Course11:RAG调优
Q:Q:一个视频文件是对应一个1152维的向量,还是对视频进行抽帧,每一帧对应一个1152维的向量?Thinking:当用户提问与知识切片的相似度不高时,能否通过A为每个知识切片生成可能的问题,通过问题与问题的匹配来提高检索准确度?Q:原始的检索结果排序是根据相关性高低排序的,这里的rerank重排应该是抛弃了原有的相关性排名,重新计算分值再排序吗?Q:9张鞋的图片,让大模型生成带声音介绍的视频,
RAG高级技术与调优
从不同的维度对RAG进行调优?


坚实基础---知识库层面

场景1:知识库问题生成与检索优化
Thinking:当用户提问与知识切片的相似度不高时,能否通过A为每个知识切片生成可能的问题,通过问题与问题的匹配来提高检索准确度?
TODO:对知识库进行问题生成,并进行检索优化
LLM问题生成提示词参考:

自动生成多样化问题:为知识库中的每个知识切片自动生成多种类型、不同难度的问题

generate_questions_for_chunk():为单个知识切片生成基础问题
generate_diverse_questions():生成更多样化的问题(8个)
构建双重检索索引:同时构建基于原文内容和生成问题的BM25检索索引
检索评估:针对两种检索方式,进行详细的评估
场景2:对话知识沉淀
使用LLM整理历史对话,生成一组新的知识

案例

知识点提取
信息标签:事实 需求 用户意图 流程 注意等等


知识梳理:merge_similar_knowledge(self, knowledge_list):
使用LLM合并相似的知识点,过滤掉需求和问题类型
过滤掉需求和问题类型的知识,因为它们是临时的、个性化的
场景3:知识库健康度检查

LLM缺失检查步骤

LLM过期检查步骤

场景4:知识库版本管理与性能比较

版本差异统计

精准雷达---RAG高效召回方法
Thinking:都有哪些RAG召回的策略,提升召回的质量?
1.如果要召回更多的片段,如何设置?
docs = knowledgeBase.similarity_search(query, k=10)
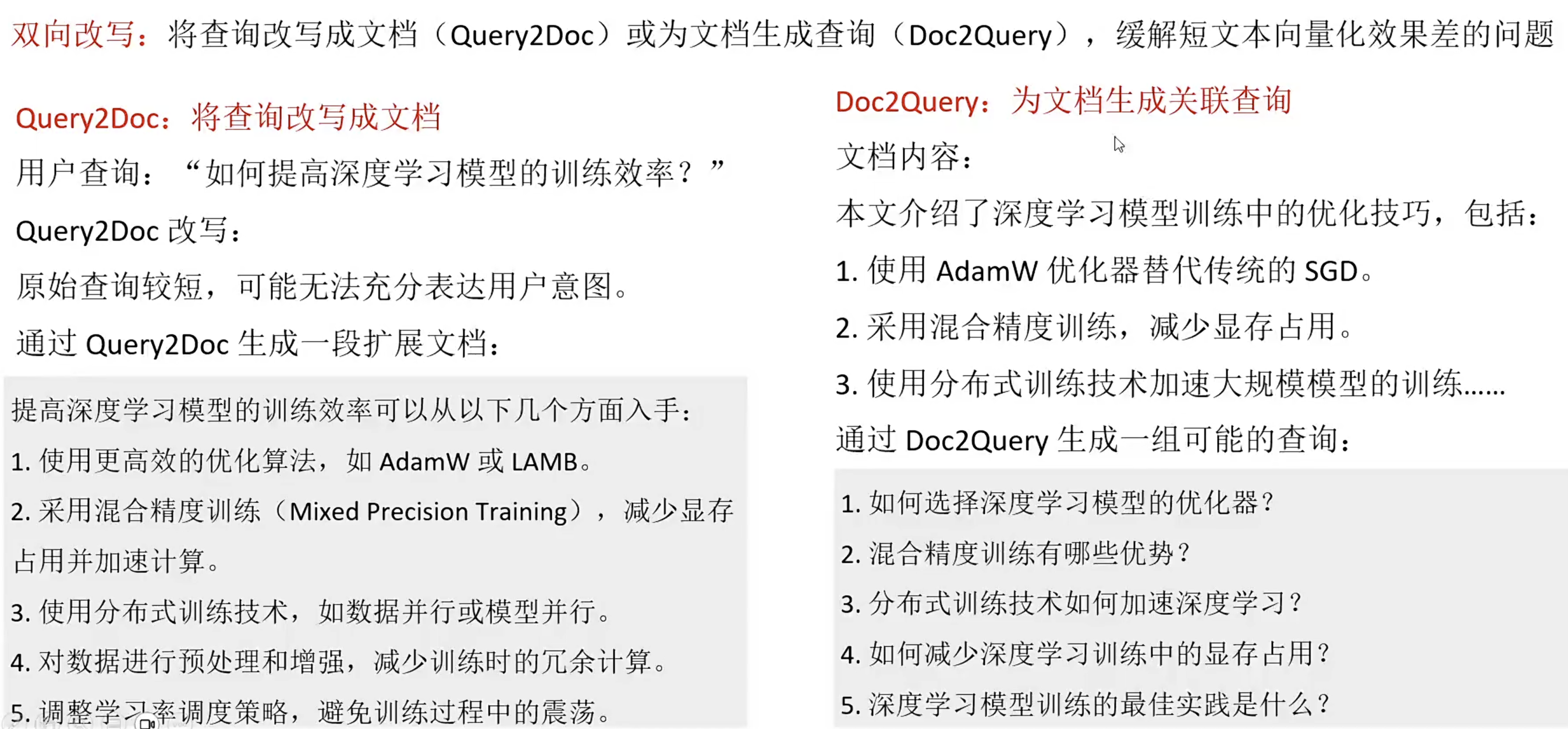
2、优化查询扩展

3、索引扩展

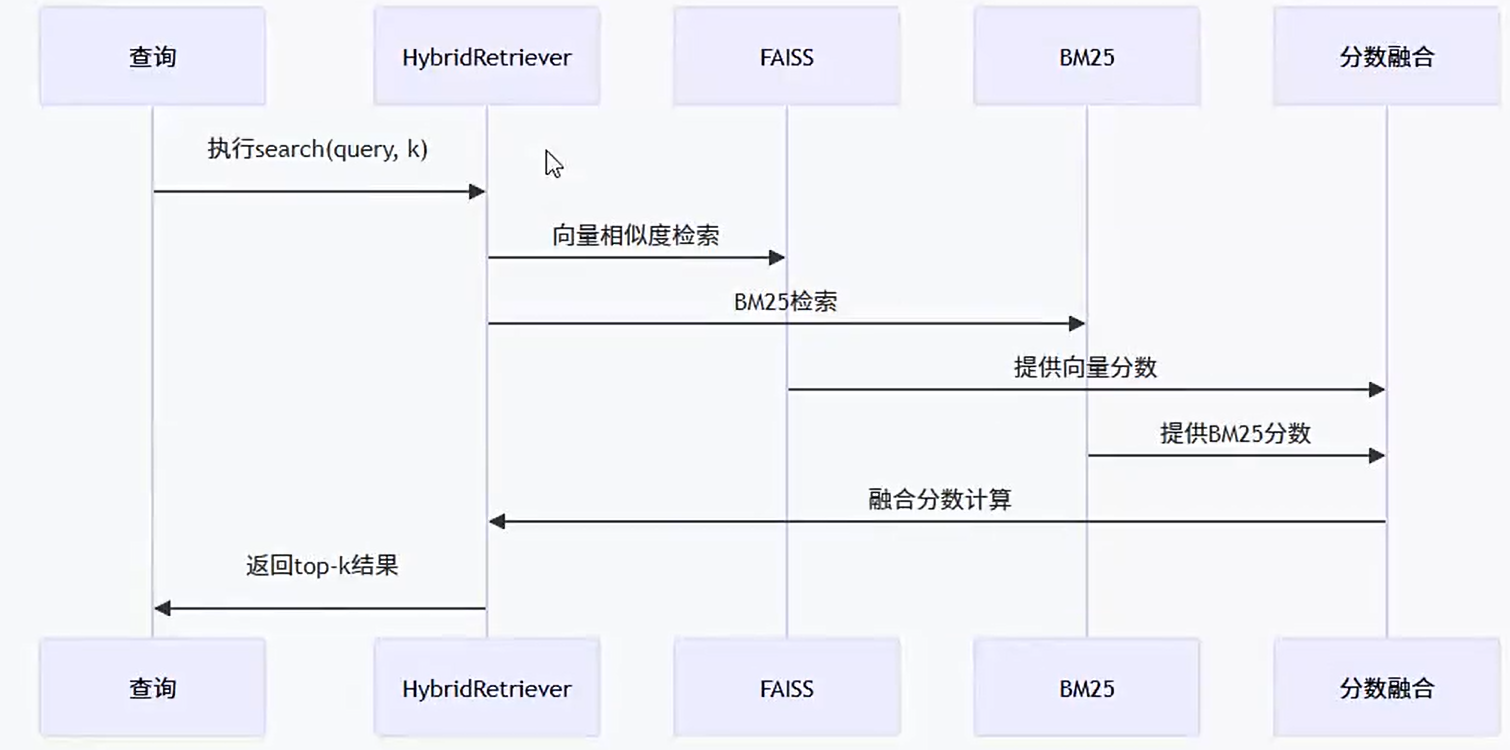
chatpdf-faiss-HybridSearch-logic
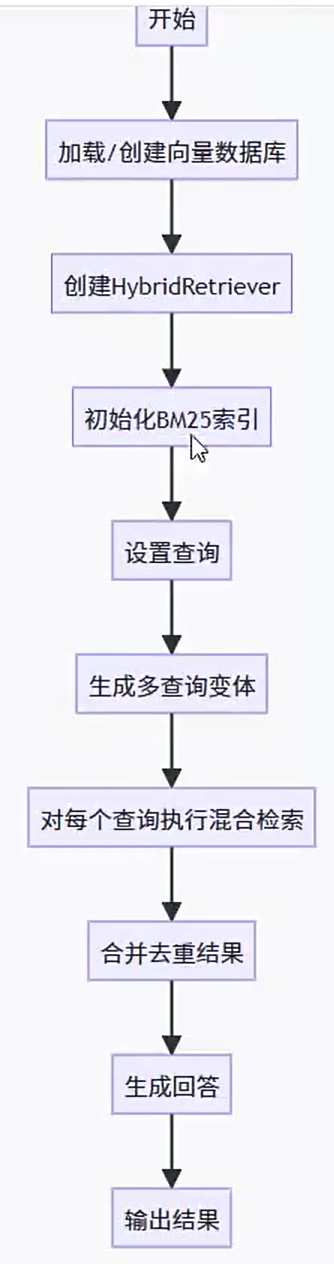
HybridRetriever混合检索器
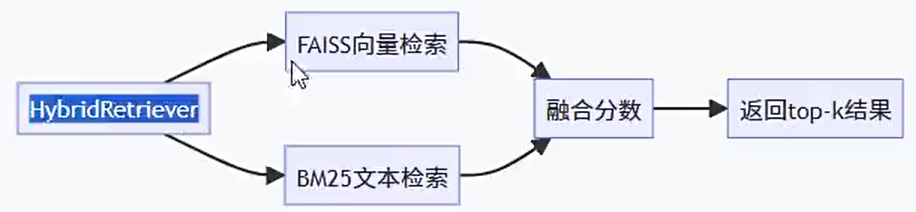
混合检索过程
多查询增强
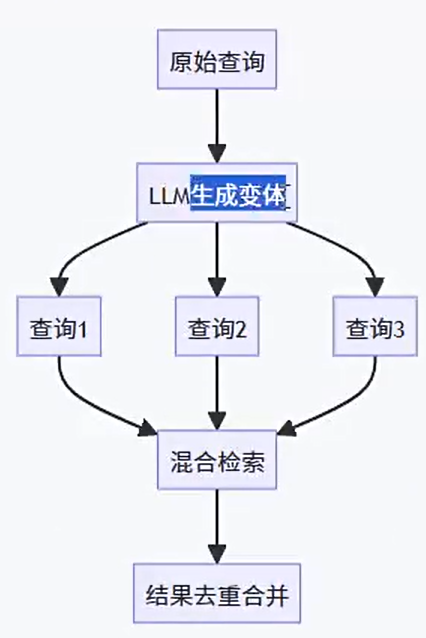
数据流向
rerank使用策略
RAG高效召回法
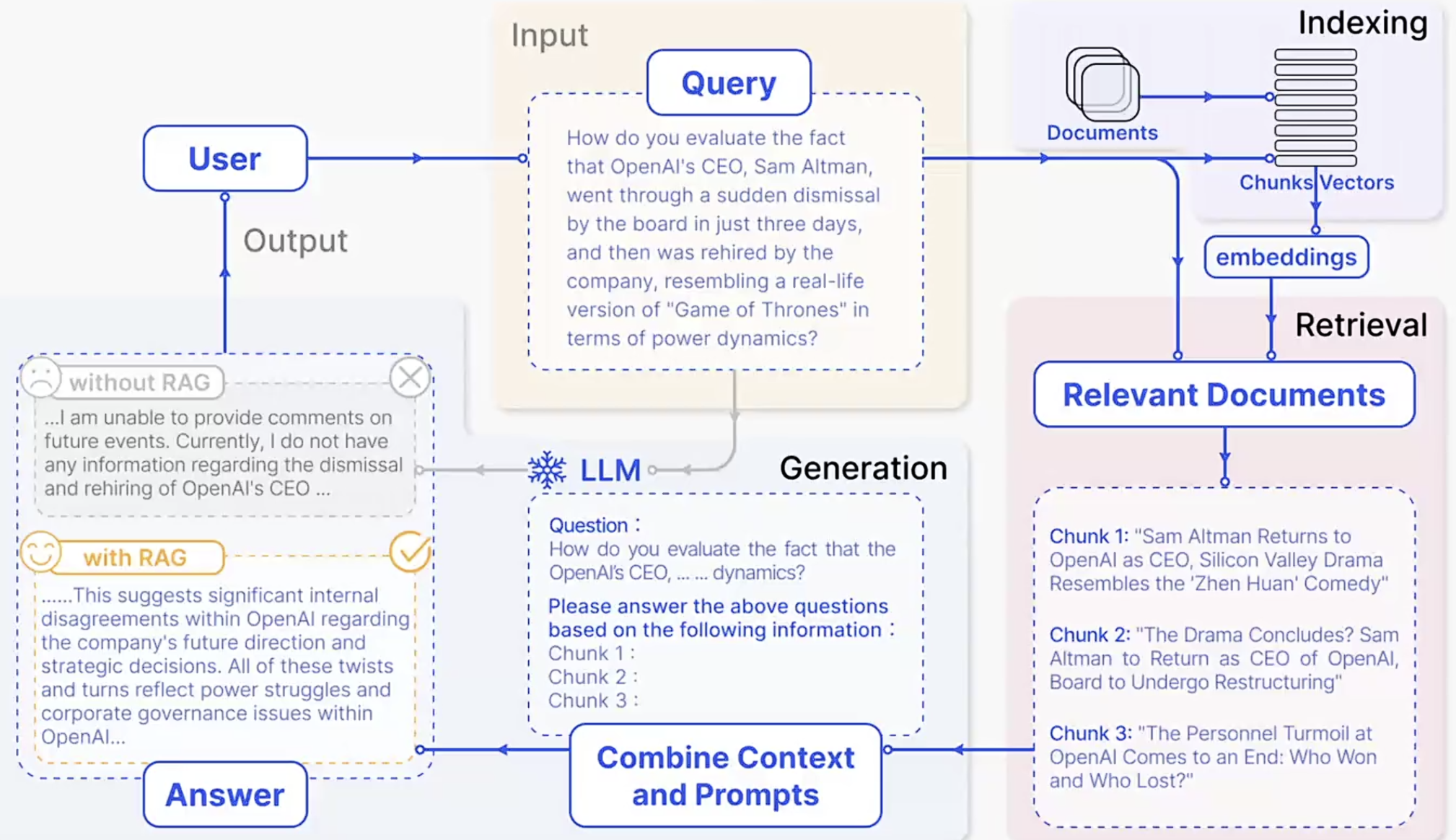
Native RAG
RAG的步骤:
Indexing=>知识存储。
Retrieval=>在大量的知识中,通过相似度计算找到一小部分有用片段,给到模型参考。
Generation=>结合用户的提问和检索到的知识,让模型生成有用的答案。
其中:
chunk=>一定程度内,越精细检索精度越高
Vectors:特征的向量化表达

全局视野---GraphRAG
检索流程示例
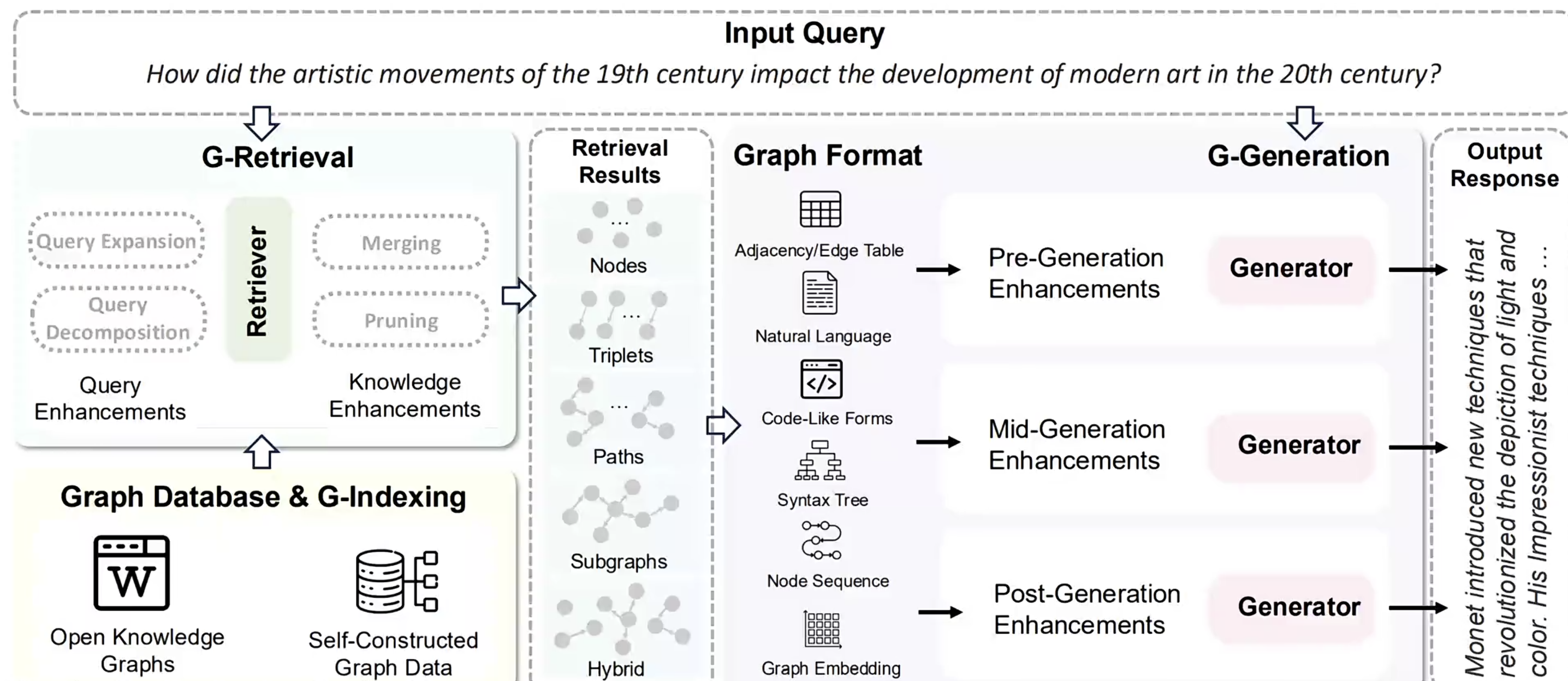
查询模式
在查询时,使用这些结构为LLM上下文窗口提供材料来回答问题。
主要查询模式有:
全局搜索,通过社区层级摘要来推理有关语料库的整体问题

局部搜索 通过扩展到其邻居和相关概念来推理特定实体的情况。
适合回答细节/具体场景 事件 时间等
GraphRAG方法是使用LLM构建基于图的文本索引,分两个阶段:
首先从源文档中派生出实体知识图谱
然后为所有密切相关的实体组预生成社区摘要。

检索优势

索引构建(Indexing)一一知识的结构化

Q&A
Q:多模态模型是怎么识别语言视频的,大模型是怎么思考生成视频的,原理是什么?
A:多模态模型识别语言视频,核心是多模态编码 → 跨模态对齐到共享语义空间 → 时空建模抓动态 → 融合推理得到统一理解。;
语言视频 = 视觉(画面 / 帧序列)+ 听觉(语音 / 音效)+ 文本(字幕 / 语音转写)+ 时序(动作 / 事件流)。模型要做的是把这些信息 “对齐、融合、理解”。
大模型生成视频,核心是文本语义解析 + 时空扩散生成 + 时序连贯性建模。
生成视频 = 从文本 / 图像等条件,按时间顺序生成连贯、逼真的帧序列。主流技术是扩散模型 + Transformer 时空建模(如 Sora、Stable Video Diffusion)。
Q:Q:一个视频文件是对应一个1152维的向量,还是对视频进行抽帧,每一帧对应一个1152维的向量?一个视频文件是对应一个1152维的向量
A:一个视频文件是对应一个1152维的向量!
Q:推荐可直接使用的RAG的开源软件
A:ragflow, dify, fastgpt, qwen-agent
Q:怎么解析word pdf ppt文档中包含的图片并为其添加描述
A:Step1,找到图片,保存到本地;Step2,使用qwen-vl上传该图片,prompt=帮我描述这张图片
Q:我们存储是把知识片段和问题作为同一个新知识片段存储嘛,还是把扩写的问题与知识片段建立索引分开进行存储?
A:两者都可以
Q:MD5是什么
A:加密算法,用于唯一值的生成
Q:企业使用时,这个版本在库里怎么存储
A:打上标签、用不同库index v1,v2、chunk进行metadata的打标
Q:知识库冲突
A:人+AI,比如人更清楚时效性信息
Q:9张鞋的图片,让大模型生成带声音介绍的视频,用什么大模型呢?通义万相2.6,只支持传入一张图片
A:gemini nana banana即梦
Q:pdf文件中包含表格或者图片,有批量工程化的手段吗
A:mineru对pdf进行解析,里面也有表格的处理方法,一般是建议转换为html格式
Q:通过距离来求相识度,这样也是归一化吗
A:是的,先计算距离(>=1),然后转化成了0-1之间1/s
Q:如果项目是分布式的,faiss的文件怎么存储呢?
A:milvus
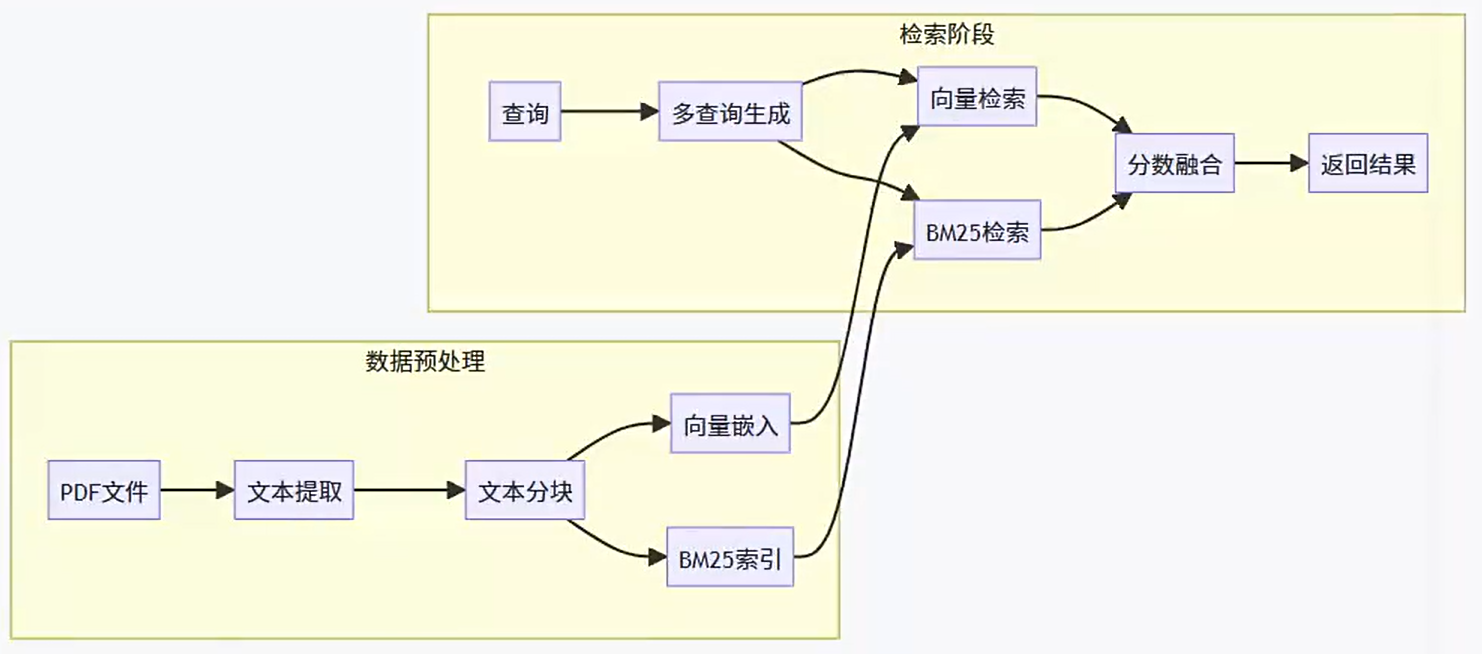
Q: 重排的价值
A:BGE-RerankCohere Rerank,精准---chunks1000万=>召回(相当于粗筛,速度快)100个=>重排rerank(精度高,速度慢)5个
Q:原始的检索结果排序是根据相关性高低排序的,这里的rerank重排应该是抛弃了原有的相关性排名,重新计算分值再排序吗?
A:embedding向量相似度模糊语义,不是精确回答score
rerank是相对比embedding更精确的计算,因为一对一计算query和chunk之间的score;
query embedding 与chunk embedding只是1024维的相似程度,也不给出不一样惊喜score
Q:NOTEBOOKLM是不是采用了graphRAG的方式?
A:small-to-big
Q: Q:graphrag,是不是可以使用模型来生成切片知识间建立关联?
A:entity + relationship、community

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)