时空特征融合新趋势:跨尺度、跨模态、跨主体的统一表示正在成主流
本文聚焦时空特征融合技术的最新进展,精选4篇代表性研究:1)V2XPnP提出统一Transformer框架,实现多智能体时空信息高效融合;2)基于ChangeMamba的遥感检测方法通过精确融合块提升变化检测精度;3)SFADNet采用自适应图融合机制改进交通预测;4)VideoFusion创新性构建多模态数据集,实现视频融合与修复。这些研究从不同维度(融合位置、可解释性、可扩展性)推动时空特征融
过去几年,“时空特征融合”正在从一个通用口号,变成各领域模型性能跃迁的关键抓手:在自动驾驶里,它决定了多视角、多帧信息能否在 3D 空间中稳定对齐;在协同感知里,它决定了多主体、多时刻的数据能否在带宽与实时性约束下高效汇聚;在视频生成与超分辨率里,它又决定了画面细节能否在扩散式采样中保持跨帧一致;甚至在脑电解码、蛋白动力学这类科学数据中,跨尺度的时空结构同样成为提升泛化能力的核心线索。本文精选15 论文,从“融合发生在哪里、融合如何可解释、融合如何高效可扩展”三个维度,带你快速看清这个方向的最新脉络与下一步机会点。
1.V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction.
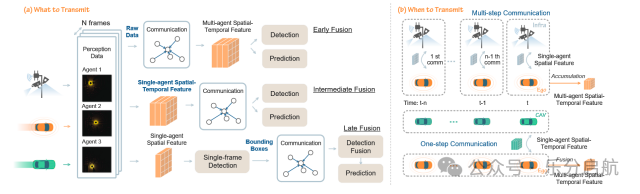
【创新点】
-
提出统一 Transformer 框架融合跨时间、跨空间与多智能体信息。
-
设计中间融合机制(what/when/how 传输策略)提升效率。
-
构建首个大规模真实时序 V2X 序列数据集支持所有协作模式。
【方法】研究中设计了一种基于统一Transformer架构的中间融合框架,能够有效建模多智能体、多帧与高精度地图间的复杂时空关系。
【实验】实验使用了自主研发的V2XPnP Sequential Dataset数据集,全面支持车联网的各种合作模式,并通过广泛实验证明了所提框架在感知与预测任务上优于现有先进方法,相关代码和数据集将公开以促进未来研究。
2.Precision Spatio-Temporal Feature Fusion for Robust Remote Sensing Change Detection
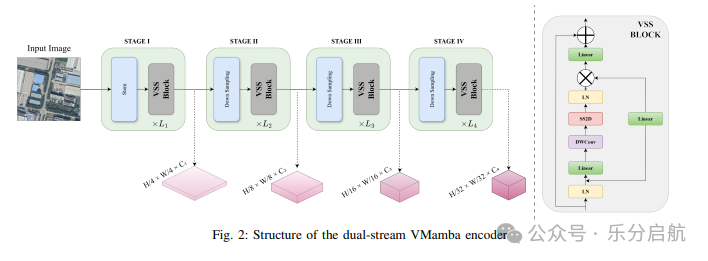
【创新点】
-
引入精细时空融合模块(precision fusion blocks)捕获通道维 temporal 差异。
-
增强解码器结构保留细节信息并减低计算量。
-
优化损失函数提升遥感变化检测精度(IoU/Recall)
【方法】 研究基于ChangeMamba架构,引入了精确融合块以捕捉通道间的时变特征和像素级差异,采用轻量级解码器管道和优化的损失函数来保持局部细节并解决类别不平衡问题。
【实验】在SYSU-CD、LEVIR-CD+和WHU-CD数据集上进行的实验表明,该方法相比现有最佳技术实现了更高的精度、召回率、F1分数、IoU和总体准确率。
3.SFADNet: Spatio-Temporal Fused Graph based on Attention Decoupling Network for Traffic Prediction
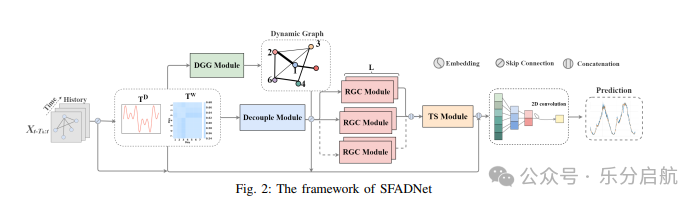
【创新点】
-
跨模式自适应时空图融合机制分解注意力。
-
利用残差图卷积与时间序列模块加强动态关系捕获。
-
不同交通模式下独立图融合改善预测准确度。
【方法】SFADNet通过网络将交通流量分为多个模式,并为每个模式构建独立的自适应时空融合图,利用交叉注意机制、残差图卷积模块和时间序列模块捕捉不同细粒度交通模式下的动态时空关系。
【实验】在四个大规模数据集上进行的广泛实验表明,SFADNet在性能上优于当前最先进的基础模型。
4.VideoFusion: A Spatio-Temporal Collaborative Network for Multi-modal Video Fusion and Restoration

【创新点】
-
提出多模态视频融合数据集 M3SVD。
-
差分强化模块促进跨模态特征交互。
-
Bi-temporal co-attention 捕获前后时间一致性
【方法】VideoFusion模型通过微分强化模块、模态引导融合策略和双向时间共注意机制,实现了跨模态信息的交互增强和时空依赖性的统一建模。
【实验】实验使用了自构建的M3SVD数据集,包含220对时序同步、空间配准的红外-可见光视频对,共153,797帧,结果显示VideoFusion在连续场景中的表现优于现有的图像导向融合方法,有效减少了时间不一致性和干扰。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)