给AI装上“外挂大脑”:一文看懂检索增强生成 (RAG)
摘要:检索增强生成(RAG)技术通过为大语言模型配备外部知识库,有效解决了AI"幻觉"、知识过时、无法处理私有数据等问题。其工作流程分为三步:首先建立向量化知识库索引,然后检索相关文档片段,最后让大模型基于检索结果生成答案。该技术已应用于知识库问答、新必应搜索和GitHub Copilot等场景,使AI从"闭卷考试"转变为"开卷考试",大
写在前面(太长不看版):
你有没有发现,强大的 ChatGPT 有时候也会一本正经地胡说八道?或者问它最近发生的新闻,它却一无所知?
这是因为目前的大模型(LLM)更像是一个**“超级学霸”**,它在“出厂”前背完了海量的书,但它的知识就停留在它背书的那一刻,而且它记不住所有冷门知识,更不知道你的私密文件。
“检索增强生成”(Retrieval Augmented Generation,简称 RAG) 技术,就是为了解决这个问题而生的。简单来说,RAG 就是给这个学霸配了一个**“超级图书馆”和“搜索引擎”**。
当你提问时,它不再只是靠回忆(容易记错),而是先去图书馆里翻书(检索),找到相关资料,再结合资料给你写答案。这样,它的回答就更准确、更新鲜,还能处理你的私人数据了。
这篇文章将带你轻松搞懂这个当前最火的 AI 技术。
1. 为什么需要 RAG?(AI 的短板)
虽然像 ChatGPT 这样的大语言模型(LLM)已经非常厉害了,能写代码、能聊天、能推理,但它们有几个明显的“硬伤”:
(1)爱“产生幻觉”(胡说八道)
大模型生成答案本质上是在做“文字接龙”。当它遇到不熟悉的领域或冷门知识时,为了把话接下去,它可能会自信满满地编造一个错误的答案。这在专业领域(如医疗、法律)是非常危险的。
类比: 就像参加一场闭卷考试,学霸遇到没背过的题,为了不留白,只能瞎蒙一个。
(2)知识不新鲜(甚至过时了)
大模型的训练需要极高的时间和金钱成本,不可能天天更新。比如 GPT-4 的大部分知识截止到 2021 年 9 月。你问它今天早上的新闻,它肯定不知道。
类比: 学霸用的教材是三年前出版的,里面自然没有最新的时事。
(3)不知道你的秘密(私有数据)
大模型是在公开互联网数据上训练的。它绝对不可能知道你们公司内部的项目文档,也不可能知道你私人电脑里的日记。
类比: 学霸只读过图书馆里的公版书,没看过你锁在抽屉里的私人笔记。
(4)说话没凭没据(缺乏可解释性)
当大模型给出一个结论时,它很难告诉你这个结论具体是参考了哪本书的哪一页。
类比: 学霸写论文从来不加脚注和参考文献。
而 RAG 技术,就是为了一次性解决以上这四个问题。
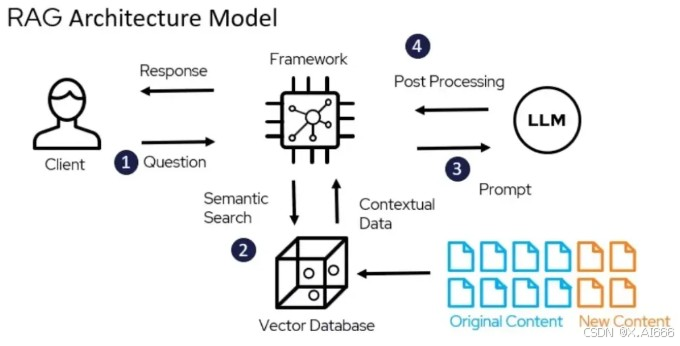
2. RAG 是怎么工作的?(开卷考试三步走)
RAG 的核心思想非常简单,就是把传统的**“信息检索”(像用百度/谷歌搜索)和“大模型生成”**结合起来。
我们可以把整个过程想象成一场**“开卷考试”**:
第一步:准备图书馆(数据处理与索引)
在考试前,我们得先建立一个“外部知识库”(外挂大脑)。
-
收集资料: 把你需要 AI 知道的各种文件(PDF、Word、公司文档、网页等)收集起来。
-
切分知识点(文本分块): AI 一次能看的字数是有限的(这叫“上下文窗口”限制)。所以我们不能把整本厚书直接扔给它,得把长文章切成一个个小的段落或知识点。
类比: 就像把大西瓜切成小块,方便一口吃掉。
-
建立索引(关键一步!): 为了能快速找到相关知识点,我们需要给这些切好的小块建立目录。
-
最核心的技术叫“向量化(Embedding)”:这听起来很高级,其实就是把一段文字变成一串数字(坐标)。神奇的是,含义相近的文字,它们变成数字后在空间里的距离也会很近。
-
我们将这些数字存入一个专门的**“向量数据库”**。这就像一个超级高效的图书馆目录系统,它不是按书名排的,而是按“含义”排的。
-
第二步:翻书找答案(查询与检索)
当用户提出问题时:
-
系统会先把用户的问题也变成那串神奇的数字(向量)。
-
然后拿着这串数字去“向量数据库”里比对,瞬间找出距离最近的几个知识点(文档片段)。
类比: 这就像你在图书馆的电脑里输入关键词,系统立刻告诉你最相关的几本书在哪个书架。
第三步:学霸写回答(响应生成)
这是最后一步:
-
系统把用户的问题,加上刚才检索到的那几个相关知识点,打包一起发给大模型(学霸)。
-
我们要对学霸说:“请参考这些资料,回答用户的问题。如果资料里没有,就说不知道,别瞎编。”
-
大模型阅读了这些“参考资料”后,就能生成一个准确、有依据的回答了。
类比: 这就是开卷考试的过程。学霸拿着你帮他找到的几页书,综合整理出最终答案。
3. RAG 的实际应用(就在你身边)
你可能已经在使用 RAG 技术了,只是没意识到。
(1)最典型的应用:知识库问答(ChatPDF 类产品)
这是目前最火的方向。你可以上传几十份复杂的 PDF 合同或技术文档,然后直接问 AI:“这些合同里关于赔偿的条款有哪些不同?”
AI 会立刻检索这几十份文档,把相关条款找出来,并总结给你看,还会标出信息来源。
价值: 让你拥有了与私有文档“对话”的能力,极大地提高了处理信息的效率。
(2) 微软的新必应 (New Bing)
当你用新必应搜索时,它不再是只给你一堆蓝色的链接。它会先去搜索网页,阅读多个网页的内容,然后给你写一个总结性的回答,并在句尾标出参考了哪个网页。这就是典型的检索增强生成。
价值: 解决了信息时效性和来源验证的问题。
(3) 程序员帮手:GitHub Copilot
程序员写代码时,Copilot 会自动补全代码。它其实也是一种 RAG。它会分析你当前光标前后的代码(上下文),甚至检索你项目里其他相似的文件,然后把这些信息作为参考,让模型生成接下来最可能需要的代码。
价值: 利用上下文检索,让 AI 更懂你想写什么。
总结
RAG(检索增强生成)并不是要取代大模型,而是大模型的最佳辅助。
它通过外接一个可随时更新的“知识库”,巧妙地解决了大模型**“幻觉”、“知识过时”和“无法利用私有数据”**的痛点。
在未来很长一段时间内,“大模型 + RAG知识库” 将会是企业和个人应用 AI 的主流方式。它让 AI 从一个只会空谈的学霸,真正变成了一个既懂得多、又靠谱的得力助手。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)