成功率飙升16%,首个SkillsBench告诉你如何用好Skills
自从Skills推出,智能体像插上了翅膀,Openclaw的火爆就是最佳例子。各种各样、各个领域的Skills指导着智能体自主规划完成各种复杂任务,直接交付结果。但究竟Skills是如何提升大模型(智能体)能力的?BenchFlow联合亚马逊、字节跳动、富士康、斯坦福大学、卡内基梅隆大学、加州大学伯克利分校、哥伦比亚大学、牛津大学等发布了首个SkillsBench。大语言模型做成智能体后,大家开始
自从Skills推出,智能体像插上了翅膀,Openclaw的火爆就是最佳例子。
各种各样、各个领域的Skills指导着智能体自主规划完成各种复杂任务,直接交付结果。
但究竟Skills是如何提升大模型(智能体)能力的?
BenchFlow联合亚马逊、字节跳动、富士康、斯坦福大学、卡内基梅隆大学、加州大学伯克利分校、哥伦比亚大学、牛津大学等发布了首个SkillsBench。

大语言模型做成智能体后,大家开始往里塞各种Skills,可行业缺一把尺子去量它到底帮没帮忙。
SkillsBench给了这把尺子,把Skills的增益、波动、翻车点摊开,像一份宝贵的Skills用法指南。
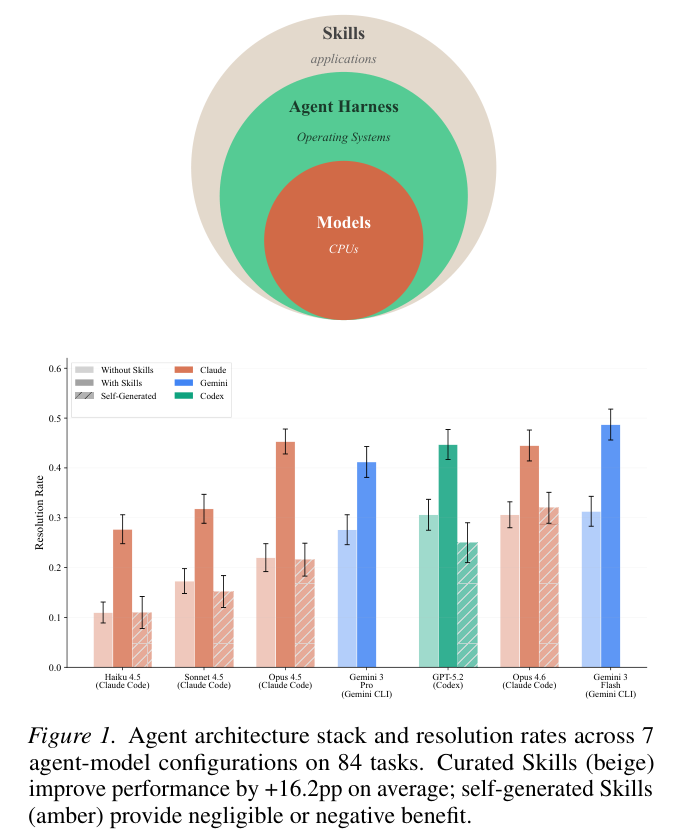
给大语言模型配备一本精心编制的专业技能操作手册,其处理复杂任务的成功率能瞬间飙升16.2个百分点,小参数模型甚至能借此跨越算力鸿沟直接反超裸奔的大型旗舰模型。
SkillsBench测试基准,全面审查了11个专业领域中84项复杂任务在不同Skills辅助下的实际表现。
研究人员测试了7种主流模型配置,收集并分析了7308次运行轨迹,揭开了一个常被忽视的行业事实:精心编制的专业Skills能大幅提升模型解决特定任务的能力,模型依靠自身生成的Skills往往适得其反。
Skills如同智能系统的大脑外挂
大语言模型具备极强的通用理解能力,但面对特定领域的复杂操作流程时,常常不知所措。
Skills正是为它们量身定制的岗位操作手册。特定的工作机制让基础模型专注于逻辑运算。外挂的Skills负责提供专业领域的标准操作程序。
智能体架构的设计巧妙借鉴了现代计算机的运作原理。底层的模型提供类似于中央处理器的基础算力。各家厂商推出的智能命令行工具充当着操作系统的角色。
开发者们编写的各类Skills化身为一个个专业的应用程序。
这些Skills内含自然语言指引、代码模板、参考案例以及验证逻辑。它们能在不改变模型内部参数的前提下,在推理阶段直接纠正和引导智能体的行为模式。
我们常常看到各种提示词工程和检索增强生成技术的讨论。Skills在本质上有着完全不同的应用侧重点。提示词往往缺乏结构化的资源支撑。
常见的检索增强多用于补充事实数据,难以提供严密的程序化动作指导。纯粹的工具调用规范仅仅罗列了接口的能力,并不包含遇到具体问题时该如何思考的操作说明。
Skills完美融合了模块化封装与操作流程指导。这种设计让它们在不同的平台和模型之间保持着极高的便携性。
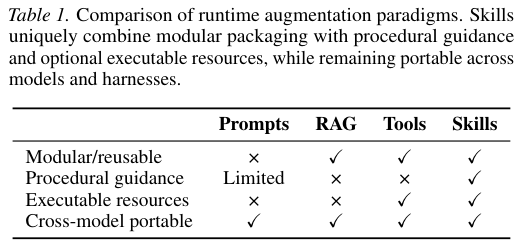
表1对比了不同运行时增强范式的特性。Skills独特地将模块化打包与程序化指导结合,并带有可选的可执行资源,同时在不同模型和系统间保持高度的跨平台移植性。
严谨的三阶段测试框架
为了精准测量Skills带来的实际增益,研究团队搭建了完全容器化的沙盒环境。每一个测试任务都被封装在独立的镜像内。这排除了外部系统环境对测试结果的干扰。
每一个任务模块都包含了四个核心组件。人类专家撰写了脱离Skills也能被理解的清晰指令目标。容器环境中预装了特制的数据文件和包含Skills代码的子目录。
后台配备了能够完美跑通该任务的参考解答路径。确定性的自动化脚本负责在任务结束后进行冷酷无情的对错裁决。所有结果均由程序断言产生,彻底摒除了让人工智能充当裁判所带来的主观评分方差。
测试基准的构建历经了一个漫长且严苛的筛选过程。社区内的105位开发者总共提交了322个候选任务。所有的提交内容都必须经过自动化机器校验与多轮人类专家审查。
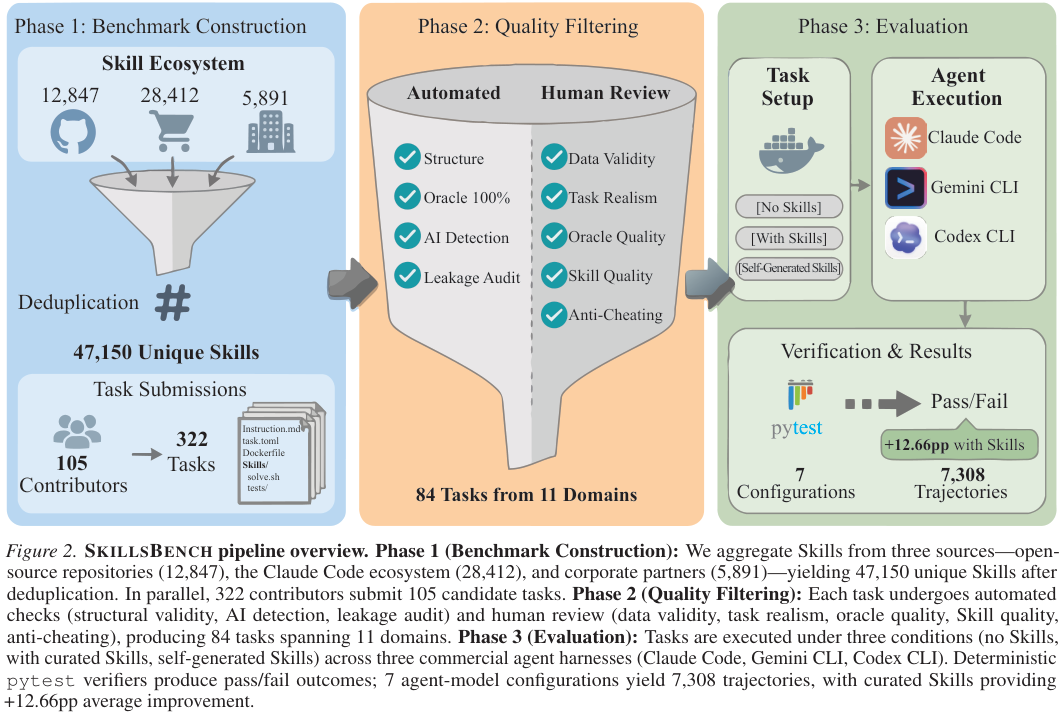
SkillsBench基准测试的三阶段构建流程,涵盖从生态系统聚合、自动化与人工联合质量过滤,直到最终在不同配置下生成七千多条运行轨迹的完整评估路径。
为了防止Skills提前泄露考题,审核人员会逐一排查代码中的隐患。
Skills内容绝对不允许包含特定任务的文件名、常数或魔法数字。指南必须是针对某一类通用问题的解决思路,绝不能直接写死特定案例的答案。
最终入选的84个高频任务涵盖了极具代表性的职业场景。这些任务依据人类专业人员在无AI辅助情况下的预估完成时间被划分成了三个难度层级。
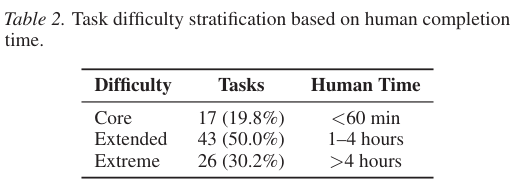
这些任务广泛覆盖了金融财务对账、网络安全漏洞排查以及自然科学数据处理等多个前沿领域。
多样化的场景设置保证了测试基准能够真实反映出外挂Skills在各行各业的泛化能力。
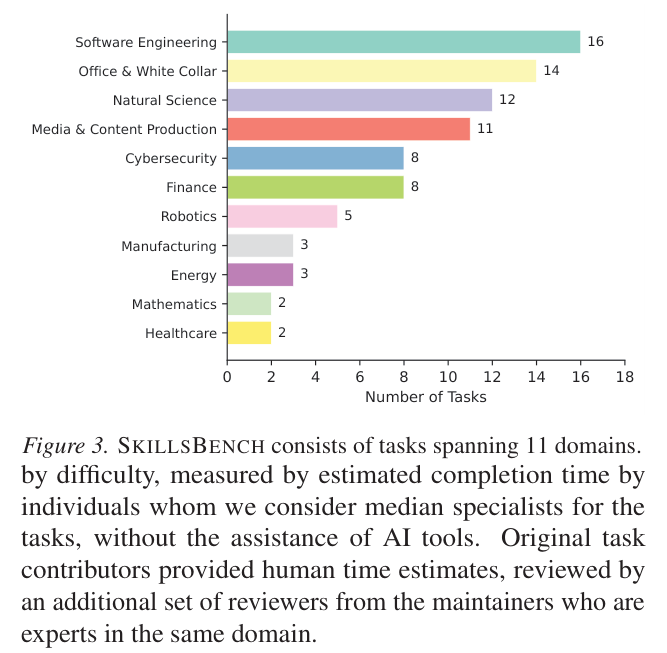
SkillsBench基准测试任务广泛覆盖了从医疗保健到软件工程等11个不同的专业领域。
揭开模型使用外挂的真相
研究团队将所有任务放置在三种截然不同的Skills条件下进行反复测试。
第一种是完全剥离Skills文件的裸奔模式。
第二种是注入人类精心编制的精选Skills模式。
第三种则极具戏剧性,系统要求大语言模型凭借自身的知识储备临时当场编写一套Skills再进行解题。
不同的前端控制台工具与底层模型排列组合,总共衍生出了7套极具代表性的主流软硬件配置。
科学的评估需要依靠精确的数据维度来度量。研究引入了物理教育界常用的标准化收益率公式。该指标可以有效排除模型基础能力过高带来的天花板效应。
标准化收益率能清晰折射出外挂Skills对模型剩余潜力究竟挖掘了多少。
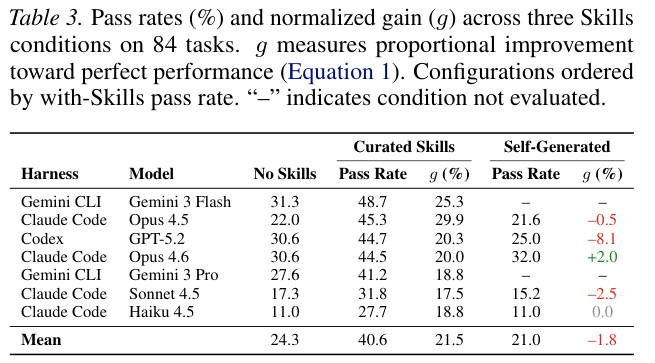
测试数据清晰展现了精选Skills带来的巨大红利。全部7种配置在配备Skills后均获得了显著提升,但收益幅度因软硬件结合的默契度而异。
Gemini阵营的组合取得了最为亮眼的原始通过率得分。
Claude code搭配旗舰模型则斩获了最高的净增长幅度,凸显出其原生Skills集成架构的优越性。
Codex虽然得分不俗,但它经常自作主张忽略外部Skills并强行用自己的老办法硬干。
对比之下,模型自我生成的Skills表现极不理想。平均成绩甚至比什么都不给还要倒退1.3个百分点。
大语言模型往往能够模糊地意识到当前任务需要专业手段,却写不准具体的应用程序接口调用参数。
在面对金融或制造业的高度冷门任务时,它们连自己缺乏哪类专业知识都毫无察觉,盲目使用通用常识去套路复杂问题。
领域维度的拆解分析带来了更有趣的发现。
Skills的效能与模型在预训练阶段“见过的世面”呈现出高度的负相关。
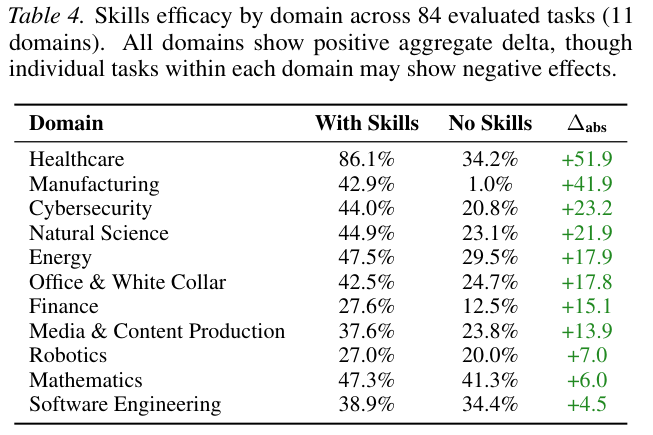
医疗保健领域的临床数据协调和制造业的特种工作流极少出现在公共训练语料库中。一旦外部Skills及时提供了这些稀缺的行业规程,模型犹如打通任督二脉,成功率暴涨五十多个百分点。
软件工程和基础数学一直是大语言模型重点强化的核心科目。
模型的大脑中早已固化了这些领域的解题套路。外部硬塞进去的Skills书反而容易打乱它们原有的肌肉记忆,导致增益极小,甚至在个别具体任务上出现了反面效果。
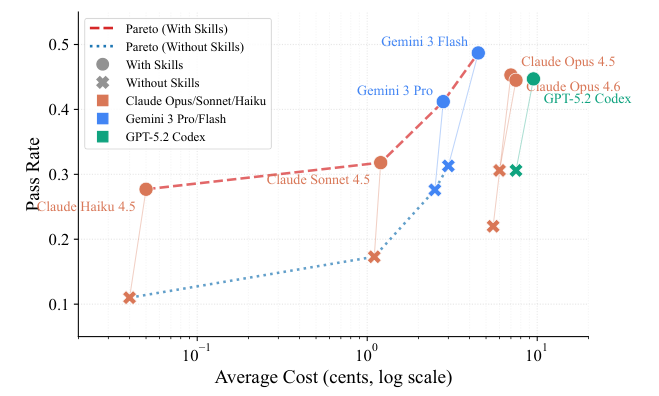
成本收益曲线勾勒出了小步快跑策略的商业价值。
Gemini Flash模型虽然在单个任务上消耗了2.3倍的输入Token,但它用高频次的试错迭代完美弥补了推理深度的不足。
得益于其极其低廉的代币单价,它最终在总成本大降百分之四十四的情况下取得了全场最佳的战绩。
Skills的精简法则与以小博大奇迹
Skills的投喂策略同样大有学问。
研究者详细追踪了不同Skills文档篇幅与任务成功率之间的微妙平衡关系。
外挂Skills绝非多多益善。
当系统同时塞入过多互不相关的Skills模板时,智能体的认知负荷会瞬间过载。它们在海量的信息中来回翻找,反而容易组合出相互冲突的错误逻辑。
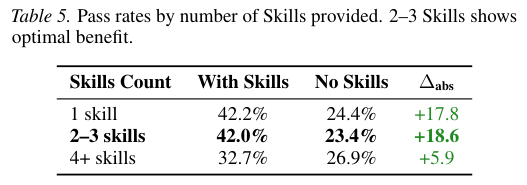
过于详尽的百科全书式指南同样是智能体作业的灾难。
冗长的段落严重消耗了模型本就宝贵的上下文注意力额度。
真正好用的Skills通常具备聚焦的业务流拆解与一到两个精简的执行案例。
结构紧凑的按步就班指引总能让智能体一秒入戏,精准执行特定领域的苛刻动作。
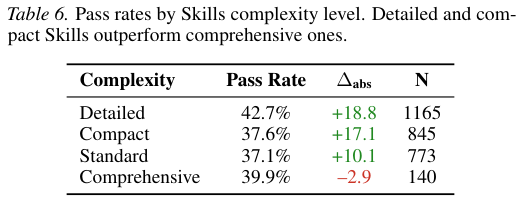
参数规模的等级森严长期以来是模型圈不可逾越的鸿沟。
高质量的外挂Skills在程序化任务中硬生生撕开了一道跨越阶层的口子。
入门级的小尺寸模型在获得优质Skills指引后,其测试表现能够超越高端大模型。
参考资料:
https://arxiv.org/pdf/2602.12670

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献260条内容
已为社区贡献260条内容

所有评论(0)