Text to SQL系统的千层套路~~~(第三层)
看完这一篇,超过95%的Agent工程师。Text-to-SQL 还在死磕 Prompt?快用业务工具化重构系统!不仅响应速度翻倍、Token 暴降,更能解决复杂逻辑。带你拆解实际系统案例,看透 Agent 设计的取舍之道。
你好,我是司沐。
上一期Text to SQL系统的千层套路文末,我们对于文中提到的第三层是什么留了个悬念。今天这期,就来详细讲讲第三层是什么。
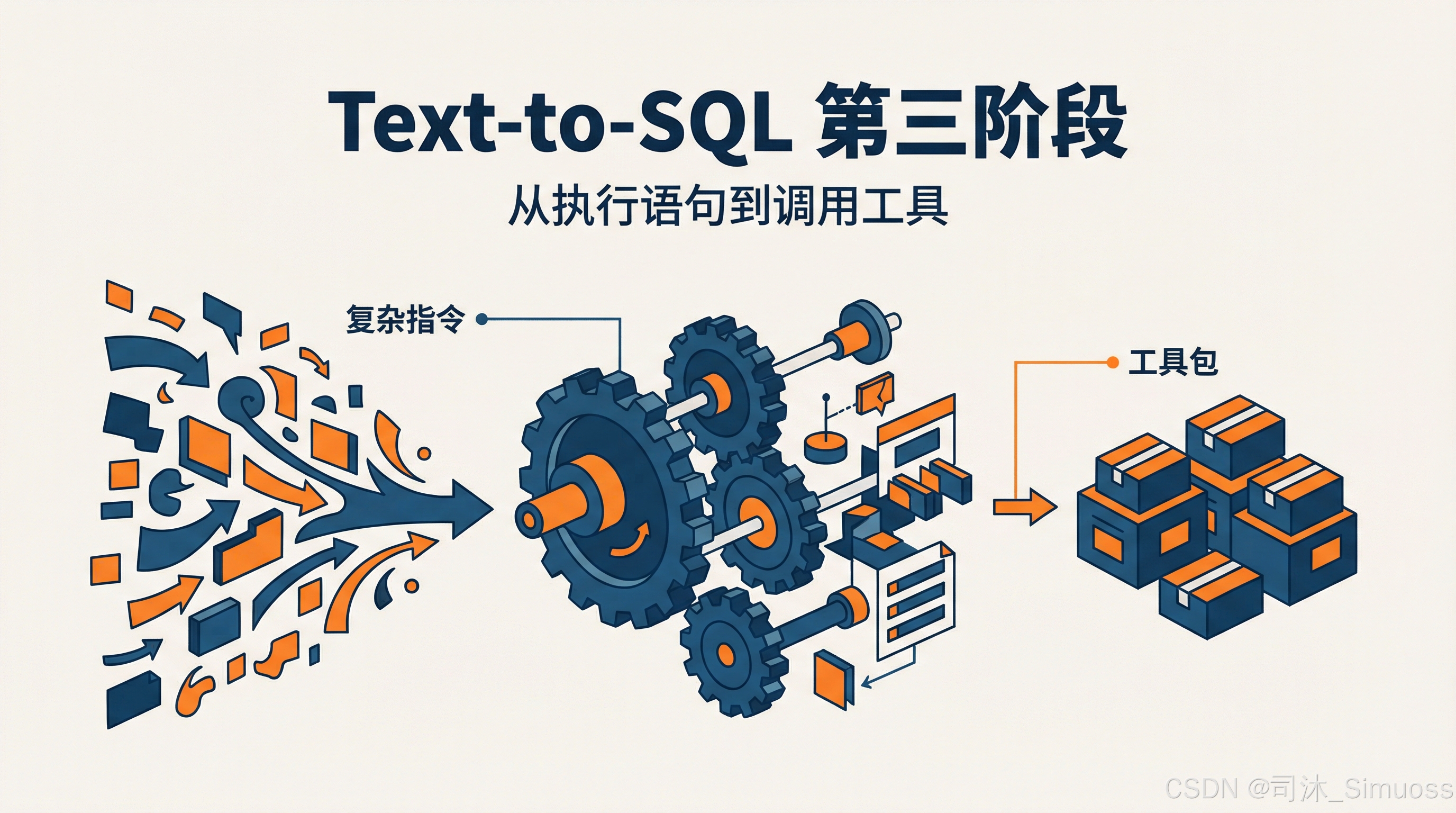
Text-to-SQL 的第三阶段,本质是把一些复杂操作打包成工具,而不是直接由 Agent 去执行 SQL。
而这就需要我们深入业务了。
01 深入业务:以教务系统为例
举一个例子,如果我们在为一所学校设计教务管理系统的 AI 功能,那一个必做事项就是将教务系统抽象成一个模型,并搞清楚这个模型的输入数据跟输出数据一共有哪些。这就是第一步。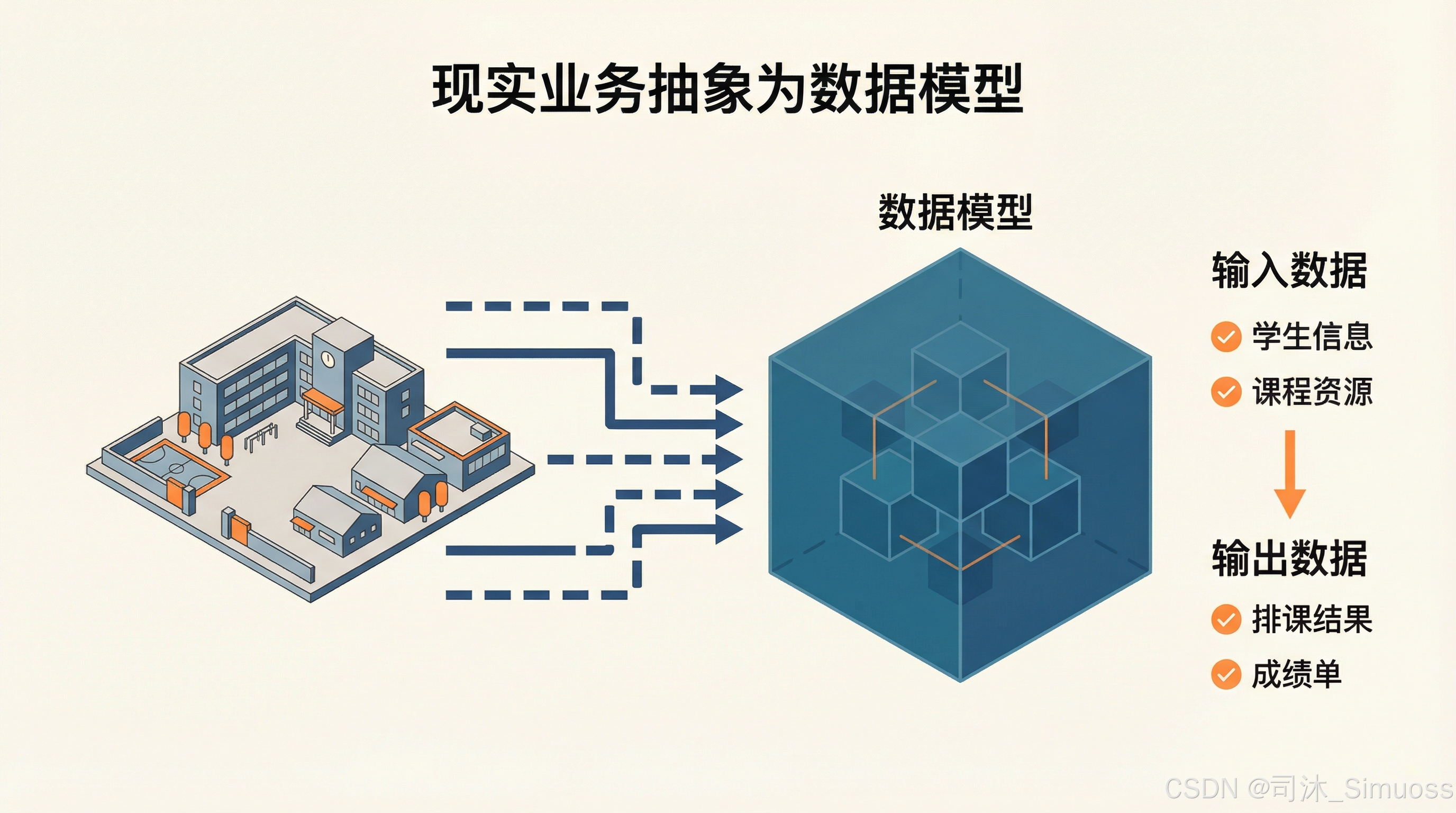
其次,搞清楚我们的用户——比如老师,比如教务系统的管理员——他们通常会在系统上进行哪些操作。
比如上一篇第二阶段里面提到的那种复杂查询,还可能有“为除了 2 班、3 班以外的 2025 级某某学院的学生新建一门课程,且要保证同一时间最多只有两节这种课程同时进行”这样的操作。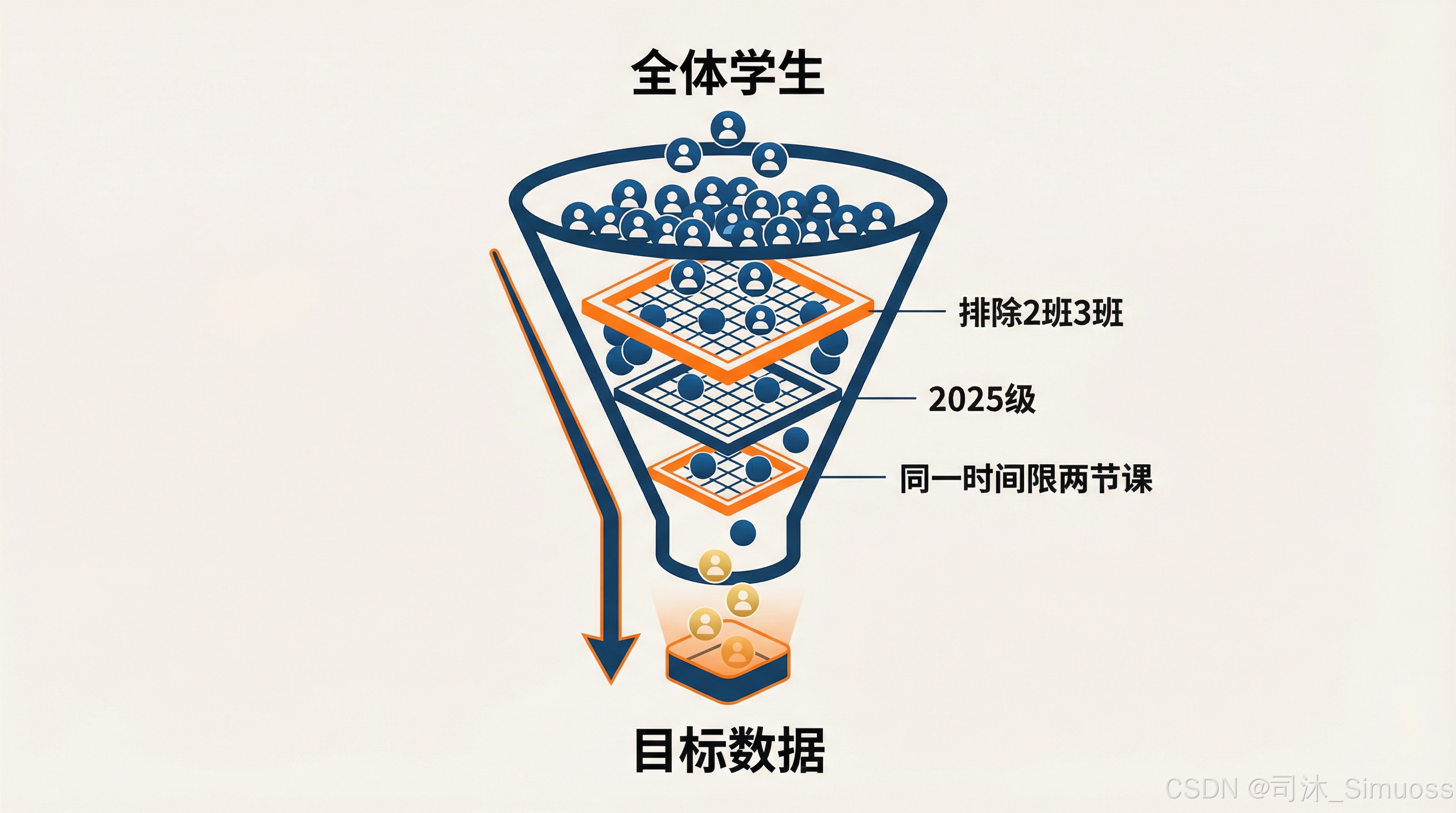
等摸清第二步之后,基本上你对整个业务流程系统就相当了解了,这个时候我们还需要进行第三步:在所有业务中抽象出最核心的查询需求。
这一句如何理解呢?
比如我们刚才的两种业务需求例子中,都至少需要 AI 自己实现一种行为:查课表。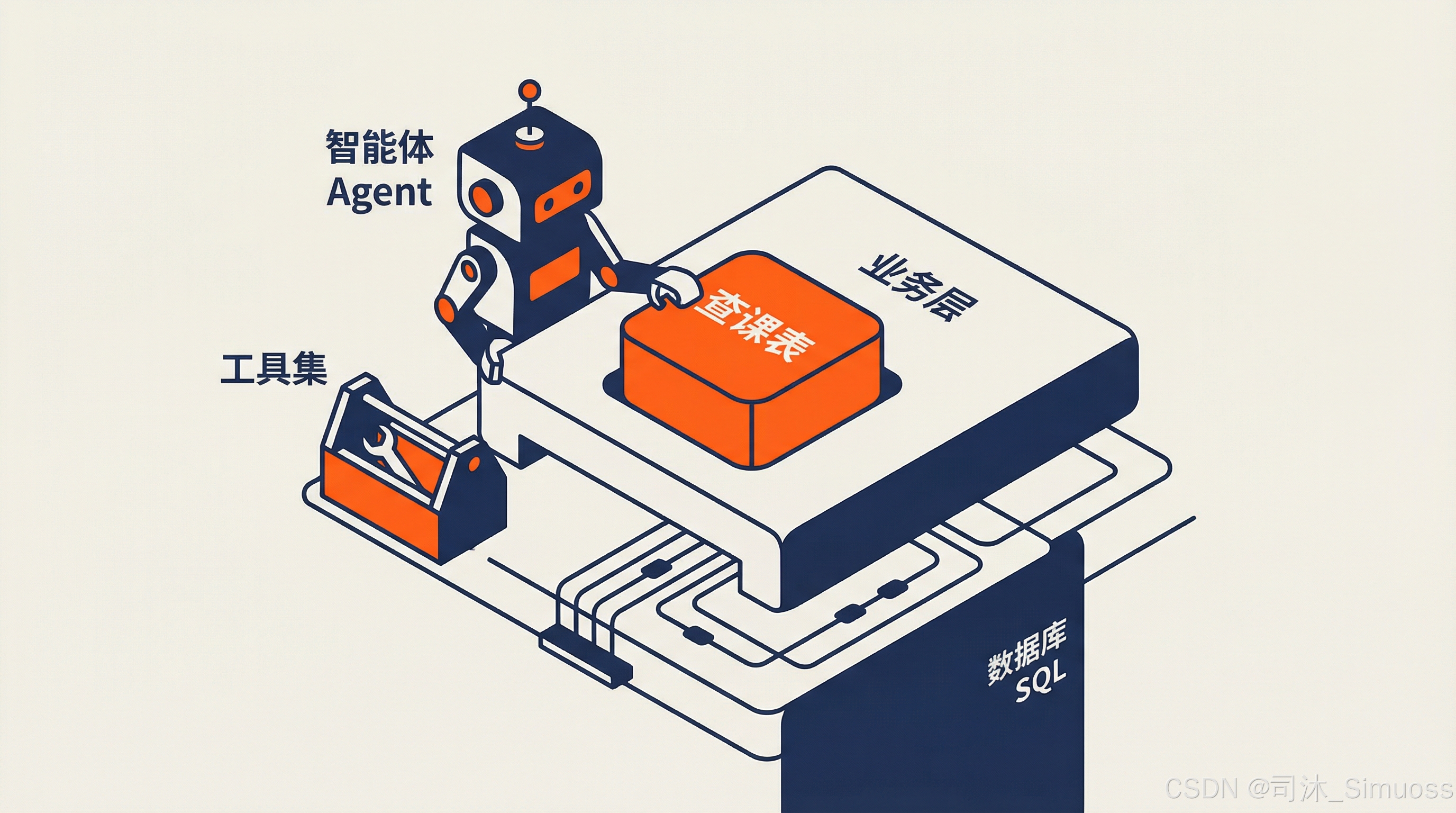
查课表这个行为是很抽象的:
- 哪个班的课表?
- 什么时候的课表?
- 哪个年级的课表?
- 已废弃的课表,还是将来需要颁布的课表?
- 只查周一的,还是查全天的?
- 查一个还是查一组?
这些都是需要根据实际场景来做选择的。
但是无论如何我们都需要“查课表”这个需求,所以我们设计的第一款工具就是查课表工具。
这个工具的本质也是一个方法,但这个方法拥有大量的入参,比如时间列表、班级列表、生效状态列表,以及可选的限制条件——比如只查周一、只查周五等等。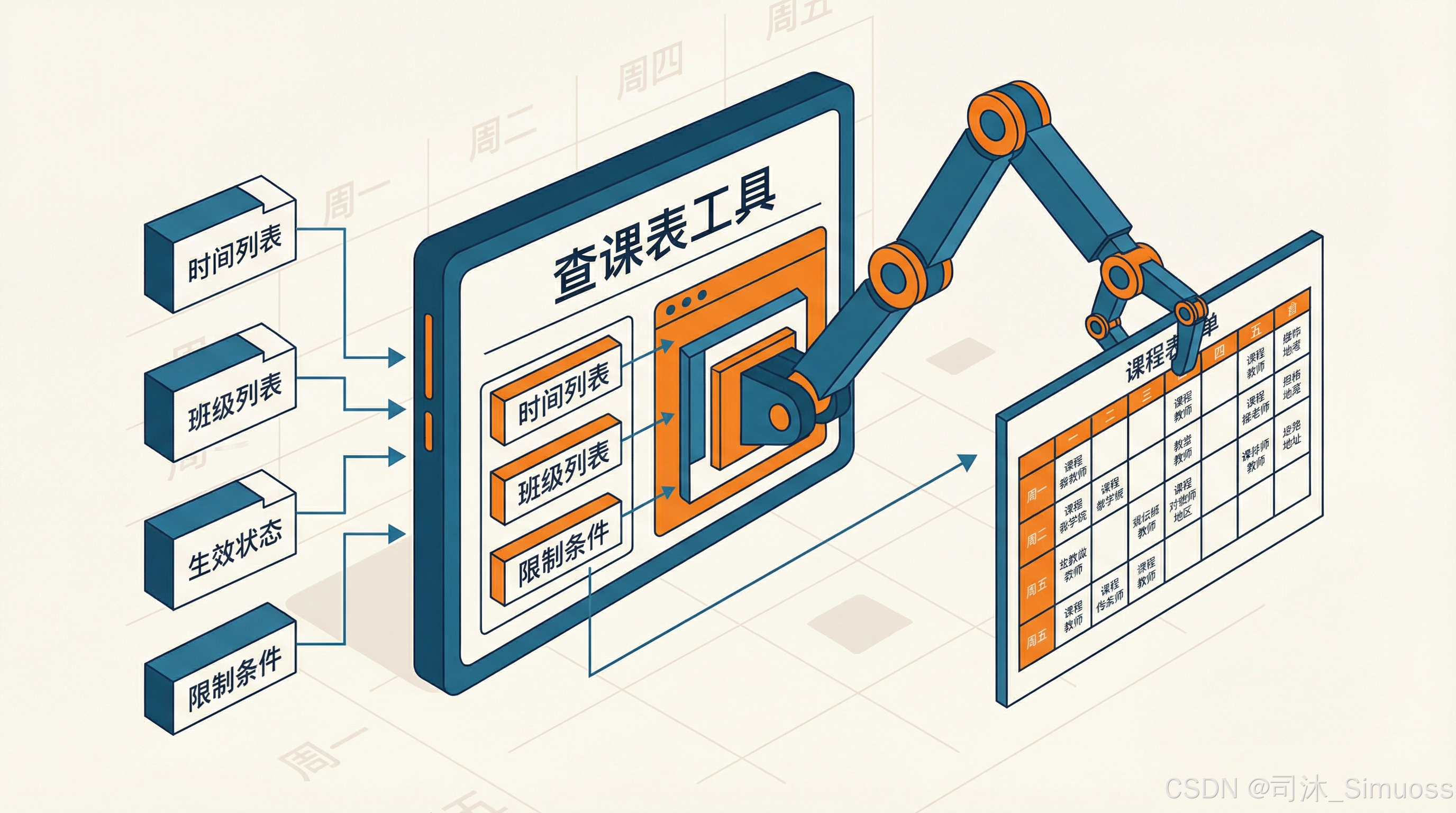
这里补充一个我在实际业务中总结出来的经验:
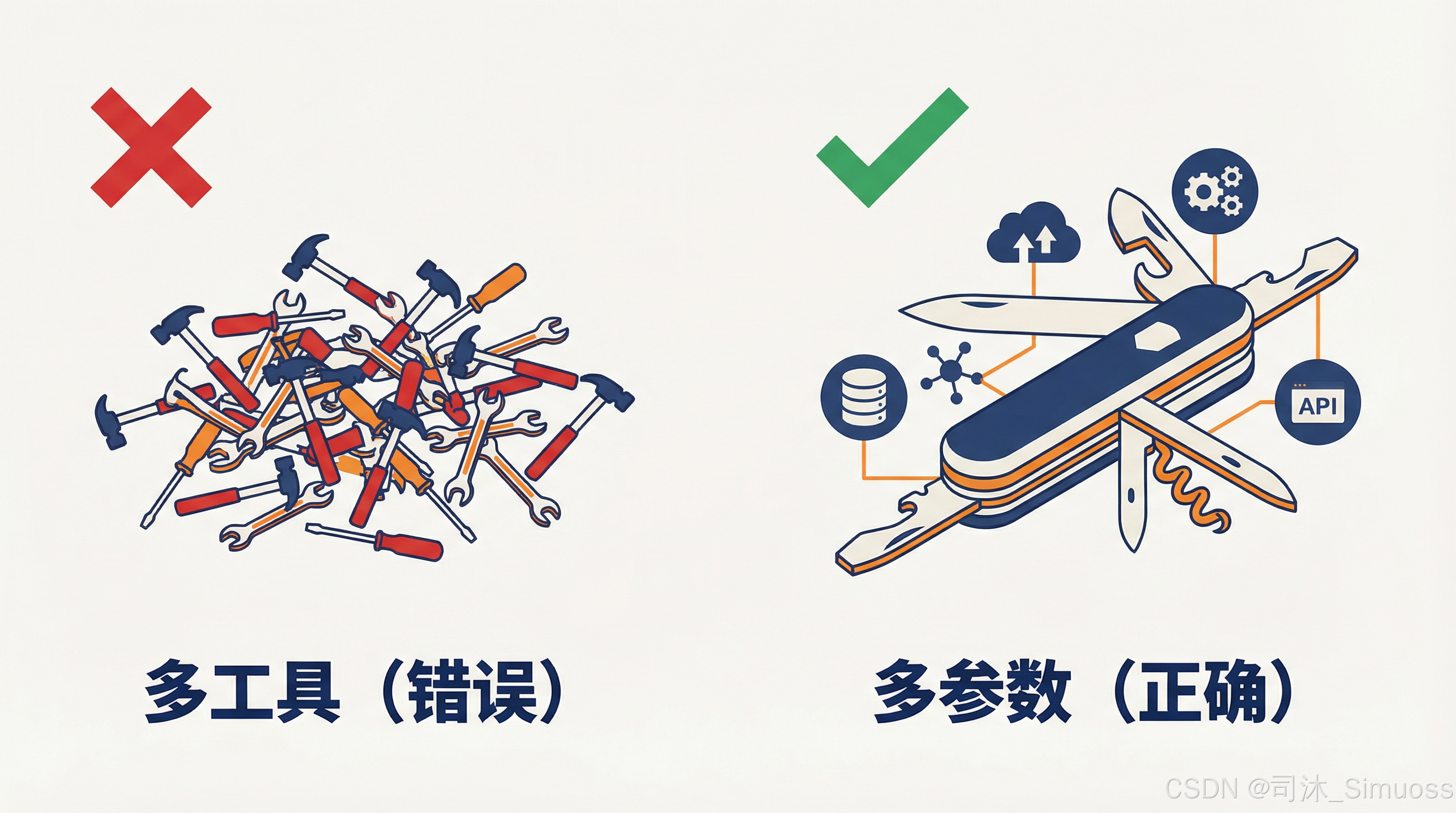
如果要给 Agent 配备工具,那“多工具、少参数”的效果是要远远差于“少工具、多参数”的。
或者换一种更好理解的方式来说,就是:如果想实现业务功能的多样化,要依靠工具参数的多样化,而不是工具的多样化
02 构建工具集:有形与无形
这时候我们就有了第一个工具。在查课表以外,我们还可能会查学生。那是以什么样的约束来查学生呢?
同样的有之前那些参数,比如按时间查、按班级查、按性别查、按年龄查、按带教的辅导员来查、按专业来查等等各式各样的参数。这些又形成了我们的第二个查学生工具。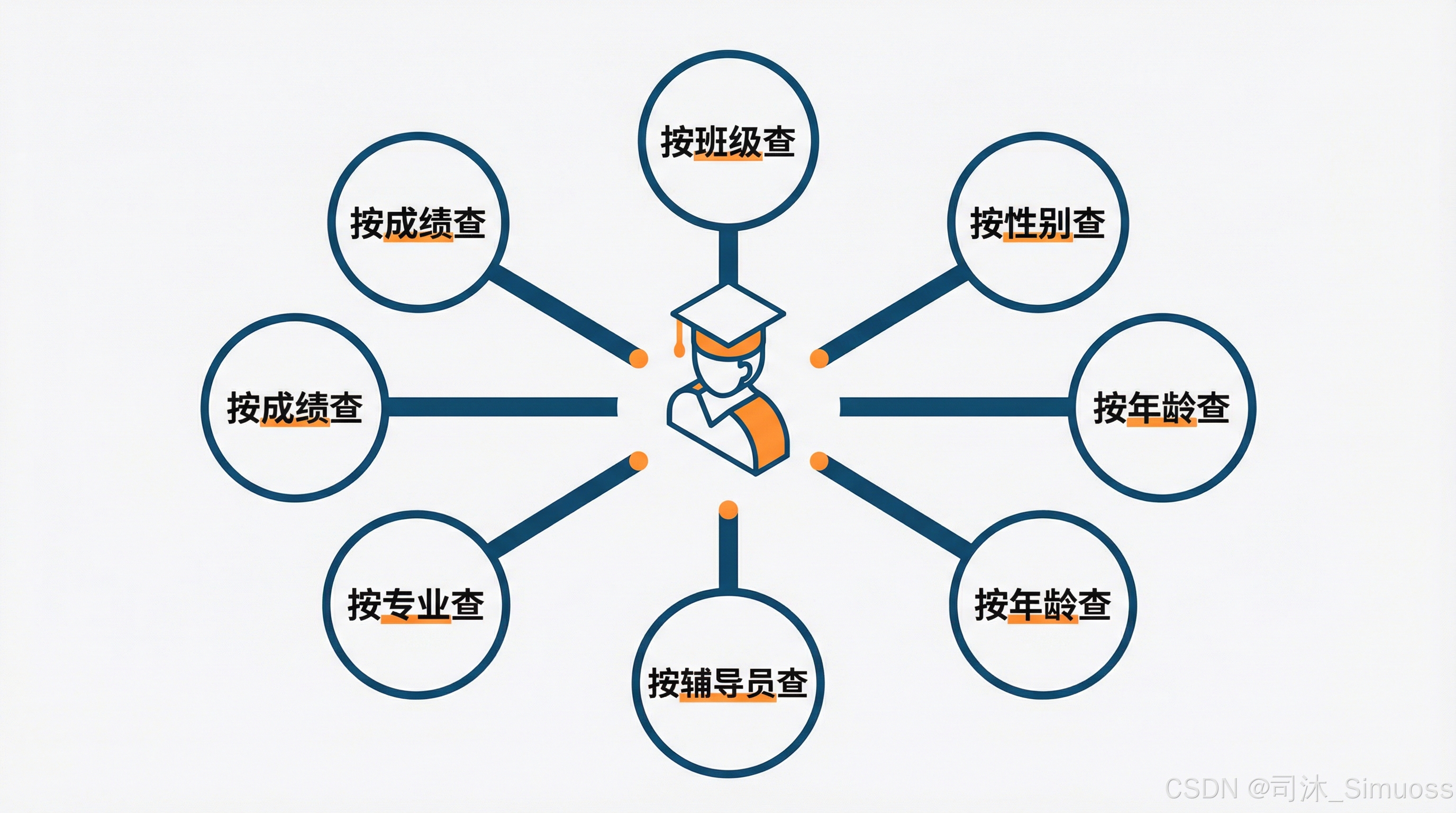
同样的还有查成绩工具、查绩点工具、查奖励工具等等。而查成绩、查绩点等等工具中,有些又是可以合并的。
上面说到的这些都是 “有形”的查询,也就是数据库表中确实存在学生表、课表、成绩表等等。
此外还有一种 “无形”的查询,比如在大学场景里的“挂科”。
数据库中不会有一个“挂科表”,但是挂科这个概念是实际存在并且高频使用的,比如代课老师需要查出自己带的班级中有哪些学生挂科了,从而算出挂科比率。
这样的无形查询还有很多,比如:
- ERP 系统里面的动销率
- 电商系统中的 GMV
- 搜索系统中的 CTR
- …
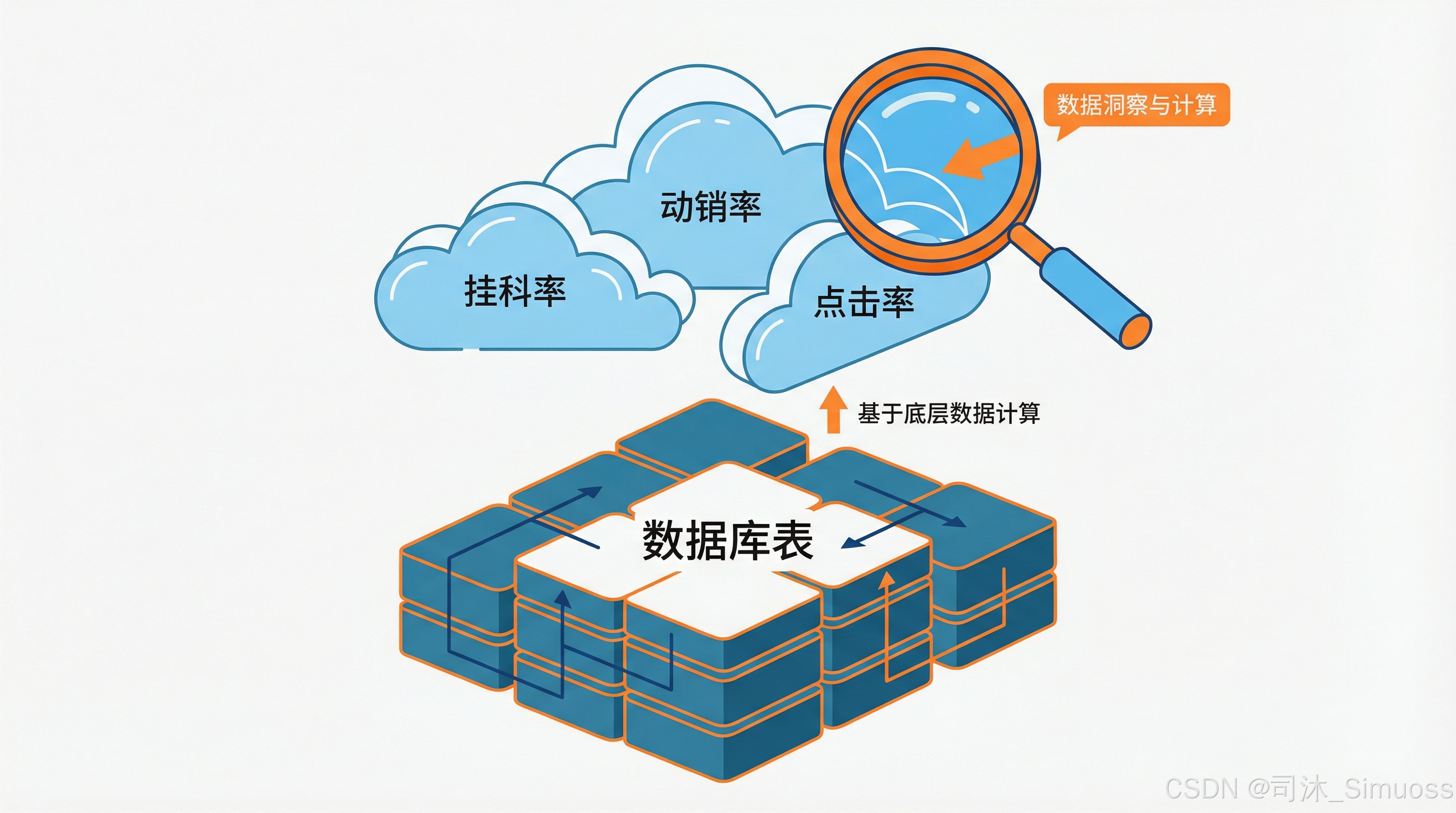
对于这些需要综合计算才能得出的高维指标,我们也要加以关注。
最终,我们希望得到一组工具集,这个工具集可以完备地在 2~3 步之内,组合出我们所需的所有业务逻辑。
03 收益:不仅仅是速度
这需要非常认真细致的工具设计,与对整体系统的深入理解,但这一切绝对是值得的。
当用上这种优化之后,你会发现系统的响应速度提高了好几倍,同时 Token 消耗量也大幅下降,因为我们缩短了 Agent 触达目标的步骤,减轻了 Agent 的心智负担。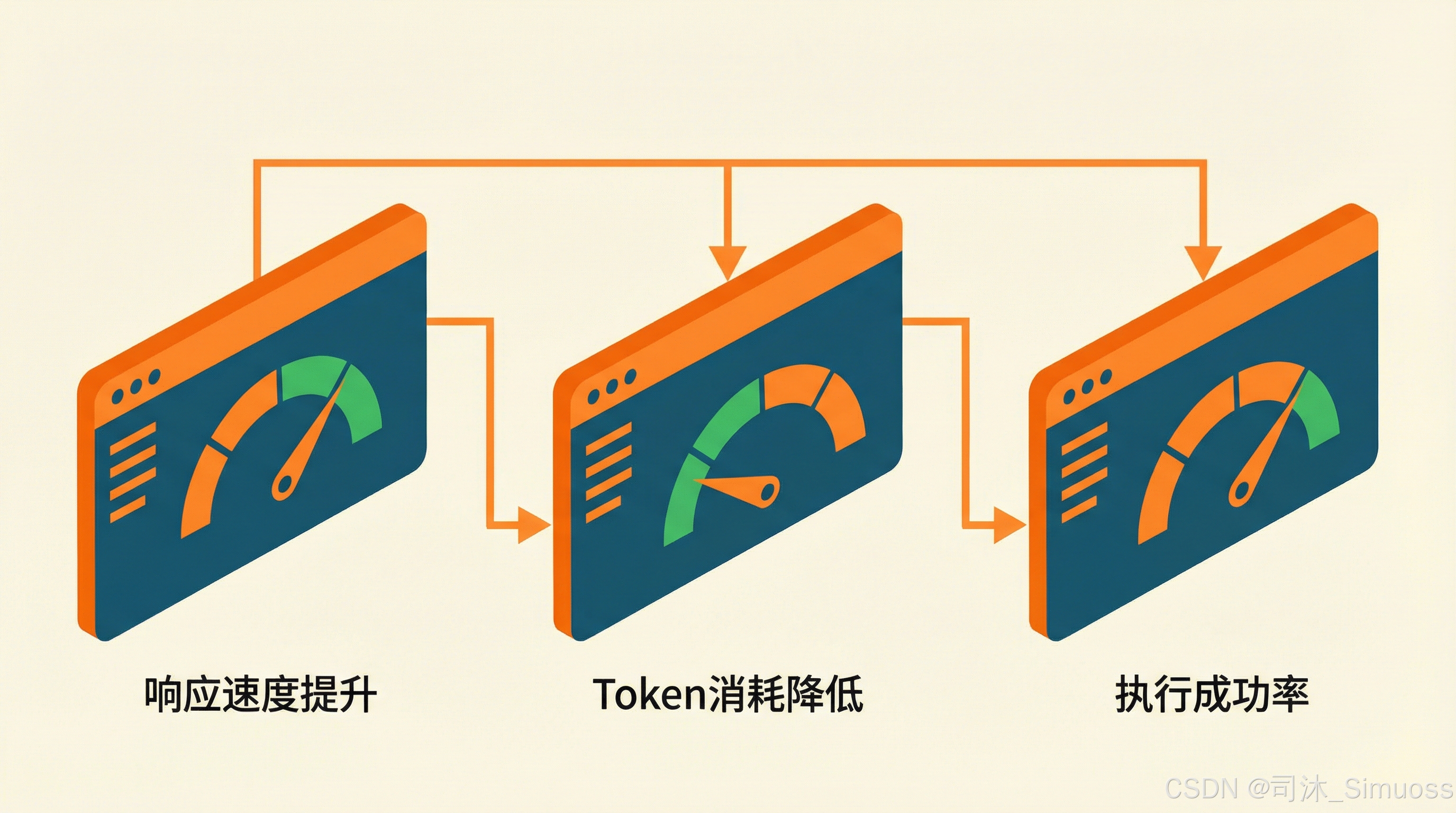
值得一提的是,通常这个时候 Agent 完成任务的成功率也会大大上升,因为较短的执行路径减轻了 Agent 层的心智压力。
所以,这个时候我们甚至可以换更便宜的模型来实现相同的准度。
同样的,这个模式还有一个显而易见的好处: Agent 不用再手写 SQL 语句了。
因为 Agent 的所有操作全部通过工具调用来实现;而在工具中,我们可以做出非常复杂的约束逻辑,比如禁止访问哪些表、比如权限控制、比如一些切片操作、以及日志记录等等。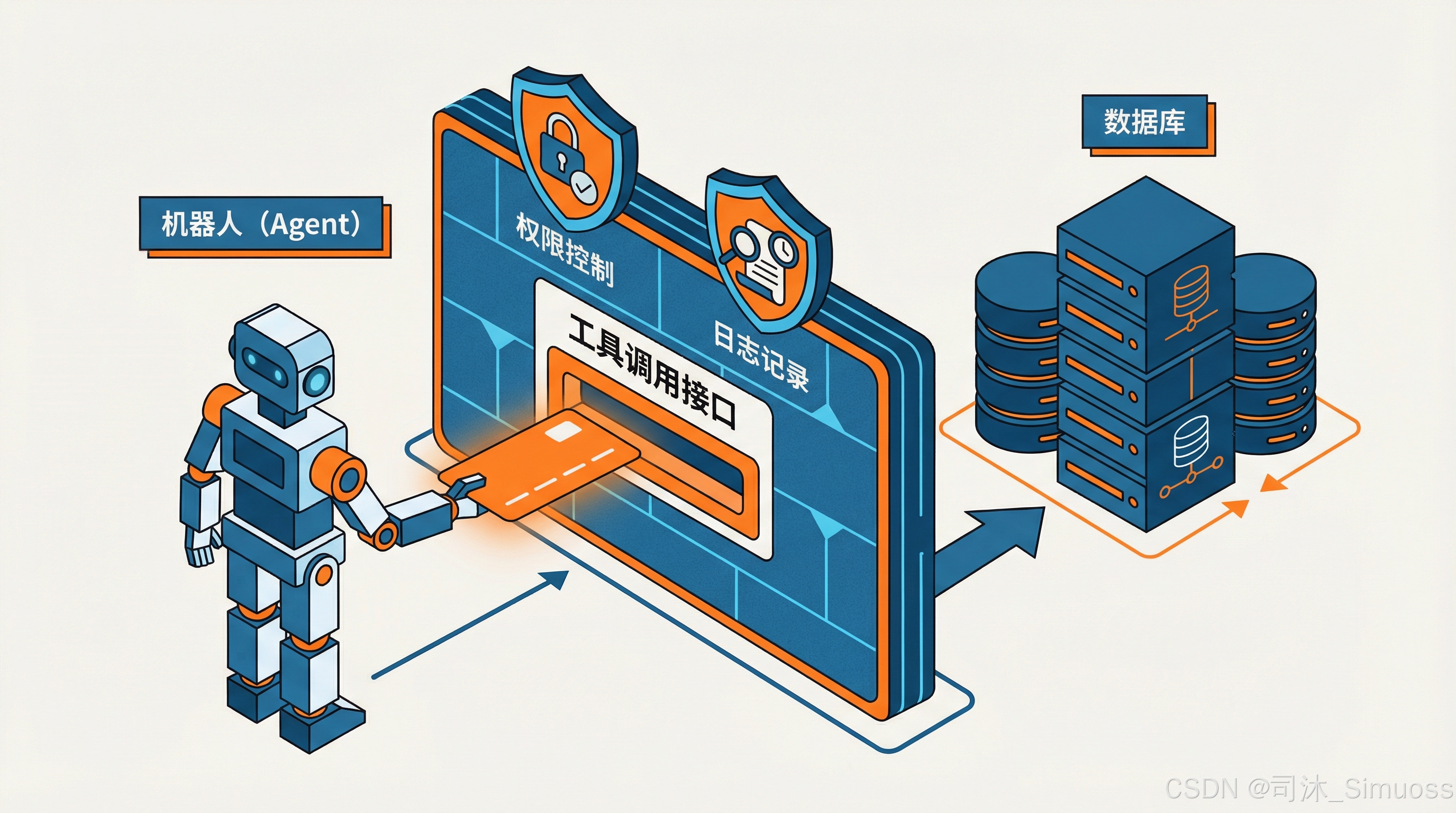
04 代价与取舍:不可能五芒星
当然,构建这样一套系统并不是没有代价的。
- 理解成本: 首先在理解业务阶段,需要花费比简单的 Text-to-SQL 系统多很多的时间。
- 开发成本: 其次,在构建上述的几种工具时,根据其出参入参的复杂程度,需要多写很多独立且复杂的后端服务,这个过程有一定的开发成本。
- 设计门槛: 最后就是这样的一套 Agent 系统,很考验 Agent 工程师的设计能力。如果系统设计得不好,就存在很多未命中的高频查询条件,或者是让 Agent 的执行路径变得很长。
如果我们确信自己可能无法设计出一个完美的工具集,那可能还需要把 Agent 直接执行 SQL 语句这一个工具加回来。
这就涉及到了我们上一篇中提到的“不可能五芒星”,这一步实际上是在牺牲准度、时间成本和金钱成本,换取能力范围的扩展。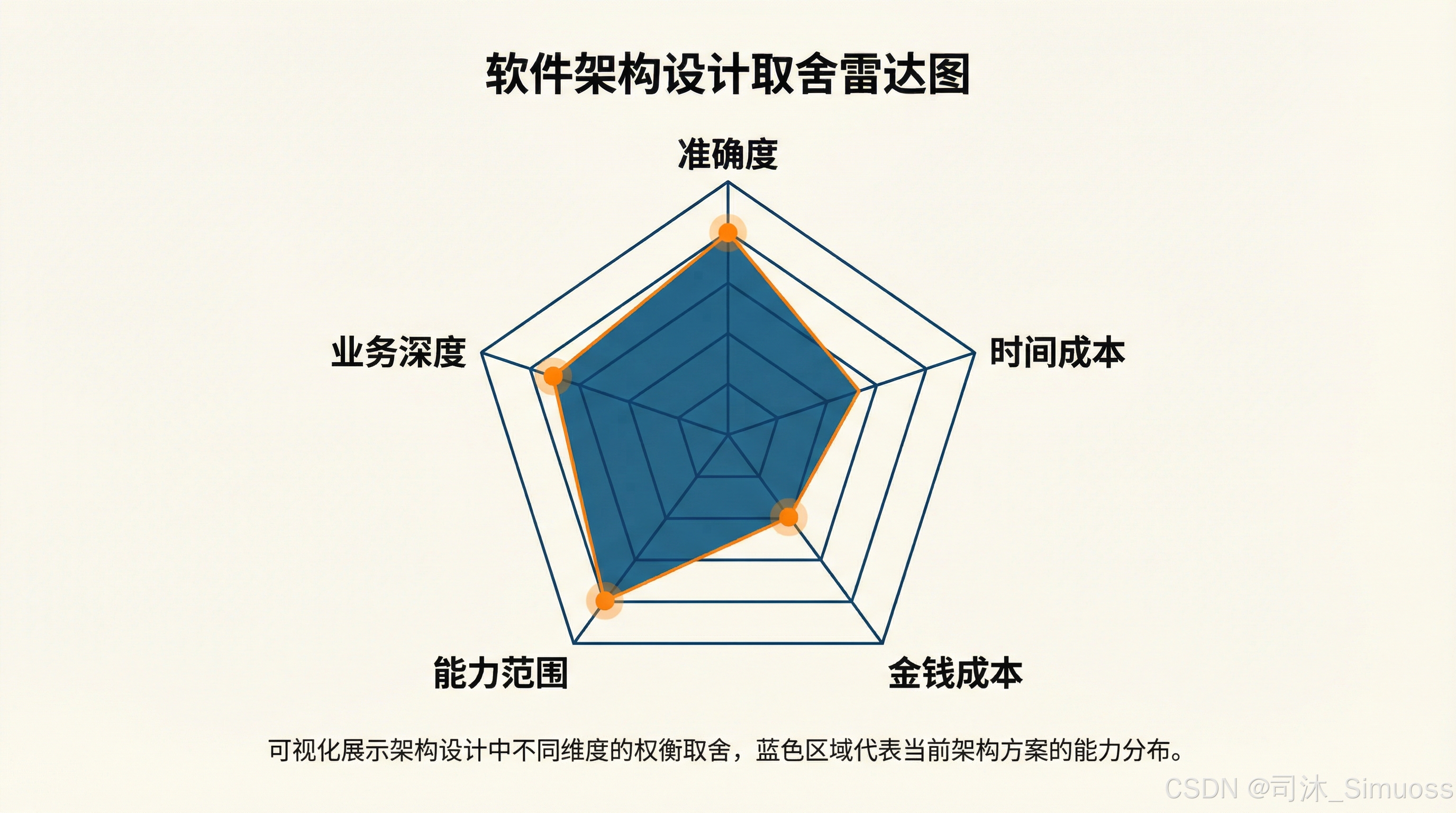
到这里我们还可以思考一下,在一个特定的系统中,如何在这 5 个维度上做取舍,在一个具体的系统中,是的如何实现?
关于“需要花大量时间研究业务”:
我认为,其实严格来说这并不是一个缺点。相反,如果有团队坚持使用 Text-to-SQL 的方式去实现原生的 Text-to-SQL 查询系统,那他大概也会遇到同样的问题。这个过程中,他对原生的 Text-to-SQL 系统进行业务精调需要花费的时间,可能比在前期就深入理解业务来得更多。
换句话说,如果想真的设计一套高可用的 Text-to-SQL 系统,那理解业务这一环一定是必不可少的。
关于“需要花大量时间做工具集的后端开发”:
这一点确实避无可避,但是有一个捷径:我们系统中通常会有一些现成的 API 接口,而这些接口已经经过了实战的检验,为我们提供了很多方法和数据的获取。这时候可以在我们的工具中直接集成这些 API 接口。甚至如果有一些接口设计得很妙,那可以直接把接口打包成一个工具,让大模型来调用,这样就可以最大限度地复用我们已有的资源,从而节省开发成本。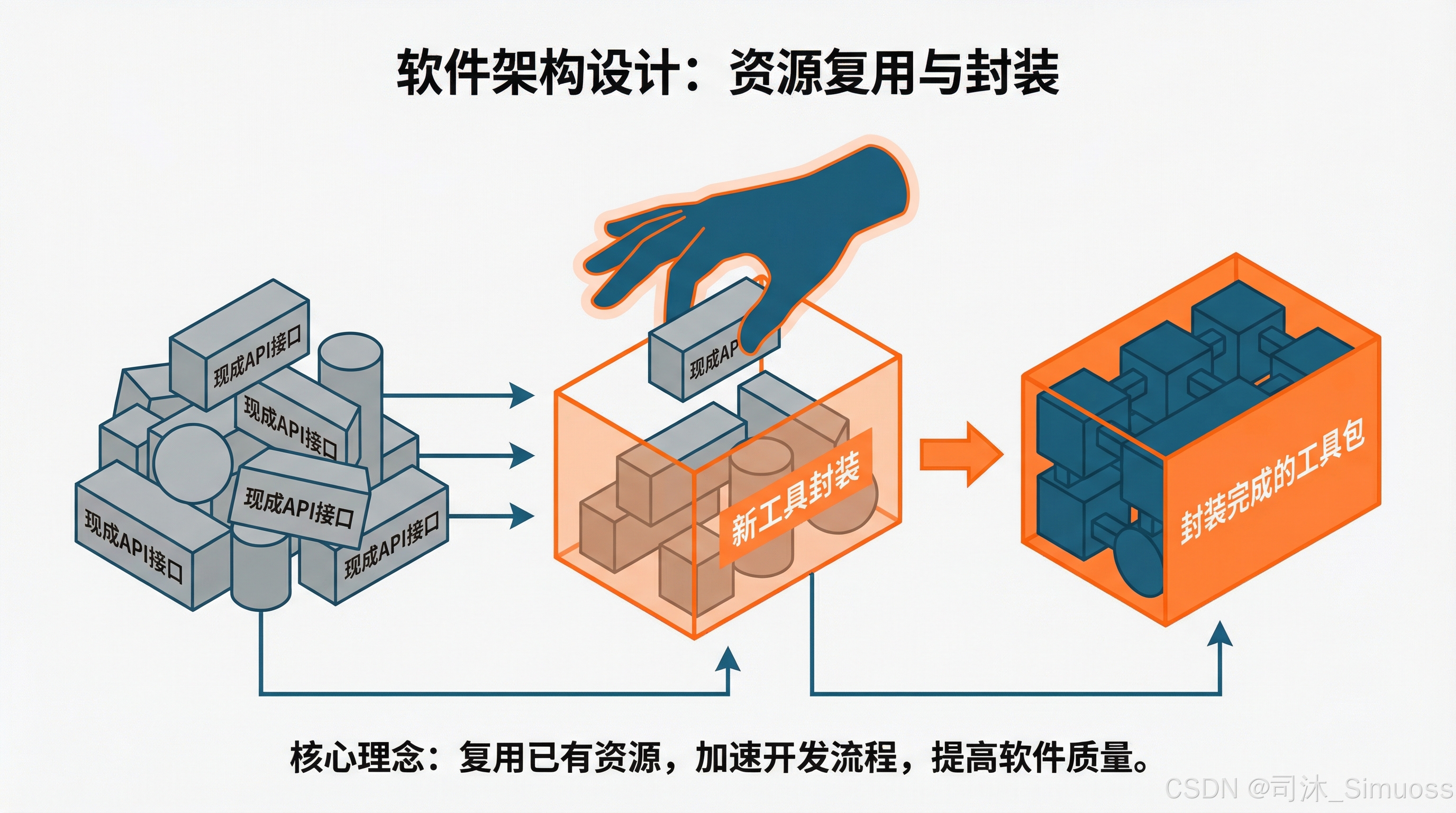
当然,在这个过程中需要注意一些边界逻辑。我们当然希望我们的后端开发工程师能够完美地处理每一种边界条件和越权问题,但实际上很多惨痛的案例告诉我们,后端通常无法对所有场景的边界拦截做到面面俱到。
这个时候就需要 AI 团队和后端开发团队深入交流沟通,找出那些可能存在风险的接口参数传递方式,并提前封堵。这同时也是在 AI 时代对后端工程师的一个提醒。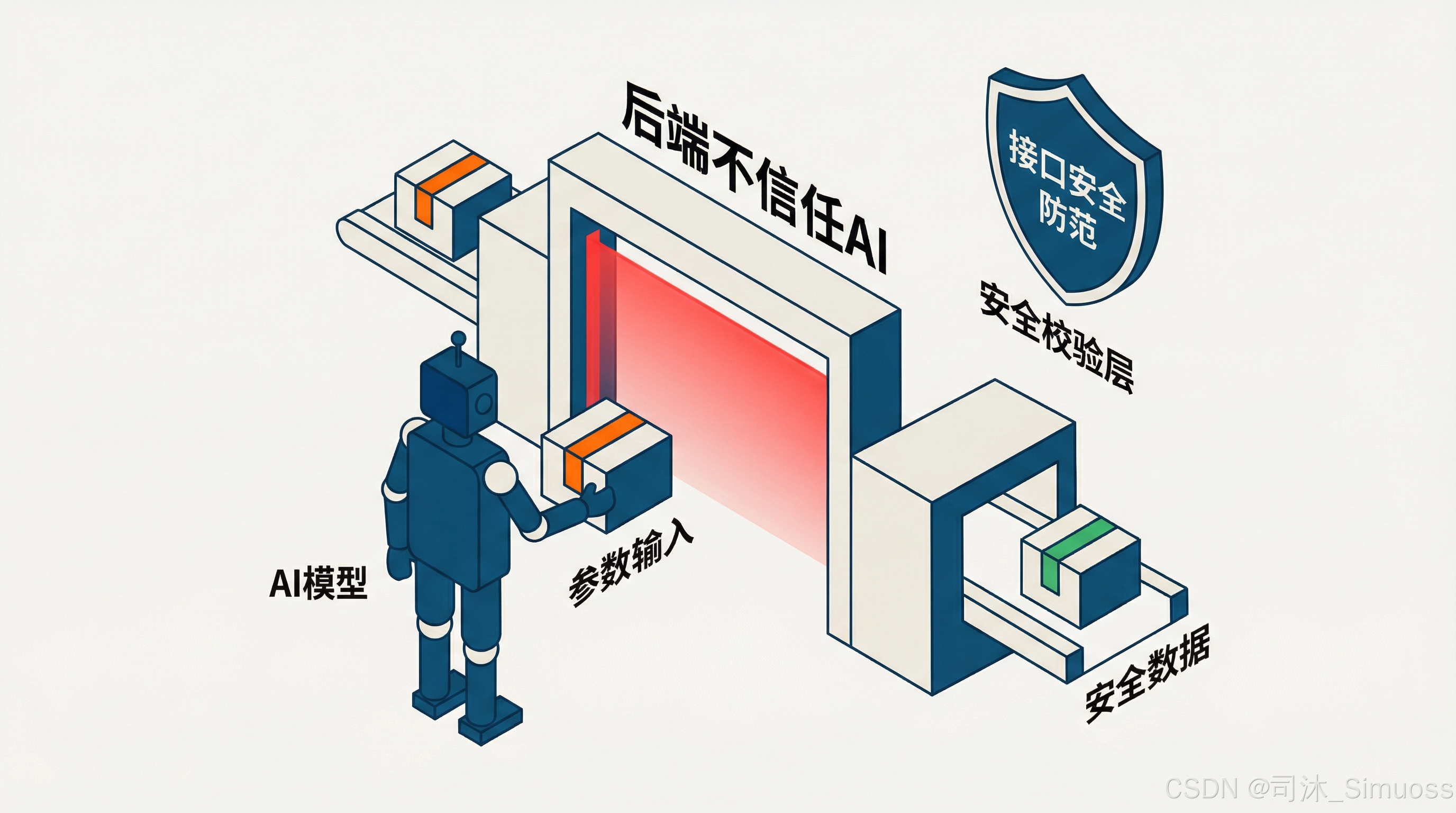
之前我们总说,后端不能相信前端发来的任何一个东西,现在后端同样也不能相信 AI 生成的任何一个参数。
05 边界与演进:Text-to-SQL 的第 4 层?
当然,即使是一个臻于完美的工具集,也一定会有一些边界条件 AI 无法执行,或者有路径但很长,以当前 AI 的能力无法准确地触达这条路径。
那么,对于那些低频的问题,难道我们要放弃吗?也不是。
低频问题分两种:低频且简单,和低频且复杂。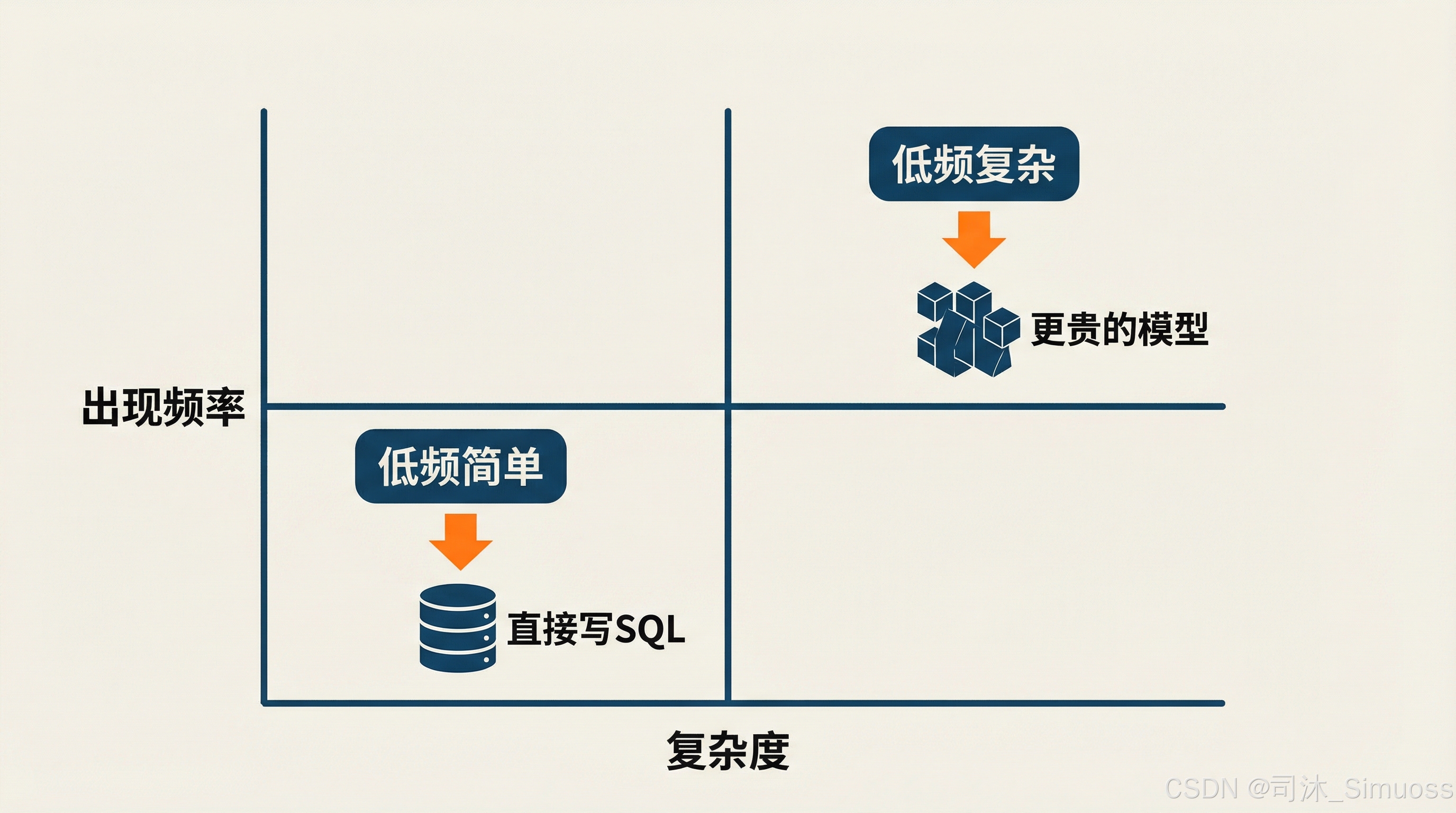
- 对于低频且简单的问题: 可以仍然依靠模型能力写 SQL 语句。这类问题的特点是未命中工具,但执行起来正确率很高。
- 对于低频且复杂的问题: 正确率就会比较低。此时这个问题就有价值单独收集起来,然后用一个更贵的模型,给予更多的上下文,把它作为一个可以迭代的新工具来设计。
当一个场景命中次数过多时,管理员可以考虑手动将其提取成一个工具,或是配置 AI 自动提取,实现 MetaSQL。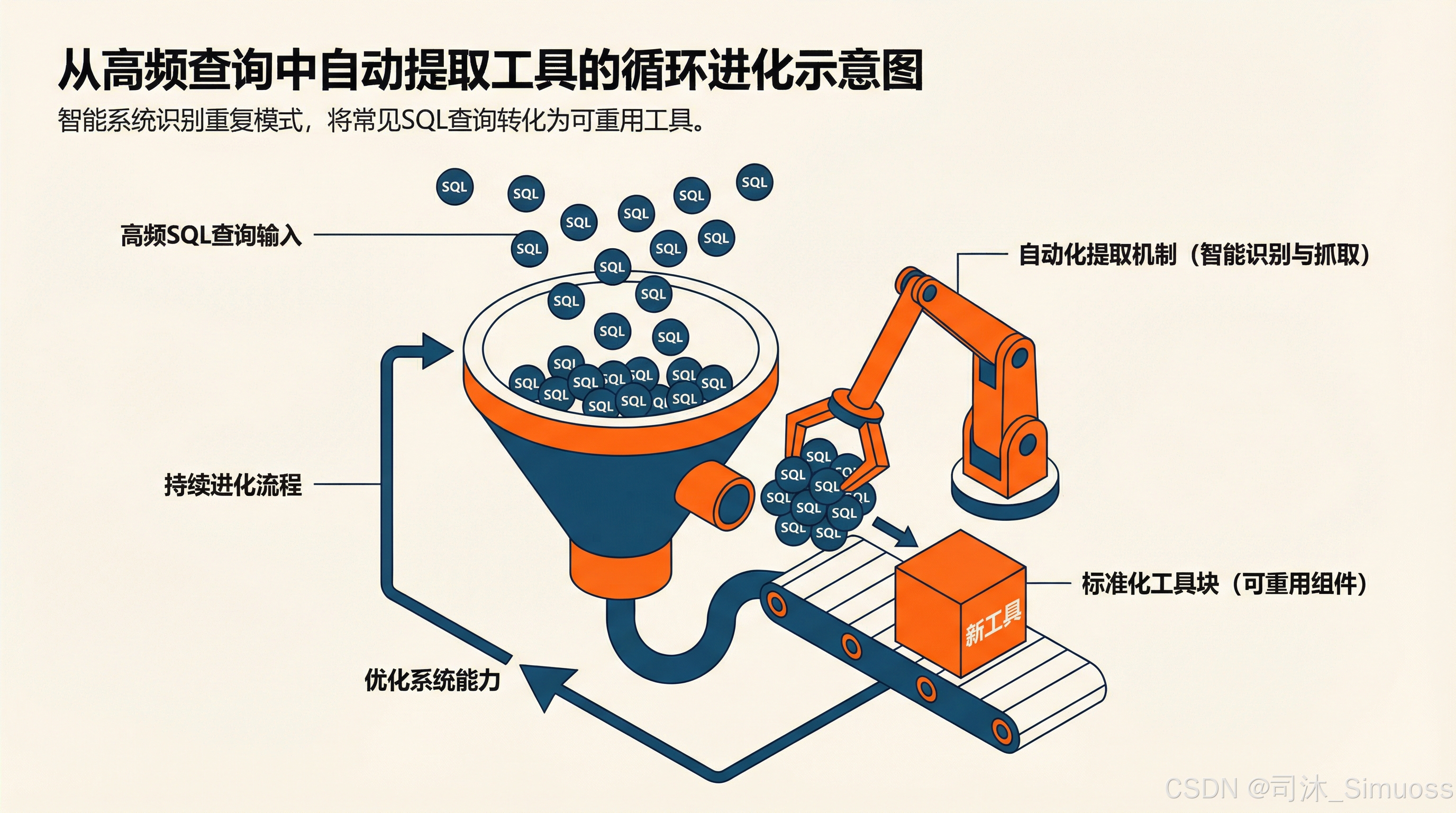
所以,工具不应该是一个闭集合,它应该是一个开放集合,可以根据系统的动态更新而更新。 或许这可能是 Text-to-SQL 系统的第 4 层,但是我们就不套娃了,暂且把它归到第 3 层中。
06 总结
讲到这里,我们的 Text-to-SQL 系统第 3 层设计基本就结束了。
当然第 3 层之上肯定还有第 4 层、第 5 层;甚至可以在第 3 层内部,在我们一开始讲到的 5 个维度上,做不同方向的取舍,都可以创造出不同的第 3 层。但这就属于后话了。
在大部分业务系统中,本文讲的这种工具集的设计方式已经足够使用了。
不过,对于淘宝、京东、微信等等大型 ToC 软件系统的 Text-to-SQL 场景,需要的就不只是 AI 层面的东西了,而是一套成体系的 Text-to-SQL 工具平台。这些平台之上还有更多的设计点,不过在这里就不赘述了。
实际上,在这一场 Text-to-SQL 之旅中,我们是有一种分析方式的,也就是了解当前 AI 的能力边界——它擅长什么,不擅长什么。
它擅长的部分,我们尽最大可能把它发挥出来;它不擅长的部分,我们利用外部框架的能力给他补齐。
这样我们就得到了一个完美的 Agent 系统。
不只对于 Text-to-SQL,对于其他的 Agent 系统,这套理论同样生效。具体就看我们在其中如何了解业务,如何设计了。
如果目前你手里有一些比较苦恼的场景(不仅限于 Text-to-SQL 系统,其他系统也可以),但不知道如何设计,欢迎在评论区留言。
以当前本账号这个粉丝量,还是可以做到有问必答的。如果问题需要保密,也可以后台直接留言。
我是司沐,下期再见~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)