使用STM32CubeMX部署AI模型流程
项目生成后我们用keil5打开项目后发现当前项目于先前的项目不同的地方在于多了一个新的文件夹,文件夹中的文件都为与AI模型相关的文件因此我们只需要了解新增文件中的内容就可以轻松实现AI模型的调用文件:这两个文件的名称与我们在添加AI模型时自定义的AI模型名称相同,因此不难推出这两个文件中存储了AI模型的相关信息,其中C文件中存储了模型的结构、接口函数的实现代码,头文件中声明了模型的接口函数、宏定义
内容简介
本文章主要介绍如何将AI模型部署到单片机上,并实现一些基础的逻辑功能,本次文章主要从模型获取,模型部署以及模型使用三个层次进行介绍
模型获取
在模型部署的前期阶段我们并没有独立制造模型的能力,但本阶段我们的目标是去使用模型而非创造模型,只要能够成功部署并调用模型本阶段的任务就圆满完成了,因此本阶段我们的模型只能自己想办法去获取,主要途径如下
意法半导体官方获取
在STM32CubeMXAI的官方下载页面中下拉就可以找到对应的官方模型库
网址如下
https://stm32ai.st.com/zh/stm32-cube-ai/
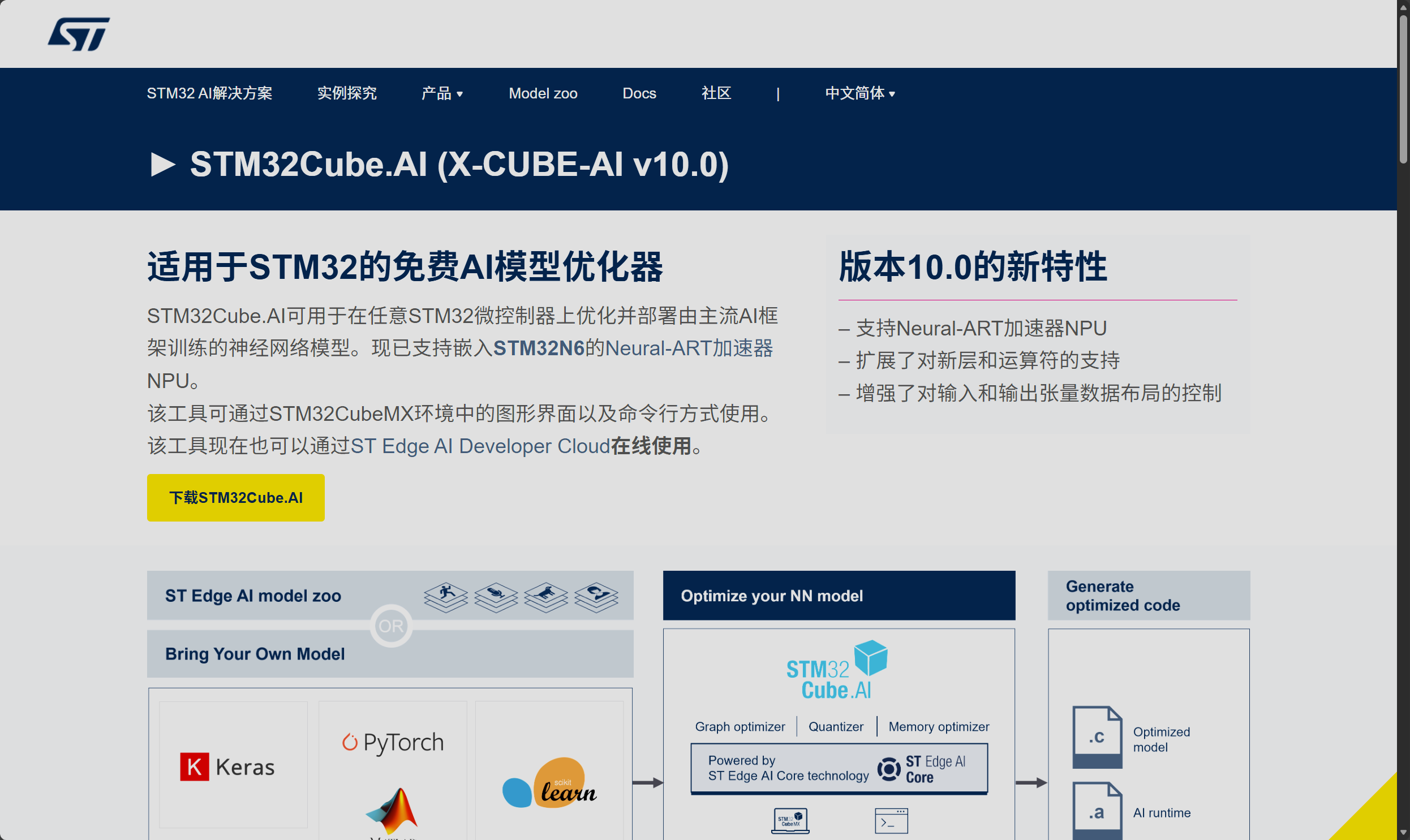
下拉后可以看到对应的STM32 Model Zoo的相关信息,点击了解更多信息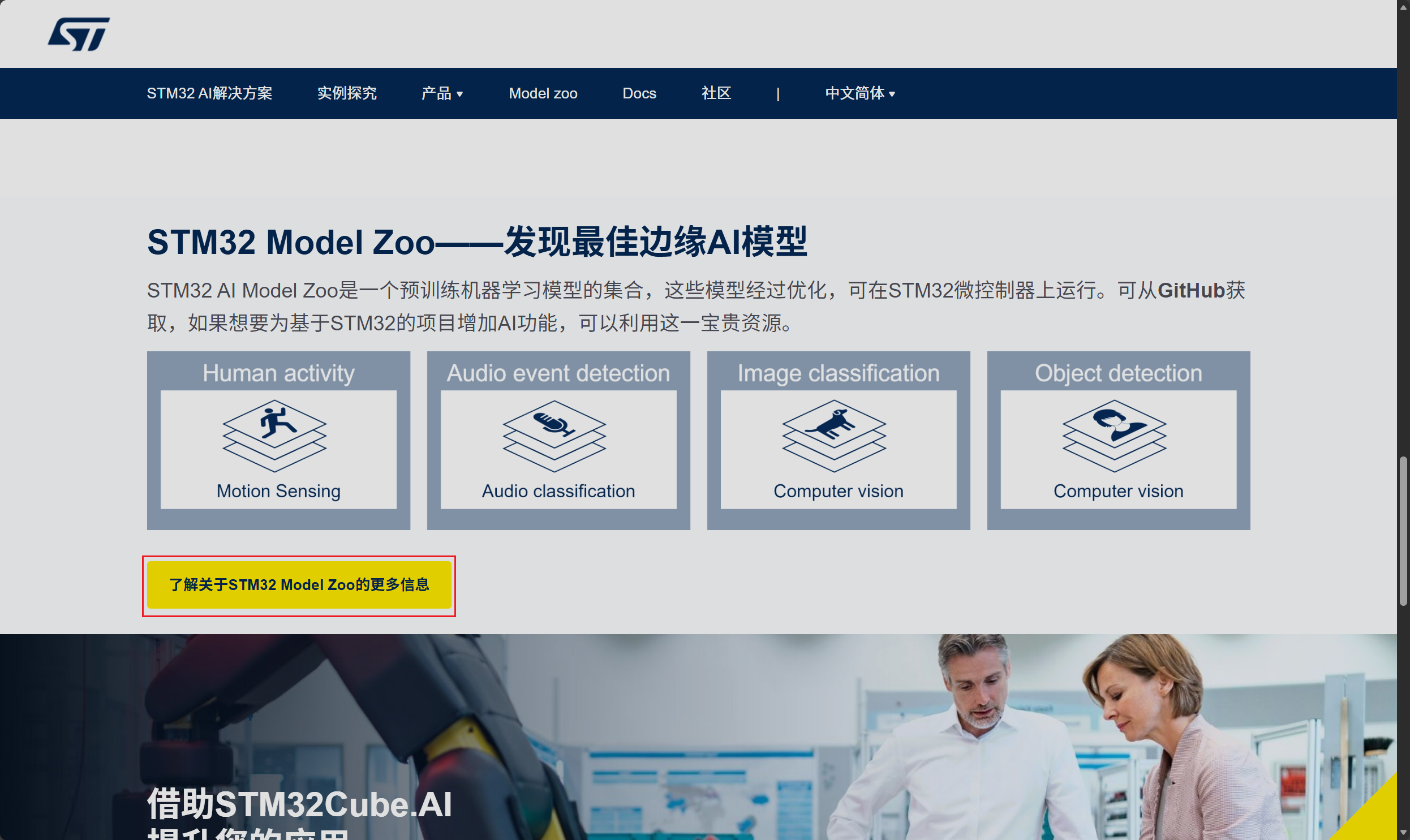
在新弹出的页面中选择前往Model Zoo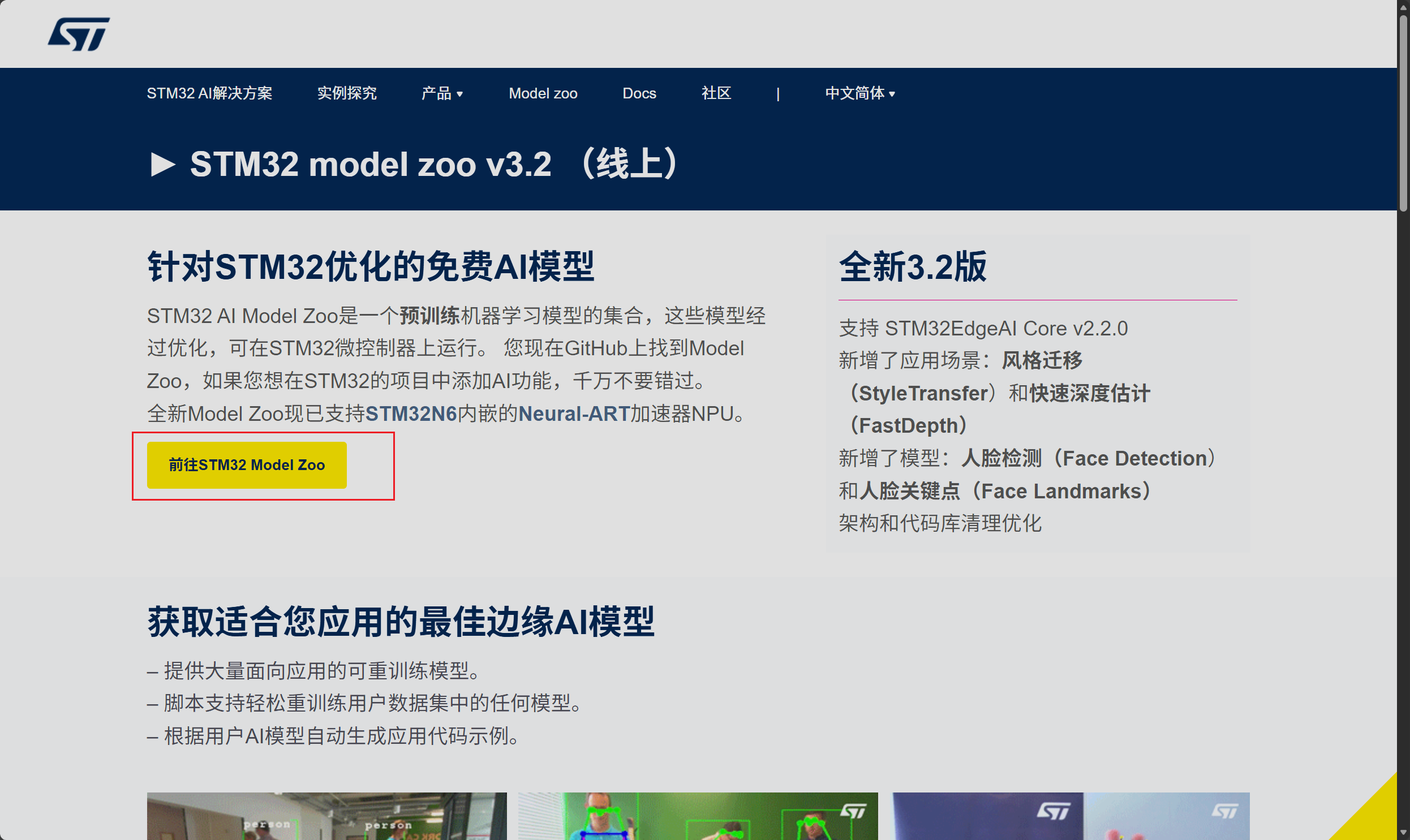
随后我们便跳转到了意法半导体官方在GitHub上提供的模型仓库,
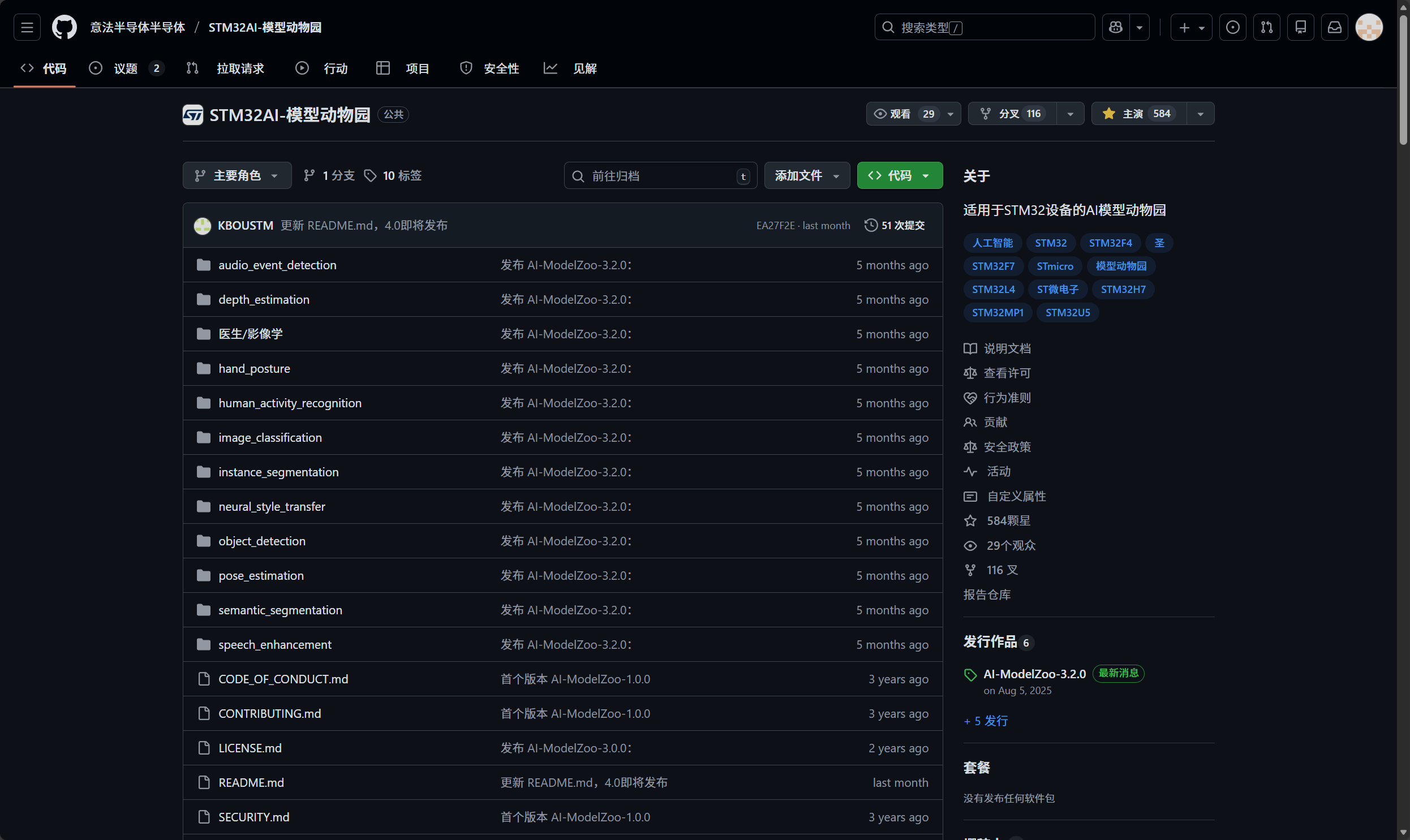
下拉即可找到不同类型的开源模型
通过观察不难发现官方提供的AI模型大多用于进行图像处理相关操作,这对开发板的板载芯片性能要求较高,且需要使用到对应的摄像头模块,最重要的部署难度也很高,因此对本阶段的学习并不友好,如果后面大家熟练掌握了如何进行模型部署后,或需要使用单片机进行图像处理的相关工作时可以回来再看看有没有满足自己使用需求的AI模型
关于模型下载的网络环境提示
意法半导体提供的AI模型主要分别存放在GitHub和Hugging Face网站中。由于这两个都是国际开源社区,国内用户在直接访问时可能会遇到页面加载缓慢、响应超时或资源无法下载等网络不稳定的情况。
建议大家在获取这些官方模型时,尽量保持良好的网络环境。如果你在下载过程中反复遇到超时问题,可以尝试在 Gitee(码云)等国内代码托管平台上搜索 STM32 Model Zoo 相关的镜像搬运仓库,这能极大提高你的模型获取效率。
浏览器搜索获取
现在在各大浏览器中搜索TInyML,Edge AI等关键词都能获得相应的教程,一般情况下对应教程中也会提供相应的模型供我们去复现相关操作,当然在微信公众号以及B站等平台都可以尝试搜索相关内容
模型部署
环境搭建
将AI模型部署到MCU上有手动和自动两种方式,绝大多数情况下我们选择自动化部署方式,自动化部署就需要使用到STM32CubeMX软件进行相关的自动化操作,但STM32CubeMX并不能做到开箱即用,需要在原有基础上进行一些改动,这里默认大家都以及成功安装好了CubeMX,并且能够正常使用CubeMX进行单片机程序的初始化操作
-
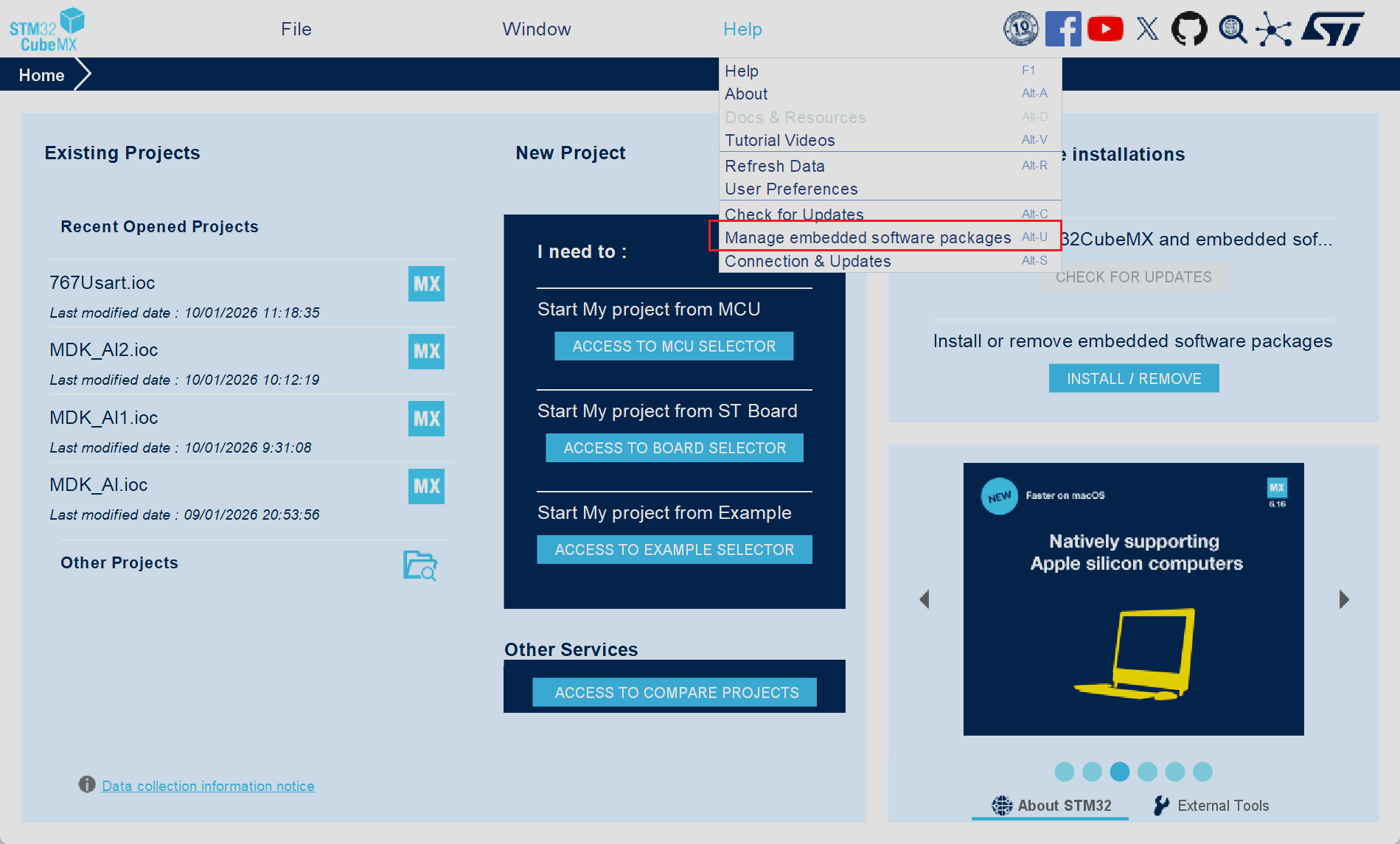
打开软件在初始界面中选择Help选项,并在随后的弹窗中选择Manager embedded software packages选项,或者直接按下键盘快捷键Alt+U
-
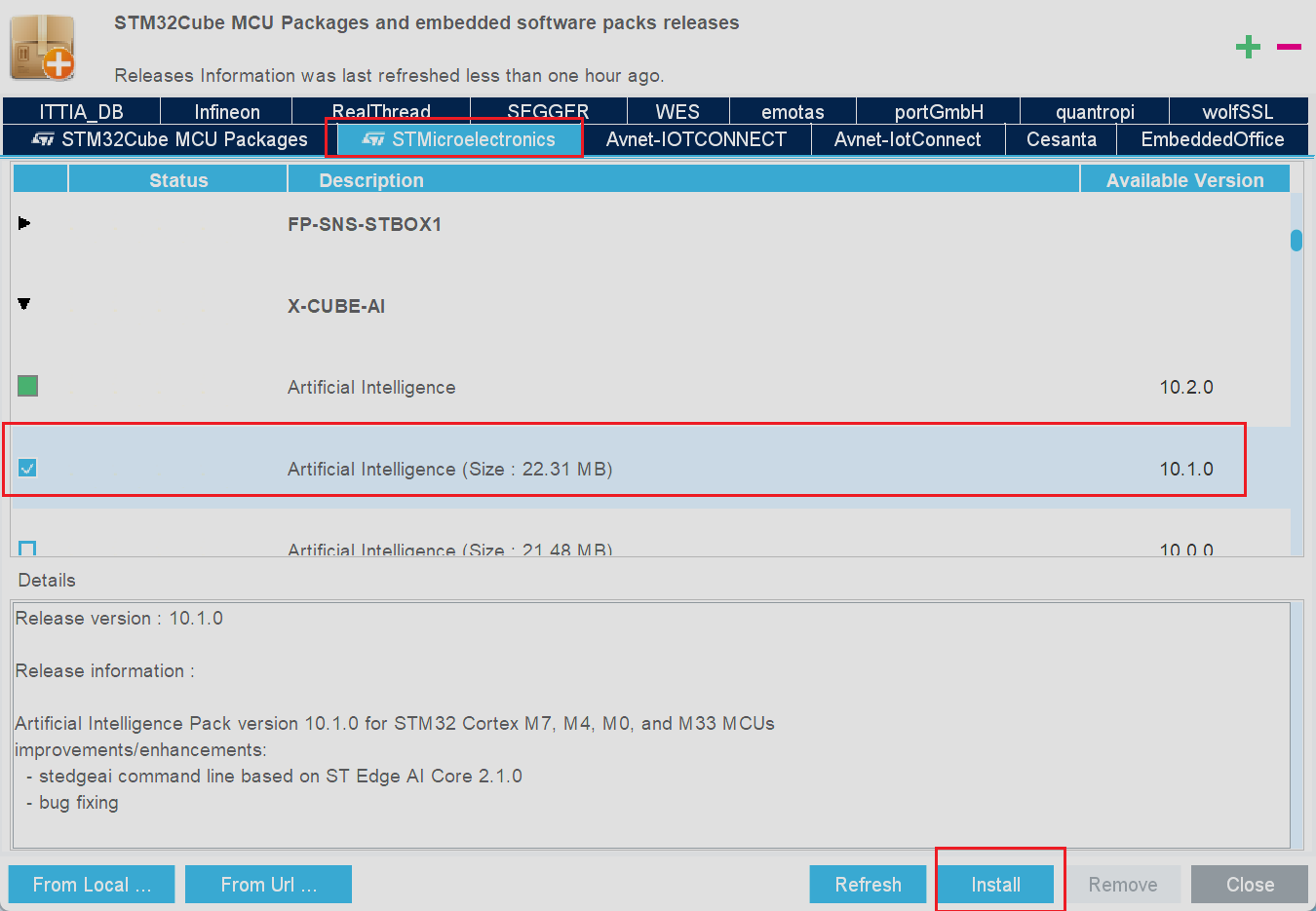
在新弹出的界面中选择STMicroeletcronics选项,并在下面的选项框中下拉找到X-CUBE-AI选项,点开折叠区并在下方选择需要安装的版本,随后选择install选项即可
-
至此基本的AI模型环境搭建操作就完成了
模型部署流程
单片机型号选择
我们打开CubeMX像往常一样尝试创建一个新的MCU工程,随后来到了芯片选型界面,在左侧的选项栏中一直下拉,就可以在最后一栏看到对应AI模型使能选项,勾选对应选项即可实现AI功能的使能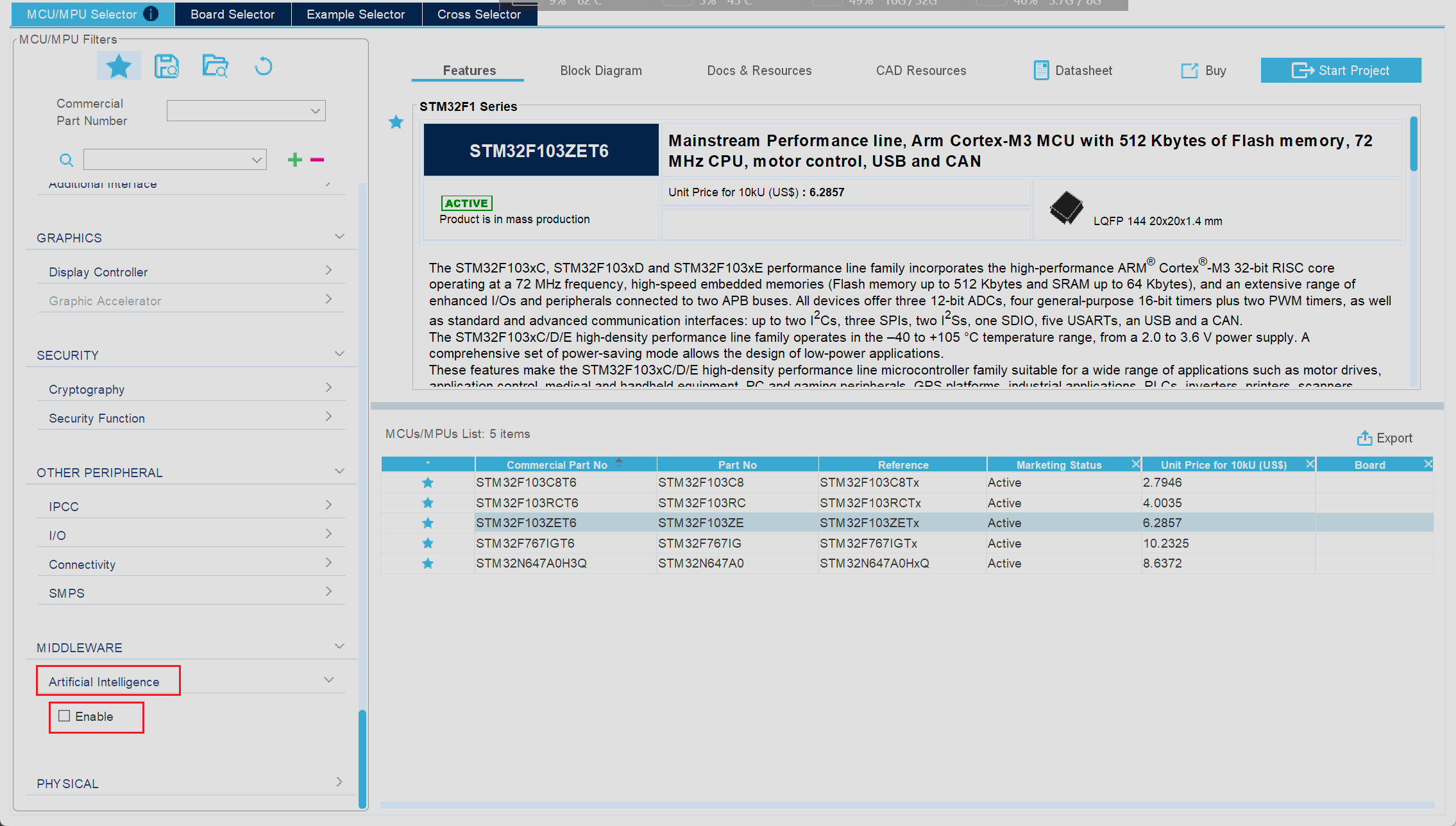
但是如果此时我们选取的是F1系列的芯片我们就会发现,此时对应的选项框为无法选择状态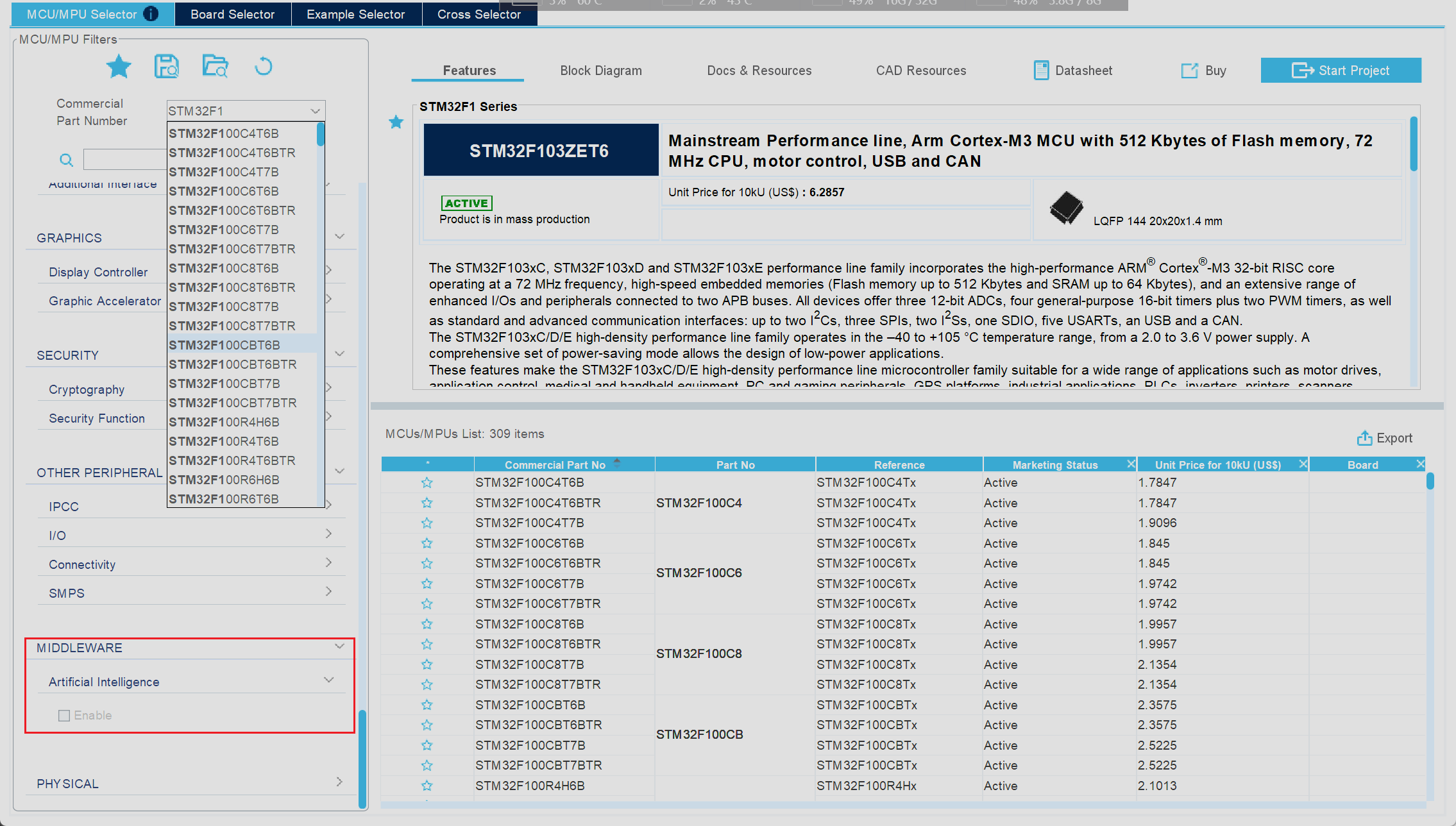
由此可以看出CubeMX并不支持对F1系列芯片进行AI模型的自动化部署功能,主要原因是F1系列芯片性能较差,因此CubeMX就默认不支持对F1系列芯片的自动化操作,但是这并不意味着我们不能在F1系列芯片上运行AI模型,我们可以手动将较小型的AI模型移植到F1系列芯片中,但是操作流程也会非常复杂
模型选择与部署
- 本次我使用的是正点原子的F7系列开发板,在工程创建后通过图形化界面对工程项目进行一系列的初始化操作
- 当时钟以及串口等相关基础配置设置完成后即可进行AI模型的部署,在图形化界面中选择Software Packs,并在弹出的选项框中选择Select Components,或者直接按下键盘上的Alt+O快捷键
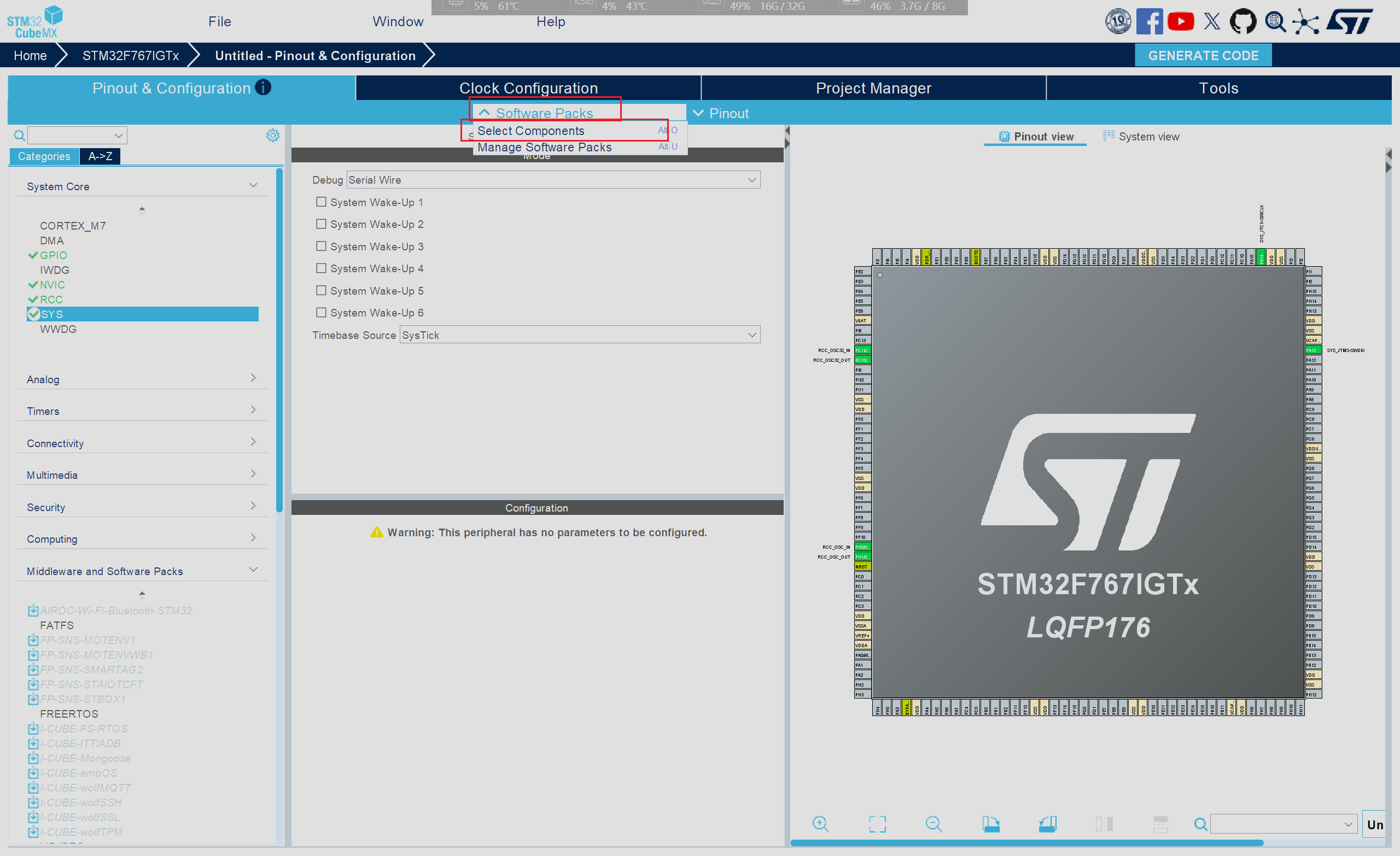
在弹出的新窗口中进行相应模型功能的使能和添加工作,在对应的选项框中打勾,并选择对应的模式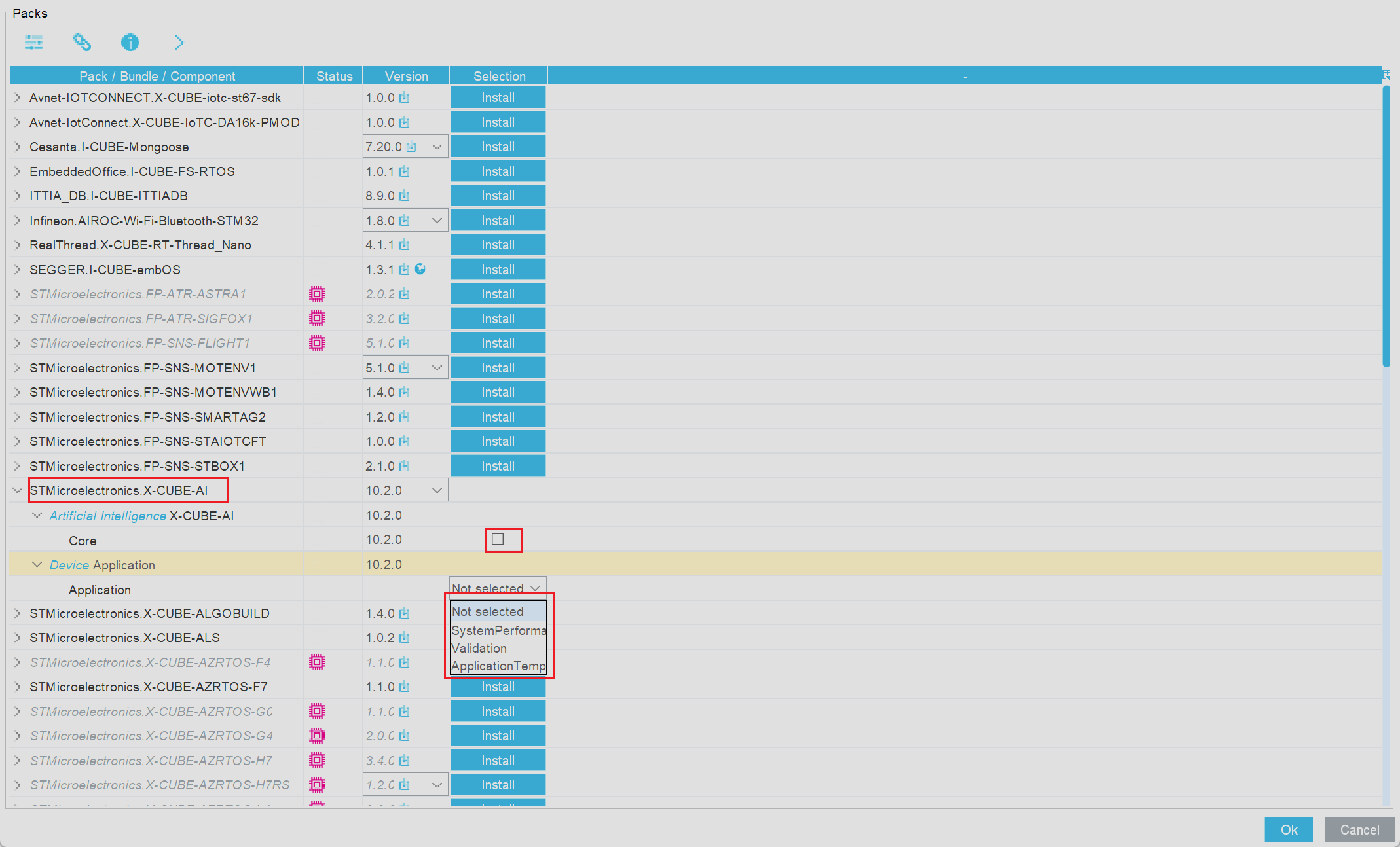
选择X-CUBE-AI折叠选项中的Core之后即可激活对应的AI功能,随后下面的选项框中就是在选择不同的模式,三种模式的应用场景各不相同
- SystemPerformance模式主要用于评估在STM32硬件上的实时性能指标(如推理时间、CPU负载等),主要应用于模型部署前的性能分析
- Validation模式主要用于验证模型转换后的准确性,该模式可以在桌面环境和MCU中进行验证,主要应用于模型转换后的可靠性检查,防止压缩以及量化导致的精度损失
- Application Template模式主要目的为提供AI模型的框架,便于用户添加对应的业务逻辑,相应的功能需要用户自行扩展,例如传感器数据采集等等,此模式应用于实际的落地项目中
根据我们目前的需求来说,我们不需要进行AI模型的可靠性检测,因为别人已经完成了这一部分操作,因此我们只需要进行模型的部署,以及模型的调用工作即可,在此我们选择Application Template模式
选择成功后在左侧的侧边栏中选择最底部的折叠选项卡,在随后弹出的新选项中选择X-CUBE-AI,并在侧边栏右侧的新窗口中点击Add network选项为当前项目中添加新的AI神经网络模型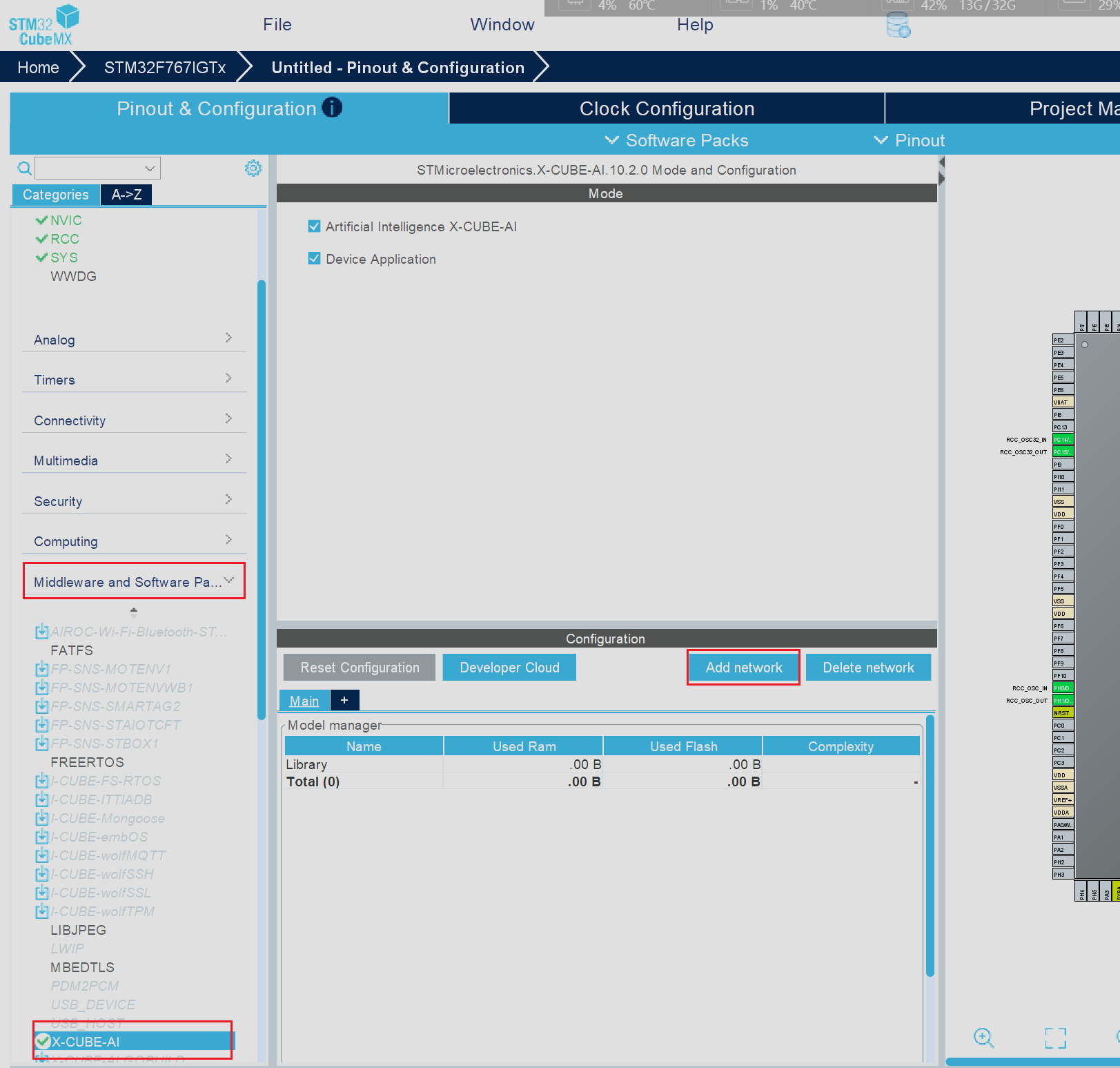
接下来我们就可以在弹出的新窗口中进行AI模型的相关配置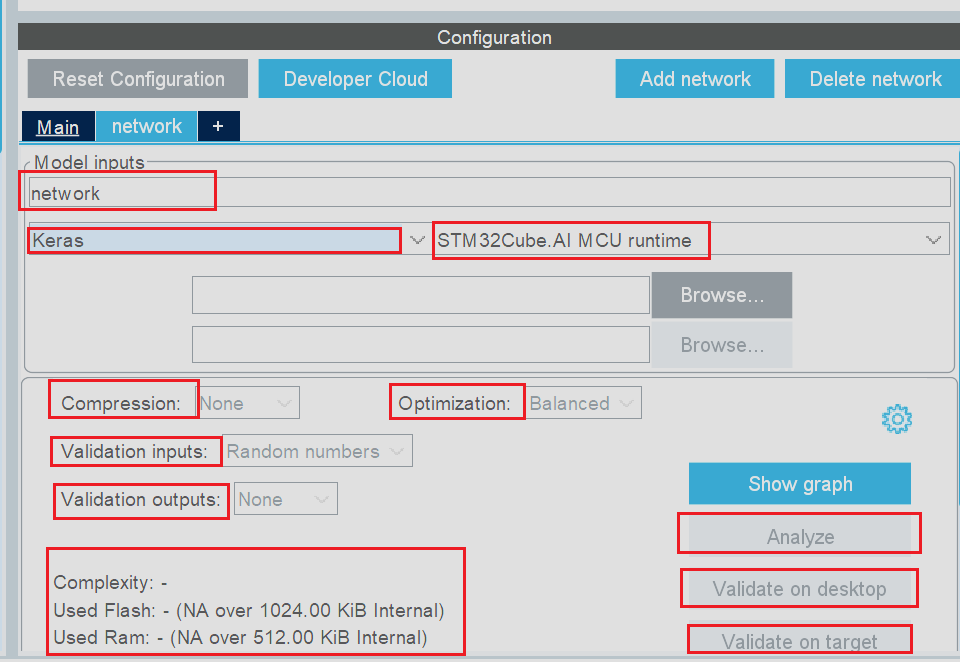
当前界面中的选项作用依次如下:
network所在栏代表的是当前AI模型的名称,支持用户自定义Keras所在栏代表AI模型文件的格式,当前CubeMX支持三种AI模型的格式,分别是Keras(对应AI模型文件后缀为.h5)、TFLite(对应AI模型文件后缀为.tflite)以及ONNX(对应AI模型后缀为.onnx),我们在使用这些AI模型的时候只需要注意选择合适的文件类型以及相应对应的文件格式即可Compression代表压缩等级,当当前AI模型体积较大无法完整写入MCU时可以使用当前选项,对AI模型进行适当的压缩,以减少资源消耗Optimization代表优化等级,即会对当前AI模型进行空间优化以及推理时间优化等Validation inputs作用为提供验证数据源,当选则Random numbers时代表使用随机生成的数据进行验证,当然我们也可以使用自己提前准备好的数据进行验证Validation outputs控制验证输出结果的处理方式,这个选项使用到的频率较低- 下面的
Complexity、Used Flash以及Used Ram在没有选择AI模型时展示了当前的MCU的硬件资源,即当前真展示的当前使用的MCU有着1MB的Flash以及512kb的Ram,用电脑的概念来类推就是当前MCU有1MB的磁盘和512KB的内存 Analyze选项的作用为验证当前AI模型能否在MCU上正常运行,例如倘若AI模型的体积较大时便会出现警告validate on desktop以及validate on target就是分别在PC端的MCU端进行模型的可靠性验证
了解了AI模型配置面板的基本功能后选择合适的AI模型类型,本次我们使用的AI模型类型文件的后缀为.tflite,依次需要选择TFLite类型的AI,选择完成后点击Browse选项,随后在对应的文件夹中找到下载好的AI模型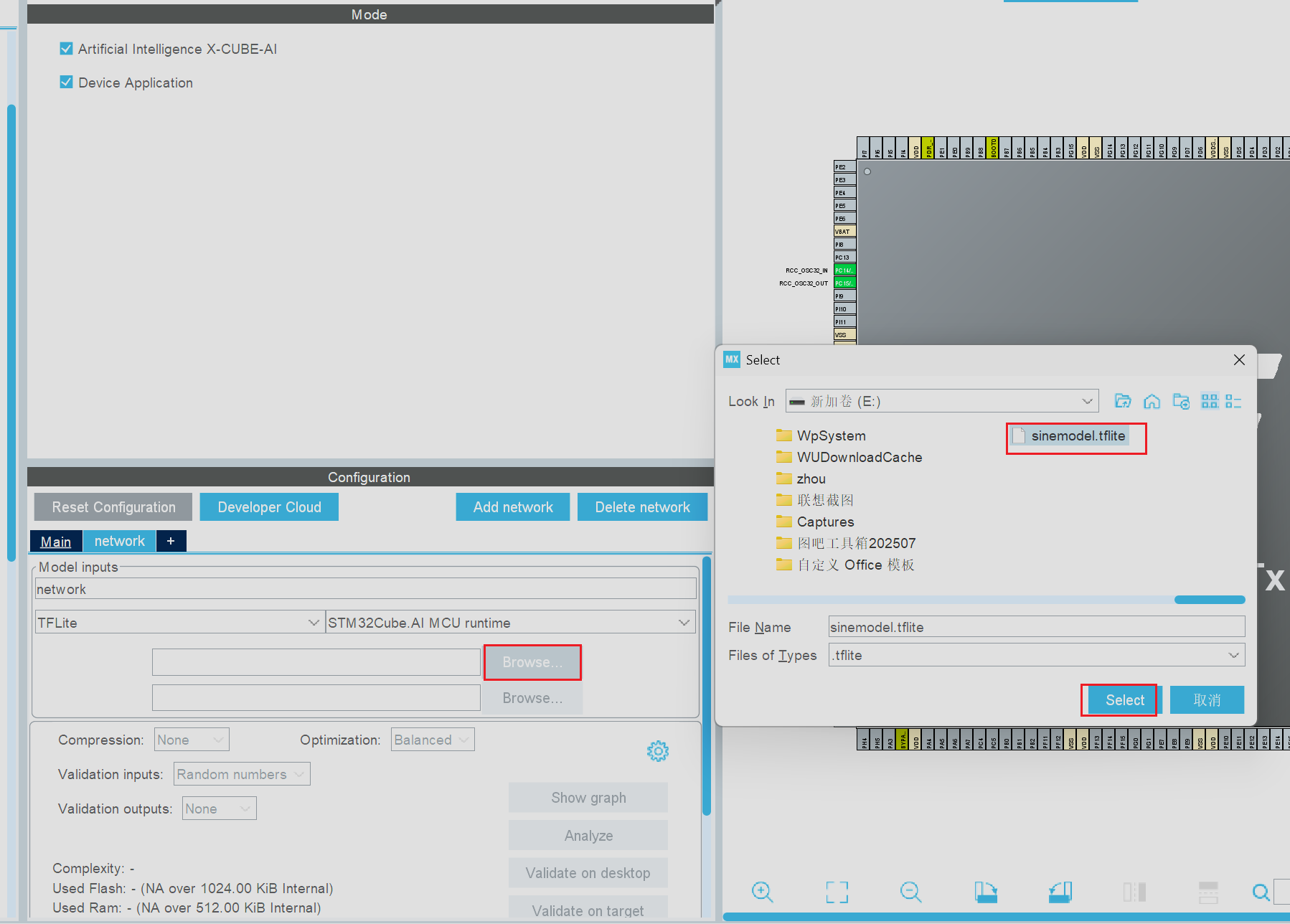
随后点击Analyze选项,当结果不报错时即代表模型可以正确烧录到MCU中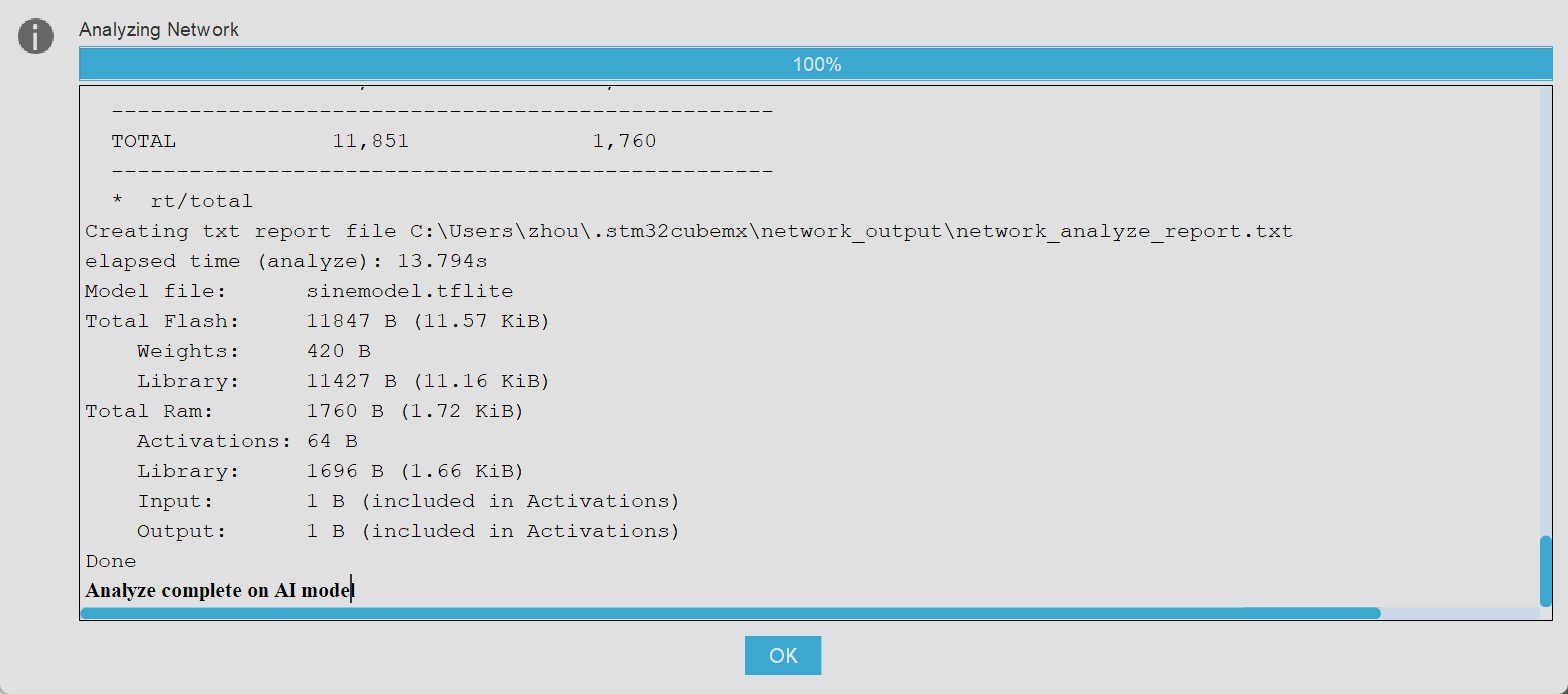
从分析界面中可以查看到AI模型占用的AI资源,Flash和Ram等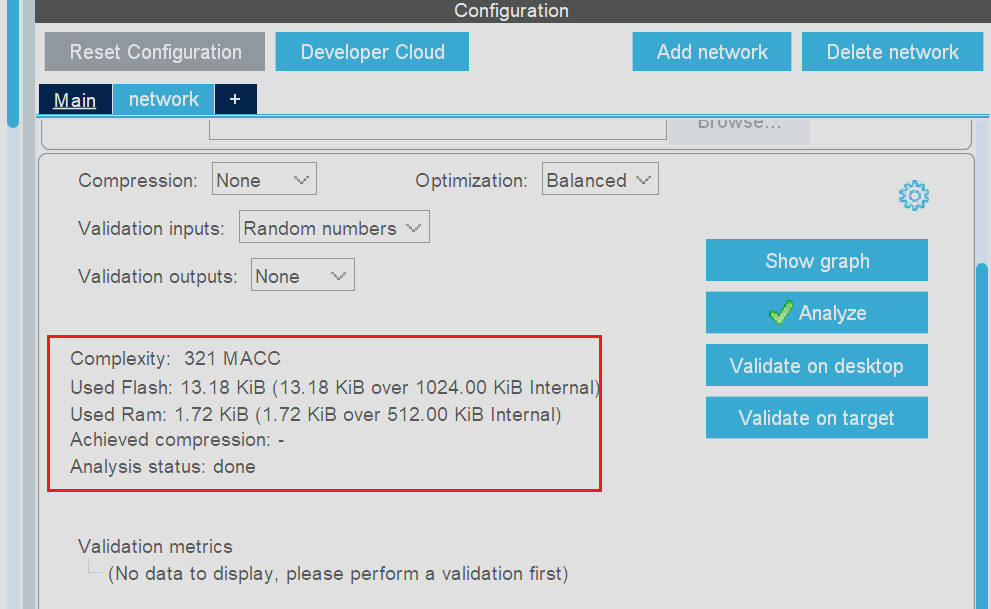
如果AI模型占用的资源超过了当前选型的芯片则可以尝试使用Compression选项对模型进行压缩,随后我们点击进入项目配置界面填写相应的工程名称以及使用的IDE(本次使用MDK_ARM)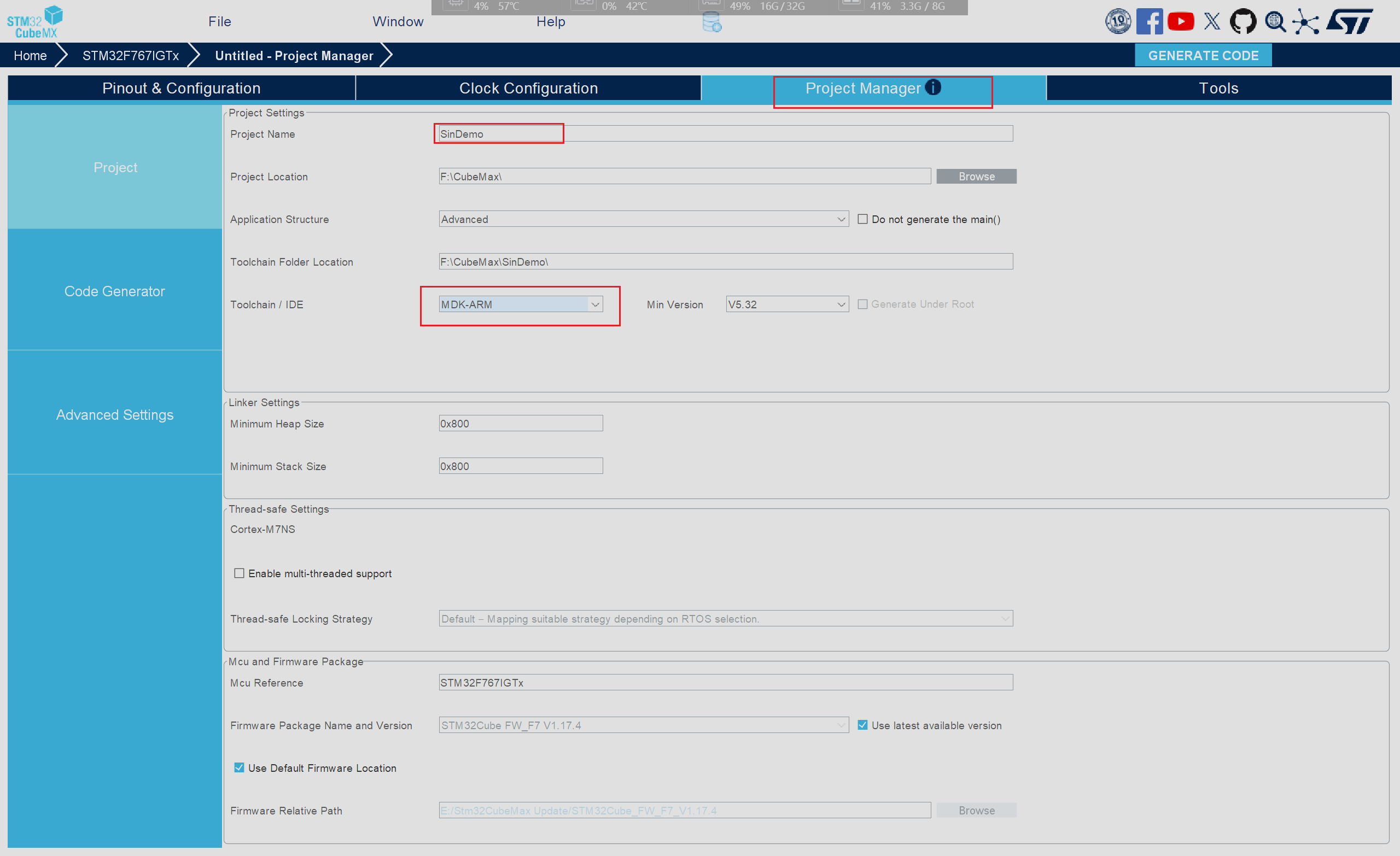
随后点击对应的Code Generator栏目并进行相应改进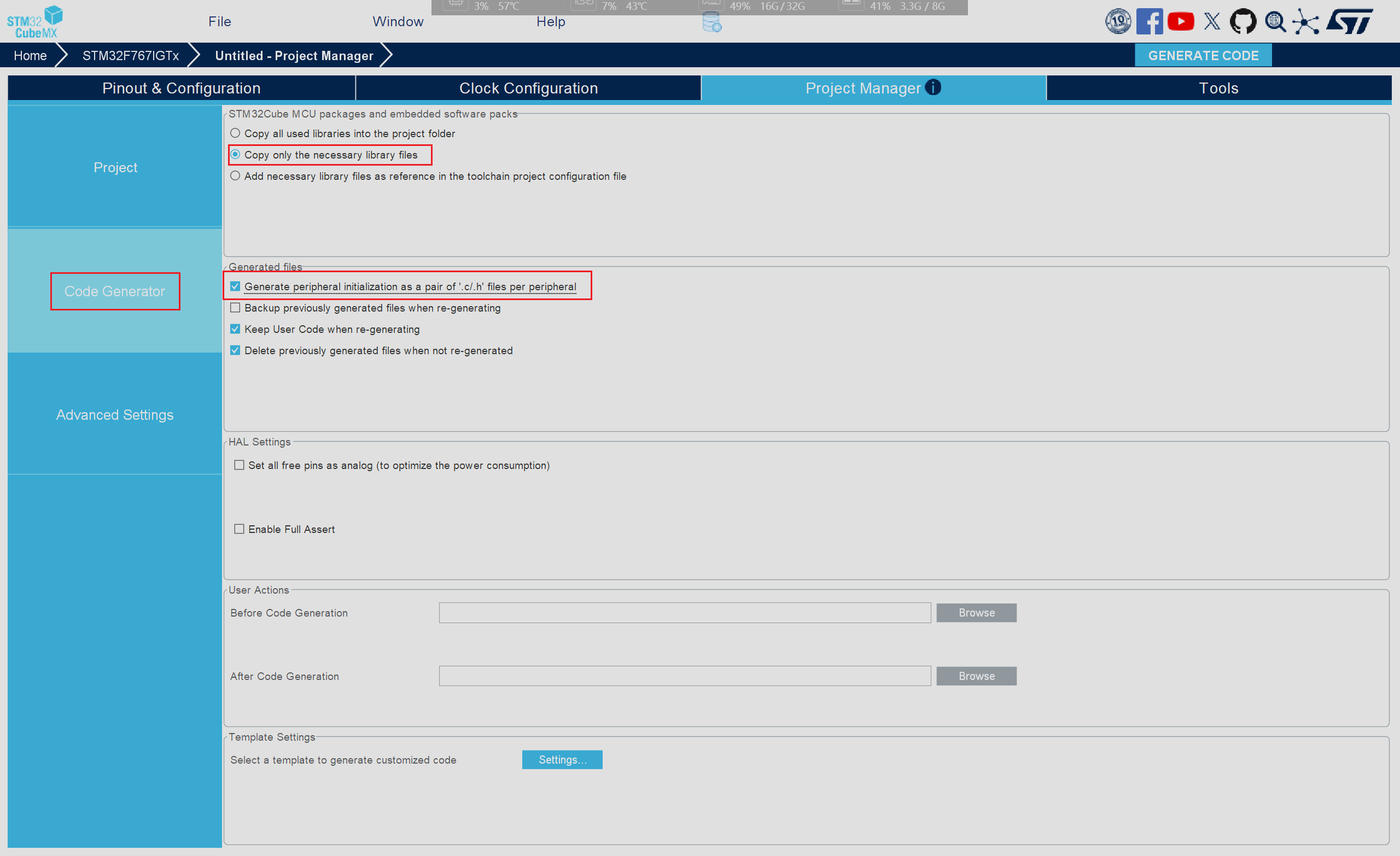
最后即可点击右上角的Generator CODE即可一键生成对应的工程
模型使用
生成文件介绍
项目生成后我们用keil5打开项目后发现当前项目于先前的项目不同的地方在于多了一个新的文件夹,文件夹中的文件都为与AI模型相关的文件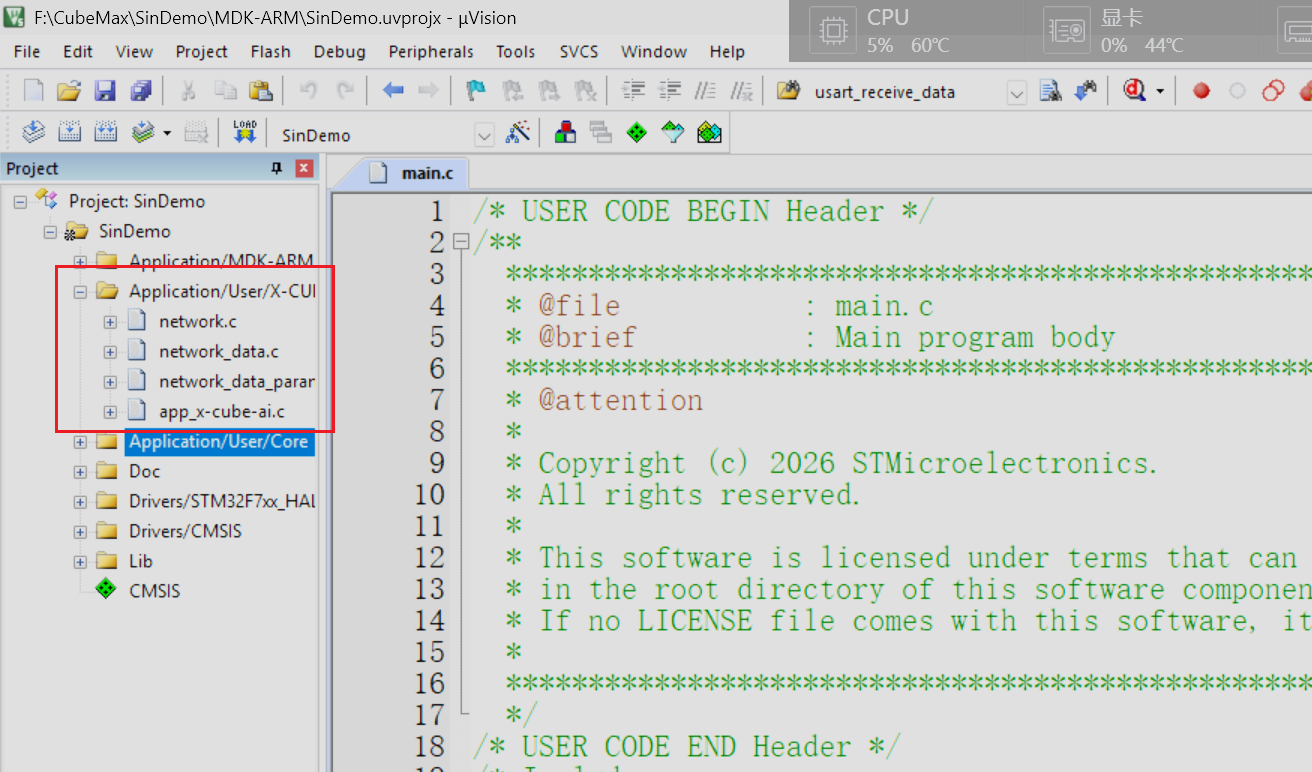
因此我们只需要了解新增文件中的内容就可以轻松实现AI模型的调用
新增文件中有4个.c文件,每个C文件又对应一个头文件,因此相当于新增了8个与AI模型有关的新文件,但是这并不意味着我们需要详细了解每一个文件中的内容,这几个文件的作用各不相同:
network.c/network.h文件:这两个文件的名称与我们在添加AI模型时自定义的AI模型名称相同,因此不难推出这两个文件中存储了AI模型的相关信息,其中C文件中存储了模型的结构、接口函数的实现代码,头文件中声明了模型的接口函数、宏定义等;network_data.c/network_data.h文件:这两个文件同样与模型本体信息有关,其中存放的是存储模型的权重(Weights)和偏置(Bias)等参数,这些通常是常量数据,存储在Flash中network_data_params.c/network_data_params.h:该文件是连接您训练好的AI模型和STM32嵌入式硬件的桥梁,当前文件相当于AI模型的数据仓库,AI依赖此文件中的内容才能够正常进行推理工作
上述文件在开发时有一个共同的特点就是我们不需要也不能够修改文件中的内容,我们只需要大致了解问价中的内容即可,具体的AI运行逻辑函数的编写大多在app_x-cube-ai.c文件中编写,其中为我们提供了空的模板函数,我们可以在其中完善自己需要的业务逻辑,如果觉得麻烦也可以直接在main.c文件中直接编写对应的函数
代码编写流程
由于CUBEMX的AI模型库并不开源,因此如果我们想要进行AI模型初始化以及AI推理等函数功能的实现就必须要调用官方提供的API函数,上述文件中我们提到AI模型的函数接口都在network.h中进行了对应声明,因此我们可以在该头文件中查找对应的API函数,在这里简单介绍一下常用的API函数以及其对应的功能
ai_network_create:创建模型实例,分配AI模型的基础内存ai_network_init:初始化模型,设置权重和激活内存ai_network_run: 执行一次推理,并获取输出ai_network_inputs_get:获取输入缓冲区的指针ai_network_outputs_get:获取输出缓冲区的指针,用于获取输出ai_network_get_error:在API调用失败后,获取并清除最近的错误码
至于如何使用官方提供的API函数这里推荐大家可以去看看意法半导体官方提供的操作案例
这篇B站教程虽然简短,但是也较为完整的阐述了整个AI模型调用的过程
【【STM32】游戏开发部教你在STM32上跑神经网络识别手写数字】https://www.bilibili.com/video/BV11C411W797?vd_source=84444fb51d2762afe0c8fdcbef574586
当你看完这些文章后应该就对AI初始化函数和AI模型运行过程的函数有了大致的了解,接下来就让我们尝试着手编写这些函数
接下来的函数的声明和定义都在main.c文件中完成,主要是为了减少操作流程
重写fputc函数
本次程序中将会调用AI模型来实现将对应的角度的正弦值通过串口输出到PC端,由于不同的MCU对应的串口引脚不同为了减少复刻难度我们可以将串口输出统一通过printf函数来实现:
- 由于
printf函数的底层实现依赖的是fputc函数,因此我们只需要重写fputc函数即可,在此之前你需要先使能一个可以与PC端进行数据收发的串口,确保可以正常向PC进行数据发送后才开始进行下一步的操作 - 重写部分代码如下,将
huart1更改为自己程序中对应的且已经使能成功的串口即可
int fputc(int ch, FILE *f) {
HAL_UART_Transmit(&huart1, (uint8_t *)&ch, 1, HAL_MAX_DELAY);
return ch;
}
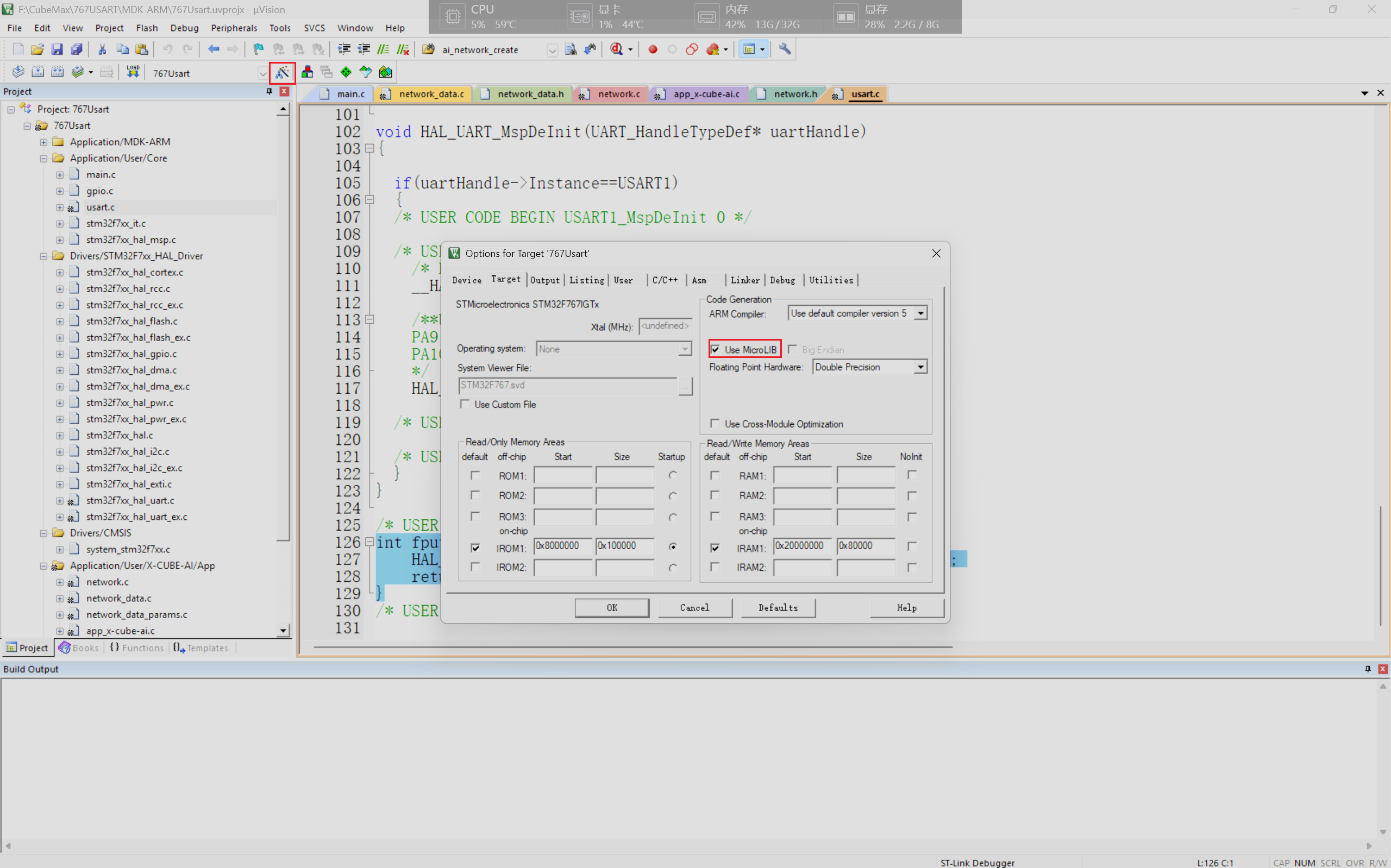
- 在keil5主界面中点击魔法棒后在随后弹出的界面中选择Use MicroLIB即可
AI初始化函数
在初始化函数中我们需要实现获取模型对应参数、模型创建、初始化模型以及获取输入输出缓冲区指针操作,这些操作要想实现看起来无从下手,但是还记得之前提到的network.c文件官方提供的API函数吗,我们接下来要进行的操作官方都已经生成了对应的API函数,我们只需要调用它们就可以了,具体的代码实现如下
void AI_Model_Init(void) {
ai_error err;
ai_network_params params;
printf("Initializing AI Model...\r\n");
//调用参数获取API函数获取AI模型参数
if (!ai_network_data_params_get(¶ms)) {
printf("Failed to get network params\r\n");
Error_Handler();
}
//调用创建模型API函数创建模型实例
err = ai_network_create(&network, AI_NETWORK_DATA_CONFIG);
if (err.type != AI_ERROR_NONE) {
printf("AI Model Creation Failed\r\n");
Error_Handler();
}
//调用初始化API函数初始化模型
if (!ai_network_init(network, ¶ms)) {
printf("AI Model Initialization Failed\r\n");
err = ai_network_get_error(network);
printf("Initialization Error\r\n");
Error_Handler();
}
//调用对应API函数获取输入输出缓冲区指针
ai_input = ai_network_inputs_get(network, NULL);
ai_output = ai_network_outputs_get(network, NULL);
printf("AI Model Initialized Successfully.\r\n");
}
AI推理函数
AI推理函数主要作用为处理输入的角度并尝试求取它们的正弦值,函数执行逻辑大致为:
- 对输出数据进行量化处理,确保所有输入的角度都在有效范围内
- 将数据进行量化后传递给AI模型进行计算
- 从输出缓冲区中读取相应数据并进行反量化处理
具体代码实现如下
/**
* @brief 运行AI模型进行推理
* @param angle_deg: 输入的角度值(0-360度)
* @retval 模型推理出的正弦值(反量化后的float值)
*/
float AI_Model_Run(int angle_deg) {
ai_i32 batch;
float real_output;
//角度预处理:将0-360度映射到0-255范围
// 计算:normalized_angle = (angle % 360) × 255 ÷ 360
uint8_t normalized_angle = (uint8_t)((angle_deg % 360) * 255 / 360);
//量化处理:将0-255范围转换到int8_t的标准范围(-128到127)
// 计算:quantized_input = normalized_angle - 128
int8_t quantized_input = (int8_t)(normalized_angle - 128);
// 将预处理后的数据写入模型输入缓冲区
*((int8_t*)(ai_input[0].data)) = quantized_input;
// 执行模型推理
batch = ai_network_run(network, ai_input, ai_output);
if (batch != 1) {
printf("AI Model Run Failed. Batch: %ld\r\n", batch);
Error_Handler();
}
// 从模型输出缓冲区读取量化结果
int8_t quantized_output = *((int8_t*)(ai_output[0].data));
//反量化处理:将量化输出转换为真实的正弦值
/* 使用network.c中定义的量化参数:
* scale = 0.008472006767988205f
* zero_point = 4
* 计算:real_output = (quantized_output - zero_point) × scale
*/
real_output = (quantized_output - 4) * 0.008472006767988205f;
return real_output;
}
main函数调用
完成上述函数的内容后即可在主函数中进行函数的调用
首先调用模型初始化函数
//初始化AI模型
AI_Model_Init();
printf("Starting AI Mode");
随后在主循环中调用AI推理函数,主循环中实现了从0度开始每隔10度输出一次对应角度的正弦值,主要执行逻辑如下:
- 内部循环每隔10度进行一次计算
- 调用AI推理函数计算对应的角度正弦值
- 调用数学库中的正弦函数计算角度对应的准确正弦值
- 计算两种正弦值的无差别
- 输出结果
代码内容如下
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
// 遍历0-360度,步长为10度,进行正弦值推理验证
for (int angle_deg = 0; angle_deg <= 360; angle_deg += 10) {
//调用AI模型推理当前角度的正弦值
float sine_value = AI_Model_Run(angle_deg);
// 计算真实的正弦值用于对比验证(使用数学库sinf函数)
float real_sine = sinf(angle_deg * 3.14159265f / 180.0f);
// 计算模型输出与真实值的绝对误差
float error = fabsf(sine_value - real_sine);
//输出结果
printf("Angle: %3d deg -> AI Output: %7.4f, Real: %7.4f, Error: %6.4f\r\n",
angle_deg, sine_value, real_sine, error);
HAL_Delay(100);
}
printf("\r\nCycle complete. Starting again...\r\n\r\n");
HAL_Delay(2000);
}
观察输出结果
完成上述代码编写操作之后点击编译运行即可将程序烧录到单片机中,此时打开VOFA+软件,连接对应端口,即可出现如下输出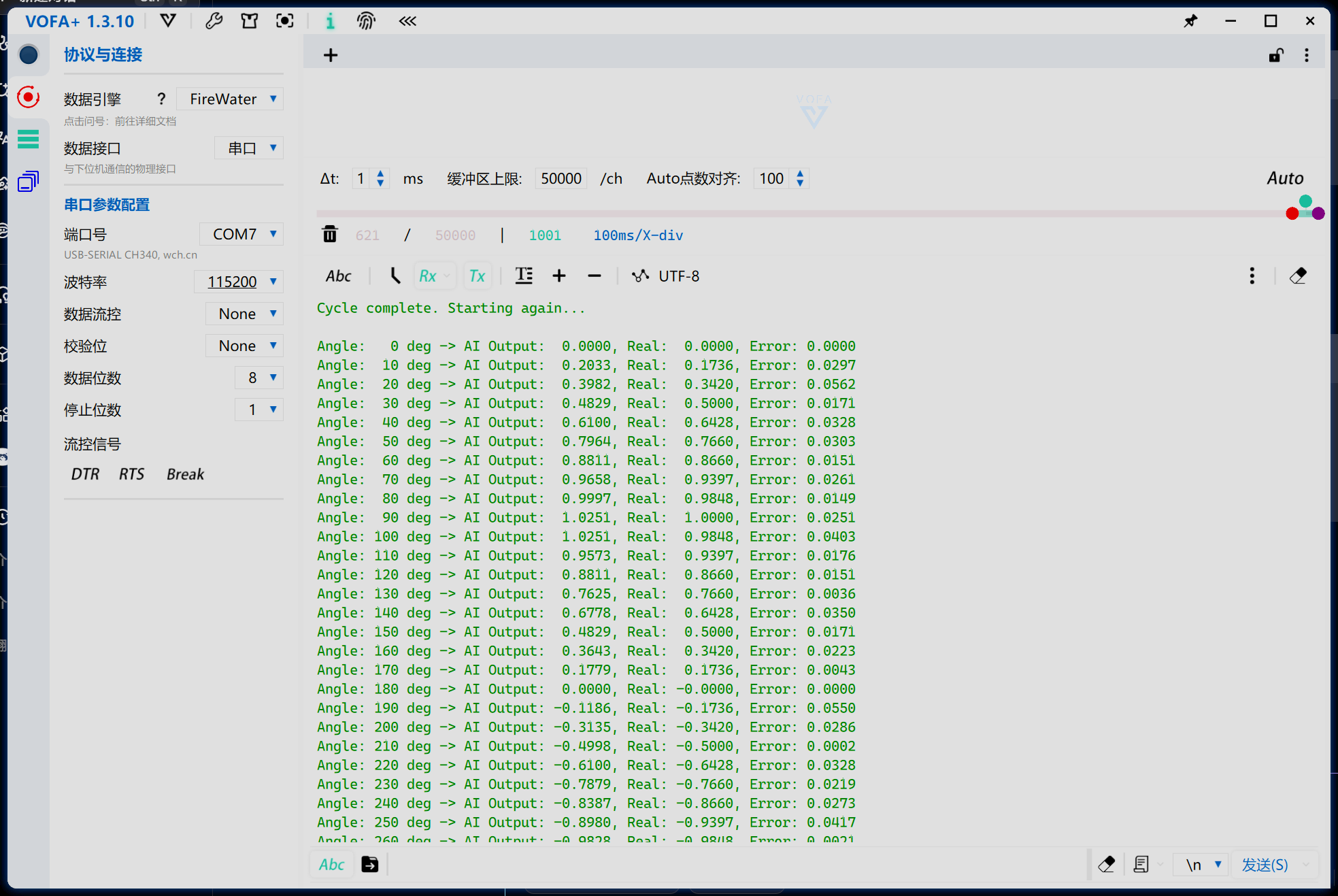
至此程序的编写就全部完成了
总结
综合模型获取以及模型嵌入的全过程我们发现模型的使用并不困难,CUBEAI已经为我们生成了便捷可靠的API函数,在本阶段我们只需要多进行几次模型下载和使用的操作,熟悉了总体的流程后在后续的学习过程中就可以加速我们的开发流程了

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)