Elasticsearch 向量搜索的速度比 OpenSearch 快高达 8 倍
Elasticsearch在过滤向量搜索性能上显著优于OpenSearch,基准测试显示其吞吐量最高快8倍,召回率更高。这种优势在上下文工程系统中尤为关键,因为AI代理通常需要执行多次"检索-推理-再检索"循环,检索延迟会被放大。测试使用2000万文档的电商数据集,Elasticsearch在相同配置下平均延迟更低(如100_9000_1配置下90ms vs 687ms),吞吐
作者:来自 Elastic Sachin Frayne
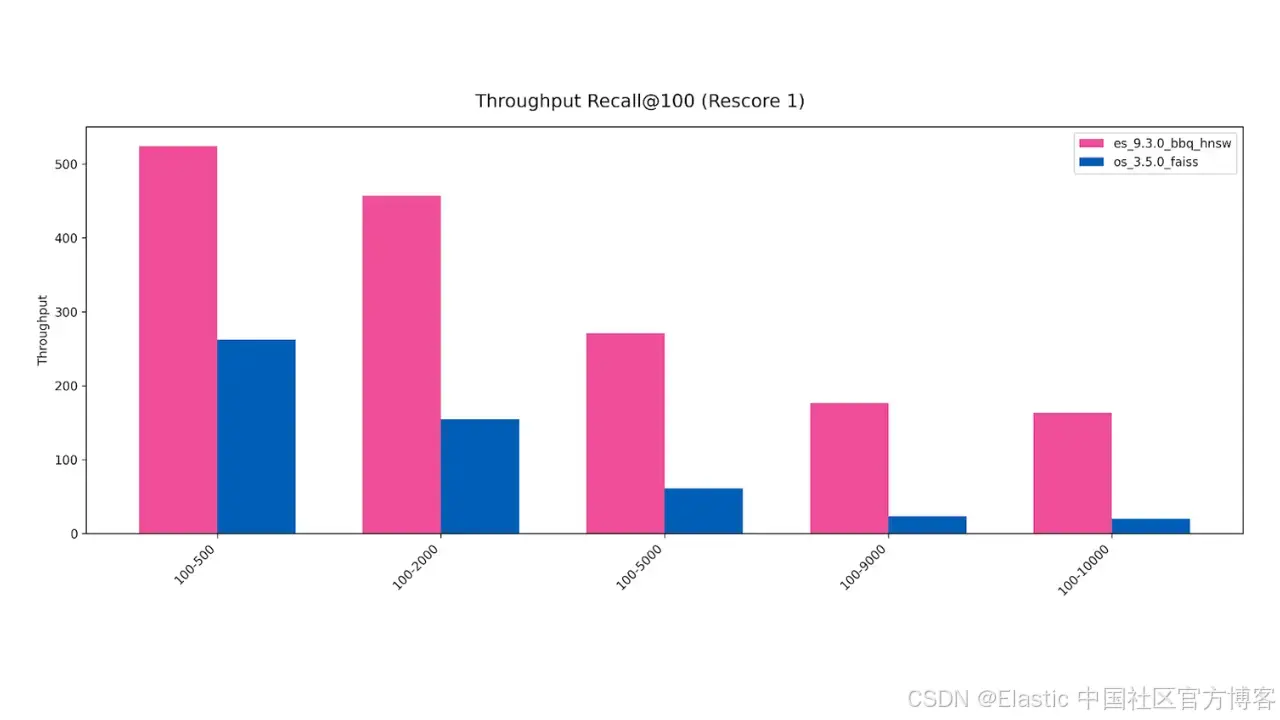
探索 OpenSearch 与 Elasticsearch 在 过滤向量搜索(filtered vector search) 基准测试中的表现差异,以及为什么向量搜索性能对 上下文工程系统(context‑engineered systems) 至关重要。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。你可以在 Elasticsearch Labs 仓库中的示例 notebook 中尝试新功能,也可以今天开始免费试用或在本地运行 Elasticsearch。
为什么搜索速度对 AI agents 和上下文工程很重要
在一个 2000 万文档的语料库基准测试中,Elasticsearch 在过滤向量搜索上的吞吐量比 OpenSearch 快高达 8 倍,同时在我们测试的各种配置中也实现了更高的 Recall@100。上下文工程不仅依赖快速的向量检索。团队还需要强大的相关性控制,例如混合搜索和过滤、操作简便性,以及可预测的性能,以支持工作流的迭代。但因为 agents 往往在每次请求中多次执行 “检索 → 推理 → 再检索” 循环,检索延迟会被放大,因此在这方面的性能提升会直接转化为更好的端到端响应速度和更低的成本。
对于上下文工程来说,检索不是一次性步骤。Agents 和应用会反复执行循环,例如 检索 → 推理 → 再检索,以精炼查询、验证事实、组装有依据的上下文并完成任务。这种模式在 agentic 工作流和迭代式增强生成(retrieval augmented generation - RAG)中很常见。由于每个用户请求可能会多次触发检索,这会增加响应延迟和/或提高基础设施成本。
上下文工程的最佳实现仍是新兴技术,不同工作流的迭代次数差异很大。这些基准测试结果最核心的概念是:上下文工程具有 方向性 —— 迭代检索会使延迟成倍增加。
为什么向量搜索性能至关重要?
想象一个购物助手回答问题:“我需要一个 60 美元以下、能放 15 英寸笔记本、耐水、并能在周五送达的随身背包。”
在生产环境中,助手很少只发起一次向量查询就停止。它会运行一个 检索循环 来构建正确的上下文,每一步通常受过滤条件限制,例如库存、地区、配送承诺、品牌规则和政策资格。
步骤 1:理解意图并转换为约束条件
Agent 将请求转化为结构化过滤器和语义查询,例如:
-
Filters(过滤条件):有库存、可配送至用户邮编、周五前送达、价格低于 60 美元、有效商品
-
Vector query(向量查询):“Carry-on backpack 15-inch laptop water resistant”
步骤 2:检索候选项并进一步精炼
通常会对检索进行多次变体查询,以避免错过优质匹配:
-
“travel backpack carry on laptop sleeve”
-
“water resistant commuter backpack 15 inch”
-
“lightweight cabin backpack”
每个查询都使用相同的资格过滤器,因为检索到不相关或不可用的商品只是浪费上下文。
步骤 3:扩展以确认细节并降低风险
Agent 再次检索以验证影响最终答案的关键属性:
-
材质与耐水性描述
-
尺寸和笔记本隔层是否合适
-
退换政策或保修限制
-
库存不足时的备选方案
这就是多步骤上下文工程:检索 → 推理 → 再检索 → 组装。
为什么延迟和召回对上下文工程很重要
这些交互可能在每个用户会话中涉及数十次带过滤条件的检索调用。这意味着每次调用的延迟会直接乘到端到端响应时间上,而低召回率会导致额外重试,或者让 agent 错过符合条件的项,从而降低答案质量。
要点:在上下文工程系统中,带过滤条件的近似最近邻(ANN)搜索不是一次性查询,而是在约束下的重复操作。因此,向量搜索性能会直接影响延迟、吞吐量和成本,即便大语言模型(LLM)是最直观的组件。
基准测试结果
在图 2 中,每个点代表一种测试配置。最佳结果位于左上角,表示 更高召回率与更低延迟。Elasticsearch 的结果始终更接近左上角,相比 OpenSearch 在相同工作负载下表现出更好的速度和精度。
结果
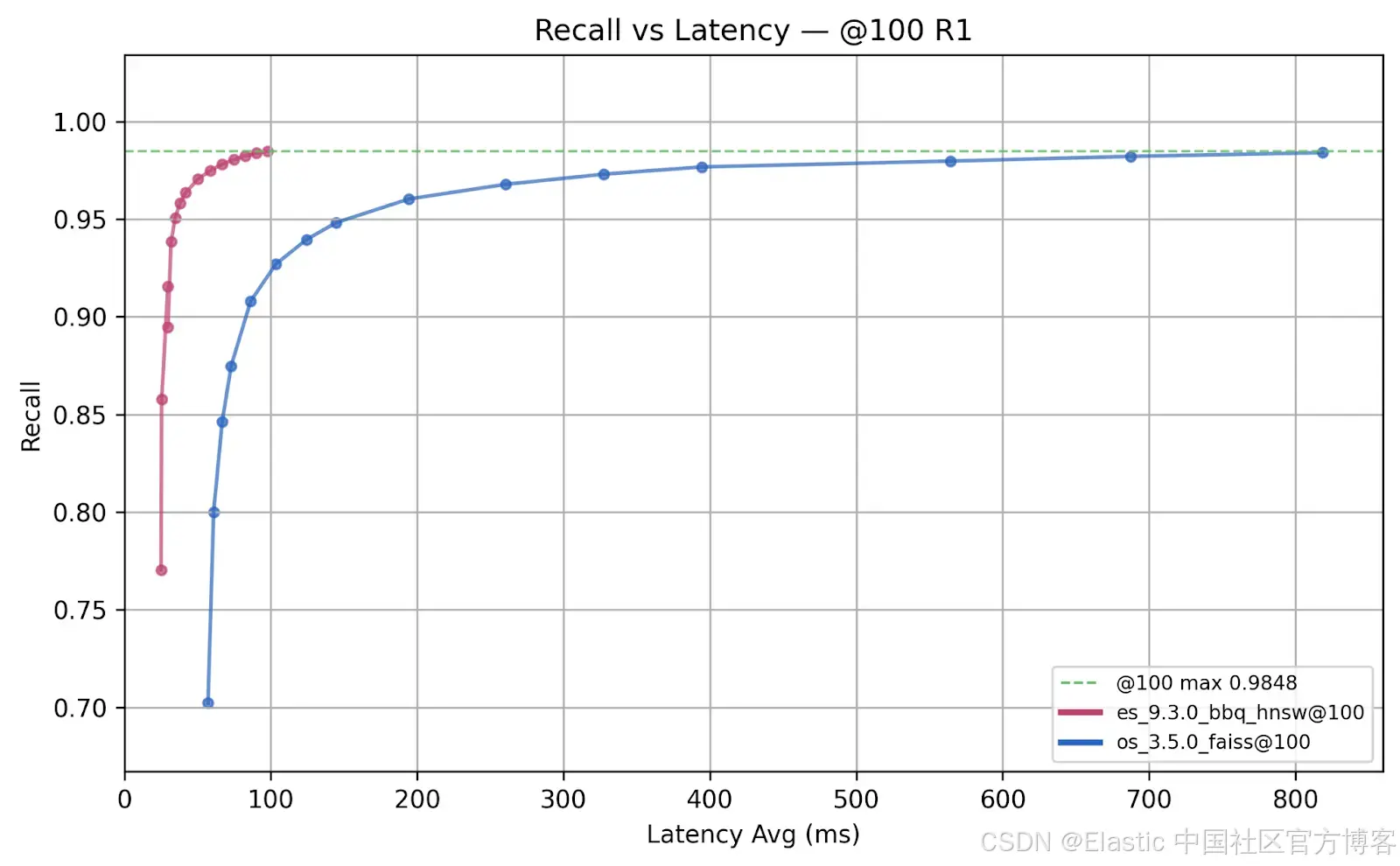
一些关键洞察
-
s_n_r_value:size_numCandidates_rescoreOversample 的缩写(在这些测试中 k 和 numCandidates 设置为相等),例如 100_500_1 表示 size=100、numCandidates=500、k=500、rescore oversample=1
-
Recall:该配置下的 Recall@100 测量值
-
Avg latency (ms):每次查询的平均端到端延迟(毫秒)
-
Throughput:每秒查询数(QPS)
-
Recall %:Elasticsearch 相比 OpenSearch 的相对召回提升,计算方式为 (Elasticsearch - OpenSearch) / OpenSearch
-
Latency Xs:OpenSearch 平均延迟除以 Elasticsearch 平均延迟
-
Throughput Xs:Elasticsearch 吞吐量除以 OpenSearch 吞吐量
例如,在 100_9000_1 配置下,OpenSearch 平均每次检索耗时 687 毫秒,而 Elasticsearch 仅 90 毫秒。在一个 10 步的检索循环中,这意味着大约 10 × (687 − 90) = 5970 毫秒,即额外 近 6 秒 的等待时间。
从表中可以看出,Elasticsearch 在 召回率、延迟和吞吐量 上均优于 OpenSearch,尤其是在大规模向量检索场景中,性能优势会被迭代检索放大,直接影响端到端响应时间和系统成本。
完整结果可查看表格:
| 引擎 | s_n_r_value | Recall | 平均延迟 (ms) | 吞吐量 | 召回 % | 延迟倍数 | 吞吐倍数 |
|---|---|---|---|---|---|---|---|
| Elasticsearch | 100_250_1 | 0.7704 | 25 | 534.75 | 9.70% | 2.28 | 1.91 |
| OpenSearch | 100_250_1 | 0.7023 | 57.08 | 279.58 | — | — | — |
| Elasticsearch | 100_500_1 | 0.8577 | 25.42 | 524.14 | 7.20% | 2.4 | 2 |
| OpenSearch | 100_500_1 | 0.8001 | 60.9 | 262.12 | — | — | — |
| Elasticsearch | 100_750_1 | 0.8947 | 29.67 | 528.09 | 5.72% | 2.25 | 2.21 |
| OpenSearch | 100_750_1 | 0.8463 | 66.76 | 239.11 | — | — | — |
| … | … | … | … | … | … | … | … |
| Elasticsearch | 100_9000_1 | 0.9837 | 90.08 | 176.96 | 0.16% | 7.63 | 7.61 |
| OpenSearch | 100_9000_1 | 0.9821 | 687.25 | 23.25 | — | — | — |
| Elasticsearch | 100_10000_1 | 0.9848 | 97.64 | 163.31 | 0.08% | 8.38 | 8.36 |
| OpenSearch | 100_10000_1 | 0.984 | 818.64 | 19.53 | — | — | — |
例如,在 100_9000_1 配置下,OpenSearch 平均每次检索耗时 687 毫秒,而 Elasticsearch 仅 90 毫秒。在一个 10 步的检索循环中,这意味着大约 10 × (687 − 90) = 5970 毫秒,也就是额外 近 6 秒 的等待时间。
从表中可以看到,Elasticsearch 在 召回率、延迟和吞吐量 上均优于 OpenSearch,尤其是在大规模向量检索场景中,这种优势在迭代检索循环中被放大,直接影响端到端响应时间和系统成本。
完整测试结果如下:
| 引擎 | s_n_r_value | Recall | 平均延迟 (ms) | 吞吐量 | 召回 % | 延迟倍数 | 吞吐倍数 |
|---|---|---|---|---|---|---|---|
| Elasticsearch | 100_250_1 | 0.7704 | 25 | 534.75 | 9.70% | 2.28 | 1.91 |
| OpenSearch | 100_250_1 | 0.7023 | 57.08 | 279.58 | — | — | — |
| Elasticsearch | 100_500_1 | 0.8577 | 25.42 | 524.14 | 7.20% | 2.4 | 2 |
| OpenSearch | 100_500_1 | 0.8001 | 60.9 | 262.12 | — | — | — |
| Elasticsearch | 100_750_1 | 0.8947 | 29.67 | 528.09 | 5.72% | 2.25 | 2.21 |
| OpenSearch | 100_750_1 | 0.8463 | 66.76 | 239.11 | — | — | — |
| Elasticsearch | 100_1000_1 | 0.9156 | 29.65 | 534.5 | 4.66% | 2.46 | 2.44 |
| OpenSearch | 100_1000_1 | 0.8748 | 72.88 | 219.01 | — | — | — |
| Elasticsearch | 100_1500_1 | 0.9386 | 31.84 | 497.3 | 3.38% | 2.71 | 2.68 |
| OpenSearch | 100_1500_1 | 0.9079 | 86.16 | 185.4 | — | — | — |
| Elasticsearch | 100_2000_1 | 0.9507 | 34.69 | 457.2 | 2.57% | 2.98 | 2.96 |
| OpenSearch | 100_2000_1 | 0.9269 | 103.36 | 154.55 | — | — | — |
| Elasticsearch | 100_2500_1 | 0.9582 | 37.9 | 418.43 | 1.99% | 3.28 | 3.26 |
| OpenSearch | 100_2500_1 | 0.9395 | 124.29 | 128.53 | — | — | — |
| Elasticsearch | 100_3000_1 | 0.9636 | 41.86 | 379.4 | 1.62% | 3.46 | 3.44 |
| OpenSearch | 100_3000_1 | 0.9482 | 144.67 | 110.34 | — | — | — |
| Elasticsearch | 100_4000_1 | 0.9705 | 50.28 | 316.21 | 1.06% | 3.87 | 3.85 |
| OpenSearch | 100_4000_1 | 0.9603 | 194.36 | 82.22 | — | — | — |
| Elasticsearch | 100_5000_1 | 0.9749 | 58.77 | 270.91 | 0.73% | 4.43 | 4.41 |
| OpenSearch | 100_5000_1 | 0.9678 | 260.33 | 61.38 | — | — | — |
| Elasticsearch | 100_6000_1 | 0.9781 | 66.75 | 238.59 | 0.52% | 4.91 | 4.89 |
| OpenSearch | 100_6000_1 | 0.973 | 327.44 | 48.81 | — | — | — |
| Elasticsearch | 100_7000_1 | 0.9804 | 74.64 | 213.49 | 0.38% | 5.28 | 5.27 |
| OpenSearch | 100_7000_1 | 0.9767 | 394.24 | 40.53 | — | — | — |
| Elasticsearch | 100_8000_1 | 0.9823 | 82.28 | 193.59 | 0.27% | 6.86 | 6.83 |
| OpenSearch | 100_8000_1 | 0.9797 | 564.14 | 28.33 | — | — | — |
| Elasticsearch | 100_9000_1 | 0.9837 | 90.08 | 176.96 | 0.16% | 7.63 | 7.61 |
| OpenSearch | 100_9000_1 | 0.9821 | 687.25 | 23.25 | — | — | — |
| Elasticsearch | 100_10000_1 | 0.9848 | 97.64 | 163.31 | 0.08% | 8.38 | 8.36 |
| OpenSearch | 100_10000_1 | 0.984 | 818.64 | 19.53 | — | — | — |
方法论
使用 Python 发送查询并跟踪响应时间和其他统计数据,我们向引擎发送了以下查询。请记住,任何 vector search 引擎的性能都取决于你如何调优其核心参数:考虑多少 candidates、多激进地 rescore,以及返回多少 context。这些设置会直接影响 recall(找到正确答案的可能性)和 latency(获取结果的速度)。
在我们的基准测试中,我们使用了在典型 agentic retrieval 循环中会调优的相同 candidate、rescore 和 result-size 设置,并测量了 Elasticsearch 在该工作负载下的表现。随后,我们用相同设置运行 OpenSearch 作为参考。
OpenSearch
GET <INDEX_NAME>/_search
{
"query": {
"knn": {
"<DENSE_VECTOR_FIELD_NAME>": {
"vector": [...],
"k": <NUMBER_OF_CANDIDATES>,
"method_parameters": {
"ef_search": <NUMBER_OF_CANDIDATES>
},
"rescore": {
"oversample_factor": <OVERSAMPLE>
},
"filter": {
<SOME_FILTER>
}
}
}
},
"size": <RESULT_SIZE>,
"_source": {
"excludes": [
"<DENSE_VECTOR_FIELD_NAME>"
]
}
}- "size": <RESULT_SIZE>:返回给 client 的 hits 数量。在本次 benchmark 中,result size 为 100 用于计算 Recall@100。
- "k": <NUMBER_OF_CANDIDATES>:nearest neighbor candidates 的数量。
- "ef_search": <NUMBER_OF_CANDIDATES>:要检查的 vectors 数量。
- "oversample_factor": :在 rescore 之前检索多少 candidate vectors。
Elasticsearch
GET <INDEX_NAME>/_search
{
"query": {
"knn": {
"field": "<DENSE_VECTOR_FIELD_NAME>",
"query_vector": [...],
"k": <NUMBER_OF_CANDIDATES>,
"num_candidates": <NUMBER_OF_CANDIDATES>,
"rescore_vector": {
"oversample": <OVERSAMPLE>
},
"filter": {
<SOME_FILTER>
}
}
},
"size": <RESULT_SIZE>,
"_source": {
"excludes": [
"<DENSE_VECTOR_FIELD_NAME>"
]
}
}- "size": <RESULT_SIZE>:返回给 client 的 hits 数量。在本次 benchmark 中,result size 为 100 用于计算 Recall@100。
- "k": <NUMBER_OF_CANDIDATES>:每个 shard 返回的 nearest neighbors 数量。
- "num_candidates": <NUMBER_OF_CANDIDATES>:在每个 shard 执行 knn search 时要考虑的 nearest neighbor candidates 数量。
- "oversample": :在 rescore 之前检索多少 candidate vectors。
示例
Knn query,(100_500_1) 如下:
OpenSearch
GET search_catalog_128/_search
{
"query": {
"knn": {
"search_catalog_embedding": {
"vector": [...],
"k": 500,
"method_parameters": {
"ef_search": 500
},
"rescore": {
"oversample_factor": 1
},
"filter": {
"term": {
"valid": true
}
}
}
}
},
"size": 100,
"_source": {
"excludes": [
"search_catalog_embedding"
]
}
}Elasticsearch
GET search_catalog_128/_search
{
"query": {
"knn": {
"field": "search_catalog_embedding",
"query_vector": [...],
"k": 500,
"num_candidates": 500,
"rescore_vector": {
"oversample": 1
},
"filter": {
"term": {
"valid": true
}
}
}
},
"size": 100,
"_source": {
"excludes": [
"search_catalog_embedding"
]
}
}完整配置,以及 Terraform 脚本、Kubernetes manifests 和 benchmark 代码,可在该 repository 的 es-9.3-vs-os-3.5-vector-search 文件夹中找到。
集群设置
我们的测试运行在六台 e2-standard-16 cloud servers 上,每台有 16 vCPUs 和 64 GB RAM。在每台服务器上,我们为运行 search engine 节点的每个 Kubernetes pod 分配了 15 vCPUs 和 56 GB RAM,其中 28 GB 预留给 JVM heap。
集群运行 Elasticsearch 9.3.0 和 OpenSearch 3.5.0(Lucene 10.3.2)。由于在本 benchmark 中两者都使用相同的 Lucene 版本,因此我们观察到的 throughput 和 latency 差异不能仅归因于 Lucene,而是反映了每个 engine 在执行 filtered k-nearest neighbor (kNN) retrieval 和 rescore 时的集成和执行差异。我们使用了单个 index,包含三个 primary shards 和一个 replica(总共 6 个 shards,每个节点 1 个)。
我们还使用同一区域的另一台服务器运行 benchmark client 并收集 timing 统计数据。
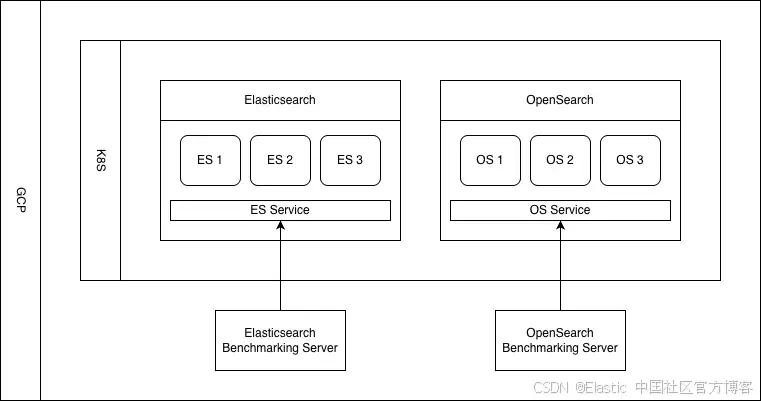
数据集
在本次基准测试中,我们使用了一个大型电商风格目录 embedding 数据集,包含 2000 万条文档,旨在反映大规模过滤向量检索的实际情况。
每条文档代表一个目录项,并包括:
-
一个 128 维的 dense vector embedding,用于近似 kNN 检索。
-
用于过滤的结构化 metadata 字段(例如,商品有效性和可用性,以及其他目录约束),支持常见的生产模式:检索最近邻时仅在符合条件的子集内进行。
我们选择此数据集是因为它捕捉了在 agentic 和 RAG 风格系统中常见的核心性能挑战:仅向量相似性不足,检索经常受过滤条件约束,系统必须在这些约束下保持高 recall 并降低 latency。相比较小的 QA 风格数据集,2000 万条文档的语料更能反映过滤 ANN 系统在实际中面临的规模和候选压力。
结论
在现代 AI 架构中,尤其是基于 context engineering 的系统,vector search 速度不是一个小细节。它是一个乘数。当 agents 和 workflows 多次执行 retrieve → reason → retrieve 循环时,检索性能直接影响端到端 latency、throughput,以及输入模型的 context 质量。
在我们的基准测试中,Elasticsearch 在依赖正确文档检索而不仅仅是相似向量的场景中,一直比 OpenSearch 提供更高的 recall 和更低的 latency。在受控数据集上,这种差异很明显;在生产环境中,这些性能提升会在大量检索调用中累积,提高响应速度、增加容量余量,并降低基础设施成本。
进一步阅读
原文:https://www.elastic.co/search-labs/blog/context-engineering-relevance-ai-agents-elasticsearch

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 39
39 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)