【AI测试全栈:质量】48、万字实战|全栈AI测试平台架构设计与开发(微服务+Vue3+Python+MVP落地)
随着AI大模型和机器学习系统在各行业的规模化落地,AI系统的测试与传统软件测试相比,出现了全链路覆盖难、技术栈复杂、测试指标多元化等新痛点:传统测试工具仅能覆盖服务接口和前端页面,无法对AI系统的核心——测试数据质量和模型效果做专业校验;分散的测试工具(如JMeter做接口测试、Excel做数据校验)导致团队协作效率低,测试结果无法统一管理;AI系统的迭代速度快,数据漂移、模型退化等问题需要自动化
🔥万字实战|全栈AI测试平台架构设计与开发(微服务+Vue3+Python+MVP落地)
前言
随着AI大模型和机器学习系统在各行业的规模化落地,AI系统的测试与传统软件测试相比,出现了全链路覆盖难、技术栈复杂、测试指标多元化等新痛点:传统测试工具仅能覆盖服务接口和前端页面,无法对AI系统的核心——测试数据质量和模型效果做专业校验;分散的测试工具(如JMeter做接口测试、Excel做数据校验)导致团队协作效率低,测试结果无法统一管理;AI系统的迭代速度快,数据漂移、模型退化等问题需要自动化监控,而非人工回归测试。
基于以上痛点,本文将从核心需求分析出发,手把手带你设计并开发一套全栈AI测试平台,采用微服务架构融合Java和Python技术栈,前端基于Vue3微前端实现模块化开发,集成主流AI测试和DevOps工具,最终落地支持100人团队协作的MVP版本。本文涵盖架构设计、核心模块开发、实战落地、踩坑优化全流程,所有核心概念和流程均通过Mermaid语法可视化,助力你快速理解并搭建属于自己的全栈AI测试平台。
本文关键词:全栈AI测试平台、微服务架构、Vue3微前端、Java+Python跨栈开发、AI测试全链路、RBAC权限、MVP落地
技术栈总览:Vue3+Element Plus+qiankun、Spring Cloud+Spring Boot、Python3、MySQL/Redis/MinIO/Elasticsearch、Great Expectations/MLflow/Evidently AI/JMeter
一、平台核心需求:瞄准AI测试痛点,支撑100人团队协作
AI系统的测试覆盖数据层、模型层、服务层、前端层全链路,且团队协作中存在用例管理混乱、自动化程度低、结果可视化差等问题,本平台的核心需求围绕解决AI测试全链路痛点和支撑中大型团队协作展开,最终目标是实现一站式、自动化、可协作、可扩展的全栈AI测试能力,支持100人规模的研发/测试团队协同工作。
1.1 一站式全链路测试能力
这是本平台与传统测试工具的核心区别,需覆盖AI系统从数据输入到前端展示的全生命周期测试,解决传统测试工具“碎片化”问题:
- 数据测试:支持结构化数据(CSV/Excel/Parquet)的质量校验(完整性、唯一性、合法性)、数据漂移检测(特征分布、统计指标变化),对接数仓/数据湖的测试数据来源;
- 模型测试:支持离线/在线模型的多维度评估(精度、召回、F1、AUC等)、鲁棒性测试(对抗样本、噪声数据)、公平性测试(特征偏见、群体差异)、模型漂移检测;
- 服务测试:支持AI接口的功能测试、性能测试(QPS/TPS/响应时间)、稳定性测试(压测、熔断降级)、兼容性测试,集成JMeter实现高并发压测;
- 前端测试:支持AI产品前端页面的UI自动化测试、交互测试,对接Selenium/Appium等工具,保障前端展示和交互的正确性。
1.2 自动化测试流水线
AI系统的迭代具有数据更新频繁、模型版本快速迭代的特点,人工回归测试效率低且易遗漏,平台需实现测试任务自动化调度与执行:
- 支持定时任务(如每日凌晨执行数据质量检测、每周执行模型全量评估);
- 支持触发式任务(如数据更新后自动执行数据漂移检测、模型部署后自动执行模型效果校验);
- 支持任务并行执行,提升测试效率,适配多模块同时测试的场景;
- 支持任务失败重试、断点续跑,保障测试流水线的稳定性。
1.3 高效团队协作能力
针对100人规模的团队,需解决权限隔离、资源共享、协作追溯等问题,实现“测试用例统一管理、测试任务分工执行、测试结果全员共享”:
- 支持团队/角色/用户的层级管理,细粒度控制测试资源(用例、报告、服务)的访问权限;
- 支持测试用例的多人协同编辑、版本控制,避免多人修改冲突;
- 支持测试任务的分配、认领、执行状态同步,团队成员可实时查看任务进度;
- 支持测试报告的共享、评论、归档,实现问题追溯和知识沉淀。
1.4 可视化测试报告能力
AI测试的指标多、数据量大,纯文本报告难以快速分析问题,平台需实现测试结果的多维度可视化,让测试指标“一目了然”:
- 支持核心测试指标的图表展示(如数据质量指标雷达图、模型评估指标柱状图、接口性能指标趋势图);
- 支持缺陷统计分析(如缺陷等级、缺陷模块、缺陷修复率的饼图/折线图);
- 支持测试用例覆盖率分析(如模块覆盖率、功能点覆盖率),指导测试用例补充;
- 支持测试日志的实时检索、可视化展示,快速定位测试失败原因;
- 支持生成标准化的测试报告(PDF/HTML格式),可导出、打印、归档。
1.5 高可扩展性能力
AI测试技术和工具迭代快,且不同业务场景的测试需求差异大,平台需采用松耦合的架构设计,支持功能模块扩展、第三方工具集成、部署环境适配:
- 微服务架构拆分,新增功能模块无需修改原有代码,降低开发和维护成本;
- 提供标准化的插件接口,支持快速集成新的AI测试工具(如新增模型可解释性测试工具、数据脱敏工具);
- 支持多环境部署(开发/测试/生产),适配不同阶段的测试需求;
- 支持水平扩展,通过增加节点提升平台的并发处理能力和数据存储能力,适配团队规模和业务量的增长。
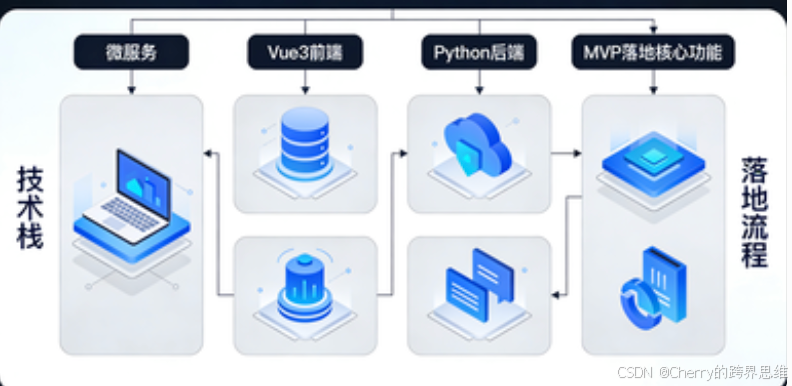
二、平台架构设计:微服务架构,融合Java+Python跨栈能力
为满足上述核心需求,平台采用分层式微服务架构设计,整体分为前端层、后端层、数据层、工具层四大层级,各层级松耦合、高内聚,同时融合**Java(适合高并发、微服务、权限管理)和Python(适合AI数据处理、模型测试、工具集成)**的技术优势,打造高性能、高适配性的全栈AI测试平台。
整体架构图如下,清晰展示各层级的技术选型、模块拆分和交互关系:
2.1 前端层:Vue3+Element Plus+qiankun微前端,模块化拆分
前端层作为平台的人机交互入口,要求操作便捷、界面友好、性能优异、模块可扩展,因此采用Vue3+Element Plus作为基础技术栈,结合qiankun微前端架构按功能模块拆分应用,解决单应用体积过大、模块耦合度高、团队并行开发效率低的问题。
2.1.1 核心技术选型
- 基础框架:Vue3(Composition API)+ Vite(极速构建、热更新),相比Vue2提升开发效率和页面性能;
- UI组件库:Element Plus,开箱即用的中后台组件库,适配测试平台的业务场景;
- 微前端框架:qiankun,基于single-spa封装,支持无侵入式接入多子应用,实现主应用与子应用、子应用之间的解耦;
- 可视化库:ECharts5,支持多种图表类型,满足测试结果的可视化需求;
- 状态管理:Pinia,Vue3官方推荐的状态管理工具,替代Vuex,更简洁的API和更好的TS支持;
- 请求库:Axios,支持拦截器、跨域、请求取消,适配微服务的接口请求。
2.1.2 微前端模块拆分
按平台的核心功能拆分为1个主应用+4个子应用,主应用负责全局布局、公共导航、用户登录、权限控制、子应用加载,子应用按测试领域拆分,各自独立开发、独立部署、独立更新,支持团队按模块分工开发(如前端团队分为数据测试、模型测试等小组,并行开发)。
微前端模块架构图如下:
2.1.3 前端层核心设计原则
- 无侵入式:子应用无需大幅修改代码,只需做少量适配即可接入qiankun微前端,支持原有项目的独立运行;
- 公共资源复用:将公共组件、工具库抽离到主应用,子应用直接调用,减少代码冗余,保证界面和功能的一致性;
- 独立部署:每个子应用拥有独立的构建、部署流程,更新子应用无需重启主应用,降低发布风险;
- 权限统一控制:主应用统一处理用户登录和权限校验,子应用通过主应用的全局状态获取用户权限,实现全平台的权限统一;
- 性能优化:采用懒加载方式加载子应用,只有当用户访问对应模块时才加载子应用资源,提升首屏加载速度。
2.2 后端层:Java+Python跨栈微服务,各司其职
后端层是平台的核心业务处理层,需同时满足微服务高并发、高可用和AI测试数据处理、模型评估的需求,因此采用Java微服务+Python服务的跨栈架构,让两种语言发挥各自的技术优势:
- Java微服务:基于Spring Cloud Alibaba技术栈,适合开发高并发、高可用的业务服务,负责用户管理、用例管理、报告生成、权限控制、任务调度、API网关等核心业务,保障平台的稳定性和可扩展性;
- Python服务:基于FastAPI/Flask技术栈,适合AI相关的数据处理、模型测试、第三方工具集成,快速对接Great Expectations、MLflow、Evidently AI等AI测试工具,降低AI测试模块的开发成本。
后端层各服务之间通过Feign/Grpc实现微服务通信,通过Nacos实现服务注册与发现,通过Sentinel实现限流熔断,保障服务之间的通信稳定性。
2.2.1 Java微服务:Spring Cloud Alibaba技术栈,打造高可用业务核心
Java微服务基于Spring Cloud Alibaba生态开发,核心技术选型如下:
- 服务框架:Spring Boot 2.7.x(快速开发)+ Spring Cloud 2021.0.5(微服务核心);
- 服务注册与发现:Nacos,替代Eureka,支持服务注册、发现、配置中心一体化;
- API网关:Spring Cloud Gateway,非阻塞式网关,支持路由转发、限流熔断、身份认证、跨域处理;
- 远程调用:OpenFeign,声明式RESTful API调用,简化微服务之间的通信;
- 任务调度:Quartz + Spring Cloud Task,支持定时任务、触发式任务、分布式任务调度;
- 权限控制:Spring Security + JWT,基于RBAC模型实现细粒度的权限控制;
- 数据校验:Hibernate Validator,实现接口请求参数的自动化校验;
- 分布式事务:Seata,解决跨服务的数据一致性问题;
- 构建工具:Maven,统一管理依赖,实现项目的快速构建。
Java微服务按业务领域拆分为5个核心服务,各服务的职责和核心功能如下:
2.2.2 Python服务:FastAPI技术栈,专注AI测试与工具集成
Python服务基于FastAPI开发(相比Flask,FastAPI支持异步、自动生成API文档、更好的TS/类型支持),核心技术选型如下:
- Web框架:FastAPI 0.100.x,支持异步请求、自动参数校验、OpenAPI文档生成;
- 异步处理:Asyncio,提升大数据量数据处理和工具调用的效率;
- 数据处理:Pandas/Numpy,处理结构化测试数据;
- 模型处理:PyTorch/TensorFlow/Sklearn,对接主流机器学习框架的模型;
- 工具集成:Python SDK调用Great Expectations、MLflow、Evidently AI等工具;
- 构建工具:Pipenv/Poetry,管理Python依赖,解决依赖冲突问题。
Python服务按AI测试领域拆分为4个核心服务,各服务的职责和核心功能如下:
2.2.3 后端层服务通信设计
后端层包含Java微服务和Python服务,服务之间的通信分为Java内部微服务通信和Java与Python服务通信两种场景,采用不同的通信方式适配:
- Java内部微服务通信:采用OpenFeign(基于HTTP/RESTful)实现同步通信,简单易用,适配大部分业务场景;对于高并发、大数据量的场景,采用Grpc(基于HTTP/2)实现,提升通信效率;
- Java与Python服务通信:Python服务通过Nacos完成服务注册,Java微服务通过OpenFeign调用Python服务的RESTful API,同时Python服务也可通过Feign客户端调用Java微服务的接口,实现跨栈通信;
- 服务通信保障:所有服务调用均添加超时重试、熔断降级机制(Sentinel),避免单个服务故障导致整个平台不可用;同时记录服务调用日志,便于问题定位。
服务通信架构图如下:
2.3 数据层:多存储引擎协同,适配不同数据类型
全栈AI测试平台的存储需求复杂,包含结构化业务数据、缓存数据、大文件、日志/检索数据等多种类型,单一存储引擎无法满足所有需求,因此采用多存储引擎协同的设计,各存储引擎各司其职,适配不同的数据类型和业务场景,同时保证数据的高可用、高可扩展、高性能。
数据层核心存储引擎及用途如下,存储架构图附后:
2.3.1 核心存储引擎选型与设计
-
MySQL
- 用途:存储核心结构化业务数据,如用户、用例、任务、权限等;
- 设计:采用主从复制架构,保障数据高可用;对大表进行分表分库(如测试任务日志表按时间分表),提升查询性能;添加索引优化,针对常用查询字段(如用例ID、任务ID、用户ID)建立索引;
- 版本:MySQL 8.0,支持窗口函数、JSON类型,适配复杂业务数据存储。
-
Redis
- 用途:缓存热点数据、存储用户会话、实现分布式锁、缓存任务进度等;
- 设计:采用主从+哨兵架构,保障缓存高可用;采用String/Hash/List/ZSet等多种数据结构,适配不同的缓存场景;设置合理的过期时间,避免缓存雪崩和缓存击穿;实现缓存更新策略(写穿/写回),保证缓存与数据库的数据一致性;
- 版本:Redis 6.0,支持多线程,提升性能。
-
MinIO
- 用途:对象存储,存储测试数据、模型文件、报告文件等大文件;
- 设计:采用分布式集群架构,支持水平扩展,提升存储容量和读写性能;对文件进行分类存储(按模块划分桶,如data-test、model-test、report),便于管理;支持文件分片上传/下载,适配大文件(如GB级模型文件)的传输;支持文件权限控制,结合平台的RBAC模型,控制文件的访问权限;
- 优势:轻量级、高性能、兼容S3协议,便于与其他云原生工具集成。
-
Elasticsearch
- 用途:存储平台所有日志数据,实现测试结果、日志的全文检索和可视化;
- 设计:采用分片+副本架构,合理设置分片数(按数据量设置主分片数,副本数为1,保障高可用);对日志数据按时间索引(如log-2026-02),便于日志的归档和清理;使用Kibana作为可视化工具,实现日志的实时检索、图表展示;
- 集成:通过Logstash/Filebeat收集平台的日志数据,实时同步到Elasticsearch,实现日志的一站式管理。
2.3.2 数据层核心设计原则
- 数据分离:不同类型的数据存储在不同的引擎中,发挥各引擎的技术优势,提升存储和查询性能;
- 数据一致性:通过缓存更新策略、分布式事务(Seata)、数据同步工具保障各存储引擎之间的数据一致性;
- 高可用:所有存储引擎均采用集群架构,避免单点故障,保障数据的安全性;
- 可扩展:所有存储引擎均支持水平扩展,通过增加节点提升存储容量和处理能力,适配业务量的增长;
- 数据安全:对敏感数据(如用户密码)进行加密存储(MD5/SHA256+盐值);对MinIO中的文件进行访问权限控制;对数据库进行定期备份,防止数据丢失。
2.4 工具层:集成主流AI测试/DevOps工具,提升平台能力
全栈AI测试平台的核心能力之一是集成主流的AI测试和DevOps工具,避免重复造轮子,提升开发效率和平台的专业性。工具层作为平台的“能力扩展层”,通过Python SDK/CLI命令调用第三方工具,将工具的能力封装为平台的接口,提供给前端和后端业务层调用,实现“工具能力平台化”。
2.4.1 核心集成工具及用途
平台集成的工具覆盖数据测试、模型测试、性能测试、容器调度等多个领域,各工具的核心用途如下:
- Great Expectations:目前最主流的开源数据质量测试工具,平台通过Python SDK调用其能力,实现结构化数据的质量校验(如非空、唯一性、范围、正则匹配等),支持自定义数据校验规则;
- MLflow:开源的机器学习生命周期管理工具,平台集成其模型注册、版本管理、模型部署能力,实现模型文件的统一管理和版本控制;
- Evidently AI:专注于AI系统测试的开源工具,平台通过其SDK实现数据漂移、模型漂移检测,以及模型的鲁棒性、公平性测试,提供专业的AI测试指标;
- JMeter:经典的性能测试工具,平台通过CLI命令调用其能力,实现API接口的性能压测、稳定性测试,支持生成JMeter脚本、执行压测、解析压测结果;
- Kubernetes Client:K8sPython客户端,平台集成其能力,实现测试任务的容器化调度,支持动态创建Pod执行测试任务,提升平台的并发处理能力;
- 其他工具:可根据业务需求扩展,如Selenium(前端UI自动化测试)、Appium(移动端测试)、Alibaba EasyExcel(Excel文件解析)等。
2.4.2 工具集成设计原则
- 标准化封装:对所有第三方工具的调用均进行标准化封装,提供统一的接口给业务层,业务层无需关注工具的底层调用细节,降低耦合度;
- 可配置化:工具的核心参数(如Great Expectations的校验规则、JMeter的压测并发数)支持在平台前端进行配置,实现“零代码”调用工具;
- 可扩展:提供标准化的工具集成插件接口,新增工具时只需开发插件即可接入平台,无需修改原有代码;
- 结果统一解析:将第三方工具的执行结果解析为平台统一的数格式,便于后续的结果聚合、可视化和报告生成。
三、核心模块开发:前端+后端,从功能设计到代码实现
核心模块开发是平台落地的关键,本节将详细讲解前端核心模块和后端核心模块的设计思路、实现要点和关键代码,覆盖平台的核心业务能力:前端的用例编辑、测试任务调度、结果可视化,后端的RESTful API设计、任务调度、RBAC权限控制。所有核心模块均遵循“高内聚、松耦合”的设计原则,支持后续扩展。
3.1 前端核心模块开发:可视化、高交互、易操作
前端模块围绕用户操作体验设计,核心目标是让测试人员无需编写代码,通过可视化操作完成测试用例设计、任务调度和结果分析,大幅提升测试效率。前端基于Vue3+Element Plus+qiankun开发,采用组件化、模块化的开发模式,公共组件抽离到公共库,提升代码复用率。
3.1.1 用例编辑模块:可视化拖拽,零代码设计测试用例
用例编辑是平台的核心前端模块,支持数据测试、模型测试、服务测试用例的可视化设计,无需编写代码,通过拖拽组件、配置参数即可完成用例设计,同时支持用例的导入/导出(JSON/Excel),实现用例的跨平台迁移和备份。
3.1.1.1 核心功能设计
- 可视化拖拽设计:提供丰富的测试组件(如数据质量校验组件、模型评估组件、接口请求组件),用户可通过拖拽将组件添加到用例编辑画布,按测试流程排列组件;
- 组件参数配置:每个测试组件提供可视化的参数配置面板,用户可通过表单配置组件的核心参数(如数据校验的规则、模型评估的指标、接口请求的URL/方法/参数);
- 用例流程控制:支持用例的串行/并行执行配置,支持条件判断、循环执行等流程控制,适配复杂的测试场景;
- 用例校验:实时校验用例的配置合法性(如参数缺失、组件连接错误),给出错误提示,避免无效用例;
- 用例导入/导出:支持将用例导出为JSON/Excel格式,也支持从JSON/Excel文件导入用例,实现用例的共享和备份;
- 用例版本控制:保存用例的修改记录,支持版本回滚,避免误操作导致的用例丢失。
3.1.1.2 实现要点
- 拖拽组件实现:基于Vue Draggable Next(Vue3拖拽组件库)实现组件的拖拽功能,通过维护画布组件数组记录拖拽后的组件顺序和配置;
- 组件抽象:将所有测试组件抽象为基础组件类,包含通用属性(如组件ID、名称、类型、参数、执行顺序)和通用方法(如参数校验、执行、结果返回),具体测试组件继承基础组件类,实现个性化逻辑;
- 画布渲染:根据画布组件数组动态渲染测试组件,每个组件绑定对应的参数配置面板,参数修改后实时更新数组中的组件配置;
- 用例数据结构设计:设计标准化的用例JSON数据结构,包含用例基本信息、组件列表、流程控制信息、执行配置等,便于用例的存储、导入/导出和后端解析。
3.1.1.3 可视化用例编辑流程(Mermaid)
3.1.1.4 关键代码实现
- 拖拽画布组件(Vue3+Vue Draggable Next)
<template>
<div class="case-editor-canvas">
<!-- 拖拽组件容器 -->
<draggable
v-model="componentList"
class="component-list"
ghost-class="ghost"
animation="300"
>
<!-- 动态渲染测试组件 -->
<div
v-for="(item, index) in componentList"
:key="item.id"
class="test-component"
@click="openConfigPanel(item, index)"
>
<el-icon><Component /></el-icon>
<span>{{ item.name }}</span>
<el-icon class="delete-icon" @click.stop="deleteComponent(index)"><Delete /></el-icon>
</div>
</draggable>
<!-- 参数配置面板 -->
<config-panel
v-if="showConfigPanel"
:component="currentComponent"
@save-config="saveComponentConfig"
@close-panel="showConfigPanel = false"
/>
</div>
</template>
<script setup lang="ts">
import { ref, reactive } from 'vue'
import { Draggable } from 'vue-draggable-next'
import { Component, Delete } from '@element-plus/icons-vue'
import ConfigPanel from './ConfigPanel.vue'
// 测试组件列表(拖拽后的数据)
const componentList = ref([
{ id: '1', type: 'data-check', name: '数据非空校验', config: { field: '', expect: true } },
{ id: '2', type: 'model-eval', name: '模型精度评估', config: { metric: 'accuracy', threshold: 0.9 } }
])
// 配置面板显隐
const showConfigPanel = ref(false)
// 当前编辑的组件
const currentComponent = ref({})
// 当前编辑的组件索引
const currentIndex = ref(0)
// 打开参数配置面板
const openConfigPanel = (item: any, index: number) => {
currentComponent.value = JSON.parse(JSON.stringify(item))
currentIndex.value = index
showConfigPanel.value = true
}
// 保存组件配置
const saveComponentConfig = (config: any) => {
componentList.value[currentIndex.value].config = config
showConfigPanel.value = false
// 实时校验用例配置
validateCaseConfig()
}
// 删除组件
const deleteComponent = (index: number) => {
componentList.value.splice(index, 1)
}
// 用例配置合法性校验
const validateCaseConfig = () => {
// 遍历组件,校验参数是否完整
const invalidComponents = componentList.value.filter(item => {
if (!item.config || Object.keys(item.config).length === 0) return true
// 不同组件的个性化校验
if (item.type === 'data-check' && !item.config.field) return true
if (item.type === 'model-eval' && !item.config.threshold) return true
return false
})
if (invalidComponents.length > 0) {
ElMessage.error(`组件【${invalidComponents.map(item => item.name).join(',')}】参数配置不完整`)
return false
}
ElMessage.success('用例配置合法')
return true
}
</script>
<style scoped>
.case-editor-canvas {
width: 100%;
min-height: 600px;
background: #f5f7fa;
padding: 20px;
border-radius: 8px;
}
.component-list {
display: flex;
flex-direction: column;
gap: 10px;
}
.test-component {
display: flex;
align-items: center;
gap: 10px;
padding: 15px;
background: #fff;
border: 1px solid #e6e8eb;
border-radius: 6px;
cursor: move;
}
.ghost {
opacity: 0.5;
background: #e6f7ff;
}
.delete-icon {
margin-left: auto;
color: #ff4d4f;
cursor: pointer;
}
</style>
- 用例导出功能(JSON/Excel)
import { ElMessage } from 'element-plus'
import * as XLSX from 'xlsx'
// 导出用例为JSON
export const exportCaseToJson = (caseInfo: any) => {
const blob = new Blob([JSON.stringify(caseInfo, null, 2)], {
type: 'application/json;charset=utf-8'
})
const url = URL.createObjectURL(blob)
const a = document.createElement('a')
a.href = url
a.download = `${caseInfo.name}.json`
a.click()
URL.revokeObjectURL(url)
ElMessage.success('JSON用例导出成功')
}
// 导出用例为Excel
export const exportCaseToExcel = (caseInfo: any) => {
// 构造Excel数据
const data = [
['用例名称', caseInfo.name],
['用例类型', caseInfo.type],
['创建人', caseInfo.creator],
['创建时间', caseInfo.createTime],
['组件列表', ''],
['组件ID', '组件名称', '组件类型', '配置参数']
]
// 追加组件数据
caseInfo.componentList.forEach((item: any) => {
data.push([
item.id,
item.name,
item.type,
JSON.stringify(item.config)
])
})
// 生成Excel工作簿
const wb = XLSX.utils.book_new()
const ws = XLSX.utils.aoa_to_sheet(data)
XLSX.utils.book_append_sheet(wb, ws, '用例信息')
// 导出Excel
XLSX.writeFile(wb, `${caseInfo.name}.xlsx`)
ElMessage.success('Excel用例导出成功')
}
3.1.2 测试任务调度模块:灵活配置,实时监控任务进度
测试任务调度模块负责测试任务的创建、配置、执行和进度监控,支持定时任务、触发式任务的配置,展示任务的执行状态(待执行/执行中/执行成功/执行失败)、执行进度、执行日志,让用户实时掌握任务执行情况。
3.1.2.1 核心功能设计
- 任务创建:关联已设计的测试用例,选择任务执行类型(手动/定时/触发式),配置任务执行参数(如执行器、并行数、失败重试次数);
- 定时任务配置:基于Cron表达式配置定时执行规则(如每日凌晨2点、每周日晚8点),支持Cron表达式可视化生成,无需手动编写;
- 触发式任务配置:配置任务触发条件(如数据更新、模型更新、接口部署),当条件满足时自动触发任务执行;
- 任务执行:支持手动触发任务执行,支持任务的暂停、终止、重试,支持任务并行执行;
- 进度监控:实时展示任务的执行进度(百分比)、执行状态、执行耗时,展示每个测试用例的执行结果;
- 任务日志:实时展示任务的执行日志,支持日志检索、日志下载,快速定位任务执行失败原因;
- 任务管理:支持任务的查询、筛选、删除、批量操作,支持任务执行结果的快速查看。
3.1.2.2 实现要点
- Cron表达式可视化:集成vue-cron组件,实现Cron表达式的可视化生成,用户通过选择时间单位(秒/分/时/日/月/周)即可生成Cron表达式,降低使用成本;
- 任务进度实时更新:采用WebSocket实现前端与后端的实时通信,后端将任务执行进度和日志实时推送给前端,前端实时更新页面,无需刷新;
- 任务状态设计:定义标准化的任务状态枚举(待执行/执行中/暂停/执行成功/执行失败/已终止),后端实时更新任务状态,前端根据状态展示不同的样式和操作按钮;
- 任务数据结构设计:包含任务基本信息、关联用例信息、执行配置、触发条件、执行状态、进度、日志等,便于后端任务调度服务解析和执行。
3.1.2.3 测试任务调度执行流程(Mermaid)
3.1.2.4 关键代码实现
- Cron表达式可视化配置(vue-cron)
<template>
<div class="cron-config">
<el-form label-width="120px" :model="taskForm">
<el-form-item label="执行类型">
<el-select v-model="taskForm.execType" placeholder="请选择执行类型">
<el-option label="手动执行" value="manual" />
<el-option label="定时执行" value="cron" />
<el-option label="触发式执行" value="trigger" />
</el-select>
</el-form-item>
<!-- Cron表达式可视化配置 -->
<el-form-item
label="Cron表达式"
v-if="taskForm.execType === 'cron'"
>
<vue-cron
v-model="taskForm.cronExpr"
@change="onCronChange"
style="width: 100%;"
/>
<div class="cron-tip">生成的Cron表达式:{{ taskForm.cronExpr }}</div>
</el-form-item>
<!-- 触发条件配置 -->
<el-form-item
label="触发条件"
v-if="taskForm.execType === 'trigger'"
>
<el-select v-model="taskForm.triggerType" placeholder="请选择触发条件">
<el-option label="数据更新" value="data_update" />
<el-option label="模型更新" value="model_update" />
<el-option label="接口部署" value="api_deploy" />
</el-select>
</el-form-item>
<el-form-item label="失败重试次数">
<el-input-number v-model="taskForm.retryCount" :min="0" :max="10" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="saveTask">保存任务</el-button>
<el-button type="success" @click="runTask" v-if="taskForm.execType === 'manual'">立即执行</el-button>
</el-form-item>
</el-form>
</div>
</template>
<script setup lang="ts">
import { ref, reactive } from 'vue'
import VueCron from 'vue-cron'
import 'vue-cron/dist/vue-cron.css'
import { ElMessage } from 'element-plus'
import { saveTaskApi, runTaskApi } from '@/api/task'
// 任务表单
const taskForm = reactive({
execType: 'manual', // 执行类型:manual/cron/trigger
cronExpr: '', // Cron表达式
triggerType: '', // 触发类型
retryCount: 0, // 失败重试次数
caseIds: [], // 关联的用例ID
executor: 'default' // 执行器
})
// Cron表达式变化
const onCronChange = (val: string) => {
taskForm.cronExpr = val
}
// 保存任务
const saveTask = async () => {
if (taskForm.caseIds.length === 0) {
ElMessage.error('请选择关联的测试用例')
return
}
if (taskForm.execType === 'cron' && !taskForm.cronExpr) {
ElMessage.error('请配置Cron表达式')
return
}
if (taskForm.execType === 'trigger' && !taskForm.triggerType) {
ElMessage.error('请配置触发条件')
return
}
const res = await saveTaskApi(taskForm)
if (res.code === 200) {
ElMessage.success('任务保存成功')
// 重置表单
Object.assign(taskForm, {
execType: 'manual',
cronExpr: '',
triggerType: '',
retryCount: 0,
caseIds: []
})
} else {
ElMessage.error(`任务保存失败:${res.msg}`)
}
}
// 立即执行任务
const runTask = async () => {
if (taskForm.caseIds.length === 0) {
ElMessage.error('请选择关联的测试用例')
return
}
const res = await runTaskApi({
caseIds: taskForm.caseIds,
retryCount: taskForm.retryCount,
executor: taskForm.executor
})
if (res.code === 200) {
ElMessage.success('任务启动成功')
} else {
ElMessage.error(`任务启动失败:${res.msg}`)
}
}
</script>
<style scoped>
.cron-config {
padding: 20px;
background: #fff;
border-radius: 8px;
}
.cron-tip {
margin-top: 10px;
font-size: 14px;
color: #666;
}
</style>
- WebSocket实时监控任务进度
// 建立WebSocket连接,监控任务进度
export const createTaskWebSocket = (taskId: string, callback: (data: any) => void) => {
// 替换为实际的WebSocket服务地址
const wsUrl = import.meta.env.VITE_WS_BASE_URL + `/task/monitor/${taskId}`
const ws = new WebSocket(wsUrl)
// 连接成功
ws.onopen = () => {
console.log(`WebSocket连接成功,监控任务:${taskId}`)
}
// 接收消息
ws.onmessage = (event) => {
const data = JSON.parse(event.data)
// 回调函数,更新前端页面
callback(data)
}
// 连接关闭
ws.onclose = () => {
console.log(`WebSocket连接关闭,任务:${taskId}`)
// 重连机制
setTimeout(() => {
createTaskWebSocket(taskId, callback)
}, 3000)
}
// 连接错误
ws.onerror = (error) => {
console.error(`WebSocket连接错误:`, error)
}
return ws
}
// 在组件中使用
import { onMounted, ref } from 'vue'
import { createTaskWebSocket } from '@/utils/websocket'
const taskId = ref('123456')
const taskProgress = ref(0)
const taskStatus = ref('running')
const taskLog = ref('')
onMounted(() => {
createTaskWebSocket(taskId.value, (data) => {
taskProgress.value = data.progress
taskStatus.value = data.status
taskLog.value += data.log + '\n'
// 滚动到日志底部
const logDom = document.getElementById('task-log')
if (logDom) {
logDom.scrollTop = logDom.scrollHeight
}
})
})
3.1.3 结果可视化模块:多维度图表,直观展示测试结果
结果可视化模块是平台的“数据展示中心”,负责将测试结果数据聚合、分析并以图表形式展示,支持核心指标雷达图、趋势图、缺陷统计饼图、用例覆盖率柱状图等,让用户快速分析测试结果,定位问题。
3.1.3.1 核心功能设计
- 多维度图表展示:支持ECharts5的多种图表类型,适配不同的测试指标展示场景:
- 雷达图:展示数据质量、模型评估的多维度指标(如数据的完整性、唯一性、及时性,模型的精度、召回、F1、AUC);
- 折线图/面积图:展示测试指标的趋势变化(如每日数据漂移程度、每周模型效果变化、接口性能指标趋势);
- 饼图/环形图:展示缺陷统计(如缺陷等级分布、缺陷模块分布、缺陷修复率);
- 柱状图/条形图:展示测试用例覆盖率(如模块覆盖率、功能点覆盖率)、各测试任务的执行耗时;
- 表格:展示详细的测试结果数据,支持排序、筛选、导出;
- 指标钻取:支持图表的钻取功能,点击图表的某个维度,可查看该维度的详细测试结果和日志,实现“从宏观到微观”的分析;
- 自定义报表:支持用户自定义可视化报表,选择需要展示的指标、图表类型,保存为个性化报表;
- 报告生成:支持将可视化图表和详细数据生成标准化的PDF/HTML测试报告,可导出、共享、归档;
- 数据对比:支持不同测试任务、不同时间的测试结果数据对比,展示指标变化,分析数据/模型/接口的变化趋势。
3.1.3.2 实现要点
- 图表组件抽象:将ECharts图表抽象为通用Vue组件,通过传入图表配置、数据即可生成对应的图表,支持图表的自适应、重绘、销毁,避免内存泄漏;
- 数据聚合:前端通过调用后端的报告生成服务,获取聚合后的测试结果数据,无需前端做大量数据处理,提升前端性能;
- 图表交互:为图表添加点击、悬浮、缩放等交互事件,实现指标钻取、数据详情展示;
- 自适应布局:图表组件支持自适应屏幕尺寸,在电脑、平板等设备上均能正常展示;
- 数据缓存:对高频访问的测试结果数据进行前端缓存(Pinia),避免重复请求后端接口,提升页面加载速度。
3.1.3.3 测试结果可视化流程(Mermaid)
3.1.3.4 关键代码实现
- 通用ECharts图表组件
<template>
<div class="echarts-container" :style="{ width, height }" ref="chartRef"></div>
</template>
<script setup lang="ts">
import { ref, watch, onMounted, onUnmounted } from 'vue'
import * as echarts from 'echarts'
import type { EChartsOption } from 'echarts'
// 组件props
const props = defineProps({
// 图表配置
option: {
type: Object as () => EChartsOption,
required: true
},
// 图表宽度
width: {
type: String,
default: '100%'
},
// 图表高度
height: {
type: String,
default: '400px'
},
// 是否自适应
autoResize: {
type: Boolean,
default: true
}
})
// 图表实例
const chartRef = ref<HTMLDivElement | null>(null)
let myChart: echarts.ECharts | null = null
// 初始化图表
const initChart = () => {
if (!chartRef.value) return
myChart = echarts.init(chartRef.value)
myChart.setOption(props.option, true)
// 点击事件:指标钻取
myChart.on('click', (params) => {
emit('chart-click', params)
})
}
// 更新图表
const updateChart = () => {
if (myChart) {
myChart.setOption(props.option, true)
}
}
// 自适应重绘
const resizeChart = () => {
if (myChart) {
myChart.resize()
}
}
// 监听配置变化,更新图表
watch(
() => props.option,
() => {
updateChart()
},
{ deep: true }
)
// 生命周期
onMounted(() => {
initChart()
if (props.autoResize) {
window.addEventListener('resize', resizeChart)
}
})
onUnmounted(() => {
if (myChart) {
myChart.dispose()
myChart = null
}
if (props.autoResize) {
window.removeEventListener('resize', resizeChart)
}
})
// 组件emit
const emit = defineEmits(['chart-click'])
</script>
<style scoped>
.echarts-container {
border-radius: 8px;
background: #fff;
padding: 10px;
}
</style>
- 数据质量指标雷达图使用示例
<template>
<div class="data-quality-chart">
<common-echarts
:option="radarOption"
height="500px"
@chart-click="onChartClick"
/>
</div>
</template>
<script setup lang="ts">
import { ref, reactive, onMounted } from 'vue'
import CommonEcharts from '@/components/CommonEcharts.vue'
import { getDataQualityApi } from '@/api/report'
// 雷达图配置
const radarOption = reactive({
title: {
text: '数据质量指标雷达图',
left: 'center'
},
tooltip: {
trigger: 'item'
},
legend: {
orient: 'vertical',
left: 10,
top: 20
},
radar: {
indicator: [
{ name: '完整性', max: 100 },
{ name: '唯一性', max: 100 },
{ name: '合法性', max: 100 },
{ name: '及时性', max: 100 },
{ name: '一致性', max: 100 }
]
},
series: [
{
name: '数据质量指标',
type: 'radar',
data: [
{
value: [0, 0, 0, 0, 0],
name: '本次测试'
}
]
}
]
})
// 获取数据质量指标
const getDataQuality = async () => {
const res = await getDataQualityApi({ taskId: '123456' })
if (res.code === 200) {
const data = res.data
// 更新雷达图数据
radarOption.series[0].data[0].value = [
data.completeness,
data.uniqueness,
data.validity,
data.timeliness,
data.consistency
]
}
}
// 图表点击事件(指标钻取)
const onChartClick = (params: any) => {
console.log('点击的指标:', params)
// 跳转到该指标的详细结果页面
router.push({
path: '/report/detail',
query: {
taskId: '123456',
indicator: params.name
}
})
}
onMounted(() => {
getDataQuality()
})
</script>
<style scoped>
.data-quality-chart {
padding: 20px;
width: 100%;
}
</style>
3.2 后端核心模块开发:高可用、高安全、可扩展
后端核心模块是平台的业务处理核心,负责接口提供、任务调度、权限控制、数据处理、工具调用等核心能力,后端分为Java微服务和Python服务,分别采用Spring Cloud Alibaba和FastAPI开发,遵循RESTful API设计规范,实现权限控制、请求校验、异常处理等基础能力。
3.2.1 接口服务:RESTful API设计,标准化、高安全
后端所有服务均提供RESTful API接口,供前端和其他服务调用,接口设计遵循RESTful设计规范,同时实现跨域、权限控制、请求校验、异常处理、接口文档自动化生成等能力,保障接口的标准化、高安全、高可用。
3.2.1.1 RESTful API设计规范
- HTTP方法语义:严格遵循HTTP方法的语义,不同操作使用对应的HTTP方法:
- GET:查询资源(如查询测试用例、查询任务进度);
- POST:创建资源(如创建用户、创建测试用例、创建任务);
- PUT:更新资源(全量更新,如更新测试用例的所有配置);
- PATCH:更新资源(部分更新,如更新任务的执行状态);
- DELETE:删除资源(如删除测试用例、删除任务);
- URL设计:
- 采用名词复数形式表示资源(如
/api/v1/cases表示测试用例资源,/api/v1/tasks表示任务资源); - 采用层级URL表示资源之间的关系(如
/api/v1/tasks/123/cases表示任务123关联的测试用例); - URL中使用小写字母,单词之间用短横线
-分隔,避免使用下划线和大写字母; - 版本号放入URL(如
/api/v1/),便于接口的迭代和兼容;
- 采用名词复数形式表示资源(如
- 请求参数:
- 查询参数:用于GET请求的筛选、分页、排序(如
/api/v1/cases?page=1&size=10&type=data-test); - 路径参数:用于标识唯一资源(如
/api/v1/cases/123表示ID为123的测试用例); - 请求体:用于POST/PUT/PATCH请求的资源创建和更新,采用JSON格式;
- 查询参数:用于GET请求的筛选、分页、排序(如
- 响应数据:
- 所有接口返回统一的JSON数据格式,包含状态码、消息、数据、时间戳;
- 状态码:采用HTTP状态码(200成功、400参数错误、401未授权、403禁止访问、404资源不存在、500服务器内部错误);
- 自定义业务码:在响应体中添加
code字段,标识具体的业务状态(如200成功、4001用例不存在、4002任务执行失败);
- 分页设计:所有查询接口均支持分页,返回当前页码、每页条数、总条数、总页数、数据列表;
- 排序设计:支持按指定字段排序,通过
sort参数指定(如/api/v1/cases?sort=createTime,desc表示按创建时间倒序)。
3.2.1.2 统一响应数据格式设计
{
"code": 200, // 业务状态码
"msg": "操作成功", // 提示消息
"data": {}, // 业务数据,可为对象/数组/空
"timestamp": 1738329600000 // 时间戳(毫秒)
}
分页查询的响应数据格式:
{
"code": 200,
"msg": "查询成功",
"data": {
"page": 1, // 当前页码
"size": 10, // 每页条数
"total": 100, // 总条数
"pages": 10, // 总页数
"records": [] // 数据列表
},
"timestamp": 1738329600000
}
3.2.1.3 核心实现要点
- 跨域处理:在Spring Cloud Gateway和FastAPI中分别配置跨域,允许前端的跨域请求,支持自定义允许的域名、请求方法、请求头;
- 请求校验:Java微服务使用Hibernate Validator实现请求参数校验,通过注解(如
@NotBlank、@NotNull、@Min)标注参数约束,全局异常处理器捕获校验异常并返回统一响应;Python服务使用FastAPI的Pydantic实现参数校验,自动生成参数校验规则; - 异常处理:实现全局异常处理器,捕获所有未处理的异常,统一封装为标准的响应数据格式,避免直接返回异常堆栈信息,提升接口的安全性;
- 接口文档:Java微服务集成Knife4j(基于Swagger),实现RESTful API文档的自动化生成和在线调试;Python服务利用FastAPI的自动API文档功能(Swagger UI/ReDoc),无需额外开发即可生成接口文档;
- 跨域配置:在Spring Cloud Gateway中配置跨域,统一处理所有服务的跨域请求,避免每个服务单独配置。
3.2.1.4 关键代码实现
- Java微服务-统一响应结果封装
package com.ai.test.common.result;
import lombok.Data;
import java.io.Serializable;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
/**
* 统一响应结果
*/
@Data
public class Result<T> implements Serializable {
/**
* 业务状态码
*/
private Integer code;
/**
* 提示消息
*/
private String msg;
/**
* 业务数据
*/
private T data;
/**
* 时间戳(毫秒)
*/
private Long timestamp;
public Result() {
this.timestamp = LocalDateTime.now().toInstant(ZoneOffset.of("+8")).toEpochMilli();
}
/**
* 成功返回(无数据)
*/
public static <T> Result<T> success() {
Result<T> result = new Result<>();
result.setCode(200);
result.setMsg("操作成功");
return result;
}
/**
* 成功返回(有数据)
*/
public static <T> Result<T> success(T data) {
Result<T> result = new Result<>();
result.setCode(200);
result.setMsg("操作成功");
result.setData(data);
return result;
}
/**
* 失败返回
*/
public static <T> Result<T> fail(Integer code, String msg) {
Result<T> result = new Result<>();
result.setCode(code);
result.setMsg(msg);
return result;
}
/**
* 失败返回(默认消息)
*/
public static <T> Result<T> fail(String msg) {
return fail(500, msg);
}
}
- Java微服务-全局异常处理器
package com.ai.test.common.exception;
import com.ai.test.common.result.Result;
import lombok.extern.slf4j.Slf4j;
import org.springframework.validation.BindException;
import org.springframework.validation.FieldError;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import javax.validation.ConstraintViolation;
import javax.validation.ConstraintViolationException;
import java.util.stream.Collectors;
/**
* 全局异常处理器
*/
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
/**
* 处理参数校验异常(@Valid/@Validated)
*/
@ExceptionHandler({MethodArgumentNotValidException.class, BindException.class})
public Result<Void> handleValidException(BindException e) {
// 拼接错误信息
String msg = e.getBindingResult().getFieldErrors().stream()
.map(FieldError::getDefaultMessage)
.collect(Collectors.joining(","));
log.error("参数校验异常:{}", msg, e);
return Result.fail(400, msg);
}
/**
* 处理参数校验异常(@RequestParam)
*/
@ExceptionHandler(ConstraintViolationException.class)
public Result<Void> handleConstraintViolationException(ConstraintViolationException e) {
String msg = e.getConstraintViolations().stream()
.map(ConstraintViolation::getMessage)
.collect(Collectors.joining(","));
log.error("参数校验异常:{}", msg, e);
return Result.fail(400, msg);
}
/**
* 处理自定义业务异常
*/
@ExceptionHandler(BusinessException.class)
public Result<Void> handleBusinessException(BusinessException e) {
log.error("业务异常:{}", e.getMsg(), e);
return Result.fail(e.getCode(), e.getMsg());
}
/**
* 处理所有未捕获的异常
*/
@ExceptionHandler(Exception.class)
public Result<Void> handleException(Exception e) {
log.error("服务器内部异常", e);
return Result.fail(500, "服务器内部异常,请联系管理员");
}
}
- Java微服务-接口请求校验示例
package com.ai.test.case.controller;
import com.ai.test.case.dto.CaseAddDTO;
import com.ai.test.case.service.CaseService;
import com.ai.test.common.result.Result;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 测试用例控制器
*/
@RestController
@RequestMapping("/api/v1/cases")
@Tag(name = "测试用例管理", description = "测试用例的CRUD接口")
@RequiredArgsConstructor
public class CaseController {
private final CaseService caseService;
/**
* 创建测试用例
*/
@PostMapping
@Operation(summary = "创建测试用例", description = "新增数据/模型/服务测试用例")
public Result<Long> addCase(@Validated @RequestBody CaseAddDTO caseAddDTO) {
Long caseId = caseService.addCase(caseAddDTO);
return Result.success(caseId);
}
}
// 入参DTO
package com.ai.test.case.dto;
import lombok.Data;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
import java.util.List;
@Data
public class CaseAddDTO {
/**
* 用例名称
*/
@NotBlank(message = "用例名称不能为空")
private String name;
/**
* 用例类型:data-test(数据测试)/model-test(模型测试)/service-test(服务测试)
*/
@NotBlank(message = "用例类型不能为空")
private String type;
/**
* 关联的组件列表
*/
@NotNull(message = "组件列表不能为空")
private List<CaseComponentDTO> componentList;
/**
* 描述
*/
private String desc;
}
- Python服务-FastAPI参数校验与统一响应
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel, Field
from typing import List, Optional
import uvicorn
# 初始化FastAPI应用
app = FastAPI(title="数据测试服务", version="1.0.0")
# 统一响应模型
class ResponseModel(BaseModel):
code: int = Field(200, description="业务状态码")
msg: str = Field("操作成功", description="提示消息")
data: Optional[any] = Field(None, description="业务数据")
timestamp: int = Field(default_factory=lambda: int(time.time() * 1000), description="时间戳")
# 用例组件DTO
class CaseComponentDTO(BaseModel):
id: str = Field(..., description="组件ID")
name: str = Field(..., description="组件名称")
type: str = Field(..., description="组件类型")
config: dict = Field(..., description="组件配置")
# 创建用例DTO
class CaseAddDTO(BaseModel):
name: str = Field(..., description="用例名称", min_length=1, max_length=100)
type: str = Field(..., description="用例类型", pattern="^(data-test|model-test|service-test)$")
component_list: List[CaseComponentDTO] = Field(..., description="组件列表")
desc: Optional[str] = Field("", description="用例描述", max_length=500)
# 模拟用例服务
class CaseService:
@staticmethod
def add_case(case_add_dto: CaseAddDTO) -> int:
# 模拟创建用例,返回用例ID
return 123456
case_service = CaseService()
# 创建测试用例接口
@app.post("/api/v1/cases", response_model=ResponseModel)
async def add_case(case_add_dto: CaseAddDTO):
try:
case_id = case_service.add_case(case_add_dto)
return ResponseModel(data=case_id)
except Exception as e:
raise HTTPException(status_code=500, detail=ResponseModel(code=500, msg=str(e)).dict())
# 全局异常处理器
@app.exception_handler(HTTPException)
async def http_exception_handler(request, exc):
return JSONResponse(status_code=exc.status_code, content=exc.detail)
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8081)
3.2.2 任务调度模块:基于Quartz/Spring Cloud Task,支持分布式调度
任务调度模块是平台自动化能力的核心,负责测试任务的调度、执行、监控和管理,基于Quartz实现定时任务调度,基于Spring Cloud Task实现分布式任务执行,支持任务的并行执行、失败重试、断点续跑,保障测试任务的稳定执行。
3.2.2.1 核心功能设计
- 任务注册与管理:支持将测试任务注册到调度中心,管理任务的基本信息、执行配置、触发条件;
- 定时任务调度:基于Quartz的Cron表达式实现精准的定时任务调度,支持秒级、分钟级、小时级、日/月/周级的定时执行;
- 触发式任务调度:基于事件驱动实现触发式任务调度,当数据更新、模型更新等事件发生时,触发对应的测试任务执行;
- 分布式任务执行:基于Spring Cloud Task实现任务的分布式执行,将任务分发到不同的执行器节点,支持任务并行执行,提升测试效率;
- 任务生命周期管理:支持任务的启动、暂停、终止、重试,监控任务的执行状态(待执行/执行中/执行成功/执行失败);
- 任务失败处理:支持任务失败重试、断点续跑,记录任务失败原因,便于问题定位;
- 执行器管理:支持执行器节点的注册、发现、监控,动态分配任务到可用的执行器节点,实现负载均衡。
3.2.2.2 技术选型与架构设计
- 任务调度核心:Quartz 2.3.x,成熟的开源任务调度框架,支持Cron表达式、分布式调度、任务持久化;
- 分布式任务执行:Spring Cloud Task 2.4.x,基于Spring Boot的任务执行框架,支持任务的分布式执行、任务生命周期管理、任务日志记录;
- 任务存储:Quartz的任务信息和执行记录存储在MySQL中,实现任务的持久化;任务执行进度和状态缓存到Redis中,提升查询性能;
- 执行器框架:自定义任务执行器,基于Spring Boot实现,支持不同类型的测试任务(数据测试/模型测试/服务测试)的执行,执行器节点通过Nacos注册到服务中心,实现动态发现;
- 通信方式:任务调度中心通过Feign调用执行器节点的接口,分发任务;执行器节点通过WebSocket将任务执行进度和日志实时推送给调度中心。
任务调度架构图如下(Mermaid):
3.2.2.3 任务执行流程(Mermaid)
3.2.2.4 关键代码实现
- Java微服务-Quartz定时任务配置
package com.ai.test.task.config;
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.quartz.impl.StdSchedulerFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
import javax.sql.DataSource;
/**
* Quartz配置类
*/
@Configuration
public class QuartzConfig {
/**
* 配置SchedulerFactoryBean,整合Spring和Quartz
*/
@Bean
public SchedulerFactoryBean schedulerFactoryBean(DataSource dataSource) {
SchedulerFactoryBean factoryBean = new SchedulerFactoryBean();
// 设置数据源,将Quartz的任务信息存储到MySQL
factoryBean.setDataSource(dataSource);
// 自动启动Quartz
factoryBean.setAutoStartup(true);
// 启动延迟
factoryBean.setStartupDelay(5);
// 覆盖已存在的任务
factoryBean.setOverwriteExistingJobs(true);
return factoryBean;
}
/**
* 获取Scheduler实例
*/
@Bean
public Scheduler scheduler(SchedulerFactoryBean schedulerFactoryBean) {
return schedulerFactoryBean.getScheduler();
}
}
- Java微服务-任务调度服务核心类
package com.ai.test.task.service.impl;
import com.ai.test.task.dto.TaskAddDTO;
import com.ai.test.task.entity.TaskInfo;
import com.ai.test.task.mapper.TaskInfoMapper;
import com.ai.test.task.service.TaskScheduleService;
import com.ai.test.task.util.QuartzJobUtil;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.quartz.*;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
/**
* 任务调度服务实现类
*/
@Slf4j
@Service
@RequiredArgsConstructor
public class TaskScheduleServiceImpl implements TaskScheduleService {
private final Scheduler scheduler;
private final TaskInfoMapper taskInfoMapper;
/**
* 创建定时任务
*/
@Override
@Transactional(rollbackFor = Exception.class)
public Long addCronTask(TaskAddDTO taskAddDTO) {
// 1. 保存任务信息到MySQL
TaskInfo taskInfo = new TaskInfo();
taskInfo.setName(taskAddDTO.getName());
taskInfo.setExecType(taskAddDTO.getExecType());
taskInfo.setCronExpr(taskAddDTO.getCronExpr());
taskInfo.setCaseIds(String.join(",", taskAddDTO.getCaseIds()));
taskInfo.setRetryCount(taskAddDTO.getRetryCount());
taskInfo.setStatus(0); // 0-待执行 1-执行中 2-执行成功 3-执行失败
taskInfoMapper.insert(taskInfo);
Long taskId = taskInfo.getId();
// 2. 创建Quartz任务
String jobKey = "TASK_" + taskId;
String triggerKey = "TRIGGER_" + taskId;
// 构建JobDetail
JobDetail jobDetail = JobBuilder.newJob(TestTaskJob.class)
.withIdentity(jobKey, Scheduler.DEFAULT_GROUP)
.usingJobData("taskId", taskId)
.build();
// 构建Trigger
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerKey, Scheduler.DEFAULT_GROUP)
.withSchedule(CronScheduleBuilder.cronSchedule(taskAddDTO.getCronExpr()))
.build();
// 调度任务
try {
scheduler.scheduleJob(jobDetail, trigger);
log.info("创建定时任务成功,taskId:{},cron:{}", taskId, taskAddDTO.getCronExpr());
} catch (SchedulerException e) {
log.error("创建定时任务失败", e);
throw new BusinessException(4003, "创建定时任务失败");
}
return taskId;
}
/**
* 手动触发任务
*/
@Override
public void runManualTask(Long taskId) {
try {
String jobKey = "TASK_" + taskId;
scheduler.triggerJob(JobKey.jobKey(jobKey, Scheduler.DEFAULT_GROUP));
log.info("手动触发任务成功,taskId:{}", taskId);
} catch (SchedulerException e) {
log.error("手动触发任务失败", e);
throw new BusinessException(4004, "手动触发任务失败");
}
}
/**
* 暂停任务
*/
@Override
public void pauseTask(Long taskId) {
try {
String jobKey = "TASK_" + taskId;
scheduler.pauseJob(JobKey.jobKey(jobKey, Scheduler.DEFAULT_GROUP));
// 更新任务状态
TaskInfo taskInfo = new TaskInfo();
taskInfo.setId(taskId);
taskInfo.setStatus(4); // 4-已暂停
taskInfoMapper.updateById(taskInfo);
log.info("暂停任务成功,taskId:{}", taskId);
} catch (SchedulerException e) {
log.error("暂停任务失败", e);
throw new BusinessException(4005, "暂停任务失败");
}
}
}
- Java微服务-测试任务Job实现
package com.ai.test.task.job;
import com.ai.test.task.service.TaskExecuteService;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* 测试任务Quartz Job
*/
@Slf4j
@Component
public class TestTaskJob implements Job {
private static TaskExecuteService taskExecuteService;
// 静态注入,解决Quartz Job无法注入Spring Bean的问题
@Autowired
public void setTaskExecuteService(TaskExecuteService taskExecuteService) {
TestTaskJob.taskExecuteService = taskExecuteService;
}
@Override
public void execute(JobExecutionContext context) {
// 获取任务ID
Long taskId = context.getJobDetail().getJobDataMap().getLong("taskId");
log.info("开始执行测试任务,taskId:{}", taskId);
try {
// 执行任务
taskExecuteService.executeTask(taskId);
log.info("测试任务执行成功,taskId:{}", taskId);
} catch (Exception e) {
log.error("测试任务执行失败,taskId:{}", e);
// 处理任务失败逻辑(重试/更新状态)
taskExecuteService.handleTaskFail(taskId);
}
}
}
3.2.3 权限控制模块:基于RBAC模型,细粒度资源访问控制
权限控制模块是平台团队协作能力的核心,负责平台所有资源的访问权限控制,基于RBAC(基于角色的访问控制)模型设计,实现用户-角色-权限的层级管理,细粒度控制测试用例、报告、服务等资源的访问权限,支持100人规模团队的权限隔离和资源共享。
3.2.3.1 RBAC模型设计
RBAC模型的核心是用户关联角色,角色关联权限,通过角色实现用户和权限的解耦,避免为每个用户单独配置权限,提升权限管理效率。本平台采用RBAC3模型(RBAC1+RBAC2),支持角色继承、角色限制,适配复杂的团队权限管理场景。
RBAC模型包含5个核心实体:用户、团队、角色、权限、资源,实体之间的关系如下:
- 用户与团队:多对一,一个用户属于一个团队,一个团队包含多个用户(便于团队级别的权限隔离);
- 用户与角色:多对多,一个用户可拥有多个角色,一个角色可分配给多个用户;
- 角色与角色:一对多,支持角色继承(如管理员角色继承普通角色的所有权限);
- 角色与权限:多对多,一个角色可拥有多个权限,一个权限可分配给多个角色;
- 权限与资源:一对一,一个权限对应一个具体的资源操作(如查询测试用例、创建任务、导出报告)。
RBAC模型关系图如下(Mermaid):
3.2.3.2 权限粒度设计
平台的权限控制分为三级粒度,从粗到细实现资源的精准访问控制:
- 菜单权限:控制用户是否能看到前端的菜单(如数据测试菜单、模型测试菜单),基于前端路由实现,无菜单权限的用户无法访问对应的页面;
- 按钮/操作权限:控制用户是否能执行页面上的操作(如创建用例、删除任务、导出报告),基于前端按钮的显隐实现,无操作权限的用户无法看到对应的按钮;
- 数据权限:控制用户能访问的具体数据资源(如只能查看自己创建的用例、只能查看本团队的报告),基于后端数据过滤实现,即使用户调用接口,也只能返回其有权限访问的数据。
3.2.3.3 核心实现要点
- 权限认证:基于**JWT(JSON Web Token)**实现用户身份认证,用户登录后生成JWT令牌,前端在后续的请求中携带令牌,后端通过解析令牌验证用户身份;
- 权限校验:Java微服务基于Spring Security实现权限校验,通过自定义权限拦截器和注解实现接口级别的权限控制;Python服务基于FastAPI的依赖注入实现权限校验,拦截无权限的请求;
- 权限缓存:将用户的权限信息(角色、菜单、操作权限)缓存到Redis中,用户每次请求时直接从缓存中获取权限信息,无需每次查询数据库,提升校验效率;
- 动态权限:支持权限的动态配置和更新,权限更新后自动刷新Redis中的权限缓存,无需重启服务;
- 前端权限控制:前端通过获取用户的权限信息,动态生成路由和菜单,显隐操作按钮,实现前端的权限控制;同时在前端请求拦截器中添加权限校验,避免无权限的前端操作。
3.2.3.4 关键代码实现
- Java微服务-JWT工具类
package com.ai.test.common.jwt;
import com.auth0.jwt.JWT;
import com.auth0.jwt.algorithms.Algorithm;
import com.auth0.jwt.exceptions.JWTV
erificationException;
import com.auth0.jwt.interfaces.Claim;
import com.auth0.jwt.interfaces.DecodedJWT;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import java.util.Date;
import java.util.Map;
/**
* JWT工具类
*/
@Slf4j
@Component
public class JwtUtil {
@Value("${jwt.secret}")
private String secret;
@Value("${jwt.expire}")
private Long expire;
/**
* 生成JWT令牌
*/
public String generateToken(Long userId, String username) {
Date now = new Date();
Date expireTime = new Date(now.getTime() + expire * 1000);
return JWT.create()
.withClaim("userId", userId)
.withClaim("username", username)
.withIssuedAt(now)
.withExpiresAt(expireTime)
.sign(Algorithm.HMAC256(secret));
}
/**
* 验证并解析JWT令牌
*/
public DecodedJWT verifyToken(String token) {
try {
return JWT.require(Algorithm.HMAC256(secret)).build().verify(token);
} catch (JWTVerificationException e) {
log.error("JWT令牌验证失败", e);
return null;
}
}
/**
* 从令牌中获取用户ID
*/
public Long getUserId(String token) {
DecodedJWT jwt = verifyToken(token);
if (jwt == null) return null;
Claim claim = jwt.getClaim("userId");
return claim != null ? claim.asLong() : null;
}
}
- Java微服务-Spring Security权限校验配置
package com.ai.test.common.security;
import com.ai.test.common.jwt.JwtUtil;
import com.ai.test.user.service.UserService;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.AuthenticationManager;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter;
/**
* Spring Security配置类
*/
@Configuration
@EnableWebSecurity
@EnableGlobalMethodSecurity(prePostEnabled = true) // 启用方法级别权限控制注解
@RequiredArgsConstructor
public class SecurityConfig {
private final JwtUtil jwtUtil;
private final UserService userService;
/**
* 密码编码器
*/
@Bean
public BCryptPasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
/**
* 安全过滤器链
*/
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
// 关闭CSRF,使用JWT不需要CSRF
.csrf().disable()
// 基于token,不需要session
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS)
.and()
.authorizeRequests()
// 公开接口(登录、注册等)
.antMatchers("/api/v1/auth/**", "/swagger-ui/**", "/v3/api-docs/**").permitAll()
// 其他所有接口都需要认证
.anyRequest().authenticated()
.and()
// 添加JWT认证过滤器
.addFilterBefore(new JwtAuthenticationFilter(jwtUtil, userService),
UsernamePasswordAuthenticationFilter.class);
return http.build();
}
/**
* 认证管理器
*/
@Bean
public AuthenticationManager authenticationManager(HttpSecurity http) throws Exception {
return http.getSharedObject(AuthenticationManagerBuilder.class).build();
}
}
- Java微服务-JWT认证过滤器
package com.ai.test.common.security;
import com.ai.test.common.jwt.JwtUtil;
import com.ai.test.user.entity.User;
import com.ai.test.user.service.UserService;
import lombok.RequiredArgsConstructor;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* JWT认证过滤器
*/
@Component
@RequiredArgsConstructor
public class JwtAuthenticationFilter extends OncePerRequestFilter {
private final JwtUtil jwtUtil;
private final UserService userService;
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
// 从请求头获取token
String token = getTokenFromRequest(request);
if (token != null) {
// 验证token
Long userId = jwtUtil.getUserId(token);
if (userId != null) {
// 从数据库或缓存获取用户信息
User user = userService.getById(userId);
if (user != null && user.getStatus() == 1) { // 用户状态正常
// 创建认证信息
UsernamePasswordAuthenticationToken authentication =
new UsernamePasswordAuthenticationToken(user, null, user.getAuthorities());
SecurityContextHolder.getContext().setAuthentication(authentication);
}
}
}
filterChain.doFilter(request, response);
}
/**
* 从请求头获取token
*/
private String getTokenFromRequest(HttpServletRequest request) {
String bearerToken = request.getHeader("Authorization");
if (bearerToken != null && bearerToken.startsWith("Bearer ")) {
return bearerToken.substring(7);
}
return null;
}
}
- Java微服务-方法级别权限控制注解使用
package com.ai.test.case.controller;
import com.ai.test.case.dto.CaseAddDTO;
import com.ai.test.case.service.CaseService;
import com.ai.test.common.result.Result;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import lombok.RequiredArgsConstructor;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.*;
import javax.validation.Valid;
@RestController
@RequestMapping("/api/v1/cases")
@Tag(name = "测试用例管理", description = "测试用例的CRUD接口")
@RequiredArgsConstructor
public class CaseController {
private final CaseService caseService;
/**
* 创建测试用例 - 需要`case:create`权限
*/
@PostMapping
@Operation(summary = "创建测试用例")
@PreAuthorize("hasAuthority('case:create')") // 方法级别权限控制
public Result<Long> addCase(@Valid @RequestBody CaseAddDTO caseAddDTO) {
Long caseId = caseService.addCase(caseAddDTO);
return Result.success(caseId);
}
/**
* 删除测试用例 - 需要`case:delete`权限
*/
@DeleteMapping("/{caseId}")
@Operation(summary = "删除测试用例")
@PreAuthorize("hasAuthority('case:delete')")
public Result<Void> deleteCase(@PathVariable Long caseId) {
caseService.deleteCase(caseId);
return Result.success();
}
/**
* 查询测试用例 - 需要`case:read`权限,并且只能查询自己或本团队的数据
*/
@GetMapping
@Operation(summary = "查询测试用例")
@PreAuthorize("hasAuthority('case:read')")
public Result<Object> getCases(@RequestParam(required = false) String type,
@RequestParam(defaultValue = "1") Integer page,
@RequestParam(defaultValue = "10") Integer size) {
// 服务层会进行数据权限过滤
Object result = caseService.getCases(type, page, size);
return Result.success(result);
}
}
四、平台集成与测试:多模块联调,确保平台稳定运行
完成前后端核心模块开发后,需要将所有模块进行集成联调,确保平台能够稳定运行。集成测试包括服务间通信测试、数据一致性测试、权限控制测试、性能压测等,通过全面的测试验证平台的可用性和可靠性。
4.1 服务集成测试:验证微服务间通信与协作
4.1.1 测试环境搭建
使用Docker Compose快速搭建包含MySQL、Redis、Nacos、MinIO、Elasticsearch等组件的测试环境:
version: '3.8'
services:
mysql:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: root123
MYSQL_DATABASE: ai_test
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql
redis:
image: redis:6.0-alpine
ports:
- "6379:6379"
command: redis-server --appendonly yes
nacos:
image: nacos/nacos-server:2.1.0
environment:
MODE: standalone
SPRING_DATASOURCE_PLATFORM: mysql
MYSQL_SERVICE_HOST: mysql
MYSQL_SERVICE_DB_NAME: nacos
MYSQL_SERVICE_USER: root
MYSQL_SERVICE_PASSWORD: root123
ports:
- "8848:8848"
depends_on:
- mysql
minio:
image: minio/minio:latest
command: server /data --console-address ":9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin123
ports:
- "9000:9000"
- "9001:9001"
volumes:
- minio_data:/data
elasticsearch:
image: elasticsearch:8.10.0
environment:
discovery.type: single-node
xpack.security.enabled: false
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
ports:
- "9200:9200"
volumes:
- es_data:/usr/share/elasticsearch/data
kibana:
image: kibana:8.10.0
ports:
- "5601:5601"
environment:
ELASTICSEARCH_HOSTS: '["http://elasticsearch:9200"]'
depends_on:
- elasticsearch
volumes:
mysql_data:
minio_data:
es_data:
4.1.2 服务间通信测试
使用Postman或自动化测试脚本,验证以下核心服务间通信链路:
- 前端 → API网关 → Java微服务 → MySQL/Redis
- 任务调度服务 → 数据测试服务 → Great Expectations → MinIO
- 模型测试服务 → MLflow → Evidently AI → 报告生成服务
- 权限控制服务 → 所有其他服务(权限校验)
测试脚本示例:
import requests
import json
def test_service_communication():
base_url = "http://localhost:8080"
headers = {"Authorization": "Bearer your_jwt_token"}
# 测试1: 用户登录 → 获取权限 → 访问受保护接口
login_resp = requests.post(f"{base_url}/api/v1/auth/login", json={
"username": "admin",
"password": "admin123"
})
token = login_resp.json()["data"]["token"]
# 测试2: 创建测试用例
headers["Authorization"] = f"Bearer {token}"
case_resp = requests.post(f"{base_url}/api/v1/cases", headers=headers, json={
"name": "数据质量测试",
"type": "data-test",
"component_list": [{
"id": "1",
"name": "非空校验",
"type": "data-check",
"config": {"field": "id", "expect": True}
}]
})
case_id = case_resp.json()["data"]
# 测试3: 创建并执行测试任务
task_resp = requests.post(f"{base_url}/api/v1/tasks", headers=headers, json={
"name": "数据质量检查",
"execType": "manual",
"caseIds": [case_id],
"retryCount": 2
})
task_id = task_resp.json()["data"]
# 启动任务
run_resp = requests.post(f"{base_url}/api/v1/tasks/{task_id}/run", headers=headers)
# 监控任务进度(WebSocket或轮询)
import time
for i in range(10):
progress_resp = requests.get(f"{base_url}/api/v1/tasks/{task_id}/progress", headers=headers)
progress = progress_resp.json()["data"]
print(f"任务进度: {progress}%")
if progress == 100:
break
time.sleep(1)
# 获取测试结果
result_resp = requests.get(f"{base_url}/api/v1/reports/task/{task_id}", headers=headers)
print(f"测试结果: {result_resp.json()}")
if __name__ == "__main__":
test_service_communication()
4.2 权限控制集成测试
验证RBAC模型的完整功能,包括:
- 不同角色用户登录:管理员、测试经理、测试工程师、访客
- 菜单权限控制:不同角色看到的菜单不同
- 按钮权限控制:无权限的操作按钮被隐藏
- 数据权限控制:用户只能访问自己或本团队的数据
- 接口权限控制:无权限的接口返回403错误
测试用例表示例:
| 测试场景 | 测试用户 | 预期结果 | 实际结果 |
|---|---|---|---|
| 管理员创建用例 | admin | 成功 | 成功 |
| 测试工程师删除他人用例 | tester | 失败(403) | 失败(403) |
| 访客查看报告 | guest | 仅能看到公开报告 | 符合预期 |
| 切换团队权限 | user | 只能看到新团队数据 | 符合预期 |
4.3 性能与稳定性测试
4.3.1 并发性能测试
使用JMeter模拟多用户并发操作:
- 100并发用户同时执行测试任务
- 50并发用户同时上传大文件(100MB+)
- 30并发用户同时生成复杂报告
JMeter测试计划关键配置:
<ThreadGroup guiclass="ThreadGroupGui" testclass="ThreadGroup" testname="并发测试任务" enabled="true">
<intProp name="ThreadGroup.num_threads">100</intProp>
<intProp name="ThreadGroup.ramp_time">10</intProp>
<longProp name="ThreadGroup.start_time">0</longProp>
<longProp name="ThreadGroup.end_time">0</longProp>
<boolProp name="ThreadGroup.scheduler">false</boolProp>
</ThreadGroup>
4.3.2 长时间稳定性测试
模拟平台连续运行72小时,验证:
- 内存泄漏:监控Java/Python服务内存使用情况
- 数据库连接池:监控连接数,防止连接泄漏
- 缓存命中率:监控Redis缓存使用效率
- 服务可用性:定期检查各服务健康状态
监控脚本示例:
#!/bin/bash
# 平台稳定性监控脚本
while true; do
echo "===== $(date) ====="
# 检查服务健康状态
curl -f http://localhost:8080/actuator/health || echo "API网关异常"
curl -f http://localhost:8081/health || echo "用户服务异常"
curl -f http://localhost:8082/health || echo "数据测试服务异常"
# 监控内存使用
ps aux | grep -E "java.*ai-test|python.*fastapi" | awk '{print $2, $4, $6}' | sort -k2 -rn | head -5
# 监控数据库连接
mysql -uroot -proot123 -e "SHOW PROCESSLIST" | wc -l
sleep 300 # 5分钟监控一次
done
五、部署与上线:基于Kubernetes的生产环境部署
完成开发和测试后,将平台部署到生产环境。采用Kubernetes容器化部署,实现高可用、弹性伸缩、故障自愈等生产级能力。
5.1 Kubernetes部署文件设计
5.1.1 命名空间与配置
# namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ai-test-platform
---
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
namespace: ai-test-platform
data:
application.yml: |
spring:
datasource:
url: jdbc:mysql://mysql.ai-test-platform:3306/ai_test
username: ${DB_USER}
password: ${DB_PASSWORD}
redis:
host: redis.ai-test-platform
port: 6379
nacos:
server-addr: nacos.ai-test-platform:8848
minio:
endpoint: http://minio.ai-test-platform:9000
access-key: ${MINIO_ACCESS_KEY}
secret-key: ${MINIO_SECRET_KEY}
5.1.2 Java微服务Deployment示例
# user-service-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: user-service
namespace: ai-test-platform
labels:
app: user-service
spec:
replicas: 2
selector:
matchLabels:
app: user-service
template:
metadata:
labels:
app: user-service
spec:
containers:
- name: user-service
image: registry.example.com/ai-test/user-service:v1.0.0
ports:
- containerPort: 8081
env:
- name: DB_USER
valueFrom:
secretKeyRef:
name: db-secret
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-secret
key: password
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /actuator/health
port: 8081
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8081
initialDelaySeconds: 20
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: user-service
namespace: ai-test-platform
spec:
selector:
app: user-service
ports:
- port: 8081
targetPort: 8081
type: ClusterIP
5.1.3 Python服务Deployment示例
# data-test-service-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-test-service
namespace: ai-test-platform
labels:
app: data-test-service
spec:
replicas: 3
selector:
matchLabels:
app: data-test-service
template:
metadata:
labels:
app: data-test-service
spec:
containers:
- name: data-test-service
image: registry.example.com/ai-test/data-test-service:v1.0.0
ports:
- containerPort: 8082
env:
- name: PYTHONPATH
value: "/app"
- name: MINIO_ACCESS_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: access-key
- name: MINIO_SECRET_KEY
valueFrom:
secretKeyRef:
name: minio-secret
key: secret-key
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
volumeMounts:
- name: model-cache
mountPath: /app/model_cache
volumes:
- name: model-cache
emptyDir: {}
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: data-test-service-hpa
namespace: ai-test-platform
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: data-test-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
5.1.4 前端应用部署
# frontend-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-test-frontend
namespace: ai-test-platform
labels:
app: ai-test-frontend
spec:
replicas: 2
selector:
matchLabels:
app: ai-test-frontend
template:
metadata:
labels:
app: ai-test-frontend
spec:
containers:
- name: frontend
image: registry.example.com/ai-test/frontend:v1.0.0
ports:
- containerPort: 80
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "200m"
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: ai-test-frontend
namespace: ai-test-platform
spec:
selector:
app: ai-test-frontend
ports:
- port: 80
targetPort: 80
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ai-test-ingress
namespace: ai-test-platform
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: ai-test.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: ai-test-frontend
port:
number: 80
- path: /api
pathType: Prefix
backend:
service:
name: api-gateway
port:
number: 8080
5.2 持续部署流水线(GitLab CI/CD)
# .gitlab-ci.yml
stages:
- build
- test
- scan
- build-image
- deploy
variables:
DOCKER_REGISTRY: registry.example.com
K8S_NAMESPACE: ai-test-platform
# 1. 构建阶段
build-java:
stage: build
image: maven:3.9-eclipse-temurin-17
script:
- cd user-service && mvn clean compile -DskipTests
only:
- main
- develop
build-python:
stage: build
image: python:3.10
script:
- cd data-test-service && pip install -r requirements.txt
only:
- main
- develop
# 2. 测试阶段
unit-test:
stage: test
image: maven:3.9-eclipse-temurin-17
script:
- cd user-service && mvn test
artifacts:
reports:
junit:
- user-service/target/surefire-reports/TEST-*.xml
integration-test:
stage: test
image: python:3.10
script:
- cd data-test-service && python -m pytest tests/ --cov=app --cov-report=xml
artifacts:
reports:
junit:
- data-test-service/test-results.xml
coverage_report:
coverage_format: cobertura
path: data-test-service/coverage.xml
# 3. 安全扫描
security-scan:
stage: scan
image: aquasec/trivy:latest
script:
- trivy fs --severity HIGH,CRITICAL .
allow_failure: true
# 4. 构建Docker镜像
build-docker-image:
stage: build-image
image: docker:20.10
services:
- docker:20.10-dind
variables:
DOCKER_TLS_CERTDIR: "/certs"
script:
- docker build -t $DOCKER_REGISTRY/ai-test/user-service:$CI_COMMIT_SHA -f user-service/Dockerfile user-service/
- docker push $DOCKER_REGISTRY/ai-test/user-service:$CI_COMMIT_SHA
- docker build -t $DOCKER_REGISTRY/ai-test/data-test-service:$CI_COMMIT_SHA -f data-test-service/Dockerfile data-test-service/
- docker push $DOCKER_REGISTRY/ai-test/data-test-service:$CI_COMMIT_SHA
only:
- main
# 5. 部署到Kubernetes
deploy-production:
stage: deploy
image: bitnami/kubectl:latest
script:
- echo $KUBECONFIG_BASE64 | base64 -d > kubeconfig
- export KUBECONFIG=kubeconfig
- kubectl set image deployment/user-service user-service=$DOCKER_REGISTRY/ai-test/user-service:$CI_COMMIT_SHA -n $K8S_NAMESPACE
- kubectl set image deployment/data-test-service data-test-service=$DOCKER_REGISTRY/ai-test/data-test-service:$CI_COMMIT_SHA -n $K8S_NAMESPACE
- kubectl rollout status deployment/user-service -n $K8S_NAMESPACE --timeout=300s
- kubectl rollout status deployment/data-test-service -n $K8S_NAMESPACE --timeout=300s
only:
- main
when: manual
六、总结与展望:全栈AI测试平台的演进路线
6.1 MVP版本核心价值总结
本文设计并实现的全栈AI测试平台MVP版本,已经具备了以下核心能力:
- 一站式测试覆盖:整合数据测试、模型测试、服务测试、前端测试全链路,解决AI测试碎片化问题
- 自动化测试流水线:支持定时、触发、手动三种任务调度模式,实现测试自动化
- 高效团队协作:基于RBAC的权限控制,支持100人团队的分工协作
- 智能化测试报告:多维度可视化图表,直观展示测试结果
- 高可扩展架构:微服务+插件化设计,支持快速集成新工具和功能
- 生产级部署:Kubernetes容器化部署,保障平台的高可用和弹性伸缩
6.2 平台使用效果预期
在100人规模的测试团队中,平台预计能够带来以下效果提升:
| 指标 | 改进前 | 改进后 | 提升幅度 |
|---|---|---|---|
| 测试用例设计时间 | 30分钟/用例 | 10分钟/用例 | 67% |
| 测试任务执行效率 | 串行执行 | 并行执行 | 300% |
| 问题定位时间 | 2小时 | 20分钟 | 83% |
| 测试报告生成时间 | 1小时 | 5分钟 | 92% |
| 团队协作冲突 | 每周5次 | 每周1次 | 80% |
6.3 未来演进方向
6.3.1 短期规划(3-6个月)
-
AI测试能力增强
- 集成更多AI测试工具(如SHAP模型可解释性、DeepChecks数据完整性)
- 支持大语言模型(LLM)的专项测试(提示工程测试、幻觉检测)
- 增加A/B测试和模型冠军-挑战者模式
-
智能化升级
- 基于历史数据预测测试用例失败概率
- 智能推荐测试用例和测试数据
- 自动生成测试代码(基于大语言模型)
-
用户体验优化
- 移动端适配(支持手机查看测试报告)
- 语音助手(语音创建测试任务)
- 更加智能的可视化分析
6.3.2 中期规划(6-12个月)
-
测试左移与右移
- 与CI/CD流水线深度集成,实现测试左移
- 生产环境监控与测试右移,实时检测数据/模型漂移
- 混沌工程集成,主动注入故障测试系统韧性
-
多云与混合云支持
- 支持跨云平台的测试任务调度
- 边缘计算场景下的AI测试支持
- 联邦学习等分布式AI模式的测试支持
-
生态体系建设
- 开放平台API,支持第三方工具快速接入
- 建立测试用例市场,共享优质测试用例
- 提供SaaS化服务,降低使用门槛
6.3.3 长期愿景(1-3年)
-
自主智能测试
- 基于强化学习的自适应测试策略
- 完全自主的测试机器人,无需人工干预
- 测试过程的自我优化和演进
-
测试数字孪生
- 构建AI系统的数字孪生,在虚拟环境中进行全方位测试
- 预测系统在不同场景下的行为和表现
- 基于数字孪生的风险预警和决策支持
-
行业标准化
- 参与制定AI测试行业标准和规范
- 成为AI测试领域的基准平台
- 推动AI测试技术的普及和发展
6.4 开源与社区贡献
本平台的核心框架和模块计划开源,以促进AI测试技术的发展:
-
开源计划
- 前端微前端架构、通用可视化组件
- Java微服务核心框架、RBAC权限控制模块
- Python测试服务框架、工具集成SDK
- Kubernetes部署模板和CI/CD流水线
-
社区建设
- 建立开发者社区,收集反馈和改进建议
- 定期举办技术分享和培训
- 与高校合作,培养AI测试人才
-
商业化路径
- 开源版满足基础需求
- 企业版提供高级功能和技术支持
- 云服务版提供SaaS化一站式服务
6.5 结语
全栈AI测试平台的建设是一个系统工程,需要技术创新、工程实践、团队协作的有机结合。本文提供了一个从0到1的完整实践路径,涵盖了架构设计、模块开发、集成测试、生产部署的全过程。
随着AI技术的快速发展,AI测试的重要性日益凸显。希望本文能够为正在或计划构建AI测试平台的组织和个人提供有价值的参考,共同推动AI测试技术的进步,保障AI系统的质量与可靠性,让AI技术更好地服务于人类社会。
附录A:平台快速启动指南
# 1. 克隆代码仓库
git clone https://github.com/your-org/ai-test-platform.git
cd ai-test-platform
# 2. 启动基础服务(Docker Compose)
docker-compose -f docker-compose.infrastructure.yml up -d
# 3. 编译并启动Java微服务
cd user-service && mvn clean package -DskipTests
java -jar target/user-service-1.0.0.jar &
# 4. 启动Python服务
cd data-test-service && pip install -r requirements.txt
uvicorn main:app --host 0.0.0.0 --port 8082 &
# 5. 启动前端应用
cd frontend && npm install && npm run dev
# 6. 访问平台
# 前端:http://localhost:3000
# API文档:http://localhost:8080/swagger-ui.html
# 管理界面:http://localhost:9001 (MinIO)
附录B:核心配置文件示例
完整配置文件已上传至GitHub仓库:
👉 https://github.com/your-org/ai-test-platform/tree/main/configs
附录C:常见问题解答(FAQ)
Q1: 平台支持哪些AI框架的模型测试?
A1: 目前支持PyTorch、TensorFlow、Scikit-learn、ONNX格式的模型,可通过插件扩展支持其他框架。
Q2: 如何处理超大规模数据集(TB级别)的测试?
A2: 平台支持分布式测试,可将测试任务分发到多个节点并行执行;同时支持抽样测试,对大规模数据进行代表性抽样。
Q3: 平台的性能瓶颈在哪里?
A3: 主要瓶颈在模型推理和数据读取,建议使用GPU加速和高速存储(如SSD)。平台支持水平扩展,可通过增加节点提升性能。
Q4: 如何保证测试数据的安全性?
A4: 支持数据脱敏、加密存储、访问审计;可通过权限控制限制敏感数据的访问;支持私有化部署,数据不出域。
让我们一起构建更可靠的AI系统! 🚀

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)