一个轻量AI Agent 平台 —— AgentForge
摘要:AgentForge是一个轻量级自托管AIAgent平台,采用FastAPI+React技术栈,提供三种执行模式:Simple单次调用、Pipeline可视化DAG编排和CustomHandler自定义逻辑。其特色包括混合RAG系统(支持向量/BM25/图谱检索)、多租户隔离、完整API接口和可观测性面板。项目不依赖LangChain,代码清晰可控,适合需要快速搭建内部AI系统或产品底座的团
前言
最近结合我的项目经验开发了一个轻量的 AI Agent 平台 AgentForge,本文介绍它的核心设计思路和功能特性。
项目地址
https://github.com/Lucas-lzy/AgentForge
为什么不用 LangChain?
市面上大多数 Agent 项目都基于 LangChain 构建。LangChain 功能强大,但也带来了不少问题:
- API 变动频繁,升级版本经常 breaking change
- 概念层级繁多,Chain / Tool / AgentExecutor 学习成本高
- 调试困难,黑盒封装导致排查问题痛苦
- 过度抽象,很多场景为了用框架而用框架
AgentForge 选择完全不依赖 LangChain,从零实现 DAG 执行引擎、RAG
检索、流式响应等核心能力,代码清晰可控,便于团队定制和二次开发。
项目简介
AgentForge 是一个轻量级自托管 AI Agent 平台,提供完整的 Web 管理界面和对外 API,可以直接Fork后作为自己产品的底座使用。
技术栈
| 层次 | 技术 |
| 后端 | FastAPI + Python 3.11 |
| 前端 | React 18 + TypeScript + Ant Design |
| 数据库 | PostgreSQL 16(pgvector + pg_bigm) |
| 缓存 | Redis 7 |
| 反向代理 | Nginx |
| 部署 | Docker Compose |
界面截图
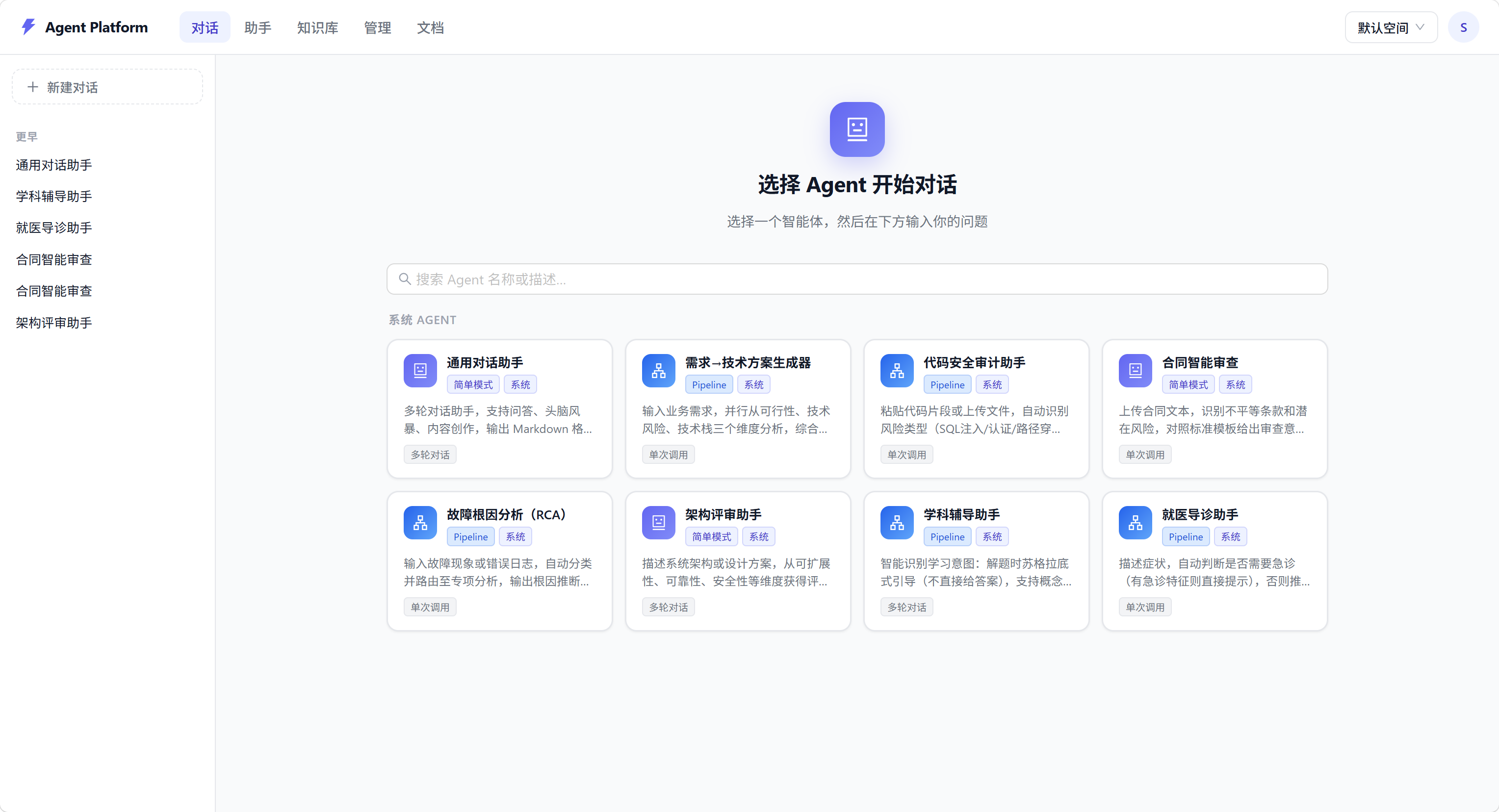
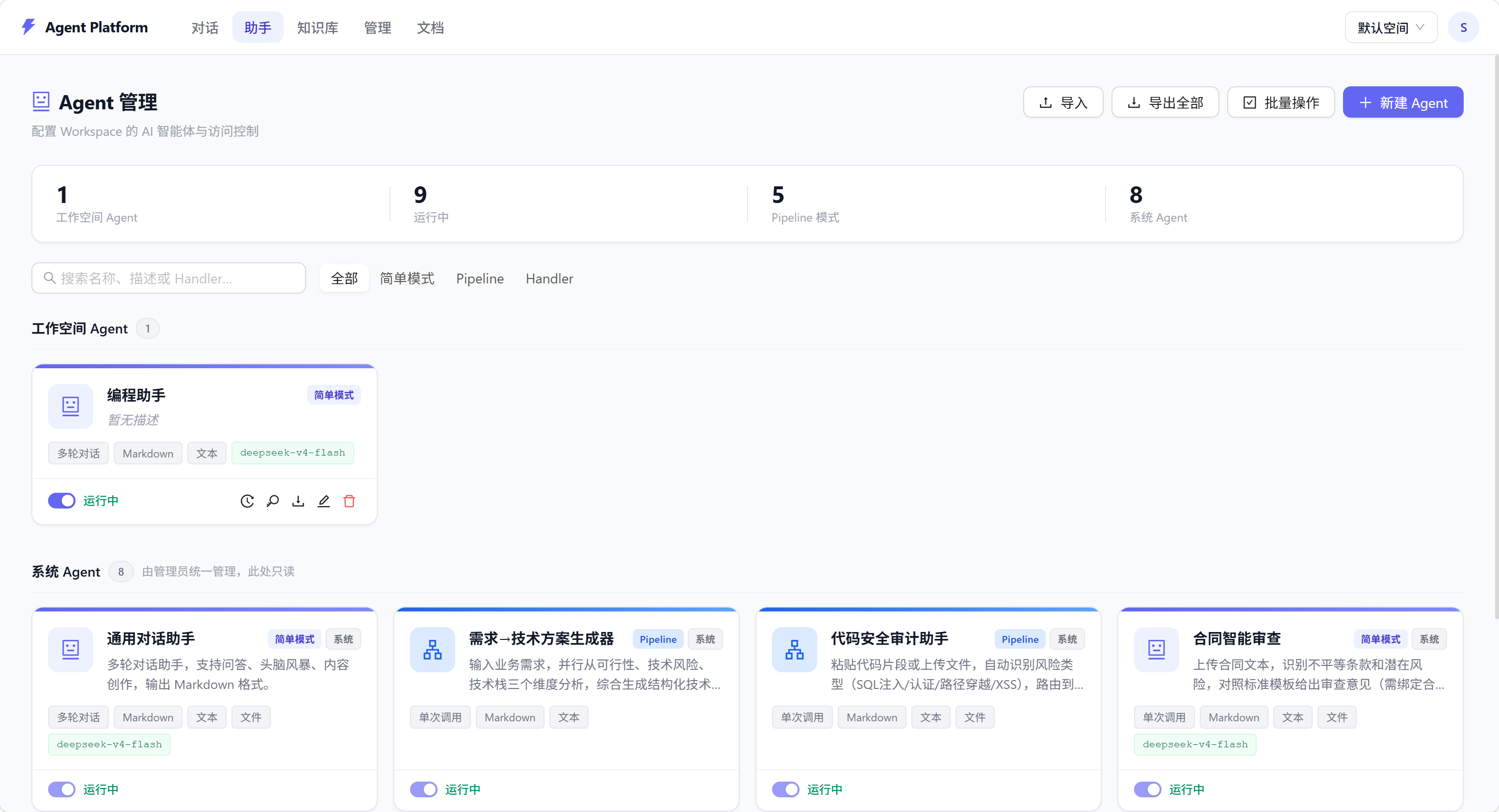
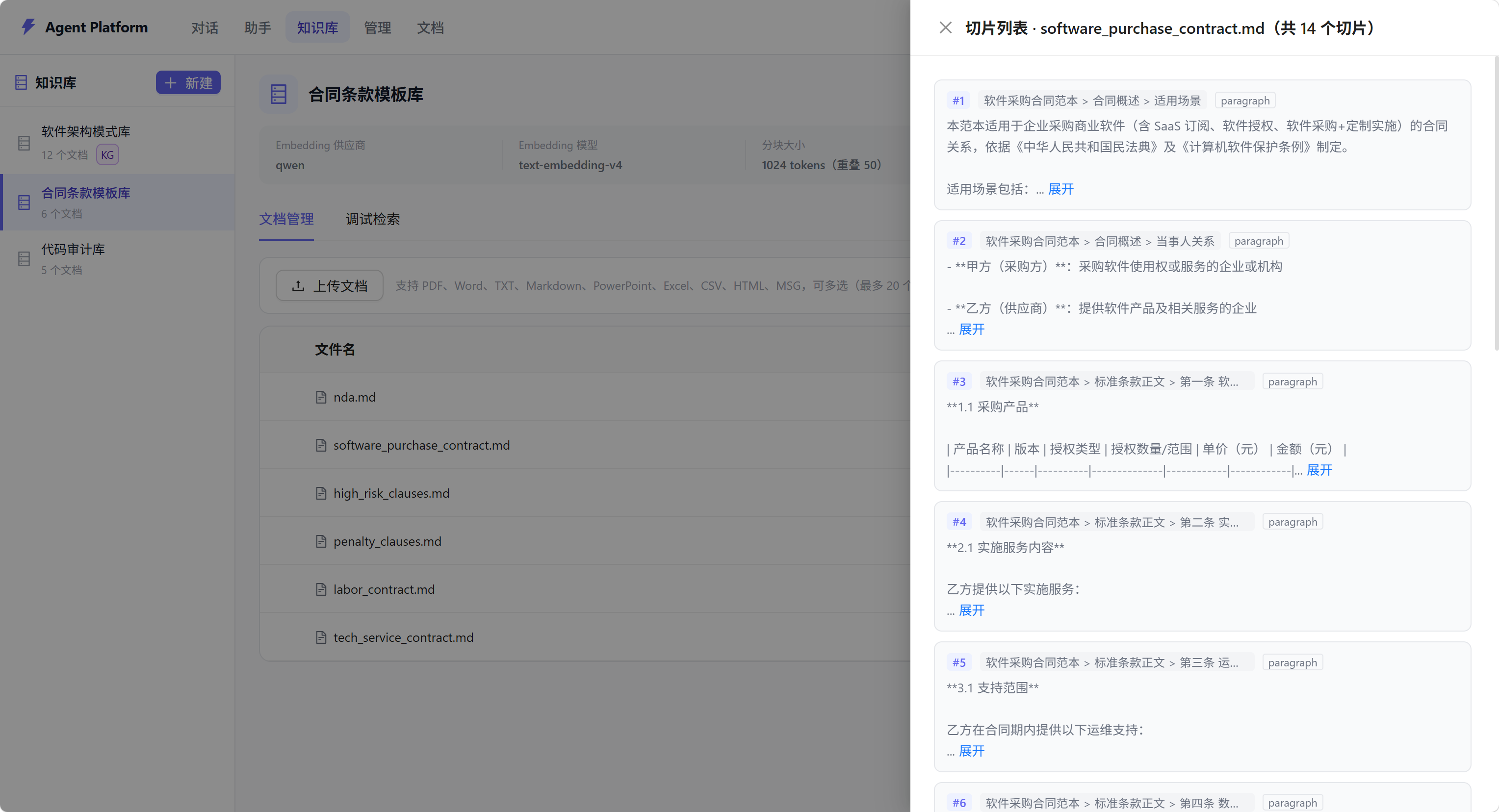
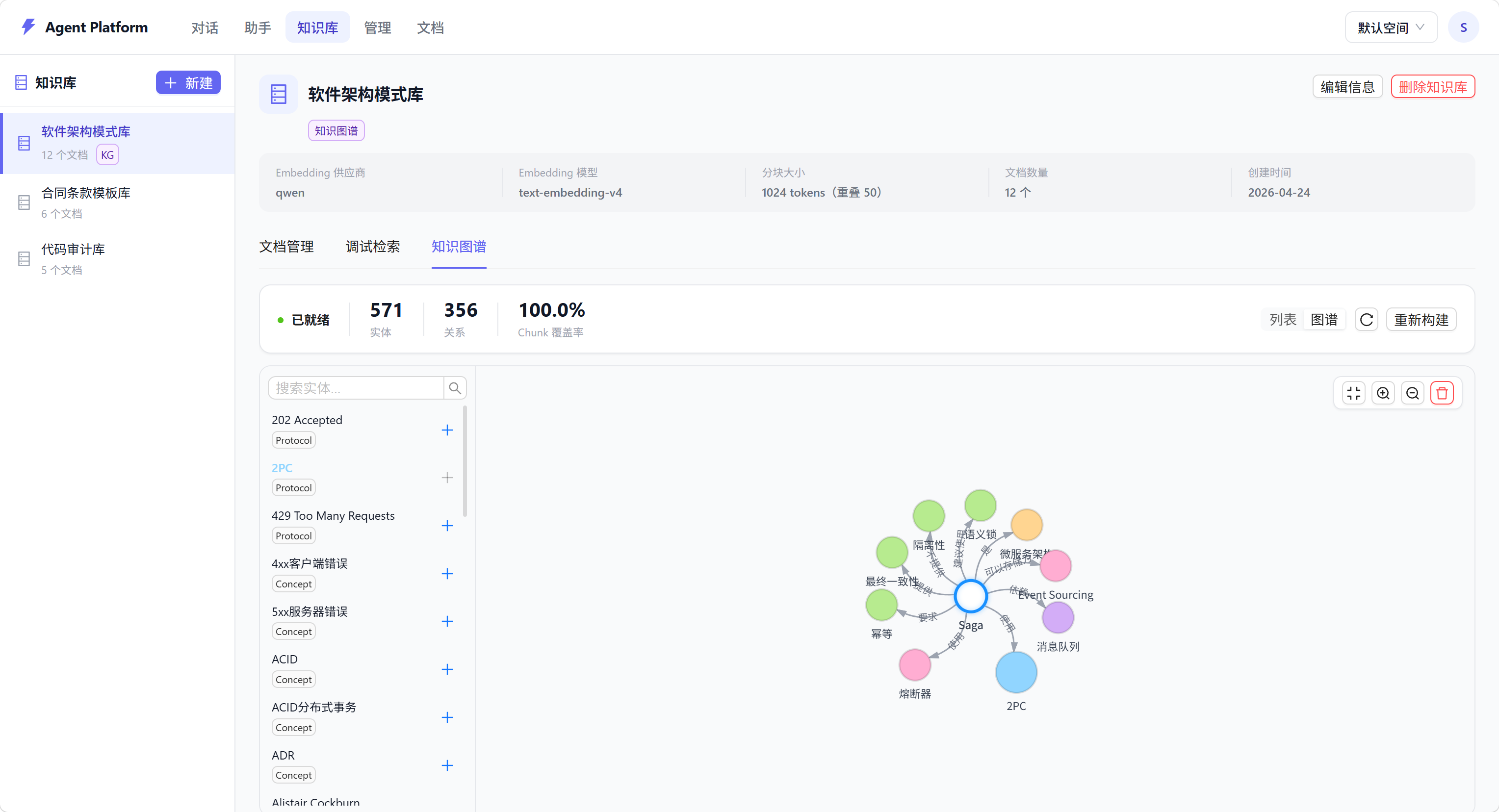
核心功能
Agent 执行模式
- Simple 模式 — 最简单,单次 LLM 调用,可选注入 RAG 上下文。
- Pipeline 模式 — 核心亮点。Agent 的执行逻辑被定义为一个 JSON 配置的 DAG(有向无环图),支持以下节点类型:
前端提供可视化 DAG 编辑器,无需写代码即可设计 Agent 执行流程,支持条件分支和并行分支。节点类型 功能 LLMStep 调用LLM ConditionStep 条件路由(字符串匹配) StaticStep 模板渲染(变量替换) RagStep RAG 检索注入 ParallelStep 并行执行多个子步骤 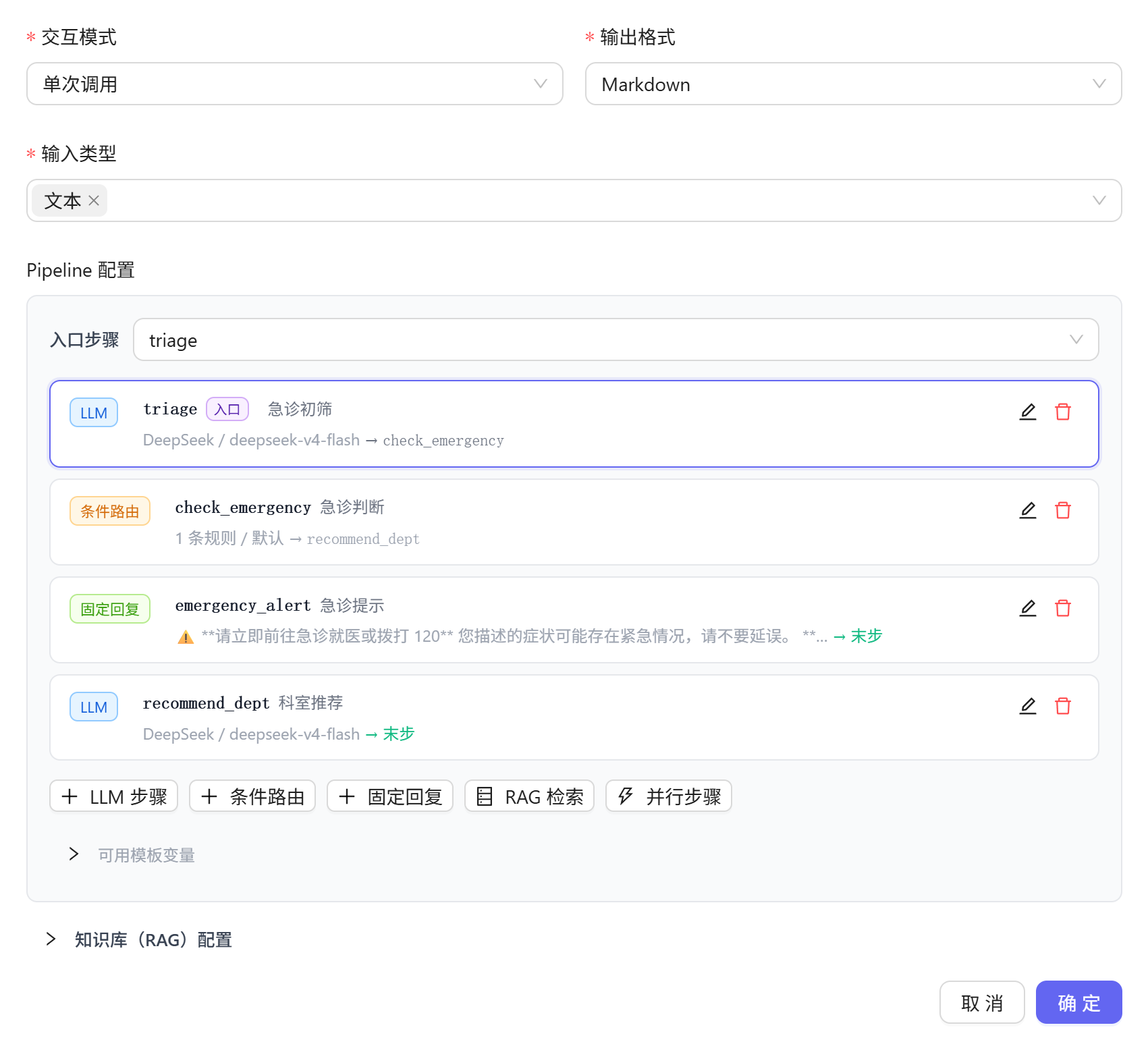
- Custom Handler 模式 — 完全自定义逻辑,继承 BaseAgentHandler 实现 stream() 异步生成器:
class MyHandler(BaseAgentHandler): async def stream(self, ctx: AgentHandlerContext): yield {"type": "delta", "content": "Hello"} yield {"type": "done"}注册一行代码即可,前端自动发现可用的 Handler 列表。
Q: 为什么我选择使用这三种模式?
A:
在深度使用 Dify、FastGPT 等主流 Agent 平台之后,我发现了一个普遍存在的痛点:纯编排平台在真实业务场景中往往力不从心。
现实是这样的——业务需求天然分层:
简单场景(如智能客服、基础 RAG 问答)任务单一,通过 Simple 直接调用或 Pipeline 简单编排就能满足需求,没必要写一行业务代码。
复杂场景则完全不同。以"对接业务系统的智能客服"为例,它需要读订单、查库存、触发工单……这时编排平台和业务系统之间天然缺一个中间层。为了填补这个空缺,团队往往不得不额外维护一个"胶水服务"——原本想用平台降本增效,反而引入了更高的系统复杂度。
这个中间层本不应该独立存在,它就是 Agent 执行逻辑本身。所以我降低了编排的比重,放弃了“拖拉拽编排”引入了 Custom Handler 模式:对于定制化程度高的场景,开发者直接在平台内编写 Python类,完全接管执行流程,业务逻辑、外部系统调用、自定义流式输出全部在一个地方闭环,不需要额外部署任何服务。
三种模式的选择逻辑因此很清晰:复杂度匹配需求,而不是用同一套方案削足适履。
混合 RAG 系统
支持三种检索策略,每个知识库独立配置:
- Vector — 纯向量检索,pgvector 余弦相似度。
- Hybrid — 向量 + BM25 混合,通过 RRF(倒数排序融合) 融合两路结果。BM25 依赖 PostgreSQL 的 pg_bigm
插件实现,无需额外部署搜索引擎。 - Graph — 知识图谱检索。
流程为:
(1). LLM 自动从文档中抽取实体和关系
(2). 构建图结构存入 PostgreSQL
(3). 检索时:实体匹配 → BFS 双向遍历(可配置 1~3 跳)→ 关联 chunk 打分排序
前端提供交互式知识图谱可视化界面(基于 @antv/g6),可以直观地浏览实体关系网络。
智能分块采用三级降级策略,避免破坏文档结构:
1. 按标题/段落整体保留(≤ chunk_size)
2. 跨段落贪心合并,带重叠
3. 超长段落固定滑窗兜底
支持 9 种文档格式:PDF、DOCX、XLSX、PPTX、HTML、MSG、TXT、MD、CSV。
外部 API
每个 API Key 绑定单个 Agent,前缀为 ap_sk_...,SHA-256 哈希存储(明文不落库)。
支持两种调用模式:
- 多轮对话:POST /api/external/sessions/{session_id}/chat
- 单次调用:POST /api/external/agents/{agent_id}/chat
两者均支持 SSE 流式响应,通过 Redis 滑动窗口实现速率限制。
多租户与权限
以 Workspace 为隔离边界,支持多工作空间。每个 Workspace 内有 admin / member 两级角色。
Agent 和 LLM Provider 支持 system 级别(跨所有工作空间只读可见)和 workspace 级别(仅本空间可见)两种作用域。
设置 SINGLE_WORKSPACE_MODE=true 可切换为单租户模式,隐藏工作空间管理 UI。
可观测性
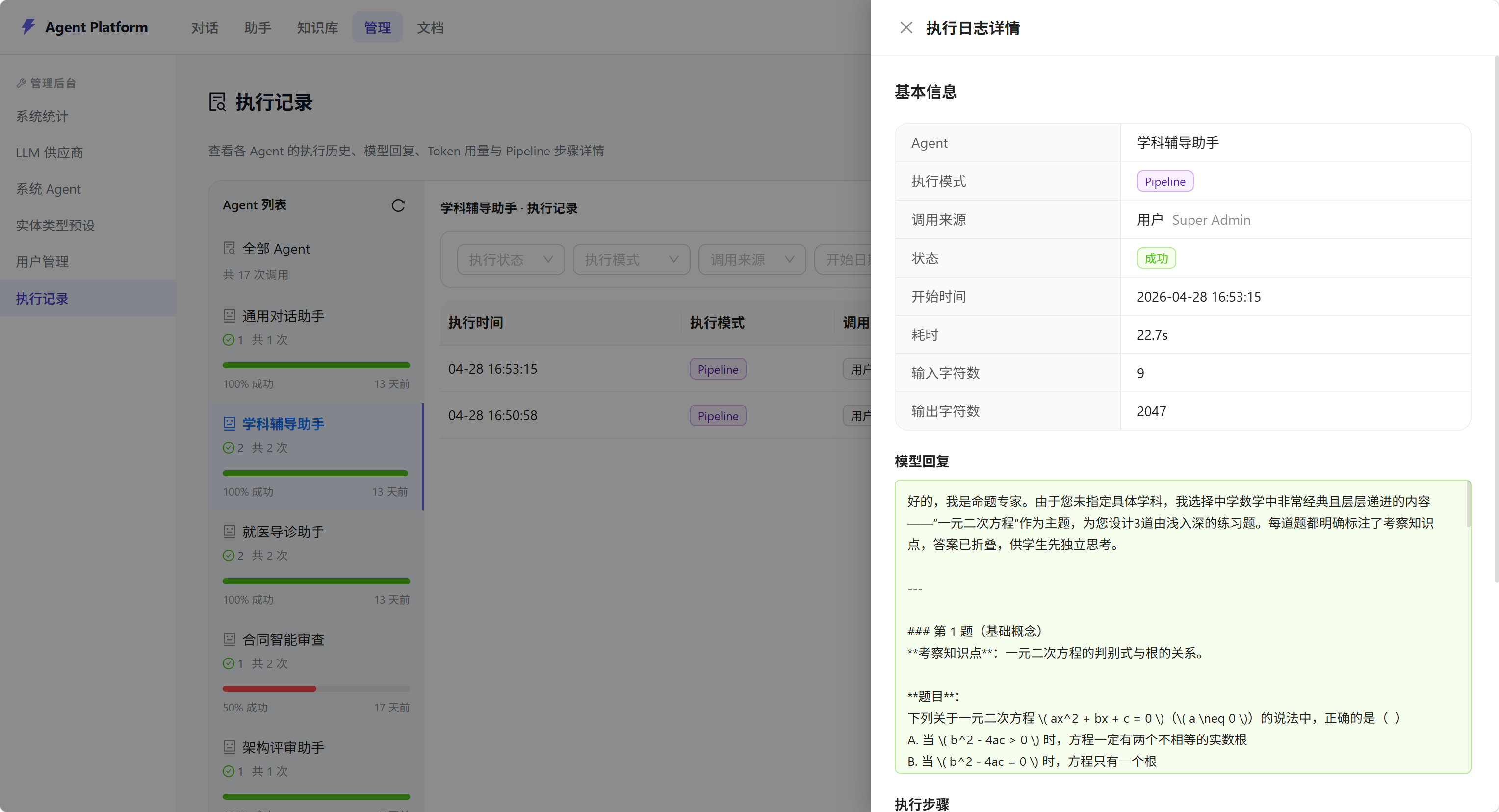
每次 Agent 执行都记录完整日志:
- 输入/输出内容
- Token 用量(Prompt + Completion)
- 执行耗时
- Pipeline 各步骤详情
- RAG 召回文档信息
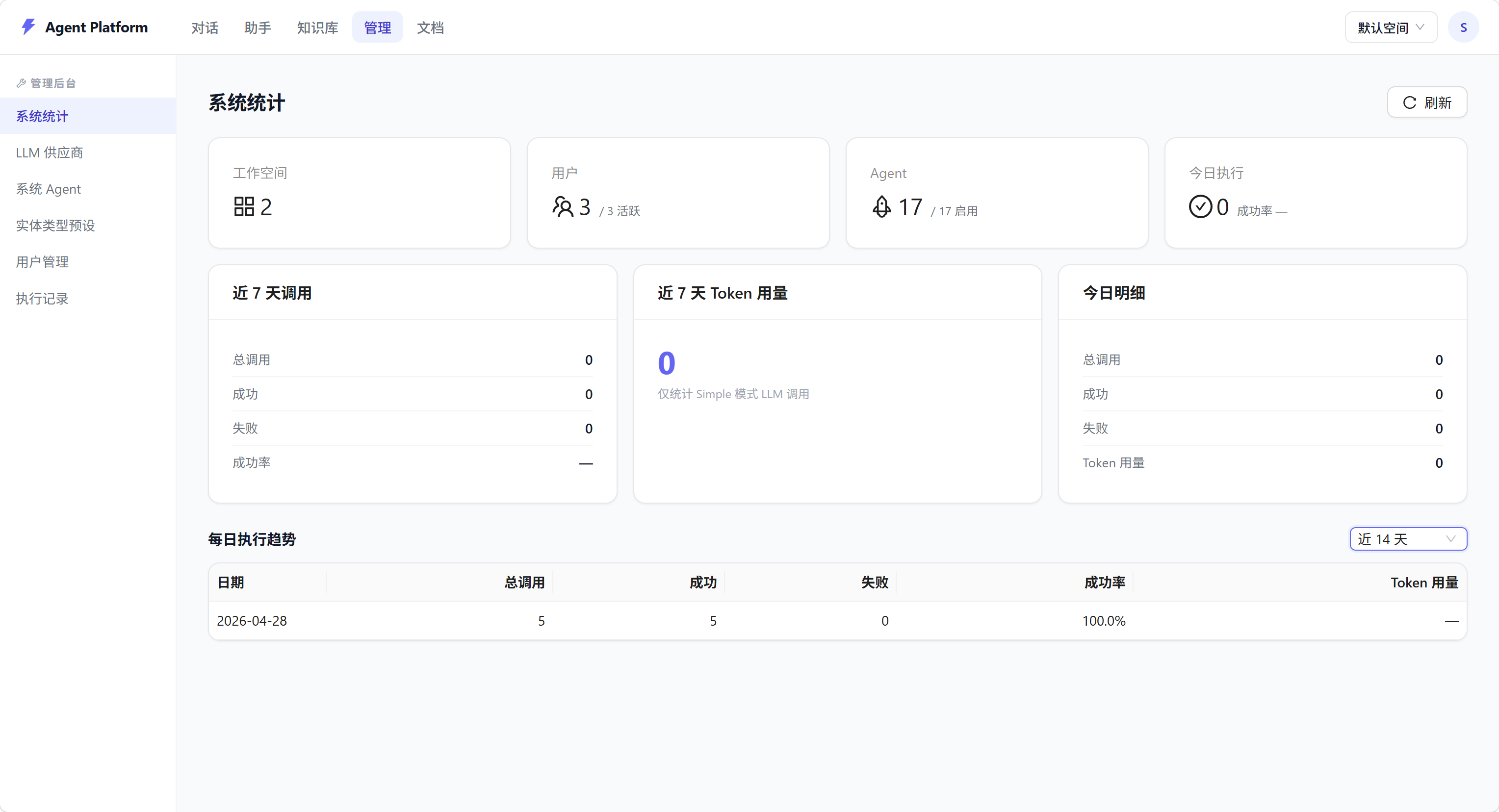
管理面板提供:工作空间统计、每日执行趋势、近 7 天 Token 用量汇总。
适合谁用?
- 想深入理解 AI Agent 平台架构的开发者(代码清晰,无框架魔法)
- 需要快速搭建内部 AI Agent 系统的团队(Docker Compose 一键启动)
- 想要 SaaS 产品底座的创业团队(MIT 许可,可直接商业化)
- 对 RAG 系统有较高要求的场景(混合检索 + 知识图谱内置实现)
最后
如果这个项目对你有帮助,欢迎在 GitHub 点个 Star,也欢迎提 Issue 和 PR。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)