RoVer:机器人奖励模型作为VLA模型的测试-时验证器
25年10月来自中科院深圳先进技术院、鹏城实验室、中山大学、南洋理工、上海AI实验室、中科院大学和拓元智慧的论文“RoVer: Robot Reward Model As Test-time Verifier For Vision-language-action Model”。视觉-语言-动作(VLA)模型已成为具身智能领域的重要范式,然而,性能的进一步提升通常依赖于训练数据和模型规模的扩展——这
25年10月来自中科院深圳先进技术院、鹏城实验室、中山大学、南洋理工、上海AI实验室、中科院大学和拓元智慧的论文“RoVer: Robot Reward Model As Test-time Verifier For Vision-language-action Model”。
视觉-语言-动作(VLA)模型已成为具身智能领域的重要范式,然而,性能的进一步提升通常依赖于训练数据和模型规模的扩展——这种方法对于机器人技术而言成本过高,并且从根本上受到数据采集成本的限制。利用RoVer解决这一限制。RoVer是一个具身化的测试-时规模化框架,它使用机器人过程奖励模型(PRM)作为测试-时验证器,在不修改现有VLA模型架构或权重的情况下增强其性能。具体而言,RoVer (i) 分配基于标量的进程奖励来评估候选动作的可靠性,以及 (ii) 预测候选动作扩展/细化的动作空间方向。在推理过程中,RoVer从基础策略同时生成多个候选动作,沿着PRM预测的方向扩展这些动作,然后使用PRM对所有候选动作进行评分,以选择最优动作执行。值得注意的是,通过缓存共享感知特征,该方法可以分摊感知成本,并在相同的测试时间计算预算下评估更多候选对象。本质上,该方法有效地将可用计算资源转化为更优的动作决策,在不增加额外训练开销的情况下实现了测试-时间规模化的优势。
视觉-语言-动作模型中的测试-时规模化。内部测试-时规模化:近期研究增强视觉-语言-动作模型(VLA)在推理阶段的内部思考:具身思维链(CoT)(Zawalski ,2025;Ji ,2025;Sun ,2024;Zhou ,2025)方法在动作生成之前强制执行多步骤推理,以改进任务分解和规划,通常通过扩展训练数据集并添加推理标注来实现。CoT-VLA 和 UniVLA(Zhao ,2025;Bu ,2025b;Wang ,2025)在推理过程中加入未来帧预测;OneTwo-VLA(Lin ,2025)使用 [BOR] 和 [BOA] token来自适应地决定何时进行推理,何时进行动作。然而,上述大部分工作都需要对训练数据集进行额外的标注。外部测试-时规模化:与在策略内部进行推理的内部TTS不同,外部TTS通过引入一个独立的奖励/价值验证器,将搜索和评分与策略解耦。该验证器在推理阶段评估候选动作,从而在不修改骨干权重的情况下指导候选生成。目前已有研究探索这一方向:Hume(Song,2025)使用价值头增强双系统VLA,以驱动重复采样和级联去噪(候选数量固定);而RoboMonkey(Kwok,2025)则研究大规模骨干网络和合成数据的奖励建模。
本文用外部过程奖励模型(PRM)增强冻结的VLA。给定观测数据、语言信息和候选动作,PRM会输出一个标量分数和一个改进方向。在推理阶段,策略建议通过在一定角度范围内沿预测方向进行采样来扩展,并执行PRM下得分最高的动作。观测数据、语言信息和状态特征在每个步骤中计算一次并缓存,以便在候选动作之间重复使用(如图所示)。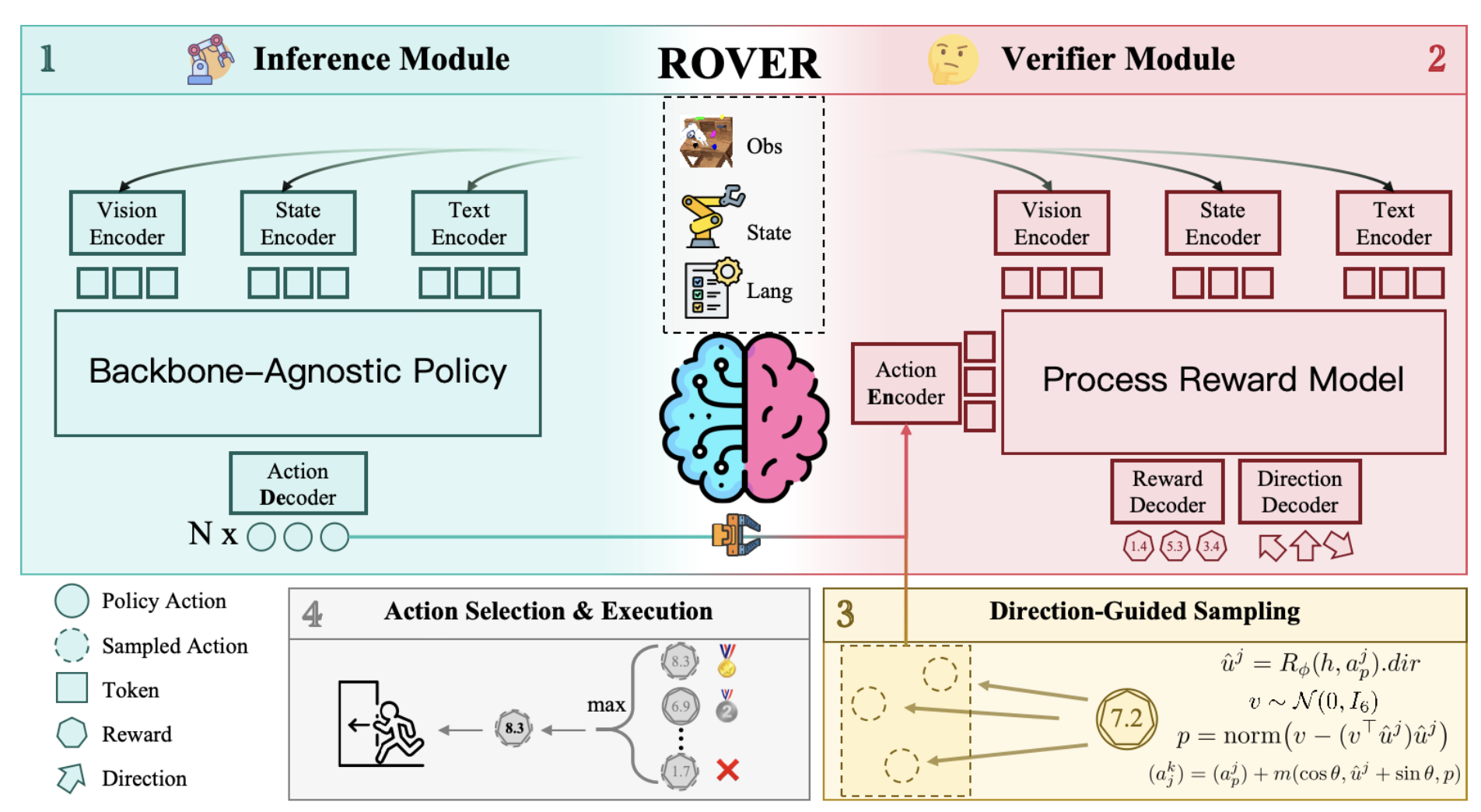
测试-时规模化。给定一个基础策略 π_θ 和一个验证器 R_φ,从 π_θ 中获取策略动作 a_p,并通过高斯噪声采样将其扩展为候选集 A = {a0 = a_p, a1, a2,…}。PRM 验证器 R_φ 使用 ri = R_φ(h, ai) 对每个候选动作进行评分,然后执行 a⋆ = arg max r(h, a)。
ROVER
RoVer 使用紧凑型过程奖励模型 (PRM) 实现外部测试-时规模化,该模型对候选动作进行评分,并预测动作子空间中的细化方向。对于在局部坐标系中定义的策略,动作在扩展和评分之前会映射到世界坐标系。
模型架构
R_φ 接收同步的多模态输入 o_t(例如,第三人称视角和手眼 RGB 图像、机器人状态和语言token)以及候选动作 ai,并输出标量过程奖励 ri 和动作空间方向 di。该模型架构遵循 GPT-2 风格(Radford,2019),并使用 GR-1 的预训练权重进行初始化(Wu,2023)。具体来说,图像编码器由预训练的 MAE 模型(He,2021)初始化,文本编码器由 CLIP 文本编码器(Radford,2021)初始化。该架构原则上支持最多 10 个时间步的历史数据作为输入。然而,为了更好地实现即插即用和加快推理速度,将输入限制为当前时间步的观测值。在初始化的主干网络之上,添加用于奖励和方向预测的额外节点。由于所有候选动作在控制步骤中共享相同的观测值、语言和状态,计算这些感知特征一次,并将其作为共享感知缓存在所有候选动作之间重复使用,同时对每个候选动作进行编码以分摊计算量。与 RoboMonkey(Kwok,2025)中微调 70 亿参数的主干网络相比,RoVer 总共需要 2 亿个参数,训练仅需 4000 万个参数。如图所示: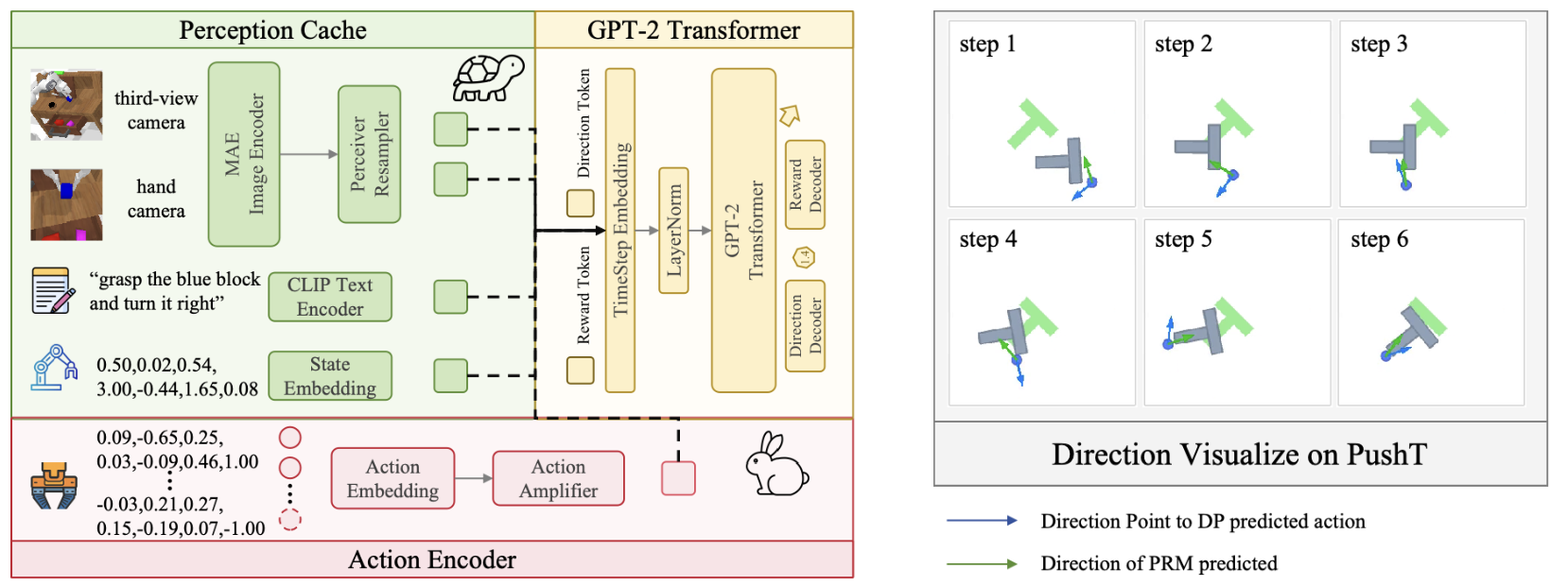
动作放大器:为了使候选动作之间的细微差异更加清晰可辨,在将动作嵌入与观察/语言token融合之前,对其应用了一个轻量级的动作放大器。该放大器是一个紧凑的多层感知器(MLP),采用 GELU 和 LayerNorm 映射,映射方向为 RH → R2H → RH,从而重新调整动作通道,使得动作子空间中的细粒度差异在强大的冻结感知/语言骨干网络下仍然显著。这种对比度增强器提高 PRM 区分和排序相邻动作的能力,同时将推理开销降至最低。为了便于理解,如上图的右侧面板可视化当底层基础策略输出平面 (x, y) 动作时,PushT 上的预测二维方向场。
模型训练
奖励模型 R_φ 的训练目标是使其能够区分两个候选动作中哪一个更优。在 RoVer 中,如果一个动作与专家动作的均方根误差 (RMSE) 距离小于另一个动作,则认为该动作更优。为了准备训练数据,首先分析策略动作 A_p 和专家动作样本 A_e 之间的分布差距。基于此分析,设定一个基准噪声尺度 σ_base = 0.1,并用它来构建锚动作 a_anc。给定专家演示 h,a_e = [apose_e, g_e ],围绕 a_e 构建局部动作元组,以获得信息丰富的偏好标签和方向监督。
方向引导和锚点中心采样。在早期实验中,简单地围绕 a_e 对噪声专家动作 a_en 进行采样会导致性能不佳。为了更好地模拟测试时的采样行为,引入锚动作的概念。通过扰动 6D 姿态子空间中的专家动作来构建锚点噪声(针对 CALVIN):
apose_anc = apose_e + n, n ∼ N (0, σ2_base, I_6), g_anc = g_e.
然后,定义从锚点动作到专家动作的真实方向向量 u_gt,利用 u_gt,定义正交超平面,该超平面将空间划分为两个半空间。
令 d_0 为 6D 姿态子空间中 a_anc 和 a_e 之间的均方根误差 (RMSE) 距离。定义自适应噪声尺度 σ_adapt,以控制候选动作围绕 a_anc 的分布范围。在实现中,对 ε_b , ε_w ∼ N (0, σ2_adapt, I_6) 进行采样,并将它们投影到正确的半空间:better,worse。由此得到:
apose_better = apose_anc +ε_b, apose_worse = apose_anc +ε_w,
其中,机械臂状态继承自 a_anc。根据构造,a_better 比 a_anc 更可能接近专家动作,而 a_worse 则更远离专家动作。
监督与目标:对于每个以锚点为中心的元组 {anchor, better, worse},监督两个信号。对于方向监督,从采样动作 a_x 指向专家动作的真实单位向量为 u_gt(a_e, a_x)。
令 uˆ = normalize (d_φ(h,a_x) ) 表示预测方向。最小化余弦偏差 L_dir,该偏差是对元组中所有采样动作取平均值得到的。对于奖励监督,令 r(a) = R_φ(h, a) 表示 PRM 得分。对于元组中每个有序对 i ≻ j,其中 a_i 比 a_j 更接近专家动作,应用 Bradley-Terry 偏好损失(Bradley & Terry, 1952):
L_rew(i ≻ j) = - log σ(r(a_i−r(a_j))
并将 L_rew 定义为所有此类有序对的平均值。
最终的训练目标结合这两个损失:
L_total = λ_dir L_dir + λ_rew L_rew,
其中 λ_dir 和 λ_rew 用于平衡两个损失。在优化过程中使用标准梯度裁剪。对于验证,跟踪余弦对齐、角度误差以及 PRM 分数相对于动作-专家距离的单调性。
方向引导的测试-时规模化
在推理阶段,RoVer 通过将策略动作扩展为一组候选动作,并在 PRM 指导下选择最佳动作,来增强冻结的 VLA 策略。与训练阶段的关键区别在于,候选动作并非来自专家动作 a_e,而是来自策略动作 a_p,并且仅在预测方向 uˆ 的引导下探索动作空间的“较好(better)”一侧。实现两种采样策略并进行比较:i) 随机采样:在无引导的情况下,用高斯噪声扰动 a_p;ii) 方向引导采样:沿着 PRM 预测的方向进行采样,从而扩展 a_p。
此过程将额外的测试-时计算转化为更优的动作选择。随机采样虽然探索范围广,但效率低下,而方向引导采样则利用 PRM 的预测方向将候选动作集中在有希望的区域,从而在相同的预算下获得更好的性能。
总结的算法如下:

实验设置:对于 RoVer,复用 GR-1 骨干架构作为验证器,并将原始动作token替换为奖励 token和方向token。总参数量为 0.2B,其中只有 4000 万个参数可训练——其余参数来自 MAE 和 CLIP 文本编码器,并被冻结。奖励模型在 CALVIN ABC→D 训练集上训练 100 个 epoch,用最终检查点在所有骨干网络上进行评估。重要的是,仅对 20% 的训练集进行采样,这表明 RoVer 也具有训练效率。研究以下问题:
Q1(与骨干网络无关的增益):RoVer 是否始终优于不同的预训练基线模型(GR-1、Dita、MoDE;以及真实机器人上的 DP)?
Q2(扩展性和采样效率):性能如何随策略提案数量 N 和每个提案的引导扩展预算 M 而扩展?在候选预算 K=N+M 固定的情况下,方向引导采样是否比非引导高斯扩展更有效?
Q3(推理效率):共享感知缓存能否分摊计算量并提高测试时的吞吐量/延迟?
基线方法:总结三个基线方法,并重点介绍将它们与 RoVer 集成时的测试时注意事项。除非另有说明,RoVer 在所有骨干网络上应用统一的候选处理方法:(i)扩展噪声仅注入到 6D 机械臂姿态分量中;(ii)夹爪尺寸不添加噪声,而是通过对 N 个基线提案进行简单投票来选择;以及(iii)感知特征在每个步骤中预编码一次(预编码),并在候选方案之间重复使用。
GR-1(Wu,2023)是一种 GPT 风格的轨迹模型,它以多视图 RGB 和语言为条件,自回归地预测末端执行器增量(6D 机械臂姿态增量加上夹爪标量)。在推理阶段,为每个控制步骤抽取 N 个随机提议,并可选择将每个动作扩展到 PRM 预测方向周围的有界角度区域内,然后根据 PRM 对所有候选动作进行排序。由于 GR-1 本身在世界坐标系增量中运行,因此无需额外的坐标系转换。
Dita(Hou,2025)是一种扩散transformer策略,它预测局部末端执行器坐标系中的相对运动(位置和欧拉角增量),并使用当前末端执行器位姿将其转换为世界坐标系增量。在 RoVer 环境下,首先在局部坐标系中采样 N 个策略动作,将每个动作转换为世界坐标系动作,然后在世界坐标系中进行噪声扩展,以与 PRM 的世界坐标系方向引导对齐。
MoDE(Reuss,2025)是一种带有混合专家去噪器的扩散transformer,它输出一个短的动作块(一系列未来动作)。在 RoVer 测试-时规模化过程中,绘制多个候选块,并通过对每个块的第一个动作(可选地在其 6D 臂组件进行方向引导扩展后)进行评分,与 PRM 进行交互,从而选择执行的动作。其他块执行策略是正交的,此处省略。
Q1:与骨干无关的性能提升。在不重新训练基础策略的情况下,将同一个 RoVer 验证器接入不同的骨干网络即可获得一致的性能提升(下表所示)。对于平均链长,GR-1 从 3.19 提升至 3.33,Dita 从 3.61 提升至 3.84,MoDE 从 4.01 提升至 4.12。从长期成功率 (SR@5) 来看,GR-1 从 41.5% 提升至 48.7% (+17.4%),而 Dita 从 50.0% 提升至 59.2% (+18.4%)。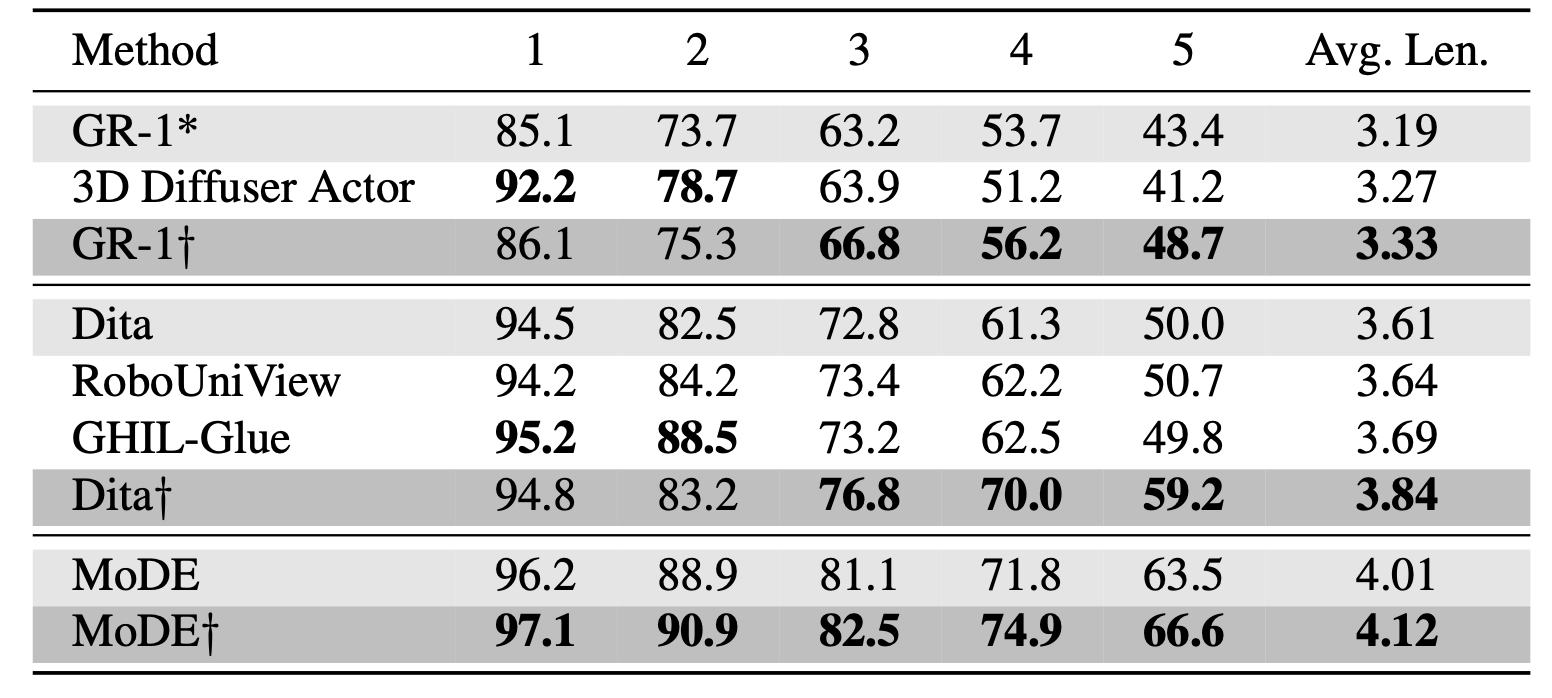
Q2:方向引导的测试-时规模化。从统一的计算视角研究规模化:给定总候选预算 K=N+M(策略提议数 N 和方向引导扩展数 M),性能通常随 K 的增加而提高,方向引导 (DG) 通过聚焦探索进一步提高样本效率。经验表明,首先增加 N 可以通过多样化策略模式在小预算下获得显著提升;然后适度增加 M 可以优化有希望的提议并带来额外的改进。在 K 相等的情况下,DG 在 GR-1 和 Dita 数据集上始终优于无引导的高斯扩展,这与方向引导的预期作用一致。
然而,对于 MoDE,并非所有设置下的性能提升都始终更高。将其归因于块-步长不匹配:MoDE 输出短动作块,而 PRM 是按时间步进行训练和应用的。为了保持统一的评估流程,仅扩展和评分每个块的第一个动作,然后执行选定的块;组块内的后续步骤不再获得进一步的指导。这限制在组块内进行干预的能力,并且随着 N+M 的增加,可能会出现非单调趋势。尽管如此,该方法仍然有效——大多数 N+M 设置仍然显示出积极的改进。
Q3:共享感知缓存的影响。通过测量在不断增加的候选预算下,每个控制步骤的实际延迟来评估跨候选缓存感知特征的影响。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献220条内容
已为社区贡献220条内容

所有评论(0)