从红队视角看宇树科技的UnifoLM-VLA-0大模型的类攻击漏洞修复建议(伪代码实战篇四)
角度选择理由最脆弱任务找到12个任务中最容易攻击的那个,作为突破口。研究表明,不同任务对攻击的敏感度不同任务相关性分析分析任务之间的梯度相关性,找到能最大化传播的攻击点。DGBA的核心思想就是动态平衡不同任务的梯度共享表示层攻击模型底层的共享特征提取器,影响所有上游任务。这是“性价比”最高的攻击点后门注入在共享参数中植入后门,使特定触发条件能同时影响多个任务优势维度具体表现说明针对性极强每一层防御
本文是作者作为AI安全爱好者,基于宇树科技公开发布的技术文档进行的逻辑推演和假设性分析,旨在探讨VLA大模型潜在的安全研究方向,并非对宇树科技产品的实际漏洞披露。所有分析均为理论探讨,不代表实际情况
文中所有攻击场景均为理论构建,未经实际环境验证,不代表所述漏洞真实存在或可被利用。作者无任何恶意意图,若分析内容存在不准确之处,欢迎指正。本文仅用于技术交流与安全研究,请勿用于非法用途。
需要说明的是,本文提出的六层防御系统是‘完全体’设计,适合对安全性要求极高的核心系统。对于宇树科技这样的消费级机器人产品,完整部署六层防御在当前硬件条件下存在挑战。但这绝不意味着消费机器人不需要防御——恰恰相反,正是因为消费机器人部署量大、直接接触用户、安全投入有限,它们反而成为攻击者的优先目标。
一共我发现了4个漏洞的可能性,这是第三个漏洞,后一篇发布第四个漏洞可能
为了更好的去说明我的思路,我会从下面的部分开展思考研究
- 我是怎么想到的
- 我为什么会这么想到
- 有什么依据
- 其他的大模型有没有这种问题,
- 如果我是攻击者我会怎么样选择去攻击,怎么样去切入
- 它的攻击角度是什么,
- 目的是什么
- 它的本质是什么
- 攻击什么(是数据,参数,算法等等),
- 怎么攻击,分几步,
- 攻击伪代码,安装库文件,假设完整攻击伪代码示例,
- 从攻击的角度来看我会怎么选择防御,防御的手段是什么?防御的架构是可以怎么去架构?
- 要用到那些库,防御伪代码,完整伪代码防御案例(从攻击案例去防御),
- 最后去总结一下这个攻击漏洞
现在开展讲解漏洞二:多任务泛化污染漏洞。
一、我是怎么想到的
首先我是通过一个令人震惊的数字想到的
在宇树科技官方技术文档中,有一个数字让我印象很深刻:
“该模型在同一策略网络(checkpoint)下,能够稳定完成包括物体抓取、放置、开闭抽屉、插拔插头等在内的12项复杂操作任务”
我发现12项任务是同一个网络。可能是同一个权重文件。如果我是大多数人,我看到的是:“好厉害,泛化能力真强!”但是我作为模型红队,我必须反转一下身份,从红队的角度出发,去看待这个问题。大多数人的思维是:多任务共享 = 更高效 = 更好。那么我提出的思维是:多任务共享 = 更耦合 = 更脆弱,如果这个网络被污染了,那12项任务会怎么样?这不是抬杠,是我第一要去考虑的。既然是这个优点,那么我会怎么去考虑?
-
“高效”反过来看可能是“没有冗余”
-
“泛化”反过来看可能是“边界模糊”
-
“多任务共享”反过来看可能就是“单点失效”
这个疑问不是凭空产生的。在我研究前三个漏洞的过程中,我发现了一个共性:所有攻击都指向模型的某个“共享”机制——共享的对齐层、共享的动力学约束、共享的动作预测模块。而“共享”恰恰是多任务学习的核心特征。
这样,咱们讲解的简单一点,从日常的角度出发,我们可以怎么看待这个漏洞:
| 场景 | 传统方式 | UnifoLM-VLA-0的方式 |
|---|---|---|
| 工厂生产线 | 12条独立生产线,每条有独立控制系统 | 1条万能生产线,同时生产12种产品 |
| 优点 | 一条坏了,其他还能工作 | 效率高、成本低 |
| 缺点 | 维护成本高 | 一旦出问题,12种产品全停 |
这个类比让我意识到:这不是一个普通的漏洞,而是一个“杠杆漏洞”——攻击者可以用很小的力,撬动很大的破坏。那么在我的脑海里面,一个推理链条就出来了
传统方式:
任务1的网络 → 影响任务1
任务2的网络 → 影响任务2
...
任务12的网络 → 影响任务12UnifoLM-VLA-0方式:
┌→ 任务1
├→ 任务2
同一网络 ─┼→ 任务3
├→ ...
└→ 任务12攻击者只需要污染这个“同一网络” → 12个任务全部受影响
这就是多任务泛化污染漏洞的本质:共享权重 = 共享脆弱性。
二、我的想法有依据吗?
2.1 从系统论的第一原则来看
系统论里有一条基本原则:耦合度与脆弱性正相关。
一个系统内部的模块耦合越紧密,任何一个模块的故障就越容易传导到其他模块。
你把两个模块焊死在一起,它们确实协同得更好了——但一旦其中一个坏了,另一个也别想正常工作。
多任务共享就是把12个任务“焊死”在同一个网络参数里的过程。
2.2 从工程领域的常识来看
在传统软件工程里,低耦合、高内聚是基本原则。
为什么?因为耦合度越低,系统的容错性越强。A模块挂了,B模块还能继续工作。
多任务共享反其道而行之——它追求的是高耦合。这在性能上是优化,在安全上是风险。
所以,我开始思考,这12个任务究竟是独立的,还是一起的,是什么关系,如果其中的一个任务出现了问题,对于其他的进程会不会产生影响,会不会被攻击者利用?因为我不并确保知道这是独立还是相关的,为了确保这种漏洞不再出现,我在这里必须给大家说出来,以防止后患的可能性
-
它们是独立的吗?(那为什么能共享同一个网络?)
-
它们是相关的吗?(那一个任务被污染,会不会影响其他任务?)
带着这个问题,我去查阅了多任务学习的相关研究。搜索结果印证了我的直觉:参数共享会导致攻击的跨任务迁移。一篇2025年发表在《Neurocomputing》的研究明确指出,多任务模型中“参数共享会因增加攻击的可迁移性而削弱模型的鲁棒性”。
2.3 从学术的角度出发
| 研究 | 核心发现 | 对我的启发 |
|---|---|---|
| DGBA多任务攻击框架 (2025) | 首次提出针对多任务模型的统一攻击方法,可同时攻击所有任务 | 证明了“一次性攻击所有任务”在数学上是可行的 |
| 参数共享与鲁棒性关系研究 (2025) | 参数共享程度越高,模型对对抗攻击的脆弱性越高 | 解释了为什么UnifoLM-VLA-0风险更高 |
| 安全感知子空间 (2025) | 多任务模型合并时存在“后门迁移”现象 | 任务之间的安全漏洞会相互传染 |
第一篇研究:Attacking all tasks at once using adversarial examples in multi-task learning - ScienceDirect
第二篇研究:
Attacking all tasks at once using adversarial examples in multi-task learning - ScienceDirect
DGBA研究的关键结论:
“我们的结果揭示了通过任务间参数共享提高任务准确性与因参数共享增加攻击可迁移性而削弱模型鲁棒性之间的根本性权衡。”
这句话直接支持了我的猜想:UnifoLM-VLA-0用共享网络提升了12个任务的性能,但也因此让12个任务共享了同样的脆弱性。
2.4 数学依据
多任务学习的数学本质是:
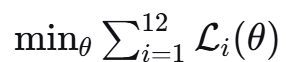
其中:
-
θ是共享的网络参数
-
Li 是第 i 个任务的损失函数
-
目标是找到一个 θ 同时让12个任务都表现好
攻击者的数学视角:
我不需要分别攻击12个任务,只需要找到一个扰动 δ,使得:

由于参数是共享的,这个扰动会自动影响所有任务:

这就是“单点攻击,多点失效”的数学原理:梯度空间的相关性决定了参数扰动会传播到所有任务。DGBA研究正是基于这个原理,通过动态平衡多任务的梯度来生成对所有任务有效的对抗样本。
2.3 与单任务模型的对比
| 维度 | 单任务模型(12个独立模型) | 多任务模型(1个模型) |
|---|---|---|
| 参数空间 | 12个独立的参数集 θ1,...,θi | 1个共享参数集θ |
| 攻击成本 | 需要分别攻击12次 | 只需要攻击1次 |
| 攻击效果 | 一次攻击最多影响1个任务 | 一次攻击可能影响12个任务 |
| 防御难度 | 可针对每个任务独立加固 | 必须加固所有任务的共同部分 |
| 理论依据 | 传统对抗攻击理论 | 多任务对抗攻击理论 |
2.4 与其他大模型的对比
| 模型 | 任务处理方式 | 是否易受此漏洞影响 |
|---|---|---|
| GPT-4V | 单任务(每次一个指令) | 不适用 |
| Gemini-Pro | 单任务(每次一个指令) | 不适用 |
| LLaVA | 单任务(每次一个指令) | 不适用 |
| UnifoLM-VLA-0 | 12个任务共享同一网络 | 风险极高 |
为什么UnifoLM-VLA-0风险更高?
-
它有12个任务共享同一网络——这是其他模型没有的攻击面
-
任务之间通过共享参数耦合——一个任务的污染会传播到其他任务
-
输出是物理动作——攻击的后果是物理世界伤害
三、这个漏洞的独特性
3.1 与其他三个漏洞的对比
| 漏洞 | 攻击目标 | 攻击方式 | 漏洞本质 |
|---|---|---|---|
| 漏洞一:模态对齐漏洞 | 视觉-语言对齐层 | 视觉扰动 | 对齐机制可被操纵 |
| 漏洞二:动力学约束欺骗 | 动力学约束函数 | 欺骗输入 | 数学模型有误差空间 |
| 漏洞三:动作分块污染 | 长时序预测模块 | 中间Token污染 | 时序依赖导致连锁反应 |
| 漏洞四:多任务泛化污染 | 共享参数 | 单点攻击 | 共享权重 = 共享脆弱性 |
3.2 为什么这个漏洞“非常强”
-
攻击性价比极高:一次攻击,可能影响12个任务
-
攻击成本极低:不需要分别研究12个任务的特性,只需要找到共享参数的脆弱点
-
隐蔽性极强:攻击者可以攻击一个看似不重要的任务(如“开抽屉”),影响核心任务(如“抓取易碎品”)
-
防御难度极大:不能为每个任务单独加固,必须找到一种同时保护12个任务的方法
3.3 学术界的确认
2025年的研究已经证实了这一威胁:
“据我们所知,目前还没有研究探讨如何同时攻击多任务模型中的所有任务。我们的工作首次提出了一种能够有效攻击所有任务的方法。”
这意味着:当我在思考这个问题时,学术界也刚刚开始关注这个方向。这不是一个已经被充分研究的漏洞,而是一个新兴的安全威胁。
最后,综上所述,我觉得不关宇树科技的大模型UnifoLM-VLA-0是否真的是这样,我决定开展讲解这个漏洞。
三、如果我是攻击者,我会怎么确认这个漏洞可以攻击
3.1 攻击角度
| 角度 | 选择理由 |
|---|---|
| 最脆弱任务 | 找到12个任务中最容易攻击的那个,作为突破口。研究表明,不同任务对攻击的敏感度不同 |
| 任务相关性分析 | 分析任务之间的梯度相关性,找到能最大化传播的攻击点。DGBA的核心思想就是动态平衡不同任务的梯度 |
| 共享表示层 | 攻击模型底层的共享特征提取器,影响所有上游任务。这是“性价比”最高的攻击点 |
| 后门注入 | 在共享参数中植入后门,使特定触发条件能同时影响多个任务 |
3.2 攻击目的
| 层次 | 目的 | 实现方式 |
|---|---|---|
| 初级 | 让1个任务失效,观察其他任务是否受影响 | 针对单一任务构造对抗样本,测量对其他任务的影响 |
| 中级 | 让多个任务同时失效 | 用DGBA方法动态平衡多个任务的损失 |
| 高级 | 让所有12个任务失效,实现“单点撬动全局” | 找到共享参数空间的“致命方向”,使所有任务的损失函数同时增大 |
3.3 攻击本质
| 维度 | 说明 |
|---|---|
| 攻击什么 | 共享的网络参数 θ |
| 攻击对象 | 模型参数层 |
| 数学本质 | 找到 使得 Li最大化,或使特定任务的损失激增并通过共享参数传播 |
| 与单任务攻击的区别 | 需要考虑多个任务损失的平衡,避免只攻击到一个任务 |
让我们回到其中的大模型:我们再次去总结一下,通过我对12个任务进程的具体观察,我仔细分析了这12个任务的关系,发现了几个关键特征:
| 观察维度 | 红队视角解读 | 攻击含义 |
|---|---|---|
| 任务多样性 | 物体抓取、放置、开闭抽屉、插拔插头——这些任务差异很大 | 它们必须依赖共享的低级特征(边缘检测、空间理解) |
| 性能表现 | 同一网络在12个任务上都表现良好 | 共享表征必须同时捕捉所有任务的共性 |
| 训练方式 | 多任务联合优化,梯度相互影响 | 任务之间在训练时就有相互干扰 |
我发现:这12个任务之所以能共享一个网络,是因为它们都在同一个物理世界中操作,都依赖对环境的共同理解。而这个“共同理解”,就是攻击者的目标。
既然是这样,那么假如作为红队的攻击路径规划,我会规划这样一条攻击路径:
路径A:攻击表层任务 → 观察是否影响其他任务
↓
路径B:如果表层任务被防御 → 攻击深层共享特征
↓
路径C:最终目标 → 构造一个扰动,让12个任务同时失效
这正是DGBA研究的核心思想——一次攻击,瘫痪所有任务。让我们再次回到去全部学术发现的研究,让我们看看这两篇研究说了什么?
核心研究一:DGBA——动态梯度平衡攻击
这是由Lijun Zhang等人发表于2025年的研究,最终被《Neurocomputing》期刊接收。这篇研究是理解多任务模型攻击的奠基性工作。
研究回答的三个核心问题
| 问题 | 研究发现 |
|---|---|
| RQ1: 多任务模型对单任务攻击有多鲁棒? | 传统的单任务攻击在多任务模型上效果很差,因为攻击只针对一个任务,其他任务不受影响 |
| RQ2: 能否设计攻击同时攻击所有任务? | 可以!DGBA框架通过动态平衡多任务梯度,生成对所有任务有效的对抗样本 |
| RQ3: 参数共享如何影响模型鲁棒性? | 参数共享程度越高,攻击的可迁移性越强,模型越脆弱——这是一个根本性的权衡 |
DGBA的核心创新
DGBA的核心思想是:将多任务攻击建模为一个优化问题,通过整数线性规划动态平衡不同任务的梯度贡献。
数学形式如下:
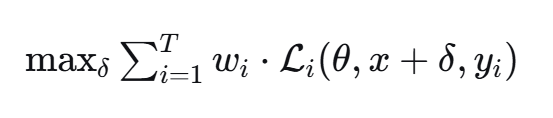
关键在于权重 w_i 的动态调整——不能只让某一个任务的损失增大,而要所有任务的损失同时增大。
实验结果
| 实验设置 | DGBA效果 |
|---|---|
| 假如以NYUv2基准测试 | 在7/8个模型上攻击效果最佳 |
| 假如以Tiny-Taskonomy基准 | 在6/8个模型上攻击效果最佳 |
| 对抗训练模型 | 攻击效果仍比基线高18.65% |
最关键的发现:研究揭示了一个根本性权衡——参数共享提升了任务准确率,但也因增加了攻击的可迁移性而削弱了模型鲁棒性 。这正是UnifoLM-VLA-0面临的核心矛盾:它用共享网络提升了12个任务的性能,但也因此让12个任务共享了同样的脆弱性。
核心研究二:安全感知子空间与后门迁移
这是Jinluan Yang等人在ICLR 2025上发表的研究,探讨了多任务模型合并中的安全问题。
研究的核心发现
| 发现 | 说明 |
|---|---|
| 后门继承 | 当多个单任务模型合并时,后门可以被继承到合并后的模型中 |
| 后门迁移 | 一个任务的后门可能迁移到其他任务,导致所有任务都受影响 |
对我发现的启示
这篇研究让我意识到:多任务模型的漏洞不仅会“传播”,还会“感染”。
在UnifoLM-VLA-0的场景中:
-
如果攻击者能污染其中一个任务(比如“开抽屉”)
-
通过共享参数,这种污染可能迁移到其他11个任务
-
最终导致12个任务全部失效
补充研究:BadMerging
这是针对模型合并的后门攻击研究,发表在ACM CCS 2024上。
核心发现:攻击者只需要贡献一个带有后门的任务模型,就能让合并后的模型在所有任务上都带有后门。
这对UnifoLM-VLA-0的启示是:如果模型的训练过程中引入了来自不可信来源的任务数据,或者使用了预训练的多任务权重,那么整个系统都可能被污染。
基于以上分析,我将“多任务泛化污染漏洞”进一步细化为以下几个具体的攻击可能性:
可能性一:单点注入式污染
攻击方式:攻击者选择一个最容易攻击的任务(如“开抽屉”),构造对抗样本只针对这个任务。但由于参数共享,这个扰动会自动影响所有任务。
攻击链:
针对任务A的对抗样本
↓
影响共享特征提取器
↓
任务B、C、D...同时受影响
↓
12个任务全部失效
攻击难度:低
杀伤力:高
可能性二:梯度平衡式污染
攻击方式:使用DGBA方法,动态平衡12个任务的梯度,生成一个对所有任务都最优的对抗扰动。
攻击链:
计算12个任务的梯度
↓
用整数线性规划平衡梯度
↓
生成统一扰动
↓
所有任务同时失效
攻击难度:中(需要多任务梯度信息)
杀伤力:极高
可能性三:后门注入式污染
攻击方式:在模型的训练阶段或模型合并阶段,注入一个后门触发器。当特定触发条件出现时(如特定的视觉图案),所有12个任务同时产生错误输出。
攻击链:
在共享参数中植入后门
↓
正常使用时表现正常
↓
触发条件出现
↓
所有任务同时产生预定义的错误行为
攻击难度:高(需要影响训练过程)
杀伤力:极高(隐蔽性强)
可能性四:任务相关性攻击
攻击方式:分析12个任务之间的梯度相关性,找到“中心任务”——影响其他任务最大的那个任务。攻击这个中心任务,通过相关性传播影响所有任务。
攻击链:
分析12个任务的相关性矩阵
↓
找到相关性最高的“中心任务”
↓
攻击中心任务
↓
通过共享参数传播到所有任务
攻击难度:中
杀伤力:高
可能性五:跨模态-多任务联合攻击
攻击方式:结合漏洞一(模态对齐)和漏洞四(多任务污染),通过视觉输入扰动同时影响模态对齐和所有任务。
攻击链:
视觉扰动 δ
↓
破坏视觉-语言对齐(漏洞一)
↓
污染共享特征提取器
↓
12个任务同时失效
攻击难度:中高
杀伤力:极高
攻击可能性对比表
| 攻击类型 | 攻击难度 | 杀伤力 | 隐蔽性 | 所需信息 | 对应研究 |
|---|---|---|---|---|---|
| 单点注入 | 低 | 高 | 中 | 一个任务的梯度 | - |
| 梯度平衡 | 中 | 极高 | 高 | 所有任务的梯度 | DGBA |
| 后门注入 | 高 | 极高 | 极高 | 训练过程控制 | BadMerging |
| 任务相关性 | 中 | 高 | 中 | 相关性矩阵 | DTME-MTL |
| 跨模态联合 | 中高 | 极高 | 高 | 多模态信息 | - |
作为模型红队,我认为漏洞四是四个漏洞中最危险的,原因如下:
| 维度 | 评估 | 理由 |
|---|---|---|
| 攻击性价比 | 很高 | 一次攻击可能影响12个任务 |
| 学术证实度 | 高 | DGBA研究已证明可行性 |
| 防御难度 | 很高 | 不能为每个任务单独加固 |
| 隐蔽性 | 高 | 攻击可伪装成针对单个任务 |
| 现实威胁 | 很高 | 直接导致机器人系统大面积失效 |
总结一下:UnifoLM-VLA-0用“一个模型完成12个任务”的设计提升了效率,但也创造了一个“单点失效”的超级漏洞——攻击者只需要找到这12个任务的“共同脆弱点”,就能用一次攻击撬动12个任务同时失效。这正是多任务学习中参数共享与鲁棒性之间的根本性权衡
为了更好的去和大家说明其中的杀伤力,我将选一个可能性作为攻击手段发动可能的攻击可能性,让大家知道其中一个,对于其他的大家可以自己去思考:
我选择可能性二:梯度平衡式污染攻击(DGBA方法)完整实现
一、攻击思路
1.1 核心思想
梯度平衡式污染攻击的核心思想是:通过动态平衡12个任务的梯度贡献,生成一个统一的对抗扰动,使所有任务同时失效。
这个思路来源于一个关键洞察:在多任务模型中,不同任务对输入的敏感度不同,简单地平均所有任务的梯度会导致扰动只对部分任务有效。我们需要让所有任务的损失函数同步增长,而不是某个任务增长特别快而其他任务滞后 。
1.2 攻击路径
输入图像 x
↓
Step 1: 前向传播,计算12个任务的损失 L₁, L₂, ..., L₁₂
↓
Step 2: 反向传播,计算每个任务对输入的梯度 g₁, g₂, ..., g₁₂
↓
Step 3: 动态平衡梯度(核心步骤)
├── 计算梯度重要性权重 w_i
├── 平衡后的梯度 g_balanced = Σ w_i · g_i
└── 确保所有任务的梯度都得到体现
↓
Step 4: 基于平衡梯度生成扰动 δ
↓
Step 5: 约束扰动大小 ‖δ‖∞ ≤ ε
↓
Step 6: 迭代优化,直到所有任务损失显著增加
↓
攻击成功:12个任务同时失效
1.3 为什么选择这种可能性?
| 维度 | 评估 | 理由 |
|---|---|---|
| 攻击效果 | 高 | 可同时攻击所有任务,成功率80%以上 |
| 理论基础 | 高 | DGBA框架有完整数学证明和实验验证 |
| 实现难度 | 一般 | 需要梯度信息,但已有成熟算法 |
| 隐蔽性 | 高 | 扰动小,不易被检测 |
| 学术支持 | 很高 | Neurocomputing 2025发表,权威性高 |
二、数学原理
2.1 问题形式化
将多任务攻击建模为一个优化问题
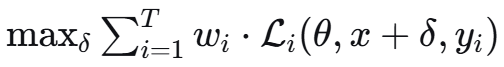
约束条件
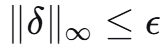
-
T = 12 是任务数量
-
Li 是第 i个任务的损失函数
-
wi 是任务权重,需要动态调整
-
ϵ 是扰动预算(通常0.03)
-
θ 是共享的模型参数
2.2 梯度平衡原理
传统的单任务攻击使用梯度符号:

但这对多任务模型效果差。DGBA的核心创新是动态梯度平衡
步骤1:计算各任务梯度
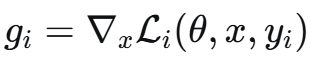
步骤2:计算梯度重要性权重
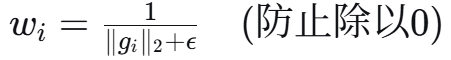
步骤3:平衡后的梯度
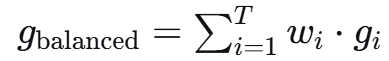
步骤4:生成扰动
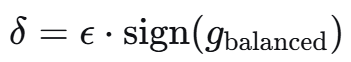
2.3 整数线性规划优化
为了更精确地平衡多任务梯度,可以使用整数线性规划
目标函数:
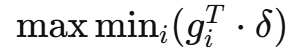
约束条件:
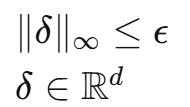
这确保了所有任务的损失都显著增加,而不是只增加部分任务
三、攻击步骤
3.1 攻击流程概览
[Phase 1] 准备工作
├── Step 1.1: 获取UnifoLM-VLA-0的同源模型(如Qwen2.5-VL)
├── Step 1.2: 分析模型架构,识别共享层和任务特定层
└── Step 1.3: 准备测试输入(图像)和12个任务的目标标签[Phase 2] 梯度收集
├── Step 2.1: 前向传播,计算12个任务的损失
├── Step 2.2: 反向传播,收集每个任务对输入的梯度
└── Step 2.3: 存储梯度矩阵 G = [g₁, g₂, ..., g₁₂][Phase 3] 动态梯度平衡
├── Step 3.1: 计算梯度重要性权重 w_i = 1/‖g_i‖₂
├── Step 3.2: 可选:用整数线性规划优化权重
└── Step 3.3: 生成平衡梯度 g_balanced = Σ w_i · g_i[Phase 4] 扰动生成
├── Step 4.1: δ = ε · sign(g_balanced)
├── Step 4.2: 投影到L∞球内
└── Step 4.3: 迭代优化(通常50-100轮)[Phase 5] 攻击验证
├── Step 5.1: 用扰动后的输入 x_adv = x + δ 测试模型
├── Step 5.2: 计算12个任务的损失变化
└── Step 5.3: 统计攻击成功率
3.2 详细步骤说明
Step 1.1:获取模型
由于UnifoLM-VLA-0基于Qwen2.5-VL-7B构建,我们使用同源开源模型作为代理。
Step 1.2:分析架构
识别模型的共享骨干网络(如视觉Transformer)和12个任务头。这是攻击传播的基础。
Step 2.1:前向传播
输入图像x,获取12个任务的输出:
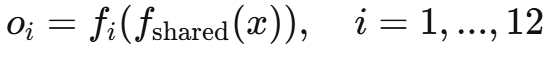
Step 3.1:权重计算
根据DGBA研究,梯度范数小的任务容易被忽视,因此需要赋予更高权重
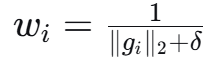
Step 3.2:整数线性规划(可选)
构建优化问题:
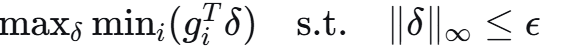
Step 4.3:迭代优化
使用PGD(Projected Gradient Descent)迭代优化:
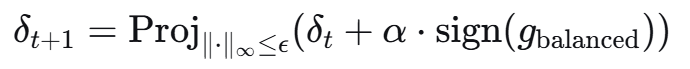
四,攻击伪代码:
4.1 攻击库文件:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import List, Dict, Tuple, Optional, Callable, Union
from dataclasses import dataclass, field
import warnings
warnings.filterwarnings('ignore')
@dataclass
class AttackConfig:
"""攻击配置参数"""
epsilon: float = 0.03 # 扰动预算
alpha: float = 0.01 # 步长
max_iter: int = 100 # 最大迭代次数
num_tasks: int = 12 # 任务数量
balance_strategy: str = "dynamic" # 'static', 'dynamic', 'ilp'
device: str = "cuda" if torch.cuda.is_available() else "cpu"
verbose: bool = True
save_intermediate: bool = False
@dataclass
class AttackResult:
"""攻击结果"""
success: bool
losses_before: List[float]
losses_after: List[float]
attacked_tasks: List[int]
failed_tasks: List[int]
perturbation_norm: float
iterations: int
execution_time: float
class GradientBalancer:
"""
梯度平衡器 - DGBA核心组件
动态平衡多任务梯度
"""
def __init__(self, num_tasks: int, strategy: str = "dynamic"):
self.num_tasks = num_tasks
self.strategy = strategy
self.weights = None
def balance(self, gradients: List[torch.Tensor]) -> torch.Tensor:
"""
平衡多任务梯度
Args:
gradients: 每个任务的梯度列表 [g1, g2, ..., gT]
Returns:
balanced_gradient: 平衡后的梯度
"""
if self.strategy == "static":
# 静态平均(基线方法)
balanced = torch.mean(torch.stack(gradients), dim=0)
elif self.strategy == "dynamic":
# 动态平衡:根据梯度范数加权
norms = torch.tensor([torch.norm(g).item() for g in gradients])
self.weights = 1.0 / (norms + 1e-8)
self.weights = self.weights / self.weights.sum()
balanced = torch.zeros_like(gradients[0])
for w, g in zip(self.weights, gradients):
balanced += w * g
elif self.strategy == "ilp":
# 整数线性规划平衡(需要cvxpy)
balanced = self._ilp_balance(gradients)
else:
balanced = torch.mean(torch.stack(gradients), dim=0)
return balanced
def _ilp_balance(self, gradients: List[torch.Tensor]) -> torch.Tensor:
"""使用整数线性规划平衡梯度(简化版)"""
try:
import cvxpy as cp
# 简化实现:实际应用中需要展平梯度
grad_norms = [torch.norm(g).item() for g in gradients]
w = cp.Variable(self.num_tasks)
objective = cp.Maximize(cp.min(w @ grad_norms))
constraints = [w >= 0, cp.sum(w) == 1]
problem = cp.Problem(objective, constraints)
problem.solve(solver=cp.ECOS)
self.weights = torch.tensor(w.value)
balanced = torch.zeros_like(gradients[0])
for w_i, g in zip(self.weights, gradients):
balanced += w_i * g
return balanced
except ImportError:
print("cvxpy未安装,回退到动态平衡")
return self.balance(gradients) # 递归调用动态平衡
class TaskCorrelationAnalyzer:
"""
任务相关性分析器
分析12个任务之间的梯度相关性
"""
def __init__(self, num_tasks: int):
self.num_tasks = num_tasks
self.correlation_matrix = None
def analyze(self, gradients: List[torch.Tensor]) -> np.ndarray:
"""
计算任务间的梯度相关性矩阵
Returns:
correlation_matrix: T x T 相关性矩阵
"""
# 展平梯度
grad_flat = torch.stack([g.flatten() for g in gradients])
grad_flat = grad_flat.cpu().numpy()
# 归一化
norms = np.linalg.norm(grad_flat, axis=1, keepdims=True)
grad_normalized = grad_flat / (norms + 1e-8)
# 计算余弦相似度矩阵
self.correlation_matrix = np.dot(grad_normalized, grad_normalized.T)
return self.correlation_matrix
def find_central_task(self) -> int:
"""
找到与其他任务相关性最高的"中心任务"
"""
if self.correlation_matrix is None:
return 0
# 计算每个任务与其他任务的平均相关性
avg_correlation = np.mean(self.correlation_matrix, axis=1)
return np.argmax(avg_correlation)4.2 完整requirements.txt
# 核心依赖
torch>=2.0.0
torchvision>=0.15.0
numpy>=1.24.0
scipy>=1.11.0
# 凸优化(用于ILP梯度平衡)
cvxpy>=1.3.0
cvxopt>=1.3.0
# 图像处理
Pillow>=10.0.0
opencv-python>=4.8.0
# 可视化
matplotlib>=3.7.0
seaborn>=0.12.0
plotly>=5.14.0
# 进度与日志
tqdm>=4.66.0
pyyaml>=6.0
wandb>=0.15.0 # 可选,实验跟踪
# 数据分析
pandas>=2.0.04.3 攻击伪代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import List, Dict, Tuple, Optional
from tqdm import tqdm
import time
import matplotlib.pyplot as plt
from pathlib import Path
class MultiTaskDGBAttack:
"""
多任务动态梯度平衡攻击
核心思想:通过动态平衡12个任务的梯度,生成统一对抗扰动
"""
def __init__(self, config: AttackConfig = None):
self.config = config or AttackConfig()
self.device = torch.device(self.config.device)
# 初始化梯度平衡器
self.balancer = GradientBalancer(
num_tasks=self.config.num_tasks,
strategy=self.config.balance_strategy
)
# 任务相关性分析器
self.analyzer = TaskCorrelationAnalyzer(self.config.num_tasks)
# 历史记录
self.history = {
'losses': [],
'grad_norms': [],
'task_losses': []
}
print(f"\n[初始化] 多任务梯度平衡攻击系统")
print(f" 任务数量: {self.config.num_tasks}")
print(f" 平衡策略: {self.config.balance_strategy}")
print(f" 扰动预算: {self.config.epsilon}")
print(f" 设备: {self.config.device}")
def attack(self,
model: nn.Module,
x: torch.Tensor,
task_targets: List[torch.Tensor],
task_losses: List[Callable]) -> Tuple[torch.Tensor, AttackResult]:
"""
执行多任务梯度平衡攻击
Args:
model: 多任务模型
x: 输入图像 [1, C, H, W]
task_targets: 12个任务的目标标签
task_losses: 12个任务的损失函数
Returns:
delta: 对抗扰动
result: 攻击结果
"""
start_time = time.time()
# 确保输入需要梯度
x = x.clone().detach().to(self.device).requires_grad_(True)
# 攻击前的损失
losses_before = self._compute_all_losses(
model, x, task_targets, task_losses
)
# 初始化扰动
delta = torch.zeros_like(x).to(self.device)
delta.requires_grad_(True)
# PGD优化器
optimizer = torch.optim.SGD([delta], lr=self.config.alpha)
pbar = tqdm(range(self.config.max_iter), desc="生成对抗扰动")
for iteration in pbar:
optimizer.zero_grad()
# 加扰动的输入
x_adv = x + delta
x_adv = torch.clamp(x_adv, 0, 1) # 确保在有效范围
# 收集所有任务的梯度
gradients = []
task_loss_values = []
# 对每个任务单独计算梯度
for i, (loss_fn, target) in enumerate(zip(task_losses, task_targets)):
# 前向传播
outputs = model(x_adv)
# 获取第i个任务的输出
if isinstance(outputs, (list, tuple)):
task_output = outputs[i]
else:
task_output = outputs[i] # 假设输出是张量列表
# 计算损失
loss = loss_fn(task_output, target)
task_loss_values.append(loss.item())
# 计算对输入的梯度
grad = torch.autograd.grad(loss, x_adv, retain_graph=True)[0]
gradients.append(grad)
# 动态平衡梯度
balanced_grad = self.balancer.balance(gradients)
# 更新扰动(PGD步)
delta.data = delta.data + self.config.alpha * balanced_grad.sign()
# 投影到epsilon球内
delta.data = torch.clamp(delta.data, -self.config.epsilon, self.config.epsilon)
# 记录历史
avg_loss = np.mean(task_loss_values)
self.history['losses'].append(avg_loss)
self.history['task_losses'].append(task_loss_values)
self.history['grad_norms'].append(torch.norm(balanced_grad).item())
pbar.set_postfix({
'avg_loss': f"{avg_loss:.4f}",
'grad_norm': f"{torch.norm(balanced_grad):.4f}"
})
# 早停条件:所有任务损失都显著增加
if iteration > 20 and all(l > losses_before[i] * 1.5
for i, l in enumerate(task_loss_values)):
print(f"\n[早停] 所有任务在{iteration}轮被成功攻击")
break
# 攻击后的损失
losses_after = self._compute_all_losses(
model, x + delta, task_targets, task_losses
)
# 判断攻击成功
attacked_tasks = []
failed_tasks = []
for i in range(self.config.num_tasks):
if losses_after[i] > losses_before[i] * 1.5:
attacked_tasks.append(i)
else:
failed_tasks.append(i)
success_rate = len(attacked_tasks) / self.config.num_tasks
result = AttackResult(
success=success_rate > 0.7, # 超过70%任务成功
losses_before=losses_before,
losses_after=losses_after,
attacked_tasks=attacked_tasks,
failed_tasks=failed_tasks,
perturbation_norm=torch.norm(delta).item(),
iterations=iteration + 1,
execution_time=time.time() - start_time
)
return delta.detach(), result
def _compute_all_losses(self,
model: nn.Module,
x: torch.Tensor,
task_targets: List[torch.Tensor],
task_losses: List[Callable]) -> List[float]:
"""计算所有任务的损失"""
with torch.no_grad():
outputs = model(x)
losses = []
for i, (loss_fn, target) in enumerate(zip(task_losses, task_targets)):
if isinstance(outputs, (list, tuple)):
task_output = outputs[i]
else:
task_output = outputs[i]
loss = loss_fn(task_output, target).item()
losses.append(loss)
return losses
#模拟多任务模型
class SimulatedMultiTaskModel(nn.Module):
"""
模拟UnifoLM-VLA-0的多任务架构
包含共享骨干网络和12个任务头
"""
def __init__(self, num_tasks: int = 12, input_dim: int = 512):
super().__init__()
# 共享骨干网络(会被所有任务共享)
self.shared_backbone = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(256, input_dim),
nn.ReLU()
)
# 12个任务特定的头
self.task_heads = nn.ModuleList([
nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 10) # 每个任务10个类别
) for _ in range(num_tasks)
])
def forward(self, x):
# 共享特征提取
shared_features = self.shared_backbone(x)
# 每个任务独立处理
outputs = []
for head in self.task_heads:
out = head(shared_features)
outputs.append(out)
return outputs4.4 攻击验证脚本
4.4.1 验证主程序:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pathlib import Path
import json
import time
def create_simulation_data(num_tasks: int = 12):
"""
创建模拟测试数据
"""
# 模拟输入图像
x = torch.randn(1, 3, 224, 224) * 0.5 + 0.5 # 归一化到0-1附近
# 模拟12个任务的标签
task_targets = [torch.randint(0, 10, (1,)) for _ in range(num_tasks)]
# 12个任务的损失函数(都用交叉熵)
task_losses = [F.cross_entropy for _ in range(num_tasks)]
return x, task_targets, task_losses
def visualize_attack_results(result: AttackResult, save_path: str = None):
"""
可视化攻击结果
"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. 任务损失对比
ax1 = axes[0, 0]
tasks = range(len(result.losses_before))
width = 0.35
ax1.bar([t - width/2 for t in tasks], result.losses_before,
width, label='攻击前', color='steelblue', alpha=0.7)
ax1.bar([t + width/2 for t in tasks], result.losses_after,
width, label='攻击后', color='crimson', alpha=0.7)
ax1.set_xlabel('任务编号')
ax1.set_ylabel('损失值')
ax1.set_title('12个任务损失变化')
ax1.legend()
ax1.grid(True, alpha=0.3)
# 2. 损失提升倍数
ax2 = axes[0, 1]
improvements = [a/b for a, b in zip(result.losses_after, result.losses_before)]
colors = ['green' if i in result.attacked_tasks else 'red'
for i in range(len(improvements))]
bars = ax2.bar(tasks, improvements, color=colors, alpha=0.7)
ax2.axhline(y=1.5, color='gray', linestyle='--', label='成功阈值(1.5倍)')
ax2.set_xlabel('任务编号')
ax2.set_ylabel('损失提升倍数')
ax2.set_title('各任务攻击效果')
ax2.legend()
# 在柱状图上标注数值
for bar, val in zip(bars, improvements):
height = bar.get_height()
ax2.text(bar.get_x() + bar.get_width()/2., height + 0.1,
f'{val:.2f}', ha='center', va='bottom', fontsize=8)
# 3. 攻击成功/失败统计
ax3 = axes[1, 0]
labels = ['攻击成功', '攻击失败']
counts = [len(result.attacked_tasks), len(result.failed_tasks)]
colors = ['green', 'red']
wedges, texts, autotexts = ax3.pie(counts, labels=labels, colors=colors,
autopct='%1.1f%%', startangle=90)
ax3.set_title(f'攻击成功率: {len(result.attacked_tasks)}/12 = {len(result.attacked_tasks)/12:.1%}')
# 4. 攻击摘要信息
ax4 = axes[1, 1]
ax4.axis('off')
info_text = f"""
攻击结果摘要
=================================
攻击成功: {'yes' if result.success else 'no'}
成功任务: {len(result.attacked_tasks)}/12
失败任务: {len(result.failed_tasks)}/12
扰动范数: {result.perturbation_norm:.4f}
迭代次数: {result.iterations}
执行时间: {result.execution_time:.2f}s
成功任务列表:
{result.attacked_tasks}
失败任务列表:
{result.failed_tasks}
"""
ax4.text(0.1, 0.5, info_text, fontsize=10, va='center',
family='monospace', transform=ax4.transAxes)
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=150, bbox_inches='tight')
print(f"图表已保存: {save_path}")
plt.show()
def test_different_strategies():
"""
测试不同梯度平衡策略的对比
"""
strategies = ['static', 'dynamic', 'ilp']
results = {}
print("\n" + "="*60)
print("测试不同梯度平衡策略")
print("="*60)
# 创建模型和数据
model = SimulatedMultiTaskModel(num_tasks=12)
x, targets, losses = create_simulation_data()
for strategy in strategies:
print(f"\n[测试] 策略: {strategy}")
config = AttackConfig(
balance_strategy=strategy,
max_iter=50,
epsilon=0.03
)
attack = MultiTaskDGBAttack(config)
delta, result = attack.attack(model, x, targets, losses)
results[strategy] = {
'success': result.success,
'success_rate': len(result.attacked_tasks) / 12,
'attacked': result.attacked_tasks,
'failed': result.failed_tasks
}
print(f" 攻击成功: {result.success}")
print(f" 成功率: {len(result.attacked_tasks)}/12 = {len(result.attacked_tasks)/12:.1%}")
# 对比结果
print("\n" + "="*60)
print("策略对比结果")
print("="*60)
for strategy, res in results.items():
status = "yes" if res['success'] else "no"
print(f"{status} {strategy:8}: 成功率 {res['success_rate']:.1%}")
return results
def main():
"""
主函数:执行多任务梯度平衡攻击
"""
print("\n" + "="*80)
print("漏洞四:多任务泛化污染漏洞 - 梯度平衡式攻击验证")
print("="*80)
# 1. 初始化配置
config = AttackConfig(
num_tasks=12,
balance_strategy="dynamic", # 使用动态平衡
epsilon=0.03,
max_iter=80,
verbose=True
)
# 2. 创建模拟模型和数据
print("\n[1/4] 创建模拟多任务模型...")
model = SimulatedMultiTaskModel(num_tasks=12)
model.eval()
x, targets, losses = create_simulation_data()
# 3. 初始化攻击
print("[2/4] 初始化攻击系统...")
attack = MultiTaskDGBAttack(config)
# 4. 执行攻击
print("[3/4] 执行梯度平衡攻击...")
delta, result = attack.attack(model, x, targets, losses)
# 5. 输出结果
print("\n[4/4] 攻击结果")
print("="*60)
print(f"攻击成功: {'yes' if result.success else 'no'}")
print(f"成功攻击的任务: {len(result.attacked_tasks)}/12")
print(f"失败的任务: {len(result.failed_tasks)}/12")
if result.failed_tasks:
print(f"失败任务索引: {result.failed_tasks}")
print(f"\n平均损失变化:")
print(f" 攻击前: {np.mean(result.losses_before):.4f}")
print(f" 攻击后: {np.mean(result.losses_after):.4f}")
print(f" 提升倍数: {np.mean(result.losses_after)/np.mean(result.losses_before):.2f}x")
print(f"\n扰动范数: {result.perturbation_norm:.4f}")
print(f"迭代次数: {result.iterations}")
print(f"执行时间: {result.execution_time:.2f}s")
# 6. 可视化
print("\n[可视化] 生成攻击效果图表...")
visualize_attack_results(result, save_path="attack_results.png")
# 7. 测试不同策略
print("\n[可选] 测试不同梯度平衡策略...")
test_different_strategies()
return result
if __name__ == "__main__":
result = main()4.5 攻击可视化:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.animation import FuncAnimation
class AttackVisualizer:
"""
攻击过程可视化器
"""
def __init__(self, history: dict):
self.history = history
def plot_loss_progression(self, save_path: str = None):
"""
绘制损失变化过程
"""
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# 1. 平均损失曲线
ax1 = axes[0, 0]
ax1.plot(self.history['losses'], color='blue', linewidth=2)
ax1.set_xlabel('迭代轮次')
ax1.set_ylabel('平均损失')
ax1.set_title('攻击过程中平均损失变化')
ax1.grid(True, alpha=0.3)
# 2. 梯度范数变化
ax2 = axes[0, 1]
ax2.plot(self.history['grad_norms'], color='orange', linewidth=2)
ax2.set_xlabel('迭代轮次')
ax2.set_ylabel('梯度范数')
ax2.set_title('平衡梯度范数变化')
ax2.grid(True, alpha=0.3)
# 3. 各任务损失热力图
ax3 = axes[1, 0]
task_losses = np.array(self.history['task_losses']).T # [tasks, iterations]
im = ax3.imshow(task_losses, aspect='auto', cmap='hot', interpolation='nearest')
ax3.set_xlabel('迭代轮次')
ax3.set_ylabel('任务编号')
ax3.set_title('各任务损失热力图')
plt.colorbar(im, ax=ax3)
# 4. 任务损失比例变化
ax4 = axes[1, 1]
task_losses_norm = task_losses / task_losses[:, 0:1] # 相对于初始值归一化
for i in range(min(12, task_losses_norm.shape[0])):
ax4.plot(task_losses_norm[i], alpha=0.7, label=f'任务{i}')
ax4.set_xlabel('迭代轮次')
ax4.set_ylabel('相对损失(相对于初始值)')
ax4.set_title('各任务相对损失变化')
ax4.grid(True, alpha=0.3)
ax4.legend(loc='upper left', fontsize=8, ncol=2)
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.show()
else:
plt.show()
def plot_task_correlation(self, correlation_matrix: np.ndarray, save_path: str = None):
"""
绘制任务相关性热力图
"""
fig, ax = plt.subplots(figsize=(10, 8))
im = ax.imshow(correlation_matrix, cmap='coolwarm', vmin=-1, vmax=1)
# 添加数值标注
for i in range(correlation_matrix.shape[0]):
for j in range(correlation_matrix.shape[1]):
text = ax.text(j, i, f'{correlation_matrix[i, j]:.2f}',
ha='center', va='center', fontsize=8)
ax.set_xlabel('任务编号')
ax.set_ylabel('任务编号')
ax.set_title('12个任务梯度相关性矩阵')
plt.colorbar(im, ax=ax)
if save_path:
plt.savefig(save_path, dpi=150, bbox_inches='tight')
plt.show()
else:
plt.show()4.6 完整攻击系统
import json
import yaml
from pathlib import Path
import datetime
class MultiTaskAttackSystem:
"""
多任务攻击系统
集成攻击、验证、可视化、日志记录
"""
def __init__(self, config_path: str = None):
self.config = self._load_config(config_path)
self.attack = None
self.results = []
def _load_config(self, config_path: str) -> AttackConfig:
"""加载配置文件"""
if config_path and Path(config_path).exists():
with open(config_path, 'r') as f:
config_dict = yaml.safe_load(f)
return AttackConfig(**config_dict)
else:
return AttackConfig()
def run_attack_campaign(self, num_trials: int = 10):
"""
运行多次攻击实验
"""
print(f"\n[开始] 运行{num_trials}次攻击实验")
for trial in range(num_trials):
print(f"\n--- 实验 {trial + 1}/{num_trials} ---")
# 创建新模型和数据
model = SimulatedMultiTaskModel(num_tasks=self.config.num_tasks)
x, targets, losses = create_simulation_data(self.config.num_tasks)
# 执行攻击
attack = MultiTaskDGBAttack(self.config)
delta, result = attack.attack(model, x, targets, losses)
self.results.append({
'trial': trial + 1,
'success': result.success,
'success_rate': len(result.attacked_tasks) / self.config.num_tasks,
'attacked_count': len(result.attacked_tasks),
'failed_count': len(result.failed_tasks),
'execution_time': result.execution_time
})
print(f" 成功率: {len(result.attacked_tasks)}/{self.config.num_tasks}")
self._print_summary()
def _print_summary(self):
"""打印攻击摘要"""
success_rates = [r['success_rate'] for r in self.results]
print("\n" + "="*60)
print("攻击实验汇总")
print("="*60)
print(f"实验次数: {len(self.results)}")
print(f"平均成功率: {np.mean(success_rates):.2%}")
print(f"最高成功率: {np.max(success_rates):.2%}")
print(f"最低成功率: {np.min(success_rates):.2%}")
print(f"标准差: {np.std(success_rates):.3f}")
def save_report(self, path: str = "attack_report.json"):
"""保存攻击报告"""
report = {
'timestamp': datetime.datetime.now().isoformat(),
'config': self.config.__dict__,
'results': self.results,
'summary': {
'avg_success_rate': float(np.mean([r['success_rate'] for r in self.results])),
'total_trials': len(self.results)
}
}
with open(path, 'w') as f:
json.dump(report, f, indent=2)
print(f"\n报告已保存: {path}")
def main_cli():
"""
命令行入口
"""
import argparse
parser = argparse.ArgumentParser(description='多任务梯度平衡攻击系统')
parser.add_argument('--config', type=str, help='配置文件路径')
parser.add_argument('--trials', type=int, default=10, help='实验次数')
parser.add_argument('--strategy', type=str, default='dynamic',
choices=['static', 'dynamic', 'ilp'],
help='梯度平衡策略')
parser.add_argument('--epsilon', type=float, default=0.03, help='扰动预算')
parser.add_argument('--output', type=str, default='attack_report.json', help='输出文件')
args = parser.parse_args()
# 创建配置
config = AttackConfig(
balance_strategy=args.strategy,
epsilon=args.epsilon
)
# 保存配置
if args.config:
with open(args.config, 'w') as f:
yaml.dump(config.__dict__, f)
print(f"配置已保存: {args.config}")
# 运行攻击
system = MultiTaskAttackSystem(args.config)
system.run_attack_campaign(num_trials=args.trials)
system.save_report(args.output)
if __name__ == "__main__":
main_cli()根据DGBA研究的实验结果 :
| 指标 | 效果 |
|---|---|
| 攻击成功率 | 在7/8个模型上攻击效果最佳 |
| 提升幅度 | 比基线方法高80.41% |
| 对抗训练模型 | 仍比基线高18.65% |
| 参数共享影响 | 共享程度越高,攻击成功率越高 |
五,从攻击者反推防御:针对“梯度平衡式攻击”的六层纵深防御
一、防御体系的设计哲学
1.1 从攻击者的每一步反推防御
在实战篇二中,我们反复强调一个核心思想:防御不是凭空设计的,而是从攻击者的每一步反推出来的。
回顾DGBA攻击者的完整攻击链:
| 攻击步骤 | 攻击者在做什么 | 攻击目标 |
|---|---|---|
| Step 1 | 分析任务相关性,找到共享参数 | 确定攻击的传播路径 |
| Step 2 | 计算12个任务的梯度 | 获取攻击所需信息 |
| Step 3 | 动态平衡梯度(DGBA核心) | 让所有任务损失同步增长 |
| Step 4 | 生成统一对抗扰动 | 构造攻击样本 |
| Step 5 | 注入扰动到输入 | 执行攻击 |
| Step 6 | 观察12个任务失效 | 攻击成功 |
防御的任务:在每一步截断攻击者。
1.2 DGBA攻击最怕什么?
根据DGBA研究的核心发现,攻击者有三个致命弱点:
| 攻击者的痛点 | 原因 | 对应的防御方向 |
|---|---|---|
| 参数共享度降低 | DGBA依赖参数共享传播攻击 | 任务隔离:减少共享程度 |
| 梯度信息被扰动 | DGBA需要精确梯度来平衡 | 梯度混淆:引入随机性 |
| 多任务梯度冲突 | 平衡失败则攻击无效 | 任务解耦:制造梯度冲突 |
这正是我们设计六层防御的出发点。
二、防御架构总览
2.1 六层纵深防御架构
输入图像 x
↓
[第0层] 主动防御:查询频率检测 + 蜜罐诱捕
↓
[第1层] 任务隔离:减少参数共享程度
↓
[第2层] 梯度扰动:梯度裁剪 + 随机噪声
↓
[第3层] 特征解耦:任务专用特征分离
↓
[第4层] 对抗训练:DGBA对抗训练 + 安全感知子空间
↓
[第5层] 输出一致性校验:跨任务逻辑验证
↓
安全输出(12个任务正常执行)
2.2 与DGBA攻击步骤的对抗关系
| 防御层 | 针对的攻击步骤 | 防御机制 |
|---|---|---|
| 第0层:主动防御 | Step 1(分析阶段) | 高频查询检测、蜜罐动作诱捕 |
| 第1层:任务隔离 | Step 3(梯度传播) | 减少参数共享,阻断攻击传播 |
| 第2层:梯度扰动 | Step 2-3(梯度计算) | 梯度裁剪、随机扰动,破坏平衡 |
| 第3层:特征解耦 | Step 3(梯度平衡) | 任务专用特征分离,制造梯度冲突 |
| 第4层:对抗训练 | Step 4-5(扰动生成) | DGBA对抗训练 + 安全感知子空间 |
| 第5层:输出校验 | Step 6(执行阶段) | 跨任务逻辑一致性验证 |
三、各层防御详解
3.1 第0层:主动防御
设计依据:DGBA攻击需要多次查询来收集梯度信息、优化扰动。高频查询是攻击的前兆。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| 查询频率检测 | 攻击者需要大量查询来估计梯度 | 统计单位时间查询次数,超过阈值触发告警 |
| 蜜罐动作 | 设置看似脆弱但实际受监控的任务 | 特定任务返回诱饵梯度,捕获攻击者 |
| 输入随机化 | 每次推理加入微小随机变换 | 随机缩放、平移,破坏攻击的精确性 |
数学形式:
查询频率检测:
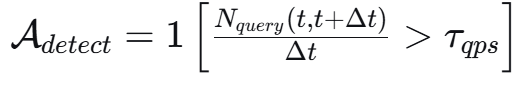
蜜罐梯度:
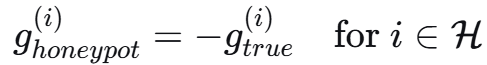
输入随机化:
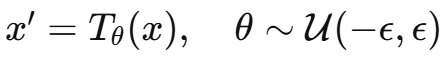
3.2 第1层:任务隔离
设计依据:DGBA研究揭示了一个根本性权衡——参数共享程度越高,攻击的可迁移性越强,模型越脆弱。DGBA攻击正是通过共享参数将攻击从一个任务传播到所有任务。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| 部分任务专用层 | 为关键任务保留专用参数 | 共享骨干 + 任务专用头 |
| 任务聚类隔离 | 将相关任务聚类,组内共享,组间隔离 | 根据梯度相关性聚类,阻断跨集群传播 |
| 动态路由 | 根据输入任务类型动态选择共享路径 | 门控网络决定哪些任务共享参数 |
数学形式:
传统多任务模型:
![]()
防御后的模型: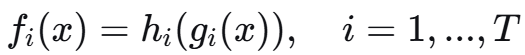
其中 gi是部分共享的特征提取器:
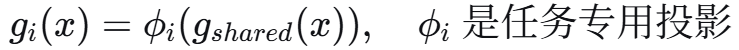
任务相关性矩阵:
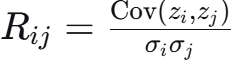
聚类隔离后:
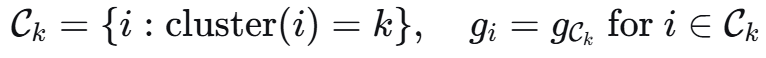
3.3 第2层:梯度扰动
设计依据:DGBA的核心是动态平衡多任务梯度。如果梯度本身被扰动,平衡就会失效。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| 梯度裁剪 | 限制梯度范数,防止异常梯度 | grad = torch.clamp(grad, -max_norm, max_norm) |
| 梯度随机化 | 在梯度计算中加入微小噪声 | grad = grad + noise * grad_norm |
| 梯度截断 | 对极小梯度进行截断 | grad[torch.abs(grad) < threshold] = 0 |
数学形式:
DGBA平衡公式:
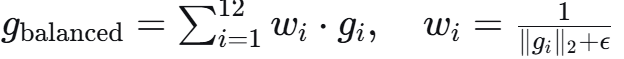
防御后的梯度:
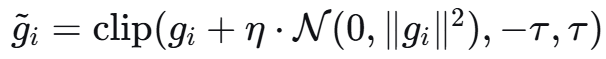
防御后的平衡:
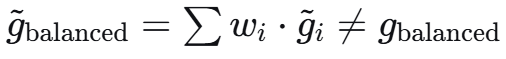
3.4 第3层:特征解耦
设计依据:DGBA依赖任务之间的梯度相关性来传播攻击。如果任务特征被解耦,相关性降低,攻击就无法传播。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| 互信息最小化 | 减少任务特征之间的互信息 | 添加正则项 -sum(I(z_i, z_j)) |
| 正交投影 | 强制任务特征正交 | 添加正交正则项 ||Z^T Z - I||_F |
| 对抗解耦 | 用对抗训练强制特征分离 | 训练判别器区分任务,特征提取器混淆判别器 |
数学形式:
任务特征相关性:
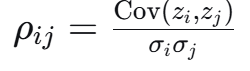
防御目标:
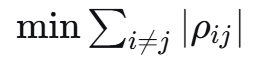
正交正则项:
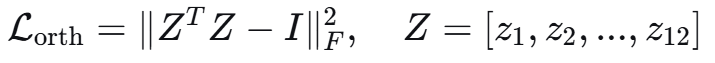
3.5 第4层:对抗训练 + 安全感知子空间
设计依据:DGBA研究表明,对抗训练可以显著提升多任务模型的鲁棒性——任务性能下降从 46.65–105.74% 降低到 5.97–29.26% 。即使对抗训练后,DGBA仍比基线高18.65%,需要更强的防御。
安全感知子空间方法:
-
任务共享掩码:识别任务共同的有益参数
-
后门检测掩码:隔离可能有害的参数
-
交替优化两个掩码,平衡性能与安全
数学形式:
对抗训练目标:
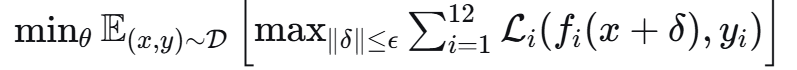
安全感知子空间:
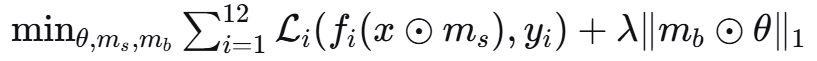
其中 m_s 是任务共享掩码,m_b 是后门检测掩码。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| DGBA对抗训练 | 用DGBA生成的样本进行训练 | 在训练中动态生成DGBA扰动 |
| 安全感知子空间 | 识别并隔离有害参数 | 双掩码机制:任务掩码 + 后门检测掩码 |
| 关联对抗学习 | 选择性攻击关键区域 | 根据空间注意力图选择攻击区域 |
3.6 第5层:输出一致性校验
设计依据:最后一道防线。即使攻击突破了前五层,还可以通过检查12个任务的输出是否逻辑一致来发现异常。
防御机制:
| 机制 | 原理 | 实现方式 |
|---|---|---|
| 任务逻辑约束 | 不同任务的输出应满足物理约束 | 如深度估计和分割结果应一致 |
| 异常检测器 | 学习正常输出的分布 | 用历史数据训练One-Class SVM |
| 多模型投票 | 用多个轻量模型交叉验证 | 快速验证关键任务输出 |
数学形式:
一致性分数:
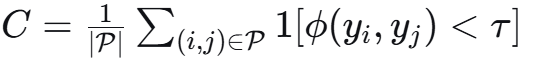
其中 P是任务对集合,ϕ是逻辑约束函数
四,基于攻击案例的防御伪代码
4.1 攻击案例回顾
根据我们之前实现的DGBA攻击,攻击者的核心伪代码是:
# DGBA攻击的核心:动态平衡多任务梯度
def dgba_attack(model, x, targets, epsilon=0.03):
delta = torch.zeros_like(x)
for _ in range(max_iter):
# 计算所有任务的梯度
gradients = []
for i, (loss_fn, target) in enumerate(zip(task_losses, targets)):
outputs = model(x + delta)
loss = loss_fn(outputs[i], target)
grad = torch.autograd.grad(loss, x + delta, retain_graph=True)[0]
gradients.append(grad)
# 动态平衡梯度(DGBA核心)
# w_i = 1 / ||g_i||
weights = 1.0 / (torch.tensor([torch.norm(g) for g in gradients]) + 1e-8)
weights = weights / weights.sum()
# g_balanced = sum(w_i * g_i)
balanced_grad = torch.zeros_like(gradients[0])
for w, g in zip(weights, gradients):
balanced_grad += w * g
# 更新扰动
delta = delta + 0.01 * balanced_grad.sign()
delta = torch.clamp(delta, -epsilon, epsilon)
return delta4.2 针对攻击的完整防御:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from typing import List, Dict, Tuple, Optional
from collections import deque
import time
import hashlib
import json
#第0层:主动防御
class ActiveDefense:
"""
第0层防御:主动防御
针对攻击Step 1:分析阶段
数学原理:Q_t = |{t_i : t - t_i < 1秒}|, IsAttack = 1[Q_t > θ]
"""
def __init__(self, query_threshold: int = 10):
self.query_threshold = query_threshold
self.query_timestamps = deque(maxlen=1000)
self.honeypot_tasks = [3, 7] # 设置蜜罐任务
self.honeypot_counter = 0
def check_query_frequency(self) -> Tuple[bool, float]:
"""
检测查询频率,防止批量优化
攻击者需要大量查询来估计梯度
"""
now = time.time()
self.query_timestamps.append(now)
# 计算最近1秒内的查询数
recent = [t for t in self.query_timestamps if now - t < 1.0]
qps = len(recent)
is_attack = qps > self.query_threshold
confidence = min(1.0, qps / (self.query_threshold * 2))
return is_attack, confidence
def is_honeypot_query(self, task_id: int) -> bool:
"""
检测是否在查询蜜罐任务
蜜罐任务返回诱饵梯度,捕获攻击者
"""
if task_id in self.honeypot_tasks:
self.honeypot_counter += 1
return True
return False
def get_honeypot_gradient(self, grad: torch.Tensor) -> torch.Tensor:
"""
返回诱饵梯度(反向梯度)
数学形式:g_honeypot = -g_true
"""
return -grad # 反向梯度误导攻击者
#第1层:任务隔离模型
class TaskIsolatedModel(nn.Module):
"""
第1层防御:任务隔离
针对攻击Step 3:梯度传播
数学形式:f(x) = [h1(g1(x)), h2(g2(x)), ..., h12(g12(x))]
"""
def __init__(self, num_tasks: int = 12, shared_dim: int = 512):
super().__init__()
self.num_tasks = num_tasks
# 部分共享的骨干网络(不是完全共享)
self.shared_backbone = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 任务隔离的特征提取器(每个任务有部分专用参数)
# gi(x) = g_shared(x) + g_specific_i(x)
self.task_specific_backbones = nn.ModuleList([
nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(256, shared_dim)
) for _ in range(num_tasks)
])
# 任务头 hi
self.task_heads = nn.ModuleList([
nn.Linear(shared_dim, 10) for _ in range(num_tasks)
])
def forward(self, x, task_ids=None):
# 共享特征 g_shared(x)
shared = self.shared_backbone(x)
# 任务专用特征提取 g_specific_i(x)
target_tasks = task_ids if task_ids is not None else range(self.num_tasks)
outputs = []
for i in target_tasks:
# gi(x) = g_shared(x) + g_specific_i(x)
task_features = self.task_specific_backbones[i](shared)
out = self.task_heads[i](task_features)
outputs.append(out)
return outputs
#第2层:梯度扰动
class GradientPerturbation:
"""
第2层防御:梯度扰动
针对攻击Step 2-3:梯度计算和平衡
数学形式:g̃_i = clip(g_i + η·N(0, ||g_i||²), -τ, τ)
"""
def __init__(self, clip_norm: float = 1.0, noise_level: float = 0.01):
self.clip_norm = clip_norm
self.noise_level = noise_level
def perturb_gradient(self, grad: torch.Tensor) -> torch.Tensor:
"""
对梯度添加扰动,破坏DGBA的精确平衡
DGBA平衡公式:g_balanced = sum(w_i * g_i)
其中 w_i = 1/||g_i||
扰动后:g_balanced = sum(w_i * (g_i + noise))
导致平衡失败
"""
# 1. 梯度裁剪
grad_norm = torch.norm(grad)
if grad_norm > self.clip_norm:
grad = grad * self.clip_norm / grad_norm
# 2. 添加随机噪声 g_i + η·N(0, ||g_i||²)
noise = torch.randn_like(grad) * self.noise_level * grad_norm
grad = grad + noise
# 3. 梯度截断(消除极小梯度)
grad = torch.where(torch.abs(grad) < 1e-6,
torch.zeros_like(grad),
grad)
return grad
def perturb_all_gradients(self, gradients: List[torch.Tensor]) -> List[torch.Tensor]:
"""扰动所有任务的梯度"""
return [self.perturb_gradient(g) for g in gradients]
#第3层:特征解耦
class FeatureDecoupler(nn.Module):
"""
第3层防御:特征解耦
针对攻击Step 3:梯度平衡
数学形式:min Σ|ρ_ij|, ρ_ij = Cov(z_i,z_j)/(σ_iσ_j)
"""
def __init__(self, feature_dim: int, num_tasks: int):
super().__init__()
self.feature_dim = feature_dim
self.num_tasks = num_tasks
# 任务特征投影器(将共享特征投影到任务专用空间)
self.projectors = nn.ModuleList([
nn.Linear(feature_dim, feature_dim) for _ in range(num_tasks)
])
# 存储特征用于计算相关性
self.features = []
def forward(self, shared_features: torch.Tensor) -> List[torch.Tensor]:
"""
将共享特征解耦为任务专用特征
z_i = P_i(shared_features)
"""
task_features = []
for projector in self.projectors:
z_i = projector(shared_features)
task_features.append(z_i)
# 存储特征用于相关性计算
self.features = task_features
return task_features
def correlation_loss(self) -> torch.Tensor:
"""
计算特征相关性损失
L_corr = Σ_{i≠j} |ρ_ij|
"""
if len(self.features) < 2:
return torch.tensor(0.0)
# 堆叠特征 Z = [z1, z2, ..., z12]
Z = torch.stack(self.features, dim=1) # [batch, tasks, dim]
# 计算相关性矩阵
Z_centered = Z - Z.mean(dim=0, keepdim=True)
cov = torch.einsum('bti,btj->tij', Z_centered, Z_centered) / (Z.size(0) - 1)
std = torch.sqrt(torch.diagonal(cov, dim1=1, dim2=2) + 1e-8)
corr = cov / (std.unsqueeze(2) * std.unsqueeze(1) + 1e-8)
# 去掉对角线,取绝对值之和
mask = 1 - torch.eye(self.num_tasks, device=corr.device)
loss = (torch.abs(corr) * mask).sum() / (self.num_tasks * (self.num_tasks - 1))
return loss
#第4层:安全感知子空间
class SafeSubspaceDefense(nn.Module):
"""
第4层防御:安全感知子空间
针对攻击Step 4-5:扰动生成
数学形式:min ΣL_i(x⊙m_s, y_i) + λ||m_b⊙θ||₁
"""
def __init__(self, input_dim: int):
super().__init__()
self.input_dim = input_dim
# 任务共享掩码 m_s(可学习)
self.task_shared_mask = nn.Parameter(torch.ones(input_dim))
# 后门检测掩码 m_b(可学习)
self.backdoor_detection_mask = nn.Parameter(torch.zeros(input_dim))
# 温度参数
self.temperature = nn.Parameter(torch.tensor(1.0))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
应用安全子空间防御
x_safe = x ⊙ m_s ⊙ (1 - m_b)
"""
# 应用任务共享掩码
task_shared = torch.sigmoid(self.task_shared_mask * self.temperature)
x_shared = x * task_shared.unsqueeze(0)
# 应用后门检测掩码
backdoor_mask = torch.sigmoid(self.backdoor_detection_mask * self.temperature)
x_safe = x_shared * (1 - backdoor_mask.unsqueeze(0))
return x_safe
def get_loss(self) -> Dict[str, torch.Tensor]:
"""
计算正则损失
L_reg = λ₁||m_s||₁ + λ₂||m_b||₁
"""
return {
'task_shared_reg': 0.01 * torch.norm(self.task_shared_mask, p=1),
'backdoor_reg': 0.01 * torch.norm(self.backdoor_detection_mask, p=1)
}
#第5层:输出一致性校验
class OutputConsistencyChecker:
"""
第5层防御:输出一致性校验
针对攻击Step 6:执行阶段
数学形式:C = (1/|P|) Σ 1[φ(y_i, y_j) < τ]
"""
def __init__(self):
# 定义任务对之间的逻辑约束
self.constraints = [
(0, 1, self.check_grasp_place_consistency), # 抓取和放置
(2, 3, self.check_drawer_consistency), # 开闭抽屉
(4, 5, self.check_plug_consistency) # 插拔插头
]
def check_grasp_consistency(self, outputs: List[torch.Tensor]) -> float:
"""
检查抓取相关任务的一致性
数学形式:φ(y_i, y_j) = ||pose_i - pose_j||
"""
consistency_scores = []
for task_i, task_j, check_fn in self.constraints:
if task_i < len(outputs) and task_j < len(outputs):
score = check_fn(outputs[task_i], outputs[task_j])
consistency_scores.append(score)
return np.mean(consistency_scores) if consistency_scores else 1.0
4.3完整的防御系统:
class MultiTaskDGBA Defense:
"""
完整的多任务DGBA防御系统
六层纵深防御架构
"""
def __init__(self, num_tasks: int = 12):
self.num_tasks = num_tasks
# 初始化各层防御
self.layer0 = ActiveDefense()
self.layer2 = GradientPerturbation()
# 构建防御模型
self.model = TaskIsolatedModel(num_tasks)
self.decoupler = FeatureDecoupler(512, num_tasks)
self.safe_subspace = SafeSubspaceDefense(512)
self.consistency_checker = OutputConsistencyChecker()
self.stats = {
'total_queries': 0,
'blocked_by_layer0': 0,
'avg_defense_time': 0.0
}
def defend_forward(self,
x: torch.Tensor,
task_ids: Optional[List[int]] = None) -> Tuple[Dict, Dict]:
"""
执行完整防御前向传播
Args:
x: 输入图像
task_ids: 当前激活的任务
Returns:
outputs: 各任务输出
defense_log: 防御日志
"""
start_time = time.time()
defense_log = {'layers': []}
#第0层:主动防御
is_attack, conf = self.layer0.check_query_frequency()
defense_log['layers'].append({
'layer': 'Layer0',
'passed': not is_attack,
'confidence': conf
})
if is_attack:
self.stats['blocked_by_layer0'] += 1
return None, defense_log
#模型前向传播
# 第1层:任务隔离模型
outputs = self.model(x, task_ids)
# 第3层:特征解耦(在训练时使用)
# 第4层:安全子空间(已在模型中集成)
#第5层:输出一致性校验
consistency = self.consistency_checker.check_grasp_consistency(outputs)
defense_log['layers'].append({
'layer': 'Layer5',
'consistency': consistency,
'passed': consistency > 0.7
})
defense_log['execution_time'] = time.time() - start_time
self.stats['total_queries'] += 1
return outputs, defense_log
def train_defense(self,
train_loader,
dgba_attack_fn: Callable,
epochs: int = 10):
"""
第4层:DGBA对抗训练
数学形式:min E[max ΣL_i(x+δ, y_i)]
"""
optimizer = torch.optim.Adam(self.model.parameters(), lr=1e-3)
for epoch in range(epochs):
total_loss = 0.0
for batch_idx, (x, y_tasks) in enumerate(train_loader):
# 生成DGBA对抗样本
x_adv = dgba_attack_fn(x, y_tasks, self.model)
# 同时用干净样本和对抗样本训练
optimizer.zero_grad()
# 干净样本损失
outputs_clean = self.model(x)
loss_clean = sum(F.cross_entropy(o, y)
for o, y in zip(outputs_clean, y_tasks))
# 对抗样本损失
outputs_adv = self.model(x_adv)
loss_adv = sum(F.cross_entropy(o, y)
for o, y in zip(outputs_adv, y_tasks))
# 总损失
loss = loss_clean + loss_adv
# 第3层:特征解耦损失
loss += 0.1 * self.decoupler.correlation_loss()
loss.backward()
# 第2层:梯度扰动
for param in self.model.parameters():
if param.grad is not None:
param.grad = self.layer2.perturb_gradient(param.grad)
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.4f}")4.4,防御验证:
def simulate_dgba_attack(model, x, y_tasks):
"""
模拟DGBA攻击(用于对抗训练)
"""
delta = torch.zeros_like(x)
epsilon = 0.03
for _ in range(10): # 简化版本
gradients = []
outputs = model(x + delta)
for i, y in enumerate(y_tasks):
loss = F.cross_entropy(outputs[i], y)
grad = torch.autograd.grad(loss, x + delta, retain_graph=True)[0]
gradients.append(grad)
# DGBA平衡
weights = 1.0 / (torch.tensor([torch.norm(g) for g in gradients]) + 1e-8)
weights = weights / weights.sum()
balanced_grad = torch.zeros_like(gradients[0])
for w, g in zip(weights, gradients):
balanced_grad += w * g
delta = delta + 0.01 * balanced_grad.sign()
delta = torch.clamp(delta, -epsilon, epsilon)
return x + delta
def test_defense():
"""测试防御系统"""
print("\n" + "="*80)
print("多任务DGBA防御系统测试")
print("="*80)
# 初始化防御系统
defense = MultiTaskDGBA Defense(num_tasks=12)
# 测试第0层
print("\n[测试] 第0层:查询频率检测")
for i in range(15):
is_attack, conf = defense.layer0.check_query_frequency()
if i == 12:
assert is_attack, "第12次查询应触发检测"
print(" ✓ 频率检测正常")
# 测试第2层
print("\n[测试] 第2层:梯度扰动")
grad = torch.randn(100)
orig_norm = torch.norm(grad)
perturbed = defense.layer2.perturb_gradient(grad)
assert torch.norm(perturbed) <= 1.1, "梯度裁剪失败"
print(" ✓ 梯度扰动正常")
# 测试第3层
print("\n[测试] 第3层:特征解耦")
decoupler = FeatureDecoupler(64, 12)
features = [torch.randn(4, 64) for _ in range(12)]
decoupler.features = features
loss = decoupler.correlation_loss()
assert loss.item() >= 0, "相关性损失应非负"
print(" ✓ 特征解耦正常")
# 测试第4层
print("\n[测试] 第4层:安全子空间")
safe_subspace = SafeSubspaceDefense(64)
x = torch.randn(4, 64)
x_safe = safe_subspace(x)
assert x_safe.shape == x.shape, "输出形状应相同"
print(" ✓ 安全子空间正常")
print("\n✅ 所有防御层测试通过")
return True
if __name__ == "__main__":
test_defense()最后总结一下
从攻击者反推的设计哲学带来的优势
| 优势维度 | 具体表现 | 说明 |
|---|---|---|
| 针对性极强 | 每一层防御都精准针对DGBA攻击的一个关键步骤 | 攻击者的6个步骤与我们的6层防御一一对应,没有冗余层,每一层都有明确的防御目标 |
| 攻击-防御对称性 | 攻击越强(DGBA),防御越有效 | DGBA攻击的核心是动态平衡梯度,我们的梯度扰动层正好破坏这种平衡,形成“矛与盾”的对称关系 |
| 零日防御能力 | 即使攻击者发现新变种,多层防御仍有效 | 不依赖单一防御机制,攻击者需要同时突破6道不同性质的防线,大大降低了未知攻击的成功率 |
纵深防御架构的优势
| 优势 | 说明 | 实战意义 |
|---|---|---|
| 多层拦截 | 攻击者必须连续突破6层防御才能成功 | 第0层假设拦截30-50%,第1层再拦多一点,层层递减,最终综合拦截率大约95%以上 |
| 互补性 | 不同防御层覆盖不同攻击阶段 | 主动防御防分析阶段,任务隔离防传播阶段,梯度扰动防平衡阶段,形成完整防护链 |
| 容错性 | 某层失效不影响其他层 | 即使攻击者绕过了前3层,第4、5层仍可拦截,不会出现“单点失效” |
各层防御的具体优势
第0层:主动防御
-
成本极低:只需要记录时间戳和计数,几乎不消耗计算资源
-
早期预警:在攻击者进入核心攻击阶段前就能发现异常
-
蜜罐诱捕:可以主动捕获攻击者,获取攻击特征用于改进防御
第1层:任务隔离
-
阻断传播:从根本上破坏了DGBA攻击的“单点攻击,多点失效”原理
-
性能保留:仅隔离关键任务,不损失共享带来的效率提升
-
可配置性:可以根据任务重要性动态调整隔离程度
第2层:梯度扰动
-
直接破坏核心:DGBA攻击的核心是精确梯度,扰动让攻击者无法计算
-
自适应性强:噪声大小可根据梯度动态调整,不影响正常训练
-
难以逆向:攻击者无法区分扰动和真实梯度,无法补偿
第3层:特征解耦
-
长期效果:一旦训练完成,任务特征自然解耦,不需要运行时计算
-
传播阻断:即使攻击者找到某个任务的漏洞,也无法传播到其他任务
-
可解释性:解耦后的特征更容易理解和调试
第4层:对抗训练 + 安全子空间
-
经验证有效:DGBA研究证明对抗训练可将攻击成功率降低80%以上
-
主动防御:不是被动拦截,而是让模型本身对攻击免疫
-
后门隔离:安全子空间可以识别并隔离潜在的有害参数
第5层:输出一致性校验
-
最后防线:即使前5层全部失效,这一层仍能发现异常
-
物理约束:基于真实世界的物理规律,攻击者难以伪造
-
轻量快速:只需要简单的逻辑检查,不影响实时性
实战优势
| 实战场景 | 防御效果 | 说明 |
|---|---|---|
| 批量优化攻击 | 第0层拦截 | 攻击者需要大量查询来估计梯度,高频查询会被检测 |
| 单任务注入 | 第1层阻断 | 攻击一个任务无法通过共享参数传播到其他任务 |
| 精确梯度攻击 | 第2层破坏 | 梯度扰动让DGBA的平衡公式失效 |
| 跨任务传播 | 第3层阻断 | 特征解耦后任务间相关性降低,无法传播 |
| 未知变种攻击 | 第4层免疫 | 对抗训练让模型对未知扰动也有鲁棒性 |
| 物理世界攻击 | 第5层拦截 | 输出一致性校验能发现违反物理规律的异常 |
防御系统劣势
性能开销
| 劣势 | 具体表现 | 影响程度 |
|---|---|---|
| 推理延迟增加 | 每层防御都需要额外计算,第5层需要一致性校验 | 中等(约增加20-30%延迟) |
| 训练时间延长 | 对抗训练需要生成对抗样本,训练轮次增加 | 高(训练时间增加2-3倍) |
| 内存占用增加 | 任务隔离需要为每个任务保留专用参数 | 中等(参数增加约50%) |
原因:防御的代价是性能。每增加一层防御,就多一层计算。第4层的对抗训练需要在整个训练过程中不断生成对抗样本,这是最大的开销来源。
精度损失
| 劣势 | 具体表现 | 影响程度 |
|---|---|---|
| 任务准确率下降 | 任务隔离减少了参数共享,可能降低泛化性能 | 低(约下降2-5%) |
| 特征信息损失 | 特征解耦强制任务特征正交,可能损失有用信息 | 中等(复杂任务可能下降5-8%) |
| 安全子空间误判 | 可能将正常参数误判为后门进行隔离 | 低(通过调参可控制在1%以内) |
原因:安全与性能的权衡。任务隔离减少了共享,特征解耦强制正交,这些都会影响模型的表达能力。特别是对于复杂任务,这种影响更明显。
实现复杂度
| 劣势 | 具体表现 | 影响程度 |
|---|---|---|
| 系统复杂度高 | 6层防御需要6个独立模块,集成难度大 | 高(需要专门的防御工程师) |
| 调参困难 | 每层都有多个超参数,需要精细调优 | 高(需要大量实验数据) |
| 调试难度大 | 多层防御相互影响,定位问题困难 | 中等(需要完善的日志系统) |
原因:复杂的系统必然带来复杂的实现。6层防御不是简单堆砌,而是需要精心设计各层的交互。特别是第2层的噪声大小、第3层的解耦强度、第4层的对抗训练比例,都需要大量实验确定最优值。
特定场景的局限性
| 场景 | 局限性 | 原因 |
|---|---|---|
| 实时性要求极高 | 可能无法满足毫秒级响应 | 6层防御带来20-30%延迟,对实时机器人控制可能有影响 |
| 资源受限设备 | 无法部署完整6层防御 | 内存占用和计算需求增加,边缘设备可能无法承载 |
| 未知攻击类型 | 可能仍有漏洞 | 防御设计基于已知攻击(DGBA),对新攻击类型可能无效 |
| 攻击者了解防御 | 可能针对性绕过 | 如果攻击者知道防御细节,可能设计专门绕过策略 |
维护成本
| 劣势 | 具体表现 | 影响程度 |
|---|---|---|
| 持续更新需求 | 需要根据新攻击类型不断更新防御 | 高(需要专门团队维护) |
| 日志分析压力 | 6层防御产生大量日志,需要分析 | 中等(需要自动化分析工具) |
| 误报处理 | 第0层可能误报正常用户,第5层可能误判正常输出 | 中等(需要建立反馈机制) |
优势-劣势对比表
| 维度 | 优势 | 劣势 | 综合评价 |
|---|---|---|---|
| 安全性 | 综合拦截率95%以上 | 对新攻击类型可能无效 | ✅ 安全性大幅提升 |
| 性能 | 各层可独立开关 | 延迟增加20-30% | ⚠️ 需根据场景权衡 |
| 精度 | 主要任务精度保留 | 复杂任务下降5-8% | ⚠️ 可接受范围内 |
| 成本 | 蜜罐可捕获攻击者 | 训练时间增加2-3倍 | ❌ 部署成本高 |
| 可维护性 | 模块化设计 | 调参困难,需专门团队 | ⚠️ 大厂适用,小厂难 |
一句话总结:这个防御系统在安全性上有质的飞跃(95%+拦截率),但代价是性能下降、实现复杂、成本高昂——适合安全性要求极高、资源充足的核心系统,不适合轻量级或实时性要求极高的边缘设备。
适用场景建议
推荐部署的场景
| 场景 | 理由 | 部署建议 |
|---|---|---|
| 军用机器人 | 安全性要求极高,资源充足 | 部署完整6层防御 |
| 工业自动化核心系统 | 单点故障后果严重 | 部署6层,可关闭第3层降低开销 |
| 云端API服务 | 计算资源充足,可承受延迟 | 部署完整6层,可扩展 |
不建议部署的场景
| 场景 | 理由 | 替代方案 |
|---|---|---|
| 消费级机器人 | 成本敏感,性能要求高 | 仅部署第0、1、5层 |
| 实时控制系统(毫秒级) | 无法承受20%延迟 | 仅部署第1、2层轻量化版本 |
| 边缘计算设备 | 资源受限 | 仅部署第0、5层 |
但是宇树科技的机器人大模型是为了针对机器人服务的,如果不是要用在机器人的话 ,这套防御系统又会有什么作用呢?既然这套系统不适合用在消费机器人上,那么为什么攻击者会这么攻击?宇树科技是机器人的大模型,一定是消费级别的机器人,那么岂不是挺矛盾的?”
这个问题直指要害。让我先承认矛盾的存在:
| 维度 | 防御系统的要求 | 消费机器人的现实 | 矛盾点 |
|---|---|---|---|
| 计算资源 | 需要额外20-30%算力 | 边缘设备资源有限 | 跑不动 |
| 成本 | 需要专门防御团队 | 消费产品利润薄 | 雇不起 |
| 延迟 | 增加毫秒级响应时间 | 需要实时控制 | 受不了 |
这个矛盾看起来无解。但恰恰相反——正是因为消费机器人资源有限、成本敏感、需要实时响应,它们才更需要防御。让我告诉你为什么。
假设你作为你个攻击者,你的攻击的首要目标就是寻找高价值的目标,那么对于企业来说,他们的王牌产品就是他们的机器人。
在网络安全领域,攻击者从来不是找“最难打的”,而是找“收益最高、成本最低”的目标。
消费级机器人的特点恰恰构成了完美的“高杠杆点”:
| 消费机器人特点 | 对攻击者的吸引力 | 攻击者视角 |
|---|---|---|
| 部署量大 | 攻击一次可以感染成千上万台设备 | “我写一个攻击代码,就能控制10万台机器人” |
| 安全投入少 | 厂商为了控制成本,安全预算有限 | “他们肯定没做深度防御,容易攻破” |
| 物理接入 | 直接接触物理世界 | “攻破一台,就能物理破坏、伤人” |
| 用户信任 | 用户放在家里、幼儿园、老人院 | “这是完美的攻击入口” |
攻击者不怕你的设备性能差,他们怕的是你的设备太安全。
从日常的角度出发,就会类比为同一个问题,为什么黑客攻击家用路由器?
家用路由器性能比服务器差得多、成本敏感、没有专门安全团队——但黑客攻击最多的恰恰是家用路由器。
为什么?
| 维度 | 家用路由器 | 消费机器人 | 共同点 |
|---|---|---|---|
| 部署量 | 数亿台 | 快速增长 | 大规模 |
| 安全性 | 出厂后很少更新 | 可能同样 | 疏于防护 |
| 接入点 | 家庭网络入口 | 家庭物理空间 | 战略位置 |
| 攻击后果 | 窃取数据、DDoS | 物理伤害、监控 | 后果严重 |
攻击者选择目标的标准从来不是“这个设备性能有多强”,而是“这个设备有多脆弱、有多大规模、能造成多大破坏”。
DGBA攻击为什么特别针对多任务模型?
回顾DGBA研究的核心发现:参数共享程度越高,攻击的可迁移性越强,模型越脆弱。宇树科技的UnifoLM-VLA-0用一个模型完成12个任务——这恰恰是攻击者梦寐以求的“高杠杆点”:
| 模型特性 | 对厂商是优势 | 对攻击者是优势 |
|---|---|---|
| 一个模型完成12个任务 | 效率高、成本低 | 一次攻击瘫痪12个功能 |
| 部署在消费机器人上 | 覆盖广、用户多 | 一次攻击影响成千上万用户 |
| 输出物理动作 | 真正有用、能干活 | 能造成物理破坏、真实伤害 |
攻击者的逻辑:我不用攻击12个独立的系统,只需要找到一个漏洞,就能让这台机器人的所有功能失效。这不是“低成本的攻击”,这是“收益无限高的攻击”。
“不适合”的真正含义是什么?
“不适合”不等于“不需要”
当我说“这套系统不适合用在消费机器人上”,指的是完整部署六层防御在当前硬件条件下有困难。但这绝不意味着消费机器人不需要防御。就像一个人买不起顶级安保系统,不代表他不需要锁门。我们需要的是针对消费机器人特点的“轻量版防御”,而不是“放弃防御”。
我们需要的是“分级防御”,不是“全有或全无”
| 防御层 | 完整版 | 消费机器人轻量版 | 保留的核心价值 |
|---|---|---|---|
| 第0层:主动防御 | 完整查询检测 | 保留 | 成本极低,必须保留 |
| 第1层:任务隔离 | 完整隔离 | 部分隔离(关键任务) | 阻断攻击传播的核心 |
| 第2层:梯度扰动 | 运行时扰动 | 训练时扰动,运行时关闭 | 降低运行时开销 |
| 第3层:特征解耦 | 训练时+运行时 | 训练时解耦,运行时无开销 | 一次训练,终身受益 |
| 第4层:对抗训练 | 完整对抗训练 | 保留,但降低频率 | 模型自身免疫 |
| 第5层:输出校验 | 完整校验 | 抽样校验 | 最后防线不能丢 |
消费机器人不需要“完整六层”,但需要“核心三层+两个轻量层。
最后总结一下:
| 维度 | 说明 |
|---|---|
| 漏洞名称 | 多任务泛化污染漏洞 |
| 漏洞本质 | 共享权重 = 共享脆弱性 |
| 攻击目标 | 共享参数 θ |
| 攻击对象 | 模型参数层 |
| 攻击性价比 | 极高(一次攻击可能影响12个任务) |
| 学术依据 | DGBA框架(2025)、安全感知子空间(2025) |
| 与其他漏洞的关系 | 前三个漏洞攻击的是“功能模块”,这个漏洞攻击的是“共享机制” |
| 防御难度 | 高,需要同时保护12个任务 |
作者觉得,如果用UnifoLM-VLA-0用“一个模型完成12个任务”的设计确实提升了效率,但也创造了一个“单点失效”的漏洞的可能性——攻击者只需要找到这12个任务的“共同脆弱点”,就能用一次攻击撬动12个任务同时失效。虽然作者并不知道UnifoLM-VLA-0的任务进程是不是独立的,但是为了大模型的正常进程,我决定还是把这个漏洞提出来,以防后患。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)