【大模型综述】Large Language Models: A Survey
摘要——自2022年11月ChatGPT发布以来,大语言模型(LLMs)因其在广泛自然语言任务上的强大表现而备受关注。正如缩放定律[1],[2]所预测的,大语言模型的通用语言理解与生成能力是通过在海量文本数据上训练数百亿模型参数而获得的。大语言模型研究领域虽较新,却正以多种不同方式迅速发展。本文回顾了一些最著名的大语言模型,包括三个主流的模型系列(GPT、LLaMA、PaLM),并探讨了它们的特性
Large Language Models: A Survey
大型语言模型综述
摘要
摘要——自2022年11月ChatGPT发布以来,大语言模型(LLMs)因其在广泛自然语言任务上的强大表现而备受关注。正如缩放定律[1],[2]所预测的,大语言模型的通用语言理解与生成能力是通过在海量文本数据上训练数百亿模型参数而获得的。大语言模型研究领域虽较新,却正以多种不同方式迅速发展。本文回顾了一些最著名的大语言模型,包括三个主流的模型系列(GPT、LLaMA、PaLM),并探讨了它们的特性、贡献与局限性。同时,我们概述了构建与增强大语言模型的相关技术。接着,我们梳理了为大语言模型训练、微调及评估所构建的常用数据集,回顾了广泛使用的模型评估指标,并比较了若干主流大语言模型在一组代表性基准测试上的性能表现。最后,我们通过讨论开放挑战与未来研究方向来总结全文。
1.引言
语言建模是一个历史悠久的研究课题,可追溯至20世纪50年代香农将信息论应用于人类语言的研究——他通过衡量简单n元语法语言模型预测或压缩自然文本的效果来开展相关工作[3]。自此,统计语言建模成为众多自然语言理解与生成任务的基础,其应用范围涵盖语音识别、机器翻译到信息检索等诸多领域[4]、[5]、[6]。
基于Transformer架构的大语言模型(LLMs)在网页规模文本语料上进行预训练,其最新进展显著扩展了语言模型的能力。例如,OpenAI的ChatGPT和GPT-4不仅可用于自然语言处理,还能作为通用任务求解器,驱动如Microsoft Co-Pilot等系统,能够遵循人类对复杂新任务的指令,并在需要时执行多步骤推理。因此,大语言模型正逐渐成为开发通用人工智能代理或人工通用智能(AGI)的基础构建模块。
随着大语言模型领域的快速发展,新发现、新模型与新技术在数月甚至数周内便层出不穷[7]、[8]、[9]、[10]、[11],人工智能研究者与实践者常感难以确定构建大语言模型驱动AI系统的最佳方案。本文对近期大语言模型的进展进行了及时的综述,希望本综述能为学生、研究人员和开发者提供一份有价值且易于使用的参考资料。
大语言模型是基于神经网络的大规模预训练统计语言模型。其近期成功是数十年语言模型研发积累的成果,这一发展历程可按不同的起始点与演进速度划分为四个阶段:统计语言模型、神经语言模型、预训练语言模型及大语言模型。
统计语言模型将文本视为单词序列,并通过单词概率的乘积来估算文本概率。其主要形式为马尔可夫链模型,即n-gram模型,该模型根据当前词的前n-1个词来计算其条件概率。由于单词概率是通过文本语料库收集的单词及n1元组频次进行估算,模型需通过平滑技术处理数据稀疏性问题(即对未出现的单词或n-gram赋予零概率),具体方法是为未出现的n-gram保留部分概率质量[12]。N-gram模型被广泛应用于众多自然语言处理系统,但由于数据稀疏性无法完全捕捉自然语言的多样性和变异性,这些模型存在固有局限性。
早期神经语言模型[13]、[14]、[15]、[16]通过将词语映射到低维连续向量(嵌入向量),并利用神经网络聚合其前序词语的嵌入向量来预测下一个词,以此应对数据稀疏性问题。神经语言模型学习到的嵌入向量定义了一个隐含空间,其中向量间的语义相似度可直接通过其距离计算。这为计算任意两个输入的语义相似度开辟了道路,无论其形式(例如,网络搜索中的查询与文档[17]、[18]、机器翻译中不同语言的句子[19]、[20])或模态(例如,图像描述任务中的图像与文本[21]、[22])如何。早期的神经语言模型是任务特定模型,即它们基于任务特定数据进行训练,其学习到的隐含空间也是任务特定的。
预训练语言模型(PLMs)与早期的神经语言模型不同,是任务无关的。这种通用性同样延伸至其学习到的隐藏嵌入空间。PLMs的训练与推理遵循预训练与微调范式:即采用循环神经网络[23]或Transformer架构[24], [25], [26]的语言模型首先在网络规模的未标注文本语料库上进行预训练,以完成词语预测等通用任务,随后使用少量(带标注的)任务特定数据针对具体任务进行微调。关于PLMs的最新综述可参见[8], [27], [28]。
大语言模型主要指基于Transformer架构的神经语言模型¹,其参数量达数百亿至数千亿规模,并基于海量文本数据进行预训练,例如PaLM[31]、LLaMA[32]和GPT-4[33]等(汇总见表III)。相较于预训练语言模型,大语言模型不仅规模显著更大,且展现出更强的语言理解与生成能力,更重要的是具备小规模语言模型所缺乏的涌现能力。如图1所示,这些涌现能力包括:(1)上下文学习,即大语言模型在推理时能够通过提示中提供的少量示例学习新任务;(2)指令跟随,即经过指令微调的大语言模型无需显式示例即可遵循指令完成新型任务;(3)多步推理,即大语言模型能通过思维链提示[34]将复杂任务分解为中间推理步骤进行求解。大语言模型还可通过外部知识与工具进行增强[35]、[36],从而实现与用户及环境的高效交互[37],并能利用交互过程中收集的反馈数据(例如基于人类反馈的强化学习)实现持续自我优化。
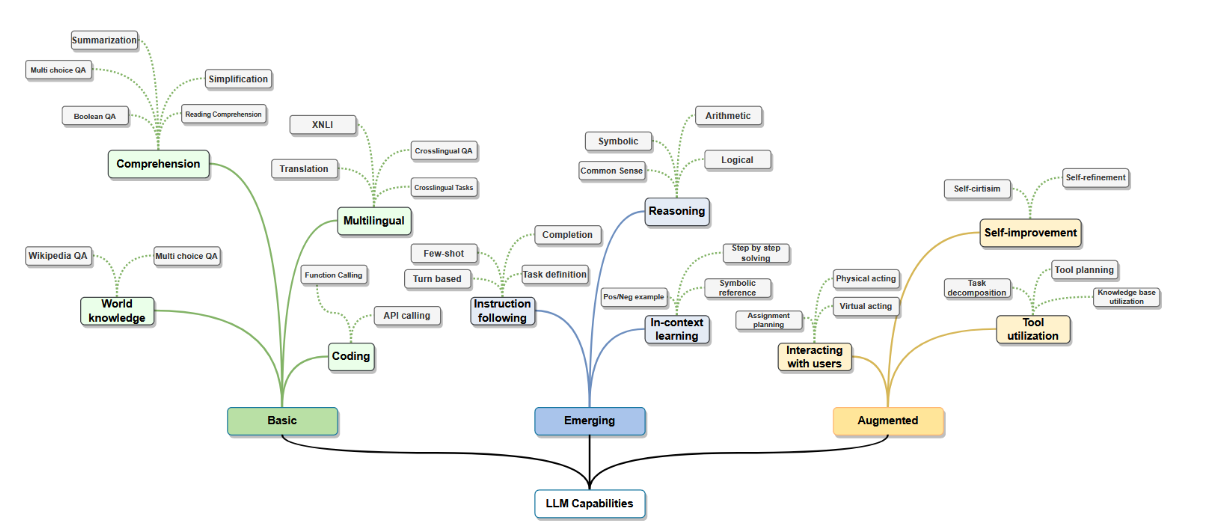
图1:大语言模型能力。
通过先进的应用与增强技术,大型语言模型可部署为所谓的人工智能体:即能够感知环境、做出决策并执行行动的人工实体。既往研究主要聚焦于开发针对特定任务和领域的人工智能体。大型语言模型所展现出的涌现能力,使得构建基于大型语言模型的通用人工智能体成为可能。虽然大型语言模型的训练旨在静态环境中生成响应,但人工智能体需要采取行动与动态环境进行交互。因此,基于大型语言模型的智能体通常需要对模型进行增强,例如从外部知识库获取更新信息、验证系统操作是否产生预期结果,以及处理未按预期发展的情况等。我们将在第四章详细讨论基于大型语言模型的智能体。
本文后续章节结构如下:第二章节将概述大语言模型的研究现状,重点介绍三大模型系列(GPT、LLaMA 和 PaLM)及其他代表性模型。第三章节探讨大语言模型的构建方法。第四章节讨论大语言模型的实际应用方式及其在现实场景中的增强技术。第五、六章节回顾用于评估大语言模型的常用数据集与基准测试,并总结已公开的模型评估结果。最后,第七章节总结全文,归纳当前面临的挑战并展望未来研究方向。
图2:论文结构。
2.大语言模型
在本节中,我们首先回顾早期的预训练神经语言模型,它们是大型语言模型的基础。随后我们将讨论聚焦于三大类大型语言模型:GPT、LlaMA 和 PaLM。表一概述了其中部分模型及其特性。
A. 早期预训练神经语言模型
[38]、[39]、[40]开创了使用神经网络进行语言建模的先河。Bengio等人[13]开发了最早可与n-gram模型相媲美的神经语言模型之一。随后,[14]成功将神经语言模型应用于机器翻译。Mikolov发布的RNNLM(一个开源的神经语言模型工具包)[41]、[42]极大地促进了神经语言模型的普及。此后,基于循环神经网络及其变体(如长短期记忆网络[19]和门控循环单元[20])的神经语言模型,被广泛应用于机器翻译、文本生成和文本分类等众多自然语言处理任务中[43]。
随后,Transformer架构[44]的发明成为神经语言模型发展史上的又一里程碑。该架构通过自注意力机制并行计算句子或文档中每个词语对其他词语的“注意力分数”,以建模词间相互影响。相比循环神经网络,Transformer实现了更高程度的并行化,这使得在GPU上利用海量数据高效预训练超大规模语言模型成为可能。此类预训练语言模型可通过微调适配多种下游任务。
我们根据神经网络架构,将早期流行的基于Transformer的预训练语言模型分为三大主要类别:仅编码器、仅解码器以及编码器-解码器模型。关于早期预训练语言模型的全面综述可参见文献[43]和[28]。
1)仅编码器预训练语言模型:顾名思义,仅编码器模型仅包含编码器网络。这类模型最初是为语言理解任务开发的,例如文本分类任务,其中模型需要为输入文本预测类别标签。代表性的仅编码器模型包括BERT及其变体,例如下文将描述的RoBERTa、ALBERT、DeBERTa、XLM、XLNet、UNILM等。
BERT(来自Transformer的双向编码器表征)[24] 是目前使用最广泛的仅编码器语言模型之一。BERT包含三个模块:(1)嵌入模块,将输入文本转换为嵌入向量序列;(2)多层Transformer编码器堆栈,将嵌入向量转换为上下文表征向量;(3)全连接层,将(最后一层的)表征向量转换为独热向量。BERT采用两种目标进行预训练:掩码语言建模和下一句预测。预训练的BERT模型可通过添加分类器层进行微调,以适用于多种语言理解任务,包括文本分类、问答和语言推理。BERT框架的高层概览如图3所示。由于BERT在发布时显著提升了众多语言理解任务的性能水平,人工智能领域受此启发,基于BERT开发了许多类似的仅编码器语言模型。
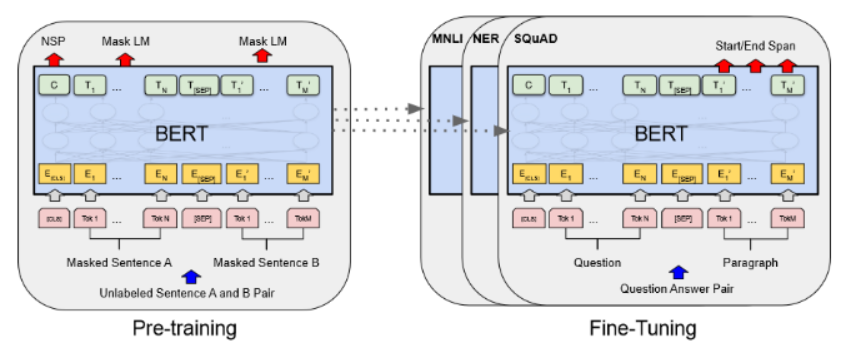
图3:BERT的整体预训练与微调流程。由文献[24]提供。
RoBERTa [25]通过一系列模型设计选择与训练策略显著提升了BERT的鲁棒性,例如修改若干关键超参数、移除下一句预测的预训练目标,并使用更大的小批量与更高的学习速率进行训练。ALBERT [45]采用两种参数削减技术以降低内存消耗并提升BERT训练速度:(1) 将嵌入矩阵分解为两个较小矩阵;(2) 使用跨组共享的重复层结构。DeBERTa(基于解耦注意力机制的增强解码BERT)[26]通过两项新技术改进了BERT与RoBERTa模型:其一是解耦注意力机制,每个词分别由内容编码向量和位置编码向量表示,并基于词的内容与相对位置通过解耦矩阵分别计算注意力权重;其二是引入增强掩码解码器,在解码层整合绝对位置信息以预测预训练中被遮蔽的词元。此外,该模型采用新型虚拟对抗训练方法进行微调以提升模型泛化能力。ELECTRA [46]提出替换词元检测(RTD)这一新型预训练任务,实验证明其样本效率高于掩码语言建模(MLM)。RTD并非对输入进行遮蔽,而是通过小型生成网络采样生成替代词元替换部分原始词元以破坏输入,随后训练判别模型检测被破坏输入中的每个词元是否被替换,而非预测被替换词元的原始身份。如图4所示,由于RTD任务针对全部输入词元进行定义,而非仅针对被遮蔽的少量子集,其样本效率显著高于MLM。
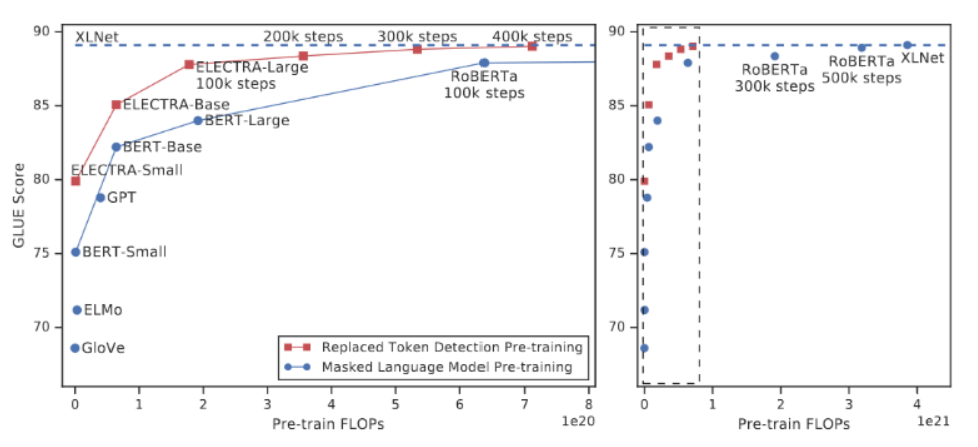
图4:替换词检测与掩码语言建模的对比示意图。由文献[46]提供。
XLMs [47] 通过两种方式将BERT扩展为跨语言模型:(1) 仅依赖单语数据的无监督方法;(2) 利用平行数据并采用全新跨语言模型目标的监督方法,如图5所示。在提出之时,XLMs在跨语言分类、无监督与有监督机器翻译任务上均取得了最先进的结果。
也存在仅编码器的语言模型,它们利用了自回归(解码器)模型在训练与推理方面的优势。XLNet和UNILM即为两个典型代表。XLNet[48]基于Transformer-XL架构,采用广义自回归方法进行预训练,该方法通过最大化因式分解顺序所有排列的期望似然来学习双向上下文信息。UNILM(统一预训练语言模型)[49]则通过三种语言建模任务进行预训练:单向预测、双向预测及序列到序列预测。该模型采用共享的Transformer网络,并利用特定的自注意力掩码来控制预测所依据的上下文条件(如图6所示)。此预训练模型可针对自然语言理解与生成任务进行微调。
- 仅解码器预训练语言模型:OpenAI开发的GPT-1和GPT-2是两种应用最广泛的仅解码器预训练语言模型。这些模型为后续更强大的大语言模型(即GPT-3和GPT-4)奠定了基础。
GPT-1 [50]首次证明,通过对仅解码器Transformer模型在多样化无标注语料库上进行生成式预训练(GPT,采用自监督学习方式,即下一词/元预测),随后针对每个特定下游任务(使用少得多的样本)进行判别式微调,如图7所示,可以在广泛的自然语言任务上获得良好性能。GPT-1为后续的GPT模型铺平了道路,每个后续版本都在架构上有所改进,并在各种语言任务上实现了更优的性能。
GPT-2 [51] 表明,当在由数百万个网页组成的大型WebText数据集上进行训练时,语言模型能够在没有任何显式监督的情况下学会执行特定的自然语言处理任务。GPT-2模型遵循了GPT-1的模型设计,并做了一些修改:将层归一化移至每个子块的输入处,并在最终的自注意力块之后增加了额外的层归一化。初始化过程经过修改,以适配残差路径上的累积效应并对残差层权重进行缩放,词汇表规模扩展至50,265,上下文长度从512个标记增至1024个标记。
3)编码器-解码器预训练语言模型:在文献[52]中,Raffle等人指出几乎所有自然语言处理任务均可转化为序列到序列的生成任务。因此,编码器-解码器语言模型本质上是一种统一模型,能够执行所有自然语言理解与生成任务。下文将重点评述的典型编码器-解码器预训练模型包括T5、mT5、MASS和BART。
T5模型[52]是一种文本到文本的迁移转换器,它通过引入一个统一框架,将各类自然语言处理任务都转化为文本到文本的生成任务,从而有效地利用迁移学习进行自然语言处理。mT5[53]是T5的多语言变体,其基于包含101种语言文本的新通用爬虫数据集进行预训练。
MASS(MAsked Sequence to Sequence pre-training)模型[54]采用编码器-解码器框架,在给定句子其余部分的前提下重构被遮蔽的句子片段。编码器以随机遮蔽了片段(若干连续标记)的句子作为输入,解码器则负责预测被遮蔽的片段。通过这种方式,MASS实现了对编码器和解码器的联合训练。编码器与解码器分别负责语言嵌入和生成任务。
BART [55]采用标准的序列到序列翻译模型架构,其预训练过程通过任意噪声函数破坏文本,随后学习重构原始文本。
B. 大型语言模型家族
大语言模型主要指数百亿至数千亿参数的基于Transformer的预训练语言模型。相较于前述预训练模型,大语言模型不仅参数量级显著提升,更展现出更强的语言理解与生成能力,以及小规模模型所不具备的涌现能力。下文将依据图8所示,综述三大类大语言模型:GPT系列、LLaMA系列与PaLM系列。
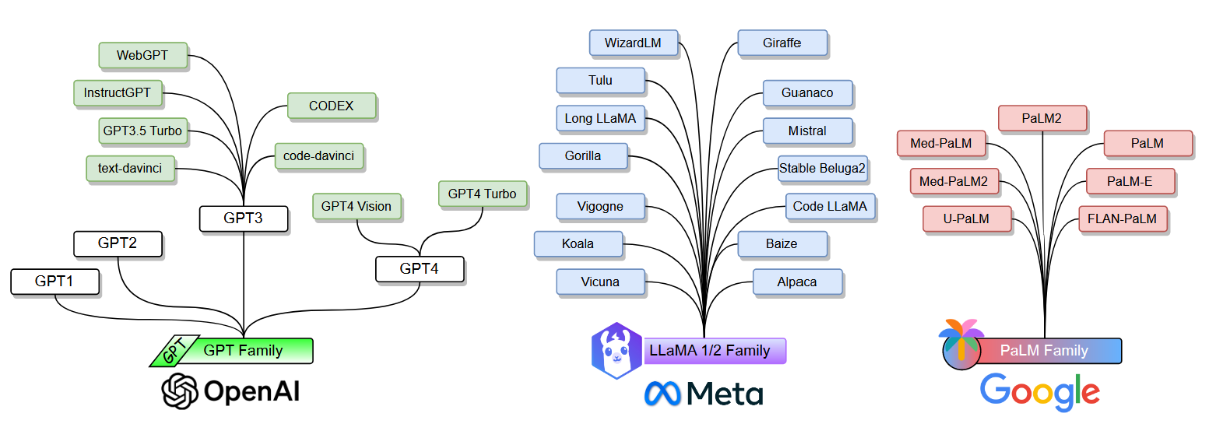
图8:主流大语言模型家族。
- GPT系列:生成式预训练Transformers(GPT)是由OpenAI开发的一系列仅包含解码器的基于Transformer架构的语言模型。该系列包括GPT-1、GPT-2、GPT-3、InstrucGPT、ChatGPT、GPT-4CODEX与WebGPT等。尽管早期GPT模型(如GPT-1与GPT-2)为开源模型,但近期模型(如GPT-3与GPT-4)均为闭源,仅能通过API接口访问。GPT-1与GPT-2模型已在先前预训练语言模型小节中讨论,下文我们将从GPT-3开始展开。
GPT-3 [56] 是一个拥有 1750 亿参数、经过预训练的自回归语言模型。GPT-3 被广泛认为是第一个真正意义上的大语言模型,这不仅因为它比之前的预训练语言模型规模大得多,更因为它首次展现出了在先前较小模型中未观察到的 涌现能力。GPT-3 展现了上下文学习的涌现能力,这意味着无需任何梯度更新或微调,仅通过纯文本交互指定任务和少量示例演示,即可将 GPT-3 应用于任何下游任务。GPT-3 在许多自然语言处理任务中取得了强大性能,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,例如单词重组、在句子中使用新词、三位数算术等。图 9 绘制了 GPT-3 的性能随上下文提示中示例数量变化的函数关系。
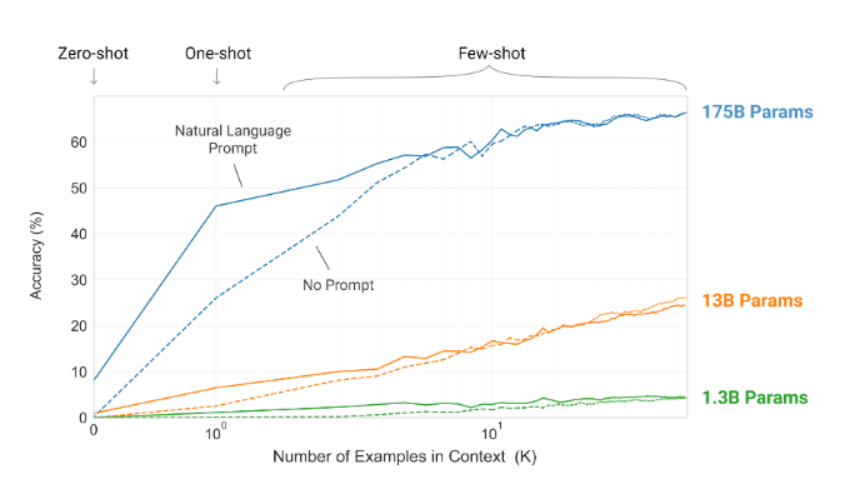
图9:GPT-3表明,规模更大的模型能对上下文信息的利用效率持续提升。该图展示了模型在一项简单任务上的上下文学习性能,此任务要求模型移除单词中的随机符号。实验同时包含了有自然语言任务描述和无描述两种情况。引自[56]。
CODEX [57]由 OpenAI 于 2023 年 3 月发布,是一个通用编程模型,能够解析自然语言并据此生成代码。CODEX 是 GPT-3 的衍生模型,基于从 GitHub 收集的代码库进行微调,专门用于编程应用。微软的 GitHub Copilot 即由 CODEX 驱动。
WebGPT [58] 是 GPT-3 的另一分支,它经过微调,能够使用基于文本的网络浏览器来回答开放式问题,从而辅助用户进行网络搜索与浏览。WebGPT的训练分为三个步骤。首先,WebGPT利用人类演示数据学习模仿人类的浏览行为。接着,通过训练一个奖励函数来预测人类偏好。最后,通过强化学习和拒绝采样对WebGPT进行微调,以优化该奖励函数。
为使大型语言模型能够遵循预期的人类指令,InstructGPT [59] 被提出,旨在通过基于人类反馈的微调,使语言模型与用户在广泛任务上的意图保持一致。该方法首先从标注员编写的提示词及通过OpenAI API提交的提示词入手,收集了一个展示期望模型行为的标注员示范数据集。随后,GPT-3在此数据集上进行了微调。接着,收集了一个由人工排序的模型输出数据集,以利用强化学习进一步微调模型。该方法被称为"基于人类反馈的强化学习",如图10所示。最终得到的InstructGPT模型在真实性方面有所提升,有害输出生成有所减少,同时在性能上仅有微小影响。在公共自然语言处理数据集上的回归分析。
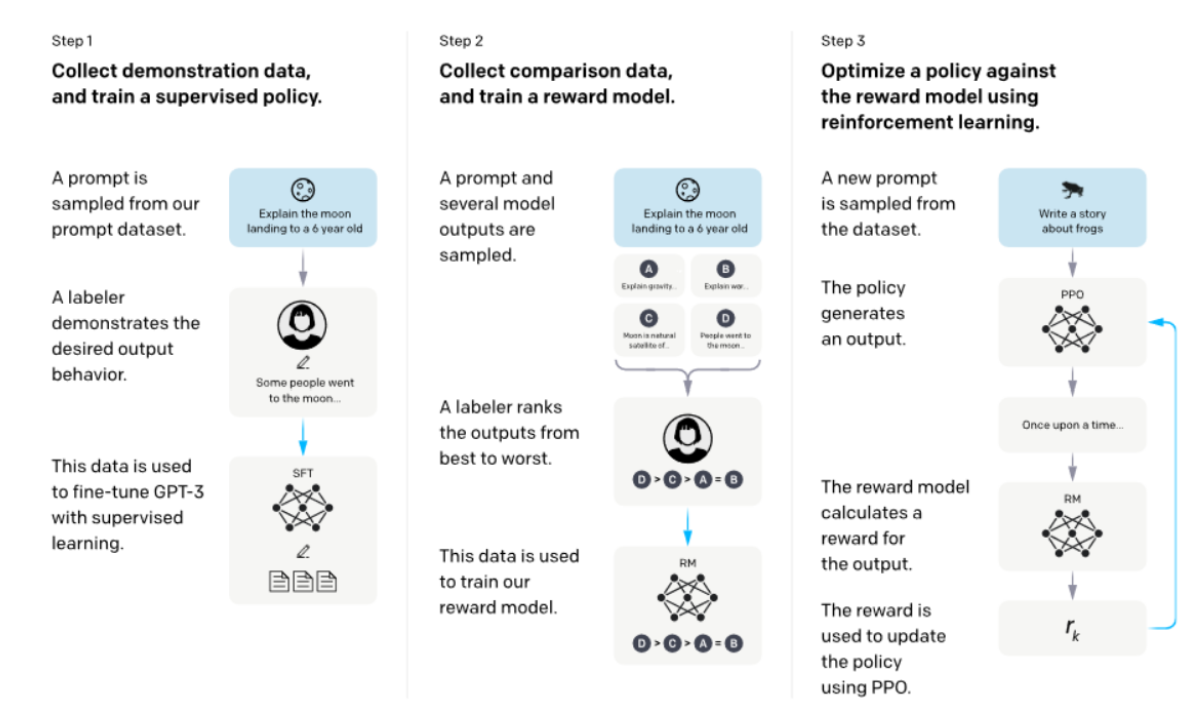
图10:RLHF的高级概述。由[59]提供。
大型语言模型发展最重要的里程碑,是2022年11月30日发布的ChatGPT(Chat Generative Pre-trained Transformer)[60]。ChatGPT是一种聊天机器人,它使用户能够引导对话以完成广泛的任务,例如问答、信息检索、文本总结等。ChatGPT由GPT-3.5(及后续的GPT-4)驱动,该模型是InstructGPT的姊妹模型,经训练可遵循提示中的指令并提供详尽的回应。
GPT-4 [33] 是 GPT 家族中最先进、最强大的大语言模型。它于2023年3月发布,是一个多模态大语言模型,能够接收图像和文本作为输入,并生成文本输出。尽管在一些最具挑战性的现实场景中,其能力仍不及人类,但GPT-4在各种专业和学术基准测试中展现出人类水平的性能,例如在图11所示的一项模拟律师资格考试中,其得分约位于应试者的前10%。与早期的GPT模型类似,GPT-4首先在大型文本语料库上进行预训练以预测下一个词元,随后通过基于人类反馈的强化学习进行微调,以使模型行为与人类期望的目标保持一致。
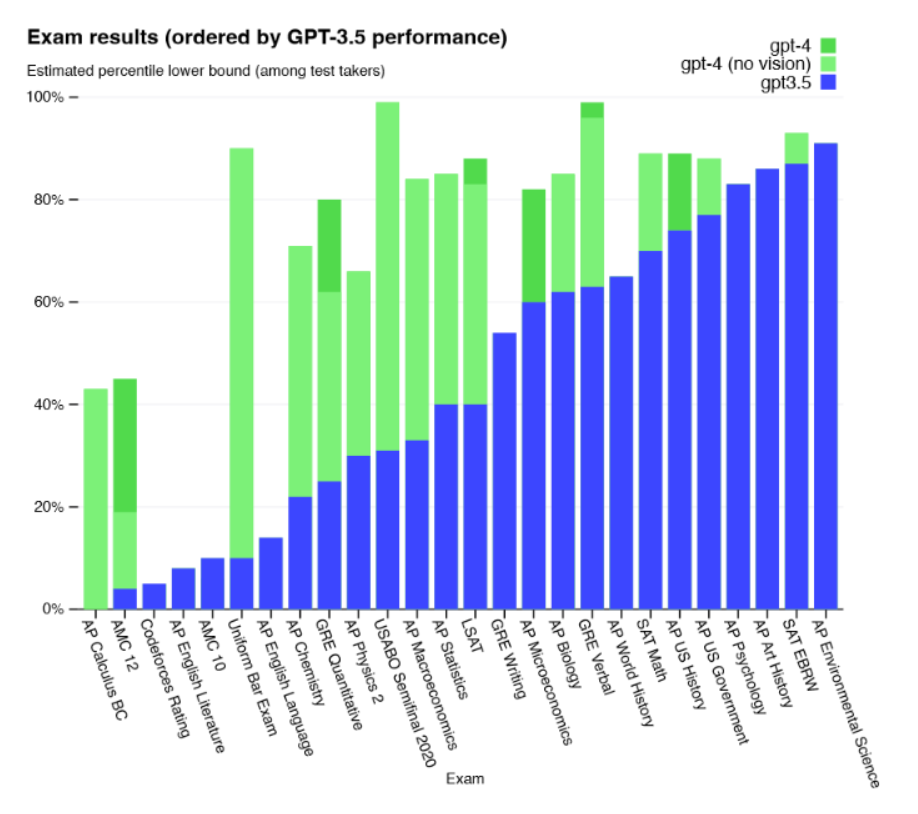
图11:GPT-4在学术与专业考试中的表现,与GPT-3.5对比。引自[33]。
- LLaMA系列模型:LLaMA是Meta发布的一系列基础语言模型。与GPT模型不同,LLaMA模型是开源的,即在非商业许可下向研究社区开放模型权重。因此,随着众多研究团队广泛使用这些模型来开发更优秀的开源大语言模型以抗衡闭源模型,或为关键任务型应用开发专用领域大语言模型,LLaMA系列得以迅速发展。
首套LLaMA模型[32]于2023年2月发布,参数量级涵盖70亿至650亿。这些模型基于从公开数据集中收集的数万亿token进行预训练。LLaMA采用GPT-3的Transformer架构,并进行了若干细微的架构调整,包括:(1)使用SwiGLU激活函数替代ReLU;(2)采用旋转位置编码取代绝对位置编码;(3)使用均方根层归一化替代标准层归一化。开源LLaMA-13B模型在多数基准测试中性能优于专有GPT-3(1750亿参数)模型,使其成为大语言模型研究的优质基线。
2023年7月,Meta与微软合作发布了LLaMA-2系列模型[61],该系列包含基础语言模型以及专为对话优化的微调聊天模型,即LLaMA-2 Chat。据报告,LLaMA-2 Chat模型在多项公开基准测试中表现优于其他开源模型。图12展示了LLaMA-2 Chat的训练流程。该流程始于使用公开可用的在线数据对LLaMA-2进行预训练,随后通过监督微调构建LLaMA-2 Chat的初始版本。之后,模型通过人类反馈强化学习(RLHF)、拒绝采样和近端策略优化进行迭代精炼。在RLHF阶段,积累人类反馈以修正奖励模型至关重要,这能防止奖励模型变化过大,从而保障LLaMA模型训练的稳定性。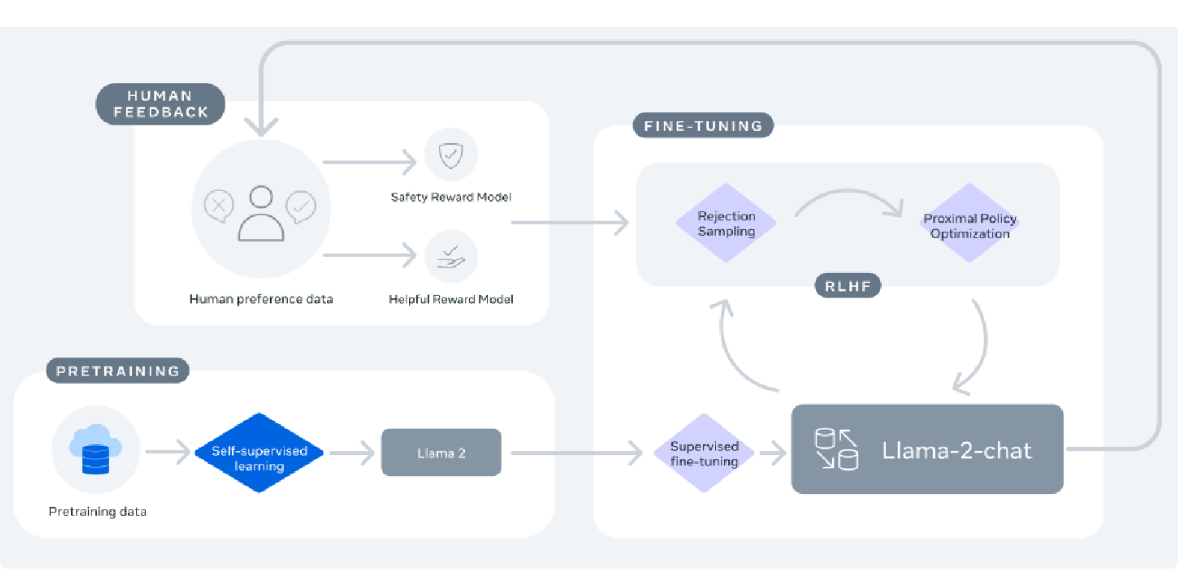
图12:LLaMA-2对话模型的训练过程。来源:[61]。
Alpaca [62]基于LLaMA-7B模型微调而成,其训练使用了52K条遵循指令的演示数据,这些数据采用自指令风格通过GPT-3.5(text-davinci-003)生成。Alpaca的训练成本效益显著,尤其适用于学术研究。在自指令评估集上,尽管Alpaca模型规模小得多,但其表现与GPT-3.5相近。
Vicuna团队通过使用从ShareGPT收集的用户共享对话数据对LLaMA进行微调,开发出了130亿参数的对话模型Vicuna-13B。基于GPT-4的初步评估显示,Vicuna-13B的质量达到了OpenAI ChatGPT和Google Bard的90%以上,并在超过90%的案例中优于LLaMA和斯坦福Alpaca等其他模型。图13展示了GPT-4评估的Vicuna与其他知名模型的相对响应质量。Vicuna-13B的另一优势是其相对有限的模型训练计算需求,该模型的训练成本仅需300美元。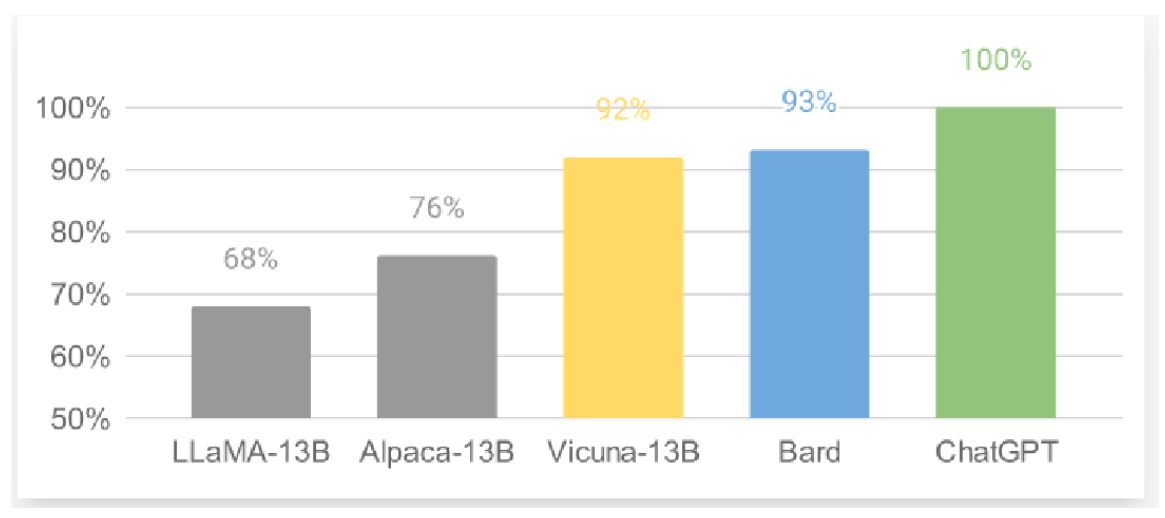
图13:Vicuna及其他几款知名模型由GPT-4评估的相对响应质量。由Vicuna团队提供。
与Alpaca和Vicuna类似,Guanaco模型[63]同样是基于指令跟随数据对LLaMA进行微调的模型。但其微调过程通过QLoRA技术实现了极高效率,使得拥有650亿参数的模型仅需单块48GB GPU即可完成微调。QLoRA通过冻结的4位量化预训练语言模型将梯度反向传播至低秩适配器(LoRA)。在Vicuna基准测试中,最优的Guanaco模型超越了此前发布的所有模型,达到了ChatGPT性能水平的99.3%,而仅在单GPU上经过24小时微调即实现这一结果。
考拉(Koala)[64] 是另一款基于LLaMA构建的指令遵循语言模型,但它特别专注于使用包含用户输入以及由ChatGPT等高性能闭源聊天模型生成回复的交互数据。根据基于真实世界用户提示的人工评估,Koala-13B模型的表现与最先进的聊天模型具有竞争力。
Mistral-7B [65] 是一款拥有70亿参数的语言模型,旨在实现卓越性能与高效能。在所有评估基准测试中,Mistral-7B的表现均超越了最佳开源130亿参数模型(LLaMA-2-13B),并在推理、数学和代码生成任务上超越了最佳开源340亿参数模型(LLaMA-34B)。该模型采用分组查询注意力机制以加速推理,并结合滑动窗口注意力机制,能够以较低的推理成本有效处理任意长度的序列。
LLaMA家族正在快速扩张,基于LLaMA或LLaMA2构建的指令跟随模型日益增多,包括Code LLaMA [66]、Gorilla [67]、Giraffe [68]。仅举几例,包括Vigogne [69]、Tulu 65B [70]、Long LLaMA [71]以及Stable Beluga2 [72]。
- PaLM系列模型:PaLM(Pathways语言模型)系列由谷歌开发。首个PaLM模型[31]于2022年4月发布,且未开源截至2023年3月。该模型为基于Transformer架构的5400亿参数大型语言模型,其预训练数据来自包含7800亿标记的高质量文本语料库,涵盖广泛自然语言任务与应用场景。PaLM 使用Pathways系统在6144个TPU v4芯片上进行预训练,该架构实现了跨多TPU Pod的高效训练。通过在上百项语言理解与生成基准测试中创造少样本学习性能纪录,PaLM证明了模型扩展的持续优势。PaLM540B不仅在一系列多步推理任务上超越现有精调模型,更在最新发布的BIG-bench基准测试中达到与人类相当的水平。
U-PaLM系列模型包含8B、62B和540B三种规模,其训练方法是在PaLM基础上采用UL2R进行持续训练。该方法以UL2的混合去噪目标[73]对大型语言模型进行少量步数的持续训练。据报道,该方法可实现约2倍的计算资源节省率。
U-PaLM后续通过指令微调成为Flan-PaLM[74]。与上文提及的其他指令微调工作相比,Flan-PaLM的微调使用了更大量的任务集、更大的模型规模以及思维链数据。因此,Flan-PaLM显著优于以往的指令遵循模型。例如,基于1.8K个任务进行指令微调的Flan-PaLM-540B模型,其性能大幅超越原始PaLM-540B模型(平均提升+9.4%)。微调数据包含473个数据集、146个任务类别,总计1,836项任务,如图14所示。
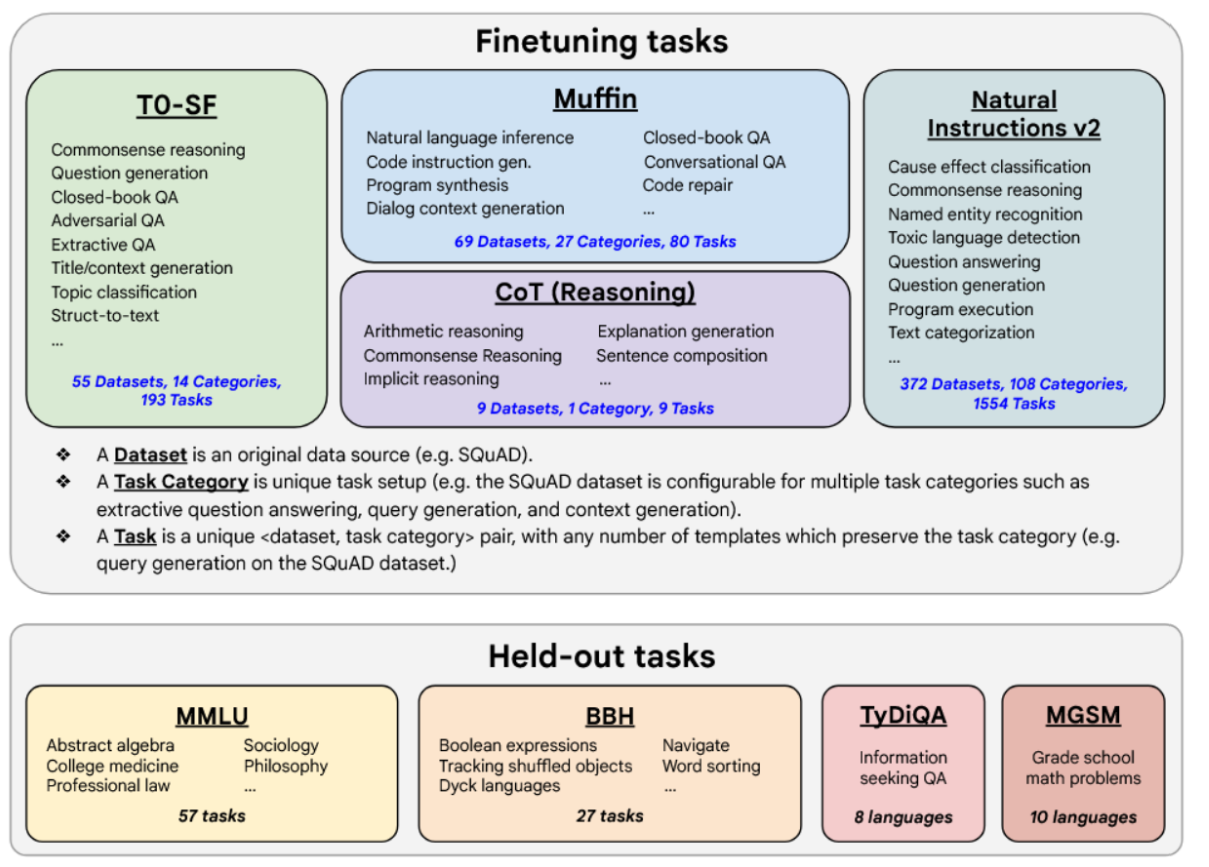
图14:Flan-PaLM微调包含上述任务类别中的473个数据集。承蒙[74]提供。
PaLM-2 [75] 是一款相较于其前代 PaLM 计算效率更高、具备更优多语言与推理能力的大语言模型。PaLM-2 采用多种目标混合进行训练。通过在英语、多语言及推理任务上的广泛评估表明,PaLM-2 在不同模型规模下均显著提升了其在下游任务上的性能,同时相比 PaLM 展现出更快、更高效的推理能力。
Med-PaLM [76] 是一款特定领域的 PaLM 模型,旨在为医学问题提供高质量答案。它通过指令提示调优在 PaLM 上进行了微调,这是一种使用少量示例就能将大语言模型适配到新领域的参数高效方法。尽管 Med-PaLM 在许多医疗保健任务上取得了非常令人鼓舞的成果,但其表现仍逊于人类临床医生。Med-PaLM 2 通过医学领域微调和集成提示技术改进了 Med-PaLM [77]。在 MedQA 数据集(即一个整合了涵盖专业医学考试、研究和消费者查询的六个现有开放问答数据集的基准)上,Med-PaLM 2 得分高达 86.5%,较 Med-PaLM 提升了超过 19%,并创造了新的最先进水平。
C. 其他代表性大型语言模型
除前文讨论的三大模型族外,还存在其他广受欢迎的大型语言模型。这些模型虽不属于上述任一体系,却取得了卓越性能,并推动了该领域的发展。本节将简要介绍这些大型语言模型。
FLAN:在文献[78]中,Wei等人探索了一种提升语言模型零样本学习能力的简单方法。他们研究表明,通过在由指令描述的数据集集合上对语言模型进行指令微调,能显著提升其在未见任务上的零样本性能。他们选取了一个1370亿参数的预训练语言模型,并在超过60个通过自然语言指令模板表述的NLP数据集上进行了指令微调。他们将这一经过指令微调的模型称为FLAN。图15对比了指令微调与“预训练-微调”及提示学习方法的差异。
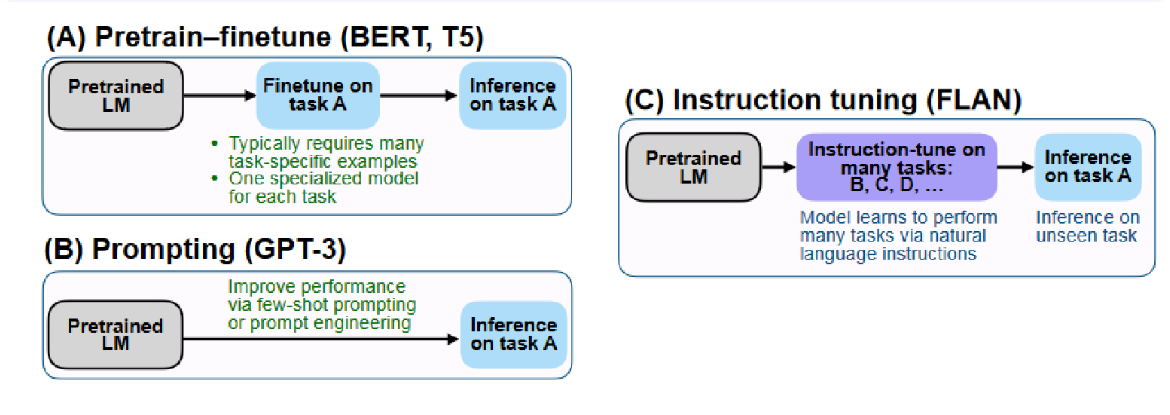
图15:指令调优与预训练-微调及提示方法的比较。由文献[78]提供。
在文献[79]中,Rae等人对基于Transformer的语言模型性能进行了跨规模分析——从参数规模数千万的模型到拥有2800亿参数、名为Gopher的模型。这些模型在152项多样化任务上进行了评估,并在绝大多数任务中实现了最先进的性能表现。不同规模模型的层数、键值大小及其他超参数详见图16。
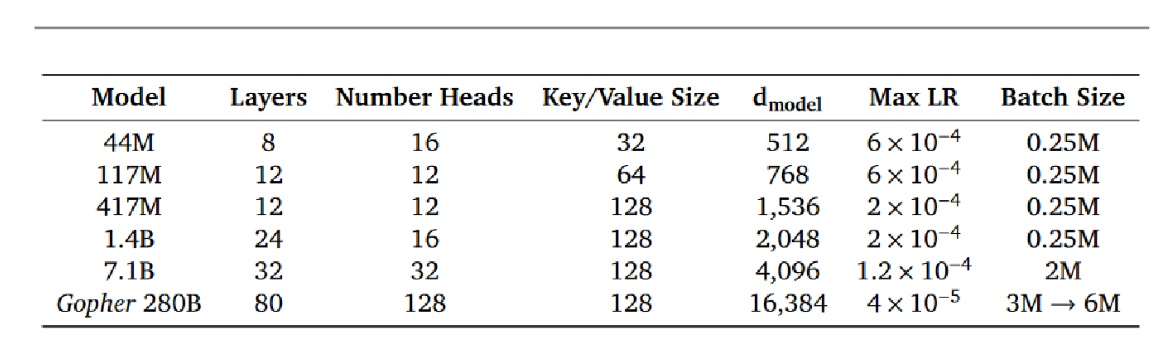
图16:不同参数规模的Gopher模型架构细节(承蒙[78]提供)。
T0:在文献[80]中,Sanh等人开发了T0系统,该系统能够轻松地将任何自然语言任务映射为人类可读的提示形式。他们通过转换大量有监督数据集每个数据集包含多种不同措辞的提示。这些经过提示处理的数据集可用于基准测试模型执行完全未见任务的能力。随后,开发了一个T0编码器-解码器模型,该模型接收文本输入并生成目标响应。该模型通过在多任务混合的自然语言处理数据集上进行训练,这些数据集被划分为不同的任务。
ERNIE 3.0:在文献[81]中,孙宇等人提出了一个名为ERNIE 3.0的统一框架,用于预训练大规模知识增强模型。该框架融合了自回归网络和自编码网络,使得训练后的模型能够通过零样本学习、少样本学习或微调,轻松适配自然语言理解与生成任务。他们使用包含纯文本和大规模知识图谱的4TB语料库,训练了参数量达100亿的ERNIE 3.0模型。图17展示了Ernie 3.0的模型架构。
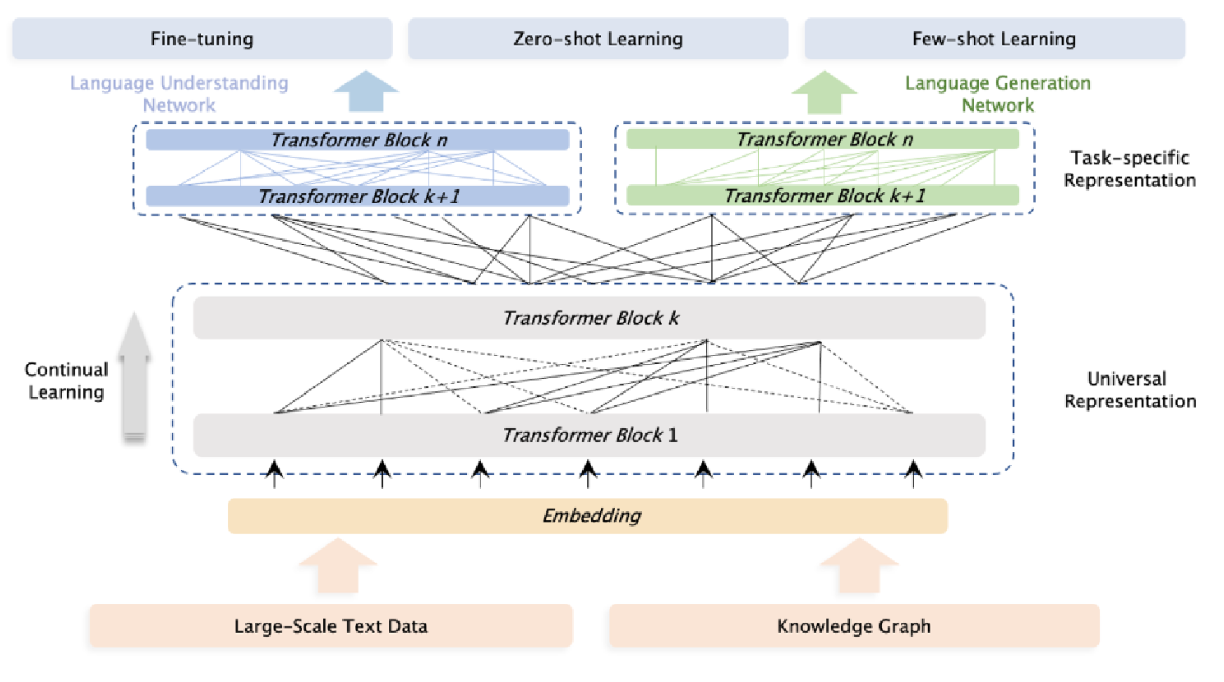
图 17:ERNIE 3.0 的高级模型架构。引自文献[81]。
RETRO模型:在文献[82]中,Borgeaud等人通过基于局部相似性从大规模语料库中检索文档片段作为条件,增强了自回归语言模型。利用一个包含2万亿词元的数据库,检索增强型变压器(Retro)在Pile基准测试中取得了与GPT-3和Jurassic-1[83]相当的性能,而参数数量减少了25%。如图18所示,Retro结合了一个冻结的Bert检索器、一个可微分编码器和一个分块交叉注意力机制,能够基于比常规训练多一个数量级的数据进行词元预测。
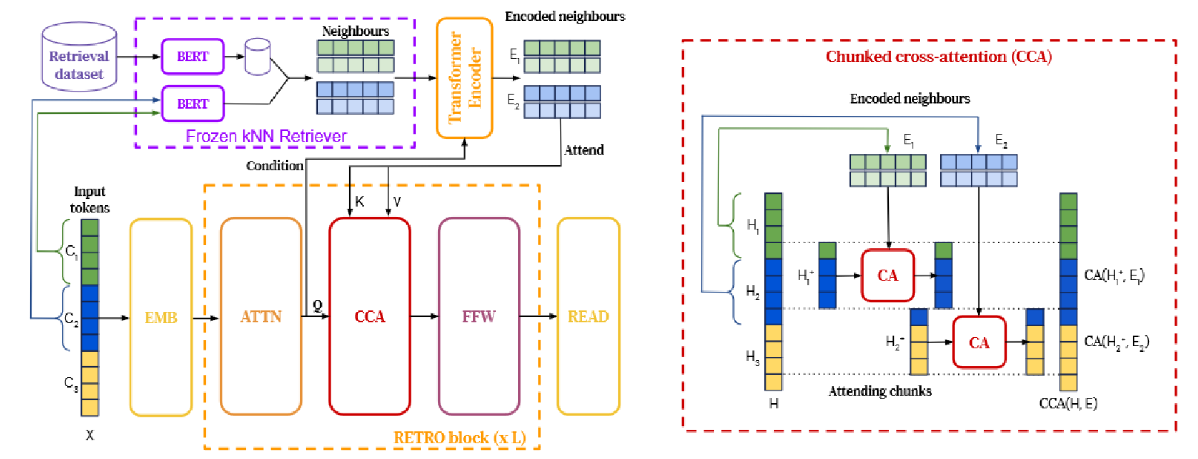
图18:检索增强型架构。左图:简化版本,其中长度为n=12的序列被分割为l=3个大小为m=4的块。对于每个块,我们检索k=2个邻居,每个邻居包含r=5个标记。检索路径显示在顶部。右图:CCA算子中的交互细节。因果性得以保持,因为第一个块的邻居仅影响第一个块的最后一个标记以及第二个块的标记。承蒙[82]提供。
GLaM:在文献[84]中,Du等人提出了一个名为GLaM(通用语言模型)的大型语言模型系列,该系列采用稀疏激活的混合专家架构以实现模型扩展。在保持模型容量的同时,相较于稠密模型变体显著降低了训练成本。规模最大的GLaM模型拥有1.2万亿参数,约为GPT-3的7倍。其训练能耗仅为GPT-3的三分之一,推理计算量减少一半,仍在29项NLP任务中实现了更优异的整体零样本、单样本及少样本性能。图19展示了GLAM的整体架构。
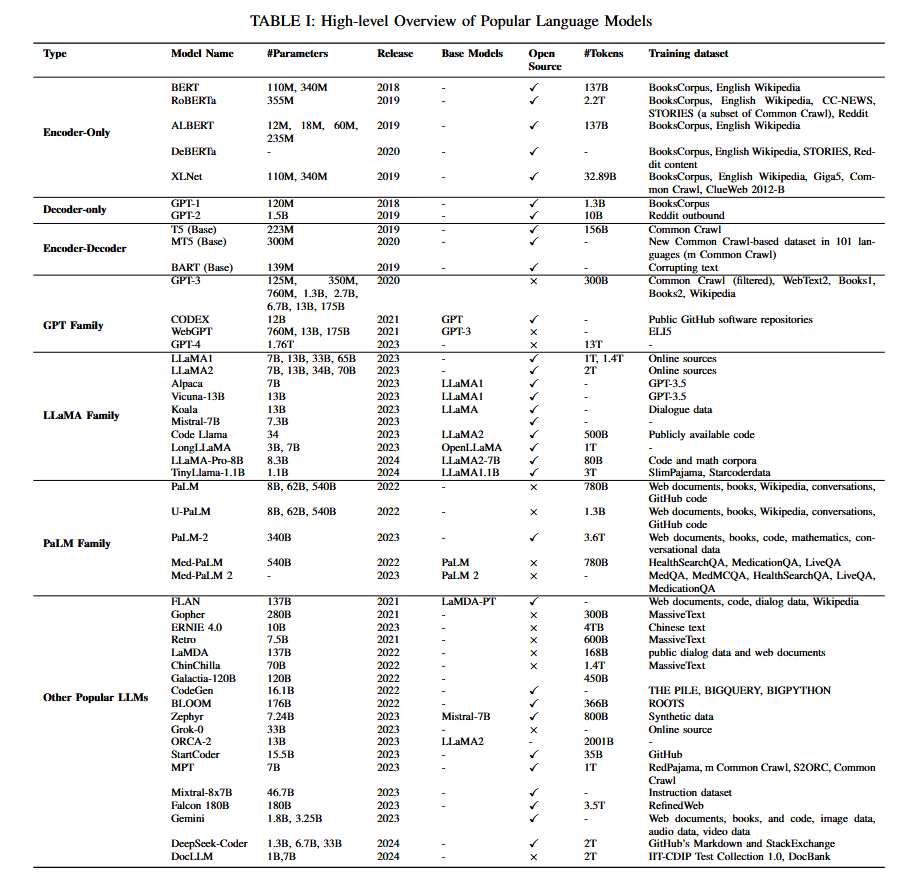
图26:Transformer工作原理高层次概览。由[44]提供。
LaMDA:在文献[85]中,Thoppilan等人提出了LaMDA,这是一个专为对话设计的、基于Transformer架构的神经语言模型系列,其参数量高达1370亿,并在1.56万亿词的公开对话数据及网络文本上进行了预训练。研究表明,通过带标注数据进行微调,并赋予模型查询外部知识源的能力,可在安全性和事实依据这两个关键挑战上取得显著改进。
在文献[86]中,张等人提出了开放预训练Transformer(OPT),这是一套参数量从1.25亿到1750亿不等的仅解码器预训练Transformer模型,并向研究人员公开。OPT模型的参数配置如表20所示。
图20:不同OPT模型架构细节。由文献[86]提供。
Chinchilla:文献[2]中,Hoffmann等人研究了在给定计算预算下训练Transformer语言模型的最优参数量与训练令牌数。通过训练超过400个语言模型(参数量从7000万到超过160亿,训练令牌数从50亿到5000亿),他们发现实现计算最优训练时,模型参数量与训练令牌数应等比例缩放:参数量每增加一倍,训练令牌数也需相应增加一倍。他们通过训练一个预测为计算最优的模型Chinchilla验证了这一假设。该模型与Gopher使用相同的计算预算,但采用700亿参数和额外多4%的数据进行训练。
Galactica:在文献[87]中,Taylor等人提出了Galactica,这是一个能够存储、整合并推理科学知识的大语言模型。该模型基于大规模科学语料进行训练,包括学术论文、参考资料、知识库及其他多种来源。Galactica在推理任务上表现优异,在数学MMLU测试中以41.3%的成绩超越Chinchilla的35.7%,并在MATH数据集上以20.4%的准确率显著优于PaLM 540B模型的8.8%。
CodeGen:Nijkamp等人在文献[88]中训练并发布了一个参数量高达161亿的大型语言模型家族CODEGEN,该模型基于自然语言和编程语言数据训练,并开源了训练库JAXFORMER。他们通过模型在HumanEval基准的零样本Python代码生成任务上达到与先前最优方法相当的性能,证明了其有效性。此外,作者深入研究了程序合成的多步骤范式,即将单个程序分解为多个指定子问题的提示。他们还构建了一个包含115个多样化问题集的多轮编程基准MTPB,其中每个问题集均被分解为多轮提示。
在[89]中,Soltan等人证明,基于去噪和因果语言建模(CLM)任务混合预训练的多语言大规模序列到序列(seq2seq)模型,在各种任务上比仅解码器模型是更高效的小样本学习器。他们训练了一个包含200亿参数的多语言seq2seq模型,称为Alexa教师模型(AlexaTM 20B),并证明其在单样本摘要任务上达到了最先进的性能,超过了参数量大得多的5400亿参数PaLM解码器模型。AlexaTM由46个编码器层、32个解码器层、32个注意力头组成,且dmodel = 4096。
麻雀:在文献[90]中,Glaese等人提出了Sparrow,一种旨在比基于提示的语言模型基线更有助、正确且无害的信息寻求对话代理。研究者采用人类反馈强化学习训练模型,并引入两项创新以协助人类评估员判断代理行为。Sparrow模型的高层流程如图21所示。
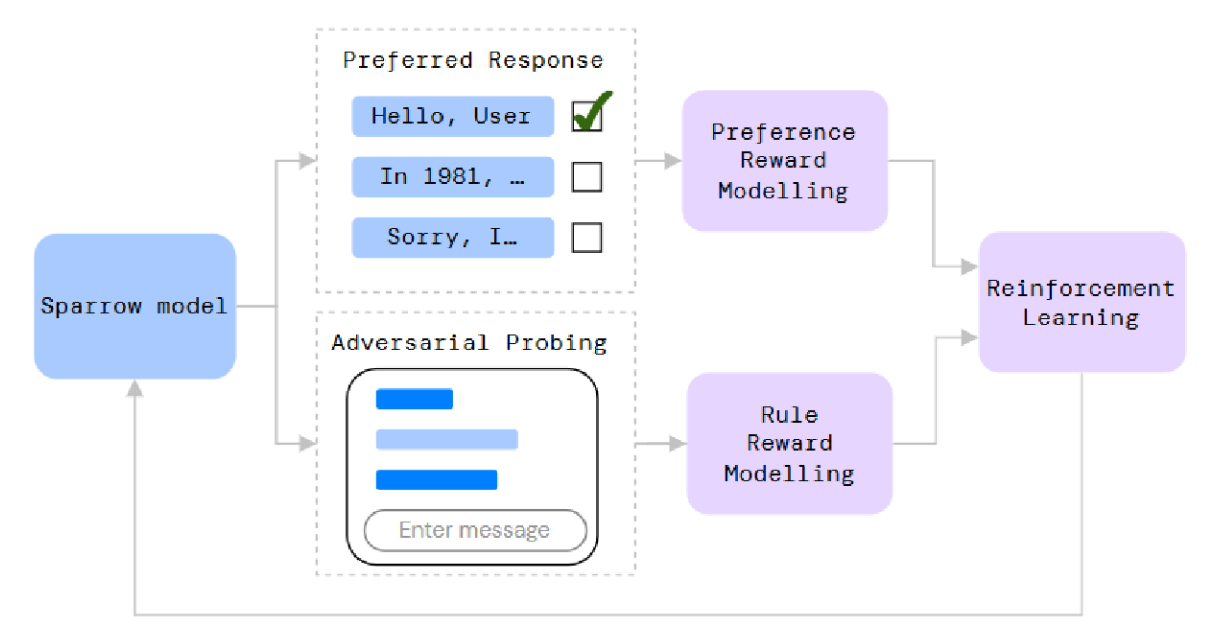
图21:Sparrow流程依赖人工参与以持续扩增训练集。承蒙[90]提供。
在[91]中,Lewkowycz等人提出了Minerva模型,这是一个在通用自然语言数据上预训练、并进一步在技术内容上训练的大型语言模型,旨在解决此前大型语言模型在定量推理(如解决数学、科学和工程问题)方面的不足。
MoD:在文献[92]中,Tay等人提出了一个用于自然语言处理自监督学习的广义统一视角,展示了不同预训练目标如何相互转化,以及在不同目标之间进行插值如何能有效提升性能。他们提出了混合去噪器(MoD),这是一种融合了多种预训练范式的预训练目标。该框架被称为统一语言学习(UL2)。图22展示了UL2预训练范式的概览。
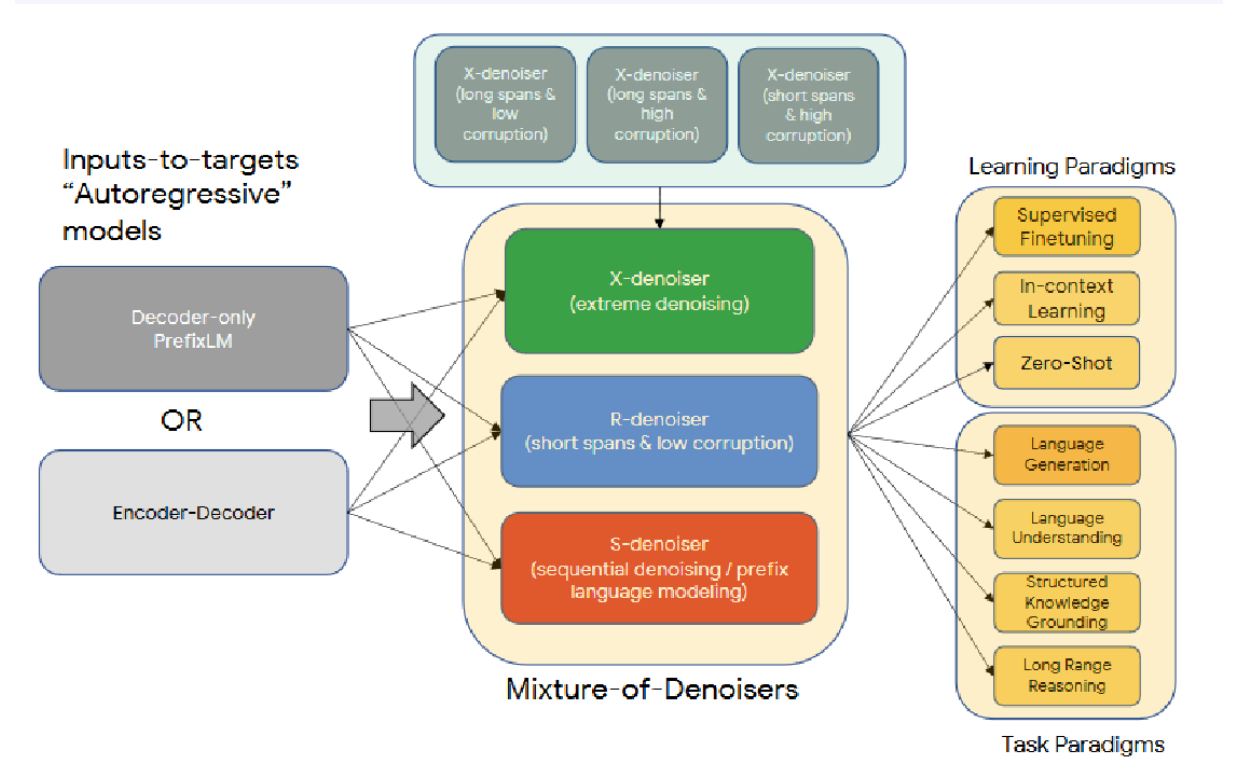
图22:UL2预训练范式概览。承蒙[92]提供。
在[93]中,Scao等人提出了BLOOM模型,这是一个拥有1760亿参数的开源语言模型,由数百名研究人员协作设计与构建。BLOOM是一个仅包含解码器的Transformer语言模型,基于ROOTS语料库进行训练,该数据集涵盖46种自然语言和13种编程语言(总计59种语言)的数百种数据源。图23展示了BLOOM架构的概览。
图23:BLOOM架构概览。由文献[93]提供。
在[94]中,Zeng等人提出了GLM-130B,这是一个拥有1300亿参数的双语(英文和中文)预训练语言模型。该研究旨在开源一个至少与GPT-3(davinci)性能相当的千亿规模模型,并揭示如何成功训练如此大规模模型的实践经验。
Pythia:在文献[95]中,Biderman等人提出了Pythia——一套包含16个大型语言模型的系列,所有模型均使用完全相同顺序的公开数据进行训练,参数量级涵盖从7000万到120亿。我们为这16个模型中的每一个均公开提供了154个检查点,同时发布了用于下载和重建其精确训练数据加载器的工具,以供进一步研究。
Orca:在文献[96]中,Mukherjee等人开发了Orca模型,这是一个拥有130亿参数的模型,其通过学习模仿大型基础模型的推理过程。Orca从GPT-4提供的丰富信号中学习,这些信号包括解释轨迹、逐步思维过程以及其他复杂指令,整个过程在ChatGPT的教师辅助指导下进行。
StarCoder:在文献[97]中,李等人提出了StarCoder和StarCoderBase模型。这是两个拥有155亿参数、支持8K上下文长度、具备代码填充能力,并利用多查询注意力机制实现快速大批次推理的模型。StarCoderBase基于“The Stack”数据集的一万亿标记进行训练,该数据集是一个包含大量经许可的GitHub代码库、附带检查工具与退出机制的大型集合。研究团队随后在350亿Python标记上对StarCoderBase进行微调,从而创建了StarCoder。他们实施了迄今为止对代码大语言模型最全面的评估,结果表明StarCoderBase在支持多编程语言的开放代码大语言模型中性能领先,并与OpenAI的code-cushman-001模型性能相当或更优。
KOSMOS:在文献[98]中,黄等人提出了KOSMOS-1,这是一个能够感知通用模态、进行上下文学习(即小样本学习)并遵循指令(即零样本学习)的多模态大语言模型(MLLM)。具体而言,他们基于网络规模的多模态语料库从头开始训练KOSMOS-1,这些语料包含任意交错的文本与图像、图像-标题配对以及纯文本数据。实验结果表明,KOSMOS-1在以下方面表现出色:(i)语言理解、生成,甚至无需OCR的自然语言处理(直接输入文档图像);(ii)感知-语言任务,包括多模态对话、图像描述、视觉问答;(iii)视觉任务,例如基于描述的图像识别(通过文本指令指定分类)。
Gemini:在文献[99]中,Gemini团队推出了一个全新的多模态模型家族,该系列模型在图像、音频、视频和文本理解方面展现出卓越的能力。Gemini家族包含三个版本:Ultra用于处理高度复杂的任务,Pro版本在增强性能和大规模部署能力方面表现突出,而Nano则专为设备端应用设计。Gemini架构基于Transformer解码器构建,并经过训练以支持32K的上下文长度(通过采用高效的注意力机制实现)。
其他一些流行的LLM框架(或用于高效开发LLM的技术)包括InnerMonologue [100]、Megatron-Turing NLG [101]、LongFormer [102]、OPT-IML [103]、MeTaLM [104]、Dromedary [105]、Palmyra [106]、Camel [107]、Yalm [108]、MPT [109]、ORCA2 [110]、Gorilla [67]、PAL [111]、Claude [112]、CodeGen 2 [113]、Zephyr [114]、Grok [115]、Qwen [116]、Mamba [30]、Mixtral-8x7B [117]、DocLLM [118]、DeepSeek-Coder [119]、FuseLLM-7B [120]、TinyLlama-1.1B [121]、LLaMA-Pro-8B [122]。
图24概述了一些最具代表性的大语言模型框架,以及推动大语言模型取得成功并不断突破其能力边界的相关研究成果。
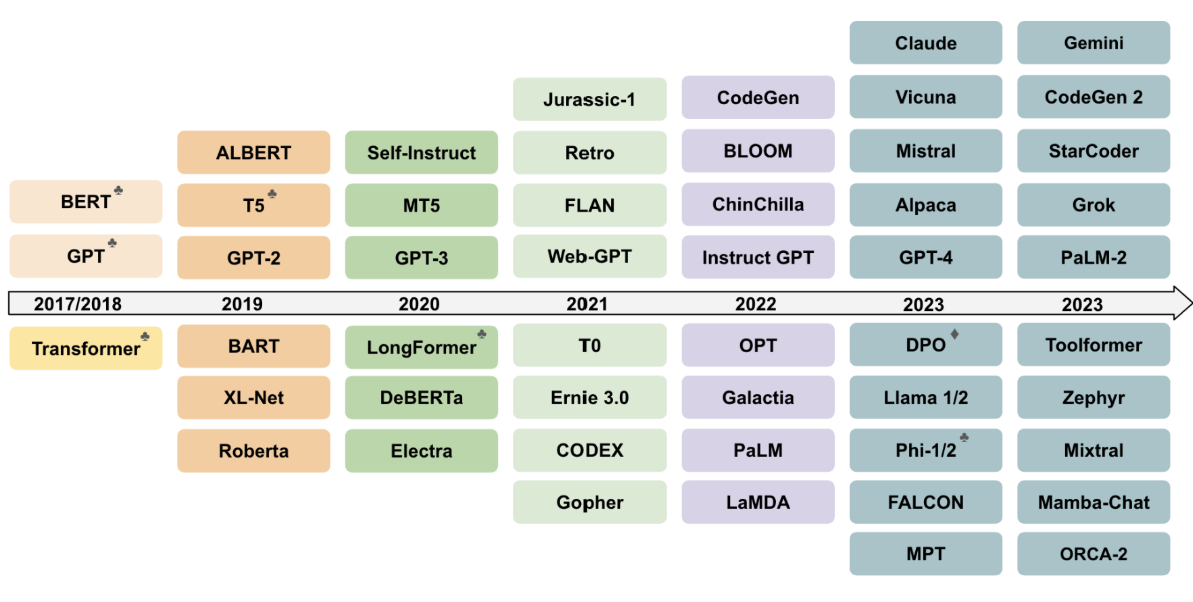
图24:迄今为止部分最具代表性的大型语言模型框架时间线。除达到我们#参数量阈值的大型语言模型外,我们还纳入了一些突破语言模型边界、为其成功铺平道路的代表性工作(如原始Transformer、BERT、GPT-1),以及部分小型语言模型。♣ 标注的实体不仅作为模型,同时也代表方法论;♦ 标注的则仅为方法论。
3.大型语言模型的构建原理
在本节中,我们首先回顾用于大语言模型的常见架构,随后讨论从数据准备、分词、到预训练、指令微调和对齐等一系列数据与建模技术。选定模型架构后,训练大语言模型的主要步骤包括:数据准备(收集、清洗、去重等)、分词、模型预训练(以自监督学习方式进行)、指令微调以及对齐。我们将在下文分别阐述每个步骤。这些步骤亦在图25中加以说明。
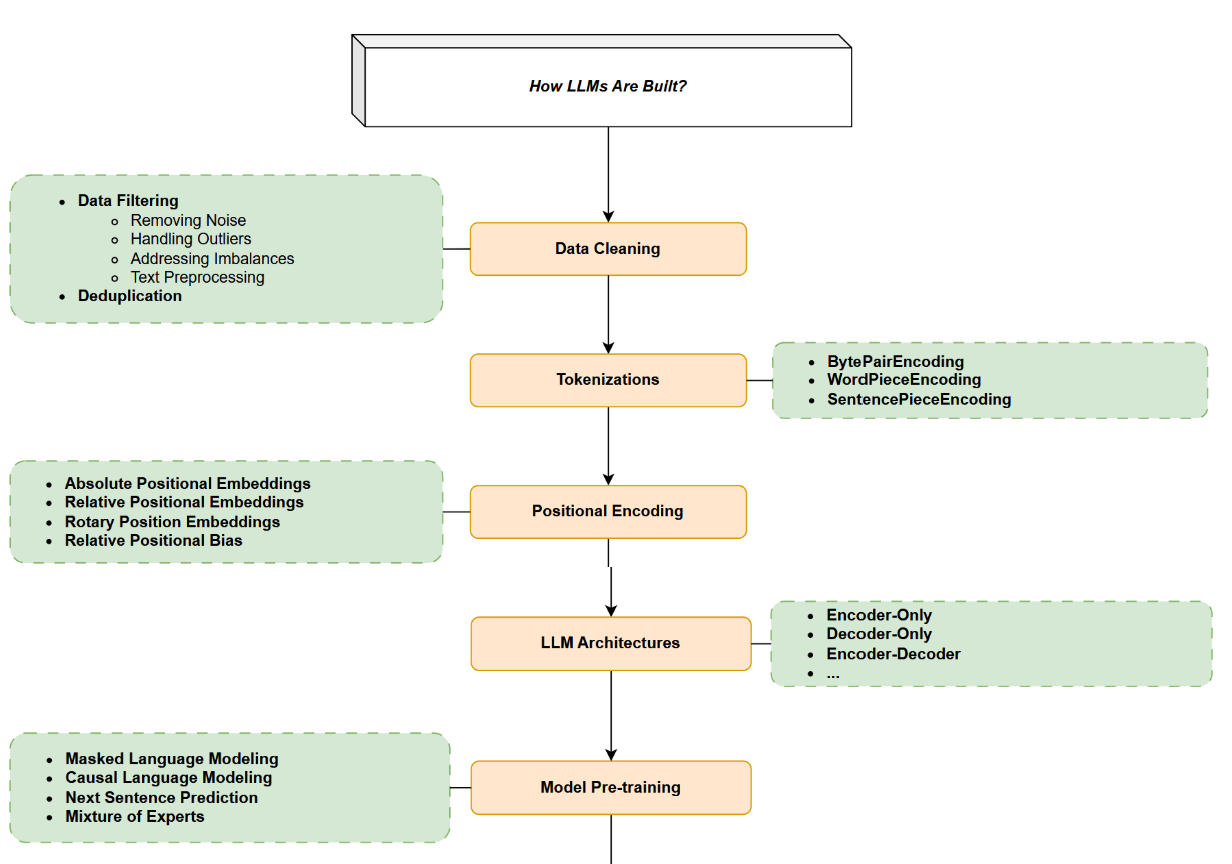
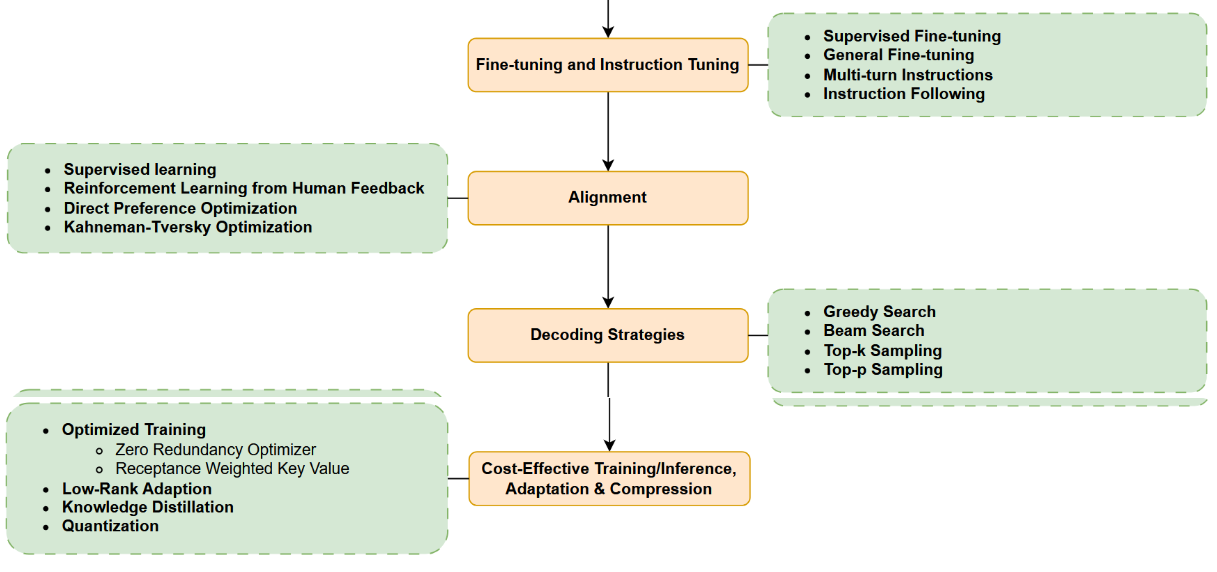
图25:本图展示了大型语言模型(LLMs)的不同组成部分。
A. 主流大语言模型架构
当前最主流的LLM架构包括仅编码器、仅解码器以及编码器-解码器三种。其中绝大多数都以Transformer作为基础构建模块。因此,我们在此也对Transformer架构进行回顾。
1)Transformer:在一项开创性工作中[44],Vaswani等人提出了Transformer框架,其最初设计旨在利用GPU进行高效并行计算。Transformer的核心是(自)注意力机制,该机制在使用GPU时,能比循环和卷积机制更有效地捕捉长期上下文信息。图26展示了Transformer工作流程的高层概览。本节我们将概述其主要组件与变体,更多细节请参阅文献[44]与[123]。
Transformer语言模型架构最初是为机器翻译任务提出的,由编码器和解码器构成。编码器由N=6个相同的Transformer层堆叠而成。每层包含两个子层:第一个是多头自注意力层,第二个是简单的位置前馈全连接网络。解码器同样由6个相同层堆叠而成。除包含编码器每层中的两个子层外,解码器包含第三子层,该层对编码器堆栈的输出执行多头注意力操作。注意力函数可描述为将查询和一组键值对映射到输出的过程,其中查询、键、值和输出均为向量。输出以值的加权和形式计算,每个值对应的权重通过查询与对应键的兼容性函数计算得到。研究发现,相较于使用d_model维度的键、值和查询执行单一注意力函数,采用不同且可学习的线性投影将查询、键和值分别线性映射到d_k、d_k和d_v维度更为有效。模型还引入了位置编码,以融合序列中标记的相对或绝对位置信息。
-
仅编码器架构:对于此类模型,在每一阶段,注意力层均可访问初始句子的所有词汇。其预训练通常包含对给定句子进行某种形式的破坏(例如,随机掩码其中的词汇),并让模型负责发现或重建原始句子。编码器模型非常适用于需要理解完整序列的任务,如句子分类、命名实体识别和抽取式问答。一个著名的仅编码器模型是BERT(基于Transformers的双向编码器表示),由文献[24]提出。
-
仅解码器架构:对于此类模型,在任何阶段,对于任意词语,其注意力层仅能访问该词语在句子中之前出现的位置信息。这类模型有时也被称为自回归模型。其预训练目标通常被设定为预测序列中的下一个词(或标记)。仅解码器模型最适用于文本生成类任务。GPT系列模型是该类别中的典型代表。
4)编码器-解码器模型:此类模型同时采用编码器和解码器结构,有时亦被称为序列到序列模型。在每一处理阶段,编码器的注意力层能够读取初始句子的全部词汇,而解码器的注意力层仅能访问输入序列中给定词汇之前的位置信息。这类模型通常采用编码器或解码器模型的预训练目标,但往往会涉及更为复杂的机制。例如,部分模型通过将随机文本片段(可能包含多个词汇)替换为单个特殊掩码词进行预训练,其训练目标在于预测该掩码词所替代的原始文本。编码器-解码器模型最适用于基于给定输入生成新句子的任务场景,例如文本摘要、机器翻译或生成式问答。
B. 数据清洗
数据质量对基于其训练的语言模型性能至关重要。过滤、去重等数据清洗技术已被证明对模型性能具有重大影响。例如在Falcon40B [124]中,Penedo等人证明仅通过适当过滤和去重的网络数据就能训练出强大的模型,其表现甚至显著优于基于最先进数据集The Pile训练的模型。尽管进行了广泛过滤,他们仍能从CommonCrawl获取五万亿词元的数据量。他们还发布了从我们的REFINEDWEB数据集中提取的6000亿个词元,以及基于此数据训练的13亿/75亿参数语言模型。图27展示了本工作对CommonCrawl数据的精炼处理过程。
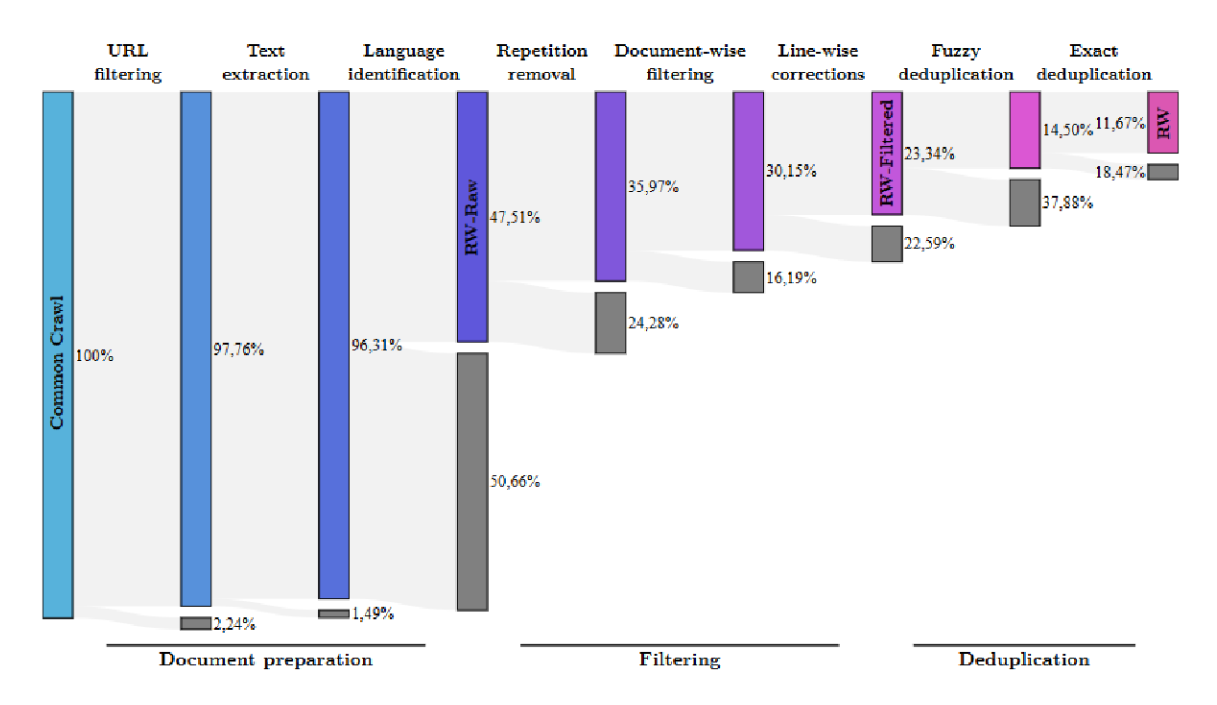
图27:宏数据精炼的后续阶段剔除了最初来自CommonCrawl的近90%文档。承蒙[124]惠允。
-
数据过滤:数据过滤旨在提升训练数据质量及大语言模型的训练效果。常用数据过滤技术包括:
噪声去除:指消除可能影响模型泛化能力的无关或噪声数据。例如,可从训练数据中移除虚假信息,以降低模型生成错误响应的概率。质量过滤的两类主流方法是基于分类器的框架和基于启发式的框架。
异常值处理:识别并处理数据中的异常值或离群点,防止其对模型产生过度影响。
平衡处理:均衡数据集中类别或范畴的分布,以避免偏见并确保公平表征。这对负责任的人工智能模型训练与评估尤为重要。
文本预处理:通过去除停用词、标点符号或其他对模型学习贡献不显著的元素,实现文本数据的清洗与标准化。
歧义处理:解决或排除训练过程中可能干扰模型的模糊或矛盾数据。这有助于模型提供更明确可靠的答案。 -
去重:去重是指移除数据集中重复实例或相同数据重复出现的过程。重复数据点可能在模型训练过程中引入偏差并降低多样性,因为模型可能多次从相同示例中学习,这可能导致对这些特定实例的过拟合。一些研究[125]表明,去重能提升模型对新未见数据的泛化能力。
去重处理在处理大型数据集时尤为重要,因为重复数据可能无意间夸大某些模式或特征的重要性。这在自然语言处理任务中尤为关键,因为多样化和具有代表性的训练数据对于构建鲁棒的语言模型至关重要。
具体的去重方法可根据数据特性和所训练语言模型的具体需求而有所不同,可能涉及比较完整数据点或特定特征以识别并消除重复项。在文档层面,现有工作主要依赖文档间高层特征(如n-元组重叠率)的重叠比例来检测重复样本。
C. 分词处理
标记化(Tokenization) 指将文本序列转换为更小单元(即标记)的过程。最简单的标记化工具仅依据空白字符将文本切分为标记,但大多数标记化工具依赖于一个词词典。然而,未登录词(Out-Of-Vocabulary, OOV)在这种情况下会成为一个问题,因为标记器仅识别其词典中的词汇。为提高词典的覆盖范围,目前用于大型语言模型的常用标记器基于子词(sub-words)构建,这些子词可以组合形成大量词汇,包括训练数据中未出现的词或不同语言的词。下文我们将介绍三种常用的标记器。
1)字节对编码:字节对编码最初是一种数据压缩算法,它利用字节层面的频繁模式来压缩数据。根据定义,该算法主要尝试保留高频单词的原始形态,并对不常见的单词进行拆分。这种简洁的范式使得词汇表不会过于庞大,同时又能充分表征常见词汇。此外,若算法的训练数据中也频繁出现后缀或前缀,则高频单词的形态变化也能得到很好的表示。
2)WordPiece编码:该算法主要用于BERT和Electra等知名模型。训练初始阶段,算法会提取训练数据中的所有字母字符,以确保训练数据集中不会出现UNK(未知标记)。这种情况通常发生在模型接收到分词器无法处理的输入时,多见于某些字符超出分词范围的情形。与字节对编码类似,该算法基于词频统计,致力于最大化所有词汇单元收入词表的概率。
- SentencePiece编码:尽管前述两种分词器性能强劲,相较于空白字符分词具有诸多优势,但它们仍默认词语始终由空白字符分隔。这一假设并非总是成立,事实上在某些语言中,词语可能受到多余空格甚至生造词等噪声元素的干扰。SentencePiece编码正是为解决这一问题而生。
D. 位置编码
绝对位置嵌入(Absolute Positional Embeddings, APE)[44] 最初在Transformer模型中被用于保留序列的顺序信息。具体而言,词的位置信息会被添加到编码器与解码器堆栈底部的输入嵌入中。位置编码有多种选择,可以是学习的,也可以是固定的。在原始Transformer中,采用了正弦和余弦函数来实现这一目的。在Transformer中使用APE的主要缺陷在于其只能处理特定数量的标记。此外,APE无法考虑标记之间的相对距离。
-
相对位置编码:相对位置编码通过扩展自注意力机制,使其能够考虑输入元素之间的成对关联关系。该编码在模型中分两个层级添加:首先作为键向量的附加成分,随后作为值矩阵的子成分。该方法将输入视为带有标签和定向边的全连接图。在线性序列中,这些边能够捕捉输入元素间相对位置差异的信息。通过设置截断距离(表示为 k 满足 2 ≤ k ≤ n − 4),可以限定相对位置的最大范围。这使得模型能够对训练数据中未出现过的序列长度进行合理预测。
-
旋转位置编码:旋转位置编码(RoPE)[127] 解决了现有方法的若干问题。学习到的绝对位置编码可能缺乏泛化能力与意义表达,尤其在句子较短时更为明显。此外,当前如T5的位置编码等方法在构建位置间的完整注意力矩阵时面临挑战。RoPE采用旋转矩阵对词的绝对位置进行编码,同时将明确的相对位置信息纳入自注意力机制中。RoPE带来了诸多有益特性,包括对句子长度的灵活适应性、随相对距离增加而减弱的词间依赖性,以及通过相对位置编码增强线性自注意力的能力。GPT-NeoX-20B、PaLM、CODEGEN和LLaMA等模型均在架构中采用了RoPE。
4)相对位置偏置:此类位置编码的设计理念旨在推理阶段实现对长于训练序列的文本外推。Press等人在文献[128]中提出的线性偏置注意力机制(ALiBi),并非简单地将位置嵌入与词嵌入相加,而是在查询-键对的注意力分数中引入了与两者距离成正比的惩罚性偏置。BLOOM模型采用了ALiBi技术。
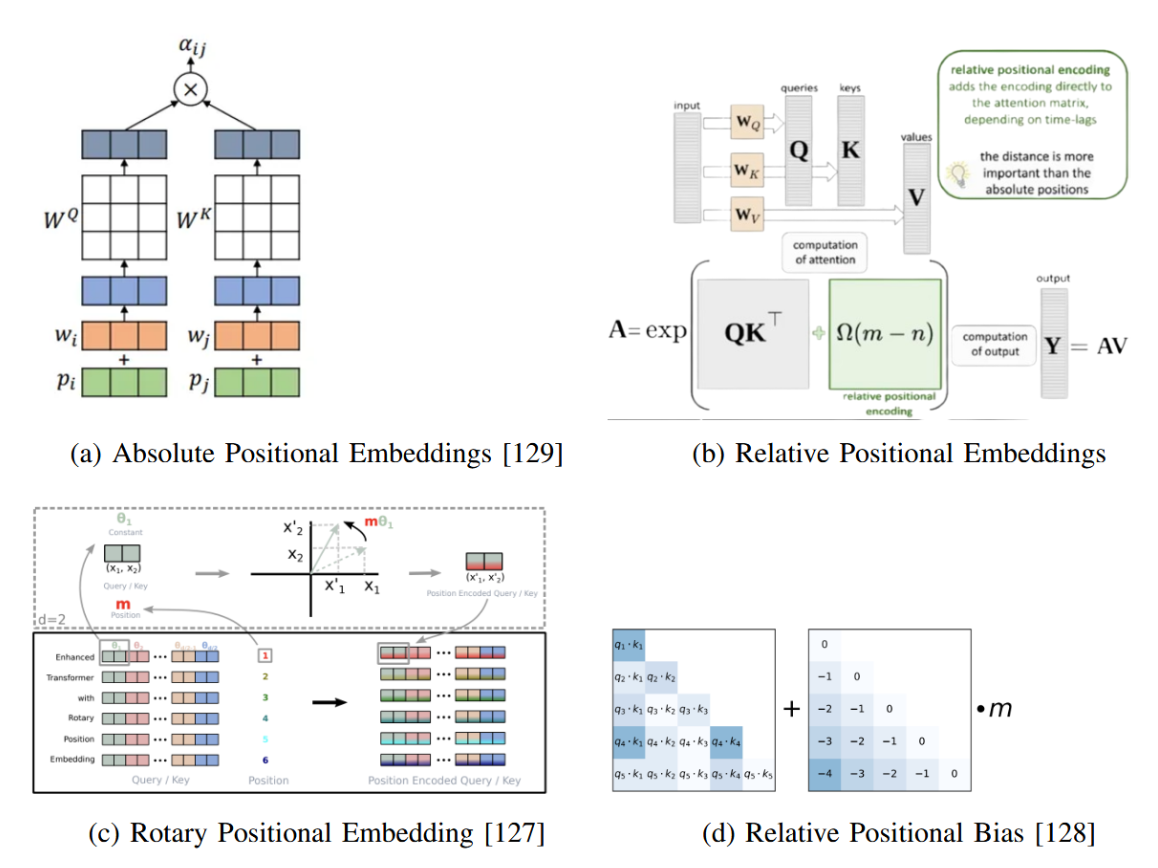
图28:大型语言模型中采用的各种位置编码方法。
E. 模型预训练
预训练是大型语言模型训练流程中的首要步骤,它帮助大语言模型获得基础的语言理解能力,这种能力可广泛应用于各类语言相关任务。预训练过程中,大语言模型通常在自监督学习方式下,基于海量(通常是无标注的)文本进行训练。预训练存在多种方法,例如下一句预测[24],其中两种最常用的方法是下一词预测(自回归语言建模)和掩码语言建模。
在自回归语言建模框架中,给定一个包含n个标记的序列x1, …, xn,模型以自回归的方式尝试预测下一个标记xn+1(有时是下一个标记序列)。此场景中一种常用的损失函数如公式2所示,即预测标记的对数似然。
L A L M ( x ) = ∑ i = 1 N p ( x i + n ∣ x i , . . . , x i + n − 1 ) ( 1 ) \mathscr{L}_{ALM}(x)=\sum_{i=1}^Np(x_{i+n}|x_i,...,x_{i+n-1})\mathrm{(1)} LALM(x)=i=1∑Np(xi+n∣xi,...,xi+n−1)(1)
鉴于该框架的自回归性质,仅解码器模型自然更适合学习完成此类任务的方法。
在掩码语言建模中,序列中的部分词汇被掩码遮盖,模型通过上下文语境来预测被掩码的词汇。这种方法有时也被称为去噪自编码。若将序列 x 中被掩码/破坏的样本记为 x ̃,则该方法的训练目标可表述为:
L M L M ( x ) = ∑ i = 1 N p ( x ~ ∣ x \ x ~ ) ( 2 ) \mathscr{L}_{MLM}(x)=\sum_{i=1}^Np(\tilde{x}|x\backslash\tilde{x})\mathrm{(2)} LMLM(x)=i=1∑Np(x~∣x\x~)(2)
近期,混合专家模型(MoE)[130]、[131]在大型语言模型领域也变得十分流行。MoE使得模型能够以远低于传统密集模型的计算量进行预训练,这意味着在相同的计算预算下,可以大幅扩展模型或数据集的规模。MoE主要由两个核心组件构成:稀疏MoE层,用于替代密集的前馈网络层,其包含一定数量(例如8个)的“专家”,每个专家本身是一个神经网络。在实践中,这些专家通常是前馈网络,但也可以是更复杂的网络结构;门控网络或路由器,其决定将哪些令牌发送给哪些专家。值得注意的是,一个令牌可以被发送给多个专家。如何将令牌路由至专家是使用MoE时需要做出的重要决策之一——路由器由可学习的参数组成,并与网络其余部分一同进行预训练。图29展示了MoE中使用的Switch Transformer编码器块的示意图。
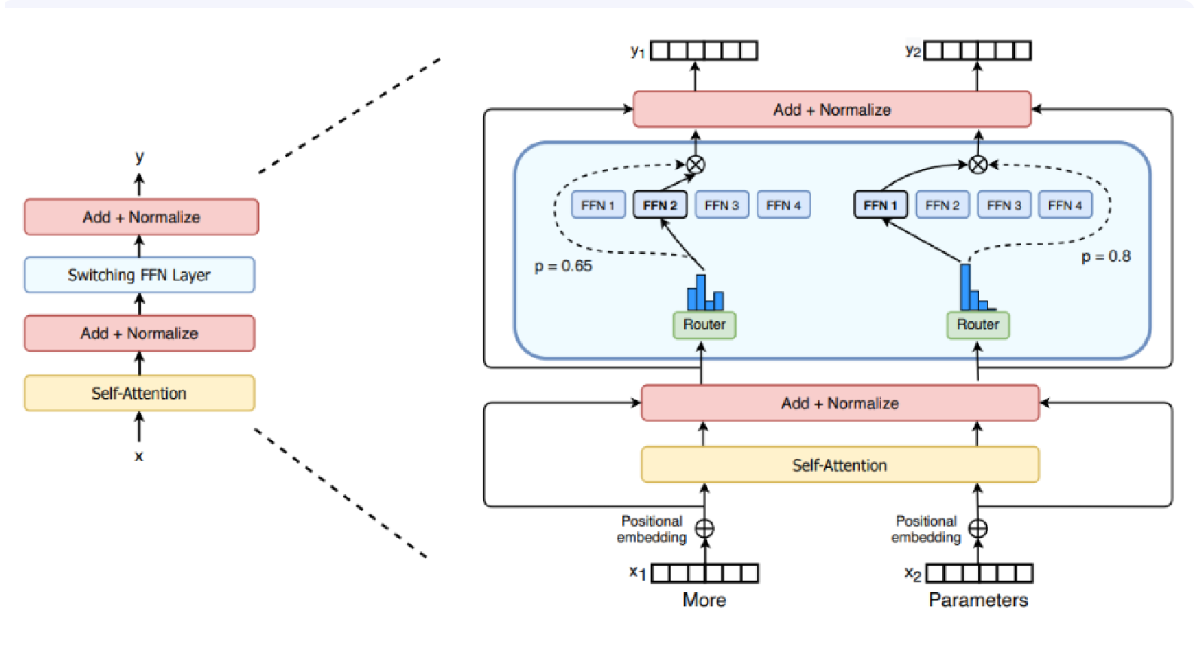
图29:Switch Transformer编码器模块示意图。该架构将Transformer中原有的密集前馈网络层替换为稀疏Switch前馈网络层(浅蓝色)。改编自文献[131]。
F. 微调与指令调优
早期基于自监督训练的语言模型(如BERT,其训练原理参见第III-E节)无法直接执行具体任务。为使基础模型具备实用价值,需使用标注数据针对特定任务进行微调(即所谓的有监督微调,简称SFT)。例如,在原始BERT论文[24]中,该模型被微调应用于11项不同任务。尽管近期的大型语言模型无需微调即可使用,但针对特定任务或数据的微调仍能提升其性能。例如,OpenAI报告显示,经过任务特定数据微调后,参数规模小得多的GPT-3.5 Turbo模型可以超越GPT-4的表现。
尽管微调不必针对单一任务进行,且存在多种多任务微调方法(例如参见Mahabi等人[132]的研究),但已知对一个或多个任务进行微调能够提升效果并降低提示工程的复杂度,同时可作为检索增强生成的替代方案。此外,选择微调还可能出于其他考量。例如,通过微调可使模型接触预训练阶段未涵盖的新数据或专有数据。
对大型语言模型进行微调的一个重要原因,是使其输出结果符合人类通过提示词下达指令时的预期。这就是所谓的指令微调[133]。我们将在第IV-B节详细探讨如何设计与构建提示词,但在指令微调的语境中,需要理解“指令”本身就是一种提示词,它明确了大型语言模型需要完成的任务。诸如Natural Instructions[134]这类指令微调数据集不仅包含任务定义,还包含其他组成部分,例如正/反例或需要避免的事项。
特定方法及指令数据集在不同指令调优过程中的应用存在差异,但一般而言,经过指令调优的模型表现优于其基础原始模型。例如,InstructGPT [59]在多数基准测试中超越了GPT-3。与此类似,相较于LLaMA,Alpaca [62]亦展现出更优性能。
由Wang等人提出的Self-Instruct方法[135]同样是这一方向上的一种流行方案。该方法引入了一个框架,通过引导预训练语言模型自身生成的数据,来提升其遵循指令的能力。其流程是:先从语言模型中生成指令、输入和输出样本,接着过滤掉无效或相似的样本,最后用这些数据对原始模型进行微调。
G. 对齐
人工智能对齐是引导AI系统符合人类目标、偏好与准则的过程。基于词汇预测任务预训练的大语言模型常展现出非预期的行为模式,例如可能生成具有毒性、危害性、误导性及偏见倾向的内容。
上文讨论的指令微调使大型语言模型朝着对齐目标更进了一步。然而在许多情况下,有必要引入后续步骤以进一步提升模型的对齐程度,避免非预期行为[3]。本小节将梳理目前主流的模型对齐方法。
强化学习人类反馈(RLHF)与强化学习AI反馈(RLAIF)是两种主流方法。RLHF利用奖励模型从人类反馈中学习对齐。该奖励模型经过微调后,能够根据人类给出的对齐偏好对不同输出进行评分。奖励模型向原始大语言模型提供反馈,并利用此反馈进一步微调大语言模型[137]。而强化学习AI反馈则直接将一个经过预训练且良好对齐的模型与大语言模型连接,帮助其从规模更大、对齐度更高的模型中学习[138]。
在另一项近期研究(称为DPO)[139]中,Rafailov等人指出RLHF是一种复杂且往往不稳定的过程,并尝试通过新方法解决该问题。他们利用奖励函数与最优策略之间的映射关系,证明这一带约束的奖励最大化问题可通过单阶段策略训练进行精确优化,其本质是在人类偏好数据上求解分类问题。由此产生的算法被他们命名为直接偏好优化(DPO),该算法稳定性强、性能优异且计算轻量,无需拟合奖励模型、在微调期间从语言模型采样或进行大量超参数调整。他们发现,使用DPO进行微调在生成内容的情感控制方面超越了RLHF,并提升了摘要任务中的响应质量。图30展示了DPO与RLHF的高层对比。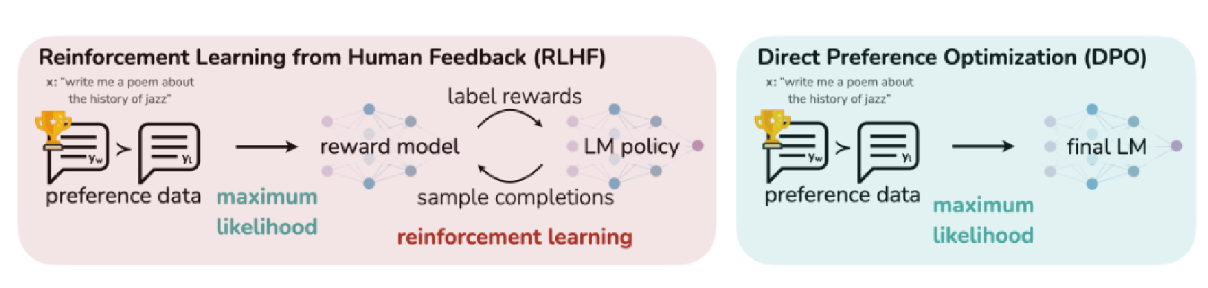
图30:DPO在优化人类偏好的同时避免了强化学习。现有基于人类反馈的微调方法首先将奖励模型拟合到提示数据集及人类对回答对的偏好数据上,随后使用强化学习寻找能最大化习得奖励的策略。与之相对,DPO通过简单的分类目标直接优化最满足偏好的策略,无需显式奖励函数或强化学习过程。据[139]。
最近,Ethayarajh等人提出了一种新的对齐方法,称为卡尼曼-特沃斯基优化(KTO)[136]。与现有的先进方法不同,KTO不需要成对的偏好数据(x, yw, yl),而仅需要(x, y)以及关于y是否理想的判断。研究表明,在1B至30B的规模上,尽管未使用成对偏好数据,KTO对齐模型的表现与DPO对齐模型相当或更优。KTO在实际应用中也远比偏好优化方法更易使用,因为它所需的数据类型要丰富得多。每家零售企业都拥有大量客户互动数据,并记录每次互动是否成功(例如完成购买)或不成功(例如未购买)。然而,它们基本没有或完全缺乏反事实数据(即,如何能使一次不成功的客户互动 y l y_l yl 转变为成功的互动 y w y_w yw)。图 31 展示了 KTO 与上文讨论的其他对齐方法之间的高层次比较。
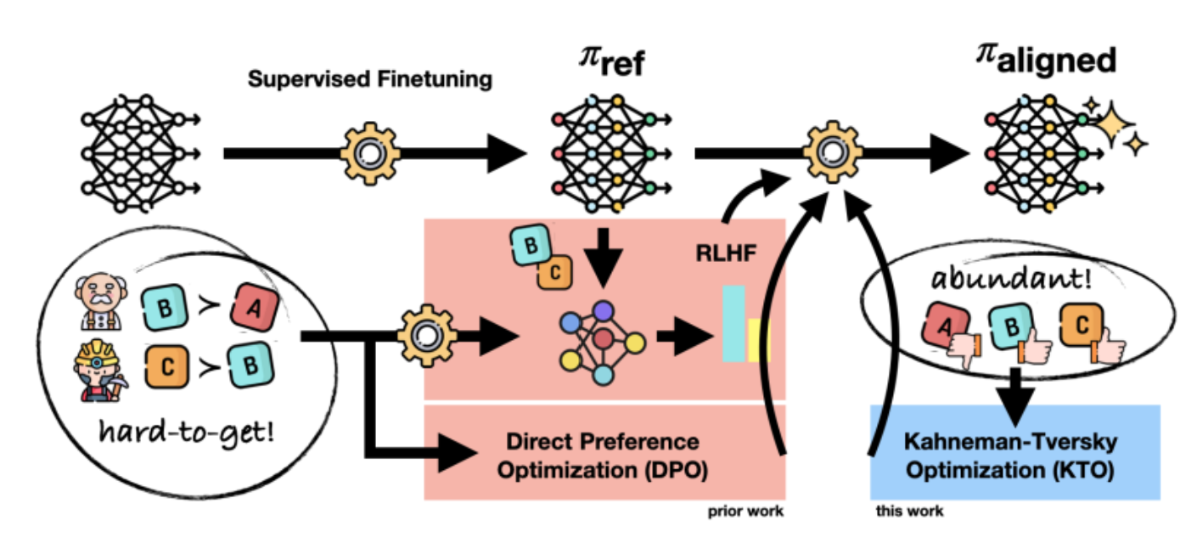
图31:大语言模型对齐通常包含监督微调和优化以人为中心的损失函数(HALO)两个步骤。然而,现有方法所需的配对偏好数据难以获取。相比之下,KTO所使用的数据类别要丰富得多,这使其在现实世界中应用起来更为便捷。图片承蒙文献[136]提供。
H. 解码策略
解码指使用预训练大语言模型进行文本生成的过程。给定输入提示,分词器将输入文本中的每个词元转换为对应的词元ID。随后,语言模型以这些词元ID作为输入,预测下一个最可能的词元(或词元序列)。最终模型生成逻辑值,并通过softmax函数转换为概率值。学界已提出多种解码策略,其中最常用的包括贪婪搜索、束搜索,以及不同的采样技术,如Top-K采样和Top-P采样(核心采样)。
- 贪婪搜索:贪婪搜索在每一步都将概率最高的词元作为序列中的下一个词元,并丢弃所有其他潜在选项。可以想象,这种方法虽然简单,但会严重损失时序一致性与连贯性。它仅考虑每一步的最概然词元,而忽略了该选择对序列整体的影响。这一特性使其速度较快,但也意味着它可能错失那些通过选择概率稍低的后续词元而产生的更优序列。
2)束搜索:与仅考虑下一个最可能标记的贪心搜索不同,束搜索会考虑N个最可能的标记,其中N表示束的数量。此过程会重复进行,直到达到预定义的最大序列长度或出现序列结束标记。此时,整体得分最高的标记序列(亦称“束”)将被选作输出。例如,当束大小为2且最大长度为5时,束搜索需要追踪2^5 = 32条可能序列。因此其计算强度高于贪心搜索。
3)Top-k采样:Top-k采样是一种利用语言模型生成的概率分布,从最可能的k个选项中随机选择标记的技术。
假设我们有六个标记(A、B、C、D、E、F)且 k=2,其中 P(A)=30%,P(B)=20%,P©=P(D)=P(E)=P(F)=12.5%。在 top-k 采样中,标记 C、D、E、F 被忽略,模型输出 A 的概率为 60%,输出 B 的概率为 40%。这种方法确保我们优先考虑概率最高的标记,同时在选择过程中引入随机性元素。
随机性通常通过温度的概念引入。温度T是一个介于0到1之间的参数,它会影响softmax函数生成的概率分布,使得最可能的词元更具影响力。实际应用中,只需将输入的logits除以温度值即可实现该效果
s o f t m a x ( x i ) = e x i / T ∑ j e x j / T softmax(x_i)=\frac{e^{x_i/T}}{\sum_je^{x_j/T}} softmax(xi)=∑jexj/Texi/T
较低的温度设定会显著改变概率分布(在文本生成中常用于控制生成输出的“创造性”水平),而较高的温度则会优先考虑概率较高的标记。Top-k是一种创造性的采样方式,可与束搜索结合使用。Top-k采样选择的序列可能并非束搜索中概率最高的序列。但必须记住,最高分数并不总是产生更真实或有意义的序列。
- Top-p采样:Top-p采样(亦称核心采样)与Top-k采数的处理方式略有不同。该方法并非固定选取概率最高的k个标记,而是设定一个截断概率值p,使得所选标记的概率之和超过p,从而形成一个可供随机抽取下一个标记的“核心”集合。具体而言,在Top-p采样中,语言模型会按概率降序遍历标记,并持续将标记加入候选列表,直至累计概率超过阈值p。可以设想,当Top-k标记集未能涵盖足够概率质量时,这种方法更具优势。与采样数量固定的Top-k采样不同,核心采样所涵盖的标记数量是动态可变的。这种特性通常能生成更多样化、更具创造性的文本输出,使得核心采样在文本生成任务中得到广泛应用。
I.具有成本效益的训练/推理/适配/压缩
在这一部分,我们回顾一些用于以更经济(且对计算更友好)的方式训练和使用大语言模型的流行方法。
- 优化训练:目前已有多种针对大语言模型优化训练的框架,以下介绍其中几个重要的方案。
ZeRO:在文献[140]中,Rajbhandari等人提出了一种新颖的解决方案——零冗余优化器(ZeRO),通过对内存进行优化,显著提升了大语言模型的训练速度,同时提高了可高效训练的模型规模。ZeRO消除了数据并行和模型并行训练中的内存冗余,同时保持了较低的通信开销和较高的计算粒度,使得模型规模能够与设备数量成比例扩展,并持续保持高效性。
RWKV:在文献[141]中,Peng等人提出了一种新颖的模型架构——Receptance加权键值(RWKV),该架构结合了Transformer的高效可并行训练特性与RNN的高效推理能力。该方法采用线性注意力机制,使得模型既能以Transformer形式表示,也能以RNN形式表示,从而在训练期间实现计算并行化,并在推理过程中保持恒定的计算和内存复杂度,由此成为首个可扩展至数百亿参数规模的非Transformer架构。RWKV架构如图32所示。RWKV与不同Transformer如图33所示。
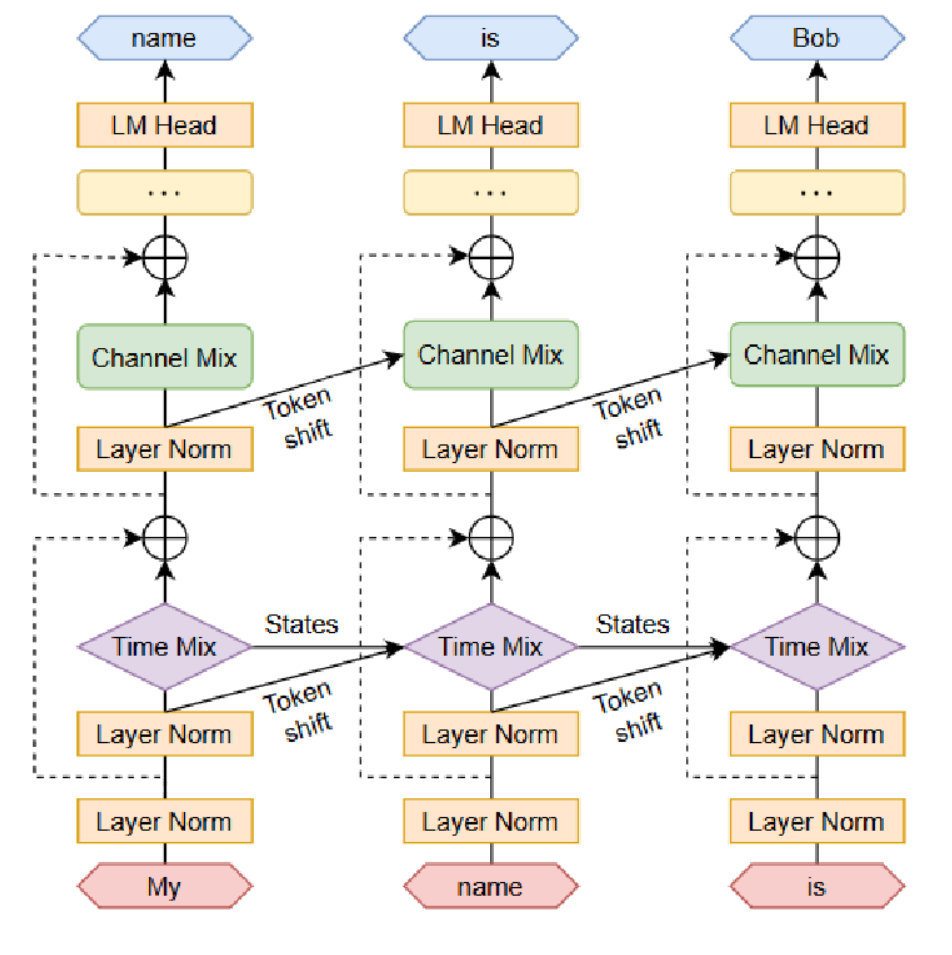
图32:RWKV架构。承蒙[141]提供。
图33:RWKV与各类Transformer架构的时间复杂度对比。其中T表示序列长度,d表示特征维度,c为MEGA模型二次注意力机制的块大小。数据来源:[141]。
- 低秩自适应(LoRA):低秩自适应是一种流行且轻量化的训练技术,能显著减少可训练参数量。其核心洞见在于,面向特定任务微调后的权重与初始预训练权重之间的差值通常表现出“低内在秩”特性——即该差值矩阵可通过一个低秩矩阵良好近似[142]。使用LoRA进行训练速度更快、内存效率更高,且生成的模型权重更小(仅数百MB),便于存储和共享。低秩矩阵的一个特性是其可表示为两个较小矩阵的乘积。这一认知引出了以下假设:微调权重与初始预训练权重间的差值矩阵,可表示为两个更小矩阵的矩阵乘积。通过专注于更新这两个小矩阵而非完整的原始权重矩阵,可大幅提升计算效率。
具体而言,对于预训练权重矩阵 W 0 ∈ R d × k W_0 ∈ R^{d×k} W0∈Rd×k,LoRA 通过低秩分解表示其更新量: W 0 + ∆ W = W 0 + B A W_0 + ∆W = W_0 + BA W0+∆W=W0+BA,其中 B ∈ R d × r B ∈ R^{d×r} B∈Rd×r , A ∈ R r × k A ∈ R^{r×k} A∈Rr×k,且秩 r ≪ m i n ( d , k ) r ≪ min(d, k) r≪min(d,k)。训练期间,W0 被冻结且不接收梯度更新,而 A 和 B 包含可训练参数。值得一提的是,W0 与 ∆ W = B A ∆W = BA ∆W=BA 均与相同输入相乘,它们各自的输出向量按坐标求和。对于 h = W 0 x h = W_0x h=W0x,其修改后的前向传播可表示为: h = W 0 x + ∆ W x = W 0 x + B A x h = W_0x + ∆W x = W0x + BAx h=W0x+∆Wx=W0x+BAx。通常,A 采用随机高斯初始化,B 采用零初始化,因此 ∆W = BA 在训练开始时为零。随后,他们将 ∆ W x ∆Wx ∆Wx 乘以 α / r α/r α/r,其中 α 是 r 中的常数。该重参数化过程如图 34 所示。
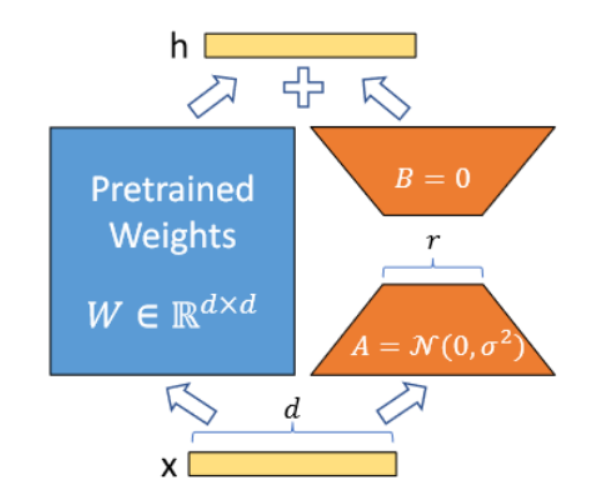
图34:LoRA重参数化示意图。此过程中仅训练矩阵A与B。[142]提供。
值得一提的是,LoRA可应用于神经网络中权重矩阵的子集,以减少可训练参数的数量。在Transformer架构中,自注意力模块包含四个权重矩阵(Wq、Wk、Wv、Wo),MLP模块包含两个。在大多数情况下,LoRA仅专注于调整注意力权重以适应下游任务,并冻结MLP模块,此举既出于简化考虑也为了提升参数效率,因此MLP模块在下游任务中不参与训练。
3)知识蒸馏:知识蒸馏是一种向更大模型学习的过程 [143]。早期最佳性能模型的发布已证明,即使采用API蒸馏方法,该技术也非常有效。该方法亦被称作一种将多个模型而非单一模型的知识提炼至较小模型的途径。通过此方法创建的小型模型具备更小的体积,甚至可部署于边缘设备使用。如图35所示的知识蒸馏技术,阐释了该训练方案的一般架构。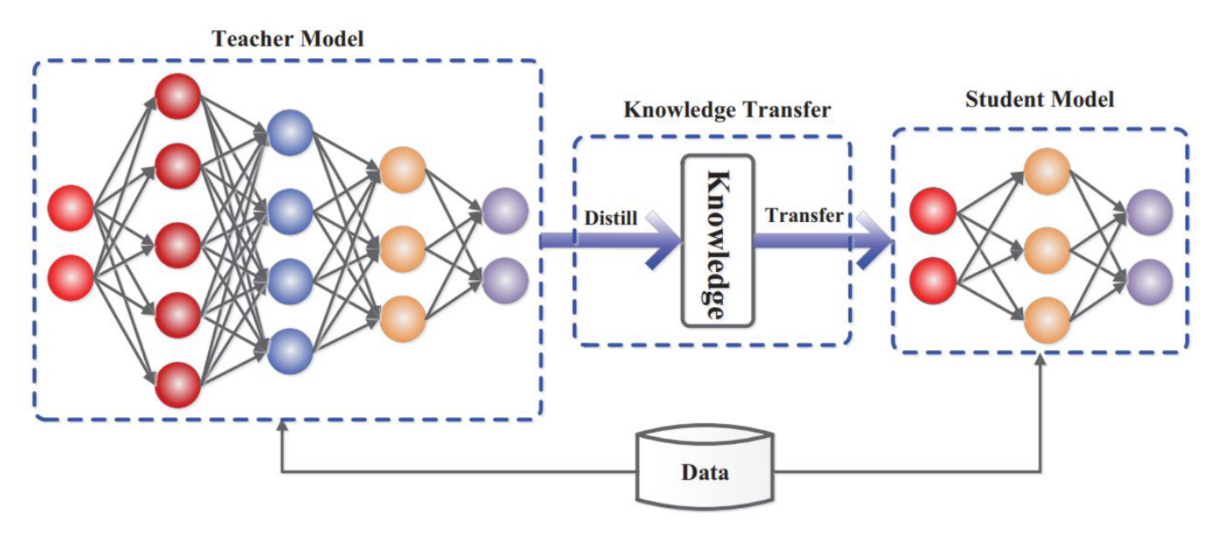
图35:包含学生模型与教师模型的通用知识蒸馏框架(引自[144])。
知识可通过不同学习形式进行迁移:响应蒸馏、特征蒸馏和API蒸馏。响应蒸馏仅关注教师模型的输出,试图教导学生模型如何完全或至少近似地复现教师模型的预测表现。特征蒸馏不仅使用最终层,同时利用中间层为学生模型构建更优的内部表征,这有助于较小模型获得与教师模型相似的表示能力。
API蒸馏是指利用API(通常来自LLM提供商如OpenAI)训练较小模型的过程。对于大型语言模型而言,该方法通过直接使用大模型的输出来训练模型,因此与响应蒸馏高度相似。这类蒸馏方式引发了许多担忧,因为当模型本身未公开时,终端用户接触的是(通常)需要付费的API接口。另一方面,尽管用户需为每次调用付费,其对预测结果的使用却受到限制——例如OpenAI禁止利用其API创建未来可能与其形成竞争关系的LLM。在此类场景中,核心价值在于训练数据本身。
4)量化:深度学习的核心是一组应用于矩阵的数学函数,其模型权重具有特定精度。降低权重精度可用于缩小模型规模并提升运算速度。例如,与Int-8运算相比,Float-32运算速度较慢。这一过程称为量化,可在不同阶段实施。主要模型量化方法可分为:训练后量化与量化感知训练。训练后量化通过两种常用方法处理已训练的模型:动态量化与静态量化。动态训练后量化在运行时计算量化范围,其速度低于静态量化。量化感知训练将量化准则融入训练过程,在训练期间直接对量化模型进行优化训练。该方法能保证最终模型性能良好,且无需在训练结束后再进行量化处理。
4.大语言模型的应用与增强路径
一旦大型语言模型完成训练,我们便可将其用于多种任务以生成所需输出。通过基础提示即可直接使用这些模型。然而,为充分发挥其潜力或解决某些缺陷,我们需要借助外部手段对模型进行增强。本节首先简要概述大型语言模型的主要不足,并深入探讨幻觉问题。随后阐述提示工程及若干增强方法如何不仅能应对这些局限,更能拓展大型语言模型的能力边界,甚至将其发展为具备与外部世界交互能力的完整人工智能体。
A. 大语言模型的局限性
必须牢记,大语言模型(LLM)的本质是训练用于预测词元。尽管微调和对齐能提升其表现并扩展其能力维度,但若使用方式过于简单,仍会暴露出一些重要的局限性。主要包括以下几点:
• 不具备状态/记忆能力。大语言模型自身无法记住先前提示中的内容,这对于许多需要某种状态维持的应用场景而言是一个重大限制。
• 具有随机性/概率性。若将相同提示多次发送给大语言模型,很可能得到不同的回应。尽管存在温度等参数可控制回答的波动性,但这是其训练固有的特性,可能引发问题。
• 信息存在滞后性,且无法自主访问外部数据。大语言模型本身甚至不知道当前时间或日期,也无法获取训练集之外的信息。
• 模型规模通常非常庞大。这意味着训练和部署需要大量昂贵的GPU机器。在某些情况下,最大型的模型服务等级协议(SLA)表现较差,尤其在延迟方面。
• 会产生幻觉。大语言模型没有“真相”的概念,且通常是在优劣混杂的内容中进行训练。它们可能生成看似合理但实则虚假的答案。
尽管上述局限在某些应用中均可能至关重要,我们仍有必要对最后一项——幻觉问题——进行稍深入的探讨。过去数月间,这一问题已引发广泛关注,并催生了我们后续将介绍的诸多提示策略与大语言模型增强方法。
幻觉:在大语言模型领域,“幻觉"现象已受到广泛关注。根据文献定义,特别是在《自然语言生成中的幻觉研究综述》论文[145]中,大语言模型的幻觉被描述为"生成无意义或与提供源内容不符的文本”。该术语虽源于心理学领域,现已被人工智能学界所采纳。
大语言模型的幻觉可大致分为两类:
- 内在幻觉:这类幻觉与源材料直接冲突,引入了事实性错误或逻辑矛盾。
- 外在幻觉:这类幻觉虽不与源材料矛盾,但无法从中得到验证,包含推测性或无法确认的内容。
在大语言模型语境中,“源”的定义随任务类型而异。在对话型任务中,它指代“世界知识”;而在文本摘要任务中,则指向输入文本本身。这一区分对于评估和解读幻觉现象至关重要。幻觉的影响同样高度依赖具体语境。例如,在诗歌创作等创造性活动中,幻觉可能被视为可接受的,甚至是有益的。
基于互联网、书籍、维基百科等多源数据训练的大型语言模型,其文本生成依赖于概率模型,并不具备对真实性或虚假性的内在理解。尽管近期出现了指令微调、基于人类反馈的强化学习等进展,试图引导大型语言模型产生更符合事实的输出,但其基础的概率模型本质及其固有局限性依然存在。近期研究《大型语言模型在推理任务中的幻觉来源》[146] 指出,导致大型语言模型产生幻觉的两个关键因素:真实性先验与相对频率启发式,这凸显了大型语言模型训练与输出生成过程中固有的复杂性。
对大语言模型中幻觉现象的有效自动化测量需要结合统计指标与基于模型的指标。统计指标方面:
• ROUGE [147] 和 BLEU [148] 等常见指标用于评估文本相似性,主要关注内在幻觉。
• 当具备结构化知识源时,则采用如 PARENT [149]、PARENTT [150] 和 Knowledge F1 [151] 等更先进的指标。虽然有效的各项指标在捕捉句法和语义的细微差别方面存在局限性。
基于模型的度量指标:
• 基于信息抽取的度量指标:利用信息抽取模型将知识简化为关系元组,随后与源内容进行比对。
• 基于问答的度量指标:通过问答框架评估生成内容与源内容之间的重叠度(参见[152])。
• 基于自然语言推理的度量指标:使用自然语言推理数据集,依据给定前提评估生成假设的真实性(参见[153])。
• 真实性分类度量指标:通过构建任务特定数据集以进行精细化评估,从而提供更精确的判断(参见[154])。
尽管自动化指标有所进展,人类判断仍是关键环节。其通常采用两种方法论:
1)评分法:评估者依据预定量表对幻觉程度进行量化评分。
2)对比分析法:评估者将生成内容与基线或真实参照进行比对,从而引入关键的主观评估维度。
FactScore [155] 是近期一种可用于人工与模型评估的指标实例。该指标将大语言模型的生成内容分解为“原子事实”,最终得分通过计算每个原子事实准确性的总和得出,各原子事实权重相等。准确性为二进制数值,仅表示原子事实是否得到源材料支持。作者通过多种自动化策略,利用大语言模型对这一指标进行估算。
最后,缓解大语言模型的幻觉问题是一项多方面的挑战,需要针对不同应用采取定制化策略。这些策略包括:
• 产品设计与用户交互策略。例如用例设计、输入/输出结构设计,或提供用户反馈机制。
• 数据管理与持续改进。维护并分析一组用于追踪的幻觉案例集,对于模型的持续改进至关重要。
• 提示工程与元提示设计。如第四部分B节所述的检索增强生成等许多高级提示技术,可直接应对幻觉风险。
• 针对幻觉缓解的模型选择与配置。例如,采用较低温度参数设置的大型模型通常表现更佳。此外,诸如基于人类反馈的强化学习或领域特定微调等技术也能降低幻觉风险。
B. 大语言模型应用:提示词设计与工程
在生成式人工智能模型中,提示词是用户为引导模型输出而提供的文本输入。其形式可涵盖从简单问题到详细描述或具体任务。提示词通常包含指令、问题、输入数据和示例。实践中,为从AI模型中获得期望的响应,提示词必须包含指令或问题,其他元素则为可选。高级提示词涉及更复杂的结构,例如“思维链”提示,即引导模型遵循逻辑推理过程以得出答案。
提示工程是一门快速发展的学科,旨在塑造大语言模型及其他生成式人工智能模型的交互方式与输出结果。其核心在于通过精心设计最优提示,以达成生成模型在特定目标下的预期效果。这一过程不仅涉及对模型的指令传达,还需要理解模型的能力边界、运作限制及其所处的应用语境。
提示工程超越了简单的提示构建;它需要融合领域知识、对AI模型的理解以及系统化的方法,以便针对不同情境定制提示。这可能涉及创建可根据给定数据集或语境进行程序化修改的模板。例如,基于用户数据生成个性化回复时,可能会使用能动态填入相关用户信息的模板。
此外,提示工程是一个迭代且探索性的过程,类似于传统的机器学习实践(如模型评估或超参数调优)。该领域的快速发展表明其有潜力革新机器学习的某些方面,超越特征工程或架构工程等传统方法。另一方面,版本控制和回归测试等传统工程实践需要适应这一新范式,正如它们曾适应其他机器学习方法一样[156]。
下文我们将详细阐述一些最富趣味且广受欢迎的提示工程技术方法。
1)思维链:思维链技术最初由谷歌研究者在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》[34]中提出,代表了大语言模型提示工程领域的关键进展。该方法的核心理念在于认识到,大语言模型虽擅长于标记预测,但其设计初衷并非进行显式推理。思维链技术通过引导模型逐步完成关键的推理步骤,从而解决了这一问题。
思维链技术的核心在于将大语言模型的隐性推理过程显性化。通过明确推理所需的步骤,该技术引导模型更接近逻辑严谨的推理结果,尤其在那些需要超越简单信息检索或模式识别的复杂场景中,这一优势尤为显著。思维链技术的核心在于将大语言模型的隐性推理过程显性化。通过明确推理所需的步骤,该技术引导模型更接近逻辑严谨的推理结果,尤其在那些需要超越简单信息检索或模式识别的复杂场景中,这一优势尤为显著。
CoT提示主要呈现为两种形式:
- 零样本思维链:通过指示大语言模型“逐步思考”,促使其拆解问题并阐明每个推理阶段。
- 人工思维链:作为更复杂的变体,需提供逐步推理示例作为模型模板。虽然能产生更有效的成果,但其可扩展性和可维护性方面存在挑战。
人工思维链提示方法比零样本提示更有效。然而,这类基于示例的思维链效果取决于所选示例的多样性,而手动构建包含此类逐步推理示例的提示既困难又容易出错。这正是自动思维链方法[157]发挥作用之处。
2)思维树(ToT):思维树(Tree of Thought, ToT)[158]提示技术源于一种理念,即先考虑多种备选解决方案或思维过程,再收敛至最合理的一种。ToT基于“思维树”分支扩散的思想,其中每个分支代表不同的推理路径。该方法使大语言模型能够探索多种可能性与假设,类似于人类在确定最可能情境前会权衡多重场景的认知过程。
思维链(ToT)方法的关键在于对这些推理路径的评估。当大语言模型生成不同的思维分支时,每个分支的有效性及其与查询的相关性都会得到评估。此过程涉及对各分支进行实时分析与比较,从而筛选出最连贯、最合乎逻辑的结果。
ToT(思维树)在单一推理路径可能不足的复杂问题解决场景中尤为有效。它使大语言模型能够模拟更接近人类的问题解决方式,在得出结论前综合考虑多种可能性。该技术增强了模型处理模糊性、复杂性和精细化任务的能力,使其成为高级人工智能应用中的宝贵工具。
3)自洽性:自洽性方法[159]采用基于集成学习的策略,通过提示大语言模型对同一查询生成多个回应。这些回应之间的一致性可作为其准确性与可靠性的衡量指标。
Self-Consistency(自我一致性)方法基于一个核心原则:若大型语言模型对同一提示生成多个相似的回应,则该回应正确的可能性更高。该方法要求模型多次处理同一查询,并逐次分析回应的一致性。在那些对事实准确性与精确性要求极高的应用场景中,此技术尤为有效。
响应一致性可通过多种方法进行测量。常见做法之一是分析回复内容的重复率,其他方法包括比较回复间的语义相似度,或采用更复杂的技术,如BERT分数或n-gram重叠分析。这些度量手段有助于量化大语言模型生成回复之间的共识程度。
自我一致性在信息真实性至关重要的领域具有重要应用。该方法尤其适用于事实核查等场景,确保人工智能模型提供信息的准确性至关重要。通过运用此技术,提示工程师能够增强大语言模型的可信度,使其在需要高事实准确度的任务中更为可靠。
- 反思:反思[160]是指引导大语言模型基于对自身答案正确性与连贯性的推理,对其输出进行评估并可能进行修正。这一概念的核心在于大语言模型进行自我评估的能力。在生成初始回答后,模型被引导去反思其输出,考量事实准确性、逻辑一致性和相关性等因素。这种内省过程能够促成修订版或改进版回答的生成。
反思机制的一个核心要素,在于大型语言模型所具备的自我修正能力。通过评估其初始生成的回答,模型能够识别潜在的错误或可改进之处。这种生成、反思、修订的迭代过程,使大型语言模型得以持续优化其输出,从而提升回答的整体质量与可靠性。
5)专家提示法:专家提示法[161]通过模拟各领域专家的回答方式来增强大语言模型(LLM)的能力。该方法通过提示大语言模型扮演专家角色并据此回应,从而提供高质量、信息充分的答案。专家提示法中的一项关键策略是多专家协同法。该策略提示大语言模型从多位专家的视角思考问题,随后综合这些观点形成全面而均衡的回答。此技术不仅增强了回应的深度,还融合了多元观点,体现出对主题更全面的理解。
-
链条:链条指的是将多个组件按顺序连接,以处理大型语言模型(LLM)复杂任务的方法。该方法涉及创建一系列相互关联的步骤或流程,每个步骤都对最终结果有所贡献。链条的概念基于构建一种工作流的理念,其中不同的阶段或组件被按序排列。链条中的每个组件执行特定功能,且其输出作为下一个组件的输入。这种端到端的编排允许进行更复杂、更细致的处理,因为每个阶段都可以针对任务的特定方面进行定制。链条的复杂性和结构可根据需求而变化。在《PromptChainer:通过可视化编程链式调用大型语言模型提示》[162]中,作者不仅描述了设计链条时面临的主要挑战,还介绍了一款支持此类任务的可视化工具。
-
Rails(约束框架):在高级提示工程中,Rails指的是一种通过预定义规则或模板来引导和控制大语言模型输出的方法。该方法旨在确保模型的响应符合特定标准或准则,从而提升输出的相关性、安全性和准确性。Rails的核心概念在于建立一个框架或一套指导原则,大语言模型在生成响应时必须遵循这些约束。这些准则通常通过一种称为"规范形式"的建模语言或模板来定义,从而实现自然语言句子结构与表达方式的标准化。
根据应用程序的具体需求,导轨可设计用于不同目的:
• 主题导轨:确保大语言模型严格遵循特定主题或领域。
• 事实核查导轨:旨在减少生成虚假或误导性信息。
• 越狱防护导轨:防止大语言模型生成试图规避其自身操作限制或准则的回应。
- 自动提示工程 (APE):自动提示工程 (APE) [163] 专注于自动化大型语言模型 (LLMs) 的提示创建过程。APE旨在简化和优化提示设计流程,利用LLM自身的能力来生成和评估提示。APE涉及以自我参照的方式使用LLM,即利用模型本身来生成、评分和优化提示。这种对LLM的递归使用能够生成更高质量的提示,从而更有可能引导出预期的响应或结果。
APE(自动化提示工程)的方法论可分解为若干关键步骤:
• 提示生成:大型语言模型根据给定任务或目标生成一系列可能的提示。
• 提示评分:基于清晰度、特异性及引发预期回复的可能性等标准,对每个生成的提示进行效果评估。
• 优化迭代:根据评估结果对提示进行优化与迭代,持续提升其质量与有效性。
C. 通过外部知识增强大型语言模型——检索增强生成
预训练大型语言模型的主要局限之一在于其缺乏最新知识或无法获取私有及特定用例信息。检索增强生成技术正是在此背景下应运而生[164]。如图37所示,RAG通过从输入提示中提取查询指令,利用该查询从外部知识源(如搜索引擎或知识图谱,见图38)检索相关信息。随后将相关信息附加至原始提示并输入大型语言模型,最终生成回答。RAG系统包含三个核心组件:检索模块、增强模块与生成模块[165]。
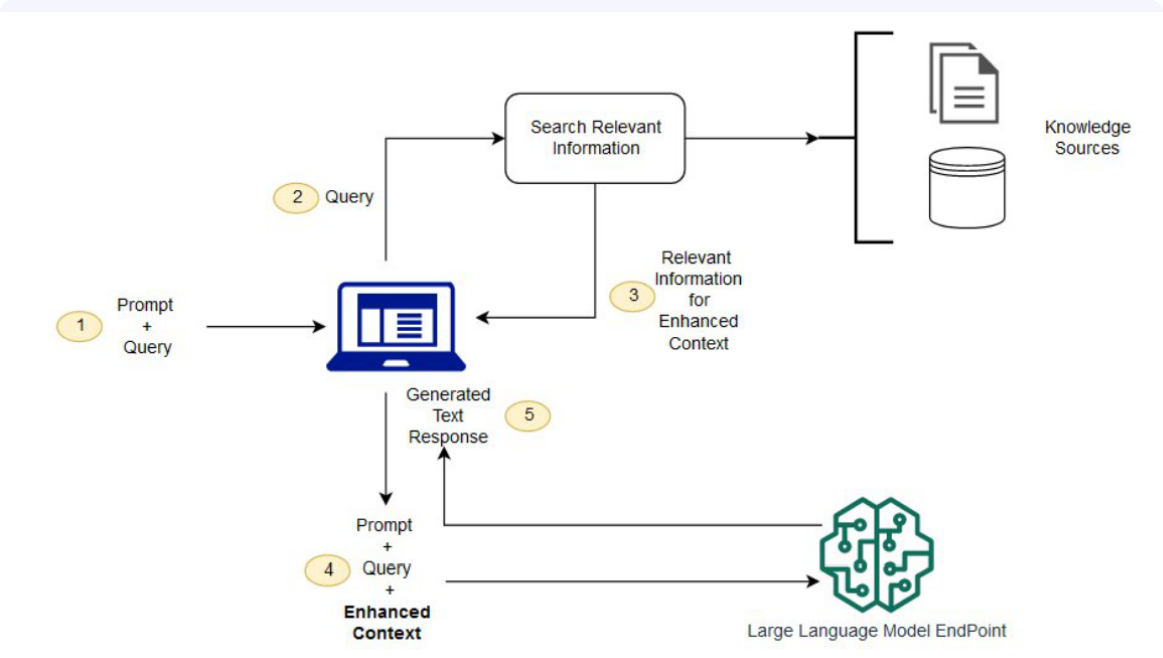
图37:将检索增强生成与大型语言模型结合用于问答应用的示例[166]。
a) RAG感知提示技术:鉴于RAG在构建先进LLM系统中的重要性,近期已发展出多种RAG感知提示技术。前向主动检索增强生成(FLARE)便是此类技术之一。
前瞻性主动检索增强生成(FLARE)[168] 通过迭代地结合预测与信息检索,提升了大型语言模型(LLM)的能力。FLARE代表了检索增强生成应用的一次演进,旨在提高LLM响应的准确性与相关性。
FLARE采用一种迭代式流程,其核心在于让大语言模型主动预测后续内容,并将这些预测作为查询以检索相关信息。该方法不同于传统的检索增强模型——后者通常仅执行单次检索后即进入生成阶段。FLARE的检索过程是动态且持续贯穿于整个生成阶段的。
在FLARE中,大语言模型生成的每个句子或文本片段都会进行置信度评估。若置信度低于设定阈值,系统会将已生成内容作为查询条件,检索相关信息,并据此重新生成或优化该句子。这种迭代机制确保回应的每个部分都能基于当前可获得的最相关、最新信息进行构建。
关于RAG框架及其相关工作的更多细节,我们建议读者参阅这篇检索增强生成的综述文献[165]。
D. 使用外部工具
如上所述,从外部知识源检索信息仅是增强大型语言模型的潜在方式之一。更广义而言,大型语言模型可以访问任意数量的外部工具(例如服务API)以扩展其功能。就此而言,检索增强生成可被视为更广泛类别的所谓“工具”中的一个具体实例。
在当前语境下,工具指代的是大型语言模型可调用的外部函数或服务。这些工具拓展了大型语言模型能够执行的任务范畴,从基础的信息检索到与外部数据库或API的复杂交互皆可涵盖。
在论文《Toolformer:语言模型能自学使用工具》[169]中,作者超越了简单的工具使用范畴,通过训练大语言模型使其能自主决定何时使用何种工具,甚至能判断API所需参数。工具集包含两种不同的搜索引擎及计算器。在后续示例中,该大语言模型分别调用了外部问答工具、计算器及维基百科搜索引擎。近期,伯克利的研究人员训练了名为Gorilla [67]的新大语言模型,其在API调用(一种特定但高度通用的工具)方面超越了GPT-4的表现。
a) 工具感知提示技术:与上文所述的检索增强生成类似,目前已开发出多种工具感知提示方法,旨在提升工具使用的可扩展性。其中一种流行技术被称为自动多步推理与工具使用。
自动多步推理与工具使用(ART)[170]是一种结合自动化思维链提示与外部工具运用的提示工程技术。该技术融合了多种提示工程策略,显著提升了大型语言模型处理复杂任务的能力,此类任务不仅需要逻辑推理,还需与外部数据源或工具进行交互。
自动化推理与工具使用(ART)采用一种系统化方法:当给定一项任务和输入时,系统首先从任务库中识别出相似任务。随后,这些任务被用作提示中的示例,指导大语言模型如何着手处理并执行当前任务。此方法在任务需要结合内部推理与外部数据处理或检索时尤为有效。
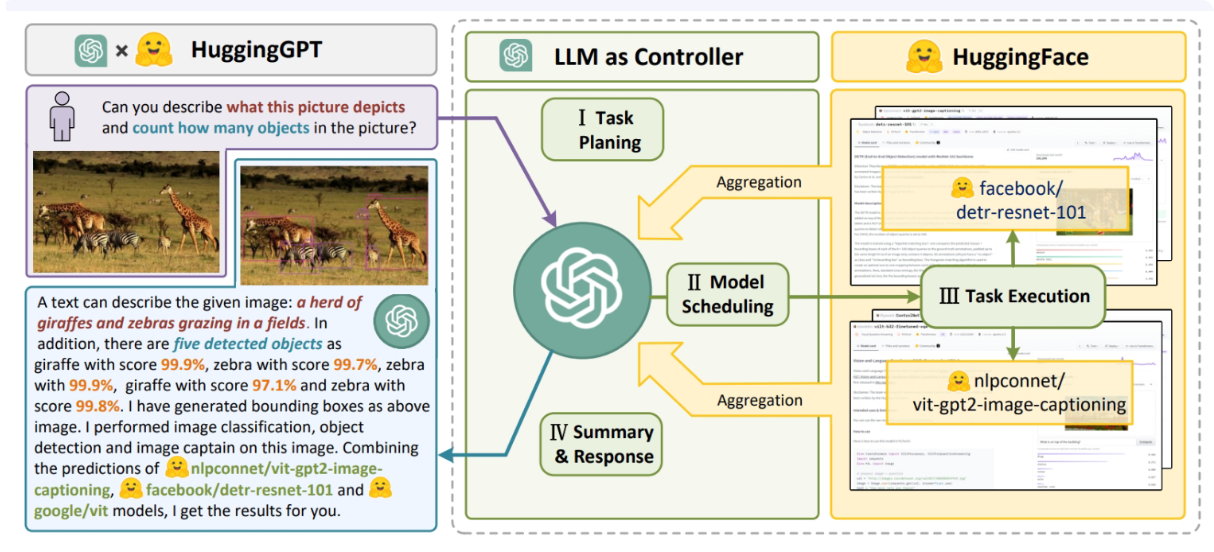
图 39: HuggingGPT:一种基于智能体的工具使用与规划方法 [图片由[171]提供]
E. 大语言模型智能体
人工智能智能体的概念在人工智能发展史上已有充分探讨。智能体通常指一种自主实体,它能够通过传感器感知环境,根据当前状态进行判断,并依据可执行的动作采取相应行为。
在大型语言模型的语境中,智能体指的是一种基于(增强型)大型语言模型专用实例的系统,能够自主执行特定任务。这类智能体被设计用于与用户及环境进行交互,根据输入信息及交互的预期目标做出决策。智能体以具备工具调用与使用能力的大型语言模型为基础,并能依据给定输入进行决策。其设计旨在处理需要一定自主性与决策能力的任务,通常超越了简单的响应生成范畴。
通用大型语言模型智能体的功能包括:
• 工具访问与调用:智能体具备访问外部工具与服务的能力,并能有效利用这些资源以完成任务。
• 决策制定:它们能够基于输入信息、上下文环境及可用工具进行决策,该过程通常涉及复杂的推理机制。
例如,一个能够访问天气API等函数(或API)的大语言模型,可以回答任何关于特定地点天气的问题。换言之,它能够利用API来解决问题。此外,如果该大语言模型能够访问支持购物功能的API,那么就可以构建一个采购代理,它不仅具备从外部世界读取信息的能力,还能基于这些信息采取行动[171]。
图40展示了另一个基于大语言模型的对话式信息检索智能体示例[36]。该模型通过一组即插即用模块进行增强,包括用于跟踪对话状态的工作记忆、为任务制定执行计划并选择下一系统动作的策略模块、执行策略所选动作的动作执行器(可整合外部知识证据或提示大语言模型生成响应),以及用于评估大语言模型响应与用户期望或特定业务需求契合度的效用模块,该模块还能生成反馈以提升智能体性能。
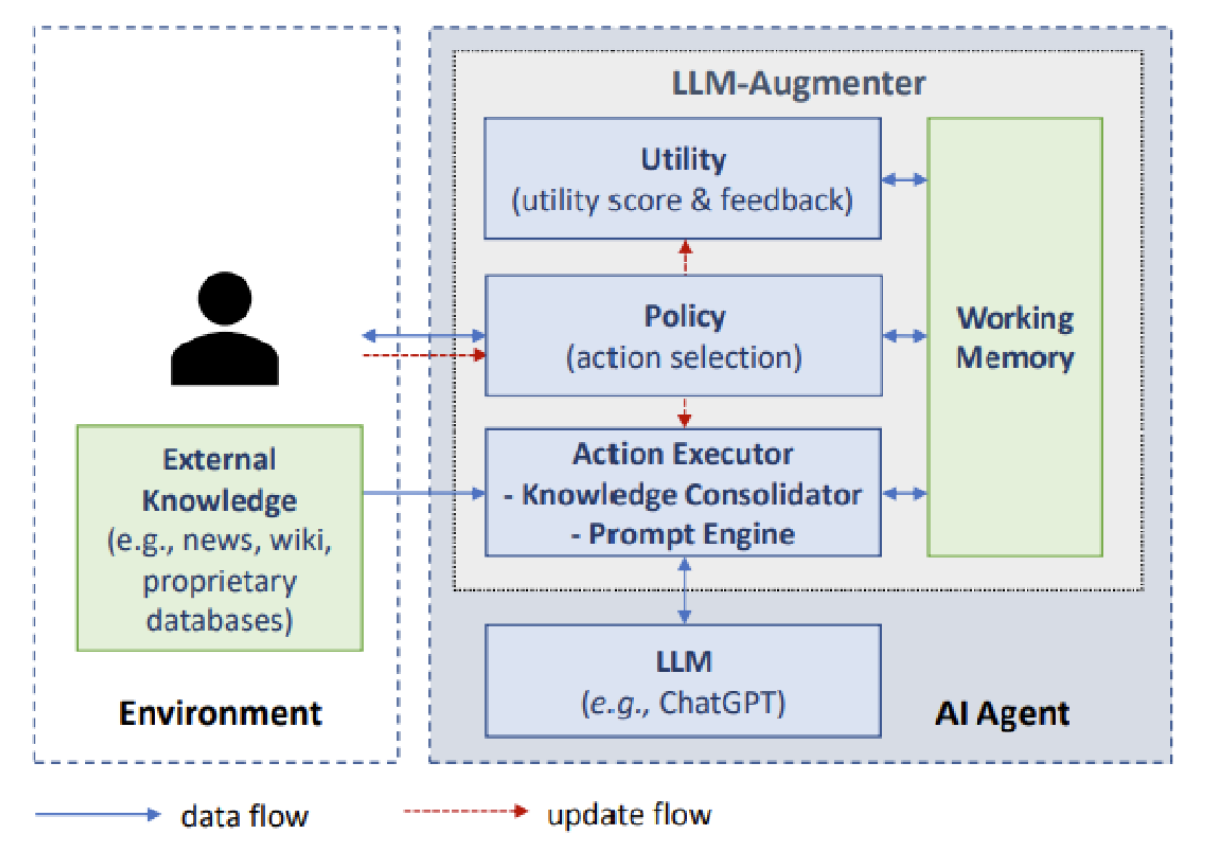
图40:基于大语言模型的对话式信息检索智能体。由文献[36]提供。
有关基于LLM的AI智能体更多细节,可参阅近期综述[172]、[173]、[174]。
a) 智能体的提示工程方法:与检索增强生成(RAG)和工具调用类似,目前也已开发出专门针对基于大语言模型的智能体需求的提示工程技术。其中三个典型示例是无观察推理(ReWOO)、推理与行动(ReAct)以及支持对话的解析智能体(DERA)。
无需观察的推理(ReWOO)[175] 旨在将推理过程与直接观察解耦。ReWOO 的工作原理是使大语言模型能够在无需立即依赖外部数据或工具的情况下,制定全面的推理计划或元计划。该方法允许智能体构建一个结构化的推理框架,在必要数据或观察结果可用时即可执行。在 ReWOO 中,大语言模型首先制定计划(一系列步骤),概述如何处理和解决给定问题。这一元规划阶段至关重要,因为它为智能体在信息可用时的处理过程奠定了基础。随后的执行阶段则将实际数据或观察结果整合到预设计划中,从而产生连贯且符合语境的响应。ReWOO 在令牌效率和工具故障鲁棒性方面具有显著优势。它使大语言模型能够处理无法即时获取外部数据的任务,转而依赖结构良好的推理框架。这种方法在数据检索成本高、速度慢或不确定的场景中尤其有利,使基于大语言模型的智能体能够保持高水平的性能和可靠性。
Reason and Act(ReAct)[176] 提示大型语言模型不仅生成言语推理,还能生成可执行步骤,从而增强模型的动态问题解决能力。ReAct 基于推理与行动相结合的原则。在此方法中,通过提示大型语言模型以交错的方式,交替生成推理轨迹(解释)和执行动作(步骤或命令)。这种方法使模型能够对问题进行动态推理,同时提出并执行具体行动。
对话式解决代理(DERA)[177]是能够进行对话、解决查询并基于交互式交流作出决策的专用人工智能代理。该技术基于在对话环境中运用多智能体的理念开发,每个智能体承担特定角色与功能。这些代理可包含负责收集分析信息的研究型智能体,以及基于所提供信息作出最终判断的决策型智能体。这种角色划分形成了条理清晰、高效协同的问题解决与决策机制。DERA在需要复杂决策与问题解决的场景中表现尤为突出,例如医疗诊断或客户服务领域。其智能体间协作互动的特性,使其能够以单智能体系统难以企及的深度与细微差别处理复杂查询。此外,这种模式与人类决策过程高度契合,使人工智能推理更具可理解性与可信度。
5.大型语言模型常用数据集
大型语言模型展现出令人瞩目的成就,但核心问题在于其实际运行效能如何,以及在特定任务或应用场景中的表现应通过何种方式评估。
大型语言模型的评估因其应用场景的不断演变而面临特殊挑战。开发大型语言模型的初衷是为了提升如翻译、摘要、问答等自然语言处理任务的性能[178]。然而,如今这些模型显然已在包括代码生成和金融在内的多个领域得到应用。此外,大型语言模型的评估还涉及公平性与偏见、事实核查以及推理能力等多个关键考量因素。本节将概述用于评估大型语言模型的常用基准。这些基准根据其训练或评估大型语言模型能力的不同侧重点进行分类。
A. 基础任务数据集:语言建模/理解/生成
本节概述了适用于评估大语言模型基础能力的基准测试与数据集。
• 自然问答 [179] 是一个问答数据集,由提交至谷歌搜索引擎的真实匿名聚合查询问题构成。标注员会看到一个提问及其对应的维基百科页面(来自搜索结果前五名),并在页面上标注长答案(通常为一个段落)和短答案(一个或多个实体,若存在),若页面中无相应长/短答案则标记为空。
• MMLU [180] 旨在评估模型在零样本和少样本场景下获得的知识。这意味着MMLU同时评估模型的通用知识和问题解决能力。它涵盖STEM、人文、社会科学及其他领域的57个学科,复杂度覆盖从基础到高级专业水平。值得一提的是,该数据集的主要贡献在于支持多任务语言理解、问答及算术推理的评估。
• MBPP [181] 代表“基础Python编程问题”,为评估代码生成模型的性能提供基准。该基准包含974个简短的Python程序,涵盖基础编程概念、标准库使用等诸多主题。每个挑战包含任务描述、代码解决方案和三个自动化测试用例。
• HumanEval [182] 是针对代码生成任务的数据集,包含164个手工设计的编程挑战。每个挑战均附有函数签名、文档字符串、代码主体及多个单元测试。开发该数据集的主要考量是确保其内容不会出现在代码生成模型的训练数据集中。
• APPS [183] 是为专注于Python编程语言的代码生成任务而设计的数据集。APPS数据集包含232,444个Python程序集合,其中每个程序平均包含18行Python代码。此外,APPS还提供了包含10,000个独特编程问题的资源库访问权限。练习,每个都包含基于文本的问题描述。最后需要强调的是,该系统包含测试用例。
• WikiSQL [184] 专为代码生成任务设计,它包含来自维基百科表格的87,726对经过仔细标注的SQL查询及对应自然语言问题。SQL查询包含三个子集:测试集(17,284个示例)、验证集(9,145个示例)和训练集(61,297个示例)。
• TriviaQA [185] 专为问答任务设计。该数据集包含超过650,000个问题-答案-证据三元组。其中有95,000个问题-答案对,每个均由 trivia 爱好者编写,并平均由六份独立来源的证据文档支撑。这些文档是通过维基百科或更广泛的网络搜索结果自动获取的。该数据集分为两个部分,包括来自维基百科和网络域的真实答案部分,以及经过验证的集合——该集合包含了从维基百科和网络中获取该数据集基于中国12至18岁初高中学生完成的英语测试,包含约28,000篇文本和100,000道由人类专家(主要为英语教师)严格编制的问题。数据集涵盖广泛主题,经特意筛选以评估学生的理解与推理能力。它分为三个子集:RACE-M、RACE-H和RACE。其中RACE-M指初中考试题,RACE-H指高中考试题,RACE则为两者的综合。
• SQuAD[187]代表“斯坦福问答数据集”,是基于维基百科文章的众包阅读理解数据集,包含约100,000组问答对,涉及500多篇文章。答案通常是对应阅读段落中的文本片段或跨句内容,部分问题可能无法直接作答。数据集按80%训练集、10%开发集和10%隐藏测试集划分。
• BoolQ[188]是一个是非型问答数据集,旨在完成阅读理解任务,共包含15,942个样本。每个样本由问题、相关段落和答案组成三元组。该数据集虽以阅读理解为核心设计理念,也可用于推理、自然语言推理及问答任务。
• MultiRC[189]是另一适用于阅读理解任务的数据集,包含简短段落及可基于段落信息回答的多句子问题。段落来源多样,涵盖新闻、小说、历史文献、维基百科文章、社会法律讨论、小学科学教材及9/11事件报告等。每个问题设多个选项,其中一项或多项为正确答案,解答需进行跨句子推理。该数据集包含约6,000个多句子问题,采集自800余个段落,平均每个问题在五个选项中含约两个有效答案。
B. 面向涌现能力的数据集:上下文学习、推理(思维链)、指令遵循
本节重点介绍用于评估大语言模型(LLM)涌现能力的基准测试与数据集。
-
GSM8K [190] 旨在评估模型的多步骤数学推理能力。该数据集包含 8.5K 道由人工编写、语言多样的小学数学应用题,分为 7.5K 道题目的训练集和 1K 道题目的测试集。这些问题通常需要 2 到 8 个步骤来求解,其解答主要是一系列使用基本算术运算的初级计算。
-
MATH [191] 用于评估模型解决数学问题的能力。该数据集包含 12,500 道来自高中数学竞赛的题目。每道题都附有分步解答和一个框出的最终答案。题目涵盖广泛的主题且具有不同难度级别,总计七个科目。此外,每道题的难度均根据 AoPS 标准在“1”到“5”的范围内进行评级,“1”代表该科目中最简单的问题,“5”代表最困难的问题。在格式上,所有问题和解答均使用 LaTeX 和 Asymptote 矢量图形语言呈现。
-
HellaSwag [192] 旨在评估大语言模型的常识推理能力。该基准包含 70,000 道多项选择题。每道题源自 ActivityNet 或 WikiHow 两个领域之一,并提供四个关于后续情境可能发展的选项。正确答案是对即将发生事件的真实描述,而三个错误答案则是为迷惑机器而生成的。
-
AI2 推理挑战赛 (ARC) [193] 用于常识推理。该基准包含 7,787 道科学考试题目。这些题目为英语,大多采用多项选择题形式,被分为两组:包含 2,590 道难题的挑战集和包含 5,197 道简单题目的简单集。每个集合均预先划分为训练、开发和测试子集。
-
PIQA [194] 旨在评估语言表征对物理常识的掌握。该数据集聚焦于日常情境,并倾向于不常见的解决方案。核心任务为多项选择问答:提供一个问题和两个潜在解决方案,然后由模型或人类选择最佳方案。每道题只有一个解决方案是正确的。
-
SIQA [195] 提供了一个评估模型对社会情境进行常识推理能力的框架。该数据集包含 38,000 道旨在评估日常情境中情感与社会智能的多项选择题,涵盖多种社会场景。其备选答案混合了人工选择的回答和经过对抗性过程筛选的机器生成回答。
-
OpenBookQA (OBQA) [196] 是一种新型问答数据集,其问题解答需要书本之外额外的常识与通用知识以及深入的文本理解。该数据集包含约 6,000 道多项选择题。每道题链接一个核心事实以及一个包含 6,000 多条事实的附加集合。题目通过多阶段众包和专家筛选流程制定。因其需要在有限背景下进行多跳推理,OpenBookQA 问题具有较高难度。
-
TruthfulQA [197] 专门设计用于评估语言模型生成答案的真实性。该数据集包含作者编写的 817 个问题,涵盖健康、法律、金融、政治等 38 个不同类别。这些问题特意设计来挑战人类回答者,因为它们可能包含导致错误答案的常见误解。
-
OPT-IML Bench [103] 是指令元学习的综合基准。它涵盖来自 8 个现有基准的 2000 项 NLP 任务,包含 1790 万样本的训练集、14.5 万样本的开发集和 32.1 万样本的测试集。
C. 增强型数据集:使用外部知识/工具
本节重点介绍为增强大语言模型能力而设计的数据集。
• HotpotQA [198] 旨在构建一个多样化且可解释的问答数据集,其问题需进行多步推理。该数据集基于英文维基百科构建,包含约11.3万个问题。每个问题均附带来自两篇维基百科文章的两个段落(称为黄金段落),同时包含众包工作者标注的、对回答问题至关重要的关键句子列表。
• ToolQA [199] 是一个用于评估大语言模型使用外部工具回答问题能力的问答基准。
• GPT4Tools 是一个指令数据集,通过引导先进教师模型(如 ChatGPT)基于视觉内容和工具描述生成指令而构建,最终产生与工具使用相关的指令数据。该数据集包含三个版本:第一版包含7.1万条指令跟随数据,用于微调 GPT4Tools 模型;第二版为经人工清洗的验证用指令数据,涵盖第一版中的工具相关指令;第三版为测试用清洗指令数据,包含第一版中未出现的部分工具相关指令。
6.主流大语言模型的基准测试表现
本节首先概述了用于评估大语言模型在不同场景下性能的若干常用指标,继而考察了主流大语言模型在部分常用数据集与基准测试中的表现。
A. 大型语言模型常用评估指标
评估生成式语言模型的性能取决于其拟应用的具体任务。对于主要从给定选项中选择答案的任务(如情感分析),可视为分类问题,其性能可使用分类指标进行评估。在此类情况下,可适用准确率、精确率、召回率、F1值等指标。还需注意,模型在特定任务(如多项选择题回答)中生成的答案始终为正确或错误。若答案不在选项集合中,亦可视为错误。
然而,纯粹开放式文本生成的部分任务无法像分类任务那样采用相同方式进行评估,需要根据具体评估目标采用不同的度量标准。代码生成在开放式生成评估中则属于截然不同的情况。生成的代码必须通过测试套件,但另一方面,理解模型是否能生成多种代码解决方案、以及从中选择正确方案的概率也同样重要。此时Pass@k是一个极佳的度量指标。其运作方式如下:针对给定问题,生成多种代码解决方案,通过不同功能测试验证其正确性,随后基于生成的n个解决方案中通过测试的c个正确解,依据公式4计算出最终评估值。
p a s s @ k : = E P r o b l e m s [ 1 − ( n − c k ) ( n k ) ] \mathrm{pass@}k:=\underset{\mathrm{Problems}}{\operatorname*{\operatorname*{\mathbb{E}}}}\left[1-\frac{\binom{n-c}{k}}{\binom{n}{k}}\right] pass@k:=ProblemsE[1−(kn)(kn−c)]
精确匹配(EM)是另一种主要关注于(预定义)答案完全一致性的评估指标。若预测结果与一个或多个期望参照文本在词元级别上完全吻合,则该预测被判定为正确。在某些情况下,该指标可与准确率等同,其数学定义如公式5所示。其中M表示正确答案总数,N表示问题总数[202]。
E M = M N EM=\frac{M}{N} EM=NM
另一方面,人类等效分数(HEQ)是F1分数的一种替代指标[203]。HEQ-Q代表单个问题的精确度,当模型的F1分数超过人类平均F1分数时,该问题的答案即被视为正确。类似地,HEQ-D表示每个对话的精确度;当对话中的所有问题均满足HEQ标准时,该对话即被判定为准确[182]。
对其他生成式任务(如机器翻译)的评估通常基于Rouge和BLEU等指标。当存在参考文本作为基准事实(例如翻译结果)以及生成模型(在本研究中即大语言模型)生成的假设文本时,这些评分方法效果良好。这类指标主要用于以计算方式检测生成答案与基准事实之间相似性的场景。所谓计算方式,是指其仅利用N-Gram等表层特征进行分析。尽管BERTScore等指标在此类场景中也有良好表现,但由于依赖另一个模型进行评判,其本身也存在显著误差。时至今日,对纯生成内容的评估依然极为困难,尚未找到完全适用的评估指标——现有指标要么仅关注N-Gram、SkipGram等简单特征,要么是自身准确性与精确度未知的模型[204]。
生成式评估指标是另一种针对大语言模型的评估方法,其利用另一个大语言模型对答案进行评估。然而,根据任务本身的性质,这种方式可能适用也可能不适用于评估。另一项导致生成式评估容易出错的因素是其对提示本身的依赖性。RAGAS 是成功融合生成式评估应用的良好范例之一。
各类基准测试与排行榜的提出,旨在应对大语言模型领域最具挑战性的问题:究竟哪个模型更优?然而,此问题并无简单答案。答案取决于大语言模型的多个不同维度。第五节展示了不同任务的分类呈现以及各类别中最重要的数据集。我们将沿用相同的分类方式,并在每个类别内进行比较分析。完成各分类的对比后,我们将通过平均不同任务的报告性能指标,对模型的综合性能提供整体概览。
评估不同的大语言模型亦可从多重视角进行。例如,一个参数量显著较少的模型与参数量庞大的模型并不完全具备可比性。基于此视角,我们将大语言模型分为四类:小型(参数≤10亿)、中型(10亿至100亿参数)、大型(100亿至1000亿参数)和超大型(参数>1000亿)。另一种分类依据是其主要使用场景。我们将每个大语言模型归为以下三类:基础模型(仅经过预训练、未进行指令微调和对话微调的语言模型)、指令模型(仅经过指令微调预训练的语言模型)以及对话模型(经过指令微调和对话微调预训练的语言模型)。除上述分类外,还需增加一个类别以区分原始模型与调优模型。原始模型指那些以基础模型或微调模型形式发布的版本。调优模型则指基于原始模型,采用不同数据集甚至不同训练方法进行再调优的模型。需注意的是,原始模型通常是在特定数据集或通过不同方法微调过的基础模型。模型权重的可获得性(无论许可协议如何)是我们分类的另一个维度。权重公开可获取(即使需申请)的模型标记为公开模型,其余标记为私有模型。表III汇总了这些定义及本文后续使用的缩写,图43则对此进行了可视化呈现。
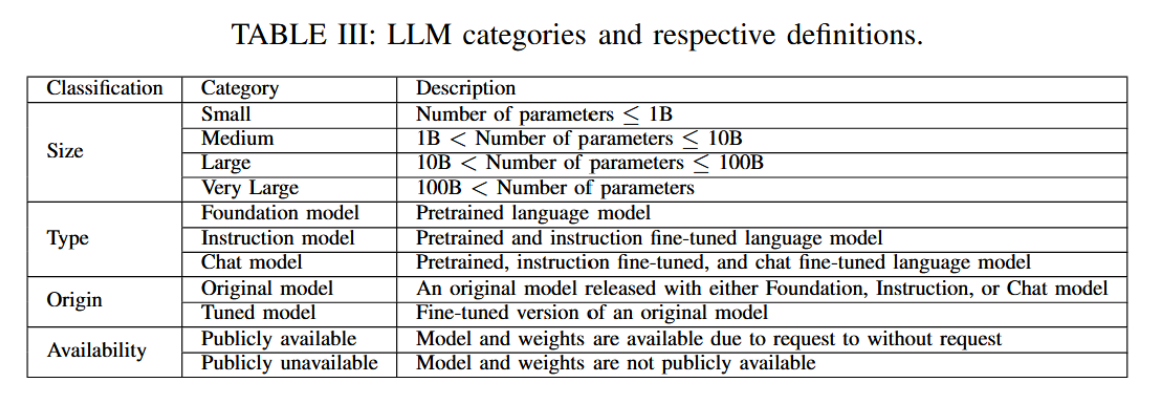
图43:大语言模型分类法。
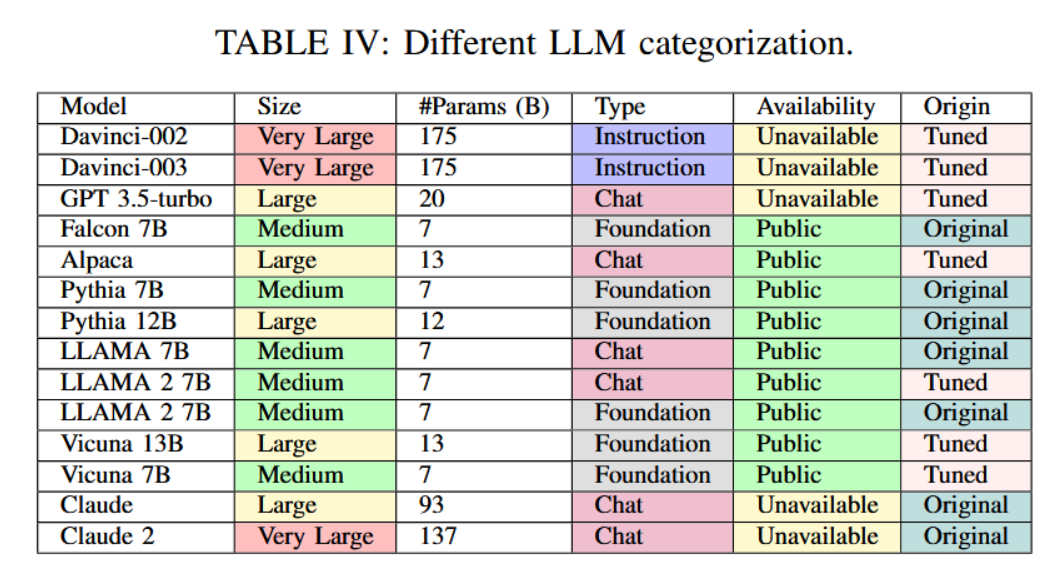
根据所提供的分类标准,我们可以将各知名大语言模型进行归类和标注,如表IV所示。由该表可知,被归类为超大规模模型的系统同样无法公开获取。
B. 大语言模型在不同任务中的表现
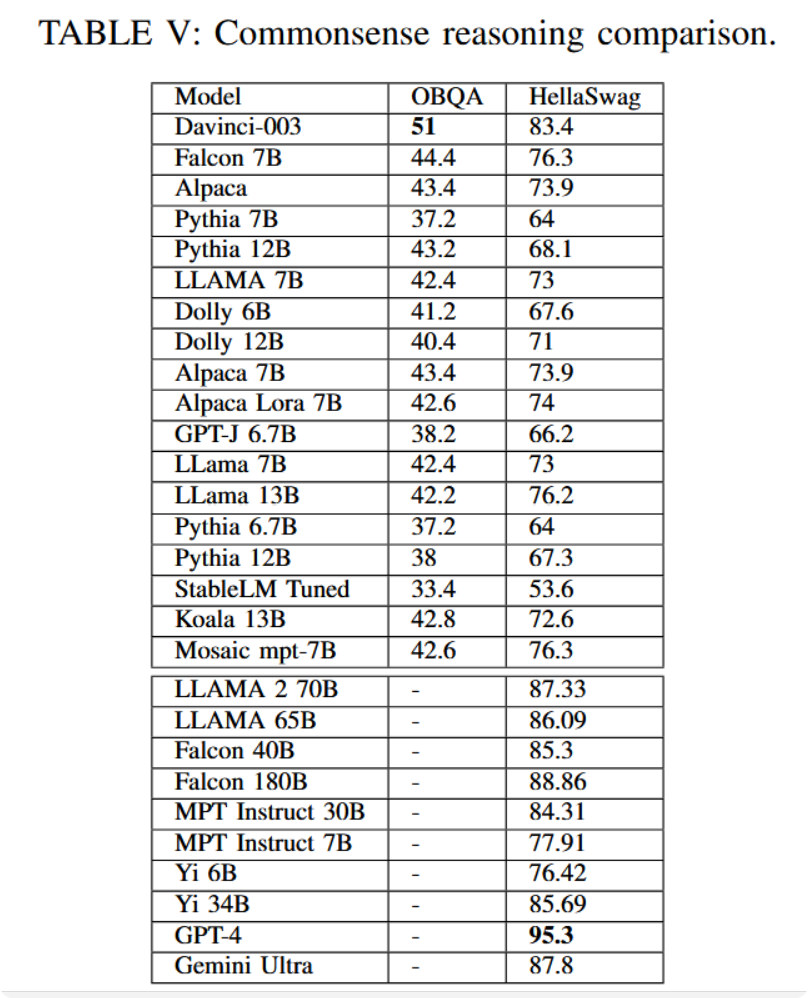
常识推理是每个模型都能获得的重要能力之一。该能力指模型运用先验知识结合推理技能的水平。以HellaSwag为例,寻找文本续写具有挑战性,因为给定文本仅包含故事片段,而待选的续写选项设计巧妙,若不具备关于世界的先验知识则无法完成。这类推理值得高度重视,因为它涉及将既有知识应用于开放文本描述的场景或事实。从表V可见,不仅未公开模型,公开模型也能在各种测试中取得良好结果。
针对某些特定的用例模型,对编码和代码生成能力有着高度需求。表VIII展示了不同模型在编码能力上的表现结果。
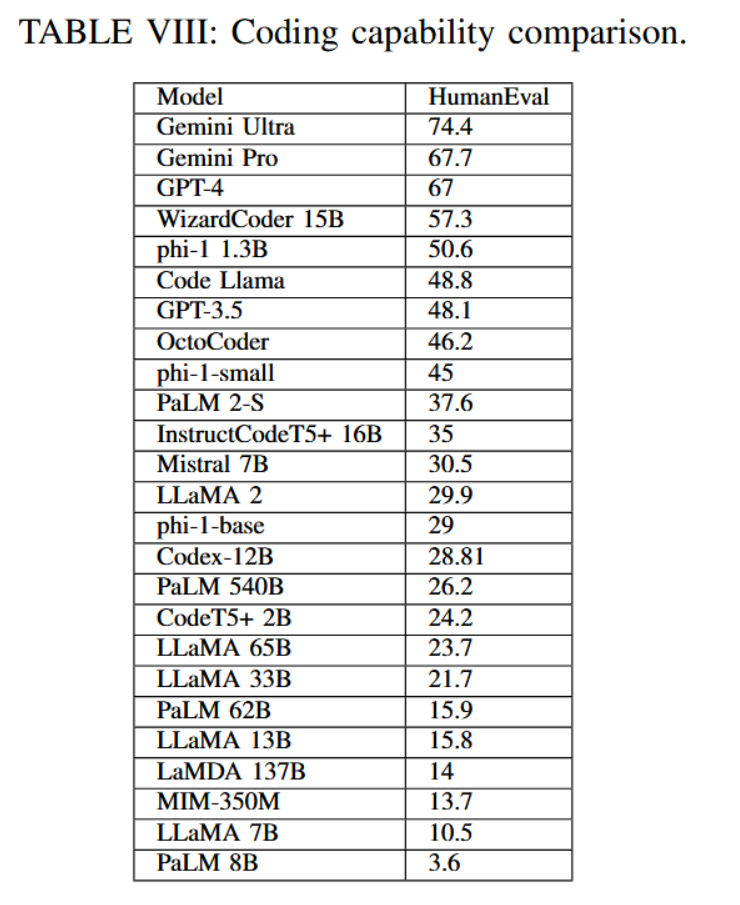
算术推理是另一项难以实现的推理能力。以GSM8K为例,该数据集包含与其答案相对应的小学数学问题。表IX为不同模型的比较提供了参考依据。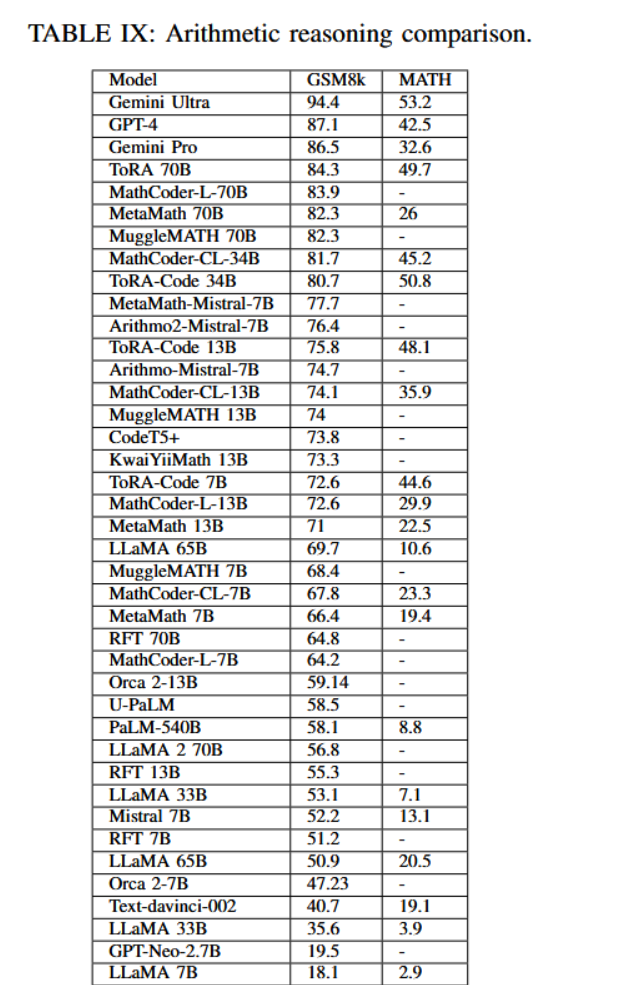
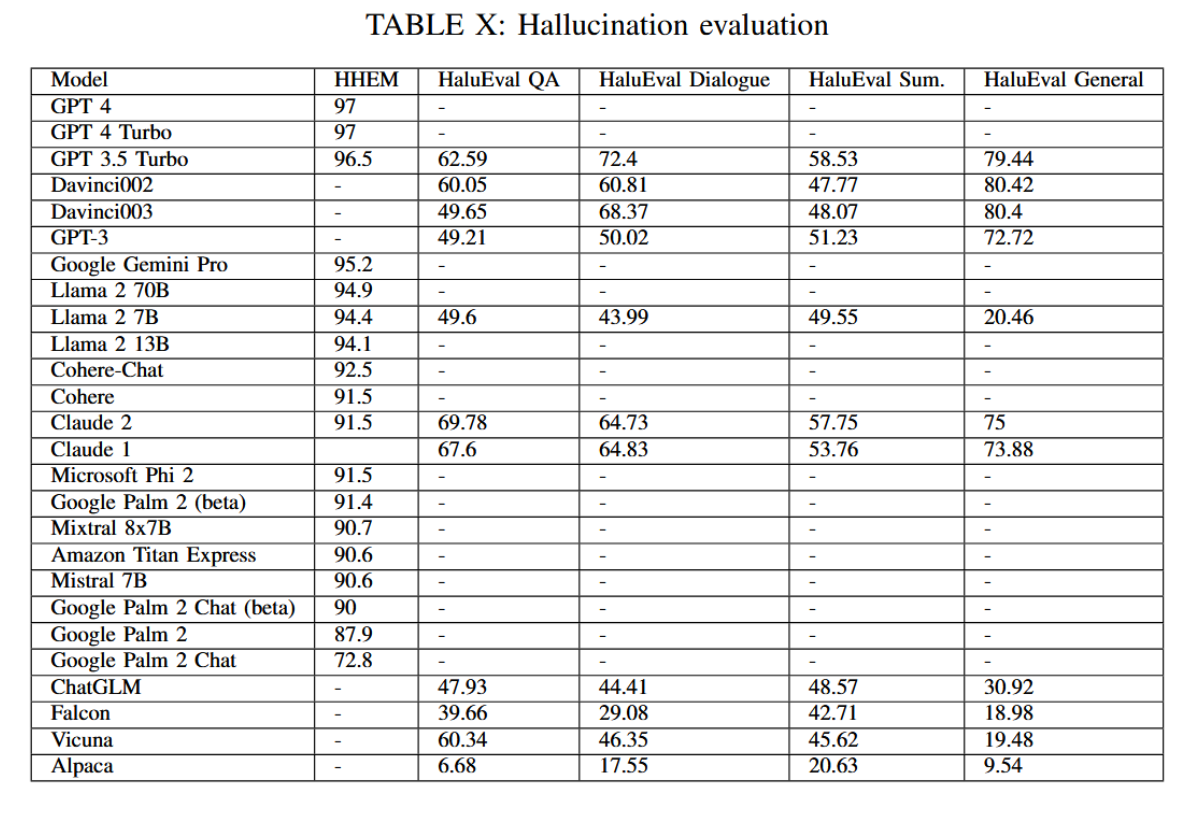
在某些情况下,大语言模型之所以会产生幻觉性答案,本质上是因为它们是基于下一个词元预测的机器。幻觉度是衡量大语言模型可信度与可靠性的重要因素之一。然而,测量幻觉度并非看上去那么简单,因为每个事实都可以用不同的风格呈现,即便是最细微的表述变化也会导致检测困难。可以合理推断,如果某个特定的大语言模型更能检测文本中的虚假信息幻觉,那么它也更为可信。HaluEval便是该领域旨在衡量幻觉度的数据集之一[205]。评估也可以通过另一个模型根据实际答案对生成内容进行判断来完成[206]。表X展示了基于这些数据集对不同模型的评估结果。
7.挑战与未来方向
正如我们在前几节中所见,大语言模型在过去一两年中取得了令人瞩目的成果。与此同时,这仍然是一个新兴且极其活跃的研究领域,其创新步伐正在加快而非放缓。然而,与任何其他发展中的领域一样,前方仍存在诸多挑战。在此我们简要提及一些目前已知的挑战和主要活跃的研究方向。值得注意的是,Kaddour等人[207]的著作中对大语言模型面临的挑战进行了详细探讨。
A. 更小更高效的语言模型
本文是一项关于大语言模型的综述研究。最初业界普遍推崇“越大越好”的理念,这一方向显然获得了回报,像GPT4这样不断增大的模型在基准测试中取得了更高的准确率和性能。然而,这些大模型在多个维度上成本高昂且效率低下(例如高延迟)。针对这些问题,当前的研究趋势是发展小语言模型,作为大语言模型的一种高性价比替代方案,尤其适用于那些可能不需要大型模型完全通用性的特定任务。该方向的代表性工作包括微软的Phi-1[208]、Phi-1.5[209]和Phi-2。
更广泛而言,我们应预见该领域将涌现大量关于如何训练更小、更高效模型的研究工作。参数高效微调(PEFT)、师生模型以及其他形式的蒸馏技术(参见第三节-I)将继续被用于从大模型中构建出更小的模型。
B. 后注意力机制的新型架构范式
Transformer块一直是当前大多数大型语言模型框架中至关重要且恒定的组成部分,但这一架构还能流行多久,以及深度学习(尤其是自然语言处理领域)下一个重大的架构突破将是什么,仍是一个巨大的问号。自2012年AlexNet问世以来,我们已经见证了包括LSTM、GRU、seq2seq在内的多种架构先后兴起与退潮,但Transformer自诞生以来始终占据主导地位。如前所述,注意力机制是驱动Transformer的核心。近期,已有一些被归类为“后注意力”的替代方法展现出颇具前景的研究进展。
此类后注意力模型中一个重要类别是所谓的状态空间模型。尽管状态空间模型这一概念在机器学习领域由来已久,但需注意在语言模型语境中,SSM通常指代较新的结构化状态空间模型架构(简称S4,参见Gu等人[29])。该类别下的近期模型包括Mamba[30]、Hyena[210]和Striped Hyena[211]。尽管这些模型在性能排行榜和计算效率方面都极具竞争力,它们还解决了更传统注意力架构面临的一个重要挑战:对更长上下文窗口支持的缺乏。
在许多提示中获得优质回答需要上下文支撑。例如,针对“为我推荐一些好电影”这一请求,其回应需要大量关于“我”的背景信息,以及当前可获取的电影资源与用户未观看影片的数据。上下文长度对于检索增强生成(RAG)尤为重要——在该技术中,大量文本可能被检索并注入提示词以生成内容(参见第 IV-C 节)。上下文长度越长,能容纳的标记数量就越多。模型接触的信息越丰富,其回应质量就越高。但另一方面,过长的上下文会使模型难以完整记忆并高效处理全部信息。基于注意力机制的模型在处理长上下文时效率显著低下,因此我们预期未来将有更多研究聚焦于开发能处理更长上下文的新机制,并构建更高效的架构体系。
值得注意的是,新型架构的研究可能不仅限于提出注意力机制的替代方案,更可能彻底重构整个 Transformer 架构。早期案例如 Monarch Mixer [212] 提出了一种新架构:该架构沿序列长度和模型维度两个方向,采用了能在 GPU 上实现高硬件效率的次二次原语——Monarch 矩阵。
在谱系的另一端,值得关注的是,一些与注意力机制兼容的架构设计近年来正崭露头角,并在构建更优、更强大的大语言模型方面证明了其价值。此类机制最典型的代表莫过于混合专家模型。混合专家模型在机器学习领域已存在多年,甚至早于深度学习时代[213],但自此之后其影响力日益增长,尤其是在Transformer模型与大语言模型的语境中。对于大语言模型而言,混合专家模型能够训练一个极其庞大的模型,而在推理过程中仅部分实例化——当门控/加权函数为某些专家分配较低权重时,这些专家将被关闭。例如,GLaM模型拥有1.2万亿参数,但在推理时仅激活64位专家中的2位[84]。
如今,混合专家模型已成为所谓前沿大语言模型(即最先进、性能最强的模型)的重要组成部分。据传,GPT-4 本身就基于混合专家架构,而一些性能顶尖的大语言模型,例如 Mixtral [117],本质上是现有大语言模型的混合专家版本。
如今,混合专家模型已成为所谓前沿大语言模型(即最先进、性能最强的模型)的重要组成部分。据传,GPT-4 本身就基于混合专家架构,而一些性能顶尖的大语言模型,例如 Mixtral [117],本质上是现有大语言模型的混合专家版本。无论是否基于注意力机制。事实上,混合专家模型也已应用于基于状态空间模型的大型语言模型,如Mamba(见引文:ioro等人,2024年,MoE-Mamba)。无论底层架构如何,未来我们应会持续看到混合专家模型带来的性能提升。
C. 多模态模型
未来的大规模语言模型预计将具备多模态能力,以统一方式处理文本、图像、视频、音频等多种数据类型。这将为问答、内容生成、创意艺术、医疗健康、机器人技术等更广泛领域的应用开辟可能性。目前已有多款显著的多模态大规模语言模型问世,例如:LLaVA [214]、LLaVA-Plus [215]、GPT-4 [33]、Qwen-VL [116]、Next-GPT [216],且这一趋势预计将持续发展。此类模型的评估亦成为新兴研究课题,尤其是对话式生成视觉模型[217]。多模态大规模语言模型能在多种任务中释放巨大潜力,该方向目前已取得显著进展,其详细内容需专文论述。
D. 改进的大型语言模型使用与增强技术
正如我们在第四部分所述,大型语言模型的诸多缺陷与局限(例如幻觉问题)可通过高级提示工程、工具调用或其他增强技术加以解决。我们应预期该领域的研究不仅将持续推进,更将加速发展。值得一提的是,在软件工程这一具体领域,已有研究(文献[218])尝试从整体软件工程工作流中自动消除此类问题。
基于大语言模型的系统已经开始取代直到最近还在使用其他方法的机器学习系统。一个明显的例子是,大语言模型正被部署用于更好地理解人们的偏好和兴趣,并提供更个性化的互动——无论是在客户服务、内容推荐还是其他应用中。这涉及对用户偏好的更深入理解,以及分析其过往互动并将其作为上下文使用。我们将会持续看到大语言模型在个性化与推荐系统领域应用的研究,同时也会看到其在许多原本采用其他机器学习技术的应用领域中得到拓展。
最后,我们预期将获得更多关注的另一个重要研究领域是基于大语言模型的智能体与多智能体系统[172]、[173]、[174]。开发具备外部工具访问能力和决策功能的大语言模型系统既令人振奋又充满挑战。在这一重要领域,我们将持续见证研究进展,有观点认为其可能最终导向人工通用智能(AGI)的实现。
E. 安全与伦理/负责任人工智能
确保大型语言模型(LLM)对抗对抗性攻击及其他漏洞的鲁棒性与安全性,是一个至关重要的研究领域[219]。随着LLM在现实应用中的部署日益广泛,必须保护其免受潜在威胁,以防止其被用于操纵公众或传播虚假信息。提升这些模型的推理能力[220],将有助于其更有效地识别潜在的对抗攻击。
解决LLM中的伦理问题与偏见是另一个活跃的研究方向。当前研究致力于确保LLM的公平性、无偏见性,以及负责任处理敏感信息的能力。由于日常使用LLM的公众数量日益增长,确保其无偏见且行为负责至关重要。
8.结论
本文综述了过去几年发展的大型语言模型。首先概述了早期的预训练语言模型(如BERT),随后回顾了三大主流LLM系列(GPT、LLaMA、PaLM)以及其他代表性模型。接着,系统梳理了构建、增强与应用LLM的方法与技术。我们评述了常用的LLM数据集与基准测试,并在公开基准上比较了一系列重要模型的性能。最后,提出了当前面临的开放挑战与未来的研究方向。
9.引用文献
- [1] J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, 2020.
- [2] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark et al., “Training compute-optimal large language models,” arXiv preprint arXiv:2203.15556, 2022.
- [3] C. E. Shannon, “Prediction and entropy of printed english,” Bell system technical journal, vol. 30, no. 1, pp. 50–64, 1951.
- [4] F. Jelinek, Statistical methods for speech recognition. MIT press, 1998.
- [5] C. Manning and H. Schutze, Foundations of statistical natural language processing. MIT press, 1999.
- [6] C. D. Manning, An introduction to information retrieval. Cambridge university press, 2009.
- [7] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- [8] C. Zhou, Q. Li, C. Li, J. Yu, Y. Liu, G. Wang, K. Zhang, C. Ji, Q. Yan, L. He et al., “A comprehensive survey on pretrained foundation models: A history from bert to chatgpt,” arXiv preprint arXiv:2302.09419, 2023.
- [9] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Computing Surveys, vol. 55, no. 9, pp. 1–35, 2023.
- [10] Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, and Z. Sui, “A survey for in-context learning,” arXiv preprint arXiv:2301.00234, 2022.
- [11] J. Huang and K. C.-C. Chang, “Towards reasoning in large language models: A survey,” arXiv preprint arXiv:2212.10403, 2022.
- [12] S. F. Chen and J. Goodman, “An empirical study of smoothing techniques for language modeling,” Computer Speech & Language, vol. 13, no. 4, pp. 359–394, 1999.
- [13] Y. Bengio, R. Ducharme, and P. Vincent, “A neural probabilistic language model,” Advances in neural information processing systems, vol. 13, 2000.
- [14] H. Schwenk, D. D ́echelotte, and J.-L. Gauvain, “Continuous space language models for statistical machine translation,” in Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, 2006, pp. 723–730.
- [15] T. Mikolov, M. Karafia ́t, L. Burget, J. Cernocky, and S. Khudanpur, “Recurrent neural network based language model.” in Interspeech, vol. 2, no. 3. Makuhari, 2010, pp. 1045–1048.
- [16] A. Graves, “Generating sequences with recurrent neural networks,” arXiv preprint arXiv:1308.0850, 2013.
- [17] P.-S. Huang, X. He, J. Gao, L. Deng, A. Acero, and L. Heck, “Learning deep structured semantic models for web search using clickthrough data,” in Proceedings of the 22nd ACM international conference on Information & Knowledge Management, 2013, pp. 2333–2338.
- [18] J. Gao, C. Xiong, P. Bennett, and N. Craswell, Neural Approaches to Conversational Information Retrieval. Springer Nature, 2023, vol. 44.
- [19] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” Advances in neural information processing systems, vol. 27, 2014.
- [20] K. Cho, B. Van Merrie ̈nboer, D. Bahdanau, and Y. Bengio, “On the properties of neural machine translation: Encoder-decoder approaches,” arXiv preprint arXiv:1409.1259, 2014.
- [21] H. Fang, S. Gupta, F. Iandola, R. K. Srivastava, L. Deng, P. Doll ́ar, J. Gao, X. He, M. Mitchell, J. C. Platt et al., “From captions to visual concepts and back,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1473–1482.
- [22] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164.
- [23] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations. corr abs/1802.05365 (2018),” arXiv preprint arXiv:1802.05365, 2018.
- [24] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [25] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- [26] P. He, X. Liu, J. Gao, and W. Chen, “Deberta: Decoding-enhanced bert with disentangled attention,” arXiv preprint arXiv:2006.03654, 2020.
- [27] X. Han, Z. Zhang, N. Ding, Y. Gu, X. Liu, Y. Huo, J. Qiu, Y. Yao, A. Zhang, L. Zhang et al., “Pre-trained models: Past, present and future,” AI Open, vol. 2, pp. 225–250, 2021.
- [28] X. Qiu, T. Sun, Y. Xu, Y. Shao, N. Dai, and X. Huang, “Pre-trained models for natural language processing: A survey,” Science China Technological Sciences, vol. 63, no. 10, pp. 1872–1897, 2020.
- [29] A. Gu, K. Goel, and C. R ́e, “Efficiently modeling long sequences with structured state spaces,” 2022.
- [30] A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” arXiv preprint arXiv:2312.00752, 2023.
- [31] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “Palm: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022.
- [32] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Roziere, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [33] OpenAI, “GPT-4 Technical Report,” https://arxiv.org/pdf/2303. 08774v3.pdf, 2023.
- [34] J. Wei, X. Wang, D. Schuurmans, M. Bosma, b. ichter, F. Xia, E. Chi, Q. V. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 24 824–24 837. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
- [35] G. Mialon, R. Dessı, M. Lomeli, C. Nalmpantis, R. Pasunuru, R. Raileanu, B. Roziere, T. Schick, J. Dwivedi-Yu, A. Celikyilmaz et al., “Augmented language models: a survey,” arXiv preprint arXiv:2302.07842, 2023.
- [36] B. Peng, M. Galley, P. He, H. Cheng, Y. Xie, Y. Hu, Q. Huang, L. Liden, Z. Yu, W. Chen, and J. Gao, “Check your facts and try again: Improving large language models with external knowledge and automated feedback,” arXiv preprint arXiv:2302.12813, 2023.
- [37] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” arXiv preprint arXiv:2210.03629, 2022.
- [38] D. E. Rumelhart, G. E. Hinton, R. J. Williams et al., “Learning internal representations by error propagation,” 1985.
- [39] J. L. Elman, “Finding structure in time,” Cognitive science, vol. 14, no. 2, pp. 179–211, 1990.
- [40] M. V. Mahoney, “Fast text compression with neural networks.” in FLAIRS conference, 2000, pp. 230–234.
- [41] T. Mikolov, A. Deoras, D. Povey, L. Burget, and J. ˇCernocky, “Strategies for training large scale neural network language models,” in 2011 IEEE Workshop on Automatic Speech Recognition & Understanding. IEEE, 2011, pp. 196–201.
- [42] tmikolov. rnnlm. [Online]. Available: https://www.fit.vutbr.cz/ ∼imikolov/rnnlm/
- [43] S. Minaee, N. Kalchbrenner, E. Cambria, N. Nikzad, M. Chenaghlu, and J. Gao, “Deep learning–based text classification: a comprehensive review,” ACM computing surveys (CSUR), vol. 54, no. 3, pp. 1–40, 2021.
- [44] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [45] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
- [46] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pretraining text encoders as discriminators rather than generators,” arXiv preprint arXiv:2003.10555, 2020.
- [47] G. Lample and A. Conneau, “Cross-lingual language model pretraining,” arXiv preprint arXiv:1901.07291, 2019.
- [48] Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” Advances in neural information processing systems, vol. 32, 2019.
- [49] L. Dong, N. Yang, W. Wang, F. Wei, X. Liu, Y. Wang, J. Gao, M. Zhou, and H.-W. Hon, “Unified language model pre-training for natural language understanding and generation,” Advances in neural information processing systems, vol. 32, 2019.
- [50] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” 2018.
- [51] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- [52] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [53] L. Xue, N. Constant, A. Roberts, M. Kale, R. Al-Rfou, A. Siddhant, A. Barua, and C. Raffel, “mt5: A massively multilingual pre-trained text-to-text transformer,” arXiv preprint arXiv:2010.11934, 2020.
- [54] K. Song, X. Tan, T. Qin, J. Lu, and T.-Y. Liu, “Mass: Masked sequence to sequence pre-training for language generation,” arXiv preprint arXiv:1905.02450, 2019.
- [55] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “Bart: Denoising sequence-tosequence pre-training for natural language generation, translation, and comprehension,” arXiv preprint arXiv:1910.13461, 2019.
- [56] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [57] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021.
- [58] R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders et al., “Webgpt: Browserassisted question-answering with human feedback,” arXiv preprint arXiv:2112.09332, 2021.
- [59] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022.
- [60] OpenAI. (2022) Introducing chatgpt. [Online]. Available: https: //openai.com/blog/chatgpt
- [61] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [62] R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Alpaca: A strong, replicable instructionfollowing model,” Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, vol. 3, no. 6, p. 7, 2023.
- [63] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” arXiv preprint arXiv:2305.14314, 2023.
- [64] X. Geng, A. Gudibande, H. Liu, E. Wallace, P. Abbeel, S. Levine, and D. Song, “Koala: A dialogue model for academic research,” Blog post, April, vol. 1, 2023.
- [65] A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al., “Mistral 7b,” arXiv preprint arXiv:2310.06825, 2023.
- [66] B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y. Adi, J. Liu, T. Remez, J. Rapin et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950, 2023.
- [67] S. G. Patil, T. Zhang, X. Wang, and J. E. Gonzalez, “Gorilla: Large language model connected with massive apis,” 2023.
- [68] A. Pal, D. Karkhanis, M. Roberts, S. Dooley, A. Sundararajan, and S. Naidu, “Giraffe: Adventures in expanding context lengths in llms,” arXiv preprint arXiv:2308.10882, 2023.
- [69] B. Huang, “Vigogne: French instruction-following and chat models,” https://github.com/bofenghuang/vigogne, 2023.
- [70] Y. Wang, H. Ivison, P. Dasigi, J. Hessel, T. Khot, K. R. Chandu, D. Wadden, K. MacMillan, N. A. Smith, I. Beltagy et al., “How far can camels go? exploring the state of instruction tuning on open resources,” arXiv preprint arXiv:2306.04751, 2023.
- [71] S. Tworkowski, K. Staniszewski, M. Pacek, Y. Wu, H. Michalewski, and P. Miło ́s, “Focused transformer: Contrastive training for context scaling,” arXiv preprint arXiv:2307.03170, 2023.
- [72] D. Mahan, R. Carlow, L. Castricato, N. Cooper, and C. Laforte, “Stable beluga models.” [Online]. Available: [https://huggingface.co/stabilityai/StableBeluga2](https:// huggingface.co/stabilityai/StableBeluga2)
- [73] Y. Tay, J. Wei, H. W. Chung, V. Q. Tran, D. R. So, S. Shakeri, X. Garcia, H. S. Zheng, J. Rao, A. Chowdhery et al., “Transcending scaling laws with 0.1% extra compute,” arXiv preprint arXiv:2210.11399, 2022.
- [74] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. Li, X. Wang, M. Dehghani, S. Brahma et al., “Scaling instructionfinetuned language models,” arXiv preprint arXiv:2210.11416, 2022.
- [75] R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen et al., “Palm 2 technical report,” arXiv preprint arXiv:2305.10403, 2023.
- [76] K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohl et al., “Large language models encode clinical knowledge,” arXiv preprint arXiv:2212.13138, 2022.
- [77] K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, L. Hou, K. Clark, S. Pfohl, H. Cole-Lewis, D. Neal et al., “Towards expertlevel medical question answering with large language models,” arXiv preprint arXiv:2305.09617, 2023.
- [78] J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Finetuned language models are zero-shot learners,” arXiv preprint arXiv:2109.01652, 2021.
- [79] J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young et al., “Scaling language models: Methods, analysis & insights from training gopher,” arXiv preprint arXiv:2112.11446, 2021.
- [80] V. Sanh, A. Webson, C. Raffel, S. H. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, T. L. Scao, A. Raja et al., “Multitask prompted training enables zero-shot task generalization,” arXiv preprint arXiv:2110.08207, 2021.
- [81] Y. Sun, S. Wang, S. Feng, S. Ding, C. Pang, J. Shang, J. Liu, X. Chen, Y. Zhao, Y. Lu et al., “Ernie 3.0: Large-scale knowledge enhanced pretraining for language understanding and generation,” arXiv preprint arXiv:2107.02137, 2021.
- [82] S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clark et al., “Improving language models by retrieving from trillions of tokens,” in International conference on machine learning. PMLR, 2022, pp. 2206–2240.
- [83] O. Lieber, O. Sharir, B. Lenz, and Y. Shoham, “Jurassic-1: Technical details and evaluation,” White Paper. AI21 Labs, vol. 1, p. 9, 2021.
- [84] N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, M. Krikun, Y. Zhou, A. W. Yu, O. Firat et al., “Glam: Efficient scaling of language models with mixture-of-experts,” in International Conference on Machine Learning. PMLR, 2022, pp. 5547–5569.
- [85] R. Thoppilan, D. De Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du et al., “Lamda: Language models for dialog applications,” arXiv preprint arXiv:2201.08239, 2022.
- [86] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al., “Opt: Open pre-trained transformer language models,” arXiv preprint arXiv:2205.01068, 2022.
- [87] R. Taylor, M. Kardas, G. Cucurull, T. Scialom, A. Hartshorn, E. Saravia, A. Poulton, V. Kerkez, and R. Stojnic, “Galactica: A large language model for science,” arXiv preprint arXiv:2211.09085, 2022.
- [88] E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with multi-turn program synthesis,” arXiv preprint arXiv:2203.13474, 2022.
- [89] S. Soltan, S. Ananthakrishnan, J. FitzGerald, R. Gupta, W. Hamza, H. Khan, C. Peris, S. Rawls, A. Rosenbaum, A. Rumshisky et al., “Alexatm 20b: Few-shot learning using a large-scale multilingual seq2seq model,” arXiv preprint arXiv:2208.01448, 2022.
- [90] A. Glaese, N. McAleese, M. Trebacz, J. Aslanides, V. Firoiu, T. Ewalds, M. Rauh, L. Weidinger, M. Chadwick, P. Thacker et al., “Improving alignment of dialogue agents via targeted human judgements,” arXiv preprint arXiv:2209.14375, 2022.
- [91] A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V. Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo et al., “Solving quantitative reasoning problems with language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 3843–3857, 2022.
- [92] Y. Tay, M. Dehghani, V. Q. Tran, X. Garcia, D. Bahri, T. Schuster, H. S. Zheng, N. Houlsby, and D. Metzler, “Unifying language learning paradigms,” arXiv preprint arXiv:2205.05131, 2022.
- [93] T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ili ́c, D. Hesslow, R. Castagn ́e, A. S. Luccioni, F. Yvon, M. Gall ́e et al., “Bloom: A 176bparameter open-access multilingual language model,” arXiv preprint arXiv:2211.05100, 2022.
- [94] A. Zeng, X. Liu, Z. Du, Z. Wang, H. Lai, M. Ding, Z. Yang, Y. Xu, W. Zheng, X. Xia et al., “Glm-130b: An open bilingual pre-trained model,” arXiv preprint arXiv:2210.02414, 2022.
- [95] S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff et al., “Pythia: A suite for analyzing large language models across training and scaling,” in International Conference on Machine Learning. PMLR, 2023, pp. 2397–2430.
- [96] S. Mukherjee, A. Mitra, G. Jawahar, S. Agarwal, H. Palangi, and A. Awadallah, “Orca: Progressive learning from complex explanation traces of gpt-4,” arXiv preprint arXiv:2306.02707, 2023.
- [97] R. Li, L. B. Allal, Y. Zi, N. Muennighoff, D. Kocetkov, C. Mou, M. Marone, C. Akiki, J. Li, J. Chim et al., “Starcoder: may the source be with you!” arXiv preprint arXiv:2305.06161, 2023.
- [98] S. Huang, L. Dong, W. Wang, Y. Hao, S. Singhal, S. Ma, T. Lv, L. Cui, O. K. Mohammed, Q. Liu et al., “Language is not all you need: Aligning perception with language models,” arXiv preprint arXiv:2302.14045, 2023.
- [99] G. Team, R. Anil, S. Borgeaud, Y. Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth et al., “Gemini: a family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2023.
- [100] W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar et al., “Inner monologue: Embodied reasoning through planning with language models,” arXiv preprint arXiv:2207.05608, 2022.
- [101] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti et al., “Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model,” arXiv preprint arXiv:2201.11990, 2022.
- [102] I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The longdocument transformer,” arXiv preprint arXiv:2004.05150, 2020.
- [103] S. Iyer, X. V. Lin, R. Pasunuru, T. Mihaylov, D. Simig, P. Yu, K. Shuster, T. Wang, Q. Liu, P. S. Koura et al., “Opt-iml: Scaling language model instruction meta learning through the lens of generalization,” arXiv preprint arXiv:2212.12017, 2022.
- [104] Y. Hao, H. Song, L. Dong, S. Huang, Z. Chi, W. Wang, S. Ma, and F. Wei, “Language models are general-purpose interfaces,” arXiv preprint arXiv:2206.06336, 2022.
- [105] Z. Sun, Y. Shen, Q. Zhou, H. Zhang, Z. Chen, D. Cox, Y. Yang, and C. Gan, “Principle-driven self-alignment of language models from scratch with minimal human supervision,” arXiv preprint arXiv:2305.03047, 2023.
- [106] W. E. team, “Palmyra-base Parameter Autoregressive Language Model,” https://dev.writer.com, 2023.
- [107] ——, “Camel-5b instructgpt,” https://dev.writer.com, 2023.
- [108] Yandex. Yalm. [Online]. Available: https://github.com/yandex/ YaLM-100B
- [109] M. Team et al., “Introducing mpt-7b: a new standard for open-source, commercially usable llms,” 2023.
- [110] A. Mitra, L. D. Corro, S. Mahajan, A. Codas, C. Simoes, S. Agarwal, X. Chen, A. Razdaibiedina, E. Jones, K. Aggarwal, H. Palangi, G. Zheng, C. Rosset, H. Khanpour, and A. Awadallah, “Orca 2: Teaching small language models how to reason,” 2023.
- [111] L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y. Yang, J. Callan, and G. Neubig, “Pal: Program-aided language models,” in International Conference on Machine Learning. PMLR, 2023, pp. 10 764–10 799.
- [112] Anthropic. claude. [Online]. Available: https://www.anthropic.com/ news/introducing-claude
- [113] E. Nijkamp, H. Hayashi, C. Xiong, S. Savarese, and Y. Zhou, “Codegen2: Lessons for training llms on programming and natural languages,” arXiv preprint arXiv:2305.02309, 2023.
- [114] L. Tunstall, E. Beeching, N. Lambert, N. Rajani, K. Rasul, Y. Belkada, S. Huang, L. von Werra, C. Fourrier, N. Habib et al., “Zephyr: Direct distillation of lm alignment,” arXiv preprint arXiv:2310.16944, 2023.
- [115] X. team. Grok. [Online]. Available: https://grok.x.ai/
- [116] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,” arXiv preprint arXiv:2308.12966, 2023.
- [117] mixtral. mixtral. [Online]. Available: https://mistral.ai/news/ mixtral-of-experts/
- [118] D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y. Pei, A. Nourbakhsh, and X. Liu, “Docllm: A layout-aware generative language model for multimodal document understanding,” 2023.
- [119] D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y. Wu, Y. K. Li, F. Luo, Y. Xiong, and W. Liang, “Deepseek-coder: When the large language model meets programming – the rise of code intelligence,” 2024.
- [120] F. Wan, X. Huang, D. Cai, X. Quan, W. Bi, and S. Shi, “Knowledge fusion of large language models,” 2024.
- [121] P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,” 2024.
- [122] C. Wu, Y. Gan, Y. Ge, Z. Lu, J. Wang, Y. Feng, P. Luo, and Y. Shan, “Llama pro: Progressive llama with block expansion,” 2024.
- [123] X. Amatriain, A. Sankar, J. Bing, P. K. Bodigutla, T. J. Hazen, and M. Kazi, “Transformer models: an introduction and catalog,” 2023.
- [124] G. Penedo, Q. Malartic, D. Hesslow, R. Cojocaru, A. Cappelli, H. Alobeidli, B. Pannier, E. Almazrouei, and J. Launay, “The refinedweb dataset for falcon llm: outperforming curated corpora with web data, and web data only,” arXiv preprint arXiv:2306.01116, 2023.
- [125] D. Hernandez, T. Brown, T. Conerly, N. DasSarma, D. Drain, S. ElShowk, N. Elhage, Z. Hatfield-Dodds, T. Henighan, T. Hume et al., “Scaling laws and interpretability of learning from repeated data,” arXiv preprint arXiv:2205.10487, 2022.
- [126] P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” arXiv preprint arXiv:1803.02155, 2018.
- [127] J. Su, Y. Lu, S. Pan, B. Wen, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,” arXiv preprint arXiv:2104.09864, 2021.
- [128] O. Press, N. A. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,” arXiv preprint arXiv:2108.12409, 2021.
- [129] G. Ke, D. He, and T.-Y. Liu, “Rethinking positional encoding in language pre-training,” arXiv preprint arXiv:2006.15595, 2020.
- [130] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” arXiv preprint arXiv:1701.06538, 2017.
- [131] W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” The Journal of Machine Learning Research, vol. 23, no. 1, pp. 5232–5270, 2022.
- [132] R. K. Mahabadi, S. Ruder, M. Dehghani, and J. Henderson, “Parameter-efficient multi-task fine-tuning for transformers via shared hypernetworks,” 2021.
- [133] S. Zhang, L. Dong, X. Li, S. Zhang, X. Sun, S. Wang, J. Li, R. Hu, T. Zhang, F. Wu, and G. Wang, “Instruction tuning for large language models: A survey,” 2023.
- [134] S. Mishra, D. Khashabi, C. Baral, and H. Hajishirzi, “Cross-task generalization via natural language crowdsourcing instructions,” arXiv preprint arXiv:2104.08773, 2021.
- [135] Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language model with self generated instructions,” arXiv preprint arXiv:2212.10560, 2022.
- [136] K. Ethayarajh, W. Xu, D. Jurafsky, and D. Kiela. Kto. [Online]. Available: https://github.com/ContextualAI/HALOs/blob/main/assets/ report.pdf
- [137] P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” Advances in neural information processing systems, vol. 30, 2017.
- [138] H. Lee, S. Phatale, H. Mansoor, K. Lu, T. Mesnard, C. Bishop, V. Carbune, and A. Rastogi, “Rlaif: Scaling reinforcement learning from human feedback with ai feedback,” arXiv preprint arXiv:2309.00267, 2023.
- [139] R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” arXiv preprint arXiv:2305.18290, 2023.
- [140] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “Zero: Memory optimizations toward training trillion parameter models,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16.
- [141] B. Peng, E. Alcaide, Q. Anthony, A. Albalak, S. Arcadinho, H. Cao, X. Cheng, M. Chung, M. Grella, K. K. GV et al., “Rwkv: Reinventing rnns for the transformer era,” arXiv preprint arXiv:2305.13048, 2023.
- [142] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021.
- [143] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [144] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
- [145] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,” ACM Comput. Surv., vol. 55, no. 12, mar 2023. [Online]. Available: https://doi.org/10.1145/3571730
- [146] N. McKenna, T. Li, L. Cheng, M. J. Hosseini, M. Johnson, and M. Steedman, “Sources of hallucination by large language models on inference tasks,” 2023.
- [147] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013
- [148] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, P. Isabelle, E. Charniak, and D. Lin, Eds. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics, Jul. 2002, pp. 311318. [Online]. Available: https://aclanthology.org/P02-1040
- [149] B. Dhingra, M. Faruqui, A. Parikh, M.-W. Chang, D. Das, and W. Cohen, “Handling divergent reference texts when evaluating table-to-text generation,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. Marquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 4884–4895. [Online]. Available: https://aclanthology.org/P19-1483
- [150] Z. Wang, X. Wang, B. An, D. Yu, and C. Chen, “Towards faithful neural table-to-text generation with content-matching constraints,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault, Eds. Online: Association for Computational Linguistics, Jul. 2020, pp. 1072–1086. [Online]. Available: https: //aclanthology.org/2020.acl-main.101
- [151] H. Song, W.-N. Zhang, J. Hu, and T. Liu, “Generating persona consistent dialogues by exploiting natural language inference,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, pp. 8878–8885, Apr. 2020.
- [152] O. Honovich, L. Choshen, R. Aharoni, E. Neeman, I. Szpektor, and O. Abend, “q2: Evaluating factual consistency in knowledgegrounded dialogues via question generation and question answering,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, M.-F. Moens, X. Huang, L. Specia, and S. W.-t. Yih, Eds. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 7856–7870. [Online]. Available: https://aclanthology.org/2021.emnlp-main.619
- [153] N. Dziri, H. Rashkin, T. Linzen, and D. Reitter, “Evaluating attribution in dialogue systems: The BEGIN benchmark,” Transactions of the Association for Computational Linguistics, vol. 10, pp. 1066–1083, 2022. [Online]. Available: https://aclanthology.org/2022.tacl-1.62
- [154] S. Santhanam, B. Hedayatnia, S. Gella, A. Padmakumar, S. Kim, Y. Liu, and D. Z. Hakkani-T ̈ur, “Rome was built in 1776: A case study on factual correctness in knowledge-grounded response generation,” ArXiv, vol. abs/2110.05456, 2021.
- [155] S. Min, K. Krishna, X. Lyu, M. Lewis, W. tau Yih, P. W. Koh, M. Iyyer, L. Zettlemoyer, and H. Hajishirzi, “Factscore: Fine-grained atomic evaluation of factual precision in long form text generation,” 2023.
- [156] D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, and M. Young, “Machine learning: The high interest credit card of technical debt,” in SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop), 2014.
- [157] Z. Zhang, A. Zhang, M. Li, and A. Smola, “Automatic chain of thought prompting in large language models,” 2022.
- [158] S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y. Cao, and K. Narasimhan, “Tree of thoughts: Deliberate problem solving with large language models,” 2023.
- [159] P. Manakul, A. Liusie, and M. J. F. Gales, “Selfcheckgpt: Zeroresource black-box hallucination detection for generative large language models,” 2023.
- [160] N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” 2023.
- [161] S. J. Zhang, S. Florin, A. N. Lee, E. Niknafs, A. Marginean, A. Wang, K. Tyser, Z. Chin, Y. Hicke, N. Singh, M. Udell, Y. Kim, T. Buonassisi, A. Solar-Lezama, and I. Drori, “Exploring the mit mathematics and eecs curriculum using large language models,” 2023.
- [162] T. Wu, E. Jiang, A. Donsbach, J. Gray, A. Molina, M. Terry, and C. J. Cai, “Promptchainer: Chaining large language model prompts through visual programming,” 2022.
- [163] Y. Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba, “Large language models are human-level prompt engineers,” 2023.
- [164] P. S. H. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Ku ̈ttler, M. Lewis, W. Yih, T. Rockt ̈aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” CoRR, vol. abs/2005.11401, 2020. [Online]. Available: https://arxiv.org/abs/2005.11401
- [165] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” arXiv preprint arXiv:2312.10997, 2023.
- [166] A. W. Services. (Year of publication, e.g., 2023) Question answering using retrieval augmented generation with foundation models in amazon sagemaker jumpstart. Accessed: Date of access, e.g., December 5, 2023. [Online]. Available: https://shorturl.at/dSV47
- [167] S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, and X. Wu, “Unifying large language models and knowledge graphs: A roadmap,” arXiv preprint arXiv:2306.08302, 2023.
- [168] Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y. Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” 2023.
- [169] T. Schick, J. Dwivedi-Yu, R. Dessı, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” 2023.
- [170] B. Paranjape, S. Lundberg, S. Singh, H. Hajishirzi, L. Zettlemoyer, and M. T. Ribeiro, “Art: Automatic multi-step reasoning and tool-use for large language models,” 2023.
- [171] Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface,” arXiv preprint arXiv:2303.17580, 2023.
- [172] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou et al., “The rise and potential of large language model based agents: A survey,” arXiv preprint arXiv:2309.07864, 2023.
- [173] L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Lin et al., “A survey on large language model based autonomous agents,” arXiv preprint arXiv:2308.11432, 2023.
- [174] Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkar, R. Taori, Y. Noda, D. Terzopoulos, Y. Choi, K. Ikeuchi, H. Vo, L. FeiFei, and J. Gao, “Agent ai: Surveying the horizons of multimodal interaction,” arXiv preprint arXiv:2401.03568, 2024.
- [175] B. Xu, Z. Peng, B. Lei, S. Mukherjee, Y. Liu, and D. Xu, “Rewoo: Decoupling reasoning from observations for efficient augmented language models,” 2023.
- [176] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” 2023.
- [177] V. Nair, E. Schumacher, G. Tso, and A. Kannan, “Dera: Enhancing large language model completions with dialog-enabled resolving agents,” 2023.
- [178] Y. Chang, X. Wang, J. Wang, Y. Wu, L. Yang, K. Zhu, H. Chen, X. Yi, C. Wang, Y. Wang, W. Ye, Y. Zhang, Y. Chang, P. S. Yu, Q. Yang, and X. Xie, “A survey on evaluation of large language models,” 2023.
- [179] T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M.-W. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov, “Natural questions: A benchmark for question answering research,” Transactions of the Association for Computational Linguistics, vol. 7, pp. 452–466, 2019. [Online]. Available: https://aclanthology.org/Q19-1026
- [180] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” 2021.
- [181] J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le et al., “Program synthesis with large language models,” arXiv preprint arXiv:2108.07732, 2021.
- [182] E. Choi, H. He, M. Iyyer, M. Yatskar, W.-t. Yih, Y. Choi, P. Liang, and L. Zettlemoyer, “QuAC: Question answering in context,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Brussels, Belgium: Association for Computational Linguistics, Oct.-Nov. 2018, pp. 2174–2184. [Online]. Available: https://aclanthology.org/D18-1241
- [183] D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt, “Measuring coding challenge competence with apps,” NeurIPS, 2021.
- [184] V. Zhong, C. Xiong, and R. Socher, “Seq2sql: Generating structured queries from natural language using reinforcement learning,” arXiv preprint arXiv:1709.00103, 2017.
- [185] M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer, “TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), R. Barzilay and M.-Y. Kan, Eds. Vancouver, Canada: Association for Computational Linguistics, Jul. 2017, pp. 1601–1611. [Online]. Available: https://aclanthology.org/P17-1147
- [186] G. Lai, Q. Xie, H. Liu, Y. Yang, and E. Hovy, “RACE: Large-scale ReAding comprehension dataset from examinations,” in Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, M. Palmer, R. Hwa, and S. Riedel, Eds. Copenhagen, Denmark: Association for Computational Linguistics, Sep. 2017, pp. 785–794. [Online]. Available: https://aclanthology.org/D17-1082
- [187] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “SQuAD: 100,000+ questions for machine comprehension of text,” in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, J. Su, K. Duh, and X. Carreras, Eds. Austin, Texas: Association for Computational Linguistics, Nov. 2016, pp. 2383–2392. [Online]. Available: https://aclanthology.org/D16-1264
- [188] C. Clark, K. Lee, M. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova, “Boolq: Exploring the surprising difficulty of natural yes/no questions,” CoRR, vol. abs/1905.10044, 2019. [Online]. Available: http://arxiv.org/abs/1905.10044
- [189] D. Khashabi, S. Chaturvedi, M. Roth, S. Upadhyay, and D. Roth, “Looking beyond the surface:a challenge set for reading comprehension over multiple sentences,” in Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL), 2018.
- [190] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” CoRR, vol. abs/2110.14168, 2021. [Online]. Available: https: //arxiv.org/abs/2110.14168
- [191] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the MATH dataset,” CoRR, vol. abs/2103.03874, 2021. [Online]. Available: https://arxiv.org/abs/2103.03874
- [192] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “Hellaswag: Can a machine really finish your sentence?” 2019.
- [193] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the AI2 reasoning challenge,” CoRR, vol. abs/1803.05457, 2018. [Online]. Available: http://arxiv.org/abs/1803.05457
- [194] Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi, “PIQA: reasoning about physical commonsense in natural language,” CoRR, vol. abs/1911.11641, 2019. [Online]. Available: http://arxiv.org/abs/ 1911.11641
- [195] M. Sap, H. Rashkin, D. Chen, R. L. Bras, and Y. Choi, “Socialiqa: Commonsense reasoning about social interactions,” CoRR, vol. abs/1904.09728, 2019. [Online]. Available: http://arxiv.org/abs/1904. 09728
- [196] T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal, “Can a suit of armor conduct electricity? A new dataset for open book question answering,” CoRR, vol. abs/1809.02789, 2018. [Online]. Available: http://arxiv.org/abs/1809.02789
- [197] S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” arXiv preprint arXiv:2109.07958, 2021.
- [198] Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” CoRR, vol. abs/1809.09600, 2018. [Online]. Available: http://arxiv.org/abs/1809.09600
- [199] Y. Zhuang, Y. Yu, K. Wang, H. Sun, and C. Zhang, “Toolqa: A dataset for llm question answering with external tools,” arXiv preprint arXiv:2306.13304, 2023.
- [200] D. Chen, J. Bolton, and C. D. Manning, “A thorough examination of the cnn/daily mail reading comprehension task,” in Association for Computational Linguistics (ACL), 2016.
- [201] R. Nallapati, B. Zhou, C. Gulcehre, B. Xiang et al., “Abstractive text summarization using sequence-to-sequence rnns and beyond,” arXiv preprint arXiv:1602.06023, 2016.
- [202] Y. Bai and D. Z. Wang, “More than reading comprehension: A survey on datasets and metrics of textual question answering,” arXiv preprint arXiv:2109.12264, 2021.
- [203] H.-Y. Huang, E. Choi, and W.-t. Yih, “Flowqa: Grasping flow in history for conversational machine comprehension,” arXiv preprint arXiv:1810.06683, 2018.
- [204] S. Lee, J. Lee, H. Moon, C. Park, J. Seo, S. Eo, S. Koo, and H. Lim, “A survey on evaluation metrics for machine translation,” Mathematics, vol. 11, no. 4, p. 1006, 2023.
- [205] J. Li, X. Cheng, W. X. Zhao, J.-Y. Nie, and J.-R. Wen, “Halueval: A large-scale hallucination evaluation benchmark for large language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 6449–6464.
- [206] Simon Mark Hughes, “Hughes hallucination evaluation model (hhem) leaderboard,” 2024, https://huggingface.co/spaces/vectara/ Hallucination-evaluation-leaderboard, Last accessed on 2024-01-21.
- [207] J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” arXiv preprint arXiv:2307.10169, 2023.
- [208] S. Gunasekar, Y. Zhang, J. Aneja, C. C. T. Mendes, A. Del Giorno, S. Gopi, M. Javaheripi, P. Kauffmann, G. de Rosa, O. Saarikivi et al., “Textbooks are all you need,” arXiv preprint arXiv:2306.11644, 2023.
- [209] Y. Li, S. Bubeck, R. Eldan, A. Del Giorno, S. Gunasekar, and Y. T. Lee, “Textbooks are all you need ii: phi-1.5 technical report,” arXiv preprint arXiv:2309.05463, 2023.
- [210] M. Poli, S. Massaroli, E. Nguyen, D. Y. Fu, T. Dao, S. Baccus, Y. Bengio, S. Ermon, and C. Re ́, “Hyena hierarchy: Towards larger convolutional language models,” 2023.
- [211] M. Poli, J. Wang, S. Massaroli, J. Quesnelle, E. Nguyen, and A. Thomas, “StripedHyena: Moving Beyond Transformers with Hybrid Signal Processing Models,” 12 2023. [Online]. Available: https://github.com/togethercomputer/stripedhyena
- [212] D. Y. Fu, S. Arora, J. Grogan, I. Johnson, S. Eyuboglu, A. W. Thomas, B. Spector, M. Poli, A. Rudra, and C. R ́e, “Monarch mixer: A simple sub-quadratic gemm-based architecture,” 2023.
- [213] G. J. McLachlan, S. X. Lee, and S. I. Rathnayake, “Finite mixture models,” Annual review of statistics and its application, vol. 6, pp. 355–378, 2019.
- [214] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” arXiv preprint arXiv:2304.08485, 2023.
- [215] S. Liu, H. Cheng, H. Liu, H. Zhang, F. Li, T. Ren, X. Zou, J. Yang, H. Su, J. Zhu, L. Zhang, J. Gao, and C. Li, “Llava-plus: Learning to use tools for creating multimodal agents,” arXiv preprint arXiv:2311.05437, 2023.
- [216] S. Wu, H. Fei, L. Qu, W. Ji, and T.-S. Chua, “Next-gpt: Any-to-any multimodal llm,” arXiv preprint arXiv:2309.05519, 2023.
- [217] N. N. Khasmakhi, M. Asgari-Chenaghlu, N. Asghar, P. Schaer, and D. Z ̈uhlke, “Convgenvismo: Evaluation of conversational generative vision models,” 2023.
- [218] N. Alshahwan, J. Chheda, A. Finegenova, B. Gokkaya, M. Harman, I. Harper, A. Marginean, S. Sengupta, and E. Wang, “Automated unit test improvement using large language models at meta,” arXiv preprint arXiv:2402.09171, 2024.
- [219] L. Sun, Y. Huang, H. Wang, S. Wu, Q. Zhang, C. Gao, Y. Huang, W. Lyu, Y. Zhang, X. Li et al., “Trustllm: Trustworthiness in large language models,” arXiv preprint arXiv:2401.05561, 2024.
- [220] M. Josifoski, L. Klein, M. Peyrard, Y. Li, S. Geng, J. P. Schnitzler, Y. Yao, J. Wei, D. Paul, and R. West, “Flows: Building blocks of reasoning and collaborating ai,” arXiv preprint arXiv:2308.01285, 2023.
- [221] Microsoft. Deepspeed. [Online]. Available: https://github.com/ microsoft/DeepSpeed
- [222] HuggingFace. Transformers. [Online]. Available: https://github.com/ huggingface/transformers
- [223] Nvidia. Megatron. [Online]. Available: https://github.com/NVIDIA/ Megatron-LM
- [224] BMTrain. Bmtrain. [Online]. Available: https://github.com/OpenBMB/ BMTrain
- [225] EleutherAI. gpt-neox. [Online]. Available: https://github.com/ EleutherAI/gpt-neox
- [226] microsoft. Lora. [Online]. Available: https://github.com/microsoft/ LoRA
- [227] ColossalAI. Colossalai. [Online]. Available: https://github.com/ hpcaitech/ColossalAI
- [228] FastChat. Fastchat. [Online]. Available: https://github.com/lm-sys/ FastChat
- [229] skypilot. skypilot. [Online]. Available: https://github.com/skypilot-org/ skypilot
- [230] vllm. vllm. [Online]. Available: https://github.com/vllm-project/vllm
- [231] huggingface. text-generation-inference. [Online]. Available: https: //github.com/huggingface/text-generation-inference
- [232] langchain. langchain. [Online]. Available: https://github.com/ langchain-ai/langchain
- [233] bentoml. Openllm. [Online]. Available: https://github.com/bentoml/ OpenLLM
- [234] embedchain. embedchain. [Online]. Available: https://github.com/ embedchain/embedchain
- [235] microsoft. autogen. [Online]. Available: https://github.com/microsoft/ autogen
- [236] babyagi. babyagi. [Online]. Available: https://github.com/ yoheinakajima/babyagi
- [237] guidance. guidance. [Online]. Available: https://github.com/ guidance-ai/guidance
- [238] prompttools. prompttools. [Online]. Available: https://github.com/ hegelai/prompttools
- [239] promptfoo. promptfoo. [Online]. Available: https://github.com/ promptfoo/promptfoo
- [240] facebook. faiss. [Online]. Available: https://github.com/ facebookresearch/faiss
- [241] milvus. milvus. [Online]. Available: https://github.com/milvus-io/ milvus
- [242] qdrant. qdrant. [Online]. Available: https://github.com/qdrant/qdrant
- [243] weaviate. weaviate. [Online]. Available: https://github.com/weaviate/ weaviate
- [244] llama index. llama-index. [Online]. Available: https://github.com/ run-llama/llama index

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)