基于多智能体事件触发的一致性控制:状态轨迹图与程序实践指南(附参考文献)
本文介绍了一种面向有向通信拓扑结构的线性多智能体系统一致性控制方法,其核心在于引入指数衰减型事件触发机制,以在保证系统收敛性能的同时显著降低通信与计算资源消耗。该方法通过在每个智能体本地判断是否需要更新其状态估计值(即“触发”事件),避免了传统周期性通信策略中的冗余数据交换,适用于资源受限的分布式协同控制场景。该仿真代码实现了一个经典的、基于事件触发的多智能体一致性控制方案。它不仅验证了理论的有效
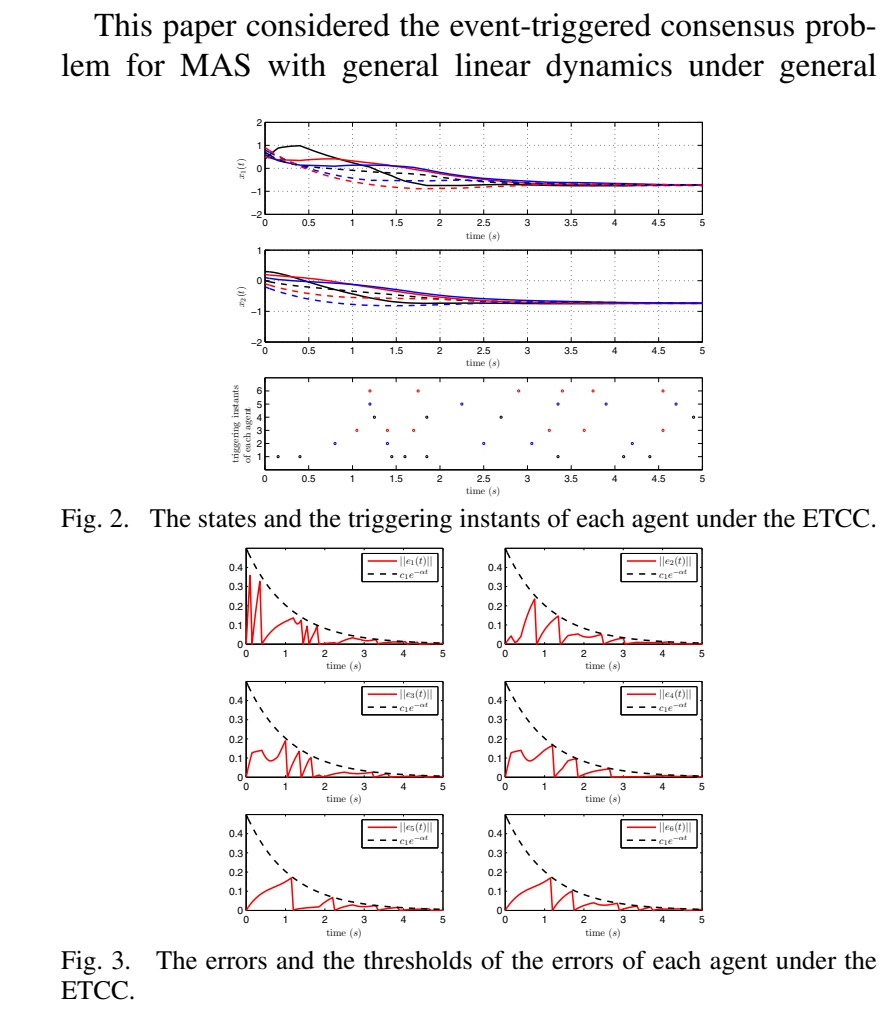
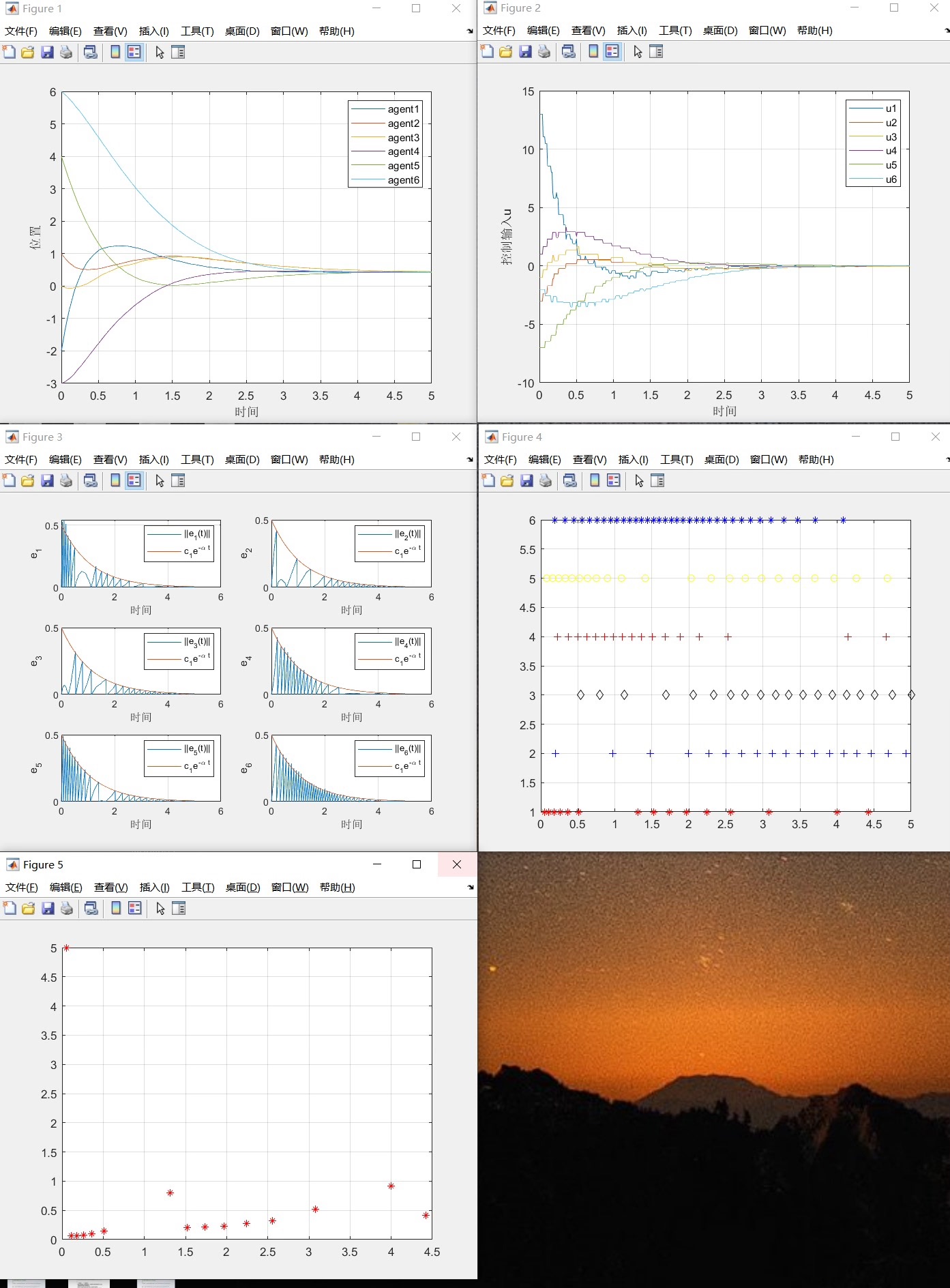
多智能体事件触发、一致性控制 状态轨迹图、控制输入图、事件触发图… 易于上手,有注释,有参考文献(与参考文献略有区别,适当变换能得到与参考文献相应的图形) 与文章不完全一致 图一:程序运行后的图形 图二:原文图形 图三:参考文献标题
概述
本文介绍了一种面向有向通信拓扑结构的线性多智能体系统一致性控制方法,其核心在于引入指数衰减型事件触发机制,以在保证系统收敛性能的同时显著降低通信与计算资源消耗。该方法通过在每个智能体本地判断是否需要更新其状态估计值(即“触发”事件),避免了传统周期性通信策略中的冗余数据交换,适用于资源受限的分布式协同控制场景。
系统模型与控制目标
考虑由6个智能体组成的线性多智能体系统,其动力学模型为一阶积分器形式:
$$
\dot{x}i(t) = ui(t), \quad i = 1, 2, \dots, 6
$$
其中 $xi(t) \in \mathbb{R}$ 为第 $i$ 个智能体的状态,$ui(t)$ 为其控制输入。通信拓扑由一个有向图描述,其对应的拉普拉斯矩阵 $L$ 已预先给定。该矩阵反映了智能体之间的信息流向与连接关系,是实现一致性控制的关键结构参数。

控制目标是设计分布式控制律 $u_i(t)$,使得所有智能体的状态在有限时间内渐近收敛至一致值,即:
$$
多智能体事件触发、一致性控制 状态轨迹图、控制输入图、事件触发图… 易于上手,有注释,有参考文献(与参考文献略有区别,适当变换能得到与参考文献相应的图形) 与文章不完全一致 图一:程序运行后的图形 图二:原文图形 图三:参考文献标题
\lim{t \to \infty} |xi(t) - x_j(t)| = 0, \quad \forall i,j
$$
事件触发机制设计
为减少不必要的通信,每个智能体不连续地广播其当前状态,而是维护一个本地状态估计 $\hat{x}i(t)$。该估计值仅在满足特定“触发条件”时才被更新为真实状态 $xi(t)$。
触发条件基于测量误差 $ei(t) = \hat{x}i(tk) - xi(t)$ 与一个时变阈值函数的比较:
$$
\|ei(t)\| \geq c1 e^{-\alpha t}
$$
其中:
- $c_1 > 0$ 为初始阈值增益,
- $\alpha > 0$ 为衰减速率。
该指数衰减阈值的设计确保了两个关键性质:
- Zeno行为规避:由于阈值随时间指数衰减,两次连续触发事件之间的时间间隔存在严格正的下界,从而避免了无限高频触发(Zeno现象)。
- 渐近一致性保证:随着阈值趋于零,测量误差也被强制收敛至零,最终保证系统达成一致。
仿真流程与核心逻辑
整个仿真过程在一个离散时间网格上进行,时间步长为 dt。在每个时间步,算法执行以下关键步骤:
- 误差计算:计算每个智能体当前的测量误差 $e_i(t)$。
- 触发判断:将误差范数与当前时刻的动态阈值进行比较。若超过阈值,则记录该时刻为触发时刻,并将本地估计 $\hat{x}i$ 更新为当前真实状态 $xi$。
- 控制输入生成:基于最新的本地估计值 $\hat{x}$,通过分布式控制律 $u = -L \hat{x}$ 计算控制输入。
- 状态更新:利用欧拉法对系统状态进行积分更新。
该流程巧妙地将连续时间的控制理论与离散事件驱动的仿真框架相结合,准确复现了事件触发控制的动态行为。
可视化与结果分析
仿真结束后,程序生成多组关键图表,用于全面评估系统性能:
- 状态轨迹图:展示所有智能体状态随时间的演化过程,直观验证一致性是否达成。
- 控制输入图:呈现各智能体控制信号的变化,反映控制能量的使用情况。
- 误差与阈值对比图:对每个智能体,绘制其测量误差与动态阈值的曲线。该图是验证触发机制有效性的核心,清晰展示了误差如何被阈值“约束”并最终收敛。
- 事件触发时刻图:以阶梯图或散点图形式,标出每个智能体发生通信(触发)的具体时间点,直接体现了通信资源的节省程度。
总结
该仿真代码实现了一个经典的、基于事件触发的多智能体一致性控制方案。它不仅验证了理论的有效性,还通过详尽的数据记录与可视化,为理解事件触发机制如何在保证系统性能的同时优化资源利用提供了宝贵的实践视角。此框架具有良好的可扩展性,可作为研究更复杂多智能体协同控制问题(如包含非线性动力学、时延或外部干扰)的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)