云平台一键部署【deepseek-ai/DeepSeek-OCR-2】视觉因果流更好的理解图片
DeepSeek-OCR 2 是DeepSeek团队推出的第二代 OCR 模型,通过引入 DeepEncoder V2 架构,实现从固定扫描到语义推理的范式转变。模型采用因果流查询和双流注意力机制,能动态重排视觉 Token,更精准地还原复杂文档的自然阅读逻辑。在OmniDocBench v1.5 评测中,模型综合得分达到 91.09%,较前代提升显著,同时显著降低了 OCR 识别结果的重复率,为
DeepSeek-OCR 2 是DeepSeek团队推出的第二代 OCR 模型,通过引入 DeepEncoder V2 架构,实现从固定扫描到语义推理的范式转变。模型采用因果流查询和双流注意力机制,能动态重排视觉 Token,更精准地还原复杂文档的自然阅读逻辑。在OmniDocBench v1.5 评测中,模型综合得分达到 91.09%,较前代提升显著,同时显著降低了 OCR 识别结果的重复率,为未来构建全模态编码器提供新路径。
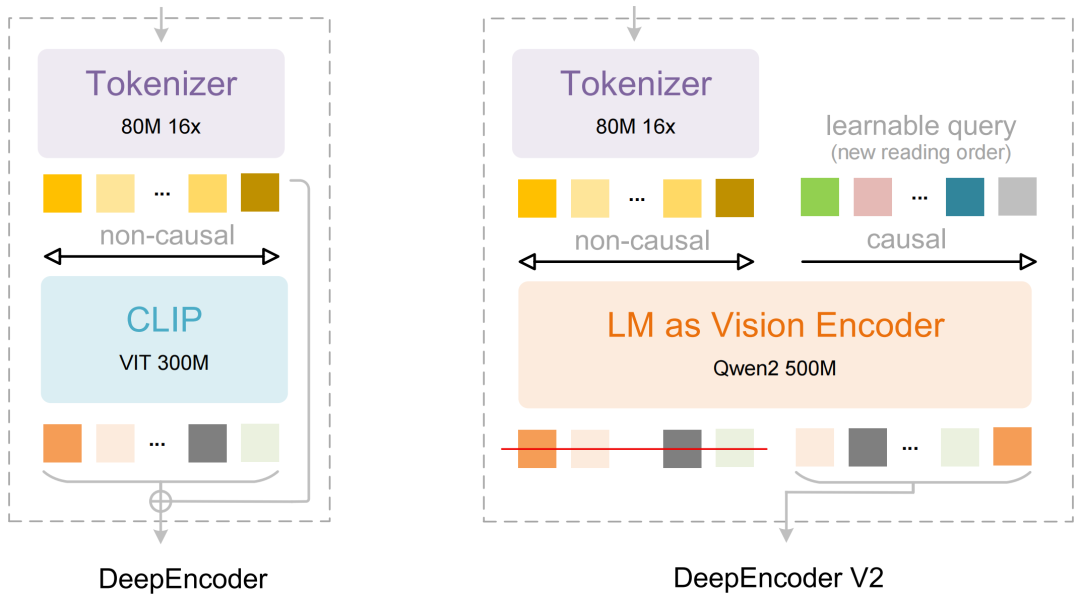
DeepSeek-OCR 2 的主要功能
-
复杂文档解析:模型能精准解析带表格、公式和多栏布局的复杂文档,还原自然阅读逻辑。
-
高效视觉压缩:仅需256到1120个视觉Token即可覆盖复杂文档页面,显著降低计算开销。
-
动态语义重排:模型通过因果流查询,根据图像语义动态调整视觉 Token 的顺序,打破传统固定扫描限制。
-
高精度识别:在OmniDocBench v1.5评测中,综合得分达到 91.09%,较前代显著提升,在阅读顺序识别方面表现出色。
DeepSeek-OCR 2 的技术原理
-
DeepEncoder V2 架构:视觉分词器将图像离散化为视觉 Token,采用 SAM-base 和两层卷积层,输出维度为 896。引入因果流查询(causal flow queries),视觉 Token 使用双向注意力,因果流查询使用因果注意力,实现语义重排。
-
因果推理机制:通过因果流查询动态重排视觉 Token,使编码器能根据图像语义动态调整 Token 的顺序。这种机制与 LLM 的单向注意力模式高度一致,能更好地贴合连续的视觉语义。
-
解码器:继续沿用 DeepSeek-OCR 的 DeepSeek-MoE Decoder,参数规模为 30 亿,约 5 亿参数在推理时激活。
-
训练流程:分为编码器预训练、查询增强和解码器专门化三个阶段,通过多阶段优化提升模型性能。
DeepSeek-OCR 2 的应用场景
-
文档处理与数字化:模型能将纸质文档快速转化为可编辑的电子文档,支持复杂布局和多语言内容的高精度识别,适用于图书馆、档案馆等机构的数字化工作。
-
学术与科研:高效解析学术论文中的公式、图表和多栏文本,辅助研究人员快速提取关键信息,提升文献整理和数据分析效率。
-
企业办公自动化:模型能自动识别合同、报表等文件中的关键信息,支持企业文档的快速审核、归档和检索,提高办公效率。
-
教育领域:将教材、试卷等文档快速数字化,支持在线教学和电子化考试,辅助师生整理学术资料,提升教学与学习效率。
-
出版与媒体:模型快速解析杂志、报纸的复杂排版,支持电子版制作和内容分发,助力媒体行业实现高效内容创作与管理。
模型 : https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
【DeepSeek-OCR-2】模型已经在趋动云『社区项目』上线,无需自己创建环境、下载模型,一键即可快速部署,快来体验【DeepSeek-OCR-2】带来的精彩体验吧!
项目入口
https://open.virtaicloud.com/web/project/detail/676678471438790656
启动开发环境
进入【DeepSeek-OCR-2】项目主页中,点击运行一下,将项目一键克隆至工作空间,『社区项目』推荐适用的算力规格,可以直接立即运行,省去个人下载数据、模型和计算算力的大量准备时间。
配置完成,点击进入开发环境,根据项目主页介绍进行部署。
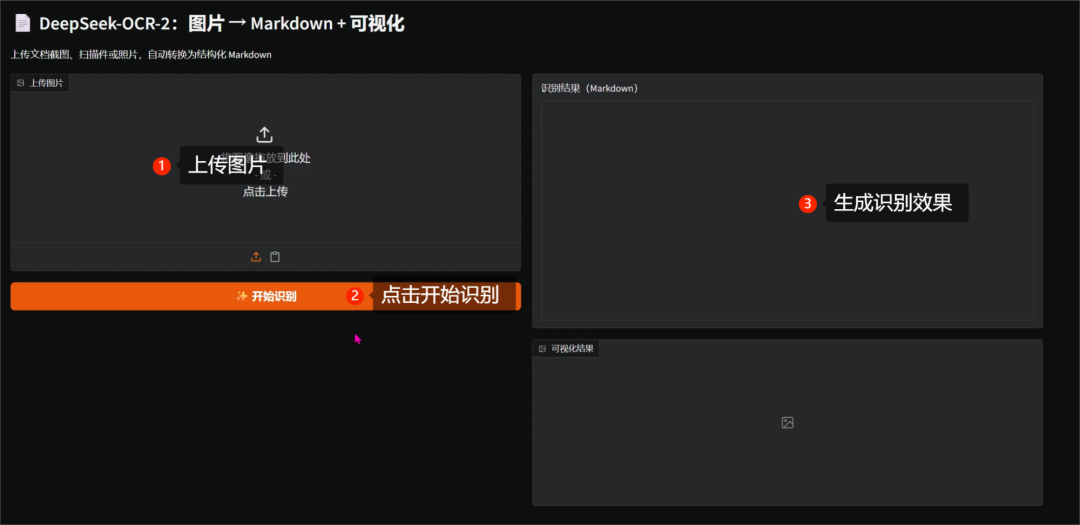
使用方法
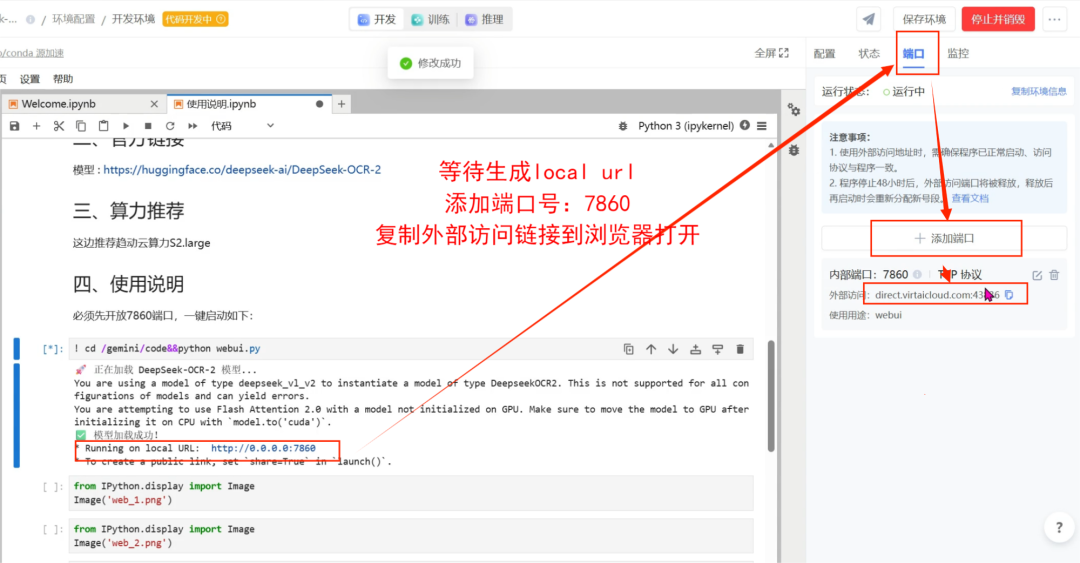
在gemini/code中找到使用说明,选中使用说明单元格,点击运行。
等待生成local URL,右侧添加端口7860。
项目使用方法
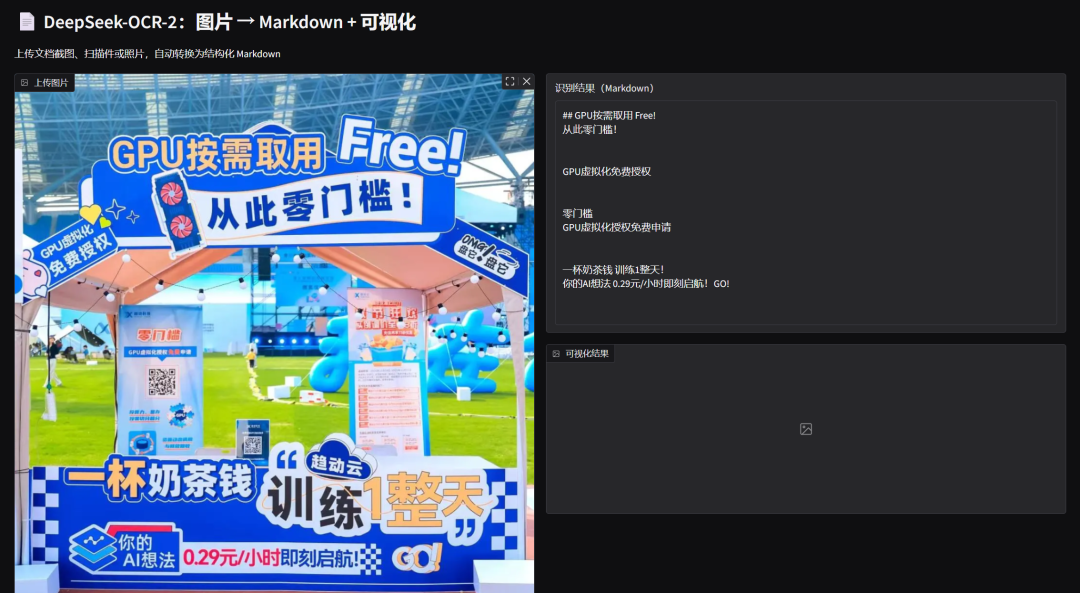
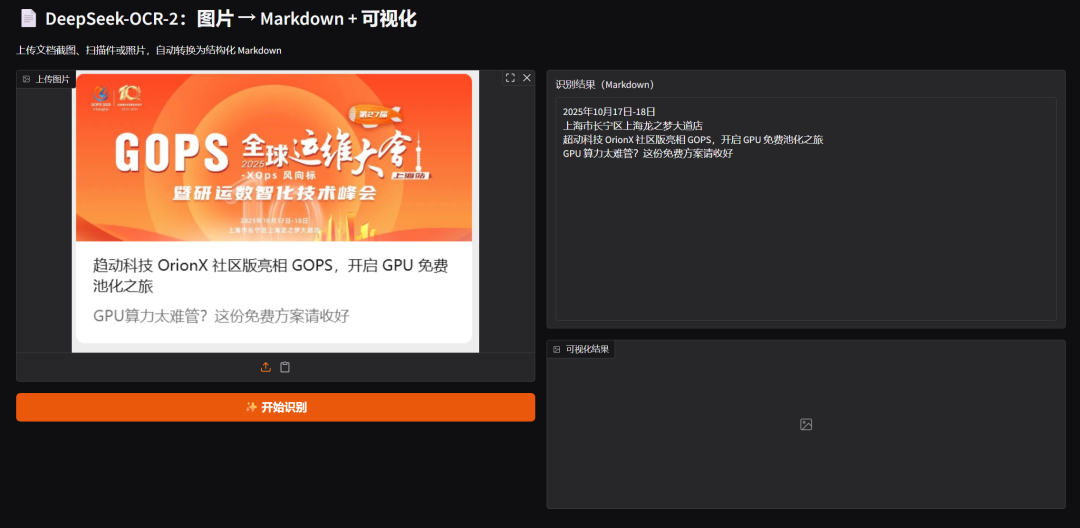
示例展示
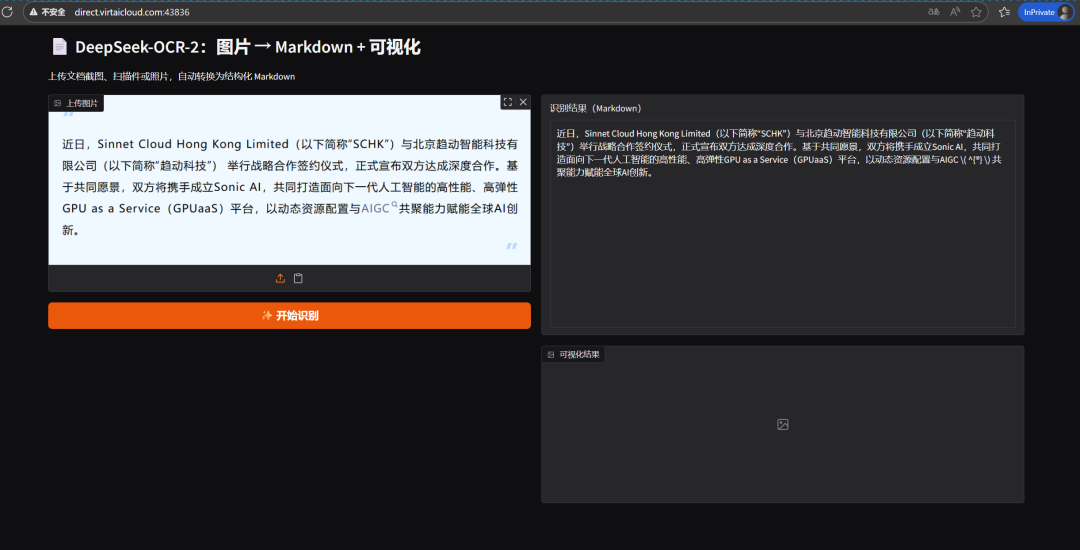
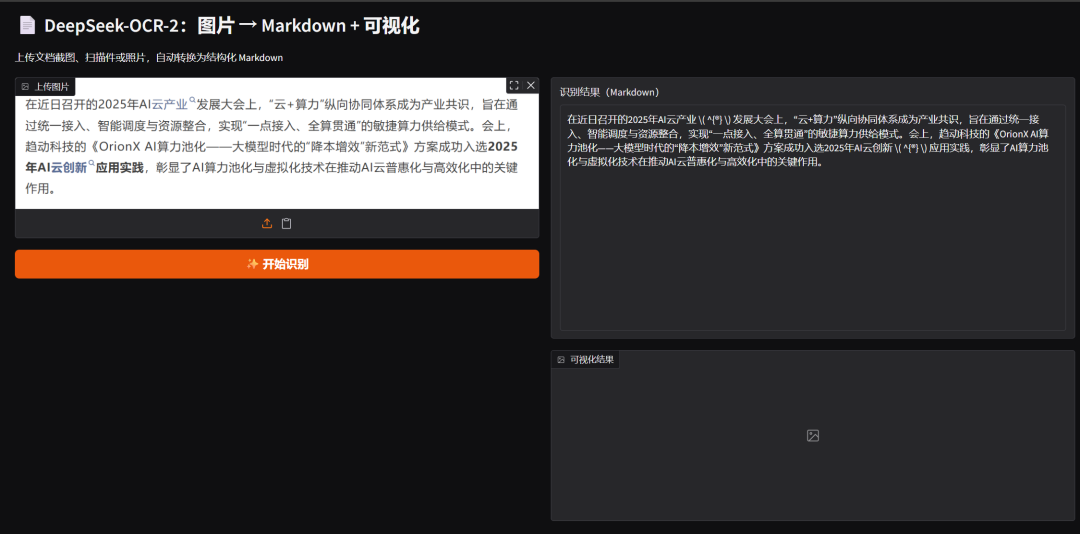
➫温馨提示: 完成项目后,记得及时关闭开发环境,以免继续产生费用!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)