Elastic AutoOps 现已对所有用户免费开放:你将获得什么
Elastic宣布AutoOps功能现已对所有自托管集群免费开放。该服务通过实时问题检测和可执行建议简化Elasticsearch运维,帮助优化性能并降低成本。不同于基础监控工具,AutoOps能自动分析根因并提供具体修复方案,支持多集群管理且无需额外基础设施。无论用户使用何种许可证类型,均可获得完整功能版本。安装过程仅需5分钟,通过轻量级agent连接ElasticCloud即可使用。AutoO
作者:来自 Elastic Valentin Crettaz, Arnon Stern 及 Ori Shafir
Elastic AutoOps 现已对所有 self-managed 集群免费开放。了解你可以获得哪些功能,以及它与 Stack Monitoring 的对比情况。
通过实时问题检测和可执行的建议,简化你的 Elasticsearch 运维,以优化性能并降低成本。 AutoOps 适用于 cloud 和 self-managed 部署。了解更多 AutoOps。
无论许可证,都是同一个 AutoOps
我们让事情变得简单:从今天开始,AutoOps 通过 Elastic Cloud Connect 对所有 self-managed Elasticsearch 集群免费提供。无论你使用 Free、Basic、Platinum 还是 Enterprise,获得的都是同一套功能产品。这不是受限预览版或 “ lite ” 版本,而是大型部署正在使用的同一产品。
对自托管社区的投入
将 AutoOps 扩展到所有用户(包括使用免费发行版的用户),体现了 Elastic 对整个 Elasticsearch 社区成功的承诺。通过免费提供 AutoOps,我们正在为支撑社区搜索和分析工作负载的数十万个集群的稳定性和性能进行投入。
Elastic Cloud Connect 使 self-managed 集群能够使用 Elastic Cloud 服务,例如 AutoOps 以及最近发布的 Elastic Inference Service( EIS ),而无需在本地维护、打补丁、监控和运行这些服务所带来的运维开销。
AutoOps 在自托管场景下如何工作以及它提供什么
随着集群在复杂性和规模上的增长,你会发现自己花越来越多的时间追逐配置调整,并尝试找出问题的根因。传统监控工具向你展示指标,而当问题出现时,仍需要你(以及你最喜欢的 large language model( LLM ))手动进行关联分析来定位根因。 AutoOps 会告诉你哪里出了问题、为什么会发生,以及该如何精确修复,通过实时问题检测和具体的解决路径来实现。
AutoOps 运行在 Elastic Cloud 上,你无需预置或维护任何基础设施。你只需在本地运行一个轻量级 agent,将你的集群连接到 AutoOps 服务,运行时的操作元数据(例如 node 统计、cluster 设置和 shard 状态)会实时发送到 AutoOps,用于生成洞察和建议。你的数据始终不会离开你的环境。
AutoOps 与自托管用户的 Stack Monitoring 对比
Stack Monitoring 为你的节点和索引提供基础遥测和基本监控,展示各类指标随时间变化的趋势,并在超过阈值时发出告警,但诊断负担往往仍然落在工程师身上。AutoOps 通过关联所有相关指标,提供集群健康的完整视图,在问题发生时给出有价值的洞察以及清晰的解决指引。
更快的根因分析
你的集群一直运行正常,但在半夜突然变成 red(而且和往常一样,前几天并没有任何变更)。
-
使用 Stack Monitoring:
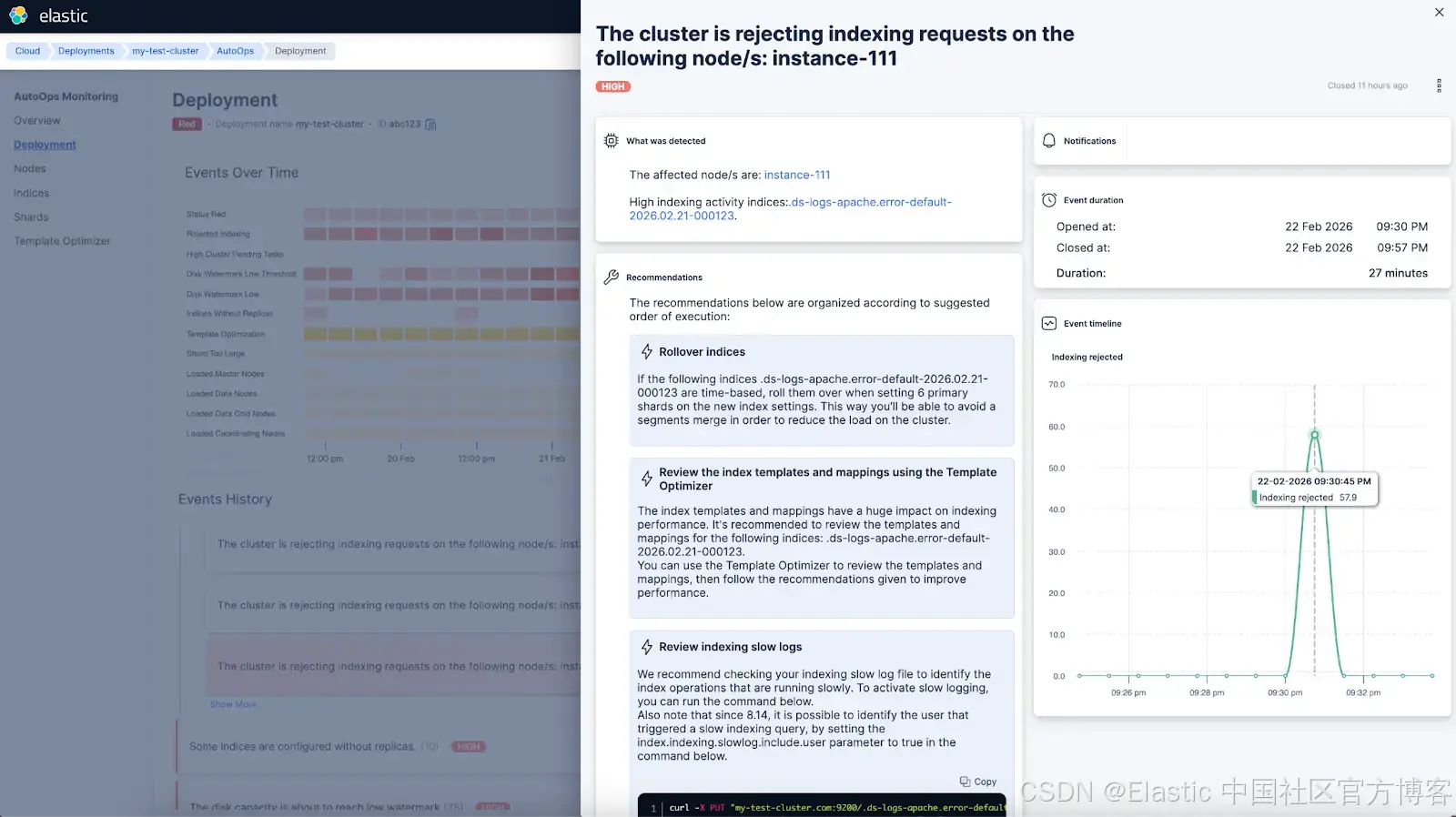
当集群健康状态变为 red 时,内置告警会通知你。要找出原因,你需要深入查看集群日志,并使用 Dev Tools 查看 shard 分配情况,弄清楚为什么那个 primary shard 无法分配。查看告警历史时,你还会看到两天前有一条告警提示 hot 节点的磁盘使用率达到了 80%。但你找不到磁盘使用情况的图表来进一步了解磁盘增长速度,只知道磁盘随后达到了 90% 使用率。当某个 data stream 需要 rollover 时,创建了新的 backing index,但 shard 无法分配到任何节点上。 -
使用 AutoOps:
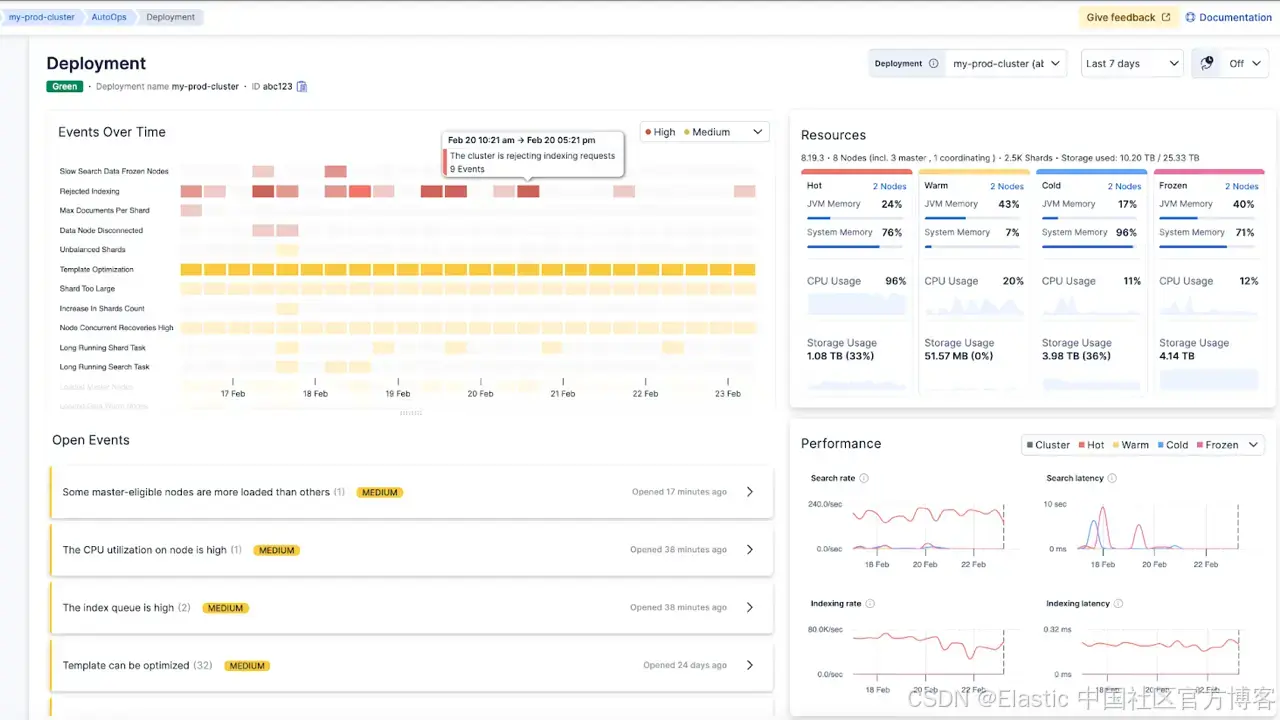
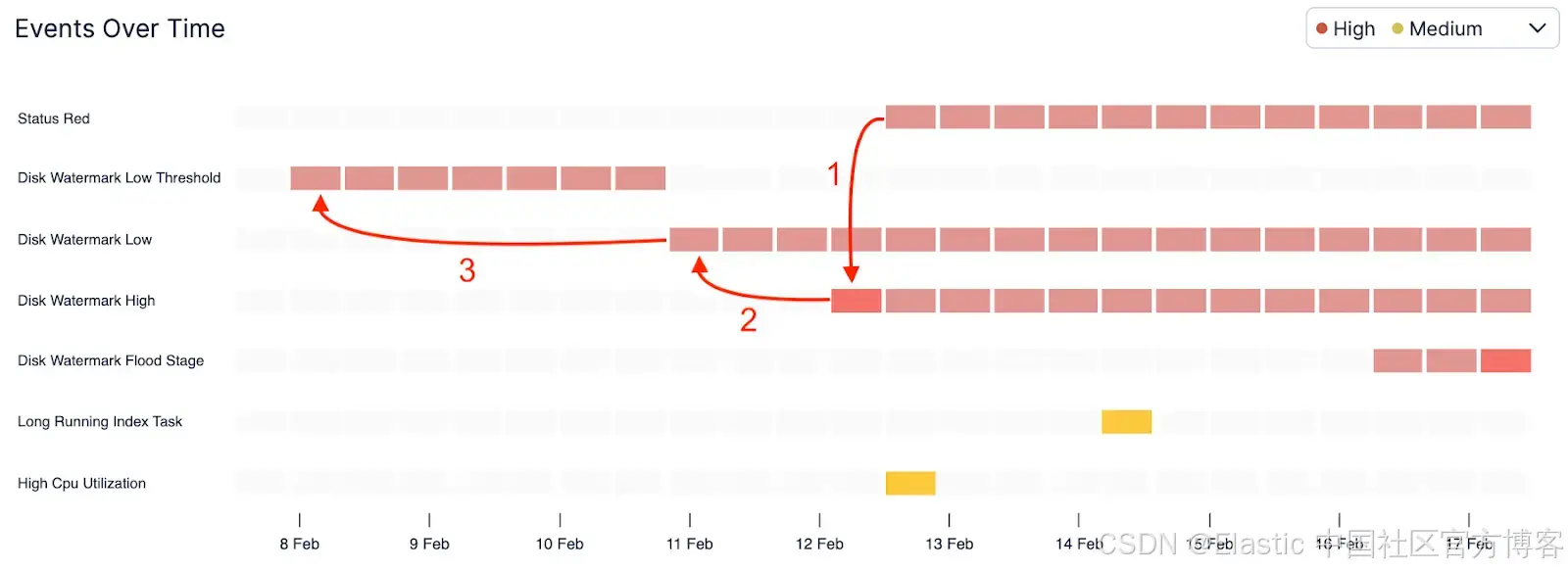
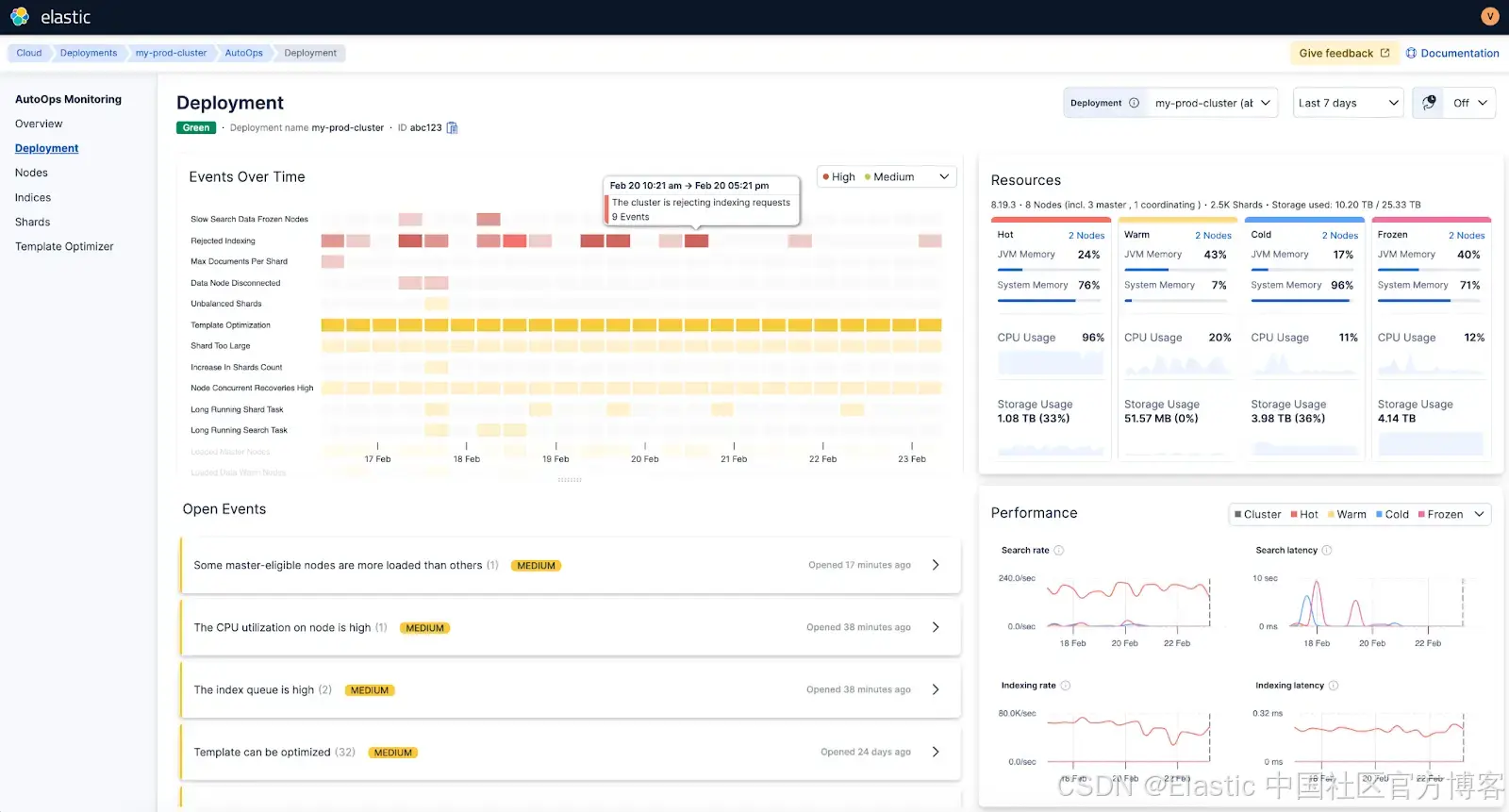
当集群变为 red 时,系统会通知你(1)。查看时间线后,你会立刻意识到,这是因为你没有对 AutoOps 之前发出的 watermark 事件采取行动 —— 包括最近开始出现的 high watermark 事件(2),以及过去几天逐步累积的 low watermark 事件(3)。现在,你可以很清楚地知道需要做什么,才能让集群恢复到 green 状态。
更高的信噪比
保持 Elasticsearch 集群健康很可能是你最关心的事情。然而,集群健康状态在 green 和 yellow(有时是 red)之间来回波动并不少见,而且其原因并不总是值得你花时间处理。
-
使用 Stack Monitoring:内置的 “Cluster Health” 告警会在每次健康状态从 green 变为 yellow 或 red 时触发。在某些情况下(例如频繁创建索引),这会产生大量重复且不必要的噪音。此外,更重要的是,它并不会区分 yellow 和 red 状态。
-
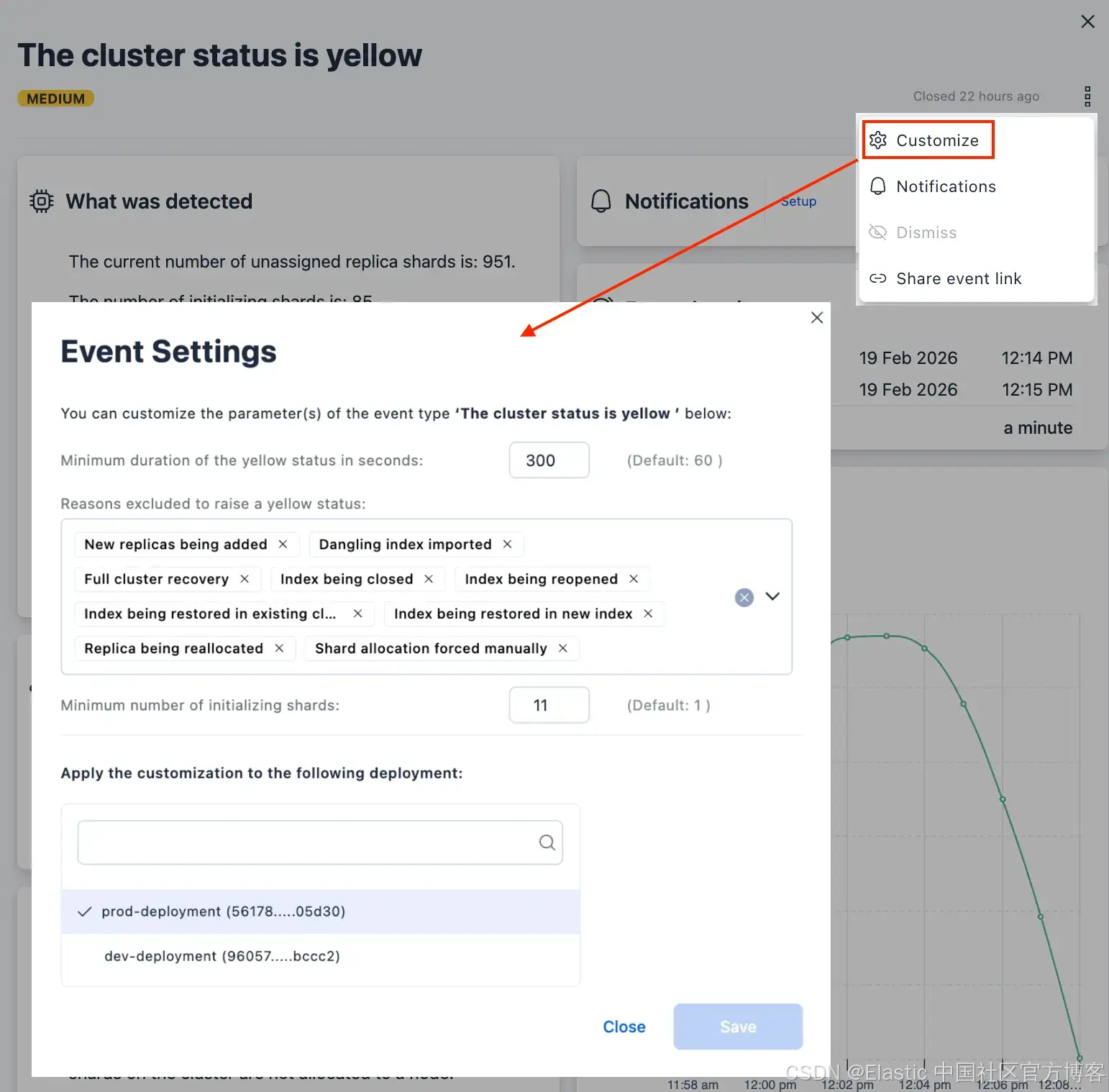
使用 AutoOps:AutoOps 提供了独立的 “Status Red” 和 “Status Yellow” 事件,并且具有不同的严重级别。后者可以通过多种方式进行自定义,以适配你的使用场景,如下方截图所示。
- 由于集群健康状态有时只会短暂变为 yellow,你可以设置在通知之前需要忽略 yellow 状态的时长(例如下图中的五分钟)。
- 此外,Elasticsearch 有许多正常的日常操作都会导致集群暂时变为 yellow。你可以选择当这些操作导致 yellow 状态时不接收通知(例如添加副本、迁移副本、关闭或打开索引等)。
- 最后,也是最重要的一点,如果你需要管理多个集群,你不必为每个集群单独配置这些规则;只需决定将该配置应用到哪些集群即可。简单而强大!
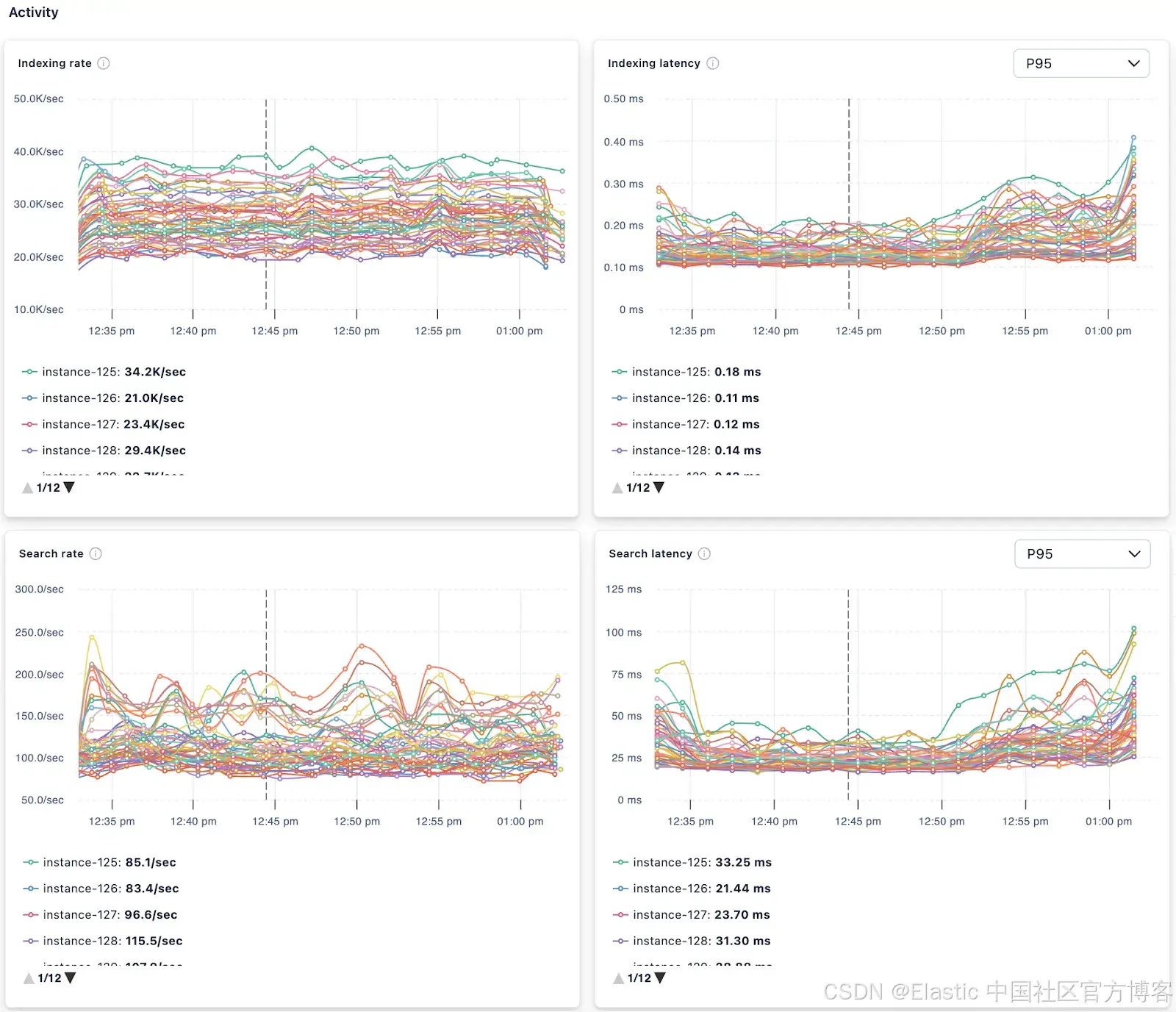
对节点指标更有洞察力的关联与对比
当你的集群规模不止几个节点时,通常需要比较各个节点之间的表现,尤其是在查看搜索和索引性能时。
-
使用 Stack Monitoring:
Nodes 列表无法让你聚焦到特定的数据层,也不提供可排序的搜索或索引性能指标。这些指标虽然存在,但只有在深入查看单个节点时才能看到,这使得节点之间的性能对比变得困难。 -
使用 AutoOps:
Nodes 视图允许你选择特定数据层的节点,并提供超过 50 种指标可视化,其中包括搜索和索引性能。这些可视化能直观地帮助你理解各个节点之间的性能差异,以及是否存在需要关注的“吃力”节点。如下图所示,我们可以看到有些节点的索引速率是其他节点的两倍,而搜索延迟则累积到最快节点的四倍。
主要差异的快速概览
下面简要展示了 AutoOps 与 Stack Monitoring 之间的一些显著差异,更详细的对比说明可在我们的官方文档中查看。
| 能力 | Stack Monitoring | AutoOps |
|---|---|---|
| 集群、节点和索引指标 | 是 | 是 |
| 实时仪表板 | 是 | 是 |
| 多集群概览 | 否 | 是 |
| 根因分析 | 否 | 自动化分析 |
| 修复建议 | 无 | 上下文中的 Elasticsearch 命令 |
| 性能调优洞察 | 无 | 是,基于使用模式 |
| 告警与通知 | 14 个内置告警 + 27 个 connector | 100+ 可自定义告警 + 7 个 connector |
| 模板与映射分析 | 无 | 检测 mapping 配置错误 |
| 部署基础设施 | 独立的 monitoring 集群 | 5 分钟安装;无需额外基础设施且无成本;仅需安装轻量级 agent |
| 其他 stack 组件 | Kibana、Logstash、Elastic APM | 即将推出 |
立即开始:五分钟安装
无论你的许可证类型如何,连接集群只需几分钟:
-
登录你的免费 Elastic Cloud 账户,或注册一个新账户。
-
选择连接集群的方式:Elastic Cloud on Kubernetes (ECK)、Kubernetes、Docker 或 Linux。
-
输入你的 Elasticsearch 集群 endpoint,并运行单条命令安装并启动轻量级 Elastic agent。
-
在你的 Elastic Cloud 账户中访问 AutoOps。
有关 AutoOps 的更多信息以及连接自托管集群的操作指南,请阅读我们的产品文档。
如有问题,请联系我们
欢迎通过以下方式向我们分享你的问题和想法:加入我们的 Slack 社区、在 Discuss 论坛发帖,或点击 AutoOps 产品页面的 “Give Feedback” 按钮。如果你连接的是付费的自托管 Platinum 或 Enterprise 集群,也可以在 Elastic Cloud 账户中联系支持团队。
了解更多
如果你想进一步了解 AutoOps 及其功能,请访问官方 AutoOps 文档以及以下 Elastic Search Labs 文章:
原文:https://www.elastic.co/search-labs/blog/elastic-autoops-free-for-self-managed-elasticsearch

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)