agent rl过程
本文研究了智能体强化学习(Agentic RL)在文本转有声书任务中的应用。实验采用微软开源的Agent Lightning框架,基于Qwen-1.5b模型进行多轮交互式训练。通过GLM-4.7作为奖励模型,对20条《天龙八部》文本片段进行格式、内容、情感等多维度评估。使用GRPO算法训练后,验证集最佳成绩达到0.552,较基线提升341%。结果表明,Agentic RL能有效提升文本转语音任务的
一.传统RL vs Agentic rl
传统的大语言模型强化学习(如RLHF)采用单轮交互范式,其优化目标为单次生成响应的质量。在这一框架下,模型接收用户输入后直接生成完整输出,并基于该输出获得奖励信号进行策略更新。此类方法已在对话系统的人类偏好对齐中取得显著成效。
然而,智能体任务场景对模型能力提出了更高要求。智能体强化学习(Agentic Reinforcement Learning) 采用多轮交互范式,模型需要与外部环境进行持续交互:生成动作(如工具调用指令)、接收环境反馈(如API返回结果)、并基于反馈进行后续决策。这一过程形成完整的交互轨迹(trajectory),优化目标从单步输出质量转变为轨迹层面的累计收益最大化。
传统RL:Input → [Model] → Output → Reward
- 单轮交互:一个 prompt 进去,一个 response 出来
- 优化目标:让单次输出的质量最高
- 典型应用:RLHF(如 ChatGPT 的对齐训练)、单轮问答优化
Agentic rl :Input → [Model] → Action₁ → Environment → Observation₁ → [Model] → Action₂ → ... → Final Output → Reward
- 多轮交互:模型需要与环境多次交互(调用工具、获取反馈、迭代决策)-
- 优化目标:让整个 trajectory(轨迹) 的累计收益最高
- 关键特点:
中间步骤有 工具调用(如搜索、代码执行、API 调用)
需要学会 何时调用什么工具 以及 如何解读工具返回
奖励可以是 稀疏的(只在最后给)或 密集的(每步都有)对应的模型更新也可以是有选择性的,具体看业务需求而定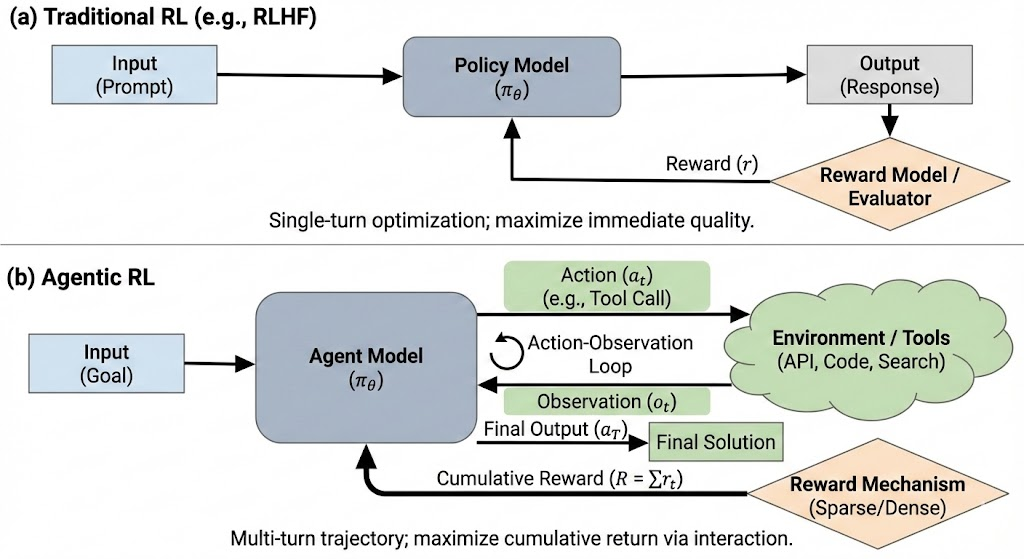
有声书Agentic RL过程
本项目基于 Agent Lightning 框架(微软开源)进行 LLM Agent 强化学习训练。简单来说此框架就是负责Tracer(记录轨迹)+ Store(存储数据)+ Trainer(协调训练),简化了多节点 Agent 的 RL 训练接入过程。
- 上层封装:使用 @agl.rollout 装饰器定义 Agent 逻辑,通过 agl.emit_reward() 发射奖励信号
- 底层引擎:Agent Lightning 内置的 agl.VERL 算法调用 veRL 框架进行 GRPO 训练
- 训练配置:双卡 FSDP 分布式训练,vLLM 推理引擎,两张a30
- Reward Model:智谱 AI GLM-4.7 作为 LLM-as-Judge
数据制作
数据来源:网络上找的天龙八部txt随机选取片段。一共二十条数据。长度控制大概在100-200之间,防止输出的token太长,显存不支持。
groud truth:经过调研对比,最终决定使用Claude ops进行生成。
格式转换: 转换为verl框架训练的数据格式parquet,20条数据4:1分tran和val
训练节点
此处只定义了一个简单的带rewrite的流程来进行训练,主要还是为了将流程打通。create和rewrite用的都是Qwen-1.5b的模型,也就是说这次训练此模型会学会这两个“角色”,实际业务中可以按需设置。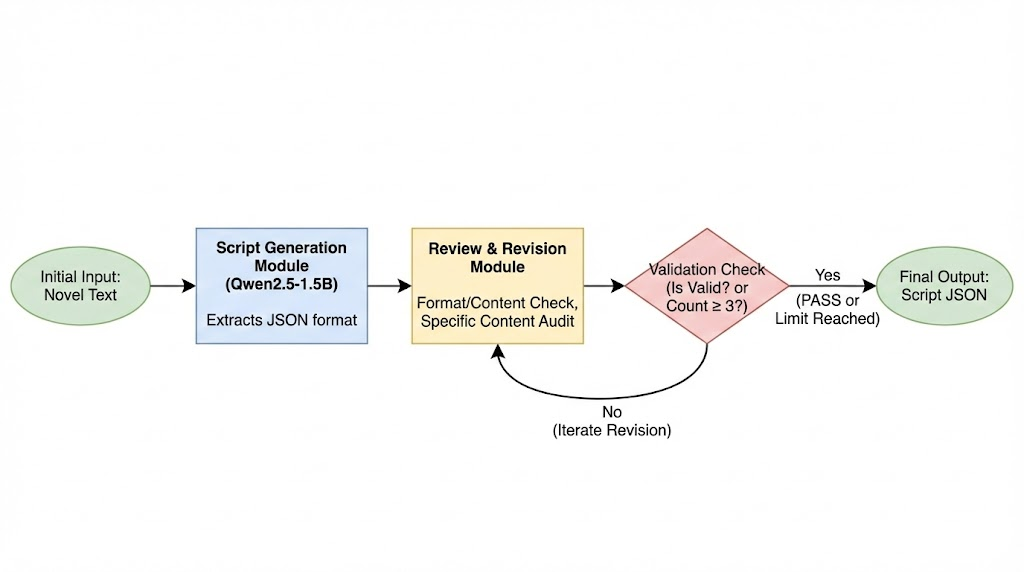
Reward Model
经过比对,最后采用了GLM4.7作为打分模型,打分的规则如下:
## 评分维度(各占权重):
1. **格式正确性 (20%)**
- JSON格式是否有效
- 是否包含所有必需字段:speaker, content, tone, intensity, delay
2. **内容完整性 (30%)**
- 是否完整覆盖了原文所有重要信息
- 是否有遗漏或多余的内容
3. **角色识别准确性 (20%)**
- speaker是否正确区分了"旁白"和角色对话
- 角色名称是否与原文一致
4. **情感标注合理性 (15%)**
- tone是否准确反映了对话/描述的情感
- intensity是否与内容强度匹配
5. **分段合理性 (15%)**
- 段落划分是否自然
- delay设置是否合理
同时还会根据对应的groud truth作为打分标准。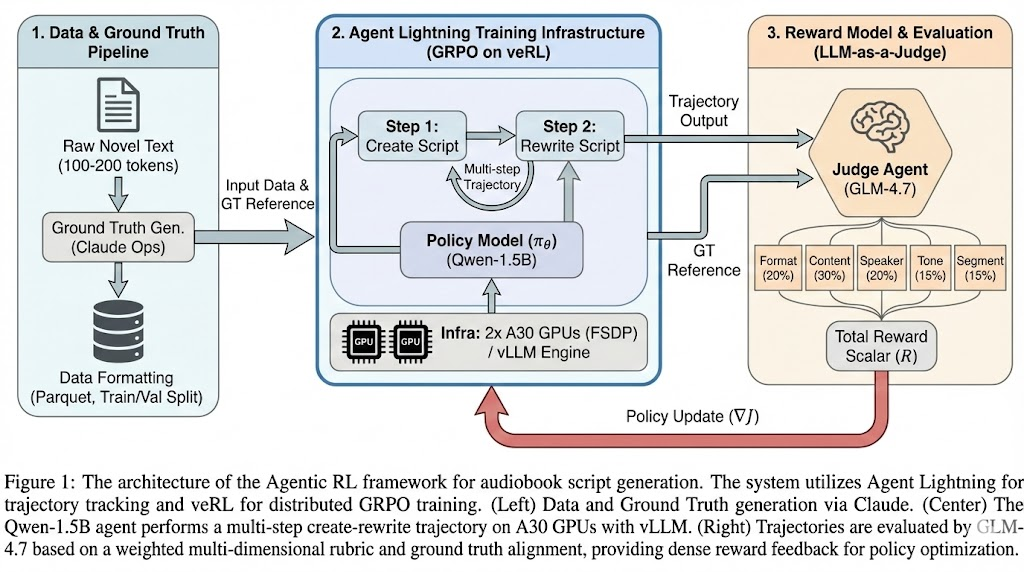
开始训练
:本实验采用 GRPO (Group Relative Policy Optimization) 算法进行策略优化。与传统 PPO 不同,GRPO 通过组内相对优势估计来计算策略梯度,无需额外的价值网络(Critic)。具体而言,每个训练样本生成 4 条独立轨迹(rollout_n=4),通过比较同组轨迹的奖励信号计算相对优势,并使用标准差进行归一化(norm_adv_by_std_in_grpo=True)。策略更新时禁用 KL 散度约束,仅依赖裁剪机制(clip_ratio∈[0.2, 0.3])控制更新幅度。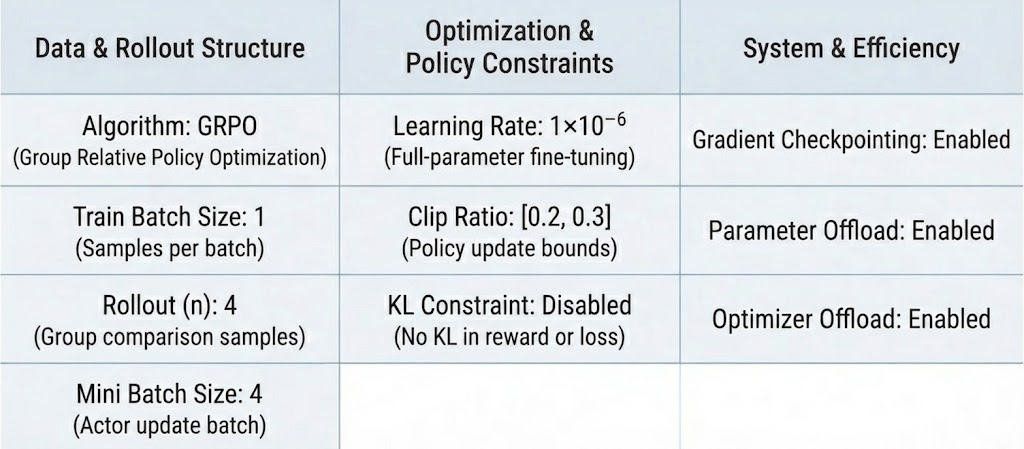
训练
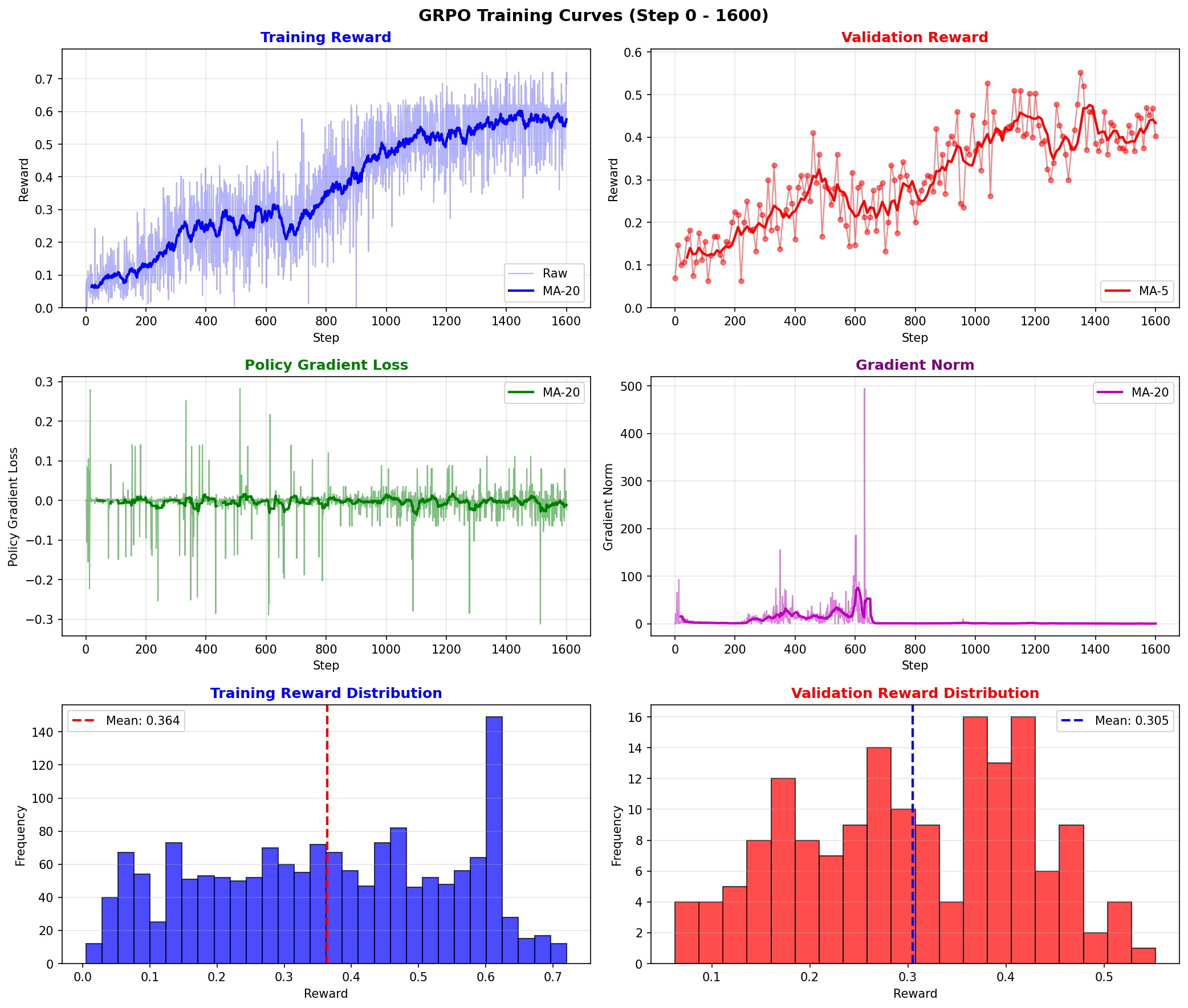
训练过程中,训练集reward持续上升并在1600步达到0.685。
然而,验证集reward在约1350步达到峰值0.552后开始下降,
表明模型在后期可能出现过拟合。
因此,我们采用验证集最优的checkpoint(step 1400)作为最终模型,
相比基线模型(reward ≈ 0.125),性能提升约 341%。
与此同时 针对 step= 1000,1400,1600的结果在同验证集上进行评估比对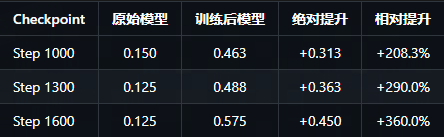
独立样本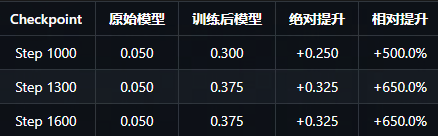

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)