本地大模型系列:1.配置本地Ollama的大模型助手
安装和配置ollama,解答一些常见问题
0.序
本文提到的所有的安装包均在百度网盘分享可以找到:https://pan.baidu.com/s/1QbPyoGq3_yOpWYvorxyPeg?pwd=8vmg
网页版(在线版)的大模型相信大家都不陌生了,只要你能够联网,就可以使用远程的大模型。
远程大模型的特点是功能强大,几乎可以做所有的事情,缺点是必须要联网,再则就是隐私问题。举个例子,我希望使用AI帮我解读一张图片,避无可避的前提是你把这张图先发给AI吧。你所有的和AI交互的内容,只要提供这项服务的供应商愿意,都可以把这些内容永久保存,感兴趣的可以了解一下豆包的隐私协议:https://www.doubao.com/legal/privacy?external=true
通过一些工具,我们是可以在本地部署大模型的,比如ollama、xreference、LM studio等。本地部署的大模型的能力肯定是不如在线大模型的,差距还是比较大的,毕竟个人电脑的性能就在那,没法跟专业计算卡相比。
但如果我们不需要太强的性能、又对隐私性要求比较高,亦或者没有网络的时候,本地大模型就可以大显身手了。
以qwen3家族为例(截止目前已经出到qwen3.5了,奈何目前ollama官方已有的模型的最低参数都是27b的,物理大小17GB,需要24G的显存的显卡才能跑起来,小用户玩不转),有专注于语言对话的qwen3、具多模态处理能力的qwen3-vl、具有向量能力的qwen3-embedding,还有ocr能力的deepseek-ocr,其实已经能帮我们完成很多工作了。并且ollama也具备本地api功能,可以通过http、python等进行调用,将其功能进行集成,对于个人来说非常方便。
当然,以上说的都是个人使用的情形,至于企业还有其他的解决方案,就不在这里讨论了。(个人使用管好自己就行,不用太考虑多并发、缓存等并发效能问题)
1.下载ollama
打开ollama官网:https://ollama.com/
找到右上角的download
选择你的平台,下载安装文件并安装
PS:ollama在windows和mac平台能够自动升级。
2.配置ollama
不同于以往,目前的ollama已经有一个UI界面了,启动以后在任务栏里面还有个图标,点开能看到下面的菜单,还有他的界面。
点击Open Ollama会打开下面的界面
这个界面一看就可以用来交互的,但是现在里面还什么都没有,我们需要下载大模型。在这之前,我们先要做一些配置。
在任务栏点开,点击Settings:
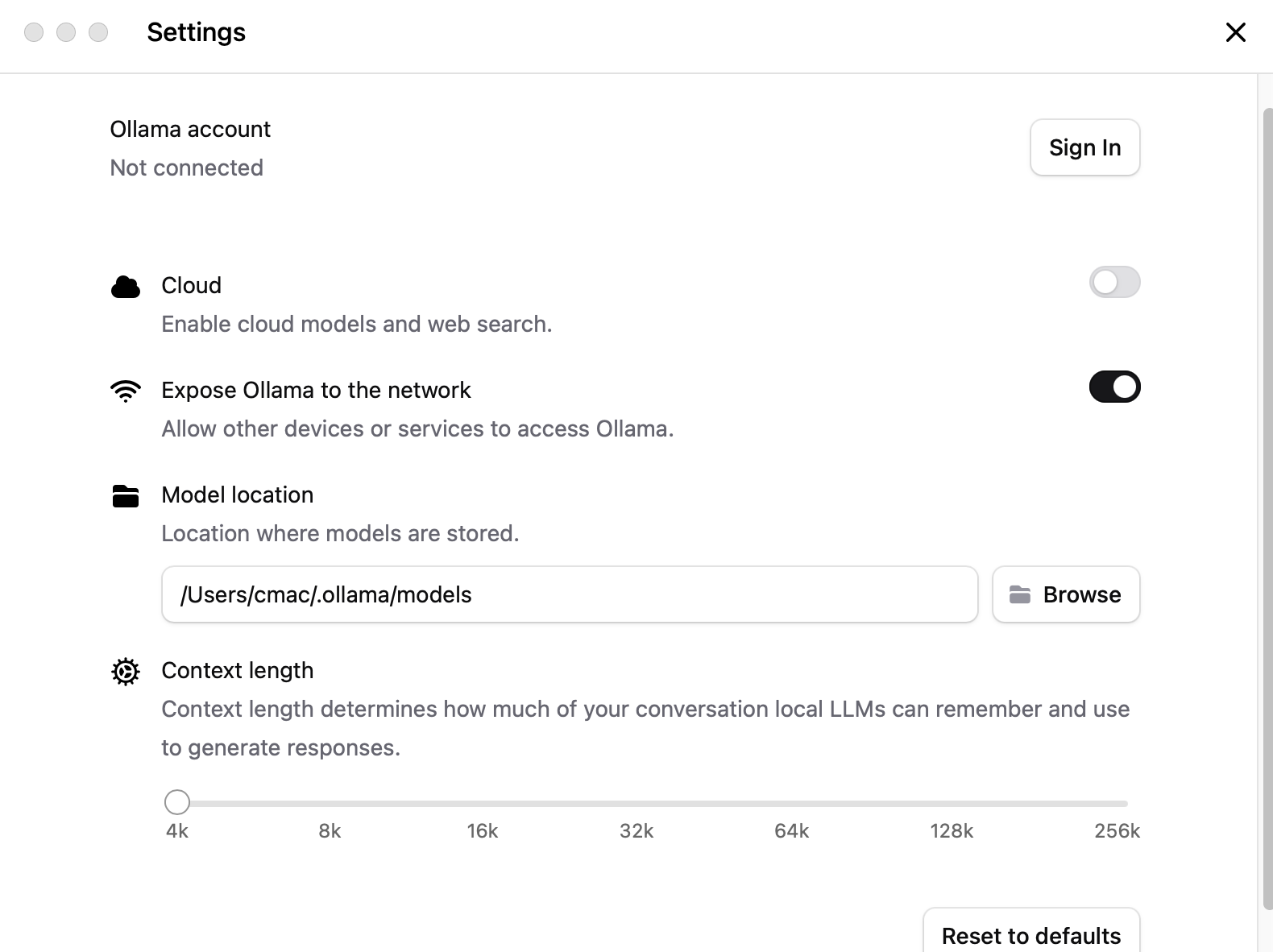
1.ollama account不需要登录也可以使用
2.cloud也不用打开,因为我们要使用的是本地模型
3.Expose ollama to the network 要打开,这样我们就可以使用ollama的api
4.Model location 要修改,这是下载大模型以后保存的位置,windows系统默认值在c盘,为了避免变成c盘展示,可以在后面的盘建一个目录,然后在这里指向这个目录
5.context length 以豆包为例,在跟豆包多轮对话以后,你会不会觉得豆包能够记住你之前问过它事情,你再提起这些事情,它也可以做出相关回答。其实在我们和豆包交互的时候,每一次都是把所有的聊天记录一并丢给豆包,而不是豆包“记住”了什么东西(惊不惊喜、意不意外),也就是说,当会话时间长了以后,豆包每次要处理内容会越来越多,因为它需要结合当前所有的内容最最合适的回答。这个context length(上下文长度)就是可以送给大模型文字的最大长度,超过这个长度就会被截断。
配置好以上以内容后,重启一次计算机。
3.下载模型
点开这个链接,就可以搜索我们需要的模型了。
我们先下载qwen3(如果你的显存够大,可以选择qwen3.5)
先搜索qwen3
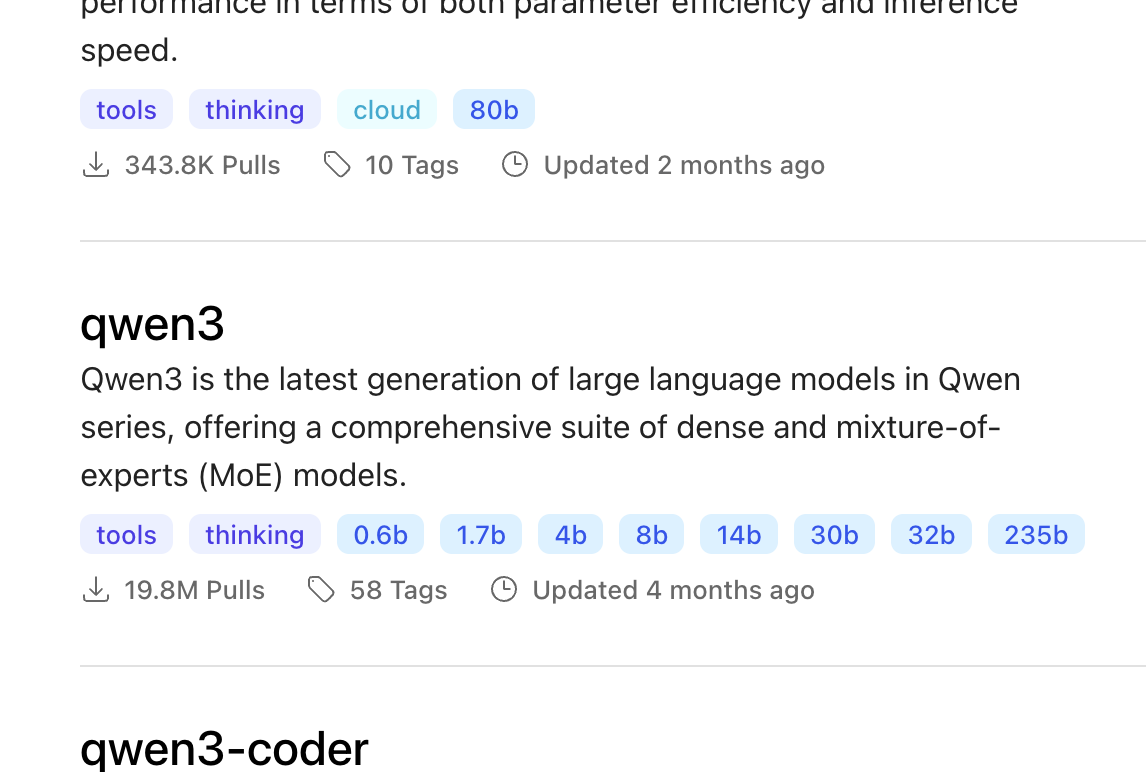
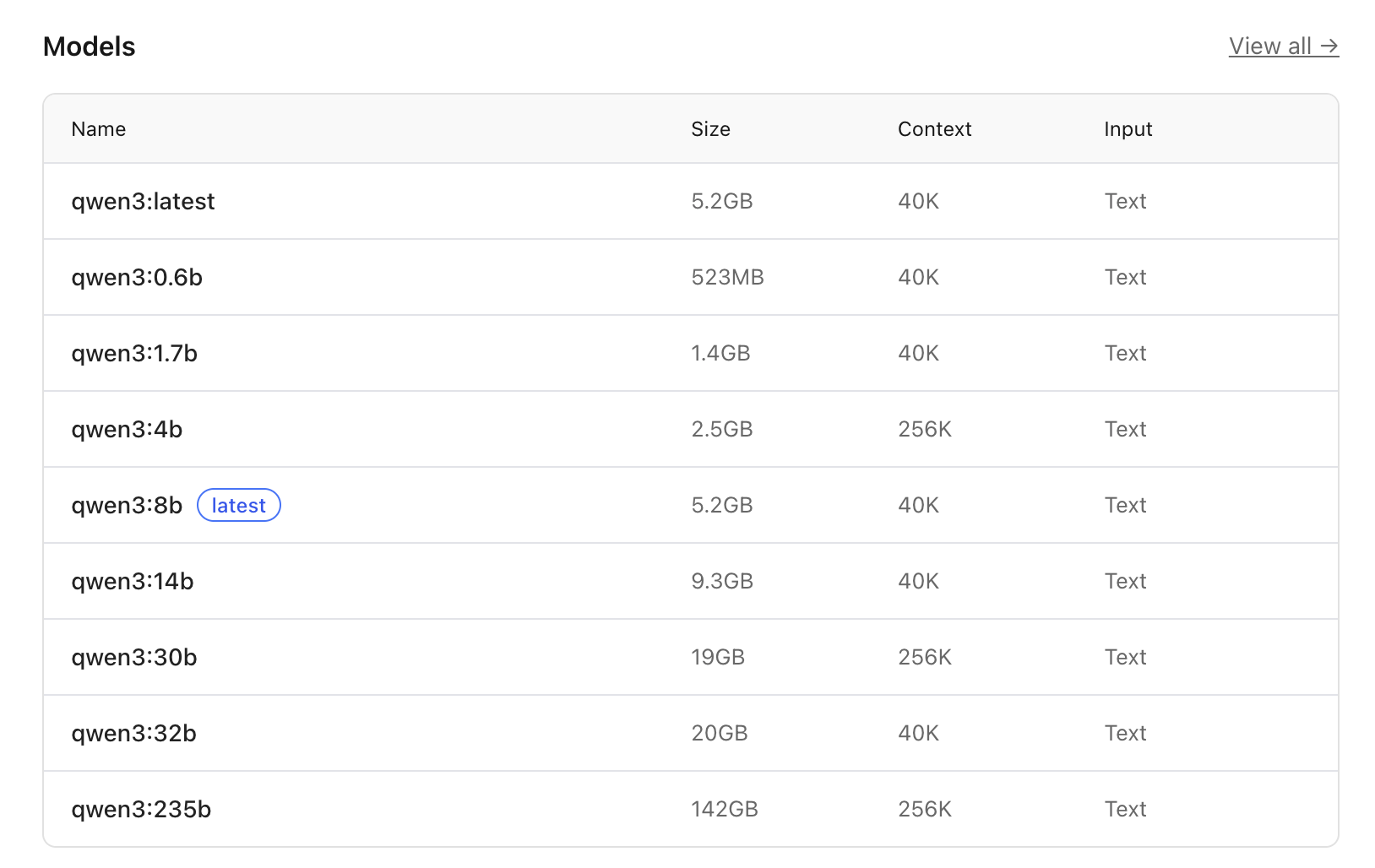
我们可以看到qwen3有很多个版本,对应不用的参数。
如果你有N卡且先配置好了显卡驱动和cuda(参见 :https://blog.csdn.net/razelan/article/details/152720013?spm=1001.2014.3001.5502),再安装ollama,那么你的ollama就能使用N卡。ollama同时支持A卡、苹果M芯片,其他不支持,民间有能够支持NPU的魔改版,但是不稳定。
以qwen3:8b为例,仅仅启动就需要占用5.2GB显存(从硬盘上先要加载到内存,再从内存加载到显存),context length越大,需要消耗的显存越多。实际加载时因显存对齐、模型元数据、GPU 驱动预留,会额外占用约 0.5~1GB,加上操作系统保留,8G显存加载6.5G的模型大约是极限,超过这个数字,大概率会变成CPU模型运行而不会使用显卡运行。
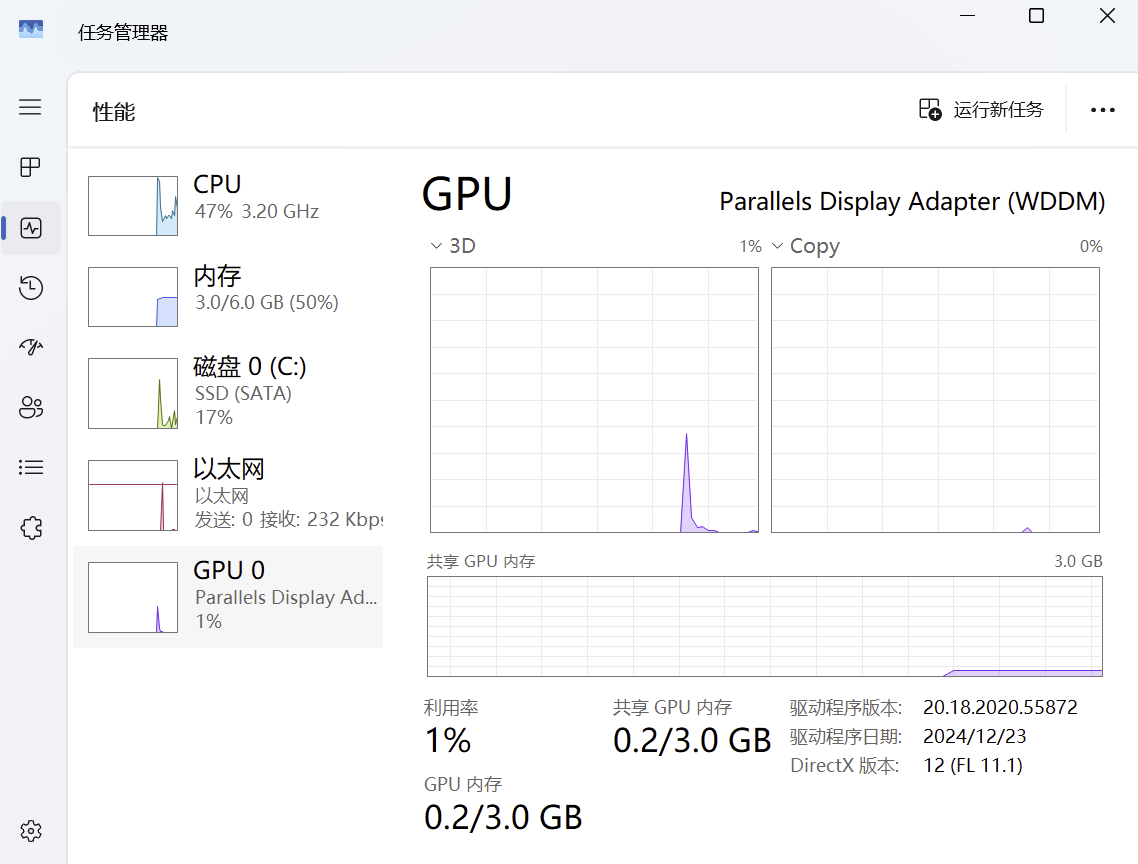
(在任务管理器--性能中通过查看内存和显存消耗的方式管家大模型究竟使用cpu还是gpu启动)
了解以上知识以后,我们就知道应当如何挑选模型了。
参数太小的模型可能会显得不那么智能,参数大的模型我们又可能背不动,在内存/显存可以负荷的上限选择一个合适的就好。
PS:模型参数越大,输出的速度越慢----很好理解,它输出文字的时候要考虑、兼顾的东西更多了。
如何下载模型:
打开cmd,输入命令:ollma --version

可以看到ollama的版本
对于比较新的模型,ollama的版本是有最低要求的。
我们使用ollama pull 模型名字的方式下载模型:
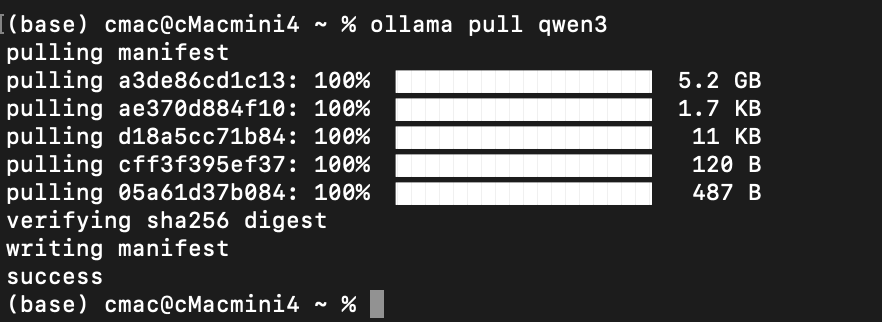
(注意:如果发现下载的速度变得很慢,只有几十k,按ctrl+c打断,重新运行pull命令,可以继续下载,速度会快一些)
严格来说,这里应该是: ollama pull qwen3:8b
但是注意在模型列表里面,8b模型后面有个latest
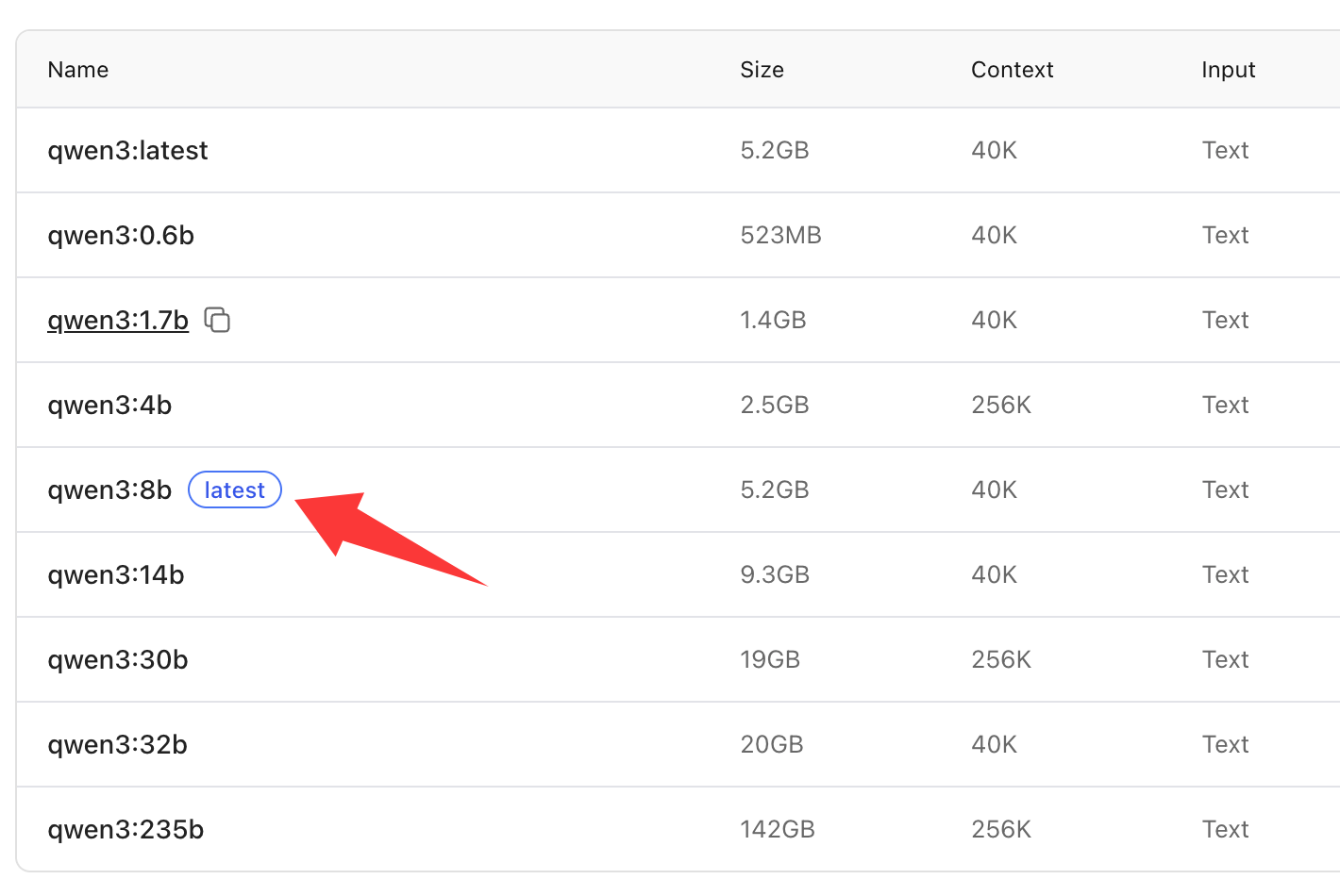
也就是说在缺省方式下(不指定参数),默认下载的是8b模型。
下载前请确认硬盘空间充足,尤其是已经修改过模型的保存路径且重启过电脑。
如果你想下载别的参数的模型(比如我想比较一下1.7b、4b、8b的实际性能),那就要在模型后指定参数,比如:ollama pull qwen3:1.7b
下载完成后,我们使用ollama list命令可以查看电脑上现有哪些模型,你也可以前往模型目录去看一下。
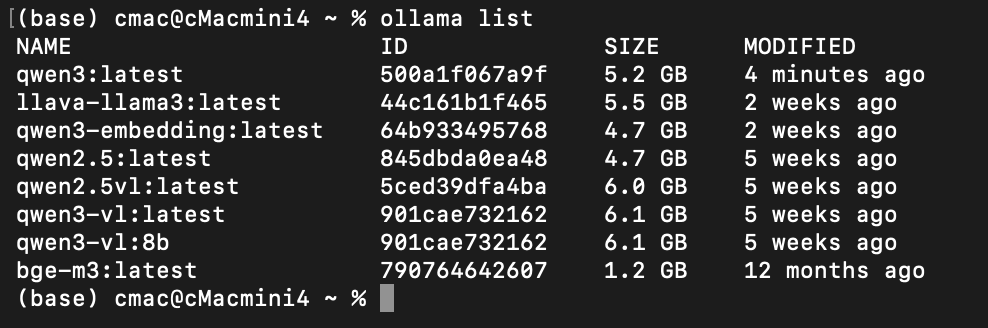
删除模型请自行百度。
4.运行模型
此时再打开ollama的界面,我们就可以看到已经有的模型了。
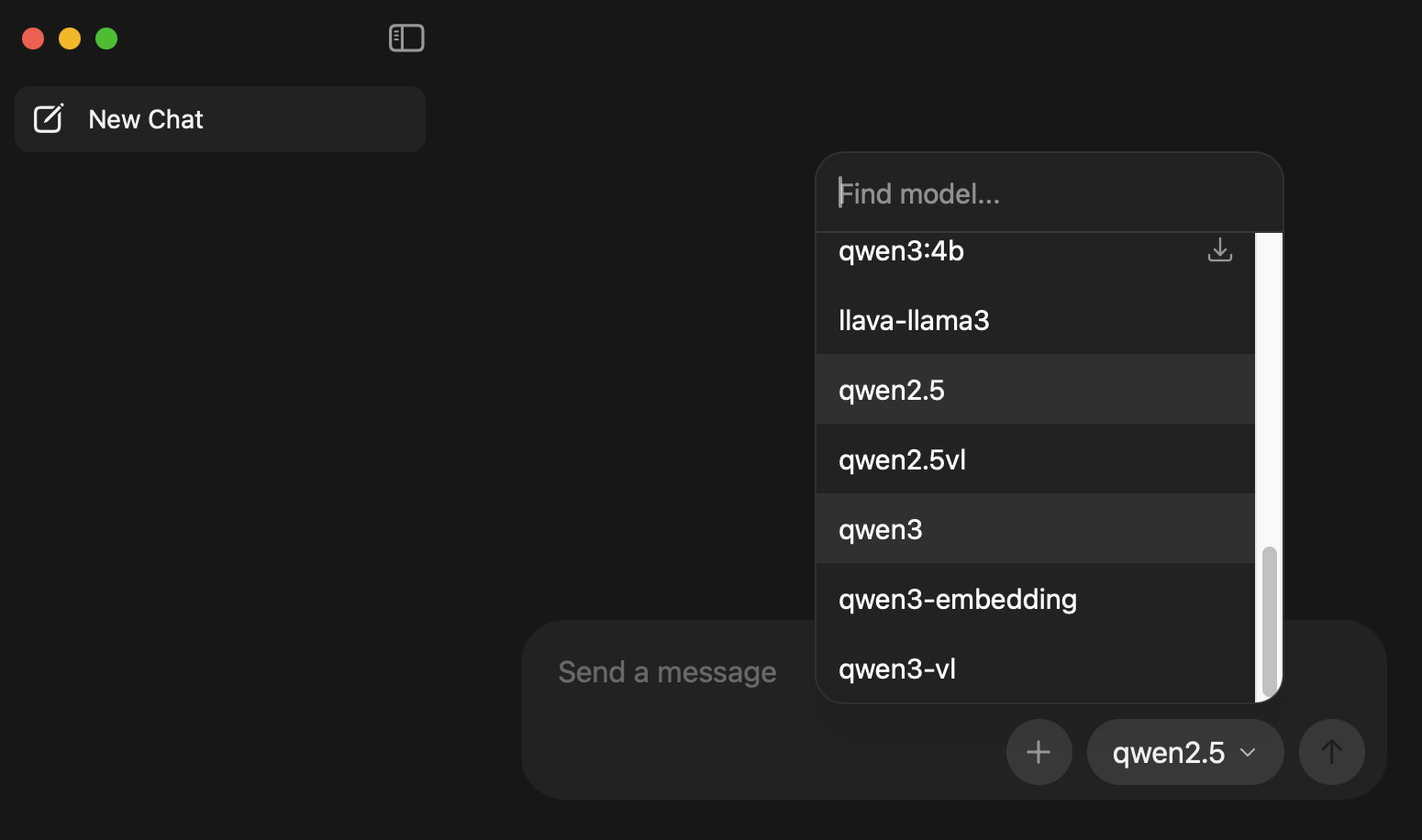
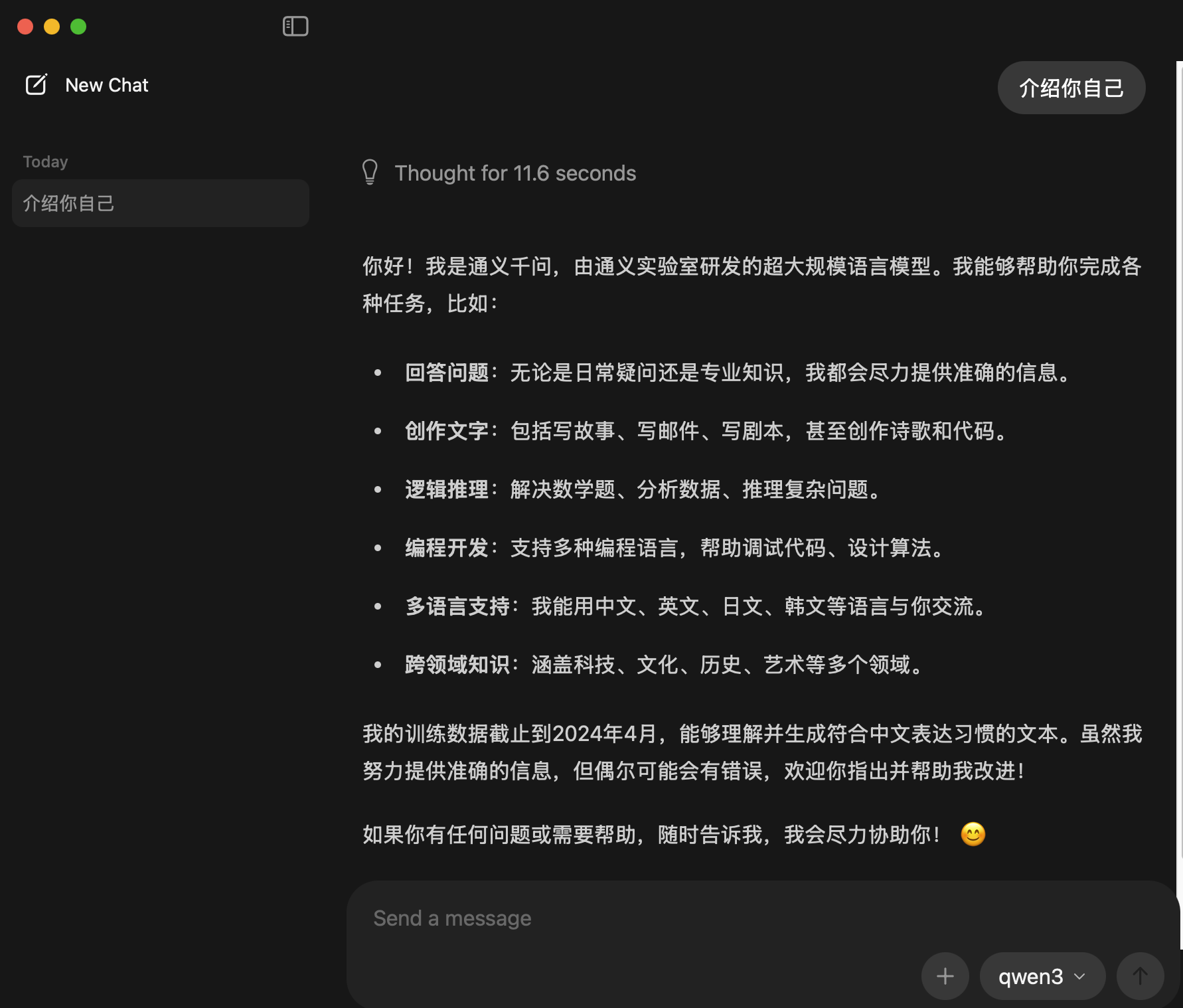
可以看到qwen3自带thinking模式。
这里解释一下thinking模式的有什么用:
与直接回答问题不同,思考模式可以帮助用户完善提问,考虑你没有考虑到的事情,我们看一下思考内容

思考模式对于问题回答的结果是相当有帮助的,但是缺点同样明显,思考是需要消耗时间的,其实你应该反思一下,什么时候需要思考模式,什么时候不需要思考模式:当你的目的很明确、提问的内容已经足以表达你的意思是,思考模式其实对回答的帮助已经不大了,还不如直接回答,例如“已知直角三角形的一条直角边为17,另外两条边各是多少”;当你对问题的描述可能都不太清晰时,思考模式就能帮上大忙,例如“给我制作一个三天两晚的珠海旅游方案”

接下来你可以对同一个问题测试一下1.7b、4b、8b的回答差异,我们选择不同的模型回答问题即可,注意模型切换后第一次回答可能需要消耗更多时间,因为ollama需要把新的模型加载进来。
5.解析图片
解析图片是多模态模型的能力,qwen3的input都是Text,说明qwen3智能处理文字,我们找到qwen3-vl,这个模型可以处理图片。
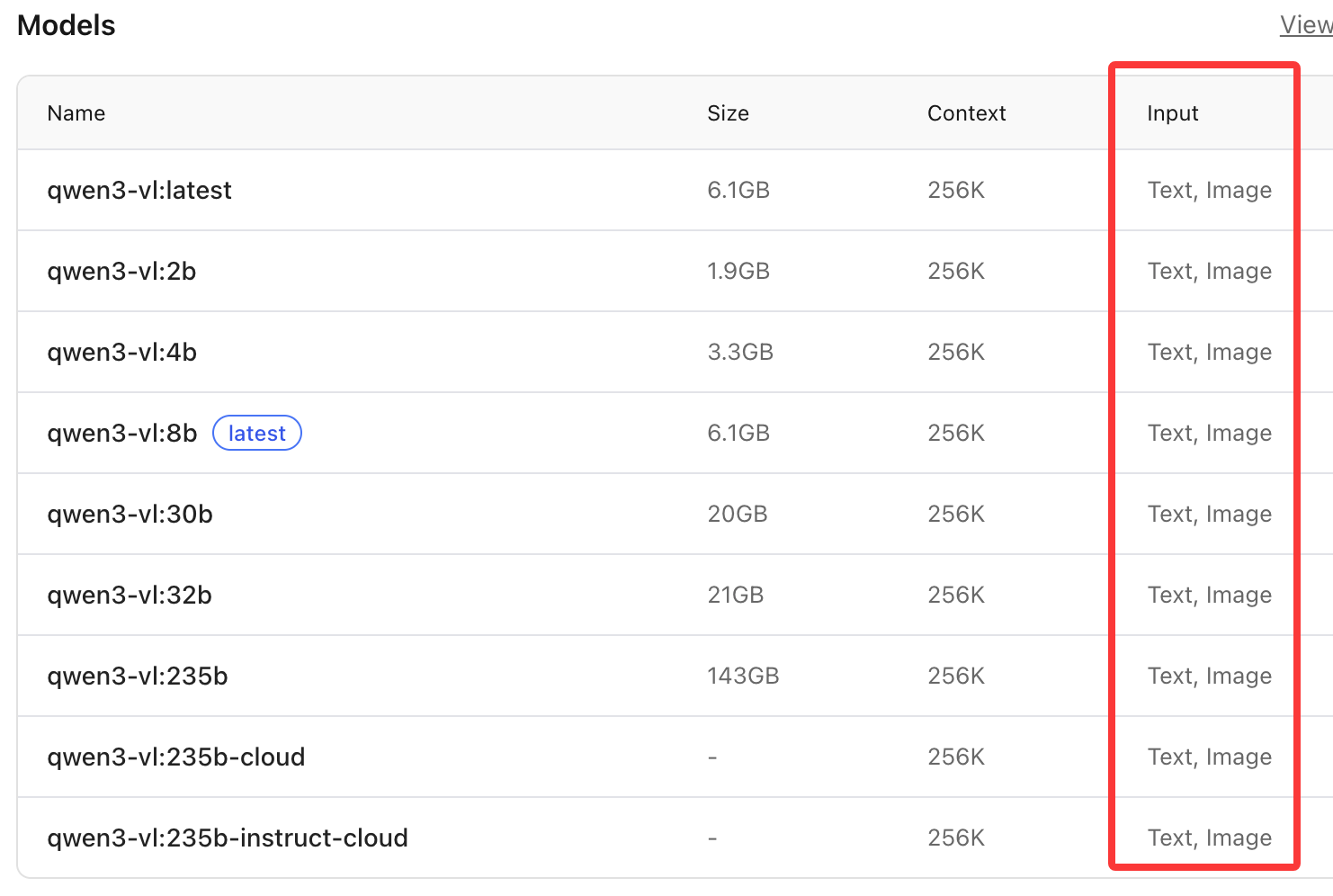
这里仍然选择8b的模型。注意同样是8b,qwen3是5.2GB,qwen3vl是6.1GB,体积要大一些,处理的速度也会要慢一些。
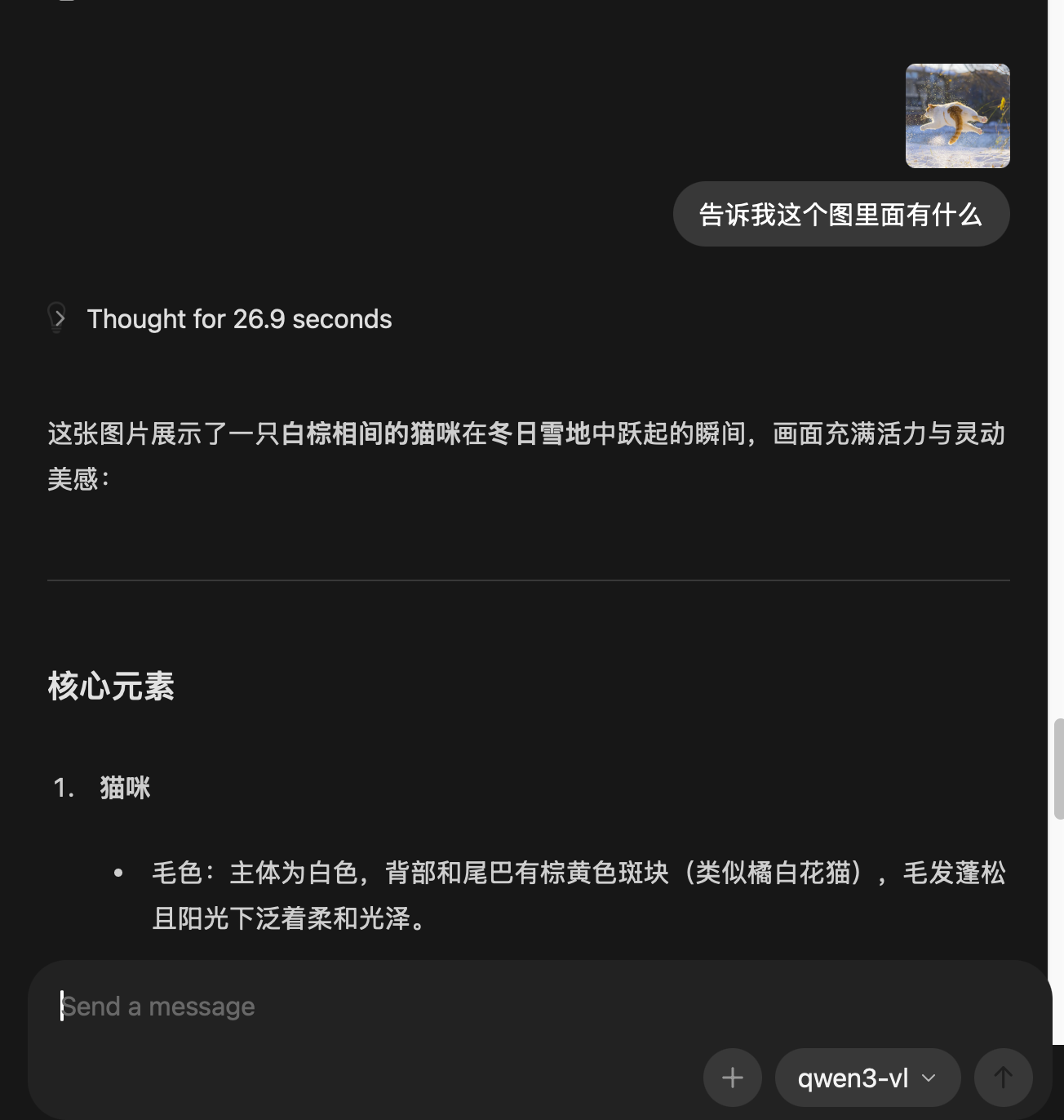
如果你觉得这个界面太过于单调,功能不太行,可以使用“chatbox”,在“https://chatboxai.app/zh“或者本文的网盘下载。
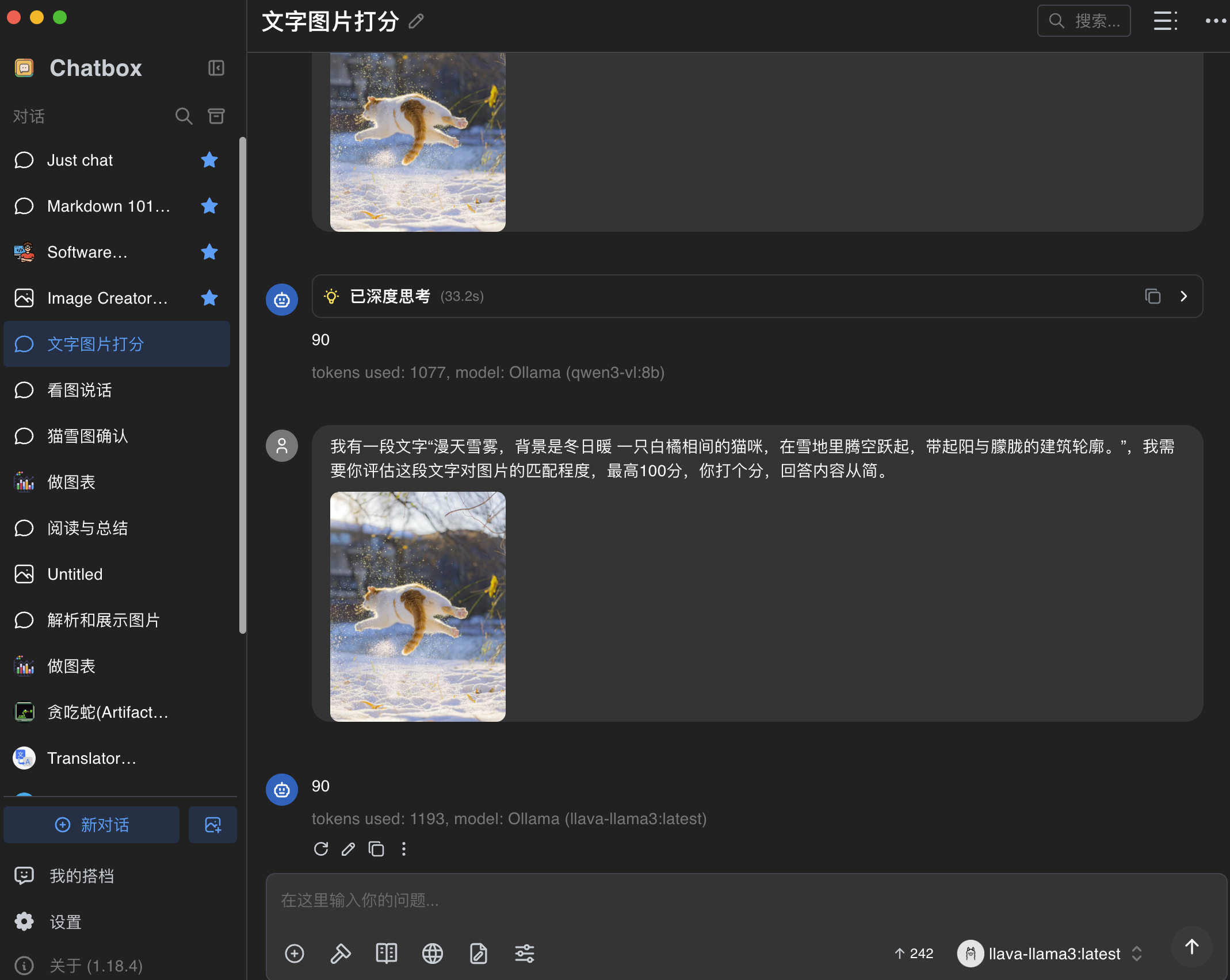
这个工具可以联网查询、上传文件、阅读网页链接等、更重要的是还有知识库功能,这个我们在下一篇介绍。
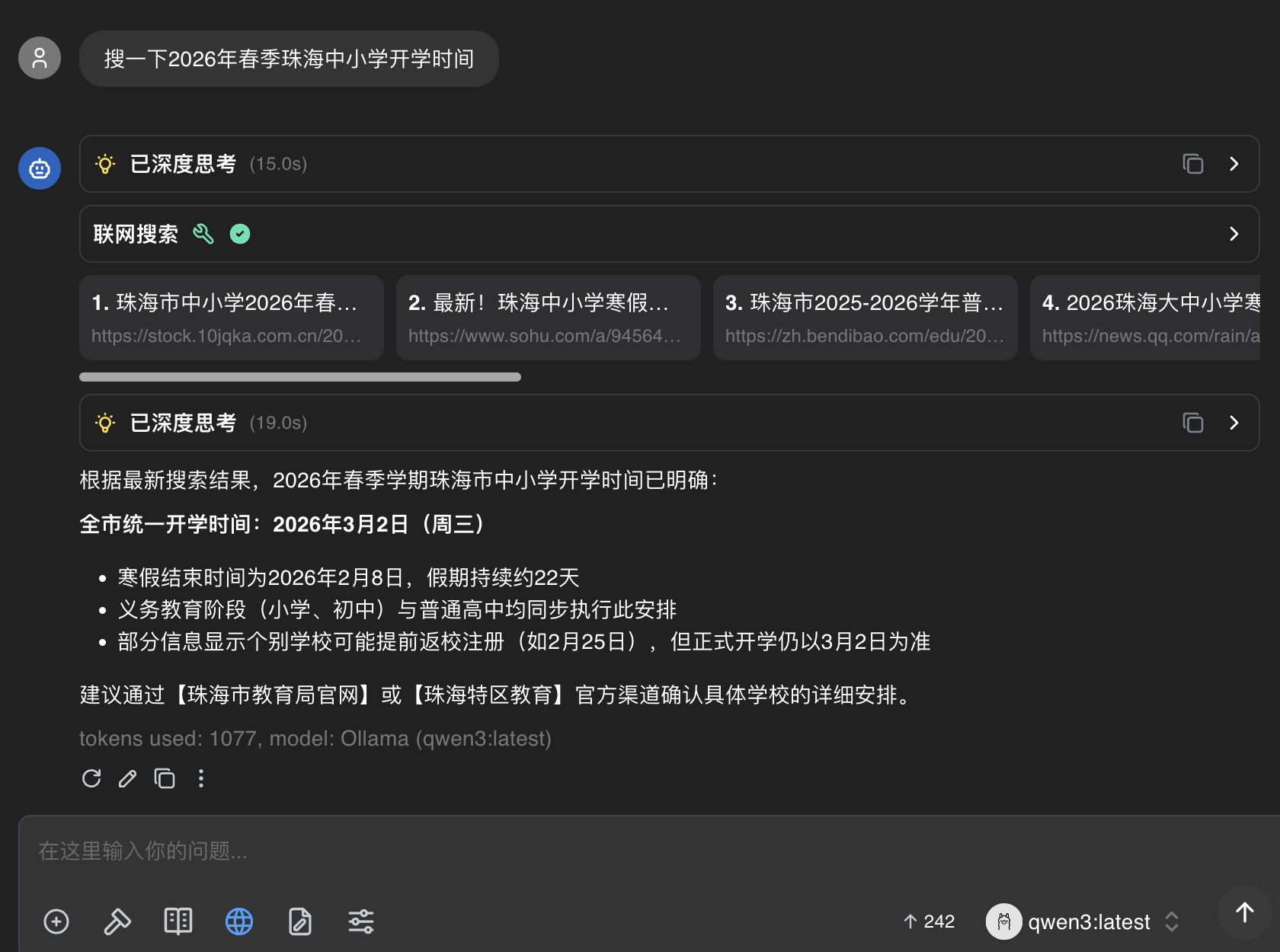
PS:这里出了个有意思的AI幻觉,竟然把3月2日识别成周三了。
无论是使用ollama自带的界面或者chatbox,其实背后都是ollama引擎在提供服务。除此之外,我们可以通过python代码跳过界面直接找ollama引擎提供服务,这些会在未来的章节继续讲解。
最后:本地大模型更重要的是为了解决隐私问题,当然如果你的显卡比较给力的话,也能够得到不错的体验效果。如果只是要提供大模型能力对隐私保护的要求不高的话,我们可以选择阿里云、chatglm、字节等多种在线方案,国内的token还是比较便宜的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)