让数据自己来:使用 AI Studio 构建自定义爬虫
针对传统爬虫开发中IP封禁、页面改版、验证码等痛点,AI Studio通过自然语言交互和智能代理网络,将复杂的技术问题封装为标准化服务。
点我跳转 Bright Data 注册链接,点击免费使用👇
通过链接注册的新客户,送30$试用金,感兴趣的小伙伴可以注册体验!
一、前言
做过买车卖车相关项目的人大多知道:关键数据很难拿。
车源信息、价格、车型走势等核心指标,并不在数据库里,而是分散在各种网页页面中。对企业来说,公开页面几乎是唯一可靠的数据来源。
技术上,写个爬虫抓数据看似简单,但一到生产环境就问题频出:IP 被封、页面改版导致解析失效、验证码拦截……团队大量时间耗在维护脚本,而非分析数据。
而业务真正关心的只有一件事**:能不能每天稳定拿到结构化数据?**
如果每次需求变更都要重写爬虫、调试代理、处理反爬,数据采集就永远无法规模化。
于是一个新思路正在兴起:别再从写代码开始。
把反爬、代理、调度这些复杂工作交给专业平台,技术人员只需说明“要什么数据”。
本文将以二手车为例,展示如何用 Bright Data AI Studio,零代码构建一套自动化、可落地的车源数据采集方案。
二、Bright Data AI Studio 概览
2.1 AI Studio 是什么?它解决了什么问题
AI Studio(此处指 Bright Data 的 AI Studio)是一个基于自然语言的智能数据采集平台。它允许用户通过描述需求(例如:“从某平台二手车网站抓取车型、价格、里程等信息”),自动生成并托管可稳定运行的网页数据采集任务,最终以 API 或结构化数据 的形式交付结果。
2.2 它核心解决的是企业级数据采集中三大痛点:
-
反爬对抗成本高
传统爬虫需自行处理 IP 封禁、验证码、浏览器指纹等问题。
AI Studio内置全球住宅代理网络与自动解封机制,将这些复杂性下沉到底层。 -
维护成本高、稳定性差
网站改版常导致XPath/CSS选择器失效,脚本频繁崩溃。AI Studio通过智能页面理解与容错机制,提升长期运行的鲁棒性,并提供可视化监控。 -
开发门槛高、交付慢
每次新需求都要写代码、调代理、测逻辑。AI Studio让非工程师(如分析师、产品经理)也能通过自然语言快速定义数据需求,实现“所想即所得”。
简言之,AI Studio 把“写爬虫”转变为“提需求”,让网页数据采集从一项高风险、高维护的工程任务,变成一项稳定、可扩展的企业级数据服务。
2.3 为什么说 AI Studio 更适合企业级场景
从整体来看,AI Studio 的设计明显不是为了“快速写一个 Demo”,而是面向长期运行的企业级应用。
它显著降低了开发门槛。数据采集能力不再依赖少数熟悉反爬和代理细节的“爬虫专家”,而是可以通过相对标准化的方式由普通工程师甚至数据分析人员完成配置。这在人员流动频繁或项目周期较长的企业环境中尤为重要。
它降低了长期运维风险。反爬策略、IP 管理、运行稳定性这些高风险问题,被集中交由平台处理,减少了因脚本失效或环境变化带来的不确定性。爬虫是否稳定运行,不再高度依赖个人经验,而更多依赖于平台能力。AI Studio 天然支持规模化扩展。无论是多站点并行采集,还是高频率、长期的数据更新,都不需要对原有方案进行结构性调整。这使得数据采集能力可以随着业务需求自然扩展,而不会成为制约系统演进的瓶颈。
正因为这些特性,AI Studio 更像是一种数据基础设施,而不是一次性工具。在接下来的实战部分中,本文将结合网站二手车的具体页面结构,进一步展示这种方式在真实二手车数据采集场景中的实际使用效果。
三、基于 Bright Data AI Studio 的自动化采集实践
使用 AI Studio 构建自定义爬虫
3.1 实战目标与采集场景说明
本次实战以二手车数据分析为背景,模拟一家数据服务企业的真实需求,目标并非“爬下来一次”,而是搭建一个可复用、可扩展的采集流程。
- 采集对象:某平台二手车网站中的车源列表页与详情页
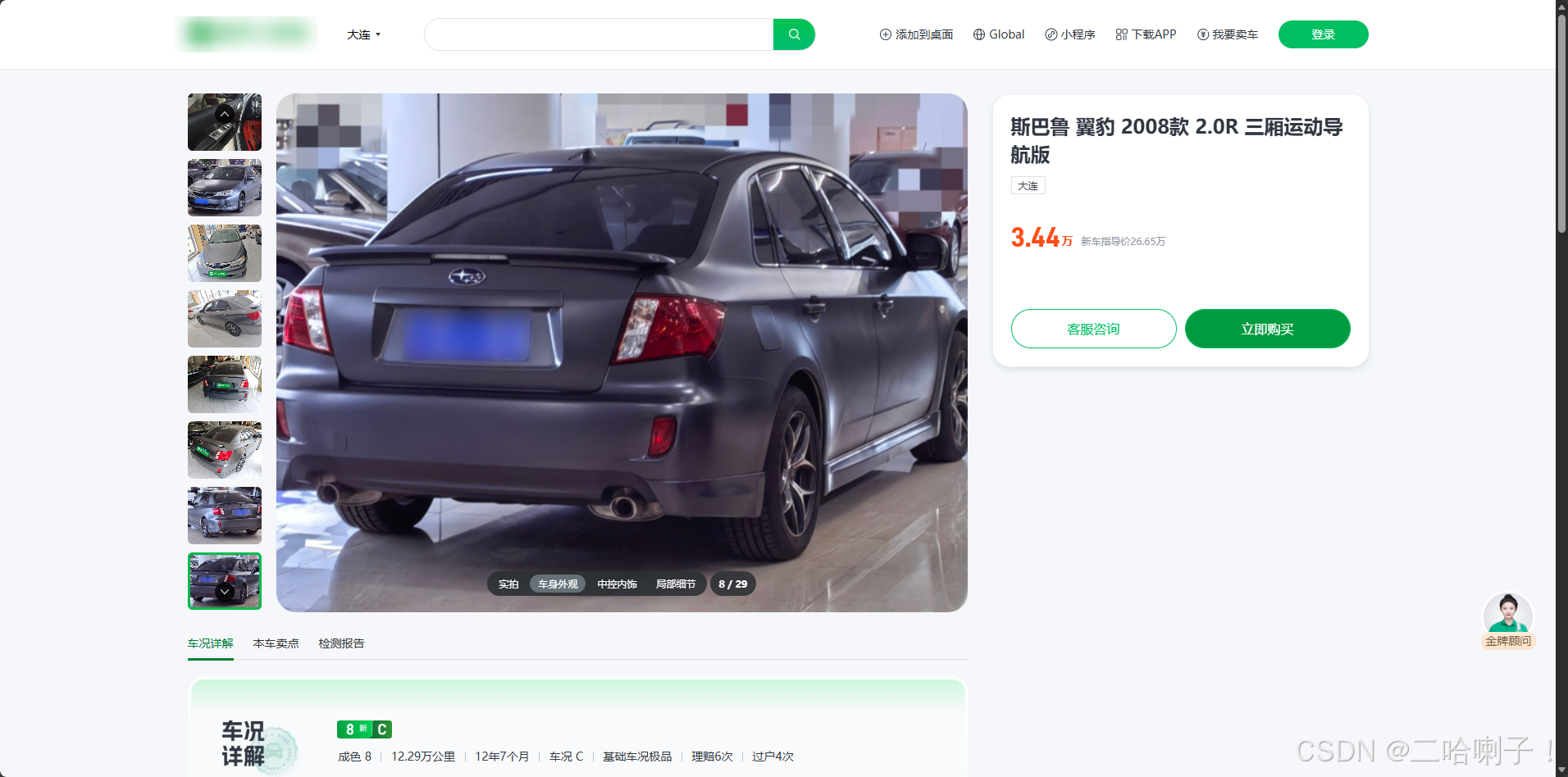
- 核心采集字段包括:
- 品牌、车型、上牌年份
- 表显里程、排量、变速箱类型
- 当前售价、车况综合评分
- 车辆亮点、过户次数等
该场景具备典型特征:多页面翻页、数据结构相对固定、且具备明显的反爬机制(如 IP 限频、行为验证、动态渲染等)。这几乎覆盖了企业在二手车数据采集中会遇到的大多数挑战。
💡 对比说明:在传统开发模式下,工程师需要手动编写爬虫脚本,精确解析页面 HTML 结构,处理动态加载、Cookie 维护、IP 封禁等问题。一旦页面改版,整个脚本可能失效,维护成本极高。而 AI Studio 的价值,正是将这些复杂性封装到底层。
3.2 使用 Bright Data 账号 👉
在企业级项目中,一个常见误区是过早写爬虫代码。事实上,准备工作是否到位,往往直接决定项目后期的稳定性。
- 注册教程
这里可能会加载的有点慢,可以稍微等一下
输入邮箱和手机号进行注册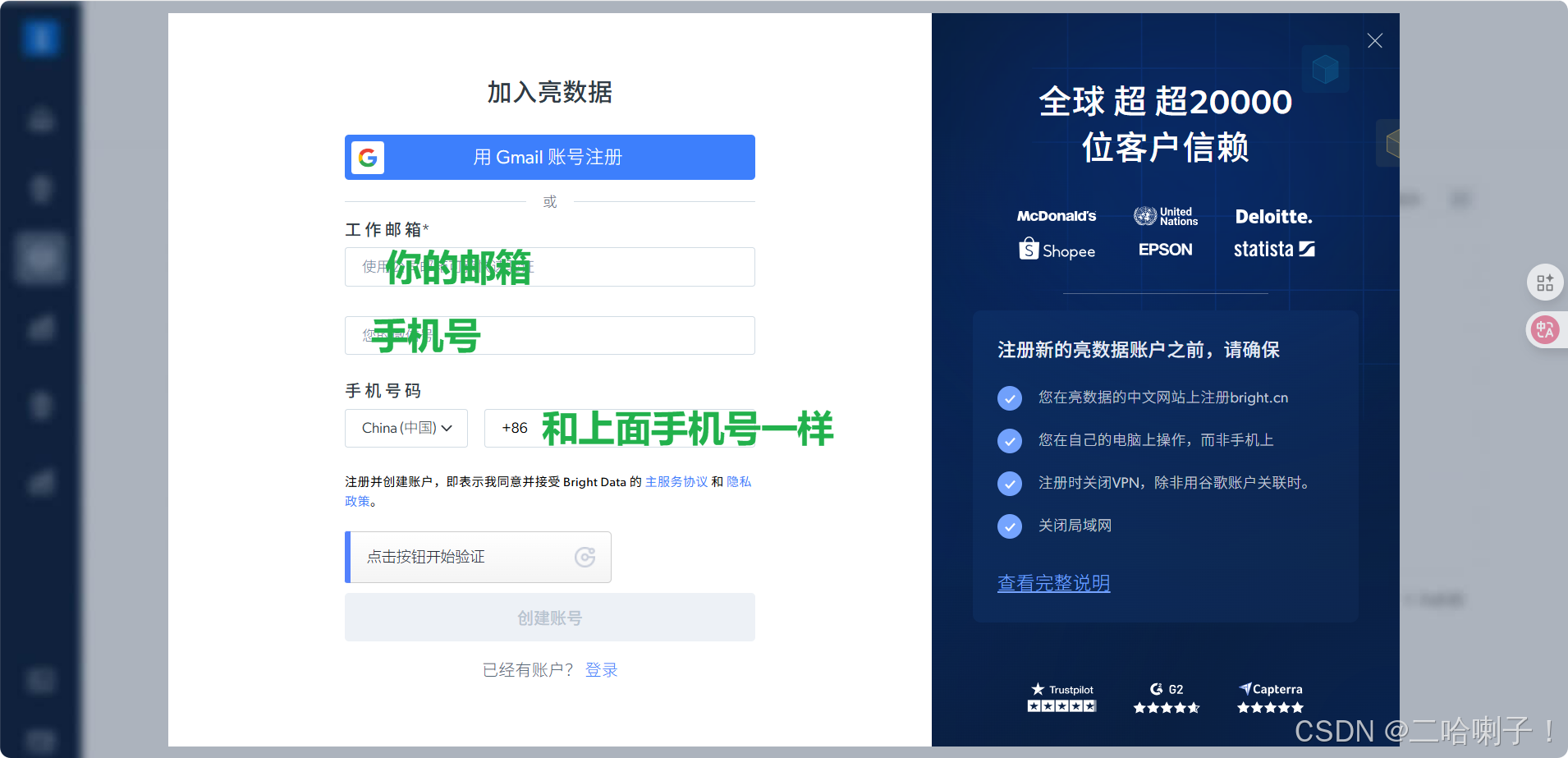
点击创建账号
跳转至邮箱验证处,输入获取到的邮箱验证码
进入到如下页面就说明创建成功
至此注册成功!
启用 AI Studio
-
作为统一的配置与管理入口,无需部署服务器或维护代理池。
-
明确采集需求
确定目标页面类型(列表页 / 详情页)、所需字段、采集频率及地域范围(如“西安站”)。
完成以上准备后,真正的“开发”工作就变成了用自然语言描述需求,而非编写代码。
与传统代理仅提供一个 IP 和端口不同,Bright Data 将大量复杂能力集中在 AI Studio 中,开发者无需在代码层面处理所有异常。
然后填写目标URL
系统自动加载目标结构
接下来定义需要采集的字段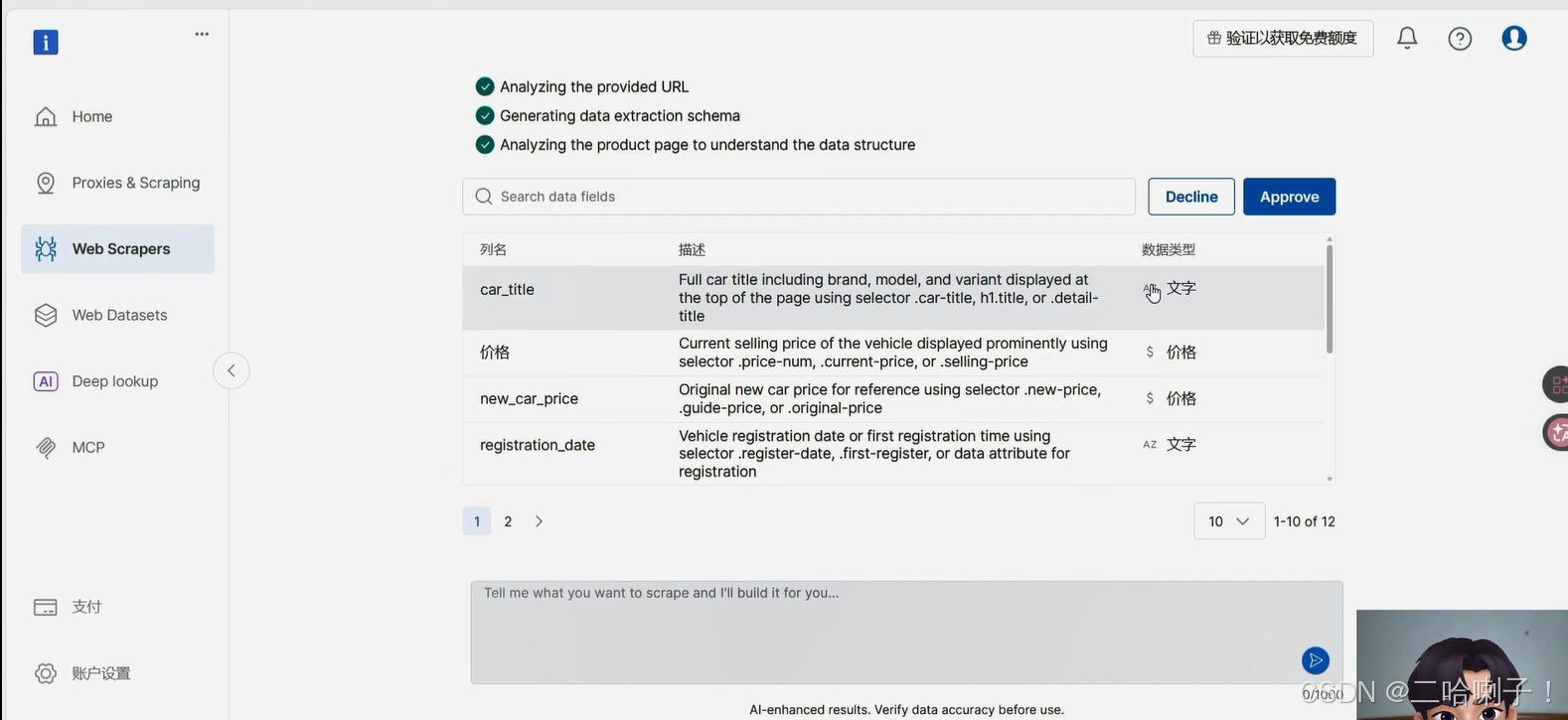
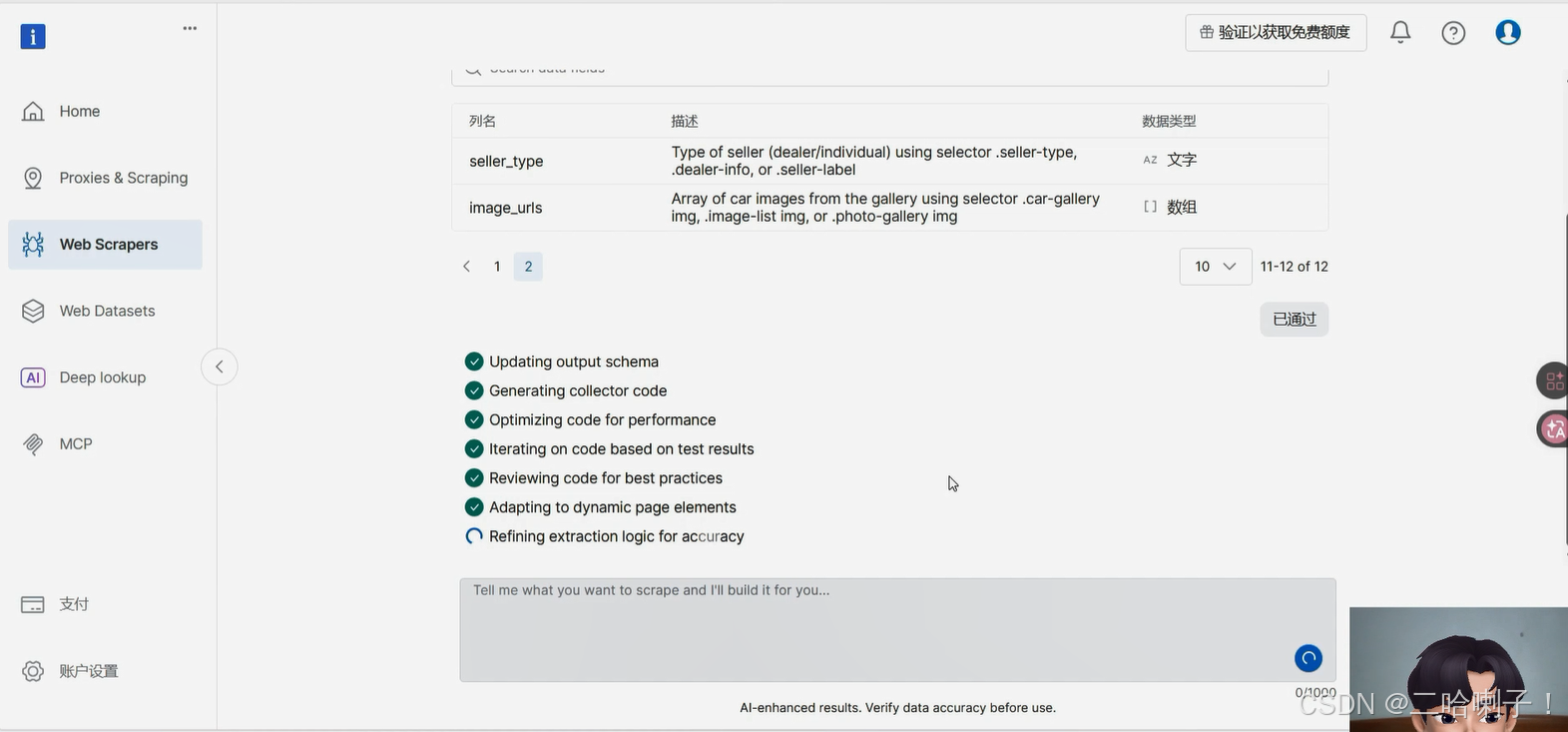
运行采集任务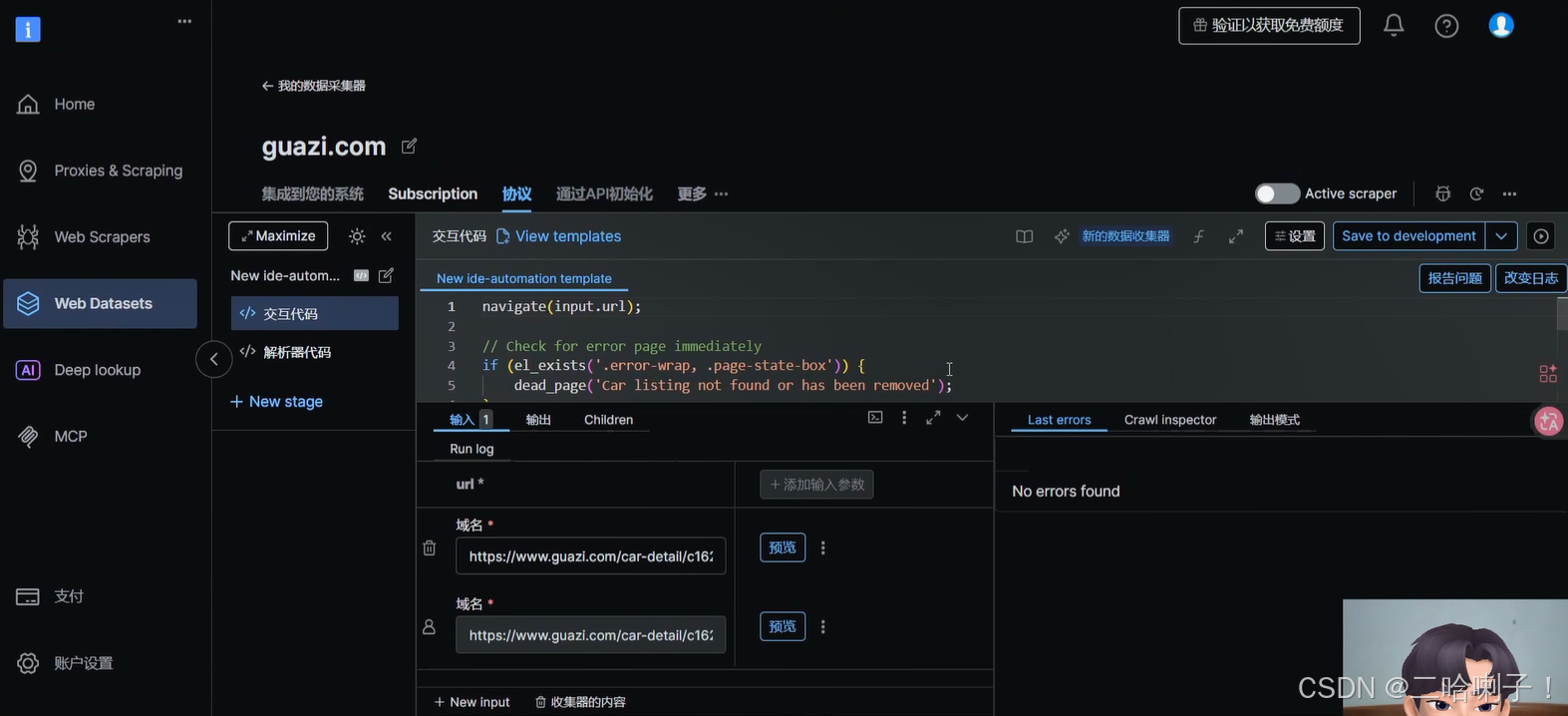
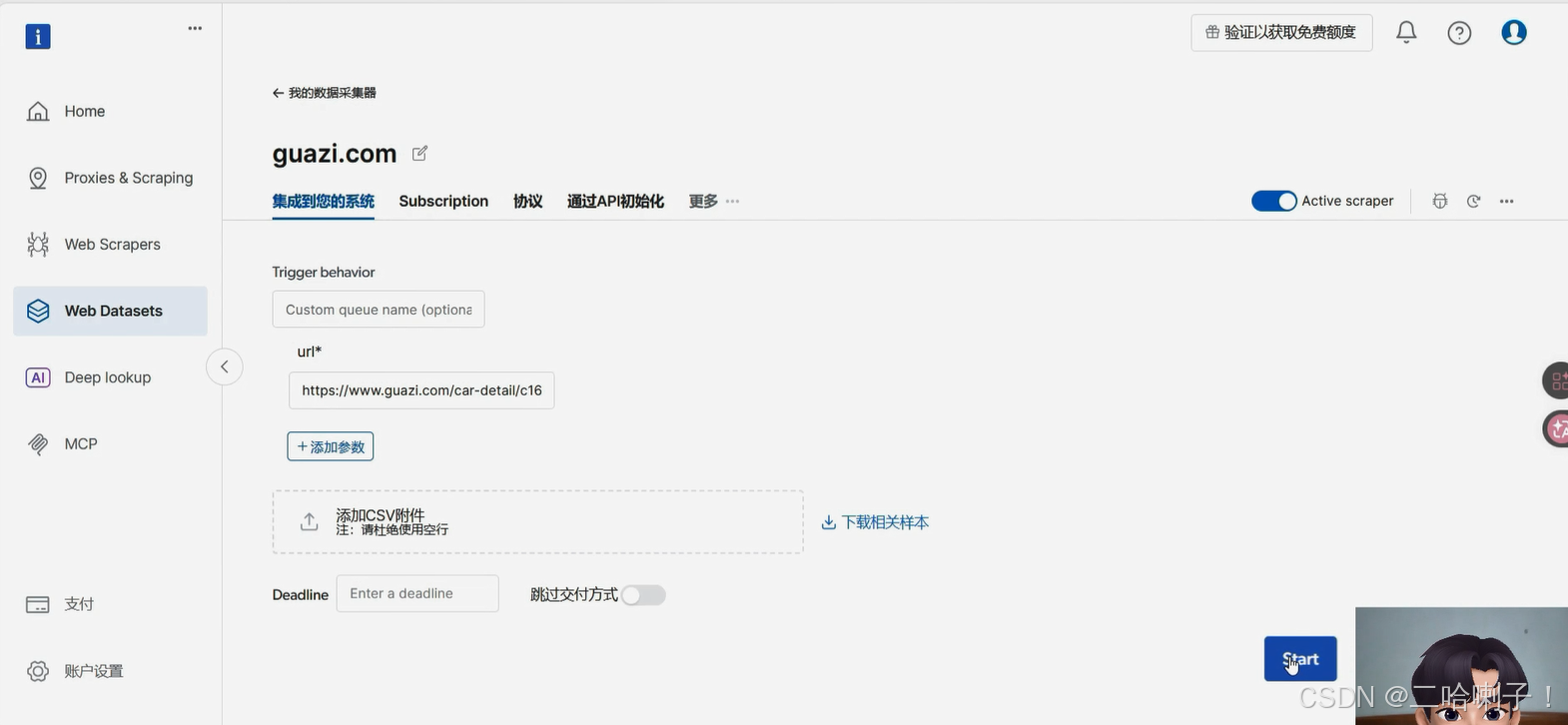
导出数据文件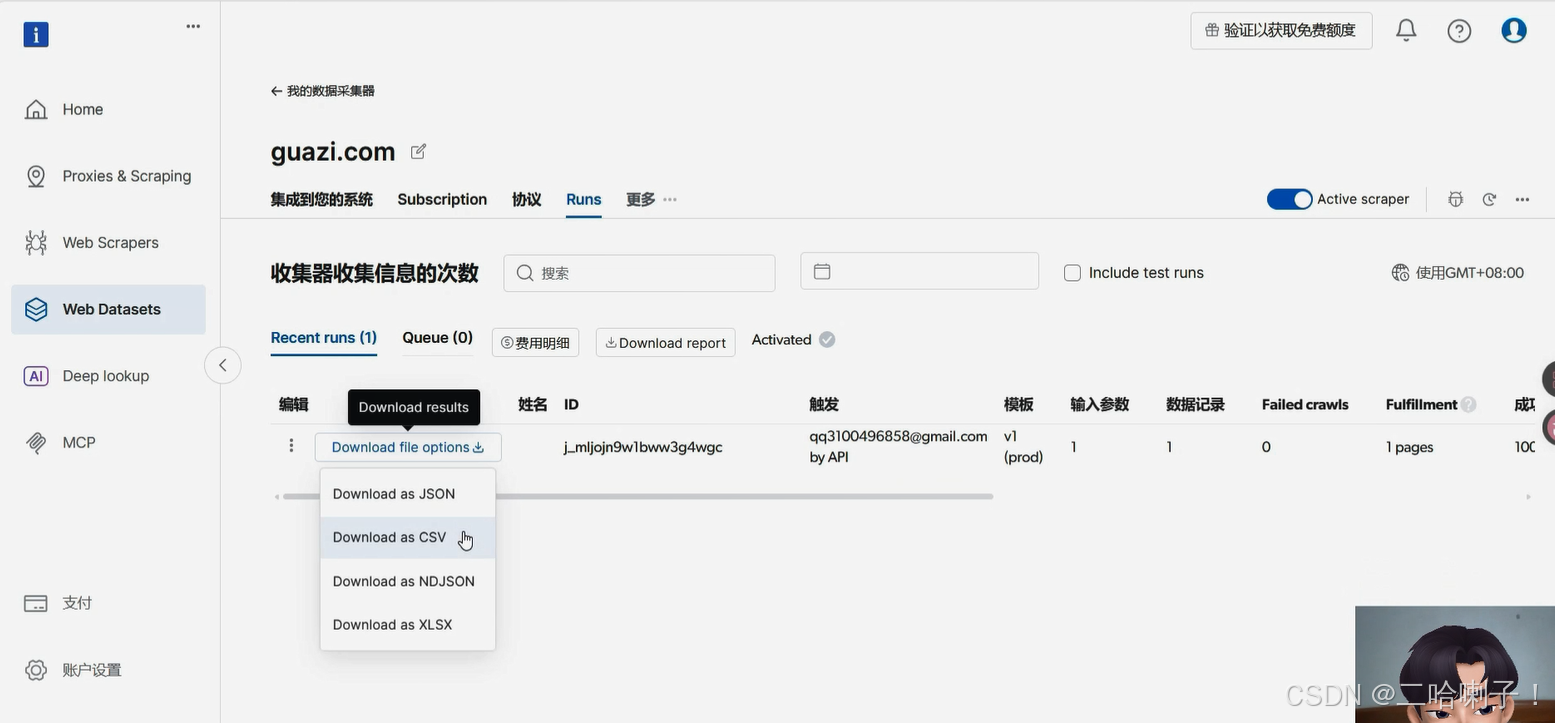
最终爬取的数据文件如下: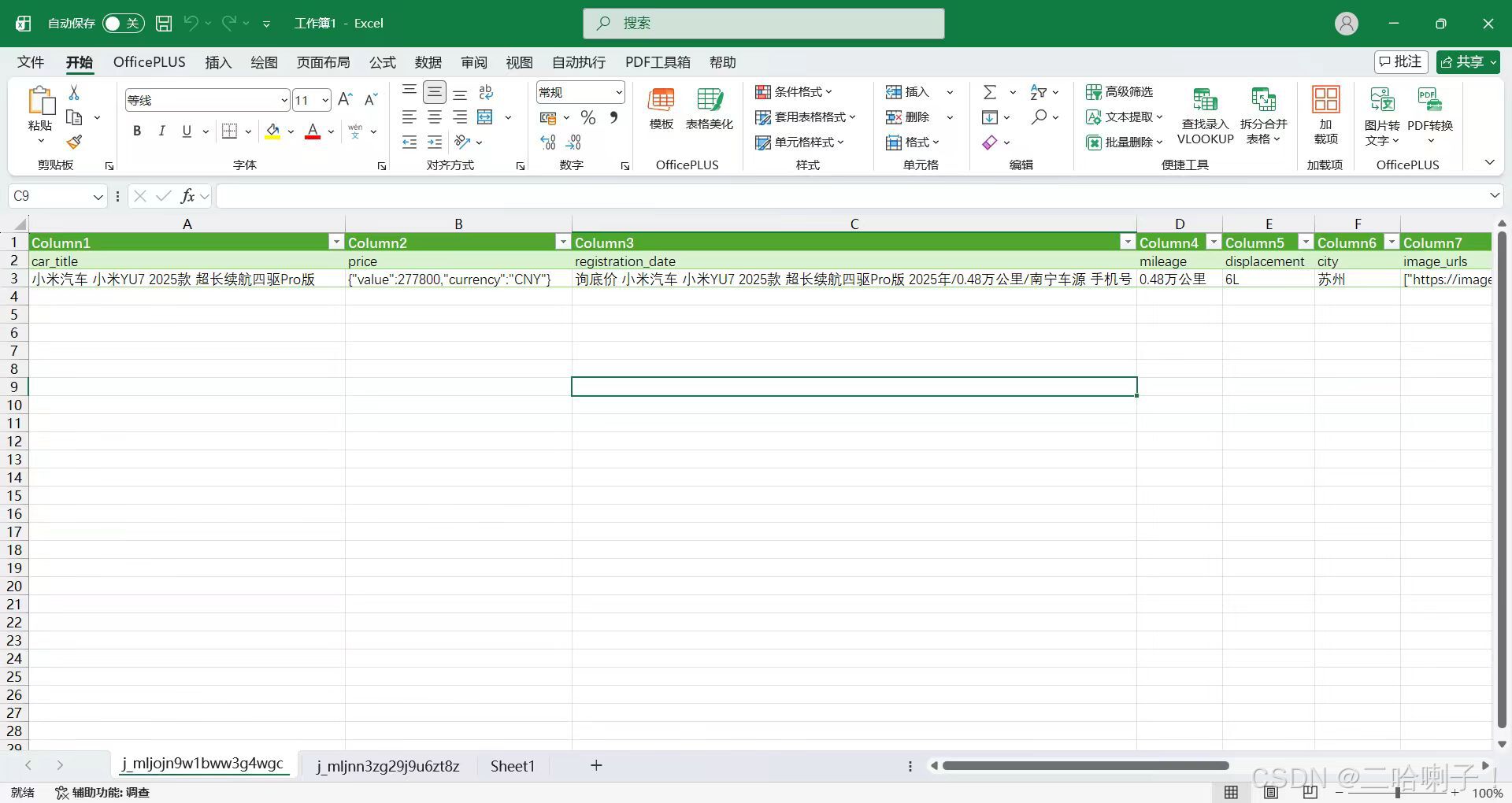
3.3 使用 Bright Data AI Studio:企业级代理的“控制中心”
与传统代理仅提供一个 IP 和端口不同,Bright Data 将大量复杂能力集中在 AI Studio 中,开发者无需在代码层面处理所有异常。
在本次实战中,AI Studio 主要承担以下角色:
- 统一配置代理网络:选择住宅 IP 类型,设置出口区域(如中国大陆)
- 自动处理反封锁逻辑:请求异常自动重试,封禁或验证码触发时自动切换 IP
- 请求状态可视化:成功 / 失败请求一目了然,便于定位异常与优化策略
对于企业而言,这一点非常关键:代理不再是“黑盒”,而是可观测、可管理的基础设施。
3.4 从“爬虫脚本”到“企业级采集任务”
当采集任务在 AI Studio 中配置完成并验证通过后,整个流程就具备了进一步扩展的可能性:
- 按城市并行采集(如北京、上海、西安同步运行)
- 设置每日定时任务,自动更新车源数据
- 通过 API 将结构化数据直接推送至数据仓库或 BI 系统
此时Bright Data 所提供的不只是“代理服务”,而是一个让采集系统可长期、稳定、自动化运行的底座能力。
四、总结与启示
在二手车这类高反爬、高价值、长周期的数据场景中,成功的关键从来不是“爬得多快”,而是能否不费劲地持续拿到干净、可靠的数据。而 Bright Data AI Studio 正是为此而生——让复杂的事自动完成,让人专注真正重要的事。
4.1 采集难在哪?
其实难点不在技术,而在长期稳定性:
反爬是持久战,短期能跑,长期必崩;
网络身份一旦被识破,再“像人”的脚本也无效;
断断续续的数据,对企业决策几乎无用。
这注定它不是一次性任务,而是一项需要省心、省力、可持续的系统工程。
4.2 Bright Data 的真实价值:让采集变得轻松可靠
Bright Data 的核心优势,就是把麻烦事全包了:IP 管理、轮换、解封?全自动处理;
页面改版、验证码拦截?平台智能应对;
任务调度、失败重试、日志监控?开箱即用。
你只需告诉 AI Studio 要什么数据,剩下的交给它,轻松与自动化优势显现的特别明显。
结果是:更低的运维负担、零人工干预、稳定如常的数据流——这才是企业真正需要的“自动化”。
4.3 关键启示:选对工具,事半功倍
网络层不是辅助,而是能力基石;
企业级方案拼的不是便宜,而是省心和可靠;
代理不是可插可拔的“配件”,而是数据管道的基础设施;
好工具的标准很简单:异常少、不用管、一直跑。
4.4 什么时候该用企业级方案?
一次性抓取?普通脚本足够。
但如果你需要:
✅ 多平台(瓜子、人人车、58同城等)
✅ 多城市并行
✅ 每日自动更新
✅ 直接对接 BI 或数据仓库
那么Bright Data 这样的方案,才是真正不费劲、高性价比的选择。
成熟的数据采集,从不靠“修脚本”维生,而是靠自动、稳定、免维护的基础设施。
而这正是 Bright Data 让人安心的地方。
点我跳转 Bright Data 注册链接,点击免费使用👇
通过链接注册的新客户,送30$试用金,感兴趣的小伙伴可以注册体验!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)