清北联合Deepseek发布最新论文!
大家最近可能被 DeepSeek-R1 的推理能力刷屏了,但在 AI 落地圈,还有一个极其头疼的“慢”问题:AI Agent(智能体)在多轮对话时,反应总是慢半拍。Deepseek联合清北发表最新论文把推理效率翻倍的。
如果你关注大模型落地,一定听过一个说法:“集群的尽头是通信,推理的瓶颈在 I/O。” 随着 DeepSeek-R1 等推理模型的普及,AI Agent(智能体)开始处理越来越长的上下文。但随之而来的问题是:模型越来越聪明,反应却越来越慢。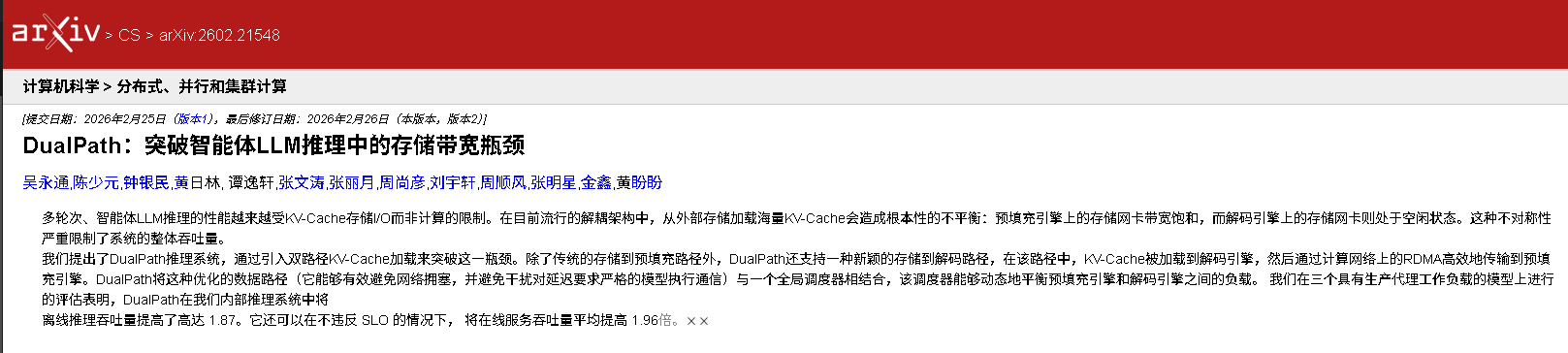
arXiv 地址:https://arxiv.org/pdf/2602.21548
DeepSeek 团队最新发布的论文 《DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference》 给出了一套极具工程美学的解法。
一、 现状剖析:为什么现有的“解耦架构”跑不动 Agent?
为了提高效率,现代大模型推理集群通常采用预推理(Prefill)与解码(Decode)分离的解耦式架构。但在 Agent 场景下,这套架构遇到了三个致命伤: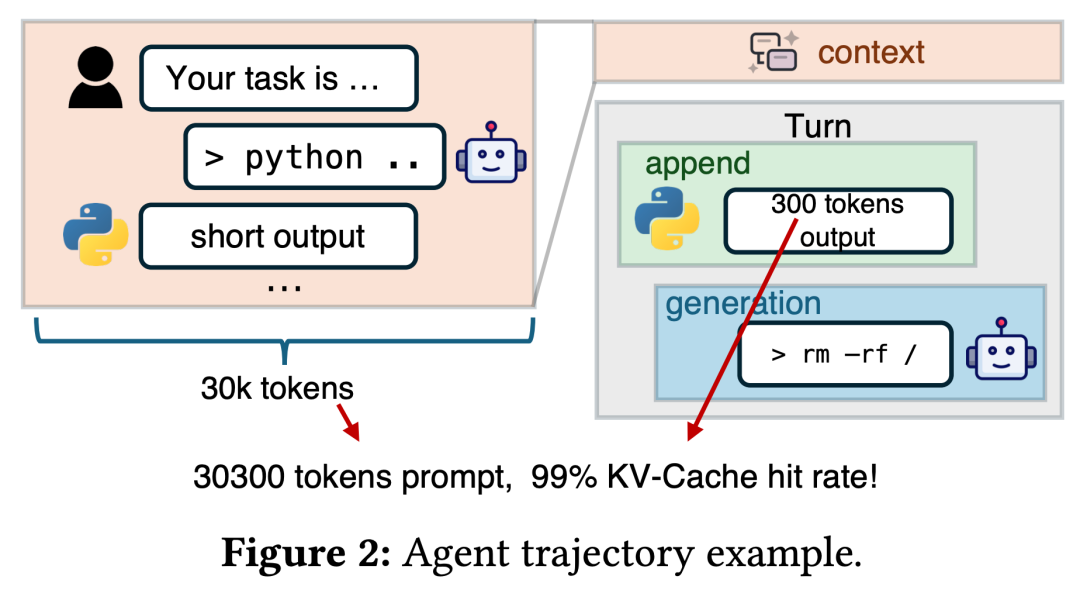
- KV-Cache 的“暴涨”: Agent 需要处理长对话和复杂工具调用,产生的 KV-Cache(键值缓存)体积巨大,单靠 GPU 显存根本存不下,必须踢到外部存储(如 NVMe SSD 或内存池)。
- 带宽的不对称性(Asymmetry):
- Prefill 阶段: 就像一个急着看书的学生,需要瞬间从书架(存储)上抓取大量的历史笔记(KV-Cache),导致其存储网卡(Storage NIC)带宽瞬间爆表。
- Decode 阶段: 就像一个慢悠悠写字的学生,一次只写一个词,对存储的需求极低,导致其网卡带宽大量闲置。
- 排队效应: 这种 I/O 阻塞会导致严重的排队延迟,即使你有再多的 H200/B200 算力,数据传不进来,计算核心也只能“空转”。
二、 DualPath 方案:从“单线作战”到“全局调度”
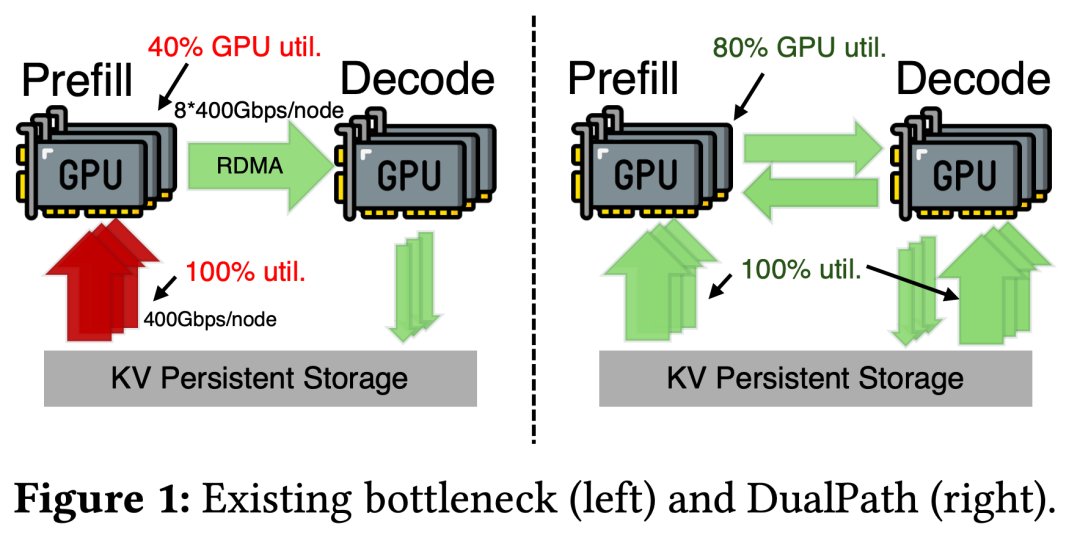
DeepSeek 提出的 DualPath(双路径)核心思路非常硬核:既然 Prefill 的门不够宽,那就借用 Decode 的门来运货。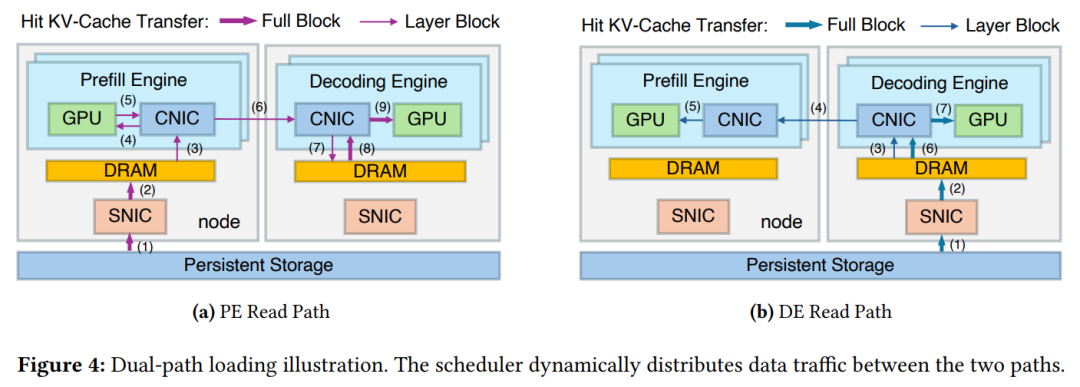
1. 创新路径:借道 RDMA
传统的路径是:存储 -> 预推理引擎。
DualPath 增加了一条:存储 -> 解码引擎 -> (通过 RDMA 高速网络) -> 预推理引擎。
- 逻辑: 既然解码节点的存储网卡是闲置的,那就让它帮邻居分担“搬运”任务。
- 优势: 这种方式避开了已经饱和的 Prefill 存储接口,利用了数据中心内部极速的计算网络(RDMA)进行数据二次中转。
2. 全局智能调度器(Global Scheduler)
这不是简单的负载均衡,而是一个多维资源平衡器。
- 它会实时监控每一台服务器的磁盘 I/O 队列、RDMA 带宽占用和 GPU 计算负载。
- 动态策略: 系统会计算“直接拉取”和“借道拉取”的预期延迟,自动选择最优路径,确保全局吞吐量最大化。
3. 优先级隔离与重叠(Overlap)
工程师们最担心的就是“搬运数据抢了计算的带宽”。
- DualPath 引入了优先级控制机制,确保延迟敏感的计算通信(如模型内部的权重传输)拥有最高优先级。
- 层级预推理: 实现了数据加载与计算在算子层面的重叠,真正做到了“一边运,一边算”,将空转时间压缩到了极限。
三、 成果展示:生产环境下的效率翻倍
在评估部分:论文在自研推理框架上实现 DualPath,核心改动约 5000 行代码。底层使用 FlashMLA、DeepGEMM、DeepEP 等高性能算子,存储后端采用 3FS 分布式存储。
评测模型包括:DS 660B(MoE + 稀疏注意力)、DS 27B(缩小版实验模型),Qwen 32B(稠密模型)。
离线批量推理
这一部分模拟 RL rollout 场景:n 个 agent 同时启动,测整体完成时间(JCT)。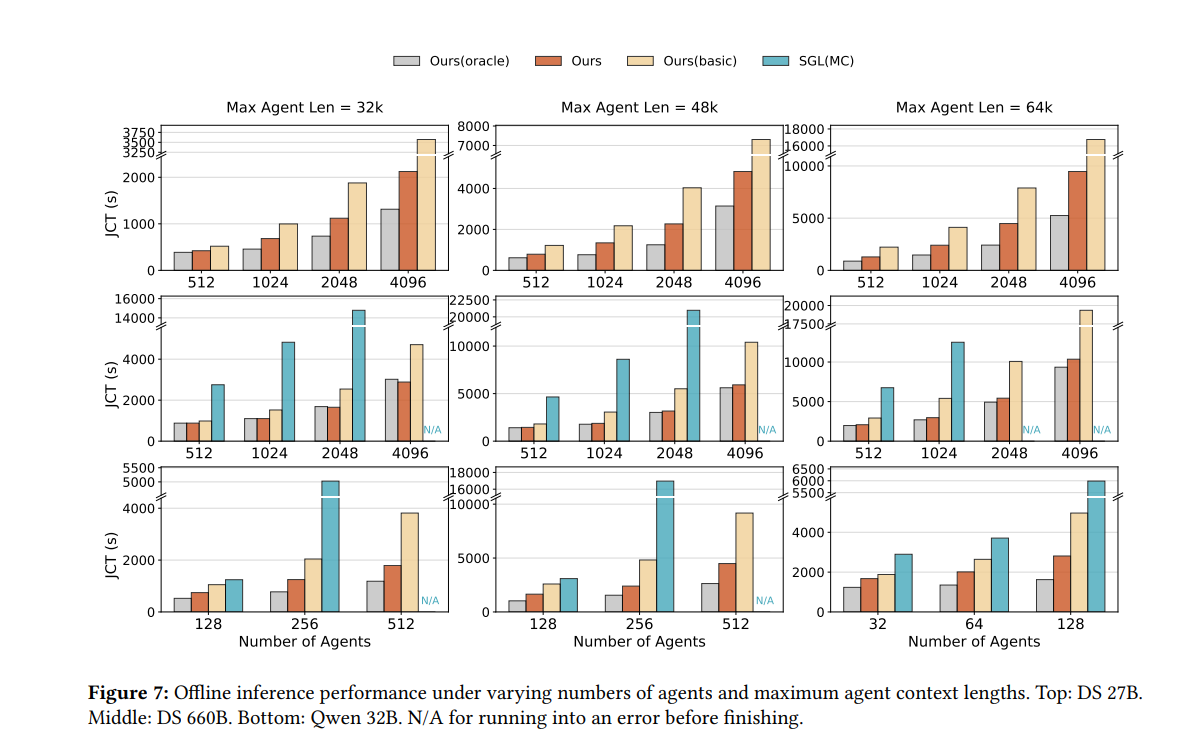
在线推理
在线服务实验部分则模拟真实生产环境下 agent 按泊松分布持续到达的场景,设置 TTFT ≤ 4 秒、TPOT ≤ 50 毫秒为服务等级目标。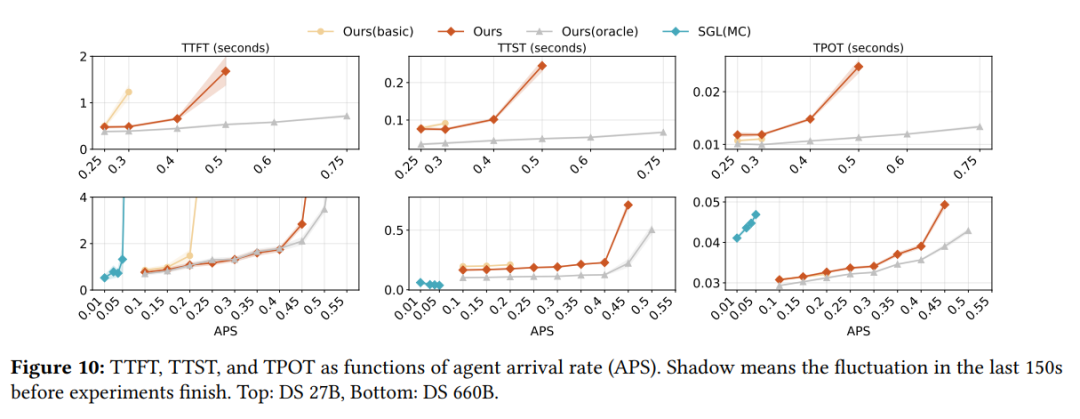
这套方案在 DeepSeek 内部的生产级 Agent 工作负载上进行了实测,数据非常能打:
| 指标 | 提升幅度 |
|---|---|
| 离线推理吞吐量 | 提升 1.87 倍 |
| 在线服务最大容量 | 提升 1.96 倍(在满足延迟要求前提下) |
简单理解: 这意味着你原本需要 100 台服务器支撑的业务,现在用 50 台就能跑得更欢,成本直接腰斩。
四、 工程师视角:DeepSeek 的工程方法论
作为同行,这篇论文最启发我的是:不要总是试图更换更好的硬件,而是去重新审视既有硬件的“闲置率”。
DualPath 并没有发明新的存储介质,它只是通过软件和系统架构的重构,打破了存储网卡与计算核心之间的那一层“墙”。在 Agentic LLM(智能体大模型)时代,这种计算、网络、存储深度融合的优化思路,才是真正通向大规模商用的钥匙。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)