AI产品经理-大模型的智力之源与能力边界
大模型的时代,从来不是 “唯技术论” 的时代,而是技术 + 业务深度融合的时代。想要让大模型真正产生价值,不是盲目追求最新、最强的模型,而是先搞懂它的原理和边界,再结合业务痛点,找到合适的结合点。作为 AI 产品经理,我们的核心竞争力,从来不是单纯的懂 AI 或懂业务,而是把 AI 的能力,精准转化为解决业务问题的方案。搞懂大模型的智力之源与能力边界,只是第一步,而真正的落地,藏在每一次的实操、每
内容摘要
围绕 AI 大模型产品经理实战营展开,核心讲解大模型的底层逻辑、能力边界及 AI 产品落地相关知识,旨在帮助学习者成为懂业务、懂 AI 的大模型产品经理,实现 AI 落地。内容涵盖大模型的定义、训练过程、运行原理、核心架构,明确了其擅长编程、文字工作等能力与不擅长数学计算、未学知识等边界,还介绍了国内外主流大模型、AI 产品构建全流程及产品经理的核心职责与能力要求,同时给出了具体的学习路径和实操任务。
脑图
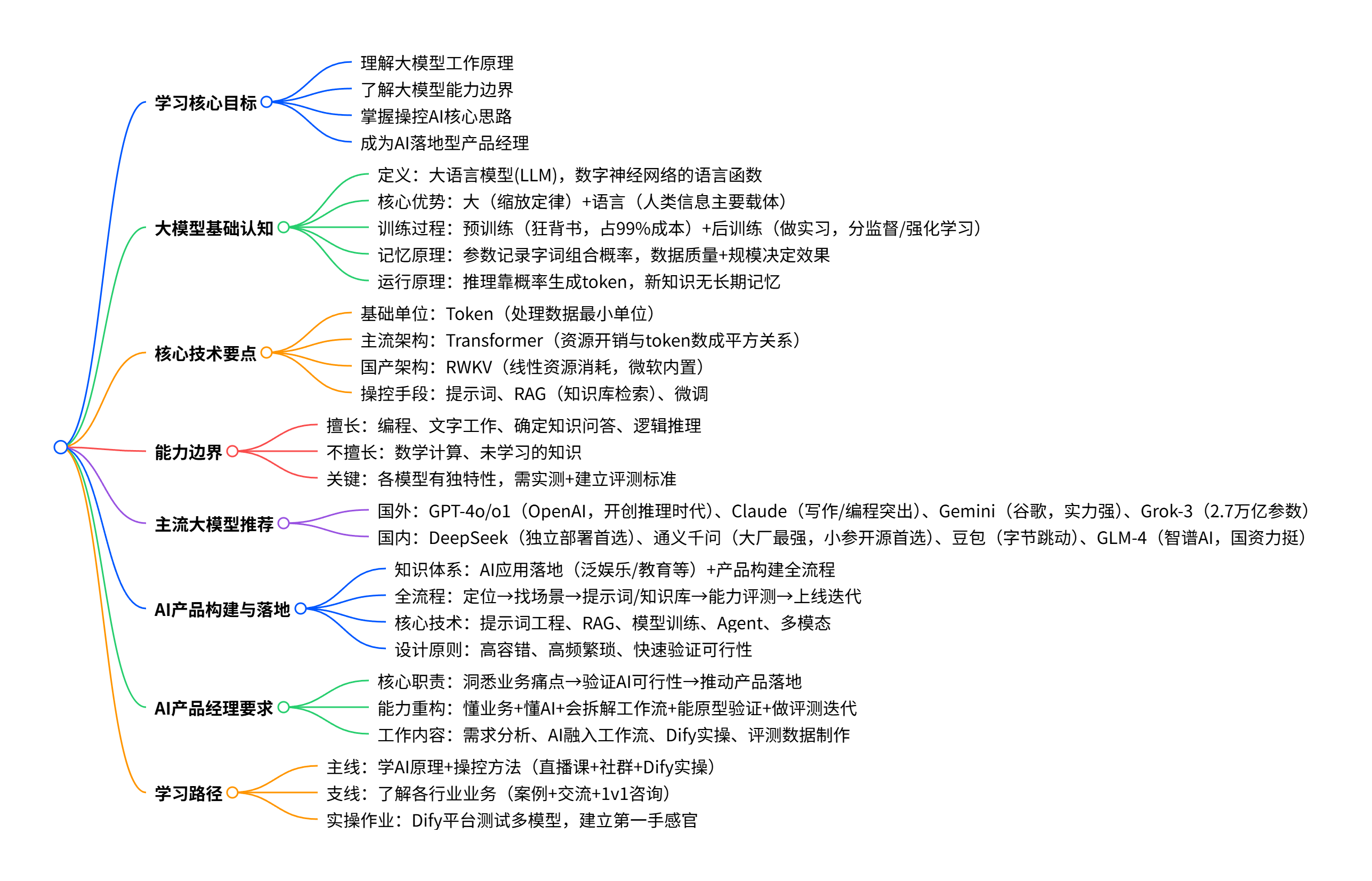
AI 大模型的浪潮早已席卷各行各业,从企业数字化到教育金融,从泛娱乐到智能创作,几乎所有领域都在尝试让大模型落地产生价值。但很多人忙活半天却收效甚微,核心问题在于:没搞懂大模型的智力之源,更摸不清它的能力边界。
对于想做好 AI 产品落地的从业者,尤其是 AI 产品经理来说,搞懂大模型的底层逻辑,是入门的必修课。只有知道它从哪来、能做什么、不能做什么,才能把它用在对的地方,设计出真正贴合业务的落地方案。这也是 AI 大模型产品经理实战营的核心初衷:培养懂 AI、懂业务,能让 AI 真正落地的复合型人才。
一、大模型到底是什么?不是越 “大” 就越厉害

提到大模型,很多人的第一印象就是 “参数大”,但其实它的全称是大语言模型(LLM),核心是数字神经网络结构+语言理解+大规模参数的结合,本质就是一个把输入转化为输出的函数:y=f (x)。
它之所以比以往的 AI 模型更智能,核心就两个点:一是懂语言。语言是人类信息传递的主要载体,能理解语言的 AI,才真正具备了贴近人类的智能表现,这也是大模型和传统 AI 的核心区别;二是缩放定律。就像人类和动物的大脑结构相似,但人类因更复杂的结构拥有更高智能,大模型也是如此,在训练到位的前提下,参数规模越大,往往越智能。
但这里有个关键前提:没训好的模型,参数再大也没用。这就像再天才的人,不上学、读烂书,也无法发挥自身天赋,大模型的 “大”,必须建立在优质训练和数据的基础上。
二、大模型是怎么 “炼” 成的?99% 的成本都花在这一步
大模型的训练过程,和人类的学习过程高度相似,分为预训练和后训练两个阶段,而且整个研发过程中,99% 的成本都花在了预训练阶段。

预训练就像人类 “狂背书”,模型会学习海量的文本、代码数据,积累基础的知识储备,这个阶段需要海量的算力和数据,极其烧钱;后训练则像 “毕业实习”,用大量的输入输出对让模型学会怎么运用知识,这个阶段的数据成本甚至可能超过训练成本,而且对模型的最终行为、能力,有着决定性的影响。
后训练主要有两种核心方法:监督学习和强化学习。监督学习是用人工标注、筛选的输入输出对训练模型,相当于有人手把手教;强化学习则是让模型自己解题,再通过人工或奖励模型反馈对错,让模型在试错中优化,比如 DeepSeek 的训练过程,就结合了多轮监督学习和强化学习,最终让模型学会 “先思考再给结论”。

很多人会问,大模型是怎么记住知识的?答案其实很颠覆:它根本不是像人类一样理解知识,只是在参数(权重)里记录了字词组合的概率。比如 “AI” 后面接 “技术” 的概率 30%,接 “在” 的概率 20%,仅此而已。所以训练数据的质量和数量,直接决定了大模型的能力 —— 数据越好,参数规模越大,模型才越厉害。

三、大模型怎么工作?其实只是在 “拼概率”
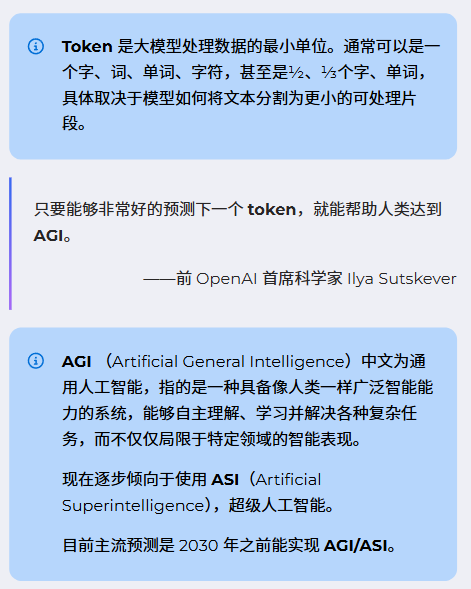
大模型的运行过程,被称为推理,就像人类运用所学知识解决问题。它的工作逻辑很简单:接收用户的提示词(任务),哪怕任务里包含新知识,也能基于自身的概率库生成响应,但一旦任务结束,这些新知识就会被彻底忘掉,没有长期记忆。

而它生成结果的核心逻辑,更是简单到超出很多人的想象:基于概率逐一生成最小处理单位 token,没有实际的检索、匹配,更没有人类意义上的 “思考”。比如输入 “我周末最喜欢的是”,模型会先基于概率生成 “和”,再生成 “朋友”,最后生成 “爬山”,一步步拼凑出完整答案。

这也解释了为什么大模型会出现 “幻觉”,会答不对 “9.11 和 9.9 哪个更大” 这类简单问题 —— 它只是在拼字词的组合概率,而非真正理解数字的大小关系,也无法真正判断信息的真伪。
就像阿兰・图灵在 1947 年说的:“如果一台机器绝对不会犯错,它就不可能是智能的。”AI 的目标从来不是 100% 正确,而是比人类的正确率更高,而大模型的幻觉,目前也尚无彻底消除的可能。

四、主流架构有优劣,国产架构值得骄傲
目前大模型的主流架构是Transformer,它的能力毋庸置疑,但有个明显的缺点:资源开销大,其资源消耗和处理的 token 数成平方关系,处理的文本越长,越烧钱、推理速度越慢。
不过也有很多创新架构在研发中,其中国产架构 RWKV尤为值得我们骄傲:它的资源消耗和处理的 token 数成线性关系,效率远高于 Transformer,而且已经被微软内置到了每一台电脑中。对我们来说,节约 token 数不仅是省钱,更是省时间,这也是未来大模型架构研发的重要方向。
而操控大模型的核心思路,其实和管理学相通,核心就是控制 AI 的记忆,主要有三个核心手段:提示词工程、RAG(知识库检索)、微调,这也是每一个 AI 产品经理必须掌握的核心技能。


五、大模型的能力边界:别把它当成 “万能神”
想要让大模型落地,最关键的一步就是搞懂它的能力边界,避免 “一刀切” 的误用。大模型不是万能的,它的擅长和不擅长领域,划分得很清晰:
它最擅长的事:
-
编程开发,能快速生成、优化代码;
-
各类文字工作,比如写作、校对、翻译、总结、润色等;
-
确定知识的问答,比如专业领域的既定知识点解答;
-
逻辑推理,注意:解数学题属于逻辑推理,而非单纯的数学计算。
它不擅长的事:
-
纯数学计算,简单的算术题都可能算错;
-
从未学习过的知识,超出训练数据范围的内容,要么答不上,要么容易产生幻觉。
当然,这只是笼统的边界,每个大模型都有自己的独特性:有的模型写作能力突出,有的编程更厉害,有的甚至在某个简单问题上表现拉胯。就像想了解一个人要多相处,想了解一个 AI 的边界,就要多多使用它 —— 没有具体试过,没有建立评测标准,就不能确定模型能不能做好某件事。

六、选大模型别信宣传,适合的才是最好的
市面上的大模型层出不穷,很多人会纠结 “哪个模型最好”,但答案是:没有最好的大模型,只有最适合的大模型。

首先要分清一个关键概念:大模型和基于大模型的对话产品是两回事。比如 GPT-4o 是大模型,ChatGPT 是基于它开发的对话产品,后者的智能完全来自前者;也有公司将两者用同一个名字命名,比如豆包、DeepSeek、通义千问等,这一点要先分清。
目前国内外的主流大模型,各有特色,给大家做了核心梳理,方便按需选择:
国外主流模型

- OpenAI(GPT-4o/o1)
:行业标杆,GPT 开创了大模型时代,o1 开创了推理型大模型时代,创造了行业事实标准;
- Claude
:写作能力突出,Claude 3.7 Sonnet 是编程领域的 “地表性价比之王”;
- Gemini
:谷歌出品,实力不俗,全系模型表现都很好,只是营销较少;
- Grok-3
:目前参数量达 2.7 万亿的超强模型,综合能力拉满。
国内主流模型

- DeepSeek
:AI 从业者的 “标配”,独立部署的首选;
- 通义千问
:阿里出品,大厂中表现最强,也是小参数量开源的首选;
- 豆包
:字节跳动出品,潜力巨大,被看好未来的发展;
- GLM-4
:智谱 AI 出品,国资力挺,新一代优质基座大模型。
选模型的核心原则:别信宣传,结合具体的业务任务做实际测试,能解决你的业务问题的,就是最好的。
七、AI 产品经理:大模型落地的核心缺口
李开复曾说过:“做大模型时代 ToC 应用的一个堵点在于人才,找到既懂大模型又懂产品的 PM 很难;而模型能力在 ToB 方面的落地,同样如此,模型能力与行业 Know-how 缺一不可。”
这句话点出了当下大模型落地的核心痛点,也重新定义了 AI 时代的产品经理:不再是单纯做需求分析、界面设计的传统 PM,而是要深度参与业务全流程的复合型人才。
AI 产品经理的核心职责
就三个核心:洞悉业务痛点,验证 AI 解决痛点的可行性,将 AI 产品真正落地。

AI 产品经理的核心工作
从实操业务、理清真实需求,到拆解工作流、将 AI 和人、传统软件融合;从用 Dify 等工具做原型验证,到制作评测数据、设定验收标准;再到后续的提示词迭代、数据迭代,甚至辅助界面设计和技术实现,每一步都需要深度参与。
简单来说,AI 产品经理必须既懂 AI,又懂业务,能把 AI 的能力,转化为解决业务问题的具体方案。
八、AI 产品构建全流程,一步都不能少
想要让 AI 产品从 0 到 1 落地,有一套完整的构建流程,每一步都要围绕业务和大模型的特性展开,核心分为三个阶段:
- 前期准备
:找到适合 AI 落地的业务场景,明确产品定位(目标用户、解决什么问题),同时完成知识库构建、知识萃取和结构化;
- 中期设计
:进行提示词组装、RAG 知识库检索,设计工作流和控制流,同时完成 AI 能力评测,制定评测用例、标准和效果度量方式;
- 后期落地
:完成产品上线,持续进行迭代优化,同时做好成本控制、安全合规,通过 AB Test 不断优化产品体验。
而支撑整个流程的核心技术,就是提示词工程、RAG、模型训练(预训练 + 微调)、Agent、多模态,AI 产品经理不需要精通技术开发,但必须理解这些技术的核心用法。

九、想做 AI 产品经理,这样学就对了
如果想成为合格的 AI 大模型产品经理,有清晰的学习路径可以遵循,分为主线任务和支线任务,两手都要抓:
主线任务:吃透 AI 本身
聚焦学习 AI 的原理和操控方法,通过直播课、社群讨论、Dify 实操,掌握提示词、RAG、微调等核心操控手段,能熟练使用各类 AI 工具。
支线任务:积累业务知识
广泛了解各行各业的业务逻辑,通过课堂案例、社群交流、1v1 方案咨询直播,积累不同领域的 Know-how,知道不同行业的痛点在哪里,这是 AI 落地的关键。
而最核心的,还是实操:去 Dify 平台测试多种大模型,建立对不同模型的第一手使用感受。在实操过程中,也要注意规范:应用名称加专属标识、切勿上传私密数据、保持对话和谐,避免不必要的问题。
十、写在最后:AI 落地,拼的是技术 + 业务的融合
大模型的时代,从来不是 “唯技术论” 的时代,而是技术 + 业务深度融合的时代。想要让大模型真正产生价值,不是盲目追求最新、最强的模型,而是先搞懂它的原理和边界,再结合业务痛点,找到合适的结合点。
作为 AI 产品经理,我们的核心竞争力,从来不是单纯的懂 AI 或懂业务,而是把 AI 的能力,精准转化为解决业务问题的方案。搞懂大模型的智力之源与能力边界,只是第一步,而真正的落地,藏在每一次的实操、每一次的业务拆解、每一次的模型测试里。
当下,正是大模型落地的黄金时期,而能把大模型真正用起来的产品经理,一定会成为各行各业的核心人才。现在开始学习、实践,一切都还不晚。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)