Java数据结构
Java数据结构
数据类型
基本数据类型
包装类型
范型
| 基本类型 | 包装类型 | 长度 |
|---|---|---|
| boolean | Boolean | 1 |
| byte | Byte | 8 |
| char | Charactor | 16 |
| short | Short | 16 |
| int | Integer | 32 |
| float | Float | 32 |
| long | Long | 64 |
| double | Double | 64 |
集合
list
ArrayList
1️⃣底层实现为数组,物理内存连续
2️⃣数组扩容为n*1.5
3️⃣实现了Collection和IList接口
4️⃣modecount 使用迭代器遍历时验证多线程数据可靠-快速失败
5️⃣线程不安全
6️⃣不能存储基本数据类型
7️⃣元素可重复,可为null
8️⃣存储有序,值无序排列
9️⃣查找快,插入慢(根据index定位,扩容需要旧数据的复制)
🔟判断为空时使用isEmpty()时间复杂度为O(1)
ArrayList<Integer> stringList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
stringList.add(i);
stringList.add(i%3);
}
System.out.println(stringList);
List<Integer> list = stringList.stream().sorted(Comparator.comparing(stringList::get)).collect(Collectors.toList());
System.out.println(list);
插入排序算法
public static void main(String[] args) {
int[] arr = new int[5];
for(int i = 0; i < 5; i++){
arr[i] = (int) Math.floor(Math.random()*5+1);
}
System.out.println(Arrays.toString(arr));
sort(arr);
}
private static void sort(int[] array) {
// 从第2个元素开始遍历 前部为有序 后续插入有序队列
for(int i = 1; i < array.length; i++){
int j;
for( j = i - 1; j >= 0; ){
if(array[i] >= array[j]){
break;
}else if(j > 0){
j--;
}
}
if(i - j > 1){
int temp = array[i];
for(int k = i; k > j; k--){
array[k] = array[k -1];
}
array[j] = temp;
}
}
System.out.println(Arrays.toString(array));
}
Vector
1️⃣底层实现为数组,物理内存连续
2️⃣扩容后为当前大小2倍
3️⃣
4️⃣
5️⃣线程安全(增删查方法使用synchronized修饰,线程安全-单独每一个方法是安全的,组合后的的方法存在线程不安全)
6️⃣判断为空时使用isEmpty()时间复杂度为O(1)
7️⃣值可重复可为null
8️⃣存储有序,值无序排列
9️⃣排列有序可重复,增删慢
Vector<byte[]> vector = new Vector<>(2);
for (int i = 0; i < 100; i++) {
byte[] bytes = new byte[1024 * 1024*10];
// Thread.sleep(5000);
vector.add(null);
vector.add(null);
}
Iterator iterator = vector.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println(Arrays.toString(vector.toArray()));
LinkedList
1️⃣底层实现:双向链表结构,实现list接口,物理空间可不连续,无大小限制
2️⃣扩容后为当前大小2倍
3️⃣
4️⃣
5️⃣线程不安全
6️⃣
7️⃣元素可重复可为null
8️⃣判断为空时使用isEmpty()时间复杂度为O(1)
9️⃣增删快
定义:
LinkedList<String> linkedList = new LinkedList<>();
for (int i = 0; i < 10; i++) {
linkedList.add("我是第" + i + "个元素");
linkedList.addFirst("我是第" + i + "个元素");
linkedList.addLast("我是第" + i + "个元素");
}
linkedList.add(null);
linkedList.add(null);
linkedList.remove();
System.out.println(linkedList);
| array | ArrayList | Vector | LinkedList | |
|---|---|---|---|---|
| 大小 | 长度固定 | . 动态扩容 | .动态扩容 | .内存不连续,长度不限 |
| 数据类心 | 存储基本数据类型 | .存储包装类型 | 存储包装类型 | 存储包装类型 |
| 性能 | 直接读取内存 | . 存储基本数据类型需要扩容及开箱装箱 | .同左 | .遍历慢于数组,适合小数据量头尾增删 |
| 多线程 | 线程不安全 | .线程不安全 | .线程安全 | .线程不安全 |
| . | . | . |
| . | ||
|---|---|---|
| IntArrayList | 存储 int 类型 | .无装箱拆箱,性能提升 5~10 倍 |
| LongArrayList | .无装箱拆箱,性能提升 5~10 倍 | |
| TIntArrayList | 存储 int 类型 | 开源库,轻量、高性能 |
| java.nio.Buffer | 底层字节 / 基本类型存储 | JDK 内置,无额外依赖 |
多线程环境考虑线程安全除了使用Collections.synchronizedList() ,还可以使用CopyOnWriteArrayList/AtomicIntegerArray/AtomicLongArray,操作数居前,可根据需要在代码块外部使用synchronized保护
Set
HashSet
1️⃣底层实现:hashmap
2️⃣线程不安全
3️⃣排列无序
4️⃣允许null值
5️⃣判断为空时使用isEmpty()时间复杂度为O(1)
6️⃣
7️⃣
8️⃣
9️⃣
HashSet<Integer> set = new HashSet<>();
set.add(1);
set.add(3);
set.add(2);
set.add(4);
set.add(9);
set.add(6);
set.add(4);
System.out.println(set);

TreeSet
1️⃣底层实现:treemap,底层实现是二叉树,sortedset接口的实现
2️⃣元素有序存储
3️⃣元素不能重复
4️⃣需要实现比较的方法(integer和string默认比较,实现compareTo(Person o),重写compare(String s1, String s2))
5️⃣读取相对较慢
6️⃣判断为空时使用isEmpty()时间复杂度为O(1)
7️⃣
8️⃣
9️⃣
TreeSet<Integer> set = new TreeSet<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2);
}
});
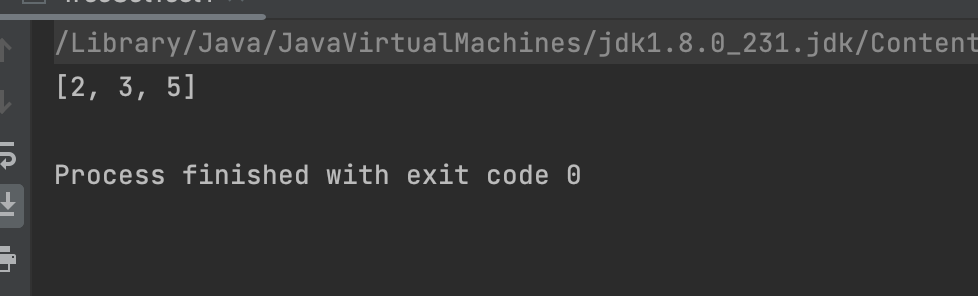
set.add(2);
String ss = "";
Arrays.sort(ss.toCharArray());
set.add(5);
set.add(2);
set.add(2);
set.add(3);
System.out.println(set);
LinkedHashSet
1️⃣底层实现:实现为:hashset,linkedhashmap
2️⃣线程不安全
3️⃣排列无序
4️⃣允许null值
5️⃣判断为空时使用isEmpty()时间复杂度为O(1)
6️⃣
7️⃣
8️⃣
9️⃣
Map
HashMap
1️⃣底层实现:数组➕链表(红黑树),扩容为2倍,扩容后重新分布,当链表长度大于8且数组长度大于64时,链表转红黑树,当链表长度小于6时,红黑树转链表
2️⃣线程不安全
3️⃣key可以为null,不可重复
4️⃣value可以为null
5️⃣使用entry遍历/使用Map.foreach()遍历,foreach遍历时不能操作元素-快速失败
6️⃣使用iterator操作元素
7️⃣重写key对象的hashcode和equals方法
8️⃣数组被撑大后 无法恢复
9️⃣
🔟
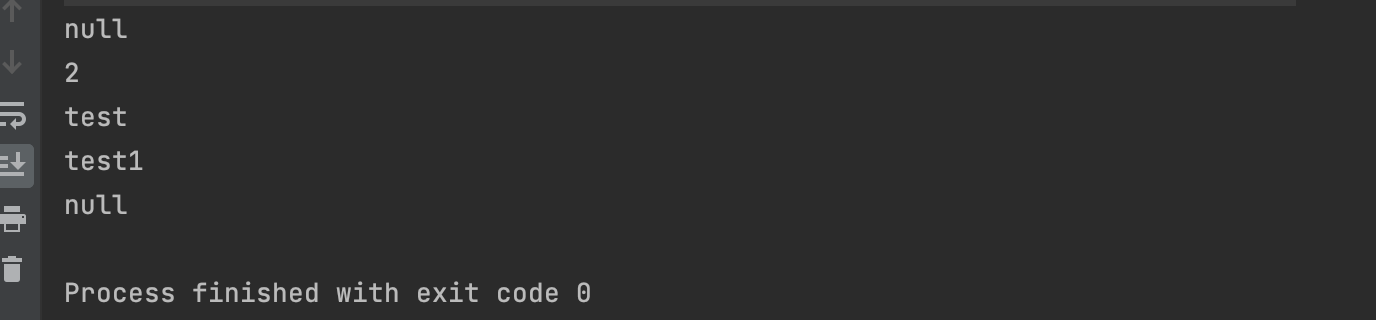
Map map = new HashMap<>(16);
map.put(null, "test");
System.out.println(map.putIfAbsent("test",new Object()));
map.put("test", "test1");
Random rand = new Random(47);
for(int i = 0; i < 10000; i++) {
map.put("value" +i,"value");
}
for(int i = 0; i < 10000; i++) {
map.remove("value" +i,"value");
}
System.out.println(map.size());
System.out.println(map.get(null));
map = Collections.synchronizedMap(map);
// map.put("","");
System.out.println(map.putIfAbsent("test",new Object()));
System.out.println(map.put("1","1"));
map.remove("");
ConcurrentHushMap
1️⃣底层实现为数组+链表(红黑树)类HashMap
2️⃣线程安全(cas+synchronized 锁链表或红黑树的头节点,使用尾插法)
3️⃣key,value不能为空–安全失败机制
4️⃣
5️⃣
6️⃣
7️⃣
8️⃣
9️⃣
🔟
线程安全:
1.7之前使用segment数组默认16,每个segment段包含若干链表,因此锁的粒度较大,效率较低,由segment数组大小决定,且初始化后不可修改 尝试获取锁时,存在并发竞争 自旋 阻塞 继承reentrantlock
1.8开始锁的粒度变小,只锁链表或者红黑树的头节点,使用尾插法,因此,支持的并发数量由数组的大小决定,可随着扩容提升 cas+synchronized
安全失败:
这是因为当通过 get(k) 获取对应的 value 时,如果获取到的是 null 时,无法判断,它是 put(k,v) 的时候 value 为 null,还是这个 key 从来没有添加。假如线程 1 调用 map.contains(key) 返回 true,当再次调用 map.get(key) 时,map 可能已经不同了。因为可能线程 2 在线程 1 调用 map.contains(key) 时,删除了 key,这样就会导致线程 1 得到的结果不明确,产生多线程安全问题,因此,ConcurrentHashMap 的 key 和 value 不能为 null。其实这是一种安全失败机制(fail-safe),这种机制会使你此次读到的数据不一定是最新的数据。
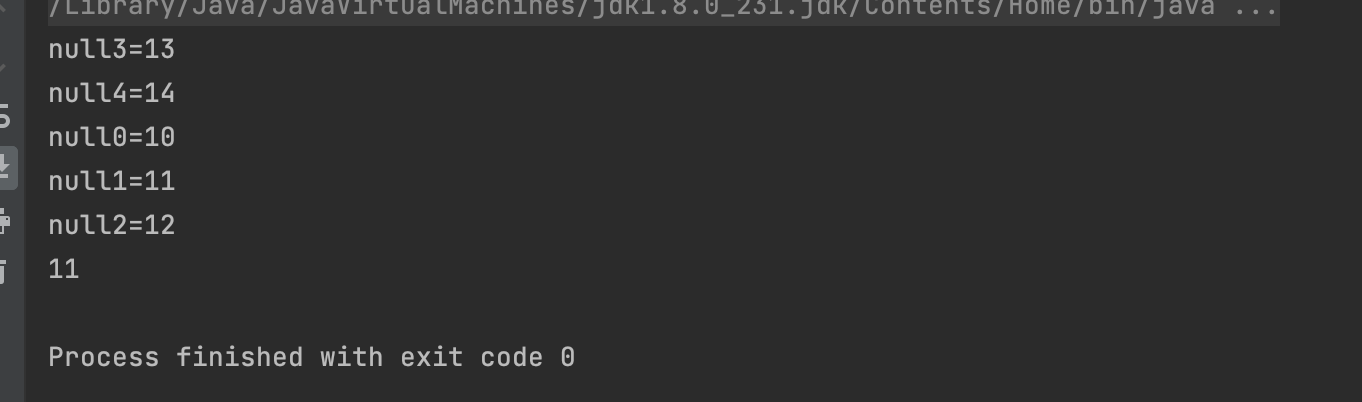
public static void main(String[] args) {
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>(16);
for (int i = 0; i < 5; i++) {
map.put("null"+i, "1" + i);
}
for (Map.Entry entry: map.entrySet()) {
System.out.println(entry);
}
System.out.println(map.get("null1"));
}
Hashtable
1️⃣底层实现为hash表
2️⃣线程安全,方法加synchronized关键字
3️⃣key,value不允许为null
4️⃣
5️⃣
6️⃣
7️⃣
8️⃣
9️⃣
🔟
Hashtable<String, String> objectObjectHashtable = new Hashtable<>();
objectObjectHashtable.put("test", "asdada");
// objectObjectHashtable.put(null, "asdasd");
System.out.println(objectObjectHashtable.toString());
{test=asdada}
Process finished with exit code 0
key为null时报错
Hashtable<String, String> objectObjectHashtable = new Hashtable<>();
objectObjectHashtable.put("test", "asdada");
objectObjectHashtable.put(null, "asdasd");
System.out.println(objectObjectHashtable.toString());
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:465)
at com.fc.base.collections.map.HashTableTest1.main(HashTableTest1.java:20)
at com.fc.base.collections.map.HashTableTest1.main(HashTableTest1.java:15)
Process finished with exit code 1
TreeMap
1️⃣底层实现为二叉树
2️⃣key 对象需要实现comparable接口或是integer类型
3️⃣使用迭代器遍历的结果为集合内部排序结果
4️⃣
5️⃣
6️⃣
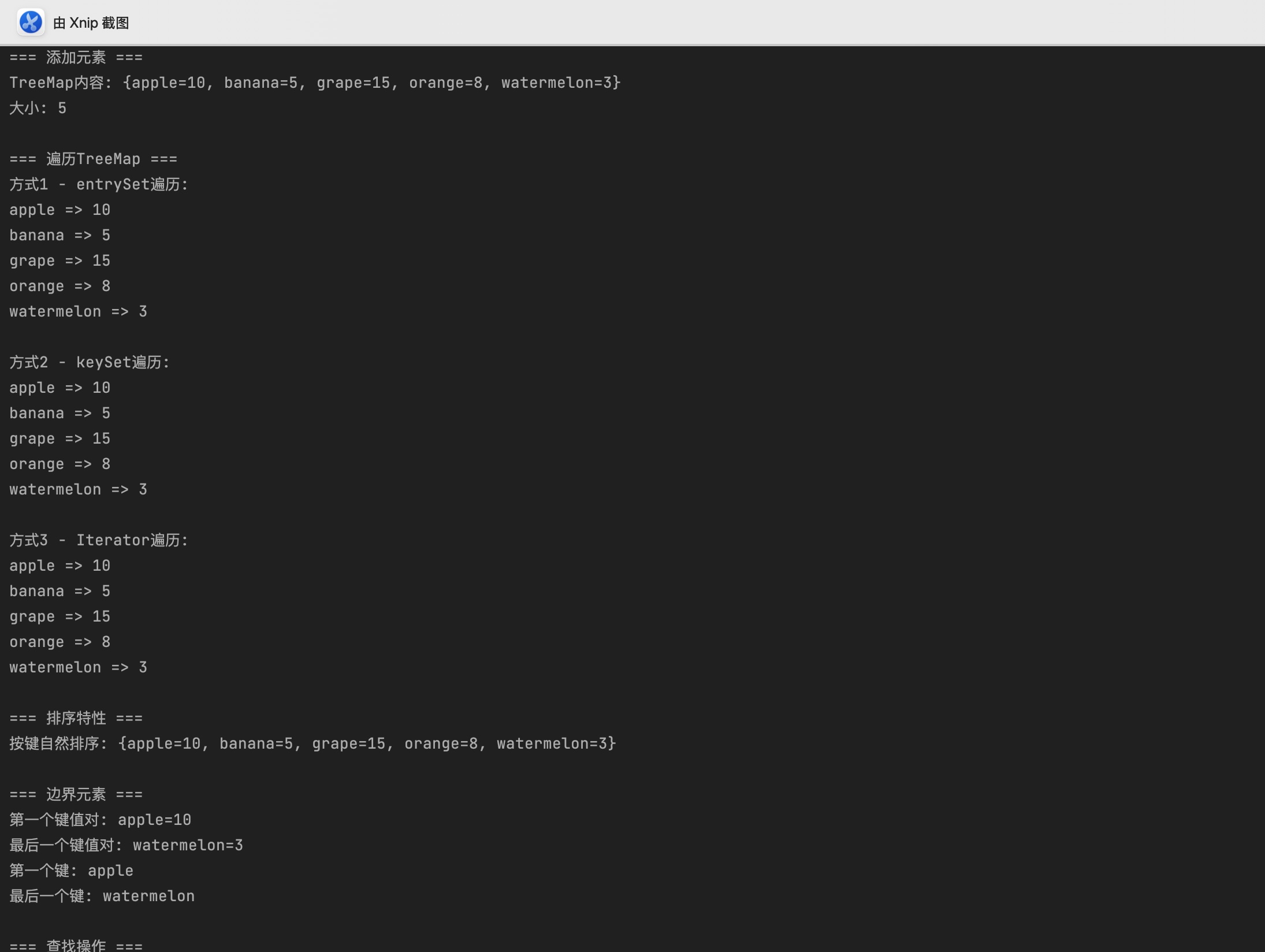
// 创建TreeMap实例
TreeMap<String, Integer> treeMap = new TreeMap<>();
// 1. 添加元素
System.out.println("=== 添加元素 ===");
treeMap.put("apple", 10);
treeMap.put("banana", 5);
treeMap.put("orange", 8);
treeMap.put("grape", 15);
treeMap.put("watermelon", 3);
System.out.println("TreeMap内容: " + treeMap);
System.out.println("大小: " + treeMap.size());
// 2. 遍历TreeMap
System.out.println("\n=== 遍历TreeMap ===");
// 方式1: 使用entrySet
System.out.println("方式1 - entrySet遍历:");
for (Map.Entry<String, Integer> entry : treeMap.entrySet()) {
System.out.println(entry.getKey() + " => " + entry.getValue());
}
// 方式2: 使用keySet
System.out.println("\n方式2 - keySet遍历:");
for (String key : treeMap.keySet()) {
System.out.println(key + " => " + treeMap.get(key));
}
// 方式3: 使用Iterator
System.out.println("\n方式3 - Iterator遍历:");
Iterator<Map.Entry<String, Integer>> iterator = treeMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println(entry.getKey() + " => " + entry.getValue());
}
// 3. 排序特性测试
System.out.println("\n=== 排序特性 ===");
System.out.println("按键自然排序: " + treeMap);
// 4. 获取边界元素
System.out.println("\n=== 边界元素 ===");
System.out.println("第一个键值对: " + treeMap.firstEntry());
System.out.println("最后一个键值对: " + treeMap.lastEntry());
System.out.println("第一个键: " + treeMap.firstKey());
System.out.println("最后一个键: " + treeMap.lastKey());
// 5. 查找相关操作
System.out.println("\n=== 查找操作 ===");
System.out.println("是否包含键'apple': " + treeMap.containsKey("apple"));
System.out.println("是否包含值10: " + treeMap.containsValue(10));
System.out.println("'banana'对应的值: " + treeMap.get("banana"));
// 6. 范围查询
System.out.println("\n=== 范围查询 ===");
System.out.println("大于等于'banana'的子map: " + treeMap.tailMap("banana"));
System.out.println("小于'orange'的子map: " + treeMap.headMap("orange"));
System.out.println("'banana'到'orange'之间的子map: " + treeMap.subMap("banana", "orange"));
// 7. 修改和删除
System.out.println("\n=== 修改和删除 ===");
treeMap.put("apple", 20); // 更新值
System.out.println("更新后: " + treeMap);
Integer removedValue = treeMap.remove("grape");
System.out.println("删除'grape'后的map: " + treeMap);
System.out.println("被删除的值: " + removedValue);
// 8. 清空操作
System.out.println("\n=== 清空操作 ===");
treeMap.clear();
System.out.println("清空后大小: " + treeMap.size());
System.out.println("是否为空: " + treeMap.isEmpty());
// 9. 自定义比较器示例
System.out.println("\n=== 自定义比较器示例 ===");
TreeMap<Integer, String> reverseMap = new TreeMap<>((a, b) -> b.compareTo(a)); // 逆序排列
reverseMap.put(1, "first");
reverseMap.put(3, "third");
reverseMap.put(2, "second");
System.out.println("逆序TreeMap: " + reverseMap);
LinkedHashMap
1️⃣底层实现为双向链表
2️⃣modifycount
3️⃣有序存储–存储顺序
4️⃣初始化时可以设置是否对访问的记录进行排序,通过get/put操作的元素会移到队尾
5️⃣重写get方法查找重排序
6️⃣
7️⃣
8️⃣
9️⃣
🔟
LinkedHashTreeMap
1️⃣
2️⃣
3️⃣
4️⃣
5️⃣
6️⃣
7️⃣
8️⃣
9️⃣
🔟
Collections.synchronizedMap(方法包装不安全的对象)
map = Collections.synchronizedMap(map);

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)