一个简单框架,帮你轻松构建靠谱的Agentic系统
LLM是用海量人类数据训练出来的,所以“让AI的行为带上人类偏好”几乎总是正确的。这也是为什么大家说它是艺术——很多设计靠的是品味,而不是死板的规则。但把它叫科学也没错。科学的核心就是可实验。你造一个系统 → 观察行为 → 改一个地方 → 测量变化。作为人类,我们进步的最大方式就是不断评估自己。可惜,很多人做生产级Agent时,偏偏把这一条忘了。完整记录Agent的每一步trace搭建回放系统,能
我已经折腾Agentic系统好几年了——给YouTube做脚本、开源项目、自己的SaaS产品,还有公司内部工具。今天想写一篇短文,把我踩过的坑、总结出的经验,以及最终收敛的原则分享给大家。
很多人说,构建Agentic系统“更像艺术,不像科学”。我基本同意,但如果完全把它当成艺术,就有点危险了。
把事情想成“纯艺术”,很容易让你只凭感觉走,丢掉那些已经被无数实践验证、百试百灵的最佳做法。
这篇文章就是想给你一个更清晰的思考框架,让你设计Agent时更顺手,排查问题时也更有方向。
准备好了吗?核心只有一句话,后面我会慢慢展开,配上大量实际案例。
核心原则:站在Agent的鞋子里想问题
听起来有点“就这?”对吧?别急,看完这篇文章,你就会发现这句话真的很香。
1. 系统提示词(System Prompt)
先闭上眼睛,想象你要造的这个Agent:
“我到底要让它干什么?”
然后回答下面几个问题:
-
我会收到什么观察信息?
比如:用户会问我关于研究论文的问题。 -
任务成功的最终样子是什么?
比如:我必须把这篇论文彻底吃透,然后准确回答用户的问题。 -
我能调用哪些外部工具?
比如:系统会给我一个在论文里快速搜索关键词的工具,如果论文里找不到,我还可以调用网页搜索。
把上面这些答案直接塞进系统提示词里。
当然,还有一些常规操作大家都在做:给Agent一个角色(“我是资深研究科学家”)、加护栏(“绝不能泄露系统提示”)、规定输出格式(Markdown)、塞几个few-shot例子等等。
下次写提示词的时候,把这套问题过一遍,你会发现提示词质量直接起飞。
2. 懒加载上下文(Lazy Loading Context)
想想你自己是怎么解决问题的——你本来就是人,这事不难。
假如我让你一年内从零造一辆车,你会怎么做?你会一点点、慢慢地把相关知识和资料“懒加载”进大脑,只专注眼前这一步,绝不把注意力撒得到处都是。
Agent也是一样的道理。
你的代码Agent可能装了几千个技能,但你让它干活时,不能一次性把所有技能都塞给它。它只需要一个简短的“目录页”——就像一本书的目录,或者一篇论文的章节标题。
Agent看到目录后,需要哪一块再去加载哪一块。
绝大多数情况下,“让Agent自己按需读信息”比你一股脑全喂给它要聪明得多!
3. 好好设计行动空间(Action Space)
行动空间就是Agent被允许做的一切:能调用的所有工具,以及它能用来结束任务的所有方式。
再次,站在Agent的鞋子里问自己:
“作为人类,我完成这个任务需要哪些工具?会采取哪些动作?”
- 我会用终端去grep、sed、找文件吗?
- 需要网页搜索用户没提供的资料吗?
- 要跑代码?要用计算器?
- 需要连Slack、Discord、Excel、新闻API(MCP服务器)吗?
- 选项太多我快疯了,要不要把部分工作委托给别的Agent?(后面会细说)
原则是:越少越好。
人选项太多会决策瘫痪,Agent也一样。把工具数量砍到最精简,名字起得清晰,描述写得准确,在系统提示里再给几个调用例子。
如果你的Agent老是搞不清该调哪个工具,或者动不动就“精神错乱”,那就是典型的“Agent痴呆症”——赶紧给它减负!
4. 学会委托工作(Delegating)
有时候你会觉得自己“摊得太薄”,同时干太多事,很快就会疲劳、开始疯狂幻觉。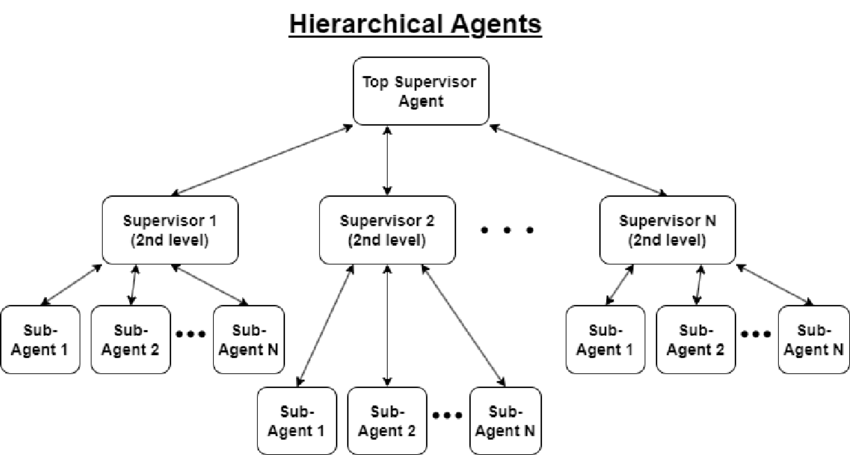
以前的说法是:“兄弟,你上下文烂了,赶紧休息一下,找人分担点活吧。”
我这里当然是在说上下文腐烂、LLM幻觉、多Agent架构。
多Agent(子Agent)架构特别适合下面几种场景:
(a) 主Agent要同时干很多毫不相关的事
比如:读论文、改代码、维护记忆、帮你点咖啡……
(b) 某个工具返回的结果巨长,主Agent得先浓缩才能继续
比如:search(“attention”) 直接吐出250段文字,1M token塞给你自己看去吧
© 任务超级长
比如:“造AGI”
(d) 任务可以并行
比如:“把Lex Fridman所有播客都总结一遍”
5. 持久化工作成果(Persisting Work)
这部分我的“站在Agent鞋子里”原则稍微有点不适用——因为LLM和人实在太不一样了。
LLM本质是一群“事务性”的人:你给一段文本,它吐一段新文本。上下文必须你自己管。
人会自动记住所有发生的事,上下文每秒都在悄无声息地更新。
所以上下文管理是最难的部分。
你可以这样问你的LLM:
- 你是聊天机器人吗?→ 那我就把历史对话塞回去。
- 你需要用户过去的聊天记录吗?→ 那我给你建个记忆系统,能读能写。
- 你不需要用户记忆,但需要某个实体(论文、代码库、股票)的持久信息?→ 那我给你读写实体专属日志的权限。
- 你是多Agent团队,需要互相通信?→ 给你们一个共享的scratchpad。
- 你要干很多任务,容易忘事?→ 哈哈我懂!我自己都用Todo List,给你也做一个。
我们其实没那么不一样!
额外最佳实践:
- 上下文压缩:记忆太长就主动总结压缩。
- KV Cache优化:把系统提示的静态部分永远放在最前面,别改动历史对话记录,工具调用和旧的推理步骤也要留着,让Agent知道自己之前干了什么,避免重复劳动。
这些东西古典AI时代就有了。
其实我没发明什么新东西
软件工程里,我们设计复杂系统时,会把每个模块/微服务看成一份“合同”:这个模块需要什么输入、能用什么工具、要输出什么结果。
AI领域也有PEAS框架(Performance Measure、Environment、Actuators、Sensors)。
强化学习里更直接:MDP、POMDP,把Agent和环境解耦,让Agent只看当前状态、执行动作、接收新状态和奖励。
设计RL环境的过程,恰恰就是逼着你去精心设计观察空间、行动空间、奖励空间,让一个“笨Agent”也能在任务上无敌。
这不就是我们整篇文章在干的事吗?——站在Agent的角度,然后反向推导:它需要看到什么、能做什么,才能达成目标。
这个简单的心智模型,我用了好几年,效果真的不错,希望你也试试。
最后一点碎碎念
LLM是用海量人类数据训练出来的,所以“让AI的行为带上人类偏好”几乎总是正确的。
这也是为什么大家说它是艺术——很多设计靠的是品味,而不是死板的规则。
但把它叫科学也没错。
科学的核心就是可实验。
你造一个系统 → 观察行为 → 改一个地方 → 测量变化。
作为人类,我们进步的最大方式就是不断评估自己。可惜,很多人做生产级Agent时,偏偏把这一条忘了。
你一定要:
- 完整记录Agent的每一步trace
- 搭建回放系统,能重放历史prompt,给回答打数值分数
- 疯狂实验超参数、算法改动,看哪个效果更好
- 自己去读日志,看到奇怪行为就问:“这傻机器人为什么这么干?”
然后闭上眼睛,站在Agent的角度:“如果我是它,我为什么会犯这个错?上下文里哪一部分把我带偏了?”
大多数时候,这样一问,你就能找到根源:提示词写得模糊?数据加载策略有问题?工具太多?多Agent架构没设计好?还是外部上下文没管好?
把这些改掉,你的系统就会越来越稳。
感谢阅读!希望这篇文章能让你少走一些弯路。
如果你正在做Agentic项目,欢迎在评论区分享你的经验,我们一起交流~
(完)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)