_norm': 2.1550605297088623, 'learning_rate': 7.600080639646077e-06, 'epoch': 0.8}
{'loss': 2.9609, 'grad_norm': 2.266796112060547, 'learning_rate': 6.545084971874738e-06, 'epoch': 0.93}
{'loss': 2.7471, 'grad_norm': 1.8668205738067627, 'learning_rate': 5.406793373339292e-06, 'epoch': 1.07}
{'loss': 2.9607, 'grad_norm': 2.0235414505004883, 'learning_rate': 4.246571438752585e-06, 'epoch': 1.2}
{'loss': 2.7321, 'grad_norm': 1.6290875673294067, 'learning_rate': 3.12696703292044e-06, 'epoch': 1.33}
{'loss': 2.6867, 'grad_norm': 2.1829676628112793, 'learning_rate': 2.1083383191600676e-06, 'epoch': 1.47}
{'loss': 2.7761, 'grad_norm': 1.8782838582992554, 'learning_rate': 1.2455998350925042e-06, 'epoch': 1.6}
{'loss': 2.6362, 'grad_norm': 1.8889576196670532, 'learning_rate': 5.852620357053651e-07, 'epoch': 1.73}
{'loss': 2.6991, 'grad_norm': 2.0048000812530518, 'learning_rate': 1.6292390268568103e-07, 'epoch': 1.87}
{'loss': 2.6784, 'grad_norm': 1.9924118518829346, 'learning_rate': 1.3537941026914302e-09, 'epoch': 2.0}
100%|███████████████████████████████████████████████████████████████████████████| 150/150 [01:30<00:00, 1.65it/s][INFO|trainer.py:4309] 2026-02-06 17:49:31,374 >> Saving model checkpoint to saves/qwen3-2b-coco-3000/lora/sft/checkpoint-150
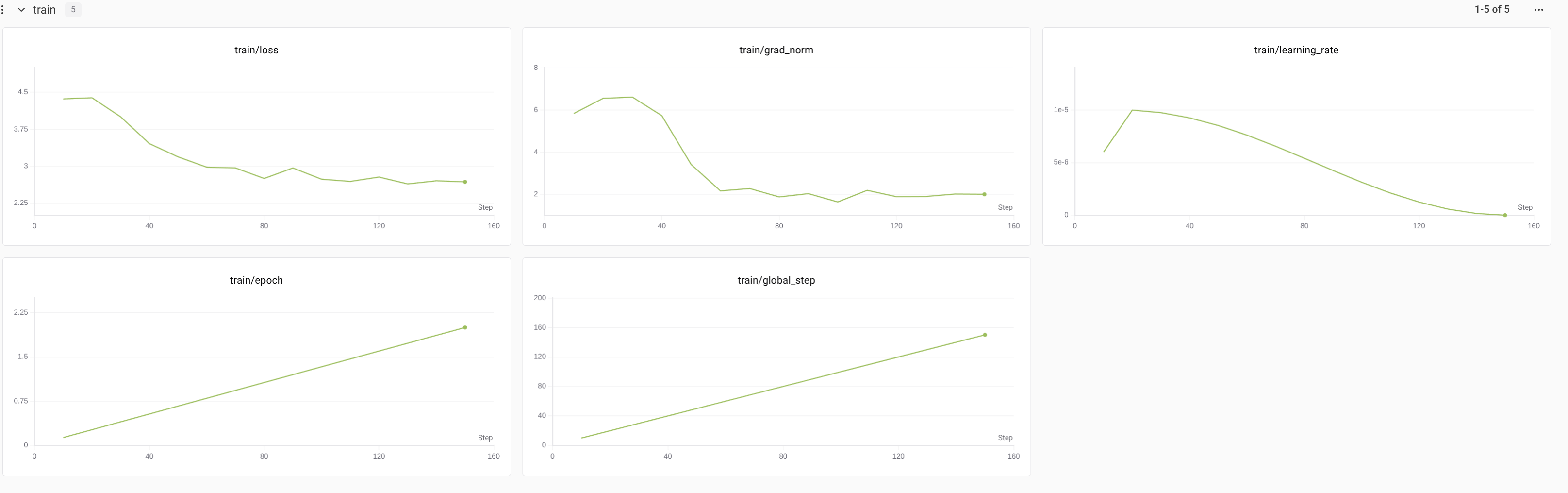
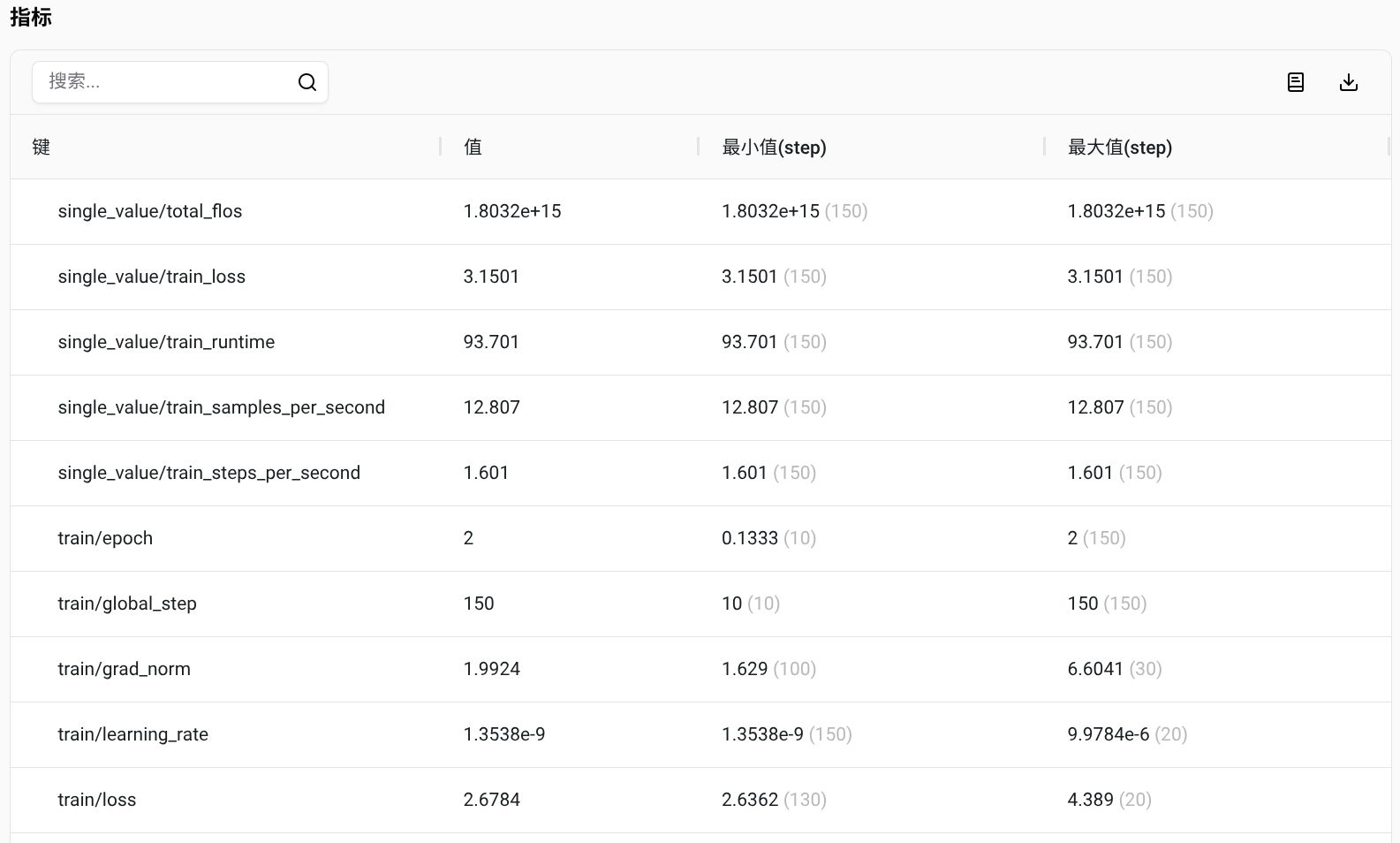
{'train_runtime': 93.701, 'train_samples_per_second': 12.807, 'train_steps_per_second': 1.601, 'train_loss': 3.1501645787556964, 'epoch': 2.0}
100%|███████████████████████████████████████████████████████████████████████████| 150/150 [01:31<00:00, 1.63it/s]
epoch = 2.0
total_flos = 1679346GF
train_loss = 3.1502
train_runtime = 0:01:33.70
train_samples_per_second = 12.807
train_steps_per_second = 1.601
Figure saved at: saves/qwen3-2b-coco-3000/lora/sft/training_loss.png
[WARNING|2026-02-06 17:49:33] llamafactory.extras.ploting:148 >> No metric eval_loss to plot.
[WARNING|2026-02-06 17:49:33] llamafactory.extras.ploting:148 >> No metric eval_accuracy to plot.
[INFO|modelcard.py:456] 2026-02-06 17:49:33,450 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
swanlab: Experiment Qwen3-VL-2B-Instruct-llamafactory has completed
swanlab: 🏠 View project at https://swanlab.cn/@goldsunshine/llamafactory
swanlab: 🚀 View run at https://swanlab.cn/@goldsunshine/llamafactory/runs/8rc4pwadl4xmyy29n1bqg
训练过程记录

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)