【NeurIPS 2023】源码解读 --- 扩散模型是多任务强化学习中的有效规划器与数据合成器
扩散模型在视觉和自然语言处理(NLP)领域已展现出强大的生成能力。最近的强化学习(RL)研究发现,扩散模型在离线数据集中建模复杂策略或轨迹方面也表现出色。然而,已有工作大多局限于单任务场景,缺乏能够在多任务挑战中发挥作用的通用智能体。本文旨在探究单个扩散模型在建模大规模多任务离线数据中的有效性,这一任务因数据分布的多样性和多模态性而具有挑战性。
文章目录
摘要
参考论文:Diffusion Model is an Effective Planner and Data Synthesizer for Multi-Task Reinforcement Learning
扩散模型在视觉和自然语言处理(NLP)领域已展现出强大的生成能力。最近的强化学习(RL)研究发现,扩散模型在离线数据集中建模复杂策略或轨迹方面也表现出色。然而,已有工作大多局限于单任务场景,缺乏能够在多任务挑战中发挥作用的通用智能体。本文旨在探究单个扩散模型在建模大规模多任务离线数据中的有效性,这一任务因数据分布的多样性和多模态性而具有挑战性。
具体而言,提出了一种基于扩散模型的方法——多任务扩散模型(MTDIFF),该方法结合Transformer主干网络与提示学习,用于多任务离线环境中的生成式规划与数据合成。MTDIFF能够利用多任务数据中的海量知识,并在任务间实现隐式知识共享。在生成式规划方面,我们在Meta-World的50个任务和Maze2D的8个地图环境中验证了MTDIFF优于最先进的算法。在数据合成方面,MTDIFF仅需单个演示作为提示即可生成高质量的数据,从而提升甚至是未见过任务的低质量数据集性能。
引言
迄今为止,离线决策的最新尝试利用扩散模型的生成能力[54,20]来优化长期规划[21,2]或增强策略的表达性[63,11,8]。然而,这些工作仅限于小规模数据集和单任务场景,难以实现广泛的泛化能力和通用策略。
在涉及学习单一模型解决多任务问题的多任务离线RL中,数据集通常包含由不同任务下的多种策略收集的、具有噪声、多模态和长时间跨度的轨迹,这使得学习具有广泛泛化能力和转移能力的策略更加困难。
Gato [47] 和其他通用代理 [29,65] 通过序列建模利用基于Transformer的架构解决多任务问题,如 S prev S_{\text{prev}} Sprev 和 R τ R_{\tau} Rτ 表示历史状态和归一化回报 [62],但这些方法高度依赖于数据集的最优性,且由于参数数量巨大,训练成本高昂。
本文采用GPT主干架构[45]来建模序列化轨迹,相较于先前基于U-Net的扩散模型[48],这一设计减少了计算负担并提升了序列建模能力[21,33]。
强化学习中的 “轨迹” 指的是 状态→动作→奖励→下一个状态 的连续序列(即 S t , A t , R t , S t + 1 . . . S_t,A_t,R_t,S_{t+1}... St,At,Rt,St+1...),这类数据是时序依赖的序列化结构—— 后一步的动作和状态与前一步的历史强相关。
U-Net 架构,其核心优势是处理网格状、空间结构数据(如图片的像素矩阵),通过 “下采样压缩特征 + 上采样恢复细节” 实现生成。但用 U-Net 建模强化学习的序列化轨迹时,存在两个问题:
- 计算效率低:U-Net 的编解码结构会对序列做冗余的空间维度处理,增加不必要的计算量;
- 序列建模能力弱:U-Net 没有针对 “时序依赖” 做优化,难以捕捉轨迹中长距离的状态 - 动作关联(比如早期状态对后期动作的影响)。
GPT 是基于 Transformer 的自回归架构,天生为序列化数据(如文本、时序序列)设计:
- 降低计算负担:Transformer 的注意力机制可直接建模序列中任意位置的依赖关系,无需 U-Net 的编解码冗余操作,减少了模型参数和计算量;
- 提升序列建模能力:自回归的生成方式(按顺序预测下一个动作 / 状态)更贴合强化学习轨迹的生成逻辑,能更精准地捕捉轨迹的时序规律。
为在训练和推理过程中区分任务,我们不提供例如独热编码的任务标识符(task identifiers),而是利用演示(demonstrations)作为提示条件(prompt conditioning),从而利用代理的少样本学习能力[50,64,69]。
| 对比维度 | 传统方法(独热编码任务标识符) | MTDIFF 方法(演示作为提示条件) |
|---|---|---|
| 核心逻辑 | 为每个任务分配一个唯一的 “标签”(如任务 A=[1,0,0],任务 B=[0,1,0]),模型通过识别标签区分任务 | 不给任务贴标签,而是输入该任务的少量演示轨迹(如 “完成任务 A 的 3 条示例轨迹”)作为 “提示”,模型从演示中学习任务特征 |
| 局限性 | 1. 只能处理预定义的已知任务,遇到未见过的新任务时,没有对应的独热编码,无法泛化;2. 依赖人工标注任务标签,扩展性差 | 1. 利用提示学习(Prompt Learning) 的少样本能力,只需少量演示即可适配新任务;2. 无需人工标注,更符合真实场景中 “任务无标签” 的需求 |
演示轨迹包含的是任务的 “目标 + 环境动态”,模型学到的是 “完成这类目标需要遵循的行为逻辑”,而非 “标签 A 对应动作 X” 的机械对应。这种抽象的规律可以迁移到同类型的新任务中(比如学会了 “推箱子” 的演示,能泛化到 “推其他物体到指定位置” 的新任务)。
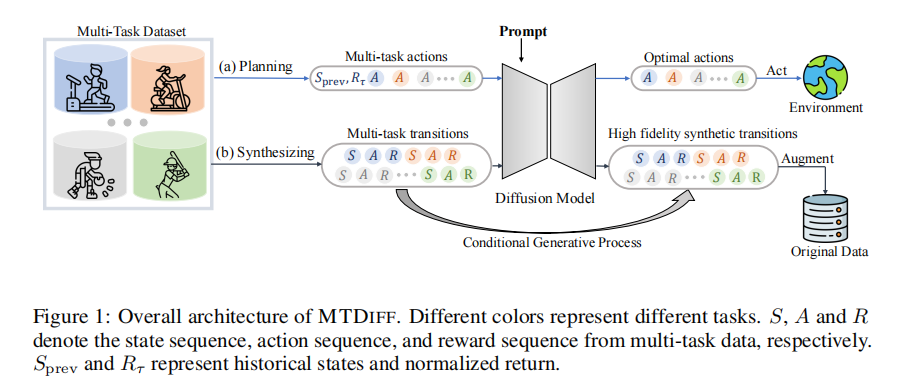
将方法命名为多任务扩散模型(Multi-Task Diffusion Model, MTDIFF)。如图1所示,针对规划和数据合成分别研究了MTDIFF的两种变体,分别称为MTDIFF-P和MTDIFF-S。
(a)对于规划任务,MTDIFF-P学习一个提示嵌入(prompt embedding)以提取任务相关表示,然后将该嵌入与轨迹的归一化回报和历史状态拼接作为模型的条件。在训练过程中,MTDIFF-P根据这些条件预测相应的未来动作序列,我们称此过程为生成式规划[78]。在推理阶段,给定少量提示(few-shot prompts)和期望的回报,MTDIFF-P会从当前状态开始,通过去噪生成最优的动作序列。
(b)通过略微调整输入和训练策略,我们可以释放扩散模型在数据合成方面的潜力。我们的核心观点是,扩散模型能够有效压缩多任务知识,相较于仅利用单任务数据进行数据增强的先前方法[38,52,28],扩散模型更具通用性。具体而言,MTDIFF-S基于任务导向的提示(task-oriented prompts)学习全轨迹(包含状态、动作和奖励)的联合条件分布。与MTDIFF-P不同的是,MTDIFF-S学习从任务背后的动态环境中合成数据。因此,MTDIFF-S仅需通过提示条件识别任务。
- 扩散模型的 “多模态生成能力” 可以压缩多个任务的知识,因此能生成覆盖多任务的高质量数据,通用性更强。
- MTDIFF-S是学 “该任务对应的环境运行逻辑”—— 比如 “任务 A 的环境中,状态和动作的转移规则是什么”。----------- 所以只需输入该任务的少量演示轨迹(任务导向的提示),模型就能从演示中识别出 “这个任务对应的环境动态是什么”,进而生成符合该动态的轨迹数据 —— 不需要额外输入 “当前状态”“期望回报”(这些是 MTDIFF-P 做规划时需要的)。
preliminaries
(1) RL
在每个时间步 t,智能体根据策略 π : S → Δ A \pi: \mathcal{S} \to \Delta_{\mathcal{A}} π:S→ΔA(从状态映射到动作的概率分布)选择动作 a t a_t at,随后得到下一个状态 s t + 1 s_{t+1} st+1 并获得标量奖励 r t r_t rt。
在单任务强化学习中,目标是学习一个最优策略 π ∗ = arg max π E a t ∼ π [ ∑ t = 0 ∞ γ t r t ] \pi^* = \arg\max_{\pi} \mathbb{E}_{a_t \sim \pi}\left[ \sum_{t=0}^{\infty} \gamma^t r_t \right] π∗=argmaxπEat∼π[∑t=0∞γtrt],即最大化该任务对应的期望累积奖励。
在多任务场景中,不同任务可能具有不同的奖励函数、状态空间和转移函数,但共享同一个动作空间(对应同一个实体智能体)。假设任务 T ∼ p ( T ) T \sim p(T) T∼p(T)(任务服从某种概率分布),则特定任务 T 对应的 MDP 可定义为 ( S T , A , P T , R T , μ T , γ ) (\mathcal{S}^T, \mathcal{A}, \mathcal{P}^T, \mathcal{R}^T, \mu^T, \gamma) (ST,A,PT,RT,μT,γ)。
多任务强化学习的目标不是求解单个 MDP,而是找到一个在所有任务上最大化期望回报的最优策略: π ∗ = arg max π E T ∼ p ( T ) E a t ∼ π [ ∑ t = 0 ∞ γ t r t T ] \pi^* = \arg\max_{\pi} \mathbb{E}_{T \sim p(T)} \mathbb{E}_{a_t \sim \pi}\left[ \sum_{t=0}^{\infty} \gamma^t r_t^T \right] π∗=argπmaxET∼p(T)Eat∼π[t=0∑∞γtrtT](其中 r t T r_t^T rtT 是任务 T 在时间步 t 的奖励)。
在离线决策中,策略是从一个静态的转移数据集 { ( s j , a j , s j ′ , r j ) } j = 1 N \{(s_j, a_j, s_j', r_j)\}_{j=1}^N {(sj,aj,sj′,rj)}j=1N 中学习的,这些数据由未知的行为策略 π β \pi_{\beta} πβ 收集而来。在多任务离线强化学习中,数据集 D \mathcal{D} D 会被划分为 “按任务分类的子集”: D = ⋃ i = 1 N D i \mathcal{D} = \bigcup_{i=1}^N \mathcal{D}_i D=⋃i=1NDi,其中 D i \mathcal{D}_i Di 是任务 T i T_i Ti 对应的经验数据。
离线强化学习的核心问题是分布偏移:由于时序差分(TD)学习的特性,策略学习过程中会出现 “训练数据分布(行为策略 π β \pi_{\beta} πβ 产生)与目标策略 π \pi π 产生的分布不匹配” 的问题。
本文将多任务策略学习视为一个条件生成过程(无需拟合价值函数),利用扩散模型强大的分布建模能力处理多任务数据,从而避免分布偏移的风险。
(2)diffusion models
在本文中,我们利用扩散模型从多任务数据 D = ⋃ i = 1 N D i \mathcal{D} = \bigcup_{i=1}^N \mathcal{D}_i D=⋃i=1NDi 中学习。设 τ \tau τ 是从 D \mathcal{D} D 中采样得到的轨迹,我们将 x k ( τ ) x_k(\tau) xk(τ) 记为扩散模型的 k 步去噪输出, y ( τ ) y(\tau) y(τ) 是表示任务属性与轨迹最优性(例如回报)的条件。前向扩散链通过 K 步逐步向数据 x 0 ( τ ) ∼ q ( x ( τ ) ) x_0(\tau) \sim q(x(\tau)) x0(τ)∼q(x(τ)) 中添加噪声,噪声的方差由预定义的方差调度 β k \beta_k βk 控制,其数学表达为: q ( x k ( τ ) ∣ x k − 1 ( τ ) ) : = N ( x k ( τ ) ; 1 − β k x k − 1 ( τ ) , β k I ) . ( 1 ) q(x_k(\tau) \vert x_{k-1}(\tau)) := \mathcal{N}\left(x_k(\tau); \sqrt{1-\beta_k}x_{k-1}(\tau), \beta_k \boldsymbol{I}\right). (1) q(xk(τ)∣xk−1(τ)):=N(xk(τ);1−βkxk−1(τ),βkI).(1)
本文中,采用 “方差保持(VP)beta 调度”,并定义 β k = 1 − exp ( − β min ( 1 K ) − 0.5 ( β max − β min ) 2 k − 1 K 2 ) \beta_k = 1 - \exp\left(-\beta_{\text{min}}(\frac{1}{K}) - 0.5(\beta_{\text{max}} - \beta_{\text{min}})\frac{2k-1}{K^2}\right) βk=1−exp(−βmin(K1)−0.5(βmax−βmin)K22k−1),其中 β max = 10 \beta_{\text{max}} = 10 βmax=10、 β min = 0.1 \beta_{\text{min}} = 0.1 βmin=0.1 为常数。可训练的反向扩散链被构建为 p θ ( x k − 1 ( τ ) ∣ x k ( τ ) , y ( τ ) ) : = N ( x k − 1 ( τ ) ∣ μ θ ( x k ( τ ) , y ( τ ) , k ) , Σ k ) p_\theta(x_{k-1}(\tau) \vert x_k(\tau), y(\tau)) := \mathcal{N}\left(x_{k-1}(\tau) \vert \mu_\theta(x_k(\tau), y(\tau), k), \Sigma_k\right) pθ(xk−1(τ)∣xk(τ),y(τ)):=N(xk−1(τ)∣μθ(xk(τ),y(τ),k),Σk),其优化可通过简化的代理损失实现:
L denoise : = E k ∼ U ( 1 , K ) , x 0 ( τ ) ∼ q , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ ( x k ( τ ) , y ( τ ) , k ) ∥ 2 ] ( 2 ) \mathcal{L}_{\text{denoise}} := \mathbb{E}_{k \sim \mathcal{U}(1,K), x_0(\tau) \sim q, \epsilon \sim \mathcal{N}(0,\boldsymbol{I})}\left[\left\Vert \epsilon - \epsilon_\theta(x_k(\tau), y(\tau), k) \right\Vert^2\right](2) Ldenoise:=Ek∼U(1,K),x0(τ)∼q,ϵ∼N(0,I)[∥ϵ−ϵθ(xk(τ),y(τ),k)∥2](2)
其中 ϵ θ \epsilon_\theta ϵθ 是由深度神经网络参数化的模型,其训练目标是预测添加到数据集样本 x 0 ( τ ) x_0(\tau) x0(τ) 中、用于生成 x k ( τ ) x_k(\tau) xk(τ) 的噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0,\boldsymbol{I}) ϵ∼N(0,I)。通过令 α k : = 1 − β k \alpha_k := 1 - \beta_k αk:=1−βk 且 α ˉ k : = ∏ s = 1 k α s \bar{\alpha}_k := \prod_{s=1}^k \alpha_s αˉk:=∏s=1kαs,我们可得反向扩散的更新公式:
x k − 1 ( τ ) ← 1 α k ( x k ( τ ) − β k 1 − α ˉ k ϵ θ ( x k ( τ ) , y ( τ ) , k ) ) + β k σ , σ ∼ N ( 0 , I ) , 其中 k = { K , . . . , 1 } . x_{k-1}(\tau) \leftarrow \frac{1}{\sqrt{\alpha_k}} \left( x_k(\tau) - \frac{\beta_k}{\sqrt{1-\bar{\alpha}_k}} \epsilon_\theta(x_k(\tau), y(\tau), k) \right) + \sqrt{\beta_k}\sigma, \quad \sigma \sim \mathcal{N}(0,\boldsymbol{I}), \quad \text{其中 } k = \{K, ..., 1\}. xk−1(τ)←αk1(xk(τ)−1−αˉkβkϵθ(xk(τ),y(τ),k))+βkσ,σ∼N(0,I),其中 k={K,...,1}.
Methodology
dffusion formulation
为了捕捉从多个 MDP 中采样得到的轨迹的多模态分布,我们将多任务轨迹建模转化为基于扩散模型的条件生成问题:
max θ E τ ∼ D i [ log p θ ( x 0 ( τ ) ∣ y ( τ ) ) ] ( 3 ) \max_{\theta} \mathbb{E}_{\tau \sim \mathcal{D}_i} \left[ \log p_\theta(x_0(\tau) \vert y(\tau)) \right](3) θmaxEτ∼Di[logpθ(x0(τ)∣y(τ))](3)
其中 x 0 ( τ ) x_0(\tau) x0(τ) 是生成的目标序列, y ( τ ) y(\tau) y(τ) 是条件。 x 0 ( τ ) x_0(\tau) x0(τ) 随后会用于生成式规划或特定任务的数据合成。式 (3) 的最大化可通过反向去噪过程 p θ p_\theta pθ 来近似实现。根据 “生成式规划” 和 “数据合成” 中不同的输入与输出形式, x ( τ ) x(\tau) x(τ) 可以表示为不同的格式。我们针对 MTDIFF-P 和 MTDIFF-S 分别设计了两种 x ( τ ) x(\tau) x(τ) 的形式:
(i)MTDIFF-P 的公式化表达:
在 MTDIFF-P 中, x ( τ ) x(\tau) x(τ) 表示用于规划的动作序列。我们将动作序列定义为:
x k p ( τ ) : = ( a t , a t + 1 , . . . , a t + H − 1 ) k ( 4 ) \boldsymbol{x}_k^p(\tau) := \left( a_t, a_{t+1}, ..., a_{t+H-1} \right)_k(4) xkp(τ):=(at,at+1,...,at+H−1)k(4)
对应的上下文条件为: y p ( τ ) : = [ y ( τ ) , R ( τ ) ] , y ′ ( τ ) : = ( Z , s t − L + 1 , . . . , s t ) ( 5 ) \boldsymbol{y}^p(\tau) := \left[ y(\tau), R(\tau) \right], \quad \boldsymbol{y}'(\tau) := \left( Z, s_{t-L+1}, ..., s_t \right)(5) yp(τ):=[y(τ),R(τ)],y′(τ):=(Z,st−L+1,...,st)(5)
其中:
- t:轨迹 τ \tau τ 中对应的时间步;
- H:输入序列 x 的长度;
- R ( τ ) R(\tau) R(τ):轨迹 τ \tau τ 对应的归一化累积回报;
- L:观测到的状态历史的长度;
- Z:作为提示的任务相关信息。
我们将 y ′ ( τ ) \boldsymbol{y}'(\tau) y′(τ) 作为普通条件,在训练和测试阶段注入模型中;同时将 R ( τ ) R(\tau) R(τ) 作为 “无分类器引导” 的条件,以得到特定任务的最优动作序列。
(ii)MTDIFF-S 的公式化表达:
在 MTDIFF-S 中,输入和输出是包含状态、动作、奖励的转移序列,生成的输出会用于数据增强。我们将转移序列定义为:
x k s ( τ ) = [ s t s t + 1 ⋯ s t + H − 1 a t a t + 1 ⋯ a t + H − 1 r t r t + 1 ⋯ r t + H − 1 ] , (6) \boldsymbol{x}_k^s(\tau) = \begin{bmatrix} s_t & s_{t+1} & \cdots & s_{t+H-1} \\ a_t & a_{t+1} & \cdots & a_{t+H-1} \\ r_t & r_{t+1} & \cdots & r_{t+H-1} \end{bmatrix}, \tag{6} xks(τ)= statrtst+1at+1rt+1⋯⋯⋯st+H−1at+H−1rt+H−1 ,(6)对应的条件为: y s ( τ ) : = [ Z ] , ( 7 ) \boldsymbol{y}^s(\tau) := \left[ Z \right],(7) ys(τ):=[Z],(7)其中 y s ( τ ) \boldsymbol{y}^s(\tau) ys(τ) 采用与 y ′ ( τ ) \boldsymbol{y}'(\tau) y′(τ) 相同的条件处理方式。
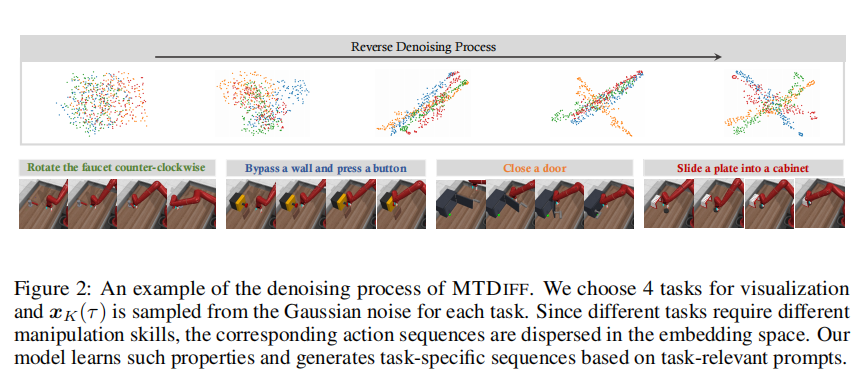
图 2 展示了 MTDIFF-P 在 Meta-World 数据集上学习到的反向去噪过程:结果表明,我们的扩散模型能够成功区分不同任务,并最终生成目标序列 x 0 ( τ ) x_0(\tau) x0(τ)。我们还通过 T-SNE 降维展示了 x 0 ( τ ) x_0(\tau) x0(τ) 的数据分布,以及执行动作序列后的渲染状态;结果显示,在 “任务相关提示” 作为条件的情况下,生成的规划序列会学习特定任务的分布,同时区分其他任务的序列 —— 这验证了 MTDIFF 可以基于 y ( τ ) y(\tau) y(τ) 学习多模态轨迹的分布。
Prompt,Training and Sampling
在多任务强化学习与大语言模型驱动的决策中,现有工作采用独热任务标识符或语言描述作为多任务训练的条件。然而,我们认为:独热编码仅能让模型学习训练任务的 “固定行为模式”,却无法泛化到新任务(因为它没有利用任务间的语义相似性);而语言描述则需要大量人工标注,且会面临歧义问题。
在 MTDIFF 中,我们利用少量轨迹片段组成的演示,在多任务场景下构建更具表达力的提示。引入提示学习不仅提升了模型的泛化能力,还能将任务信息融入框架,同时支持生成式规划与数据合成。需要说明的是,类似方法也被用于 PromptDT 中,但 “提示在扩散模型框架内如何发挥作用” 仍有待研究。
具体而言,我们将任务专属标签 Z 定义为包含状态与动作的轨迹提示: Z : = [ s t ∗ s t + 1 ∗ ⋯ s t + J − 1 ∗ a t ∗ a t + 1 ∗ ⋯ a t + 1 ∗ ] , ( 8 ) Z := \begin{bmatrix} s_t^* & s_{t+1}^* & \cdots & s_{t+J-1}^* \\ a_t^* & a_{t+1}^* & \cdots & a_{t+1}^* \end{bmatrix},(8) Z:=[st∗at∗st+1∗at+1∗⋯⋯st+J−1∗at+1∗],(8)其中带星标的元素与轨迹提示相关联,J 是用于识别任务的环境步长。通过将提示作为条件,MTDIFF 能够隐式捕捉提示中包含的转移模型与奖励函数,从而在无需额外参数微调的情况下,实现对未见过任务的泛化。
在 MTDIFF-P 的决策过程中,我们的目标是生成最大化回报的行为。具体而言,我们通过无分类器引导来实现动作规划:从高斯噪声 x K ( τ ) x_K(\tau) xK(τ) 开始,在每个中间时间步利用扰动后的噪声,将 x k p ( τ ) x_k^p(\tau) xkp(τ) 优化为 x k − 1 p ( τ ) x_{k-1}^p(\tau) xk−1p(τ),以此采样得到最优动作序列 x 0 p ( τ ) x_0^p(\tau) x0p(τ)。扰动后的噪声公式为:
ϵ θ ( x k p ( τ ) , y ′ ( τ ) , ∅ , k ) + α ( ϵ θ ( x k p ( τ ) , y ′ ( τ ) , R ( τ ) , k ) − ϵ θ ( x k p ( τ ) , y ′ ( τ ) , ∅ , k ) ) ( 9 ) \epsilon_\theta(x_k^p(\tau), \boldsymbol{y}'(\tau), \varnothing, k) + \alpha\left(\epsilon_\theta(x_k^p(\tau), \boldsymbol{y}'(\tau), R(\tau), k) - \epsilon_\theta(x_k^p(\tau), \boldsymbol{y}'(\tau), \varnothing, k)\right)(9) ϵθ(xkp(τ),y′(τ),∅,k)+α(ϵθ(xkp(τ),y′(τ),R(τ),k)−ϵθ(xkp(τ),y′(τ),∅,k))(9)
其中 y ′ ( τ ) \boldsymbol{y}'(\tau) y′(τ) 由式 (5) 定义, R ( τ ) R(\tau) R(τ) 是轨迹 τ \tau τ 的归一化回报, α \alpha α 是用于增强并提取数据集中高回报轨迹优质部分的超参数。训练阶段,我们遵循 DDPM 与无分类器引导的方法,训练由噪声模型 ϵ θ \epsilon_\theta ϵθ 参数化的反向扩散过程 p θ p_\theta pθ,对应的损失函数为:
L p ( θ ) : = E k ∼ U ( 1 , K ) , x 0 ( τ ) ∼ q , ϵ ∼ N ( 0 , I ) , β ∼ Bernoulli ( p ) [ ∥ ϵ − ϵ θ ( x k p ( τ ) , y ′ ( τ ) , ( 1 − β ) R ( τ ) + β ∅ , k ) ∥ 2 ] . ( 10 ) \mathcal{L}^p(\theta) := \mathbb{E}_{k \sim \mathcal{U}(1,K), x_0(\tau) \sim q, \epsilon \sim \mathcal{N}(0,\boldsymbol{I}), \beta \sim \text{Bernoulli}(p)} \left[ \left\Vert \epsilon - \epsilon_\theta(x_k^p(\tau), \boldsymbol{y}'(\tau), (1-\beta)R(\tau) + \beta\varnothing, k) \right\Vert^2 \right].(10) Lp(θ):=Ek∼U(1,K),x0(τ)∼q,ϵ∼N(0,I),β∼Bernoulli(p)[∥ϵ−ϵθ(xkp(τ),y′(τ),(1−β)R(τ)+β∅,k)∥2].(10)
需要注意的是:我们从伯努利分布中采样概率 p,以此随机忽略条件回报 R ( τ ) R(\tau) R(τ)。推理阶段,我们采用 “温度采样” 方法生成高回报的动作序列,即采样 x k − 1 p ∼ N ( μ θ ( x k − 1 p , y ′ ( τ ) , R max ( τ ) , k − 1 ) , β Σ k − 1 ) x_{k-1}^p \sim \mathcal{N}\left(\mu_\theta(x_{k-1}^p, \boldsymbol{y}'(\tau), R_{\text{max}}(\tau), k-1), \beta\Sigma_{k-1}\right) xk−1p∼N(μθ(xk−1p,y′(τ),Rmax(τ),k−1),βΣk−1),其中 β ∈ [ 0 , 1 ] \beta \in [0,1] β∈[0,1] 用于降低方差,以生成更优的动作序列。对于 MTDIFF-S,由于其目标是合成多样化轨迹以实现数据增强,无需 R ( τ ) R(\tau) R(τ) 这类引导信息,因此对应的损失函数为:
L s ( θ ) : = E k ∼ U ( 1 , K ) , x 0 ( τ ) ∼ q , ϵ ∼ N ( 0 , I ) [ ∥ ϵ − ϵ θ ( x k s ( τ ) , y s ( τ ) , k ) ∥ 2 ] . ( 11 ) \mathcal{L}^s(\theta) := \mathbb{E}_{k \sim \mathcal{U}(1,K), x_0(\tau) \sim q, \epsilon \sim \mathcal{N}(0,\boldsymbol{I})} \left[ \left\Vert \epsilon - \epsilon_\theta(x_k^s(\tau), \boldsymbol{y}^s(\tau), k) \right\Vert^2 \right]. (11) Ls(θ):=Ek∼U(1,K),x0(τ)∼q,ϵ∼N(0,I)[∥ϵ−ϵθ(xks(τ),ys(τ),k)∥2].(11)我们采样 x k − 1 s ∼ N ( μ θ ( x k − 1 s , y s ( τ ) , k − 1 ) , Σ k − 1 ) x_{k-1}^s \sim \mathcal{N}\left(\mu_\theta(x_{k-1}^s, \boldsymbol{y}^s(\tau), k-1), \Sigma_{k-1}\right) xk−1s∼N(μθ(xk−1s,ys(τ),k−1),Σk−1)。评估过程如图 3 所示。
Architecture Design
相比先前单任务扩散模型工作中常用的 U-Net 架构,我们采用了一种新颖的 Transformer 架构来对 ϵ θ \epsilon_\theta ϵθ进行参数化。具体实现时,我们选用 GPT2 架构 —— 它在序列建模任务中表现出色,同时在性能与计算效率之间实现了良好的平衡。
以统一的方式训练扩散模型来建模多任务数据,将不同输入都视为统一架构中的 “token”,以此提升多样化信息的利用效率。
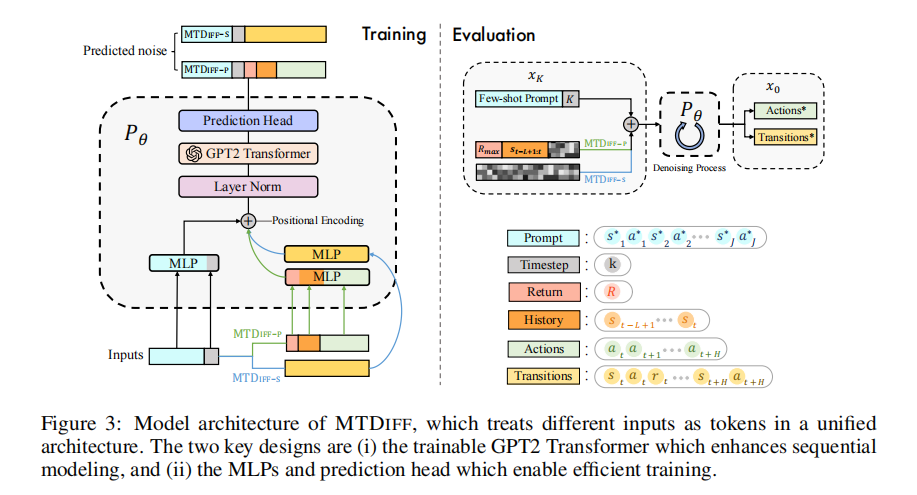
如图 3 所示,架构的处理流程如下:
首先,不同的原始输入x会通过独立的 MLP(多层感知机)f,被嵌入为相同维度d的特征向量h,具体形式为:
- 对于提示和扩散时间步: h P = f P ( x prompt ) , h T i = f T i ( x timestep ) h_P = f_P(x^{\text{prompt}}), h_{T_i} = f_{T_i}(x^{\text{timestep}}) hP=fP(xprompt),hTi=fTi(xtimestep)
- 对于 MTDIFF-S: h T r s = f T r ( x transitions ) h_{T_r}^s = f_{T_r}(x^{\text{transitions}}) hTrs=fTr(xtransitions)
- 对于 MTDIFF-P: h A p = f A ( x actions ) , h H p = f H ( x history ) , h R p = f R ( x return ) h_A^p = f_A(x^{\text{actions}}), h_H^p = f_H(x^{\text{history}}), h_R^p = f_R(x^{\text{return}}) hAp=fA(xactions),hHp=fH(xhistory),hRp=fR(xreturn)
随后,将嵌入向量 h P h_P hP和 h T i h_{T_i} hTi按以下方式拼接,分别构造成 MTDIFF-P 和 MTDIFF-S 的输入 token:
h tokens p = LN ( h T i × [ h P , h T i , h R p , h H p , h A p ] + h R p + E pos ) , h tokens s = LN ( h T i × [ h P , h T i , h T r s ] + E pos ) , h_{\text{tokens}}^p = \text{LN}\left(h_{T_i} \times \left[h_P, h_{T_i}, h_R^p, h_H^p, h_A^p\right] + h_R^p + E^{\text{pos}}\right), \quad h_{\text{tokens}}^s = \text{LN}\left(h_{T_i} \times \left[h_P, h_{T_i}, h_{T_r}^s\right] + E^{\text{pos}}\right), htokensp=LN(hTi×[hP,hTi,hRp,hHp,hAp]+hRp+Epos),htokenss=LN(hTi×[hP,hTi,hTrs]+Epos),其中 E pos E^{\text{pos}} Epos是位置嵌入, LN \text{LN} LN表示层归一化(用于稳定训练过程)。在实现中,我们通过 “与扩散时间步 h T i h_{T_i} hTi相乘” 和 “与回报 h R p h_R^p hRp相加” 的方式,强化了堆叠输入的条件信息。
GPT2 是仅含解码器的 Transformer,其自注意力机制可捕捉输入序列中不同位置的依赖关系。我们将 GPT2 作为 MTDIFF 的可训练骨干网络,用于处理序列输入,输出更新后的特征表示:
h out p = transformer ( h tokens p ) , h out s = transformer ( h tokens s ) . h_{\text{out}}^p = \text{transformer}(h_{\text{tokens}}^p), \quad h_{\text{out}}^s = \text{transformer}(h_{\text{tokens}}^s). houtp=transformer(htokensp),houts=transformer(htokenss).最后,基于输出的特征表示,我们使用由全连接层组成的 “预测头”,预测扩散时间步k对应的噪声。需要注意的是:预测的噪声与原始输入处于同一维度空间(与特征维度d不同),该噪声会在推理阶段用于反向去噪过程 p θ p_\theta pθ。
关于 MTDIFF 的训练流程、架构细节与超参数,在附录 A 中进行了总结。
Related Work
近期强化学习(RL)领域的研究表明,扩散模型能够学习离线策略的多峰分布 [63,43,11] 或人类行为 [8]。其他研究将序列决策问题表述为条件生成过程 [2],并学习生成满足条件约束的轨迹。
多任务强化学习旨在为一组多样化的任务学习一个共享策略。多任务强化学习的主要挑战是不同任务之间的梯度冲突.
数据增强 [13,39] 已被证明在强化学习中具有有效性。
更多内容请查看原文
Experiments
待续
源码分析
MTDiff 由两个主要组件组成,它们协同工作以通过扩散模型实现有效的多任务学习: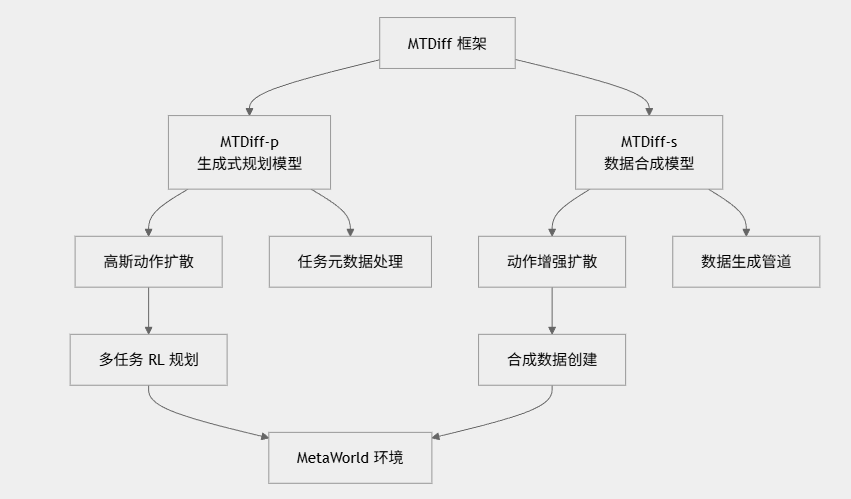
项目结构
代码库组织为几个关键目录:
MTDiff/
├── diffuser/ │ ├── models/ # 扩散模型实现
│ ├── datasets/ # 数据加载和预处理
│ └── utils/ # 实用函数和辅助工具
├── scripts/ # 训练和推理脚本
├── config/ # 配置文件
├── metaworld_prompts/ # 任务提示词嵌入
└── environment.yml # 环境规范
模型组件
Transformer 主干网络:系统采用改进的 GPT-2 架构,适配连续控制任务,其注意力机制专为机器人时序序列建模而设计 :diffuser/models/GPT2.py。
扩散过程:实现了多种扩散变体,包括用于动作生成的 GaussianActDiffusion 和用于数据合成的 AugDiffusion :diffuser/models/diffusion.py。
数据处理:框架支持多个 RL 基准测试,包括 MetaWorld、D4RL 和自定义环境,配备精密的预处理流水线 :diffuser/datasets/d4rl.py。
快速开始
环境安装:
conda env create -f environment.yml
conda activate mtdiff
该环境包含核心依赖项,如 PyTorch 1.9.1、MuJoCo 物理模拟器、D4RL 基准测试套件和 MetaWorld 环境
数据集准备:
数据集地址
从官方 Google Drive 存储库下载所需数据集,其中包含 MetaWorld 任务的预处理轨迹
训练 MTDiff-p(规划):
python scripts/mtdiff_p_meta.py \
--model models.Tasksmeta \
--diffusion models.GaussianActDiffusion \
--loss_type statehuber \
--loader datasets.RTGActDataset \
--device cuda:0
训练 MTDiff-s(数据合成):
python scripts/mtdiff_s.py \
--model models.TasksAug \
--diffusion models.AugDiffusion \
--loss_type statehuber \
--loader datasets.AugDataset \
--device cuda:0
关键参数配置:
MTDiff 的行为通过 config/ 目录中的配置文件控制。主配置位于 config/locomotion.py:
| 参数 | 默认值 | 描述 |
|---|---|---|
| horizon | 32 | 规划时域长度 |
| n_diffusion_steps | 200 | 扩散采样步数 |
| action_weight | 10 | 动作损失项权重 |
| num_tasks | 4 | 并发任务数 |
| dim_mults | (1,2) | 模型维度倍数 |
任务配置:
MTDiff 开箱即用支持 50 个 MetaWorld 任务。任务列表包括操作任务,例如:
- 组装任务:assembly-v2、disassemble-v2
- 按钮任务:button-press-v2、button-press-topdown-v2
- 门任务:door-open-v2、door-close-v2、door-lock-v2、door-unlock-v2
- 抓取放置任务:pick-place-v2、pick-place-wall-v2
- 到达任务:reach-v2、reach-wall-v2
运行推理:
训练完成后,你可以使用 MTDiff-p 进行生成式规划:
python scripts/test_mtdiff_p.py \
--diffusion_loadpath model_saved_path \
--diffusion_epoch selected_epoch \
--device cuda:0
数据集
MTDiff 实现了分层数据集架构,通过统一接口处理多样化的强化学习基准。系统支持三种主要数据集类别:D4RL 环境、MetaWorld 多任务数据集和自定义迷宫导航任务。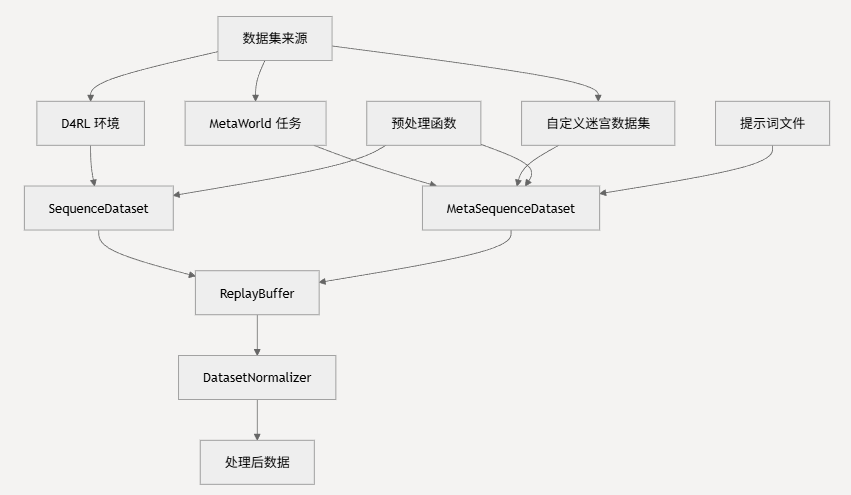
D4RL 环境
框架通过 SequenceDataset 类支持标准 D4RL 基准,该类处理单任务环境,如 MuJoCo 运动任务:
- 运动任务:Hopper、Walker、HalfCheetah、Ant
- 回放数据集:Medium、Medium-Replay、Medium-Expert 变体
- 自定义环境:任何兼容 gym 且具有 get_dataset() 方法的环境
dataset_config = utils.Config(
SequenceDataset,
env='hopper-medium-replay',
horizon=64,
normalizer='LimitsNormalizer',
preprocess_fns=['add_deltas'],
max_path_length=1000,
max_n_episodes=10000,
use_padding=True
)
MetaWorld 多任务数据集
MetaWorld 数据集通过 MetaSequenceDataset 类处理,支持 45 任务和 50 任务基准:
- MT45:45 任务子集,用于高效实验
- MT50:完整 50 任务基准,用于综合评估
- 基于提示词的初始化:使用预计算的提示词轨迹初始化每个任务
dataset_config = utils.Config(
MetaSequenceDataset,
env='metaworld',
task_list=['basketball-v2', 'button-press-v2', ...], horizon=64,
normalizer='LimitsNormalizer',
preprocess_fns=[],
max_path_length=1000,
max_n_episodes=200000,
meta_world=True,
optimal=True # 使用最优演示
)
自定义迷宫数据集
框架通过专门的加载函数支持自定义迷宫导航数据集:
- Maze2D:2D 迷宫导航,包含 8 种不同迷宫配置
- AntMaze:3D ant 在复杂迷宫环境中的导航
- 自定义格式:基于 HDF5 的数据集存储,具有标准化字段
dataset_config = utils.Config(
MetaSequenceDataset,
env='maze2d',
task_list=['maze2d-1', 'maze2d-2', ...],
horizon=64,
normalizer='LimitsNormalizer',
max_path_length=600,
maze2d=True,
seq_length=5
)
核心加载函数:
数据集加载过程通过 diffuser/datasets/d4rl.py 中的几个关键函数协调完成:
- 环境加载:load_environment() 函数处理 gym 环境的初始化和配置,提取核心环境并设置回合步数限制。
- 数据集提取:get_dataset() 函数从环境中检索原始轨迹数据,针对 AntMaze 环境提供特殊处理以修复轨迹分割和奖励缩放中的已知错误。
- 序列生成:sequence_dataset() 函数将原始数据集转换为可迭代的轨迹序列,应用预处理函数并处理回合边界。
回放缓冲区管理
diffuser/datasets/buffer.py 中的 ReplayBuffer 类提供高效的轨迹数据存储和访问:
- 存储结构:按回合组织数据,支持可配置的最大路径长度和回合数,支持动态分配和内存高效存储。
- 数据访问:提供字典式访问(buffer[‘observations’])和属性式访问(buffer.observations)以提高便利性。
- 回合管理:处理回合添加、截断和最终化,具有自动填充和终端状态管理。
预处理流水线
diffuser/datasets/preprocessing.py 中的预处理系统提供模块化转换函数:
- 函数组合:get_preprocess_fn() 函数通过组合多个转换函数创建预处理流水线,实现灵活的数据增强和特征工程。
- 动作转换:包含专门函数,如用于动作空间归一化的 arctanh_actions() 和用于计算状态差异的 add_deltas()。
- 环境特定处理:为不同环境类型提供专门预处理,包括方块操作任务的四元数到欧拉角转换和迷宫特定的终端状态处理。
归一化配置
| 归一化器类型 | 使用场景 | 优势 | 局限性 |
|---|---|---|---|
| GaussianNormalizer | 通用 | 保留统计属性 | 对异常值敏感 |
| LimitsNormalizer | 有界数据 | 保证范围 | 丢失尺度信息 |
| CDFNormalizer | 非均匀分布 | 创建均匀分布 | 计算密集 |
| SafeLimitsNormalizer | 混合数据类型 | 处理边界情况 | 保守归一化 |
MTDiff-p:生成式规划模型
MTDiff-p 代表 MTDiff 框架的核心生成式规划组件,利用 diffusion 模型进行多任务轨迹规划。该模型将基于 transformer 的架构与基于提示词的条件机制相结合,实现了灵活的任务适配和高质量的轨迹生成,适用于多样化的机器人场景。
MTDiff-p 规划模型围绕 Tasksmeta 类构建,该类作为主要的神经架构,结合了时间卷积和 transformer 注意力机制。模型采用 提示词条件生成范式,其中任务特定的演示数据指导规划过程。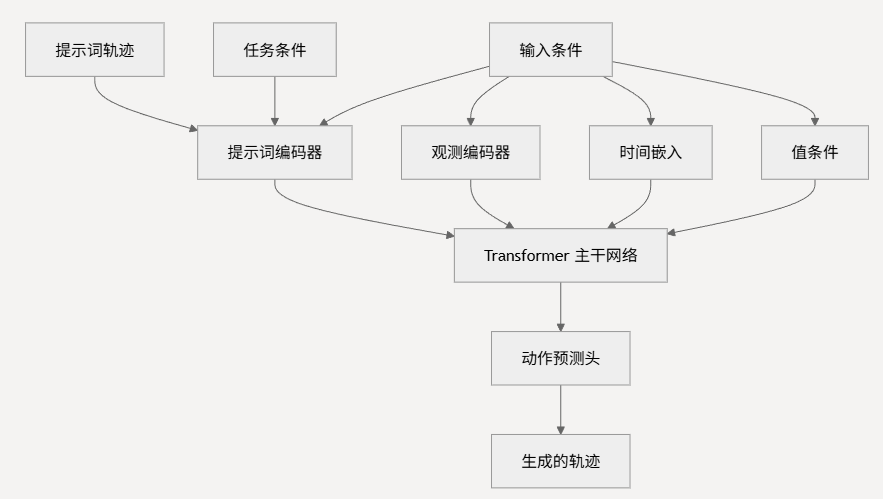
该架构处理多种输入模态:用于任务特定指导的 提示词轨迹、用于当前状态上下文的 观测、用于扩散过程指导的 时间嵌入,以及用于基于奖励条件的 值函数。这些输入被拼接后通过 transformer 主干网络处理,生成最终的动作预测。
Tasksmeta 类实现了主要的规划模型,具有以下关键特征:
- 多头注意力,具有可配置维度(默认:8 个头,256 隐藏层大小)
- 时间建模,通过带卷积层的残差块实现
- 提示词集成,通过可学习嵌入层实现
- 条件生成,支持任务和基于值的指导
模型接受维度为 [batch × horizon × transition] 的输入,其中 transition 包含观测和动作空间。前向传播通过 get_prompt_batchs 函数处理提示词数据,该函数从任务特定的提示词库中采样演示轨迹。
get_prompt_batchs 函数从提示词库中随机采样演示轨迹,将观测和动作拼接形成上下文提示词。这些提示词被嵌入并与其他条件信息结合,指导生成过程。
提示词选择策略因领域而异:
— Meta-World:时间步 0-170 的片段
— Maze 环境:时间步 0-1000 的片段
— 标准任务:时间步 500-1000 的片段
模型配置:
MTDiff-p 通过 utils.Config 系统支持灵活配置:
| 参数 | 默认值 | 描述 |
|---|---|---|
| horizon | 32 | 规划时域长度 |
| transition_dim | obs_dim + 1 | 状态-动作空间维度 |
| num_tasks | 50 (meta) / 3 (maze) | 支持的任务数量 |
| dim | 128 | 基础模型维度 |
| dim_mults | (1, 2, 4, 8) | 层维度倍数 |
| attention | True | 启用注意力机制 |
Tasksmaze
专用于 迷宫导航 任务的优化版本:
- 减小模型维度(dim=64, hidden_size=128)
- 迷宫特定的提示词处理
- 针对导航任务的简化条件
TasksmetaAug
增强版本,具有 增强的条件机制:
- 扩展的提示词处理能力
- 高级注意力机制
- 支持复杂多任务场景
训练流程
- 从任务特定回放缓冲区 加载数据集
- 使用提示词轨迹库 初始化模型
- 配置扩散过程 与损失权重
- 设置训练器 与批处理和优化
MTDiff-s:数据合成模型
MTDiff-s 模型实现了复杂的数据合成流水线,集成了基于提示词的调节机制与基于扩散的生成技术。该架构包含三个主要组件:用于任务调节的提示词编码器、用于序列建模的 Transformer 主干网络,以及用于轨迹生成的扩散过程。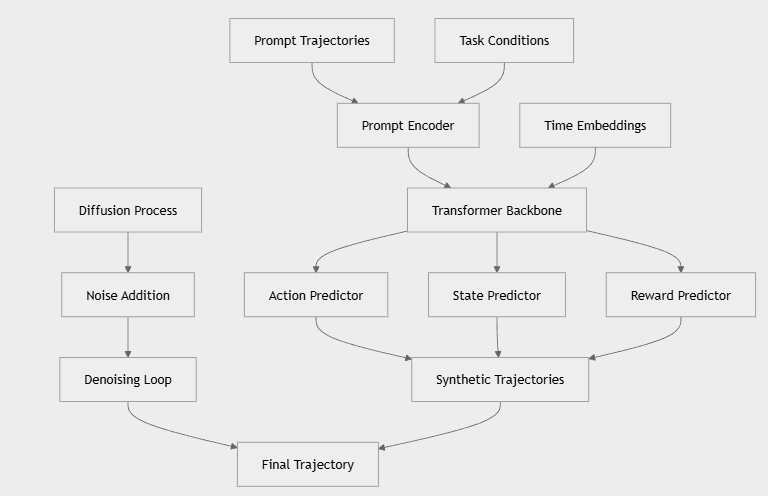
TasksmetaAug 模型
TasksmetaAug 类作为主要的数据合成模型,实现了基于 Transformer 的架构并具备提示词调节功能 TasksmetaAug。该模型处理状态、动作和奖励序列,同时整合任务特定的提示词以指导生成过程。
模型架构包括:
- GPT2 Transformer 主干网络:采用 6 层 GPT2 配置,隐藏状态维度为 256,注意力头数为 4 TasksmetaAug
- 提示词嵌入层:将提示词轨迹转换为任务调节嵌入 TasksmetaAug
- 专用 MLP:分别为状态、动作、奖励和时间信息设计独立的嵌入网络 TasksmetaAug
- 位置嵌入:用于序列排序的固定位置编码 TasksmetaAug
AugDiffusion 过程
AugDiffusion 类实现了轨迹生成的扩散机制 AugDiffusion。该方法扩展了逆扩散过程,引入任务特定的调节和损失加权策略。
主要特性包括:
- 任务条件采样:基于特定任务标识符生成轨迹 AugDiffusion
- 渐进式去噪:迭代优化随机噪声为连贯轨迹 AugDiffusion
- 损失加权:应用时间折扣以优先处理早期轨迹段 AugDiffusion
提示词处理
系统从预收集的演示轨迹中提取任务特定提示词 get_prompt_batchs。每个提示词包含从成功回合中随机采样的 20 个时间步,为目标任务提供上下文信息。
def get_prompt_batchs(prompt_trajectories, cond, num_episodes=2, num_steps=20, is_meta=True):
cond = cond.long()
trajectories = [get_prompt(prompt_trajectories[ind], num_episodes, num_steps, is_meta) for ind in cond]
return torch.tensor(np.array(trajectories))
模型配置
MTDiff-s 脚本使用特定超参数配置合成模型 mtdiff_s.py:
- Horizon:轨迹生成的时间步数为 32
- Transition Dimension:观测值加动作维度
- 任务调节:支持多个同时任务
- 设备配置:训练和推理的 GPU 加速
Transformer 骨干网络集成
MTDiff 的 Transformer 集成基础是一个定制的 GPT-2 模型,专门为轨迹生成而非语言建模进行配置。该配置揭示了优化模型用于时间序列处理的关键架构选择:
config = transformers.GPT2Config(
vocab_size=1, n_embd=hidden_size,
n_layer=4,
n_head=2,
n_inner=4 * 256,
activation_function='mish',
n_positions=1024,
n_ctx=1023,
resid_pdrop=0.1,
attn_pdrop=0.1,
)
该模型消除了词汇表依赖(vocab_size=1),因为它处理连续嵌入而非离散 token。注意力机制通过偏置缓冲区保持因果掩码,实现动作序列的自回归生成。
时间嵌入:正弦位置编码通过多层感知器捕获扩散时间步信息:
self.time_mlp = nn.Sequential(
SinusoidalPosEmb(2*dim),
nn.Linear(2*dim, dim * 4),
nn.Mish(),
nn.Linear(dim * 4, 2*dim),
)
提示词嵌入:任务特定的演示轨迹通过深度网络嵌入:
self.prompt_embed = nn.Sequential(
nn.LayerNorm(self.state_dim+self.action_dim),
nn.Linear(self.state_dim + self.action_dim, hidden_size*2),
nn.Mish(),
nn.Linear(hidden_size * 2, 4 * hidden_size),
nn.Mish(),
nn.Linear(4 * hidden_size, hidden_size),
)
Tasksmeta 架构
专为 Meta-World 环境设计,采用 4 层 2 头注意力配置。前向传播连接多个嵌入流:
- 时间嵌入(1 个 token)
- 条件返回嵌入(1 个 token)
- 提示词嵌入(20 个 token)
- 观测嵌入(2 个 token)
- 动作嵌入(horizon 个 token)
TasksmetaAug 架构
增强版本,采用 6 层 4 头注意力,预测完整的转换元组:
stacked_inputs = torch.stack(
(state_embeddings, action_embeddings, reward_embeddings, next_state_embeddings), dim=1
).permute(0, 2, 1, 3).reshape(batch_size, 4 * seq_length, self.hidden_size)
该架构交错排列状态-动作-奖励-下一状态序列,实现全面的轨迹建模。
因果注意力结构 ---- 底层 GPT-2 注意力机制通过三角偏置矩阵保持因果掩码:
self.register_buffer(
"bias", torch.tril(torch.ones((n_ctx, n_ctx), dtype=torch.uint8)).view(1, 1, n_ctx, n_ctx)
)
这确保自回归生成,其中每个动作预测仅依赖于先前的状态和动作。
位置编码集成:自定义位置嵌入处理可变长度序列:
self.position_emb = nn.Parameter(torch.zeros(1, 24+horizon, hidden_size))
# 应用方式:
stacked_inputs = t * stacked_inputs + cond_return + self.position_emb[:, :stacked_inputs.shape[1], :]
位置嵌入随时间嵌入缩放并添加任务条件,为序列生成提供时空上下文。
扩散模型的实现
MTDiff中的高斯扩散过程实现了一个复杂的前向加噪和反向去噪机制,能够为强化学习任务生成高质量的动作序列。这一过程既是MTDiff-p规划能力的基础,也是MTDiff-s数据合成功能的核心,通过可控的随机过程为序列决策提供了坚实的数学基础。
前向扩散过程
前向扩散过程在多个时间步中系统地向干净的动作序列添加高斯噪声,创建了模型可学习的可预测噪声调度。该过程从一条干净的轨迹开始,通过一系列参数化步骤逐步将其转换为纯噪声。
核心的前向采样方程实现了方差保持(VP)公式:
def q_sample(self, x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sample = (
extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
)
return sample
噪声调度可在余弦和VP调度之间配置:
if beta_schedule == 'cosine':
betas = cosine_beta_schedule(n_timesteps)
elif beta_schedule == 'vp':
betas = vp_beta_schedule(n_timesteps)
默认使用的VP调度提供了数学上最优的噪声分布,在各个时间步中保持方差结构
反向去噪过程
反向过程学习预测并去除前向过程中添加的噪声,有效地从噪声输入中重建干净的动作序列。这是通过一个神经网络实现的,该网络预测噪声本身或原始干净信号。
模型支持两种由predict_epsilon参数控制的预测策略:
def predict_start_from_noise(self, x_t, t, noise):
if self.predict_epsilon:
return (
extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
else:
return noise
当predict_epsilon=True时,模型学习预测噪声分量,然后通过数学变换恢复原始信号。这种方法已被证明能提供更稳定的训练动态
反向步骤的后验分布计算遵循解析解:
def q_posterior(self, x_start, x_t, t):
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
这使用从噪声调度导出的预计算系数计算精确的后验分布q(x_{t-1} | x_t, x_0)
待续

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)