多模态大模型微调框架之transformers
transformers 是 Hugging Face 提供的一个大模型推理和训练框架。transformers 配合 PEFT 微调库完成原生的大模型微调。PEFT (Parameter-Efficient Fine-Tuning) 是一个用于高效地将预训练模型适配到各种下游应用的库,无需对模型的所有参数进行微调。PEFT 方法仅微调少量(额外的)模型参数——显著降低了计算和存储成本——同时取得

transformers 是 Hugging Face 提供的一个大模型推理和训练框架。transformers 配合 PEFT 微调库完成原生的大模型微调。
PEFT (Parameter-Efficient Fine-Tuning) 是一个用于高效地将预训练模型适配到各种下游应用的库,无需对模型的所有参数进行微调。PEFT 方法仅微调少量(额外的)模型参数——显著降低了计算和存储成本——同时取得了与完全微调模型相当的性能。这使得在消费级硬件上训练和存储大型语言模型 (LLM) 更加容易。
安装
datasets==3.3.2
modelscope==1.23.1
qwen-vl-utils==0.0.10
peft==0.14.0
transformers==4.49.0
pillow==11.1.0
torch==2.8.0
torchvision>=0.22.0
swanlab==0.4.8
微调Qwen3-vl
模型准备
Hugging Face 上的模型下载可能会失败,解决办法:安装模搭包再下载模型
uv add modelscope
uv run modelscope download --model unsloth/Qwen3-VL-2B-Instruct-unsloth-bnb-4bit
数据集准备
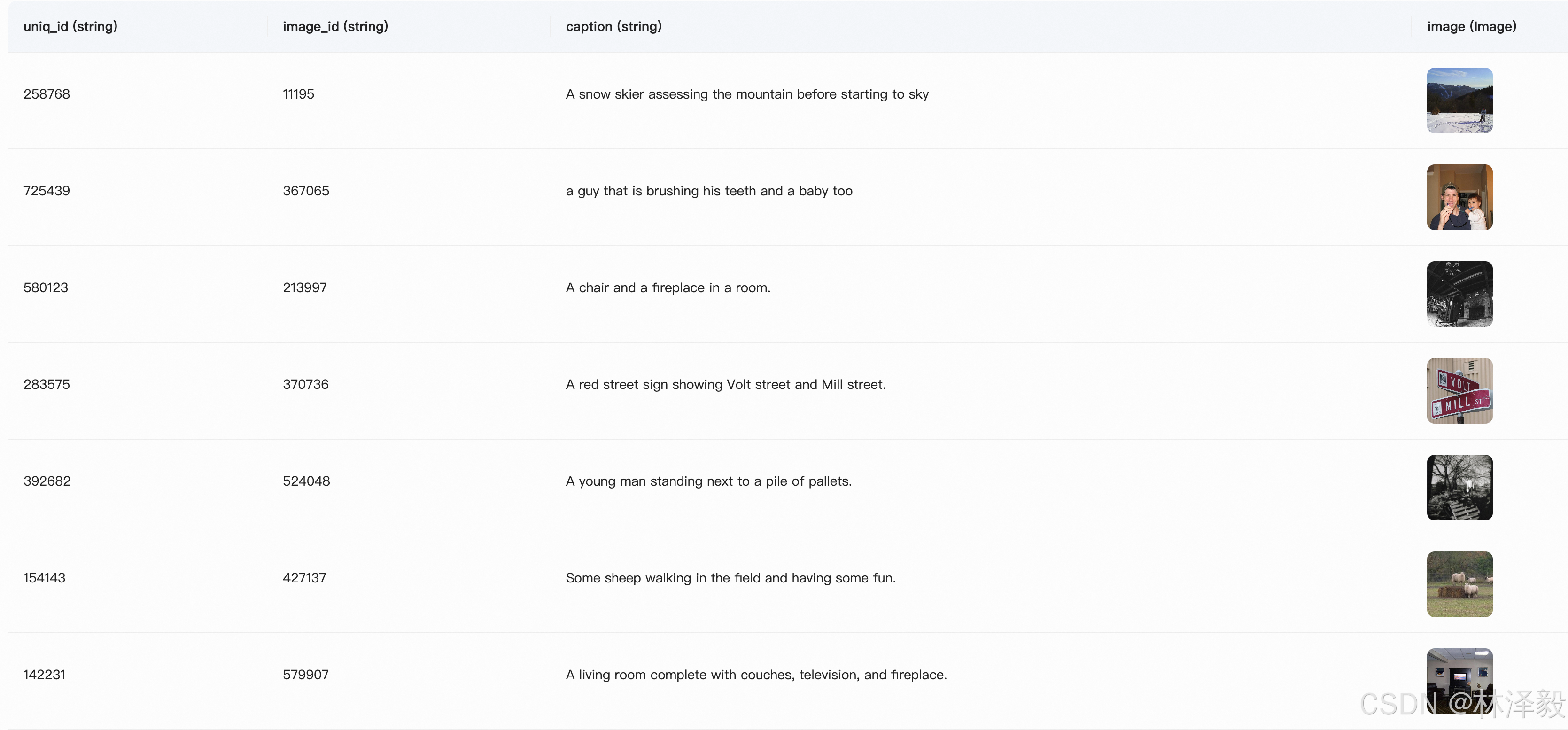
下载 COCO 2014 Caption数据集
COCO 2014 Caption数据集是Microsoft Common Objects in Context (COCO)数据集的一部分,主要用于图像描述任务。该数据集包含了大约40万张图像,每张图像都有至少1个人工生成的英文描述语句。这些描述语句旨在帮助计算机理解图像内容,并为图像自动生成描述提供训练数据。
import os
import pandas as pd
from modelscope import snapshot_download, AutoTokenizer
from modelscope.msdatasets import MsDataset
def download_model():
# 在modelscope上下载Qwen2-VL模型到本地目录下
model_dir = snapshot_download("Qwen/Qwen3-VL-2B-Instruct", cache_dir="./", revision="master")
print(f"Downloaded Qwen3-VL-7B-Instruct to {model_dir}")
def download_dataset():
MAX_DATA_NUMBER = 500
# 检查目录是否已存在
if not os.path.exists('coco_2014_caption'):
# 从modelscope下载COCO 2014图像描述数据集
ds = MsDataset.load('modelscope/coco_2014_caption', subset_name='coco_2014_caption', split='train')
print(len(ds))
# 设置处理的图片数量上限
total = min(MAX_DATA_NUMBER, len(ds))
# 创建保存图片的目录
os.makedirs('coco_2014_caption', exist_ok=True)
# 初始化存储图片路径和描述的列表
image_paths = []
captions = []
for i in range(total):
# 获取每个样本的信息
item = ds[i]
image_id = item['image_id']
caption = item['caption']
image = item['image']
# 保存图片并记录路径
image_path = os.path.abspath(f'coco_2014_caption/{image_id}.jpg')
image.save(image_path)
# 将路径和描述添加到列表中
image_paths.append(image_path)
captions.append(caption)
# 每处理50张图片打印一次进度
if (i + 1) % 50 == 0:
print(f'Processing {i + 1}/{total} images ({(i + 1) / total * 100:.1f}%)')
# 将图片路径和描述保存为CSV文件
df = pd.DataFrame({
'image_path': image_paths,
'caption': captions
})
# 将数据保存为CSV文件
df.to_csv('./coco-2024-dataset.csv', index=False)
print(f'数据处理完成,共处理了{total}张图片')
else:
print('coco_2014_caption目录已存在,跳过数据处理步骤')
if __name__ == '__main__':
download_model()
下载好的数据集是 csv 格式,然后转换成json格式,并拆分为训练集和验证集。
数据集csv转json并拆分
import os
import json
import pandas as pd
def csv_to_json(csv_file, dst_json_file):
df = pd.read_csv(csv_file)
conversations = []
for i in range(len(df)):
conversations.append({
"id": f"id{i+1}",
"conversations": [
{
"from": "user",
"value": f"请描述这张图片: <|vision_start|>{df.iloc[i]['image_path']}<|vision_end|>"
},
{
"from": "assistant",
"value": df.iloc[i]['caption']
}
]
})
# 保存为Json
with open(dst_json_file, 'w', encoding='utf-8') as f:
json.dump(conversations, f, ensure_ascii=False, indent=2)
def split_train_test(json_path, dst_json_dir, ratio=0.2):
"""数据集拆分为训练集和验证集"""
with open(json_path, 'r') as f:
data = json.load(f)
value = int(len(data) * ratio)
train_data = data[:-value]
test_data = data[-value:]
with open(f"{dst_json_dir}/train.json", "w") as f:
json.dump(train_data, f, ensure_ascii=False, indent=2)
with open(f"{dst_json_dir}/test.json", "w") as f:
json.dump(test_data, f, ensure_ascii=False, indent=2)
if __name__ == '__main__':
csv_path = "/home/lijinkui/Documents/code/QwenVL_mini/resource/coco_caption/coco_3000_caption/coco-3000-dataset.csv"
dst_json_path = "/home/lijinkui/Documents/code/QwenVL_mini/resource/coco_caption/coco_3000_caption/coco-3000.json"
csv_to_json(csv_path, dst_json_path)
dst_json_dir = "/home/lijinkui/Documents/code/QwenVL_mini/resource/coco_caption/coco_3000_caption"
split_train_test(dst_json_path, dst_json_dir, ratio=0.2)
拆分之后的数据集展示

代码示例
功能特点:
- Qlora 4bit 量化微调
- flash_attention_2 加速
备注:由于 flash_attention 的安装问题较多,已经在代码中注释掉。其安装可参考:
https://zhuanlan.zhihu.com/p/1994754750374244794
在代码中需要修改:
- 模型的路径
- 数据集的路径
- batch_size,避免显存OOM
- swanlab 信息
import os
import gc
import json
import time
import torch
import numpy as np
import swanlab
from peft import LoraConfig, get_peft_model, TaskType, PeftModel
from qwen_vl_utils import process_vision_info
from datasets import Dataset, concatenate_datasets
from transformers import (
TrainingArguments,
Trainer,
DataCollatorForSeq2Seq,
Qwen3VLForConditionalGeneration,
AutoProcessor,
BitsAndBytesConfig
)
from modelscope import snapshot_download, AutoTokenizer
from swanlab.integration.transformers import SwanLabCallback
def create_process_func(processor, tokenizer):
"""创建数据预处理函数的工厂函数"""
def process_func(example):
"""将数据集进行预处理"""
MAX_LENGTH = 8192
conversation = example["conversations"]
input_content = conversation[0]["value"]
output_content = conversation[1]["value"]
file_path = input_content.split("<|vision_start|>")[1].split("<|vision_end|>")[0] # 获取图像路径
# 检查图片是否存在
if not os.path.exists(file_path):
raise FileNotFoundError(f"图片文件不存在: {file_path}")
# 为了结构化标记,需要先规范输入格式
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": f"{file_path}",
"resized_height": 280,
"resized_width": 280,
},
{"type": "text", "text": "COCO Yes:"},
],
}
]
try:
# 将原始对话消息转换为模型特定的格式
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
# 对图像进行预处理(调整尺寸、归一化等)
image_inputs, video_inputs = process_vision_info(messages)
# 最终输入整合
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
# 将PyTorch张量转换为Python列表
inputs = {key: value.tolist() for key, value in inputs.items()}
instruction = inputs
response = tokenizer(f"{output_content}", add_special_tokens=False)
input_ids = (
instruction["input_ids"][0] + response["input_ids"] + [tokenizer.pad_token_id]
)
attention_mask = instruction["attention_mask"][0] + response["attention_mask"] + [1]
labels = (
[-100] * len(instruction["input_ids"][0])
+ response["input_ids"]
+ [tokenizer.pad_token_id]
)
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
input_ids = torch.tensor(input_ids)
attention_mask = torch.tensor(attention_mask)
labels = torch.tensor(labels)
if isinstance(inputs['pixel_values'], list):
inputs['pixel_values'] = torch.tensor(inputs['pixel_values']).to(torch.float16)
else:
inputs['pixel_values'] = inputs['pixel_values'].to(torch.float16)
# inputs['pixel_values'] = torch.tensor(inputs['pixel_values']).to(torch.float16)
inputs['image_grid_thw'] = torch.tensor(inputs['image_grid_thw']).squeeze(0)
# 清理临时变量
del instruction, response
if torch.cuda.is_available():
torch.cuda.empty_cache()
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels,
"pixel_values": inputs['pixel_values'],
"image_grid_thw": inputs['image_grid_thw']
}
except Exception as e:
print(f"处理样本时出错 {file_path}: {e}")
raise e
return process_func
def process_dataset_in_chunks(dataset, processor, tokenizer, chunk_size=200):
"""分块处理数据集以避免内存溢出"""
processed_data = []
total_samples = len(dataset)
# 创建处理函数
process_func = create_process_func(processor, tokenizer)
for i in range(0, total_samples, chunk_size):
end_idx = min(i + chunk_size, total_samples)
chunk = dataset.select(range(i, end_idx))
print(f"处理数据块 {i // chunk_size + 1}/{(total_samples - 1) // chunk_size + 1}: {i}-{end_idx - 1}")
try:
# 处理当前块
processed_chunk = chunk.map(
process_func,
batched=False,
remove_columns=chunk.column_names,
num_proc=2,
writer_batch_size=50
)
processed_data.append(processed_chunk)
# 强制垃圾回收
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
except Exception as e:
print(f"处理数据块 {i}-{end_idx - 1} 时出错: {e}")
if processed_data:
return concatenate_datasets(processed_data)
else:
raise RuntimeError("所有数据块处理都失败")
def dataloader(train_json_path, val_json_path, processor, tokenizer):
# 处理数据集
print("处理训练数据集...")
train_ds = Dataset.from_json(train_json_path)
train_dataset = process_dataset_in_chunks(train_ds, processor, tokenizer, chunk_size=100)
print(f"训练数据集处理完成,最终有 {len(train_dataset)} 条数据")
print("处理验证数据集...")
val_ds = Dataset.from_json(val_json_path)
eval_dataset = process_dataset_in_chunks(val_ds, processor, tokenizer, chunk_size=100)
print(f"验证数据集处理完成,最终有 {len(eval_dataset)} 条数据")
return train_dataset, eval_dataset
def predict(messages, model, processor):
# 准备推理
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 生成输出
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
return output_text[0]
def val(model, lora_path, model_path):
# 获取测试模型
val_peft_model = PeftModel.from_pretrained(model, model_id=lora_path)
# 加载处理器
processor = AutoProcessor.from_pretrained(model_path, use_fast=True)
# swanlab.init(
# project="Qwen3-VL-finetune",
# experiment_name="qwen3-vl-water-level-enhanced",
# description="test",
# )
# 读取测试数据
with open("/home/lijinkui/Documents/code/QwenVL_mini/resource/coco_caption/test.json", "r") as f:
test_dataset = json.load(f)
test_image_list = []
for item in test_dataset:
input_image_prompt = item["conversations"][0]["value"]
# 获取 image path
origin_image_path = input_image_prompt.split("<|vision_start|>")[1].split("<|vision_end|>")[0]
messages = [{
"role": "user",
"content": [
{
"type": "image",
"image": origin_image_path
},
{
"type": "text",
"text": "COCO Yes:"
}
]}]
response = predict(messages, val_peft_model, processor)
messages.append({"role": "assistant", "content": f"{response}"})
print(messages[-1])
test_image_list.append(swanlab.Image(origin_image_path, caption=response))
swanlab.log({"Prediction": test_image_list})
def main():
print("加载模型")
model_path = "./Qwen/Qwen3-VL-2B-Instruct"
output_path = "./output/Qwen3-VL-2B_3000"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
# 加载模型
model = Qwen3VLForConditionalGeneration.from_pretrained(
model_path,
device_map="auto",
quantization_config=bnb_config,
dtype=torch.bfloat16,
# attn_implementation="flash_attention_2"
)
print("加载预处理工具")
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=True)
# 加载处理器
processor = AutoProcessor.from_pretrained(model_path, use_fast=True)
# 允许梯度更新
model.enable_input_require_grads()
print("加载数据集")
train_json_path = "train.json"
val_json_path = "test.json"
train_dataset, eval_dataset = dataloader(train_json_path, val_json_path, processor, tokenizer)
print("配置LoRA...")
config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型为因果语言建模(Causal Language Modeling),适用于GPT等自回归模型。
# Transformer模型中需要应用LoRA的注意力机制和前馈网络层
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False, # 推理模型,训练时设置为False
r=8, # 低秩矩阵的维度, 控制可训练参数数量
lora_alpha=16, # 控制LoRA适配器输出的缩放程度, 推荐为2*r
lora_dropout=0.1, # 适当增加dropout
bias="none",
)
# 获取LoRA模型
peft_model = get_peft_model(model, config)
# 正确获取参数数量
trainable_params = sum(p.numel() for p in peft_model.parameters() if p.requires_grad)
all_params = sum(p.numel() for p in peft_model.parameters())
print(f"LoRA模型参数: 可训练参数 {trainable_params:,}, "
f"总参数 {all_params:,}, "
f"可训练比例 {trainable_params / all_params * 100:.2f}%")
print("配置超参数")
# 优化的训练参数
args = TrainingArguments(
output_dir=output_path,
per_device_train_batch_size=1,
per_device_eval_batch_size=8,
gradient_accumulation_steps=8,
logging_steps=5,
logging_first_step=True,
num_train_epochs=2,
save_steps=20,
eval_steps=20,
# eval_strategy="steps",
learning_rate=1e-5, # 降低学习率
lr_scheduler_type="cosine", # 使用余弦退火
save_strategy="steps",
save_on_each_node=True,
gradient_checkpointing=True,
report_to="tensorboard",
dataloader_pin_memory=True,
dataloader_num_workers=4,
remove_unused_columns=False,
bf16=True,
max_grad_norm=0.5, # 更严格的梯度裁剪
# load_best_model_at_end=True, # 训练结束后加载最优模型
# metric_for_best_model="eval_loss", # 以验证集loss作为最优指标
greater_is_better=False,
save_total_limit=3,
warmup_ratio=0.1, # 增加预热比例
weight_decay=0.02, # 增加正则化
)
# 设置SwanLab回调
swanlab_callback = SwanLabCallback(
project="Qwen3-VL-finetune",
experiment_name="qwen3-vl-2B-coco-3000-transformer"
)
# 配置Trainer
trainer = Trainer(
model=peft_model,
args=args,
train_dataset=train_dataset,
# eval_dataset=eval_dataset,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
callbacks=[swanlab_callback]
)
# 开始训练
print("开始模型训练...")
start = time.time()
print(f"start time: {start}")
trainer.train()
end = time.time()
print(f"end time: {end}")
# print("评估模型...")
# results = trainer.evaluate()
# print(f"评估结果: {results}")
# 保存最终模型
best_lora_weight = f"{output_path}/best_model"
trainer.save_model(best_lora_weight)
print(f"训练完成,最终模型已保存到: {best_lora_weight}")
print(f"耗时: {end-start} s")
# # 模型评估
# val(model, best_lora_weight, model_path)
if __name__ == "__main__":
main()
启动训练
python train.py
加载模型
加载预处理工具
加载数据集
处理训练数据集...
处理数据块 1/24: 0-99
处理数据块 2/24: 100-199
处理数据块 3/24: 200-299
处理数据块 4/24: 300-399
处理数据块 5/24: 400-499
处理数据块 6/24: 500-599
处理数据块 7/24: 600-699
处理数据块 8/24: 700-799
处理数据块 9/24: 800-899
处理数据块 10/24: 900-999
处理数据块 11/24: 1000-1099
处理数据块 12/24: 1100-1199
处理数据块 13/24: 1200-1299
处理数据块 14/24: 1300-1399
处理数据块 15/24: 1400-1499
处理数据块 16/24: 1500-1599
处理数据块 17/24: 1600-1699
处理数据块 18/24: 1700-1799
处理数据块 19/24: 1800-1899
处理数据块 20/24: 1900-1999
处理数据块 21/24: 2000-2099
处理数据块 22/24: 2100-2199
处理数据块 23/24: 2200-2299
处理数据块 24/24: 2300-2399
训练数据集处理完成,最终有 2400 条数据
处理验证数据集...
处理数据块 1/6: 0-99
处理数据块 2/6: 100-199
处理数据块 3/6: 200-299
处理数据块 4/6: 300-399
处理数据块 5/6: 400-499
处理数据块 6/6: 500-599
验证数据集处理完成,最终有 600 条数据
配置LoRA...
LoRA模型参数: 可训练参数 8,716,288, 总参数 1,230,278,656, 可训练比例 0.71%
配置超参数
开始模型训练...
start time: 1770616629.7425504
swanlab: swanlab version 0.7.8 is available! Upgrade: `pip install -U swanlab`
swanlab: Tracking run with swanlab version 0.4.8
swanlab: Run data will be saved locally in /home/lijinkui/Documents/code/QwenVL_mini/Qwen3VL/swanlog/run-20260209_135711-a3b1799d
swanlab: 👋 Hi goldsunshine, welcome to swanlab!
swanlab: Syncing run qwen3-vl-2B-coco-3000-transformer to the cloud
swanlab: 🌟 Run `swanlab watch /home/lijinkui/Documents/code/QwenVL_mini/Qwen3VL/swanlog` to view SwanLab Experiment Dashboard locally
swanlab: 🏠 View project at https://swanlab.cn/@goldsunshine/Qwen3-VL-finetune
swanlab: 🚀 View run at https://swanlab.cn/@goldsunshine/Qwen3-VL-finetune/runs/c9qhpa4dvxpm9h4972x5f
0%| | 0/600 [00:00<?, ?it/s]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
Casting fp32 inputs back to torch.bfloat16 for flash-attn compatibility.
`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.
{'loss': 3.7572, 'grad_norm': 5.832704067230225, 'learning_rate': 0.0, 'epoch': 0.0}
{'loss': 3.9752, 'grad_norm': 5.014480113983154, 'learning_rate': 6.666666666666667e-07, 'epoch': 0.02}
{'loss': 4.0971, 'grad_norm': 5.739471912384033, 'learning_rate': 1.5e-06, 'epoch': 0.03}
{'loss': 3.9509, 'grad_norm': 5.526793956756592, 'learning_rate': 2.3333333333333336e-06, 'epoch': 0.05}
{'loss': 4.0699, 'grad_norm': 4.930661201477051, 'learning_rate': 3.1666666666666667e-06, 'epoch': 0.07}
3%|████████ | 20/600 [00:29<13:40, 1.41s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 3.7622, 'grad_norm': 4.424675464630127, 'learning_rate': 4.000000000000001e-06, 'epoch': 0.08}
{'loss': 3.9772, 'grad_norm': 6.902733325958252, 'learning_rate': 4.833333333333333e-06, 'epoch': 0.1}
5%|████████████▊ | 32/600 [00:47<13:42, 1.45s/it]
{'loss': 3.9729, 'grad_norm': 5.41429328918457, 'learning_rate': 5.666666666666667e-06, 'epoch': 0.12}
{'loss': 3.7364, 'grad_norm': 6.195461750030518, 'learning_rate': 6.5000000000000004e-06, 'epoch': 0.13}
7%|████████████████ | 40/600 [00:58<14:03, 1.51s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 3.7806, 'grad_norm': 5.073212146759033, 'learning_rate': 7.333333333333333e-06, 'epoch': 0.15}
{'loss': 3.5278, 'grad_norm': 5.07866907119751, 'learning_rate': 8.166666666666668e-06, 'epoch': 0.17}
{'loss': 3.4849, 'grad_norm': 4.560025691986084, 'learning_rate': 9e-06, 'epoch': 0.18}
{'loss': 3.4707, 'grad_norm': 5.399397850036621, 'learning_rate': 9.833333333333333e-06, 'epoch': 0.2}
10%|████████████████████████ | 60/600 [01:29<13:24, 1.49s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 3.0381, 'grad_norm': 3.3714683055877686, 'learning_rate': 9.99864620589731e-06, 'epoch': 0.22}
{'loss': 3.0731, 'grad_norm': 3.8705101013183594, 'learning_rate': 9.993147673772869e-06, 'epoch': 0.23}
{'loss': 3.0153, 'grad_norm': 3.9309475421905518, 'learning_rate': 9.98342444022253e-06, 'epoch': 0.25}
{'loss': 2.7767, 'grad_norm': 3.157742500305176, 'learning_rate': 9.9694847320726e-06, 'epoch': 0.27}
13%|████████████████████████████████ | 80/600 [01:59<12:54, 1.49s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 2.6391, 'grad_norm': 3.163109064102173, 'learning_rate': 9.951340343707852e-06, 'epoch': 0.28}
{'loss': 2.5108, 'grad_norm': 3.397581100463867, 'learning_rate': 9.929006627092298e-06, 'epoch': 0.3}
{'loss': 2.6338, 'grad_norm': 3.0808489322662354, 'learning_rate': 9.902502478779897e-06, 'epoch': 0.32}
{'loss': 2.3545, 'grad_norm': 3.3066928386688232, 'learning_rate': 9.871850323926178e-06, 'epoch': 0.33}
17%|███████████████████████████████████████▊ | 100/600 [02:29<12:32, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 2.3455, 'grad_norm': 3.304772138595581, 'learning_rate': 9.83707609731432e-06, 'epoch': 0.35}
{'loss': 2.2901, 'grad_norm': 3.864600419998169, 'learning_rate': 9.798209221411748e-06, 'epoch': 0.37}
{'loss': 2.3544, 'grad_norm': 3.7856407165527344, 'learning_rate': 9.755282581475769e-06, 'epoch': 0.38}
{'loss': 2.0384, 'grad_norm': 3.458643674850464, 'learning_rate': 9.708332497729378e-06, 'epoch': 0.4}
20%|███████████████████████████████████████████████▊ | 120/600 [03:00<11:58, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 2.1113, 'grad_norm': 3.314185380935669, 'learning_rate': 9.657398694630713e-06, 'epoch': 0.42}
{'loss': 1.9019, 'grad_norm': 2.51772141456604, 'learning_rate': 9.602524267262202e-06, 'epoch': 0.43}
{'loss': 1.7758, 'grad_norm': 3.113595485687256, 'learning_rate': 9.543755644867823e-06, 'epoch': 0.45}
{'loss': 1.7463, 'grad_norm': 3.2002460956573486, 'learning_rate': 9.481142551569318e-06, 'epoch': 0.47}
23%|███████████████████████████████████████████████████████▊ | 140/600 [03:30<11:28, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7432, 'grad_norm': 3.075195074081421, 'learning_rate': 9.414737964294636e-06, 'epoch': 0.48}
{'loss': 1.8794, 'grad_norm': 3.2397301197052, 'learning_rate': 9.344598067954151e-06, 'epoch': 0.5}
{'loss': 1.9633, 'grad_norm': 2.6766655445098877, 'learning_rate': 9.27078220790263e-06, 'epoch': 0.52}
{'loss': 1.7057, 'grad_norm': 2.0661988258361816, 'learning_rate': 9.193352839727122e-06, 'epoch': 0.53}
27%|███████████████████████████████████████████████████████████████▋ | 160/600 [04:00<11:15, 1.53s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7554, 'grad_norm': 2.4337100982666016, 'learning_rate': 9.112375476403313e-06, 'epoch': 0.55}
{'loss': 1.8648, 'grad_norm': 2.604933500289917, 'learning_rate': 9.027918632864998e-06, 'epoch': 0.57}
{'loss': 1.6409, 'grad_norm': 2.2189531326293945, 'learning_rate': 8.94005376803361e-06, 'epoch': 0.58}
{'loss': 1.8388, 'grad_norm': 2.6021835803985596, 'learning_rate': 8.84885522435684e-06, 'epoch': 0.6}
30%|███████████████████████████████████████████████████████████████████████▋ | 180/600 [04:31<10:29, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7599, 'grad_norm': 3.2321550846099854, 'learning_rate': 8.754400164907496e-06, 'epoch': 0.62}
{'loss': 1.8179, 'grad_norm': 2.5734636783599854, 'learning_rate': 8.656768508095853e-06, 'epoch': 0.63}
{'loss': 1.9281, 'grad_norm': 2.53546142578125, 'learning_rate': 8.556042860050686e-06, 'epoch': 0.65}
{'loss': 1.8855, 'grad_norm': 2.7848012447357178, 'learning_rate': 8.452308444726249e-06, 'epoch': 0.67}
33%|███████████████████████████████████████████████████████████████████████████████▋ | 200/600 [05:01<10:02, 1.51s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.8509, 'grad_norm': 2.791349172592163, 'learning_rate': 8.345653031794292e-06, 'epoch': 0.68}
{'loss': 1.9066, 'grad_norm': 3.0583624839782715, 'learning_rate': 8.236166862382163e-06, 'epoch': 0.7}
{'loss': 1.742, 'grad_norm': 3.142404794692993, 'learning_rate': 8.123942572719801e-06, 'epoch': 0.72}
{'loss': 1.8294, 'grad_norm': 2.673813581466675, 'learning_rate': 8.009075115760243e-06, 'epoch': 0.73}
37%|███████████████████████████████████████████████████████████████████████████████████████▋ | 220/600 [05:31<09:31, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.685, 'grad_norm': 2.668875217437744, 'learning_rate': 7.891661680839932e-06, 'epoch': 0.75}
{'loss': 1.7252, 'grad_norm': 3.5572149753570557, 'learning_rate': 7.771801611446859e-06, 'epoch': 0.77}
{'loss': 1.761, 'grad_norm': 2.754807949066162, 'learning_rate': 7.649596321166024e-06, 'epoch': 0.78}
{'loss': 1.5887, 'grad_norm': 3.0725083351135254, 'learning_rate': 7.5251492078734515e-06, 'epoch': 0.8}
40%|███████████████████████████████████████████████████████████████████████████████████████████████▌ | 240/600 [06:00<08:43, 1.45s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7326, 'grad_norm': 2.860182762145996, 'learning_rate': 7.398565566251232e-06, 'epoch': 0.82}
{'loss': 1.8135, 'grad_norm': 2.5170743465423584, 'learning_rate': 7.269952498697734e-06, 'epoch': 0.83}
{'loss': 1.6632, 'grad_norm': 2.358067750930786, 'learning_rate': 7.1394188247082715e-06, 'epoch': 0.85}
{'loss': 1.7708, 'grad_norm': 2.594930410385132, 'learning_rate': 7.007074988802946e-06, 'epoch': 0.87}
43%|███████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 260/600 [06:30<08:30, 1.50s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.582, 'grad_norm': 2.139220714569092, 'learning_rate': 6.873032967079562e-06, 'epoch': 0.88}
{'loss': 1.5848, 'grad_norm': 2.3312747478485107, 'learning_rate': 6.737406172470657e-06, 'epoch': 0.9}
{'loss': 1.818, 'grad_norm': 2.643909215927124, 'learning_rate': 6.600309358784858e-06, 'epoch': 0.92}
{'loss': 1.9322, 'grad_norm': 2.6459555625915527, 'learning_rate': 6.461858523613684e-06, 'epoch': 0.93}
47%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 280/600 [06:59<07:18, 1.37s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.5393, 'grad_norm': 2.826198101043701, 'learning_rate': 6.322170810186013e-06, 'epoch': 0.95}
{'loss': 1.8932, 'grad_norm': 2.784982204437256, 'learning_rate': 6.181364408253209e-06, 'epoch': 0.97}
{'loss': 1.8126, 'grad_norm': 2.737072706222534, 'learning_rate': 6.039558454088796e-06, 'epoch': 0.98}
{'loss': 1.8351, 'grad_norm': 2.618182420730591, 'learning_rate': 5.896872929687287e-06, 'epoch': 1.0}
50%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 300/600 [07:27<06:53, 1.38s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.8525, 'grad_norm': 2.426217794418335, 'learning_rate': 5.753428561247416e-06, 'epoch': 1.02}
{'loss': 1.7577, 'grad_norm': 2.7349295616149902, 'learning_rate': 5.609346717025738e-06, 'epoch': 1.03}
{'loss': 1.585, 'grad_norm': 3.2066996097564697, 'learning_rate': 5.464749304646963e-06, 'epoch': 1.05}
{'loss': 1.6531, 'grad_norm': 2.8371496200561523, 'learning_rate': 5.319758667957929e-06, 'epoch': 1.07}
53%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 320/600 [07:57<06:43, 1.44s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.8875, 'grad_norm': 2.7357017993927, 'learning_rate': 5.174497483512506e-06, 'epoch': 1.08}
{'loss': 1.7317, 'grad_norm': 2.947751522064209, 'learning_rate': 5.02908865677497e-06, 'epoch': 1.1}
{'loss': 1.8939, 'grad_norm': 3.059084892272949, 'learning_rate': 4.883655218129719e-06, 'epoch': 1.12}
{'loss': 1.6061, 'grad_norm': 2.2707314491271973, 'learning_rate': 4.738320218785281e-06, 'epoch': 1.13}
57%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 340/600 [08:26<06:23, 1.48s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6764, 'grad_norm': 2.266660451889038, 'learning_rate': 4.59320662666071e-06, 'epoch': 1.15}
{'loss': 1.7755, 'grad_norm': 2.440293788909912, 'learning_rate': 4.448437222342441e-06, 'epoch': 1.17}
{'loss': 1.7416, 'grad_norm': 3.2049639225006104, 'learning_rate': 4.304134495199675e-06, 'epoch': 1.18}
{'loss': 1.7171, 'grad_norm': 2.971813917160034, 'learning_rate': 4.160420539746115e-06, 'epoch': 1.2}
60%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 360/600 [08:55<05:51, 1.47s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6068, 'grad_norm': 2.6754987239837646, 'learning_rate': 4.017416952335849e-06, 'epoch': 1.22}
{'loss': 1.7867, 'grad_norm': 4.011244773864746, 'learning_rate': 3.875244728280676e-06, 'epoch': 1.23}
{'loss': 1.7116, 'grad_norm': 2.0869648456573486, 'learning_rate': 3.7340241594759917e-06, 'epoch': 1.25}
{'loss': 1.5978, 'grad_norm': 2.0922114849090576, 'learning_rate': 3.593874732621847e-06, 'epoch': 1.27}
63%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 380/600 [09:25<05:28, 1.49s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7453, 'grad_norm': 2.761500597000122, 'learning_rate': 3.4549150281252635e-06, 'epoch': 1.28}
{'loss': 1.8881, 'grad_norm': 2.7363357543945312, 'learning_rate': 3.317262619769368e-06, 'epoch': 1.3}
{'loss': 1.7212, 'grad_norm': 2.6628267765045166, 'learning_rate': 3.1810339752342446e-06, 'epoch': 1.32}
{'loss': 1.8939, 'grad_norm': 2.7486565113067627, 'learning_rate': 3.0463443575536324e-06, 'epoch': 1.33}
67%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 400/600 [09:55<05:03, 1.52s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6466, 'grad_norm': 2.092799663543701, 'learning_rate': 2.9133077275909112e-06, 'epoch': 1.35}
{'loss': 1.8387, 'grad_norm': 2.8970038890838623, 'learning_rate': 2.7820366476168224e-06, 'epoch': 1.37}
{'loss': 1.7462, 'grad_norm': 3.403714179992676, 'learning_rate': 2.6526421860705474e-06, 'epoch': 1.38}
{'loss': 1.7736, 'grad_norm': 2.4016144275665283, 'learning_rate': 2.52523382358473e-06, 'epoch': 1.4}
70%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 420/600 [10:24<04:13, 1.41s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.8141, 'grad_norm': 2.872958183288574, 'learning_rate': 2.3999193603539234e-06, 'epoch': 1.42}
{'loss': 1.8813, 'grad_norm': 2.5456526279449463, 'learning_rate': 2.2768048249248648e-06, 'epoch': 1.43}
{'loss': 1.5838, 'grad_norm': 2.2993099689483643, 'learning_rate': 2.155994384485742e-06, 'epoch': 1.45}
{'loss': 1.808, 'grad_norm': 2.847153902053833, 'learning_rate': 2.0375902567303474e-06, 'epoch': 1.47}
73%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 440/600 [10:52<03:44, 1.40s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7878, 'grad_norm': 3.1877455711364746, 'learning_rate': 1.9216926233717087e-06, 'epoch': 1.48}
{'loss': 1.8152, 'grad_norm': 2.198204278945923, 'learning_rate': 1.8083995453783604e-06, 'epoch': 1.5}
{'loss': 1.5942, 'grad_norm': 2.952796697616577, 'learning_rate': 1.6978068800049624e-06, 'epoch': 1.52}
{'loss': 1.7477, 'grad_norm': 2.5162291526794434, 'learning_rate': 1.5900081996875083e-06, 'epoch': 1.53}
77%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 460/600 [11:20<03:20, 1.43s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6721, 'grad_norm': 3.454312562942505, 'learning_rate': 1.4850947128716914e-06, 'epoch': 1.55}
{'loss': 1.7207, 'grad_norm': 2.687739133834839, 'learning_rate': 1.38315518684146e-06, 'epoch': 1.57}
{'loss': 1.8274, 'grad_norm': 2.9658989906311035, 'learning_rate': 1.2842758726130283e-06, 'epoch': 1.58}
{'loss': 1.6113, 'grad_norm': 2.9206314086914062, 'learning_rate': 1.1885404319579108e-06, 'epoch': 1.6}
80%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 480/600 [11:51<03:04, 1.54s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.5999, 'grad_norm': 2.6534855365753174, 'learning_rate': 1.096029866616704e-06, 'epoch': 1.62}
{'loss': 1.5678, 'grad_norm': 2.1162548065185547, 'learning_rate': 1.006822449763537e-06, 'epoch': 1.63}
{'loss': 1.678, 'grad_norm': 2.9362614154815674, 'learning_rate': 9.209936597791407e-07, 'epoch': 1.65}
{'loss': 1.6867, 'grad_norm': 2.5584628582000732, 'learning_rate': 8.38616116388612e-07, 'epoch': 1.67}
83%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 500/600 [12:21<02:27, 1.48s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.4731, 'grad_norm': 2.393000602722168, 'learning_rate': 7.597595192178702e-07, 'epoch': 1.68}
{'loss': 1.7319, 'grad_norm': 2.1838290691375732, 'learning_rate': 6.84490588820818e-07, 'epoch': 1.7}
{'loss': 1.8493, 'grad_norm': 3.130202531814575, 'learning_rate': 6.128730102270897e-07, 'epoch': 1.72}
{'loss': 1.7278, 'grad_norm': 2.7917497158050537, 'learning_rate': 5.449673790581611e-07, 'epoch': 1.73}
87%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 520/600 [12:57<02:30, 1.88s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7285, 'grad_norm': 2.7501380443573, 'learning_rate': 4.808311502573976e-07, 'epoch': 1.75}
{'loss': 1.675, 'grad_norm': 2.702840566635132, 'learning_rate': 4.205185894774455e-07, 'epoch': 1.77}
{'loss': 1.7593, 'grad_norm': 2.8464746475219727, 'learning_rate': 3.6408072716606346e-07, 'epoch': 1.78}
{'loss': 1.7379, 'grad_norm': 2.812981367111206, 'learning_rate': 3.1156531538927615e-07, 'epoch': 1.8}
90%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 540/600 [13:36<01:57, 1.96s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.7719, 'grad_norm': 2.5678024291992188, 'learning_rate': 2.63016787428354e-07, 'epoch': 1.82}
{'loss': 1.6631, 'grad_norm': 2.303229808807373, 'learning_rate': 2.1847622018482283e-07, 'epoch': 1.83}
{'loss': 1.5365, 'grad_norm': 2.8423118591308594, 'learning_rate': 1.779812994253055e-07, 'epoch': 1.85}
{'loss': 1.779, 'grad_norm': 2.650094509124756, 'learning_rate': 1.4156628789559924e-07, 'epoch': 1.87}
93%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 560/600 [14:16<01:19, 1.98s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6596, 'grad_norm': 2.35098934173584, 'learning_rate': 1.0926199633097156e-07, 'epoch': 1.88}
{'loss': 1.6726, 'grad_norm': 2.7792632579803467, 'learning_rate': 8.109575738720621e-08, 'epoch': 1.9}
{'loss': 1.5539, 'grad_norm': 2.1199231147766113, 'learning_rate': 5.709140251444201e-08, 'epoch': 1.92}
{'loss': 1.8248, 'grad_norm': 2.5113015174865723, 'learning_rate': 3.726924179339009e-08, 'epoch': 1.93}
97%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 580/600 [14:56<00:39, 1.98s/it]/home/lijinkui/miniconda3/envs/lora/lib/python3.10/site-packages/torch/utils/checkpoint.py:85: UserWarning: None of the inputs have requires_grad=True. Gradients will be None
warnings.warn(
{'loss': 1.6467, 'grad_norm': 2.724944591522217, 'learning_rate': 2.1646046750978255e-08, 'epoch': 1.95}
{'loss': 1.737, 'grad_norm': 2.559987783432007, 'learning_rate': 1.0235036169963241e-08, 'epoch': 1.97}
{'loss': 1.7472, 'grad_norm': 2.554819107055664, 'learning_rate': 3.0458649045211897e-09, 'epoch': 1.98}
{'loss': 1.7698, 'grad_norm': 2.3446872234344482, 'learning_rate': 8.461571127882373e-11, 'epoch': 2.0}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 600/600 [15:36<00:00, 1.99s/it]swanlab: Step 600 on key train/epoch already exists, ignored.
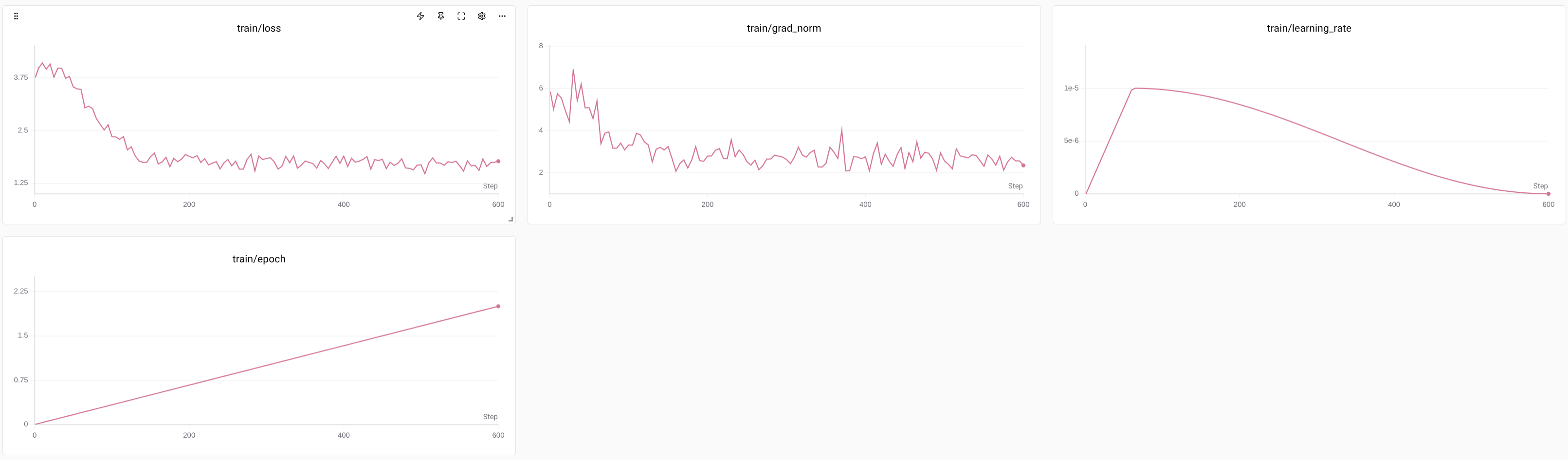
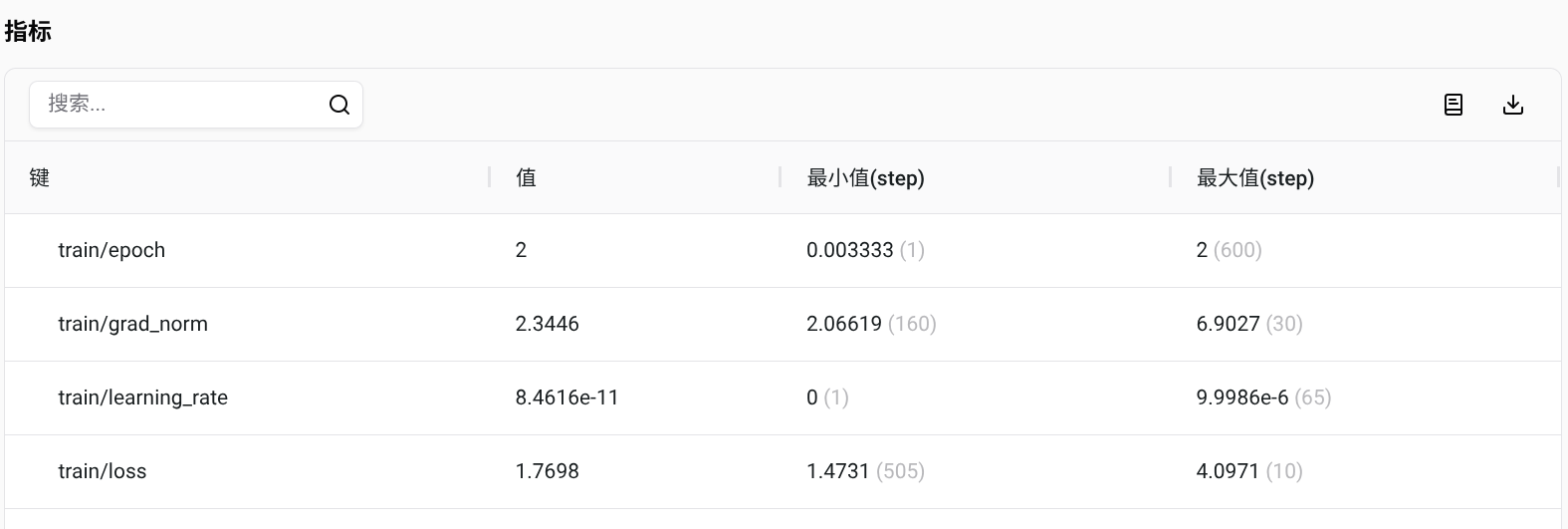
{'train_runtime': 939.312, 'train_samples_per_second': 5.11, 'train_steps_per_second': 0.639, 'train_loss': 2.037434497276942, 'epoch': 2.0}
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 600/600 [15:36<00:00, 1.56s/it]
end time: 1770617569.1923273
训练完成,最终模型已保存到: ./output/Qwen3-VL-2B_3000/best_model
耗时: 939.4497768878937 s
swanlab: Experiment qwen3-vl-2B-coco-3000-transformer has completed
swanlab: 🌟 Run `swanlab watch /home/lijinkui/Documents/code/QwenVL_mini/Qwen3VL/swanlog` to view SwanLab Experiment Dashboard locally
swanlab: 🏠 View project at https://swanlab.cn/@goldsunshine/Qwen3-VL-finetune
swanlab: 🚀 View run at https://swanlab.cn/@goldsunshine/Qwen3-VL-finetune/runs/c9qhpa4dvxpm9h4972x5f
训练过程

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)