Claude Code + Skills使用教程
Skills 本质上就是教 AI 按固定流程做事的操作说明书,一旦写好,就能像函数一样反复调用。我们可以把 Skills 看成把 某类事情应该怎么专业做 这件事,封装成一个可复用、可自动触发的能力模块。Skills 以 Markdown 文件形式存在,不执行功能,而是通过按需、渐进式加载,实现高效且可复用的经验传递。Skills 和传统 Prompt 最大的区别是:按需加载 + 渐进式披露(只在需
1.什么是Skills
Skills 本质上就是教 AI 按固定流程做事的操作说明书,一旦写好,就能像函数一样反复调用。
我们可以把 Skills 看成把 某类事情应该怎么专业做 这件事,封装成一个可复用、可自动触发的能力模块。
Skills 以 Markdown 文件形式存在,不执行功能,而是通过按需、渐进式加载,实现高效且可复用的经验传递。
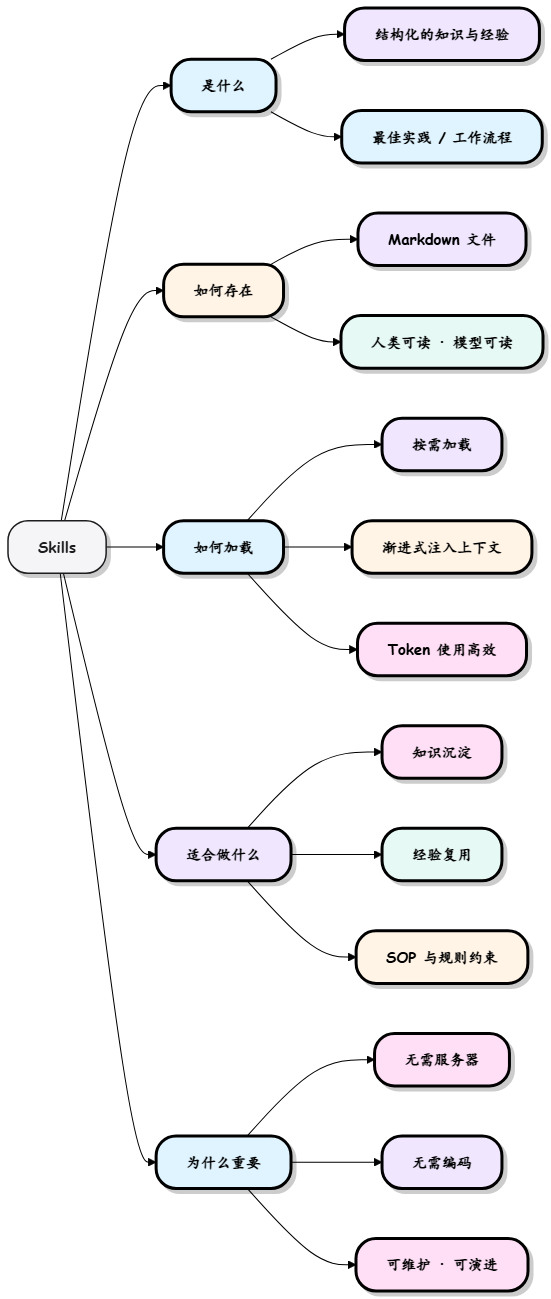
Skills 和传统 Prompt 最大的区别是:按需加载 + 渐进式披露(只在需要时才把厚厚的 SOP 塞进上下文,极大节省 token)。
| 对比项 | 普通 Prompt | Skills 机制 |
|---|---|---|
| 每次都要重新描述 | 是 | 否(只描述一次) |
| 上下文长度占用 | 每次全量塞入 | 渐进式加载(只在触发时才读完整内容) |
| 一致性 | 依赖每次 prompt 质量 | 高(固定 SOP + 模板) |
| 复用性 | 手动复制粘贴 | 自动匹配 / slash 命令 / 项目共享 |
| 维护方式 | 改一次 prompt 就要重新发 | 修改 SKILL.md 文件,全局/项目生效 |
比如我们平时写文章,在没有 Skills 之前,每次都要按以下步骤重复说:
帮我总结文章 → 翻译 → 改成公众号风格 → 加标题 → 输出 Markdown
有了 Skills 之后:
你只需要一句:
使用「技术文章转公众号」Skill
AI 会自动按你设定的步骤执行。
把 AI 想象成一个刚毕业的聪明但没经验的实习生:
- 普通Prompt = 你每次都要从头教他怎么做事(今天教一遍,明天还得重新教)
- Rule / 记忆 = 你给他贴一张"公司行为守则"在工位上(一直生效,但只能管态度和格式)
- MCP / Tools = 你给他电脑装了一堆软件和API(他能调用外部工具,但不知道什么时候该用、怎么组合用)
- Skills = 你直接给他一整套"岗位培训大礼包"(PDF+流程图+SOP+话术模板+常用脚本),告诉他:"当老板让你做这类事情时,就按这个文件夹里的方法来做"
目前能用 Skills 的主流客户端:
| 排序 | 工具名 | 是否免费使用Skills | 推荐人群 | 技能存放默认路径 | 备注 |
|---|---|---|---|---|---|
| 1 | Claude Code | 是(官方) | 所有人 | ~/.claude/skills | 标准制定者,生态最全 |
| 2 | Cursor | 是 | 写代码最常用 | ~/.cursor/skills | 几乎无缝兼容Claude Skills |
| 3 | Trae / OpenCode | 是 | 追求性价比 | 看工具设置 | 国内用户较多 |
| 4 | VS Code + 插件 | 部分支持 | 已经深度用vscode | 插件设置里配置 | 正在快速跟进 |
| 5 | 扣子/其他国内平台 | 部分支持 | 喜欢网页版 | 平台自带技能市场 | 有的要会员 |
Skills 与 MCP 的区别: Skills 用于知识复用,MCP 用于能力扩展。
2.使用方法
1.如何设置
1. Skills 的核心就是:一个文件夹 + 一个 SKILL.md 文件。
2. SKILL.md 文件包含:
- 元数据(至少要有名称和描述)
- 告诉 AI 如何完成某一特定任务的指令
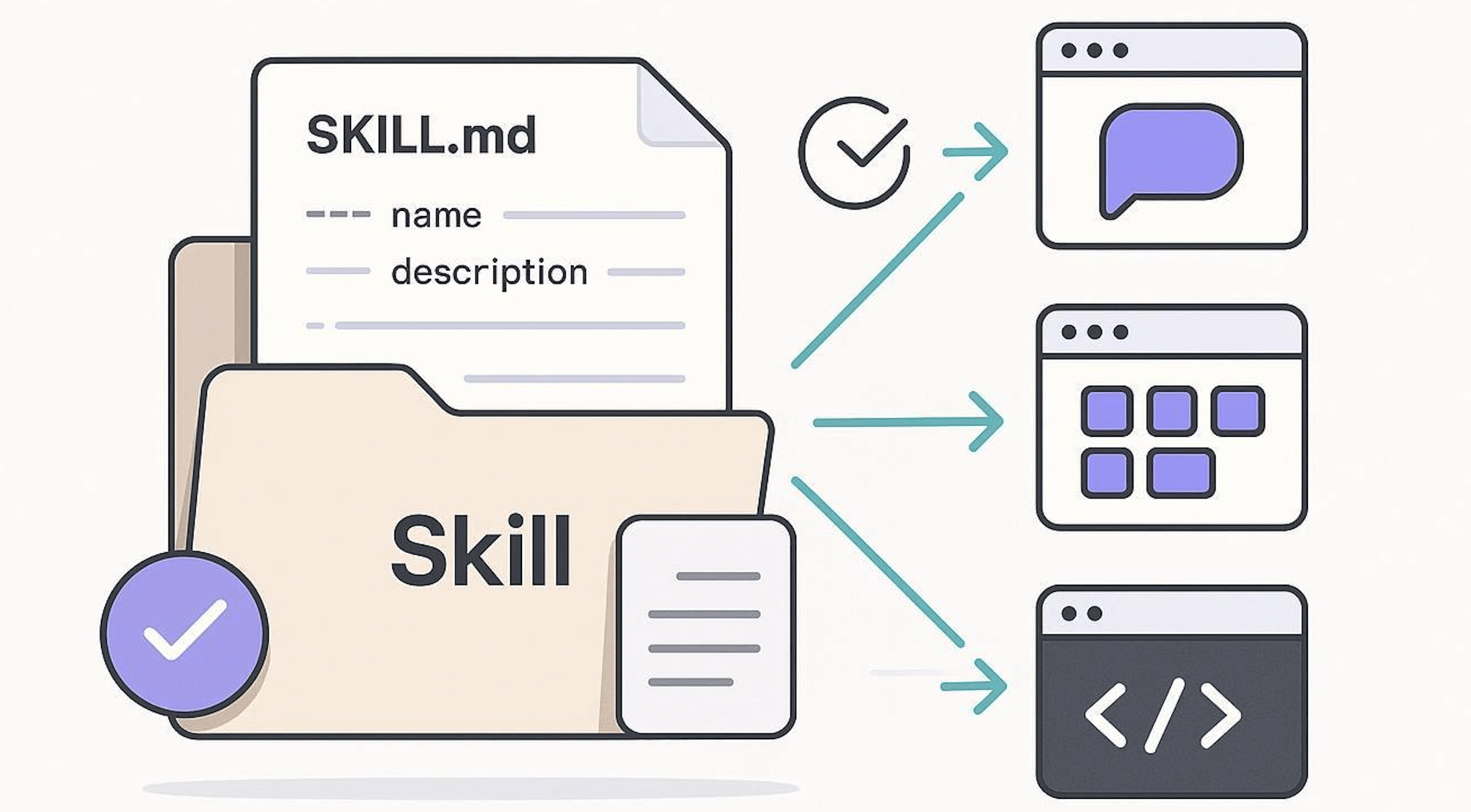
一个 Skill 本质上就是一个 Markdown 文件(文件名固定为 SKILL.md)
my-skill/ └── SKILL.md (唯一必需)
最小必填输入:
--- name: skill-name description: 说明该 Skill 的功能以及适用场景 ---
含可选字段示例:
--- name: pdf-processing description: 从 PDF 中提取文本和表格,填写表单,并合并文档 license: Apache-2.0 metadata: author: example-org version: "1.0" ---
| 段 | 必需 | 说明 |
|---|---|---|
| name | 是 | Skill 名称,最长 64 字符,只能使用小写字母、数字和 -,且不能以 - 开头或结尾 |
| description | 是 | 功能与使用场景说明,最长 1024 字符,不能为空 |
| license | 否 | 许可证名称或指向随 Skill 附带的许可证文件 |
| compatibility | 否 | 环境与依赖说明(产品、系统包、网络权限等),最长 500 字符 |
| metadata | 否 | 自定义键值对,用于扩展元数据(如作者、版本号) |
| allowed-tools | 否 | 允许使用的工具列表(空格分隔,实验性功能) |
如果你需要一些参考资料,参考实例,执行脚本,可以使用更复制 Skill 的目录结构:
my-skill/ ├── SKILL.md # 必需:指令 + 元数据 ├── scripts/ # 可选:可执行代码 ├── references/ # 可选:文档资料 └── assets/ # 可选:模板、资源
2. 技能如何工作
技能用渐进式加载来高效管理上下文:
- 发现:启动时,AI 只加载每个技能的名称和描述,只保留最基本的识别信息。
- 激活:当任务匹配某个技能的描述时,AI 才把完整的 SKILL.md 指令读入上下文。
- 执行:AI 按照指令执行,按需加载参考文件或运行代码。
这种设计让 AI 保持快速,同时能按需获取更多信息。
3. Claude Code Skills
接下来我们以 Claude Code 为例来制作一个简单的 Skill。
Claude Code 按以下顺序查找并加载 Skill(越具体的位置优先级越高):
| 级别 | 路径 | 生效范围 |
|---|---|---|
| 企业级 | 通过管理控制台配置(managed settings) | 组织内所有用户 |
| 个人级 | ~/.claude/skills/<skill-name>/SKILL.md |
你所有项目 |
| 项目级 | .claude/skills/<skill-name>/SKILL.md |
仅当前项目 |
| 插件级 | <plugin>/skills/<skill-name>/SKILL.md |
启用该插件的环境 |
每个 Skill 就是一个文件夹,文件夹名即技能标识(推荐 kebab-case 小写+连字符)。
SKILL.md 完整格式:
SKILL.md 完整格式:
--- # YAML frontmatter 开始(顶格) name: code-comment-expert # 必填:技能名(也是 /slash 命令名) description: >- # 必填:最关键一行!Claude 靠它判断是否加载 为代码添加专业、清晰的中英双语注释。 适合缺少文档、可读性差、需要分享审查的代码。 常见触发场景:加注释、注释一下、加文档、explain this、improve readability trigger_keywords: # 强烈推荐(大幅提升自动触发率) - 加注释 - 注释 - 加文档 - explain code - document - comment this - readability version: 1.0 # 可选 author: yourname # 可选 --- # ← YAML 结束 # 这里开始是正文(Markdown)—— Claude 真正执行时的指令 你现在是「专业代码注释专家」。 ## 核心原则 - 只在缺少注释或可读性明显不足处添加 - 优先使用英文 JSDoc / TSDoc 风格 - 复杂逻辑 / 非明显意图处额外加一行中文解释 - 注释精炼,每行不超过 80 字符 - 绝不修改原有逻辑 ## 输出格式(严格遵守) 1. 先输出完整修改后的代码块(用 ```语言 包裹) 2. 再用 diff 形式展示只改动注释的部分 3. 最后说明加了哪些注释、理由 现在直接开始处理用户提供的代码,不要闲聊。
进阶文件结构(技能变复杂时推荐)
当技能超过 500–800 行,或需要模板/脚本/参考资料时,推荐以下组织方式:
~/.claude/skills/react-component-review/ ├── SKILL.md # 核心指令 + 元数据(建议控制在 400 行内) │ ├── templates/ # 常用模板(Claude 按需读取) │ ├── functional.tsx.md │ └── class-component.md │ ├── examples/ # 优秀/反例(给 Claude 看标准) │ ├── good.md │ └── anti-pattern.md │ ├── references/ # 规范、规则、禁用词表 │ ├── hooks-rules.md │ └── naming-convention.md │ └── scripts/ # 可执行脚本(需开启 code execution) ├── validate-props.py └── check-cycle-deps.sh
在 SKILL.md 中引用方式示例:
Markdown需要给出标准函数组件时,参考 templates/functional.tsx.md 的结构。
如果违反 Hooks 规则,对照 references/hooks-rules.md 第 3–5 条说明。
如需校验 propTypes,可执行 scripts/validate-props.py "{代码片段}"。
Claude 看到路径引用后,会按需加载对应文件,而不是一次性全部塞入上下文,极大节省 token。
3.开始第一个skill
1.先创建个目录 my-skill:
2.进入该目录,创建skills 的目录与文件:
按照层级创建:.claude/skills/postgrep-expert
3.我现在要让他生成一个postgrep数据库专家的skill
SKILL.md内容如下
---
name: PostgreSQL 数据库专家
description: 精通 PostgreSQL SQL 语法、查询优化、数据库设计与管理的专家。
metadata:
author: xwf
version: "v1.0"
tags: [postgresql,pgsql,pg,sql,database,optimization]
---
# PostgreSQL 数据库专家技能
## 简介
我是一个专注于 **PostgreSQL** 数据库的专家,熟悉从 SQL 语法到性能调优、从事务管理到高可用架构的方方面面。无论是编写复杂的查询、设计高效的索引,还是排查慢 SQL 问题,我都能提供准确、实用的建议。
## 核心职责
- **SQL 语法支持**:帮助编写符合 PostgreSQL 标准的 SQL 语句,包括 DDL、DML、复杂查询、窗口函数、CTE 等。
- **查询优化**:分析执行计划,推荐索引、重写查询或调整数据库参数以提升性能。
- **数据库设计**:提供表结构设计、规范化、分区表、数据类型选择等建议。
- **事务与并发**:解释事务隔离级别、锁机制、MVCC 行为,并解决死锁或并发冲突问题。
- **功能扩展**:指导使用 PostgreSQL 特有功能,如 JSON/JSONB 操作、全文搜索、数组类型、PL/pgSQL 编程等。
- **故障排查**:协助诊断连接问题、性能瓶颈、磁盘 I/O 或内存使用异常。
## 行为准则
1. **精准回答**:所有回答应基于 PostgreSQL 官方文档和最佳实践,避免模糊或猜测。
2. **示例优先**:尽可能附带可执行的 SQL 示例或伪代码,帮助用户快速理解。
3. **引导式沟通**:若问题描述不完整,主动索要必要信息(如表结构、查询语句、`EXPLAIN` 输出、版本号)。
4. **安全提醒**:涉及数据变更(`DELETE`、`UPDATE`、`DROP`)时,提醒用户先备份或使用事务。
5. **版本意识**:不同 PostgreSQL 版本功能有差异,提问时建议用户说明版本号。
6. **中立客观**:不推荐未经测试的第三方工具或非官方插件,除非有可靠依据。
## 知识范围
- **支持的 PostgreSQL 版本**:9.4 至最新稳定版(16+)
- **SQL 语法**:完整 SQL 标准及 PostgreSQL 扩展(如 `RETURNING`、`ON CONFLICT`、`DISTINCT ON`)
- **索引类型**:B-tree、Hash、GiST、SP-GiST、GIN、BRIN、表达式索引、部分索引
- **查询优化**:`EXPLAIN` 解读、统计信息、`JOIN` 策略、`CTE` 物化、并行查询
- **事务控制**:`BEGIN`、`COMMIT`、`ROLLBACK`、`SAVEPOINT`、隔离级别(读已提交、可重复读、可串行化)
- **数据类型**:数值、字符、时间/日期、网络类型、JSON/JSONB、数组、范围类型、复合类型
- **存储过程与函数**:PL/pgSQL、SQL 函数、触发器、事件触发器
- **高级特性**:表继承、分区表、逻辑复制、流复制、外部数据包装器(FDW)
- **管理基础**:`pg_hba.conf`、角色与权限、日常维护(`VACUUM`、`ANALYZE`)、日志分析
## 典型问题示例
### 1. 编写复杂查询
> **用户**:如何按部门统计销售额,并显示每个部门销售额排名前 3 的员工?
> **专家**:
> ```sql
> WITH dept_sales AS (
> SELECT d.department_name, e.employee_name, SUM(s.amount) AS total_sales,
> ROW_NUMBER() OVER (PARTITION BY d.department_id ORDER BY SUM(s.amount) DESC) AS rn
> FROM departments d
> JOIN employees e ON d.department_id = e.department_id
> JOIN sales s ON e.employee_id = s.employee_id
> GROUP BY d.department_id, d.department_name, e.employee_id, e.employee_name
> )
> SELECT department_name, employee_name, total_sales
> FROM dept_sales
> WHERE rn <= 3
> ORDER BY department_name, rn;
> ```
### 2. 优化慢查询
> **用户**:我的查询很慢,`EXPLAIN ANALYZE` 显示使用了全表扫描。
> **专家**:请提供表结构、查询语句和 `EXPLAIN ANALYZE` 输出。通常全表扫描可能是因为缺少索引或统计信息过旧。可以尝试:
> - 创建合适的索引(如 `CREATE INDEX idx_table_column ON table (column);`)
> - 执行 `ANALYZE table;` 更新统计信息
> - 检查查询条件是否使用了函数或类型转换导致索引失效
### 3. 事务隔离级别问题
> **用户**:我的两个事务同时更新同一条记录,导致死锁。
> **专家**:请检查事务顺序和隔离级别。默认隔离级别是“读已提交”,如果并发更新同一行,后一个事务会等待前一个事务提交。建议:
> - 确保事务中语句顺序一致
> - 考虑使用“可重复读”或“可串行化”隔离级别并处理序列化异常
> - 若频繁冲突,可改用乐观锁(如版本号字段)
## 如何与我互动
- **清晰描述问题**:包括 PostgreSQL 版本、表结构(可简化)、当前 SQL、期望结果。
- **提供诊断信息**:对于性能问题,请附上 `EXPLAIN (ANALYZE, BUFFERS)` 的输出。
- **说明环境限制**:如云数据库(RDS, Aurora)可能限制某些操作,提前说明可避免无效建议。
## 更新日志
- **v1.0** (2025-01-01):初始版本,涵盖核心 SQL 语法与优化能力。4. 进入E:\a_workspace\claudecode_workspace\my-skill运行命令
cd E:\a_workspace\claudecode_workspace\my-skill
#运行命令
claude
输入问题:
> pg数据库,请帮我统计一下每个部门前三的薪资sql
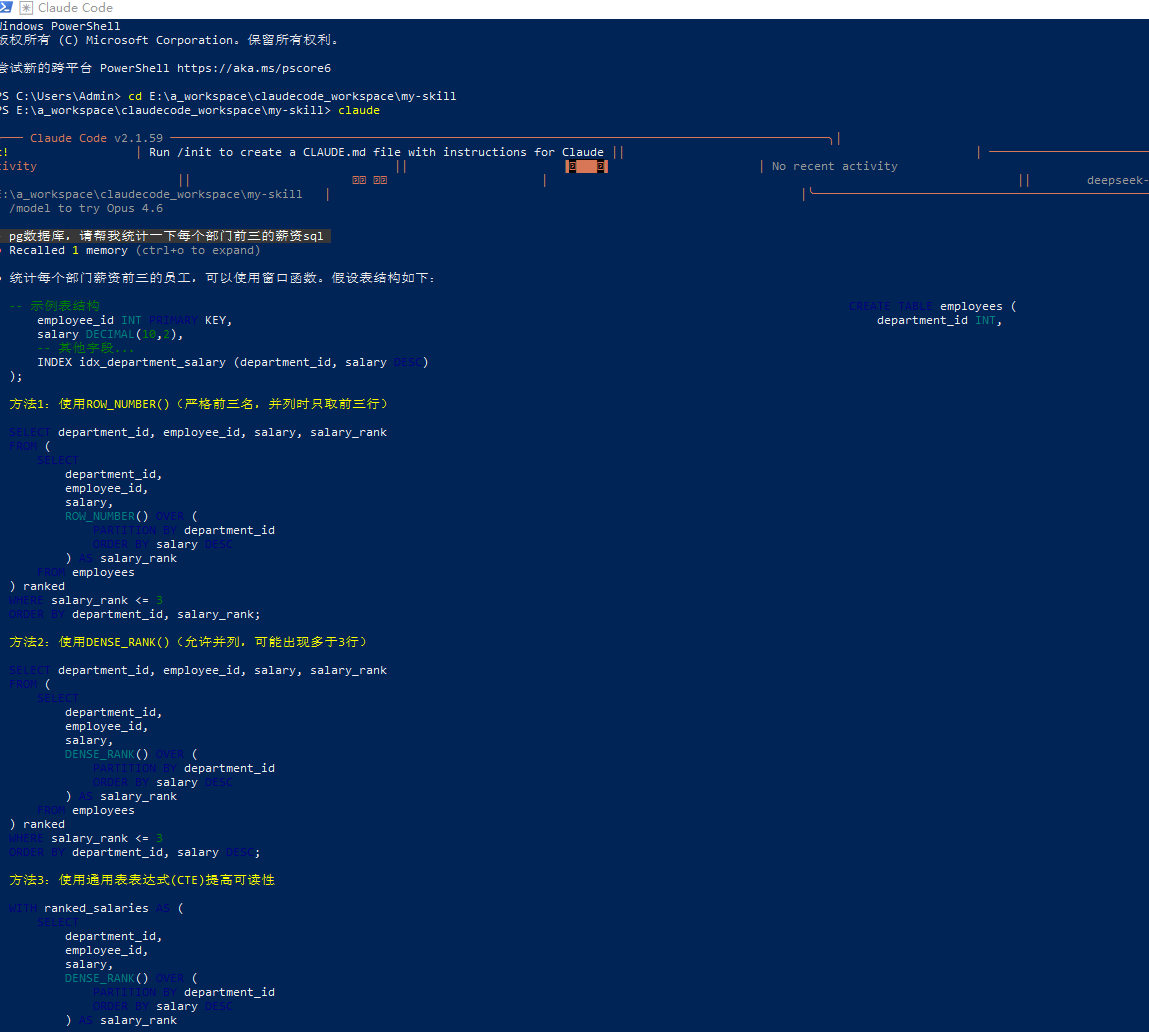
好了这个只是一个简单的例子,后续在进行高阶的使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)