[特殊字符] 我让AI替我搭n8n工作流,它居然自己修好了bug——10步全自动构建流水线揭秘
本文介绍了一个AI自动化构建n8n工作流的解决方案。作者将整个工作流构建过程封装成10个步骤的AI Skill,从需求分析到部署验证全程自动化。这套系统通过结构化框架将复杂任务拆解为可执行步骤,支持互联网检索、方案讨论、知识库查询等功能,并能自动修复常见错误。与官方AI Builder相比,该方案更透明可控,支持知识沉淀和团队复用。文末提供可直接复用的完整提示词,帮助开发者快速实现类似功能。
凌晨11点,第4次点击「Execute Workflow」,红色报错。
又崩了。
如果你用过n8n,这个场景一定不陌生:打开编辑器,面对空白画布,不知道从哪个节点开始拖。好不容易连了一串节点,运行报错。改了参数,又报错。改来改去,时间就这么没了。
我也踩过这些坑。我是一个效率强迫症患者——任何重复超过三次的事情,都想让机器去干。
后来我做了一件事:把整个n8n工作流的构建过程,封装成了一个 AI Skill。
现在,我只需要用一句话描述需求,AI 就能自动完成从需求分析到部署上线的全部 10个步骤。不是生成一段代码让你手动粘贴,而是直接在你的n8n实例上创建、验证、部署一个能跑的工作流。
手动搭工作流就像手写汇编——能跑,但你的时间不值钱吗?
读完这篇文章,你能拿到:
- 🧠 一套结构化的 10步构建框架,理解AI怎么系统性地构建工作流
- 🏭 一种 「Skill即流水线」的思维模型,把任何复杂任务拆成可执行步骤
- 🚀 文末还有 可直接复刻的超级提示词,复制给Claude Code就能从零搭建这整套系统
推荐服务:
🔥weelinking 提供稳定的 Claude、Codex、Gemini 等大模型服务,支持个人开发者与企业级定制,欢迎大家前来体验。
📱 想要获取更多AI编程工具资讯?欢迎通过官方渠道「weelinking」了解最新动态!
📖 本文导航(全文约6500字,阅读约15分钟)
🔧 先搞清楚:什么是Skill?
在开始之前,我们得先对齐一个概念。
Skill是Claude Code的能力扩展模块。 你可以把它理解成「一本写给AI的操作手册」。
打个比方:你新招了一个实习生,TA很聪明但什么都不会。你要让TA独立完成一项工作,不是每次都口头教一遍,而是写一份标准操作流程(SOP),TA照着做就行。
Skill就是这份SOP。只不过它的读者不是人,而是AI。
但Skill不只是SOP。它是纳瓦尔说的那种「代码杠杆」——写一次,复用无限次,还能分享给所有人。一个人写了一套Skill,等于雇了一个永远不会离职、不会忘记流程、还能持续进化的专家团队。
这才是AI编程的真正杠杆点:你不是在写代码,你是在训练一个永不停歇的专家。
🎯 打个比方
如果Claude Code是一个万能实习生,Skill就是你给TA的岗位培训手册。手册写得越详细,TA干活越靠谱。
说一个真实场景。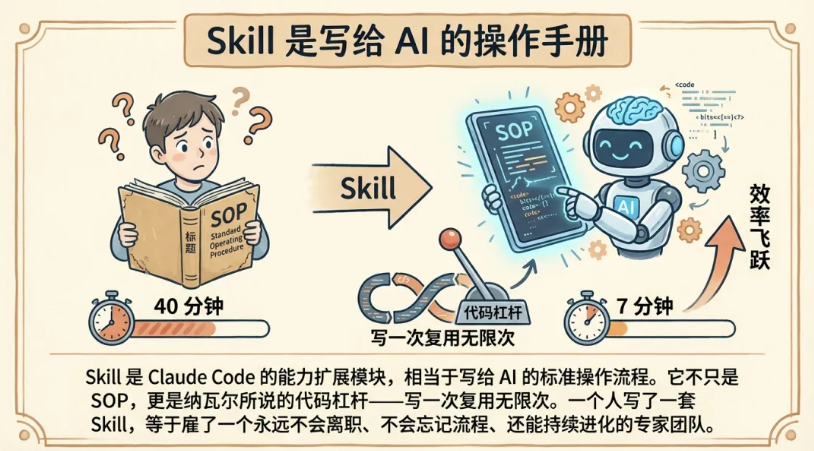
上周有人找我做一个「收到Typeform表单 → 用AI分析内容 → 写入Notion数据库 → 发送Slack通知」的工作流。以前我大概需要40分钟:查节点文档、写表达式、调试报错、绑定凭据。
用Skill,我在终端敲了一句话描述需求,去倒了杯咖啡,回来工作流已经部署好了。
那它跟n8n是什么关系?
n8n是一个开源的工作流自动化平台,你可以在上面用拖拽节点的方式搭建各种自动化流程。它有400多个官方节点,覆盖了市面上大部分常用服务。
问题在于:n8n虽然强大,但手动搭建工作流依然很痛苦。你需要知道用哪些节点、怎么配置参数、表达式语法怎么写、凭据怎么绑定……对新手来说,光是搞清楚这些就够喝一壶了。
不管你是独立开发者还是运维工程师,不管你的n8n上跑着3个工作流还是300个——手动搭建的痛苦是一样的。
所以我做了一个Skill,让AI来干这些苦活。
AI不是来替代你的,是来替代你最不想干的那部分。
🤔 为什么要用AI来搭工作流?
你可能会想:AI搭的东西质量能行吗?
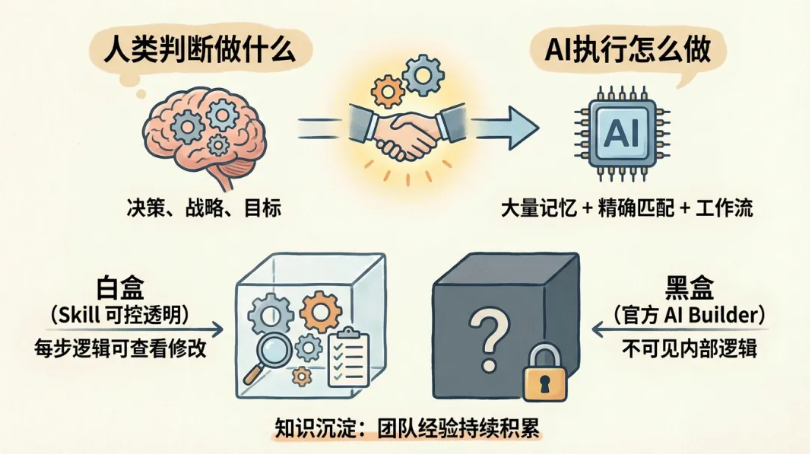
反过来想:搭工作流需要什么?记住400多个节点的配置细节、表达式语法、版本兼容性、凭据绑定规则……这些恰好是AI的强项——大量记忆 + 精确匹配 + 不犯低级错误。
人类擅长的是判断「做什么」。AI擅长的是执行「怎么做」。让对的角色干对的事,效率才能最大化。
你可能会说:「但AI又不懂我的业务逻辑。」
没错。所以Step 03是方案讨论——AI提方案,你拍板。AI不替你做决策,但它替你干决策之后的所有苦活。这才是人机协作的正确姿势。
你可能还会问:n8n不是已经有官方的AI Workflow Builder了吗?为什么还要自己做一个Skill?
官方AI Builder只管「生成」,不管「验证」。 它能帮你生成一个工作流,但不会告诉你这个工作流能不能跑。节点配置有没有错?凭据绑了没有?社区节点装了没有?这些都得你自己检查。
而且官方AI Builder是黑盒,Skill是白盒。Skill的每一步逻辑都写在Markdown文件里,你可以随时查看、修改、优化。觉得验证环节不够严格?改step08。觉得搜索策略太保守?改step02。你掌握完整的控制权。
白盒胜过黑盒,可控胜过便捷。
你敢把核心业务流程交给一个你看不见源码的黑盒吗?
还有一点:Skill能沉淀团队知识。你团队踩过的坑、总结的最佳实践、积累的架构模式,都可以写进Skill的reference/目录。下一次构建时,AI会自动调用这些知识。这是一个持续进化的知识库。
Reddit上有一位n8n深度用户分享了他的经验:与其一次性让AI生成整个工作流,不如分块构建、逐段验证。这恰好就是我这个Skill的设计思路——10步流水线,每一步都有明确的输入输出和验证条件。
Delivery Hero靠一个n8n工作流每月节省200小时。StepStone在生产环境运行着200多个关键工作流。当工作流的规模达到这个量级,手动维护已经不现实了。
工具是用来驯服的,不是用来伺候的。如果你花在「配置工具」上的时间比「使用工具」还多——那工具在驯服你。
推荐服务:如果你对这些最新的 AI 编程工具感兴趣,想体验 Claude、Codex、Gemini 等大模型的强大功能,可以通过 weelinking 平台获取稳定的服务,支持个人开发者与企业级定制。
🧩 10步全自动构建流水线:完整拆解
现在进入核心部分。这个Skill把n8n工作流的构建拆成了10个步骤,分为三个阶段。
准备阶段:从一句话到确定方案(Step 01-04)
Step 01:需求获取。
AI会问你6个问题——你想自动化什么流程?触发方式是什么?需要哪些外部服务?预期的输入输出是什么?
这一步的关键不是「问问题」,而是把模糊的需求翻译成结构化的配置。比如你说「我想做一个收到表单提交后自动发邮件的工作流」,AI会翻译成:触发方式是Form Trigger,核心节点是Email Send,数据流是表单输入 → 数据处理 → 邮件发送。
所有配置保存到JSON文件,支持断点恢复。
Step 02:互联网检索。
AI执行三轮Brave搜索,然后用WebFetch深度抓取高价值原文,接着调用n8n-mcp的节点搜索和模板搜索工具,交叉验证。
为什么要搜索互联网?因为n8n的生态在快速迭代。目前已经有8462个社区模板。本地知识库再全,也赶不上互联网的更新速度。而且如果社区已经有高度匹配的模板,AI会推荐「使用模板」的快速路径,直接跳到凭据配置,省掉中间的设计和构建环节。
Step 03:方案讨论。
AI把检索结果整理成方案摘要,展示给你确认。这是整个流水线中唯一需要你介入的步骤。
📝 记住这个
Step 03是整个流水线的「关卡」。确认之前,一切都可以调整。确认之后,AI全速推进。
Step 04:知识库查询。
根据确认的方案,AI从本地知识库中提取需要的节点配置、架构模式和代码模板。知识分三层:第一层是节点目录(540多个节点的快速索引),第二层通过MCP工具获取完整属性定义,第三层是深度参考文档。三层架构做到了按需加载——只读当前步骤需要的信息,不浪费token。
到这里,准备工作完成了。AI已经知道你要什么、搜过了互联网、确认了方案、查好了知识库。
接下来,它要开始真正动手了。
执行阶段:从蓝图到可运行工作流(Step 05-08)
Step 05:架构设计。
输出一份完整的设计稿design.md,包括节点清单、连接关系、表达式定义和Code节点逻辑。这份文档是工作流的「蓝图」——先设计再构建,设计阶段发现问题的修复成本远低于部署后。
Step 06:工作流构建。
AI根据设计稿,调用n8n API在你的n8n实例上创建工作流。如果用到了社区节点,还会通过REST API检查安装状态,未安装则自动安装。
Step 07:凭据配置。
凭据就是「通行证」——你的工作流要访问Gmail、Slack、数据库这些外部服务,就需要出示对应的通行证。AI通过REST API扫描节点、识别需求、查询已有凭据、创建缺失凭据、绑定到对应节点。
Step 08:验证修复。
这是整个Skill中最硬核的步骤(379行指令文件)。
AI调用验证工具检查工作流。如果有错误,进入修复循环:第1轮尝试内部修复;第1.5轮社区节点诊断;第2轮起触发互联网搜索;第3.5轮用测试数据实际跑一遍。最多10轮。 如果还修不好,输出终止报告和可行替代方案。
手动调试n8n工作流的错误,是大多数人放弃的原因。这个验证修复循环就是为了接住这个痛点。
🔬 底层原理
验证修复循环的本质是:快速失败,然后让AI替你兜底。每一轮修复都会重新验证,确保修一个错不会引入新的错。10轮上限是为了防止无限循环——有些错误确实是系统级的,AI也修不了。
你有没有过这种经历——手动debug一个n8n工作流,改了三小时发现是凭据没绑?
我第一次看到AI自己修好了一个连我都没发现的bug时,愣了三秒。
那一刻的感觉很奇妙:你不是在用工具,你是在跟一个搭档协作。 它不只是执行命令,它在理解你的意图,然后用你想不到的方式解决问题。
这就是为什么我说这不只是一个自动化工具。
交付阶段:从可运行到可信赖(Step 09-10)
Step 09:部署激活。
AI激活工作流,然后执行运行时验证——确认工作流在跑,触发器在监听。如果是Form类型的工作流,还会获取Form的访问URL。
🎉 里程碑
走到这一步,你的工作流已经在n8n上跑起来了。从一句话描述到一个活跃的自动化流程,全程不需要手动拖拽一个节点。
如果你之前花过两小时搭一个跑不通的工作流——现在你知道那两小时可以省下来了。
Step 10:输出导出。
AI获取完整的工作流JSON,保存到本地,同时生成部署报告。「双输出」设计:既部署到n8n实例(线上可用),又导出JSON到本地(离线备份)。两条腿走路,任何一条出问题都有兜底。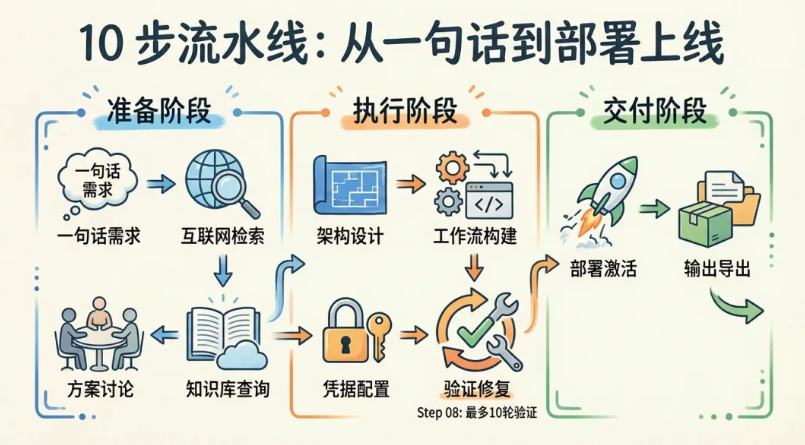
📸 实战案例:一句话生成Gemini图片生成器
光讲框架太抽象。看一个真实案例——我用这套系统搭了一个「Gemini AI图片生成器」工作流。
需求描述(我说的那句话):
“帮我做一个n8n工作流,用户通过表单输入图片主题、选择风格和语言,调用Gemini API生成图片,然后把图片直接展示在表单页面上。”
就这一句话。AI干了什么?
Step 01-03: AI问我几个问题确认需求后,搜索了Gemini 2.0 Flash的图片生成API文档,确认了generateContent接口支持IMAGE模态输出。
Step 05 架构设计: AI输出了一条6节点的链条式结构——数据从左到右依次流过每个节点:
Form Trigger → Build Request → Gemini API → Extract Image → Format Output → Show Result
这里面有几个手动搭建最容易踩坑的细节:
- 表单配置:3个输入字段(主题、风格、语言),结果直接回显到表单页面
- API调用:一段JavaScript把中文风格名翻译成英文提示词,再拼成Gemini能理解的请求格式
- 图片渲染:把AI返回的图片数据直接渲染成带圆角阴影的卡片,内嵌到表单结果页
Step 06-08: AI创建工作流、绑定Gemini API凭据——但第一轮验证没通过。
Gemini 2.0 Flash的图片生成接口比较新,AI在Build Request节点的请求体格式上踩了坑。但这正是agent的优势:它不会卡住等你来救——它自动检索了Gemini API最新文档,修正了generationConfig的参数结构,第二轮验证通过。
这次调试AI自己闭环了:发现错误 → 搜索网络 → 修正代码 → 重新验证。但不是每次都这么顺——遇到业务逻辑相关的报错,你还是得看一眼AI的修复方向对不对,必要时给它纠偏。
最终结果:6个节点,3个Code节点(含约50行JavaScript),1个HTTP Request,完整的表单交互——从用户填写到图片展示,全流程闭环。工作流JSON总计247行。
如果手动搭这个工作流,你需要做什么?
- 查Gemini 2.0 Flash API文档,搞清楚怎么请求图片生成(responseModalities: [‘TEXT’, ‘IMAGE’])
- 写Form Trigger的formFields配置(dropdown选项的JSON格式很容易写错)
- 写3个Code节点的JavaScript(风格映射、响应解析、HTML渲染)
- 配置HTTP Request的Header Auth和请求体表达式
- 调试Form的responseMode和webhookId分配
- 测试整个链路,确保base64图片能正确渲染
保守估计1-2小时。AI用了不到10分钟。
这就是「生成」和「跑通」的区别。不只是拼节点——是把API文档、表达式语法、Code节点编程、凭据绑定、Form交互这些零散知识点,全部串成一个能跑的完整系统。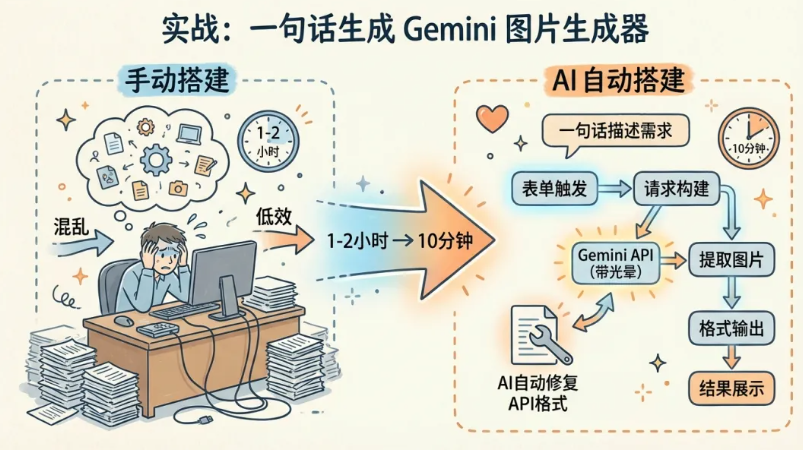
🏗️ 底层设计与迁移场景
看完10步拆解,你可能会觉得:这不就是把一个任务拆成10个小任务吗?
不完全是。关键在几个设计决策。
为什么是10步?
最初的版本只有5步(需求 → 设计 → 构建 → 验证 → 部署)。但实践中发现,「设计」这一步太重了——它既要搜索互联网、又要查知识库、还要跟用户确认方案。拆开后,每一步的职责更单一,AI的执行质量更高。反过来,20步也不好。步骤太多会增加进度管理的复杂度。
10步不是因为复杂,是因为每一步都只干一件事。
为什么先搜索互联网再查本地知识库?
互联网搜索能发现最新的节点和模板,本地知识库提供深度的配置细节。先广后深,先发现后精研。如果反过来,你可能会基于过时的知识做设计,错过更好的方案。
为什么验证和修复放在一起?
「验证 → 发现错误 → 修复 → 重新验证」是一个天然的循环。修复策略本身是分层递进的:先用本地知识修,修不好再搜互联网,再修不好就检查凭据,最后实在不行输出报告。这种层层升级的逻辑,放在一个步骤里管理最自然。
说到底,这套系统解决的是一个根本问题:你的时间花在哪里?
有些人愿意花两小时手动拖节点,觉得「亲手搭的才放心」。
但我们这类人不一样。我们相信:重复劳动是bug,不是特性。 能让机器干的事,绝不浪费人脑。
这不是懒,这是对时间的尊重。
而且这套10步流水线的设计模式不局限于n8n。你可以把它迁移到任何「需要多步骤构建复杂产物」的场景:
- Cloudflare Workers部署:需求获取 → 架构设计 → 代码生成 → 部署 → 验证
- 数据库迁移:需求分析 → 影响评估 → 迁移脚本生成 → 验证 → 执行
- CI/CD流水线搭建:需求获取 → 工具选型 → 配置生成 → 验证 → 部署
核心模式都一样:需求 → 研究 → 设计 → 构建 → 验证 → 部署。
往更深一层看,这里发生了一个范式转换。传统编程是:人写代码 → 机器执行。Skill编程是:人写规则 → AI写代码 → 机器执行。多了一层抽象,但这一层抽象让你从「怎么做」的细节中解放出来,只需要关注「做什么」和「做得对不对」。
这不是效率提升——这是编程方式的代际变化。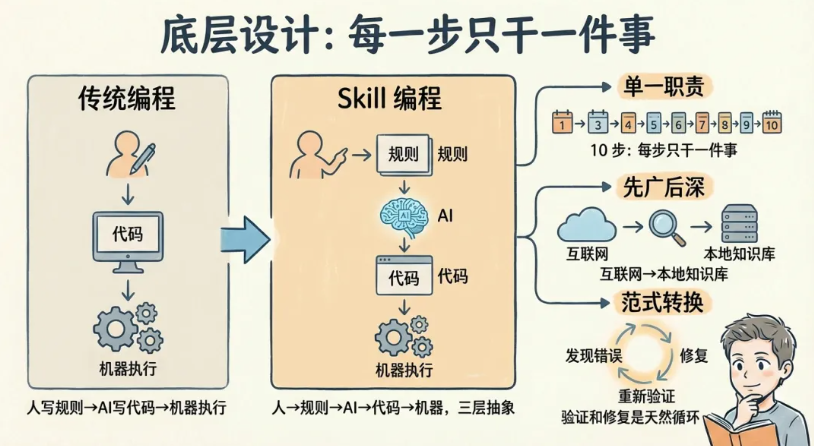
⚖️ 跟n8n官方AI Builder对比
| 维度 | 官方AI Builder | 这套Skill |
|---|---|---|
| 生成工作流 | ✅ | ✅ |
| 自动验证修复 | ❌ | ✅ 最多10轮 |
| 凭据管理 | ❌ | ✅ 自动扫描绑定 |
| 社区节点 | ❌ | ✅ 自动安装 |
| 知识沉淀 | ❌ | ✅ 持续积累 |
| 可定制性 | 黑盒 | 白盒,每步可改 |
| 断点恢复 | ❌ | ✅ |
| 费用 | n8n付费功能 | 免费(需Claude Code) |
⚠️ 常见卡点和解决思路
如果你准备自己复刻这套系统,这里是几个最容易踩的坑:
1. 社区节点安装失败
症状:构建工作流时报"Unknown node type"。
原因:社区节点未安装。
解决方案:在构建完成后,通过REST API检查安装状态,未安装的节点通过POST /community-packages安装。
2. 表达式语法错误
n8n的表达式有两种引用方式:dot notation($json.field)和bracket notation($json['field'])。当字段名包含空格或特殊字符时,必须用bracket notation。
3. typeVersion不匹配
n8n节点的不同版本配置格式可能完全不同。比如Form Trigger v2.2和v2.3的配置差异很大。AI必须使用精确的版本号。
4. 凭据绑定遗漏
工作流能通过验证但运行时报认证错误。原因是凭据没有正确绑定到节点。
5. 10轮验证还修不好怎么办?
这种情况确实存在,通常是系统级问题(比如n8n版本不兼容、API服务商变更了接口)。Skill会输出一份终止报告,说明错误原因和可行的替代方案,你可以据此手动处理。
说句实话。这套系统不是万能的。它擅长的是「结构清晰、节点成熟、API文档完善」的工作流——覆盖了大多数常见场景。但有些情况它确实搞不定:
- 涉及未公开API或私有协议的集成
- 需要复杂业务逻辑判断的分支编排(AI能搭结构,但业务规则得你来定)
- n8n社区节点本身有bug的情况
这些场景下,你仍然需要介入——审查AI的输出、调整业务逻辑、处理边缘情况。AI是搭档,不是替身。 期望它解决100%的问题,反而会让你在那10%的例外面前措手不及。
说了这么多局限,是不是有点劝退?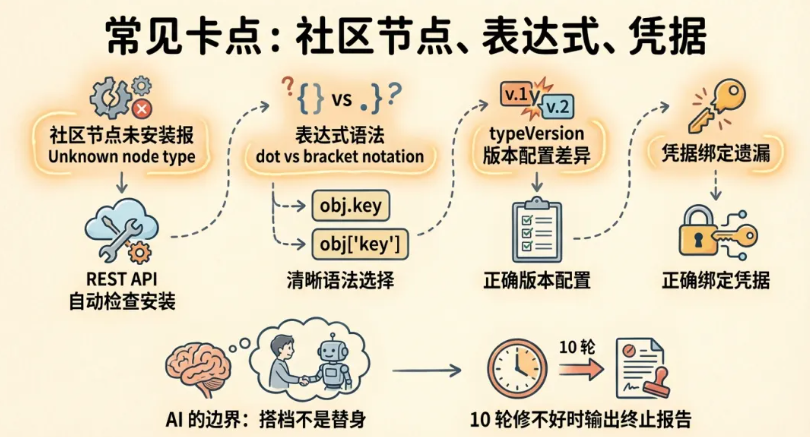
别急。上面说的是极端情况。绝大多数常见工作流——表单收集、数据同步、通知推送、AI处理——这套系统都能搞定。
不信?试一次就知道了。
🚀 一键复刻
👇 下面这段是给Claude Code的完整指令(约800字)。如果你不是程序员,可以跳过直接看文末总结。如果你要动手复刻,复制这整段发给Claude Code就行。
复制这段提示词给Claude Code,从零复刻完整系统:
你是高级自动化架构师。请从零搭建一个n8n工作流全自动构建系统(Claude Code Skill),实现以下完整功能:
系统定位:10步端到端流水线,从用户一句话需求到n8n实例上的活跃工作流,全程自动化。
目录结构:
- skill.md:主入口,声明触发条件、执行规范、10步总览、MCP工具声明、参考资料索引
- workflow/:10个步骤指令文件
- step01-requirements.md:需求获取,6问题集 + keyword标准化 + runs目录初始化
- step02-research.md:互联网检索,brave 3轮搜索 + WebFetch深度抓取 + search_nodes交叉验证 + search_templates 3轮 + 模板diff
- step03-discuss.md:方案讨论,展示research.md摘要 + 用户3轮调整 + confirmed_plan锁定 + 模板快速路径
- step04-knowledge.md:知识库查询,三层知识架构(Layer1 节点目录 + Layer2 MCP get_node + Layer3 深度文档)
- step05-design.md:架构设计,输出design.md(节点清单 + 拓扑 + 表达式 + Code逻辑 + formFields)
- step06-build.md:工作流构建,n8n_create_workflow + 社区节点REST API安装检查 + typeVersion信任链 + formTrigger特殊处理
- step07-credentials.md:凭据配置,REST API扫描/查询/创建/绑定
- step08-validate.md:验证修复,最多10轮循环(内部修复 → 社区节点诊断 → 互联网搜索 → 动态验证 → 终止报告)
- step09-deploy.md:部署激活,activate + 运行时验证 + Form URL获取
- step10-output.md:输出导出,JSON备份 + 部署报告
- reference/:知识库
- tools/:MCP工具使用指南(4文件)
- patterns/:7种核心架构模式 + 编排模式(8文件)
- code/javascript/:Code节点JS编程(6文件)
- code/python/:Code节点Python编程(5文件)
- rules/:验证规则 + 错误目录 + 误报处理(4文件)
- specs/:节点配置 + 表达式语法(8文件)
- credentials/:n8n连接凭据模板
- docs/:项目文档(setup.md + 社区节点管理)
- runs/:每次执行的独立运行目录
核心约束:
- 先读后做:执行Step N前必读对应指令文件
- 不跳步骤:严格1-10顺序执行
- 互联网检索串行调用,间隔≥2秒
- 方案必须用户确认后才能继续
- 凭据操作用REST API(MCP不支持)
- 验证最多10轮,超出输出终止报告
- 双输出:部署到n8n + 导出JSON到本地
- 每步完成后更新progress.json支持断点恢复
依赖:n8n-mcp MCP Server(19个工具:节点发现、模板管理、工作流CRUD、验证执行、版本管理)
请完整实现每个步骤的指令文件,包含详细的执行逻辑、输入输出定义、验证条件和错误处理。reference/目录下的知识文件需要包含n8n节点配置的核心规则、表达式语法规范、常见错误目录和修复策略。
🎓 结语
回顾一下这篇文章的核心:
- Skill是代码杠杆——写一次复用无限次,还能分享
- 10步流水线是可迁移的模式——不止n8n,任何复杂构建都能套
- 验证修复才是护城河——生成容易,跑通才难
如果你也是那种「不愿在重复劳动上浪费一秒钟」的人——这篇文章里的每一行,都是写给你的。
我们这群人有个共同点:不满足于用工具,而是要驯服工具。
你不需要学会搭n8n工作流——你需要学会教AI搭。
💡 本系列全程使用 weelinking 访问 Claude,国内可稳定使用
🚀 整个系列的核心理念:你不需要变成程序员,你只需要从"找人做"变成"自己能做"。
🎓 想系统学习AI编程工作流? 这套10步n8n全自动构建流水线只是「自动化工作流」模块的一个实战项目。在**weelinking**,你还会学到微信公众号批量运营、小红书内容创作、视频剪辑、SEO优化等各类实战项目。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)