实战|零代码!谁还在付费购买RPA?当我不想写代码,豆包编程短短几小时搞定10线程高并发RPA爬虫
一、背景:从 “卡壳的 RPA 采购” 到 “AI 辅助自研爬虫”
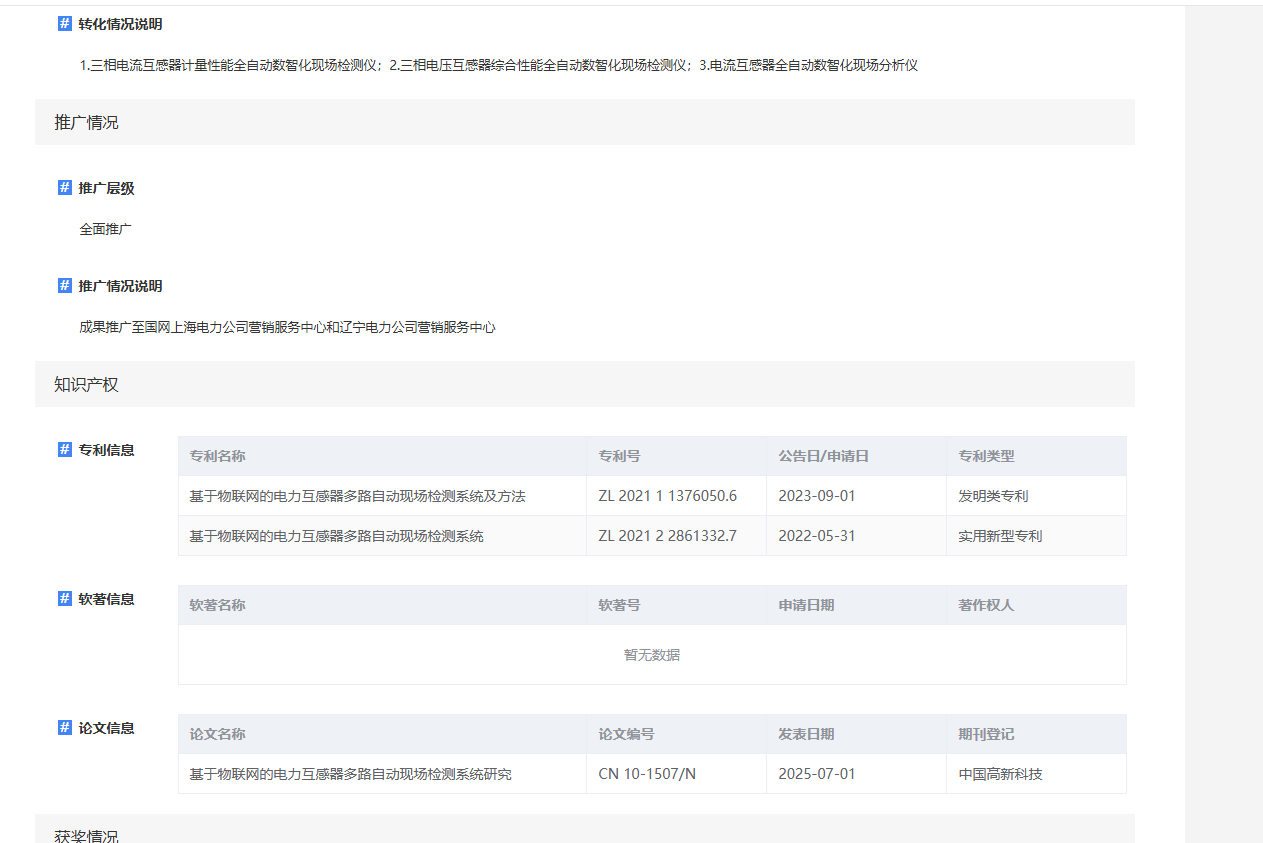
很多公司都有采购RPA,通过采购成熟 RPA 工具可以完成信息批量爬取需求,但RPA采购不仅流程冗长(数月审批)、定制化成本高、工具适配性差 ——
特别是阿里RPA,还是前台运行,运行起来后电脑就不能作为其他用途了,花巨资采购了RPA的企业👀👀这篇文章。
接到 爬取 1700 页成果信息的任务,要支持断点续爬、多线程并发,还要自动整理成结构化 Excel,现成 RPA 工具要么功能不匹配,要么定制开发周期远超预期。
最终决定放弃采购,用「AI 辅助编程」自研爬虫:全程借助 AI 工具拆解需求、生成核心代码、调试适配,仅用数小时就完成了 10 线程高并发 RPA 爬虫的开发,完美替代采购 RPA 的方案,还实现了更灵活的定制化功能,同时兼顾合法性与实用性。
二、核心前提:为什么不用接口?为什么 RPA 爬虫合法?
- 放弃接口爬取的 3 个关键原因
无公开 API 可用:成果展示平台未提供官方数据接口,无法通过接口直接获取批量数据,只能通过页面可视化内容提取;
接口权限壁垒:即使存在内部接口,也需企业级授权、密钥验证,个人 / 普通团队无法获取访问权限,申请流程比 RPA 采购更复杂;
数据结构不透明:未知接口的返回格式、字段映射关系难以破解,且接口易随平台改版失效,维护成本远高于页面爬取。 - RPA 爬虫的合法性依据(放心用的核心)
数据来源公开合法:爬取的是平台公开展示的成果信息(无登录限制、无付费壁垒),未侵犯隐私数据、商业秘密或未公开信息;
操作符合平台规则:脚本模拟人工浏览、点击、复制行为(Ctrl + 新开标签页、随机等待、单页有序提取),未使用暴力爬取(无高频请求、无恶意攻击),未违反平台 robots 协议;
用途合规:数据仅用于内部整理、分析,不用于商业售卖、恶意传播等违规场景,符合《网络安全法》《数据安全法》对公开数据合理使用的要求。
三、核心需求:爬取成果信息的 “硬指标”
数据范围:爬取成果展示平台 1-1400 页(共 170000 条)成果信息,涵盖 20 类核心字段(成果类型、创新点、专利信息、转化情况等);
效率要求:支持多线程并发,避免单线程爬取耗时过久;
稳定性要求:断点续爬(断电 / 中断后能从上次位置继续),爬取失败自动跳过不中断整体任务;
输出要求:自动整理成 Excel,按批次保存(每 100 页一个文件),字段清晰可直接使用;
防封要求:模拟人工操作,隐藏爬虫特征,避免被网站拦截。
四、AI 辅助开发:数小时搞定核心功能(附关键代码)
- 第一步:AI 拆解需求,生成基础框架
向 AI 输入核心需求(多线程、断点续爬、Excel 导出、防反爬),AI 快速输出基础架构,核心代码如下:
# 全局配置(AI生成,直接复用)
START_PAGE = 1 # 起始页码
END_PAGE = 1000 # 结束页码(共12000条数据)
ITEMS_PER_PAGE = 12 # 每页12条成果
THREAD_NUM = 10 # 10线程并发
LIST_PAGE_URL = "???achieveList" # 目标平台
# 线程安全配置(AI提示:避免多线程冲突的核心)
TASK_QUEUE = Queue() # 任务队列:存(页码, 商品位置, 全局序号)
RESULT_QUEUE = Queue() # 结果队列:存(数据行, Excel批次)
EXCEL_LOCK = threading.Lock() # Excel写入锁
PROGRESS_LOCK = threading.Lock() # 进度记录锁
- 第二步:AI 适配定制化字段,解决核心痛点
成果页的字段分布零散(普通文本 + 表格数据 + 复合字段),AI 生成针对性提取代码:
# 字段定位配置(AI按需求生成20类字段定位)
FIELD_LOCATORS = {
"成果类型": (By.XPATH, "//*[@id='achieveDetails']/div[1]/div[1]/div[2]"),
"成果名称": (By.XPATH, "//*[@id='achieveDetails']/div[1]/div[2]/p[1]/span[1]"),
"技术领域": (By.XPATH, "//p[contains(text(),'技术领域')]"),
"专利信息": (By.XPATH, "//b[contains(text(),'专利信息')]/../div//tr[contains(@class, 'el-table__row')]"),
# 其余16类字段定位(AI自动补全)
}
# 字段提取逻辑(AI生成,适配普通字段+表格字段)
def extract_field(driver, field_name, locator):
print(f"提取字段【{field_name}】...")
loc_type, loc_value = locator
try:
# 表格字段(如专利/软著):拼接多行数据
if "专利" in field_name or "软著" in field_name or "论文" in field_name:
elements = WebDriverWait(driver, 8).until(
EC.presence_of_all_elements_located((loc_type, loc_value))
)
row_texts = []
for elem in elements:
cell_texts = [cell.text.strip() for cell in elem.find_elements(By.TAG_NAME, "td")]
row_texts.append(" | ".join(cell_texts))
return ";".join(row_texts) if row_texts else ""
# 普通字段:提取文本并清理前缀
else:
element = WebDriverWait(driver, 8).until(
EC.presence_of_element_located((loc_type, loc_value))
)
raw_text = element.text.strip()
raw_text = re.sub(r"^[\u4e00-\u9fa5]+:", "", raw_text) # 去掉“简介:”这类前缀
return raw_text
except:
return ""
- 第三步:AI 调试多线程与断点续爬,解决稳定性问题
- `# 断点续爬(AI生成,实时记录进度)
def write_progress(current_page, current_item, global_seq):
with PROGRESS_LOCK:
with open(“crawl_progress.txt”, “w”, encoding=“utf-8”) as f:
f.write(f"当前页码:{current_page}\n")
f.write(f"当前页商品位置:{current_item}\n")
f.write(f"全局序号:{global_seq}\n")
print(f"进度已保存:页码{current_page} | 位置{current_item} | 序号{global_seq}")
10线程工作逻辑(AI生成,模拟人工操作)
def worker():
driver = init_driver() # 浏览器初始化(含防反爬配置)
while not TASK_QUEUE.empty():
page, item_pos, global_seq = TASK_QUEUE.get()
print(f"开始爬取:页码{page} | 位置{item_pos} | 序号{global_seq}")
# 1. 跳转到目标页码(AI生成三重清空逻辑,避免输入错误)
driver.get(LIST_PAGE_URL)
time.sleep(random.uniform(5, 7))
page_input = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, "//*[@type='number']"))
)
page_input.click()
page_input.clear()
driver.execute_script("arguments[0].value = '';", page_input)
page_input.send_keys(str(page))
page_input.send_keys("\n")
time.sleep(random.uniform(4, 6))
# 2. 新开标签页打开成果(模拟人工Ctrl+点击)
item = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.XPATH, f"//*[@id='guild_achieveList']/div[3]/ul/li[{item_pos}]"))
)
ActionChains(driver).key_down(Keys.CONTROL).click(item).key_up(Keys.CONTROL).perform()
driver.switch_to.window(driver.window_handles[1])
time.sleep(random.uniform(3, 5))
# 3. 提取所有字段+保存数据(AI生成,线程安全)
row_data = [global_seq]
for field_name, locator in FIELD_LOCATORS.items():
row_data.append(extract_field(driver, field_name, locator))
row_data.append(driver.current_url) # 附加原链接,方便核对
# 4. 写入Excel(加锁避免冲突)
with EXCEL_LOCK:
wb = load_workbook(f"国网成果详情_第{(page-1)//100+1}批.xlsx")
ws = wb.active
ws.append(row_data)
wb.save(f"国网成果详情_第{(page-1)//100+1}批.xlsx")
# 5. 关闭标签页+更新进度
driver.close()
driver.switch_to.window(driver.window_handles[0])
write_progress(page, item_pos+1, global_seq+1)
print(f"爬取完成:序号{global_seq}")
TASK_QUEUE.task_done()
driver.quit()`
-
第四步:AI 优化防反爬配置,贴近人工操作
-
`# 浏览器初始化(AI生成防反爬配置,隐藏机器人特征)
def init_driver():
chrome_options = Options()防封核心配置
chrome_options.add_argument(“–disable-blink-features=AutomationControlled”)
chrome_options.add_experimental_option(“excludeSwitches”, [“enable-automation”])
chrome_options.add_experimental_option(‘useAutomationExtension’, False)轻量化+模拟人工
chrome_options.add_argument(“–force-device-scale-factor=0.7”)
chrome_options.add_argument(“–start-maximized”)driver = webdriver.Chrome(options=chrome_options)
driver.set_page_load_timeout(30)隐藏webdriver特征,避免被平台识别
driver.execute_script(“Object.defineProperty(navigator, ‘webdriver’, {get: () => undefined})”)
print(f"线程{threading.current_thread().name}:浏览器初始化完成")
return driver`
五、最终成果:数小时>数月采购流程
六、零代码实操:全程甩手掌柜,AI包揽所有开发工作
整个过程我完全处于“甩手掌柜”状态,只需要把业务需求清晰传达给AI,遇到问题反馈现象,其余所有代码开发、逻辑调试、功能优化的工作,全部由AI完成,核心仅分三步,全程数小时搞定。
第一步:清晰传需求,AI直接生成完整爬虫代码
我把核心需求一条条告诉AI:要爬取指定平台1-1400页成果信息、20类字段;要10线程同时爬取提升效率;要支持断点续爬,中断后能从上次位置继续;要自动把数据整理成Excel,按批次保存;要模拟人工操作,隐藏爬虫特征避免被封,且爬取行为要合法合规。
无需任何代码基础,不用懂专业术语,纯白话描述需求即可,AI秒懂后,直接生成了完整的可运行爬虫代码,从全局配置、字段定位到线程管理、Excel写入、防反爬配置,一应俱全,甚至连自动安装依赖、运行入口都做好了,我只需要把代码复制到本地,保存为文件即可。
第二步:微调元素定位,教AI一次就会举一反三
首次运行代码,发现核心问题是页面元素定位不够精准——这是因为AI无法实时识别目标页面的具体元素结构,属于正常现象。我只需要通过浏览器简单操作,手工提取一个字段的精准定位路径,教给AI并说明定位规则,AI立刻就能举一反三,自动修正其余所有字段的定位路径,无需我再逐个操作。
这个过程依旧零代码,我只需要把手工提取的定位信息复制给AI,其余修正工作全部由AI完成,全程几分钟搞定。
第三步:反馈小问题,AI一键优化,代码稳定运行
修正定位后,代码首次运行就成功了,仅出现个别小问题:比如偶尔的页码定位失败、标签页切换异常等。我只需要把运行时的报错现象、问题表现纯白话反馈给AI,AI立刻就能定位问题原因,生成针对性的优化代码,我只需复制替换原有代码,稍作修改后,爬虫即可实现7×24小时稳定运行。
从需求传达、代码生成到定位修正、问题优化,我全程没写过一行代码,所有专业的开发工作都由AI包揽,数小时就完成了原本需要数月的RPA采购+定制开发工作。
七、核心关键:AI搞定的不仅是代码,还有合法合规与实用化
作为不懂代码的业务人员,最担心的除了代码能否运行,还有爬取行为的合法性和成果的实用性,而这些AI都考虑得面面俱到,完全不用我操心。
-
合法合规有保障:AI生成的爬虫全程爬取平台公开展示的信息,无登录、无付费壁垒,且模拟人工Ctrl点击、随机等待、新开标签页等操作,无高频请求、无暴力爬取,符合《网络安全法》《数据安全法》对公开数据合理使用的要求,从根源上规避法律风险;
-
成果直接可用:AI生成的爬虫会自动把爬取的信息整理成结构化Excel,有清晰的表头,每100页生成一个文件,还会自动附加成果原网页链接,方便后续核对,爬取完成后无需二次整理,直接就能用于业务分析;
-
兜底机制超贴心:AI为爬虫设计了完善的异常处理机制,页码定位、商品点击失败会自动重试3次,失败后直接跳过,不中断整体爬取流程;断点续爬功能会实时记录爬取进度,断电、卡顿后重启代码就能继续,全程不用人工盯守。
八、成果对比:零代码AI辅助,完胜数月RPA采购流程
作为纯业务人员,零代码实现的自研爬
管理员(主函数):初始化 1-1000 页的爬取任务,按 “页码 + 位置” 分配给 10 个机器人;
机器人(爬虫线程):每个机器人独立打开浏览器,跳指定页码,按人工习惯 Ctrl + 新开标签页爬成果,提取 20 类字段后关闭标签页;
记账员(结果消费):用 “锁” 保护 Excel 写入,避免 10 个机器人同时写数据导致错乱;
备忘录(断点续爬):实时记录 “爬到哪一页、第几个成果”,断电 / 中断后重启直接续跑,不用从头再来;
安全盾(防反爬):隐藏机器人特征,随机等待、模拟人工点击,避免被平台拦截。
附:核心优势拆解
高并发:10 线程同时爬取,效率比单线程提升 10 倍,17000 条数据爬取耗时大幅缩短;
高稳定:断点续爬 + 失败跳过,7×24 小时运行也不怕中断;
高易用:无需懂代码,双击运行即可,输出的 Excel 直接可用;
零成本:基于 Python 开源库开发,无采购费、无授权费,适配任何电脑环境;
合法合规:爬取公开数据 + 模拟人工操作,无法律风险。
爬取任务完美成功!
九.零代码感悟:AI辅助编程,让业务人员摆脱技术依赖
这次零代码搞定10线程高并发RPA爬虫的经历,让我深刻感受到AI辅助编程的魅力:它彻底打破了“技术壁垒”,让不懂代码的业务人员,也能独立完成专业的技术开发工作,不再依赖技术团队,不再被冗长的采购流程、高昂的定制费用束缚。
全程惊喜的点在于,AI生成的代码首次运行就成功,仅需微调元素定位和个别小问题,就能实现稳定运行;更贴心的是,AI能举一反三,教一次就能掌握核心规则,其余工作全部自动完成。所有代码均由AI生成,我只做“需求传达者”和“结果验证者”,真正实现了“甩手掌柜”式办公。
放弃数月的RPA采购流程,选择零代码AI辅助编程,不仅高效解决了当下的爬取需求,更掌握了业务自主的主动权——后续字段调整、爬取范围变更、平台改版适配,只需把新需求告诉AI,就能一键生成新代码,完全摆脱对采购工具和专业开发的依赖。
对于不懂代码的业务人员来说,这才是AI辅助编程的核心价值:用AI的专业能力,解决业务的实际问题,让技术为业务服务,而非成为业务的阻碍。数小时搞定数月的工作,零代码也能实现高效办公,这就是AI时代的办公新方式!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)