英伟达 GB300 NVL72 强势来袭 代理式 AI 性能提 50 倍成本大降
的一份近期分析表明,采用极致软硬件协同设计的 NVIDIA GB200 NVL72 芯片,相较于 NVIDIA Hopper 平台,其每瓦可处理的 token 数提升超过10倍,每 token 成本降至其 1/10。最显著的降幅出现在低延迟场景,即智能体应用运行的领域:每百万 token 的成本是 Hopper 平台的 1/35。通过跨芯片、系统架构和软件领域的创新,NVIDIA 的极致协同设计加
最新 SemiAnalysis InferenceX 数据显示,NVIDIA Blackwell Ultra 在代理式 AI 领域可实现高达 50 倍的性能提升,成本降低至 1/35
包括微软、CoreWeave 和 Oracle Cloud Infrastructure(OCI)在内的云服务提供商,正大规模部署 NVIDIA GB300 NVL72 系统,用于低延迟、长上下文场景,例如智能体编程和编程助手等应用。
NVIDIA Blackwell 平台已被 Baseten、DeepInfra、Fireworks AI 和 Together AI 等领先推理提供商广泛采用,将每 token 成本降至原来的 1/10。如今,NVIDIA Blackwell Ultra 平台正将这一势头进一步推向代理式 AI 领域。
AI 智能体和编程助手正推动软件编程相关 AI 查询量呈现爆发式增长:据 OpenRouter 发布的推理现状报告显示,此类查询占比去年已从 11% 上升至约 50%。此类应用需要低延迟以维持多步骤工作流中的实时响应能力,同时在跨整个代码库进行推理时需支持长上下文处理。
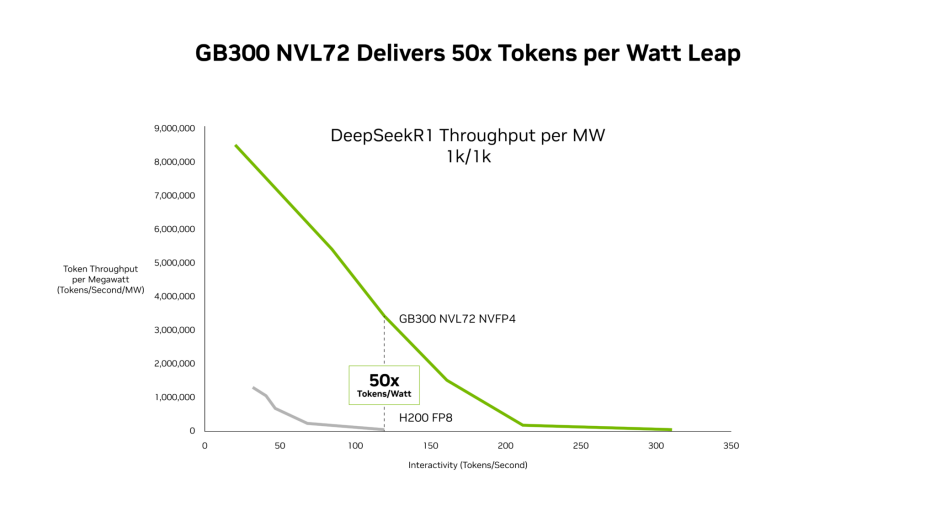
最新 SemiAnalysis InferenceX 性能数据显示,NVIDIA 的软件优化与新一代 Blackwell Ultra 平台的结合在两方面均实现了突破性进展。NVIDIA GB300 NVL72 系统每兆瓦可提供高达 50 倍的吞吐量,每 token 成本降低至 NVIDIA Hopper 平台的 1/35。
通过跨芯片、系统架构和软件领域的创新,NVIDIA 的极致协同设计加速了从智能体编程到交互式编程助手等各类 AI 工作负载的性能提升,同时实现了大规模部署的成本优化。
GB300 NVL72 为低延迟工作负载提供高达 50 倍的性能提升
Signal65 的一份近期分析表明,采用极致软硬件协同设计的 NVIDIA GB200 NVL72 芯片,相较于 NVIDIA Hopper 平台,其每瓦可处理的 token 数提升超过10倍,每 token 成本降至其 1/10。随着底层技术栈的持续优化,这些显著的性能提升空间仍在不断扩大。
NVIDIA TensorRT-LLM、NVIDIA Dynamo、Mooncake 和 SGLang 团队持续进行的优化,显著提升了 Blackwell NVL72 在所有延迟目标下混合专家模型(MoE)推理的吞吐量。例如,NVIDIA TensorRT-LLM 库的改进使 GB200 在低延迟工作负载上的性能较四个月前提升高达 5 倍。
- 更高性能的 GPU 内核经过针对效率和低延迟进行的优化,充分释放了 Blackwell 架构的强大计算能力,显著提升吞吐量。
- NVIDIA NVLink 对称内存支持 GPU 间直接内存访问,实现更高效的数据通信。
- 程序化依赖启动(PDL)通过在前一个内核完成前启动下一个内核的准备阶段,最小化空闲时间。
基于这些软件进步,搭载 Blackwell Ultra GPU 的 GB300 NVL72 将每兆瓦吞吐量提升至 Hopper 平台的 50 倍。
这种性能提升转化为经济效益上的优势,与 Hopper 平台相比,NVIDIA GB300 在整个延迟范围内都可降低成本。最显著的降幅出现在低延迟场景,即智能体应用运行的领域:每百万 token 的成本是 Hopper 平台的 1/35。
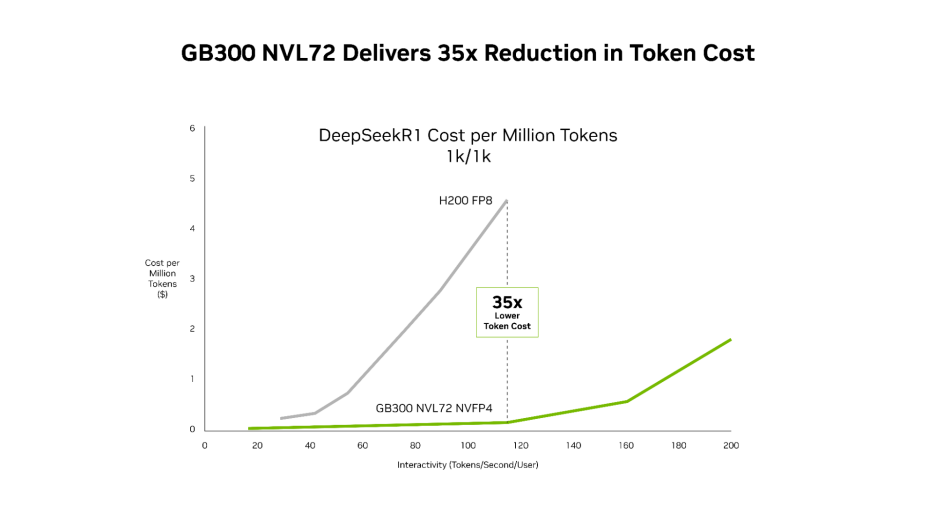
NVIDIA GB300 NVL72 及协同设计的软件栈(包括 NVIDIA Dynamo 和 TensorRT-LLM)相比 NVIDIA Hopper 平台,实现了每 token 成本降低至 1/35。
对于智能体编程和交互式助手这类工作负载,在多步骤工作流中每毫秒的延迟都会累积放大。这种持续的软件优化与新一代硬件的结合,使 AI 平台能够将实时交互体验扩展至更多用户。
GB300 NVL72 为长上下文工作负载提供卓越的经济效益
虽然 GB200 NVL72 和 GB300 NVL72 都能高效实现超低延迟,但 GB300 NVL72 在长上下文场景中的优势尤为突出。对于输入 128,000 token、输出 8,000 token 的工作负载(例如跨代码库推理的 AI 编程助手),GB300 NVL72 的每 token 成本降至 GB200 NVL72 的 2/3。
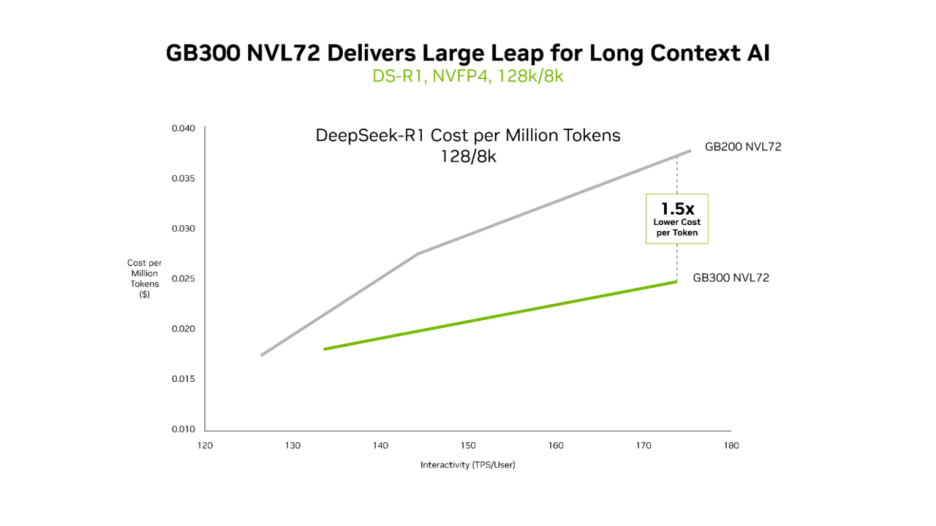
NVIDIA GB300 NVL72 专为低延迟、长上下文工作负载而设计。
随着智能体读取更多代码,上下文逐渐增长。这使其能更深入理解代码库,但也需要更强大的计算能力。Blackwell Ultra 的 NVFP4 计算性能提升 1.5 倍,注意力处理速度提升 2 倍,使智能体能够高效理解整个代码库。
为代理式 AI 打造的基础设施
领先的云服务提供商和 AI 创新者已大规模部署 NVIDIA GB200 NVL72,并正在生产环境中部署 GB300 NVL72。微软、CoreWeave 和 OCI 正将 GB300 NVL72 应用于低延迟、长上下文场景,例如智能体编程和编程助手。通过降低 token 成本,GB300 NVL72 使得能够跨大规模代码库进行实时推理的新型应用成为可能。
CoreWeave 工程高级副总裁 Chen Goldberg 表示:“随着推理成为 AI 生产的核心环节,长上下文性能和 token 效率变得至关重要。Grace Blackwell NVL72 直接解决了这一挑战。基于 GB200 的成功经验,CoreWeave 的 AI 云(包括 CKS 和 SUNK)旨在将 GB300 系统的性能提升转化为可预测的性能表现和成本效率。这将为大规模运行工作负载的客户带来更优的 token 效益和更实用的推理能力。”
NVIDIA Vera Rubin NVL72 将带来新一代性能表现
随着 NVIDIA Blackwell 系统的大规模部署,持续的软件优化将不断释放已部署设备的性能与成本优势。
展望未来,由六款全新芯片构建的 AI 超级计算机NVIDIA Rubin 平台将实现新一轮性能飞跃。对于 MoE 推理,其每兆瓦吞吐量较 Blackwell 提升高达 10 倍,百万 token 成本仅为后者的 1/10。面对新一代前沿 AI 模型,Rubin 仅需 Blackwell 1/4 的 GPU 即可完成大型 MoE 模型的训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)