原生Agent生产级模型MiniMax-M2.5概述
MiniMax-M2.5是MiniMax公司2026年推出的新一代开源文本模型,采用2300亿参数的MoE架构(推理仅激活100亿参数),在编程、工具调用和办公场景三大领域实现显著能力跃升。其创新技术包括Forge原生AgentRL框架、CISPO算法和LightningAttention架构,使推理成本降至主流模型的1/10-1/20(每小时约1美元)。该模型支持INT4量化,可在单张RTX30

MiniMax-M2.5是MiniMax公司于2026年2月12日发布的新一代文本模型,定位为"原生Agent生产级模型",并于次日(2月13日)在魔搭ModelScope平台全球开源。作为M2系列的第三个主要版本,M2.5在108天的迭代周期中实现了显著的能力跃迁,特别是在编程、工具调用与搜索、以及办公场景三大核心领域。该模型采用混合专家模型(MoE)架构,总参数规模达2300亿,但推理时仅激活100亿参数,实现了"小身材、大能力"的技术突破。通过自研的Forge原生Agent RL框架、CISPO算法和创新Reward设计,M2.5在保持行业顶尖性能的同时,将推理成本降至主流模型的1/10至1/20,实现了"每小时1美元"的经济模型突破。这一技术与商业的双重创新,正在重新定义Agent时代的AI经济模型,推动AI从实验室工具转变为"用得起的员工",为中小企业和个人开发者打开了AI普惠化的新局面。
一、模型架构与技术原理
1.1 基本架构设计
MiniMax-M2.5采用混合专家模型(MoE)架构,总参数规模达2300亿,但推理时仅激活100亿参数,实现了参数规模的"瘦身"与性能的"增肌"。这种设计使得模型在保持行业领先性能的同时,大幅降低了计算资源需求,为低成本部署奠定了基础。
MoE架构的核心优势在于其稀疏激活机制,即模型在推理过程中仅调用与当前任务相关的专家网络,而非全部参数。这种机制使得M2.5能在100亿激活参数的规模下,达到与2300亿参数模型相当的性能水平。模型通过动态路由策略选择最适合当前任务的专家网络,既保证了性能,又大幅提升了能效比。
1.2 Forge原生Agent RL框架
Forge是M2.5的核心技术创新之一,它是一种专为Agent场景设计的强化学习框架,通过解耦训练引擎与Agent,实现了对任意Agent脚手架和工具的泛化优化。Forge框架的两大核心技术突破在于:
- 异步调度策略:采用Windowed FIFO机制,解决了传统RL训练中的"掉队者效应"问题。在同步调度中,一个高延迟的任务会导致整个队列阻塞;在贪心异步调度中,虽然硬件利用率提高,但会造成训练数据分布偏移。Forge框架通过窗口化管理,既避免了队列阻塞,又保持了训练数据分布的稳定性,显著提高了训练效率。
- 树状合并训练样本策略:通过前缀树合并技术,识别并合并共享相同历史的多轮对话样本,消除重复计算。这一技术使训练速度提升约40倍,训练成本降至原来的1/40,极大降低了模型训练的门槛。
1.3 CISPO算法:长上下文信用分配优化
CISPO(Clipped IS-weight Policy Optimization)算法是M2.5的另一核心技术,主要解决强化学习训练中长序列生成任务的梯度阻塞和熵崩塌问题。传统PPO算法在处理长序列任务时,常因裁剪导致梯度贡献丢失,造成模型训练不稳定。CISPO通过以下创新设计解决了这一难题:
- 裁剪重要性采样权重而非token更新:保留长序列中所有token的梯度贡献,避免了关键信息丢失,提高了训练稳定性。
- 组归一化优势(Group Relative Advantage):从GRPO算法借鉴并简化,无需Critic网络即可实现更高效的奖励分配。
- 过程奖励机制:不仅关注最终结果,还对推理过程中的每一步进行即时反馈和打分,缓解了长上下文任务中的信用分配问题。
这些技术创新使得M2.5在训练过程中能够更高效地利用计算资源,同时保持模型的稳定性和多样性,为复杂任务的处理提供了坚实基础。
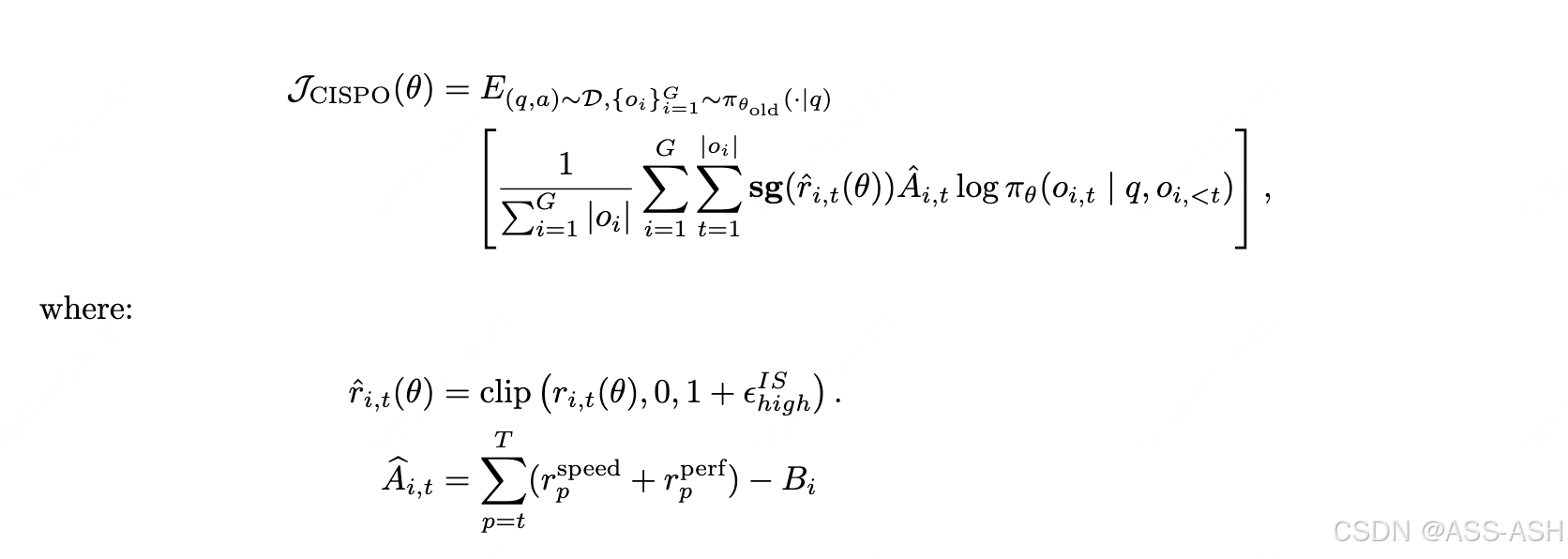
1.4 Lightning Attention架构
M2.5还采用了Lightning Attention架构,通过块分割(tiling)技术将注意力计算拆分为块内(传统矩阵乘法)和块间(线性右乘)两部分,显著提升了长上下文处理能力与推理速度。这一技术使得模型能够处理更长的上下文,同时保持稳定的推理性能,为Agent场景中复杂、多轮交互任务提供了技术支持。
1.5 高效推理与部署优化
M2.5提供了两个版本:M2.5-Lightning和M2.5,它们在能力上完全相同,但在速度和成本上有所差异:
- M2.5-Lightning:支持100 TPS(每秒事务处理量)的超高吞吐量,是主流模型的两倍左右;定价为每百万输入token约0.3美元,输出约2.4美元。
- M2.5:吞吐量为50 TPS,价格减半,输入仍为0.3美元/百万token,输出降至1.2美元/百万token。
这种设计使企业能够根据具体需求选择最适合的版本,在性能与成本之间找到最佳平衡点。同时,模型支持INT4和FP16两种量化版本,显存占用分别从24GB降至8GB和12GB,使得在单张RTX 3090显卡(16GB显存)上即可流畅运行,大幅降低了硬件部署门槛。
二、核心能力与性能表现
2.1 编程能力:接近架构师级的代码生成
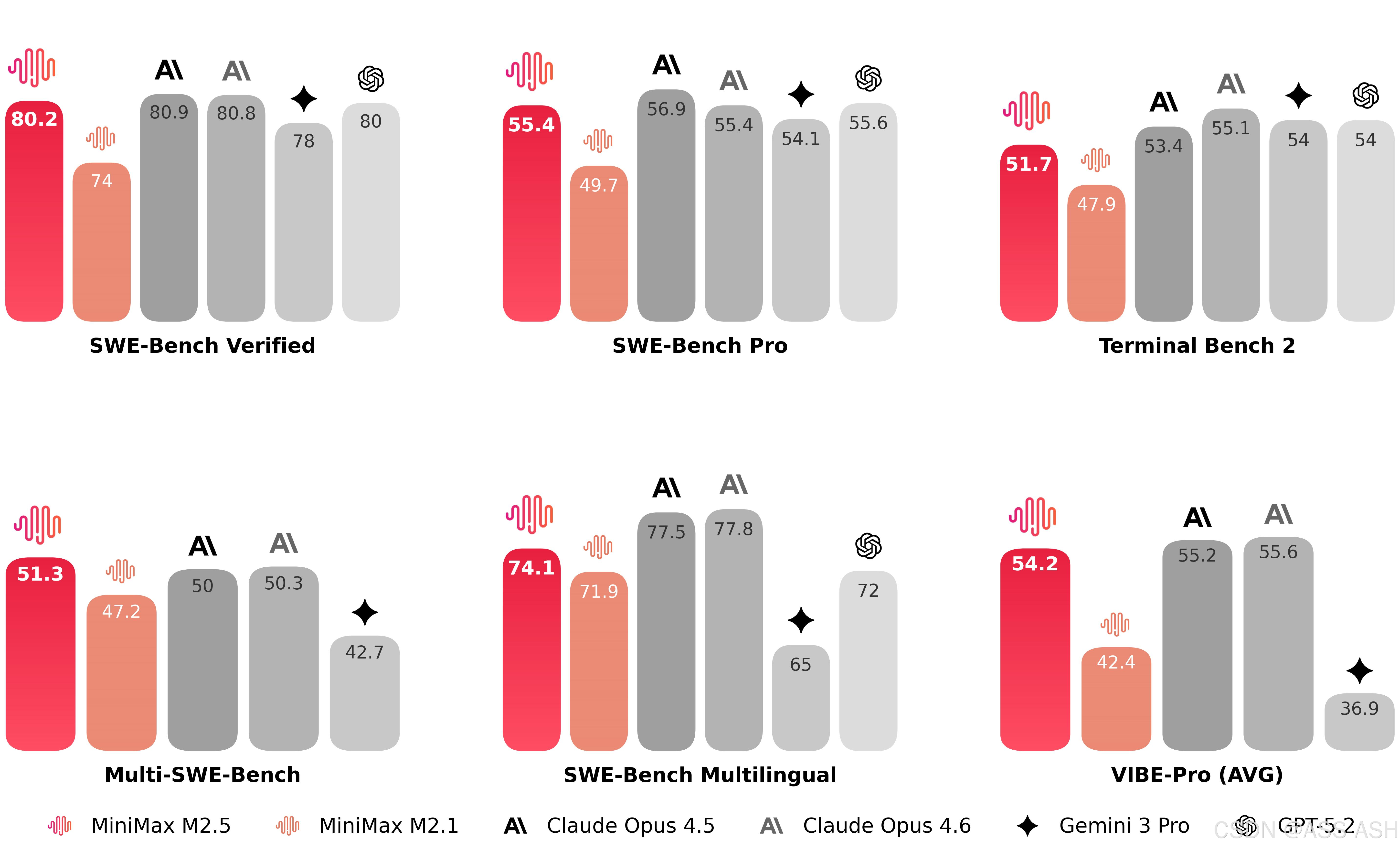
M2.5在编程能力方面表现突出,在SWE-Bench Verified评测中获得80.2%的高分,在Multi-SWE-Bench评测中达51.3%,较前代模型M2.1(SWE-Bench Verified 69.4%)有显著提升。更值得注意的是,M2.5在编程前展现出"原生Spec能力",即能够像资深架构师一样主动拆解功能需求、设计系统结构、规划UI界面,形成完整的技术方案后再进行代码生成,这一特性使其更接近真实开发工作流。
在多语言编程方面,M2.5支持超过10种编程语言(包括Go、Rust、Java、Python、C++等),覆盖从0到1的系统设计与环境搭建、从1到10的核心开发、从10到90的功能迭代,再到90到100的代码审查与测试的全流程开发。其在Droid和OpenCode两种编程脚手架上的通过率分别为79.7和76.1,均超过了Claude Opus4.6(分别为78.9和75.9),显示出在编程领域的全面竞争力。
2.2 工具调用与搜索能力:高效的任务处理
在工具调用和搜索能力方面,M2.5表现出色,在BrowseComp评测中达到76.3%的准确率(带上下文管理),RISE评测中也展现出专家级搜索能力。相比前代模型,M2.5在完成同等任务时轮次消耗减少约20%,以更少的交互步骤解决复杂问题,大幅提升了效率。
在Agent任务拆解与执行方面,M2.5结合强化学习优化的任务拆解能力,端到端运行时间比前代M2.1减少37%,从平均31.3分钟降至22.8分钟,与Claude Opus4.6的22.9分钟相当。更关键的是,M2.5平均每个任务消耗352万token,而前代M2.1需要372万token,减少了不必要的内部推演,使解决问题的路径更加精准。
2.3 办公场景能力:专业工作流的直接交付
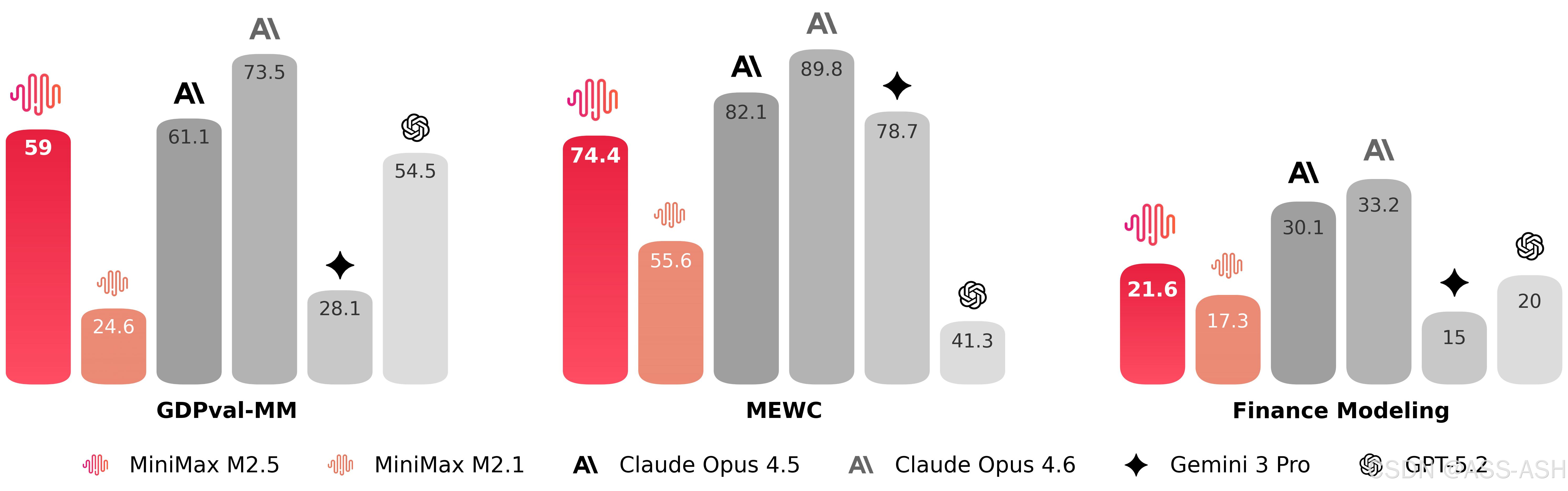
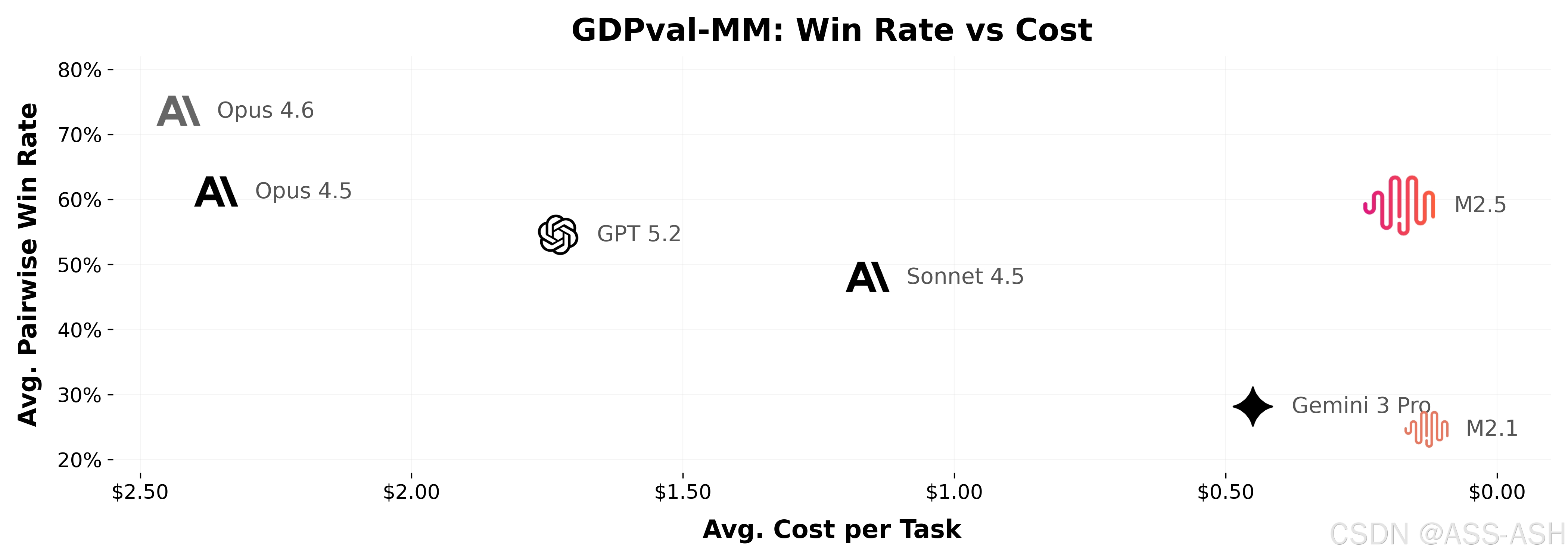
M2.5在办公场景中也取得了显著能力提升,在Word、PPT、Excel金融建模等Workspace高阶场景中表现出色。在GDPval-MM评测框架中,M2.5与主流模型对比取得了59.0%的平均胜率,表明其能够直接输出符合行业标准的文档、演示文稿和表格文件,满足企业办公场景的真实需求。
特别是在Excel金融建模方面,M2.5能够从多个公开数据源提取并核验核心数据,整合成规范的结构化表格。例如,针对全球资产管理规模前五的主权财富基金,模型能够准确提取基金名称、所属国家、资产管理规模、现任负责人等信息,并标注数据来源,展现出强大的多源数据整合能力。
2.4 中文综合能力:专业领域的精准支持
M2.5在中文综合能力评测中获得65.7%的准确率,虽然略低于同为闭源的doubao-seed(71.7%)和gemini-3-pro(72.5%),但其在编程、工具调用和搜索等垂直领域的表现已达到行业领先水平。在法律、金融等专业领域,M2.5通过与行业专家合作,将行业隐性知识融入模型训练,实现了在专业场景中的精准交付能力。
三、应用场景与落地案例
3.1 企业级应用
M2.5已在多个企业场景中落地应用,展现出强大的生产力提升能力:
- 智能客服Agent:某电商平台将M2.5部署为智能客服系统,使用INT4量化版在2台RTX 3090服务器上运行,实现100TPS的稳定吞吐。相比传统客服系统,响应延迟从5秒降至<500ms,GPU成本降低60%,同时支持5000+用户的并发咨询。这一应用使客服系统从"抽样服务"升级为"全覆盖服务",实现了服务模式的根本性转变。
- 全栈开发Agent:某代码生成平台使用M2.5原生Agent SDK,仅用3天就完成了代码生成Agent的开发与部署。用户代码生成效率提升3倍,工具调用准确率达98%,显著降低了开发门槛,使非专业开发者也能利用AI能力提升工作效率。
- 数据分析Agent:在金融领域,M2.5被用于多源数据合成与结构化分析。模型能够从多个公开渠道提取核心数据,并整合成规范的结构化表格。例如,针对全球头部主权财富基金的评测显示,模型能够准确提取并核验包括资产管理规模、收益率、基尼系数等复杂指标,数据提取准确率和整合效率均达到行业领先水平。
3.2 边缘计算与低资源场景
M2.5的轻量化设计使其能够在边缘计算场景中发挥重要作用:
- 边缘端自动化运维Agent:某制造企业将M2.5 INT4版本部署在仅配备16GB显存的边缘服务器上,结合传感器数据进行实时故障诊断。部署后故障诊断准确率达95%,且无需将数据上传至云端,有效保障了数据安全性和实时响应能力。
- 实时数据处理Agent:在工业物联网场景中,M2.5能够处理来自边缘设备的实时数据流,进行异常检测和预测性维护。其高吞吐量设计(100TPS)确保了低延迟响应,满足工业场景对实时性的高要求。
3.3 开发者生态与个人应用
M2.5的开源策略催生了丰富的开发者生态:
- 法律合同审核Agent:开发者可以基于M2.5快速构建专业法律合同审核Agent。例如,法律合同审核Agent能够结合法律知识库,对劳动合同中的试用期约定、社保条款、违约金约定等核心风险点进行标注和分析,准确率高达97.6%。这种Agent不仅能够识别高风险条款,还能提供通俗易懂的修改建议,降低了法律专业知识的使用门槛。
- 金融建模Agent:金融从业者可以利用M2.5构建自动化财务分析Agent,快速生成投资报告、风险评估模型等专业文档。模型在Excel金融建模任务中的表现尤为突出,能够处理复杂的财务公式和数据分析,大幅降低了专业金融分析的时间成本。
- 教育辅助Agent:在教育领域,M2.5能够精读数百页的专业教材(如《数学分析原理》),提炼核心概念并用通俗易懂的语言解释,帮助学生建立知识体系。这一应用使专业教育不再局限于有限的教育资源,而是能够普惠更多学习者。
四、成本效益分析与经济模型创新
4.1 低成本推理:经济模型的根本变革
M2.5的最大创新在于其极致的成本控制,这彻底改变了Agent部署的经济模型:
- Token成本对比:M2.5-Lightning的输入/输出Token价格分别为0.3/2.4美元/百万,而Claude Opus4.6为5/25美元/百万。以编程任务为例,假设平均消耗352万token,M2.5-Lightning的单任务成本约为0.84美元,而Claude Opus4.6约为8.8美元,成本优势达9.3倍。
- 运行时间成本:M2.5-Lightning以每秒100个token的速率运行,连续工作一小时的成本约为1美元;若降至每秒50个token,则每小时成本仅0.3美元。这意味着1万美元的预算理论上可以支撑4个Agent连续工作一年,使Agent的持续运行成为经济可行的选择。
- 吞吐量与成本平衡:M2.5提供两种版本,Lightning版本速度更快但成本较高,标准版本速度减半但成本也减半。这种设计使企业能够根据任务紧急程度灵活选择,在速度与成本之间找到最佳平衡点。
4.2 硬件部署成本优势
M2.5的轻量化设计使其在硬件部署方面也具有显著优势:
- 显存占用优化:通过INT4量化技术,M2.5的显存占用从24GB降至约8GB,在单张16GB显存的RTX 3090服务器上即可流畅运行,大幅降低了硬件门槛。
- 多机并行部署:通过vllm等推理框架,M2.5支持多机并行部署。例如,使用2机tensor并行可实现200TPS的吞吐量,满足大规模并发需求。这种部署策略使企业能够根据预算灵活调整计算资源规模,实现成本与性能的最优配置。
- 私有化部署优势:相比必须依赖云端API的闭源模型,M2.5支持本地化部署,企业可将模型运行在自有服务器上,避免数据传输成本和延迟问题。同时,本地部署使模型更新和定制更加灵活,适应企业特定需求。
4.3 企业TCO(总拥有成本)分析
以一个典型的企业场景为例,假设每天需要处理100个客户工单,每个工单涉及查询数据库、发送邮件等操作:
- 人工方案:雇佣一名客服,时薪20美元,每天工作8小时,成本160美元,一个月(22天)约3520美元。
- M2.5方案:处理每个工单约需5分钟,全天总计约8.3小时,按1美元/小时的成本计算,每天花费8.3美元,一个月仅需183美元。
对比之下,使用M2.5的成本仅为人工方案的5%,降本幅度高达95%。如果企业原本使用Claude Opus等高价模型,成本差异将更加显著。这种TCO的革命性降低,使企业能够将AI从辅助工具转变为真正的生产力工具,重构业务流程和商业模式。
五、模型迭代与未来发展趋势
5.1 M2系列的快速迭代路径
从M2到M2.5的108天迭代周期中,MiniMax实现了多项关键能力的跃升:
- 编程能力:SWE-Bench Verified成绩从69.4提升至80.2,进步曲线在同业中尤为陡峭。
- Agent任务效率:端到端运行时间减少37%,token消耗降低5.4%(从372万降至352万)。
- 多语言支持:Multi-SWE-Bench得分从40.5%提升至51.3%,在多语言复杂环境中超越Claude Opus4.6。
这种快速迭代路径主要得益于Forge框架的40倍训练加速和CISPO算法的稳定性提升,使模型能够持续吸收用户反馈和真实场景数据,不断优化性能。
5.2 Agent Universe生态构建
MiniMax在发布M2.5的同时,提出了构建Agent Universe生态的愿景,希望通过开源和本地化部署,降低Agent开发和部署门槛,推动Agent规模化应用。这一生态战略的核心包括:
- 开发者工具包:提供Agent SDK和Remix功能(一键复刻优秀项目),降低Agent开发门槛。
- 行业专家套组:针对金融、法律、医疗等垂直领域,提供预训练的专家Agent套组,加速行业应用落地。
- 社区驱动创新:M2.5开源后不到一天,全球用户已在MiniMax Agent平台上构建了1万多个专家Agent,形成强大的社区创新生态。
5.3 未来技术演进方向
基于当前技术趋势和M2.5的创新经验,未来大模型可能向以下方向发展:
- 多模态能力增强:将文本、语音、视觉等多模态能力深度融合,支持更丰富的Agent交互方式。
- 自适应推理机制:根据任务复杂度动态调整推理深度和广度,实现更精准的资源利用。
- 联邦学习与隐私保护:在保护数据隐私的前提下,实现跨组织、跨场景的模型持续优化。
- Agent协作网络:构建多Agent协作系统,支持复杂任务的分布式处理和协同决策。
六、总结与展望
MiniMax-M2.5代表了大模型技术发展的重要里程碑,它通过MoE架构、Forge框架、CISPO算法和Lightning Attention等创新技术,实现了**"小参数、大能力、低成本"**的技术突破。在编程、工具调用与搜索、以及办公场景三大核心领域,M2.5已达到与Claude Opus4.6等顶级模型相当的性能水平,同时将成本降至1/10至1/20,实现了AI经济模型的根本性变革。
M2.5的开源策略和本地化部署能力,使AI不再是大企业的专属工具,而是中小企业和个人开发者都能负担得起的生产力助手。这种普惠化趋势将加速AI在各行业的渗透,推动"智能体经济"的快速发展。从编程开发到客服系统,从数据分析到办公自动化,M2.5正在重新定义AI在企业中的角色——从辅助工具转变为真正的生产力伙伴。
随着Agent Universe生态的构建和完善,M2.5有望成为连接AI技术与真实业务场景的桥梁,推动AI从"会聊天"进化到"会干活",真正释放大模型在产业数字化转型中的巨大潜力。未来,随着多模态能力增强、自适应推理机制完善和联邦学习技术成熟,M2.5及其后续版本将进一步拓展应用场景,为各行业带来更深入的智能化变革。
MiniMax-M2.5的发布不仅是技术上的突破,更是AI商业化的重大创新。它证明了在保持模型性能的同时,通过架构优化和训练策略创新,可以大幅降低AI应用的经济门槛,使AI真正成为"用得起的员工",为全球企业和个人带来更普惠的智能体验。
七、相关图表
编程:像架构师一样思考和构建
在编程的核心测试中,M2.5 相比于上一代模型有了显著提升,达到了跟 Claude Opus 系列类似的水平。在多语言相关的任务 Multi-SWE-Bench 上,M2.5 更是达到了第一。
搜索和工具调用
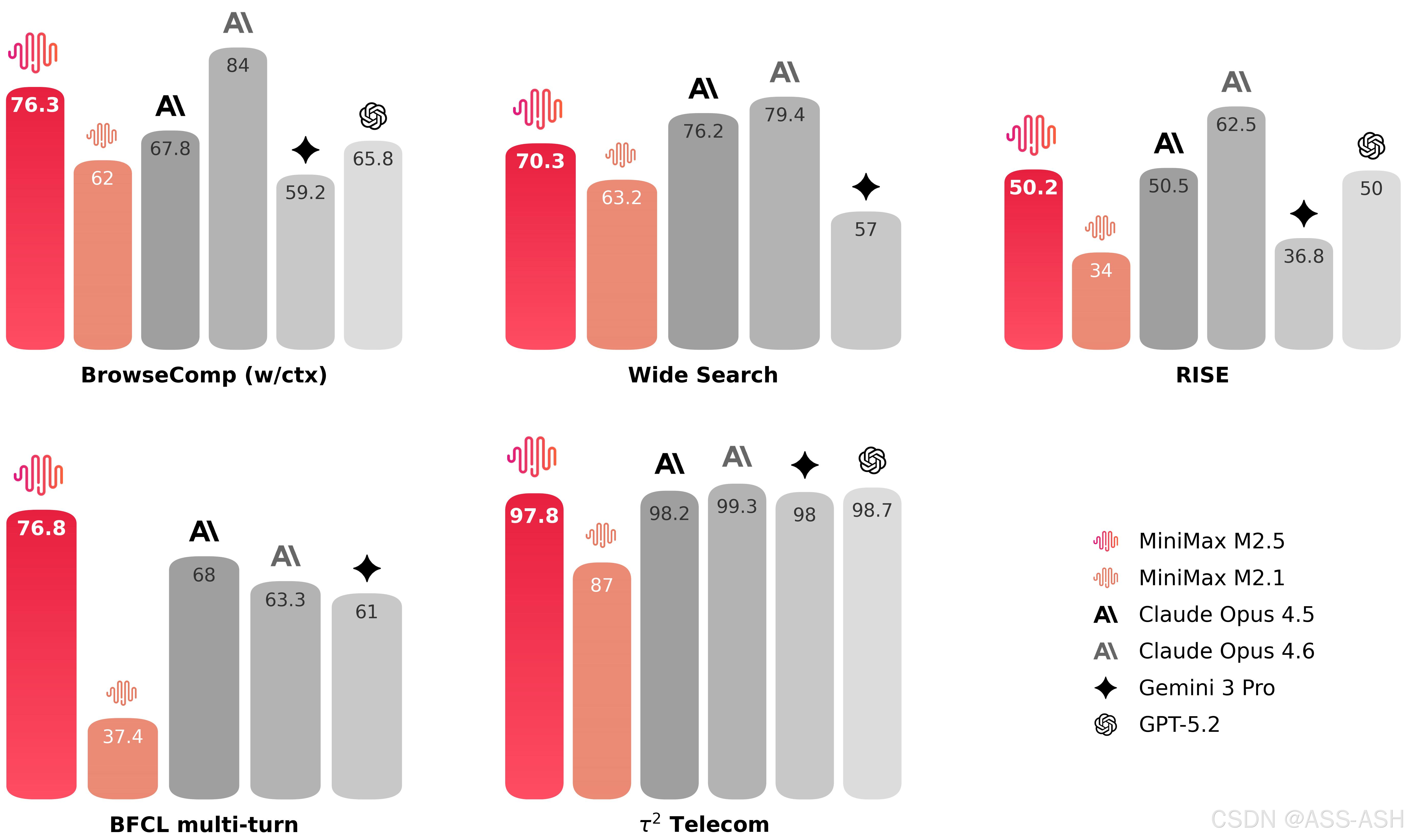
办公

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)