2026.02.24【生信洞察L0】生信,正在失去护城河
生物信息学领域正经历AI驱动的范式变革:传统分析流程(如基因组学)的技术壁垒因自动化工具而贬值,AI代理已成为基因组学活跃度榜首。单细胞组学面临算法同质化危机,空间组学则因多模态数据处理需求呈现工程红利。交叉组学领域(如营养基因组学)因技术生态空白存在套利空间。从业者需重构职业路径:在成熟领域确保基础交付能力,向高增长低饱和赛道转移,并利用AI工具(如claude-scientific-skill
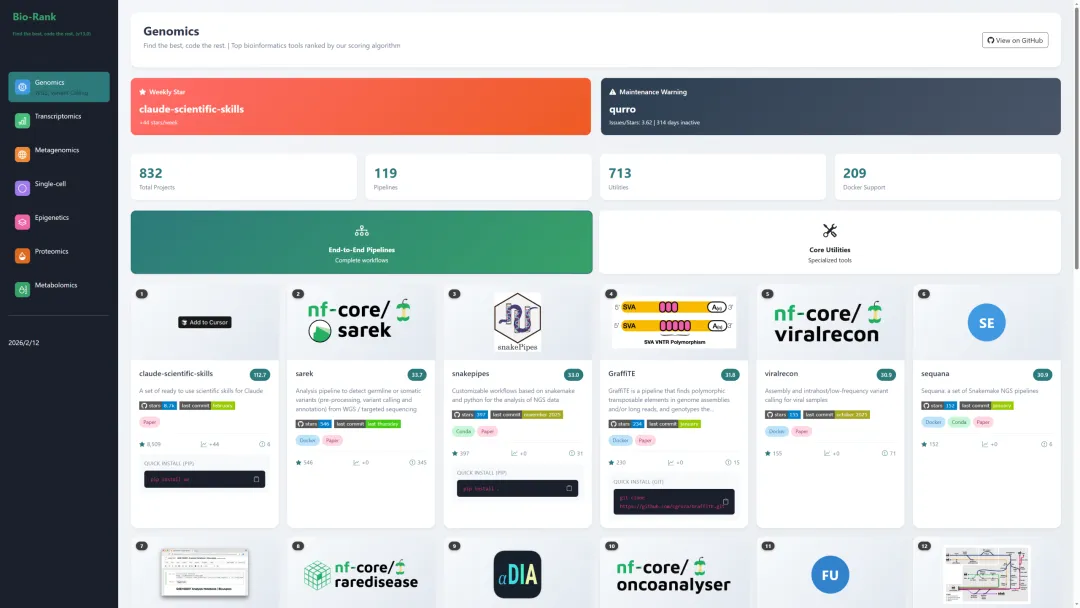
在生物信息学领域,由代码工时和环境配置堆砌起来的“经验壁垒”正在发生雪崩。过去,基于 Snakemake 或 Nextflow 从零搭建个性化分析流程,曾是区分资深工程师与新手的标尺 。然而,当 Cursor 搭配高阶提示词能将长达数周的文献检索、代码调试和图表复现压缩至 48 小时内时,生信分析中 70% 的纯执行性经验已在 AI 面前迅速贬值 。
Bio-Rank v3.0 权重模型的数据揭示了一个更具颠覆性的事实:在基因组学(Genomics)的活跃度排行榜上,Top 1 已不再是任何传统生信软件,而是 AI 代理 claude-scientific-skills 。这意味着,生信从业者的核心价值逻辑必须完成从“代码执行者”向“数据决策者”的跃迁 。
基于学术产出、开源社区活跃度、NIH 资金流向及全网热度等多维量化数据,以下是 2026 年组学技术生态的深度拆解。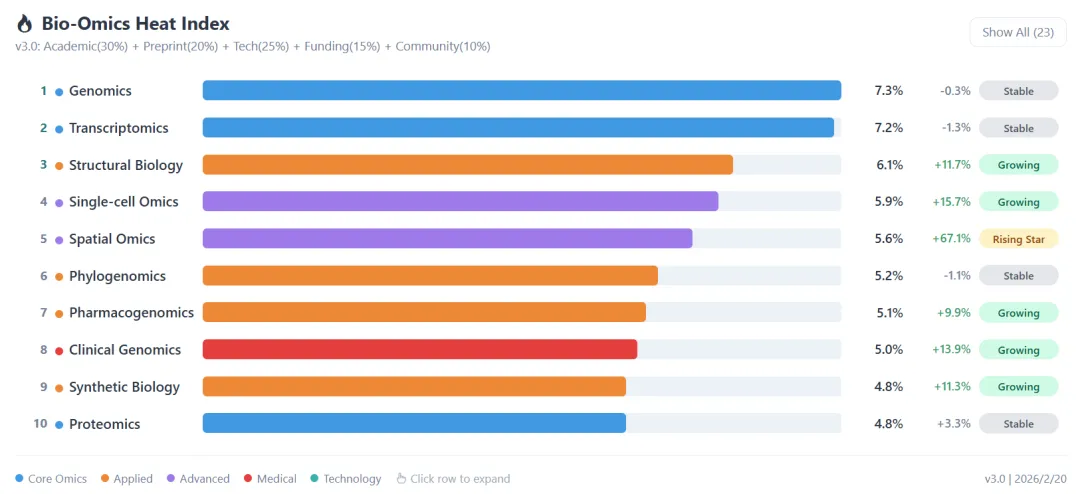
【深度拆解】:四大核心赛道的底层逻辑
1. 基因组学:从“技术护城河”到“基建沉没成本”
作为生信领域的绝对基石,基因组学(Genomics)依然维持着庞大的基本盘:年度 PubMed 论文量超 4.6 万篇,PyPI 下载量破 8,000 万次,NIH 相关项目达 3.6 万个 。然而,其年度论文增速已微转负至 -0.28%,综合热度边际变化为 -1.00%,呈现典型的“高位横盘”态势 。
在这一赛道,高技术生态评分(Tech Score ≈ 0.8654)反映的是工具链的高度成熟与标准化 。WGS/WES 流程的比对与变异检测已被各大测序企业整合为自动化流水线 。对个体而言,掌握这些流程已降级为行业基础准入门槛,不再具备溢价空间。
💡 技术洞察 (Epiphany):当底层变异检测沦为标准化的工业流水线,执迷于调参的工程师终将被自动化脚本所取代。
2. 单细胞组学:高景气掩盖下的“技术通胀”与内卷
单细胞组学(Single-cell Omics)目前位列综合热度 Rank 4,其 PubMed 年度论文量同比增长 15.68%,且 NIH 资金得分高达 0.9357,依旧是学术与资金双密集的重镇 。
但其核心隐患在于严重的“技术通胀”。其技术生态评分极低(Tech Score ≈ 0.154),暴露了底层算法的同质化危机 。无论是 R 语言还是 Python 生态,从质控、降维、聚类到细胞注释,业界已形成对 Seurat 或 Scanpy 等标准套件的深度路径依赖 。“熟练跑通单细胞流程”已成为严重供过于求的技能标签,其技术壁垒正在从“执行分析”向“连接临床真实临床决策”转移 。
💡 技术洞察 (Epiphany):过度封装的工具箱虽然降低了单细胞分析的门槛,但也锁死了常规降维聚类分析的叙事上限。
3. 空间组学:多模态升维带来的真实工程红利
空间组学(Spatial Omics,Rank 5)是本期榜单中唯一被定义为 Rising Star 的领域 。其 PubMed 论文量同比激增 67.07%,PyPI 相关工具包下载量逼近 480 万次,展现出极强的学术传染力(Citation Momentum)。
与基因组学的高饱和不同,空间组学的 GitHub 活跃度(22)与学术得分(0.8544)之间存在巨大剪刀差,且整体 Tech Score 依然偏低 。这说明在处理空间拓扑异质性与多模态数据对齐时,现有的方法论和工程化方案远未收敛,存在巨大的算法开发与流程优化真空 。
💡 技术洞察 (Epiphany):空间坐标库不是单细胞矩阵的简单外挂,它是重构组织微环境通讯网络的全新物理标尺。
4. 侧翼突围:低饱和度交叉组学的套利空间

数据表明,主航道降速与侧翼赛道升温正在同步发生。多组学(Multi-omics,Rank 12)论文增速达 24.44%;营养基因组学(Nutrigenomics,Rank 14)增速达 18.33% 且资金得分良好(0.8073);泛基因组学(Pangenomics)与影像组学(Radiomics)也均处于正增长周期 。这些领域的共同特征是:资金与学术关注度处于中高位,但技术生态(Tech Score)几近空白 。对于具备开发能力的工程师而言,这是极佳的降维打击战场。
💡 技术洞察 (Epiphany):在极度内卷的主航道里争夺小数点后两位的精度,不如去未开垦的侧翼赛道确立第一套行业标准。
【行动指南】:大模型时代的生信职业重构路径
面对技术范式的迁徙,生信从业者需要建立新的三层防御体系,核心策略是:在主航道守住底线,在侧翼赛道寻找增量,用 AI 降维打击探索成本 。
-
基本盘防御(稳定交付): 对于在校生或初级工程师,Genomics 等成熟赛道仍是必须跨越的门槛 。目标不应是“精通”,而是利用标准流程建立稳定交付数据的能力,获取学术与工业界对话的资格 。
-
结构性套利(寻找增量): 停止在成熟流程上的无效内卷。应将核心精力向 Spatial Omics、Multi-omics 等 Momentum 为 Rising Star/Hot 且 Tech Score 偏低的领域转移 。在这些领域,将个性化分析沉淀为可复用流程,能同时在论文、代码和社区获得极高的回报率 。
-
AI 重构工作流(降本增效): AI 已从单纯的代码补全工具,进化为跨领域的降维打击武器。
分析设计:各种面向表格、矩阵和图形数据的通用模型,可以用来辅助你做假设验证、结果解释和可视化迭代,如wps的AI论文智能排版,Gamma一键生成读书报告PPT等。
领域决策: 借助 claude-scientific-skills 等 Agent,快速完成文献梳理与技术可行性验证 。
代码重构: 利用 Cursor、Qoder 等编辑器,将移植和改写前沿算法(如多模态深度学习脚本)的成本压缩至极低 。
三类工具各有侧重,但一定可以让你用更低的时间成本,去碰原本因为太新、太杂、太费时间而不敢碰的问题。
在“熟能生巧”的技术可以被 AI 快速总结并执行的年代,真正能被时间拉开的差距,不再是“谁更熟悉某个工具”,而是谁更早意识到:
把精力从拥挤的主赛道,转一部分到高景气、低饱和、工具尚未成型的领域,并且学会用 AI 重构工作流——
这比在同一条生产线多待三年,要划算得多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)