KIMI-DEV: AGENTLESS TRAINING AS SKILL PRIORFOR SWE-AGENTS
该任务本身的高难度(以基准提出时的标准而言)、所提供的自动评测框架[auto-eval harness]带来的结果奖励信号的存在,以及其所反映的现实经济价值,共同使 SWE-bench 成为该领域的焦点。以 SWE-Agent(Yang et al., 2024a)和 OpenHands(Wang et al., 2025a)为代表的基于智能体的解决方案采用交互主义路径:在任务描述、可用工具集及具
ABSTRACT
1 INTRODUCTION
关于 RLVRRLVR 即"带可验证奖励的强化学习"(Reinforcement Learning with Verifiable Rewards)。普通强化学习的奖励信号往往需要人工打分或训练一个奖励模型,成本高且不稳定。而 RLVR 的核心思想是:奖励信号来自一个客观可验证的结果——比如代码能不能通过单元测试、数学题答案对不对。这类奖励不需要人工判断,直接由程序自动给出,既便宜又准确。Agentless 的流水线结构天然适配 RLVR,因为每一步(比如"定位到了正确文件吗?""补丁通过测试了吗?")都有明确的对错判断。关于"错误模式仅出现在单轮长推理内容中,行为监控困难"先理解 Agentless 的工作方式:它把整个修复任务分成几个单独的步骤,每一步模型只需完成一次输入→输出。但为了让模型"想清楚"再给答案,每一步的输出往往包含很长的思维链(Chain-of-Thought),模型在这个长推理过程中一步步分析,最后才给出结论。所谓"错误模式",指的是模型在推理过程中出现的错误行为,例如:错误地定位了缺陷位置、推理逻辑出现跳跃、自我矛盾等。问题在于:这些错误全部藏在这 一大段长推理文本的内部,而不像 SWE-Agent 那样分散在 多轮交互记录中,每一轮的行为都清晰可见、便于审查。Agentless 的错误是"一锅端"地埋在单次输出的长文本里,研究者很难定位"模型究竟在哪一步推理出了问题",自然也就难以针对性地监控和纠正模型行为。
简单打个比方:SWE-Agent 像是一个人边做边汇报,你能看到他每一步在干什么;而 Agentless 像是一个人闷头写了一大篇草稿再交给你,他中间哪里想错了,你得自己从头翻那篇草稿才能找到。
2 BACKGROUND
2.1 FRAMEWORK DICHOTOMY
然而,这种刚性结构的代价是灵活性的牺牲——当遇到需要多轮增量更新[multiple rounds of incremental updates]的场景时,Agentless 方法难以灵活应对。
与之相对,SWE-Agent 采用端到端的多轮推理范式[an end-to-end, multi-turn reasoning paradigm](Yang et al., 2024a; Wang et al., 2025a)。它们不遵循固定的工作流,而是迭代地进行规划、行动与反思,与人类开发者调试复杂问题的方式颇为相似。这种设计带来了更强的适应性,但也引入了显著的挑战:轨迹往往延伸至数十甚至数百步,LLM 的上下文窗口必须覆盖整个交互历史,且模型需要同时处理探索、推理和工具调用。
固定工作流(如 Agentless)与智能体框架(如 SWE-Agent)之间的二元对立[dichotomy],在很大程度上塑造了社区的主流观点。这两种范式通常被视为相互排斥:一种以牺牲灵活性和性能上限换取模块化与稳定性,另一种则做出相反的取舍。我们的工作对这一二元对立提出挑战,因为我们证明了 Agentless 训练能够诱导出技能先验,从而使后续的 SWE-Agent 训练更加稳定、更加高效。
2.2 TRAINING SWE-AGENTS
训练 SWE-Agent 依赖于通过与可执行环境交互来获取高质量的轨迹数据。然而,构建如此大规模的环境并收集可靠的轨迹数据,需要大量的人工投入以及对前沿模型的高成本调用,使得数据收集过程既缓慢又耗费资源(Pan et al., 2024; Badertdinov et al., 2024b)。
近期研究也尝试通过合成缺陷来反向构建可执行运行[the reverse construction of executable runtime]时,以此扩展环境构建的规模(Jain et al., 2025; Yang et al., 2025c)。然而,跨长时间跨度的信用分配问题[credit assignment across long horizons]依然是一大挑战,因为结果奖励十分稀疏,且通常只有在最终补丁[final patch]通过测试时才能获得。
强化学习技术已被提出用于解决这一问题,但当轨迹超过数十步时,往往会出现不稳定或崩溃的情况(Luo et al., 2025; Cao et al., 2025)。SWE-Agent 的训练对初始化也极为敏感:从通用预训练模型出发往往会导致脆弱的行为,例如无法有效使用工具,或陷入特定动作模式的无限循环(Pan et al., 2024; Yang et al., 2025c)。
上述局限性促使我们提出核心假设:与其从零开始训练 SWE-Agent,不如首先通过 Agentless 训练来诱导技能先验[skill priors],增强故障定位、缺陷修复、测试构造和自我反思等原子级能力。这些先验为后续的智能体训练奠定基础,使其既更加高效,又更具泛化能力。
3 AGENTLESS TRAINING RECIPE
我们不从零开始训练 SWE-Agent,而是利用 Agentless 训练来诱导技能先验[skill priors]。通过 Agentless 训练所增强的技能先验包括但不限于缺陷定位[bug localization]、补丁生成[patch generation]、自我反思与验证[self-reflection and verification],这些能力为端到端的智能体交互奠定了基础。
在本节中,我们详细阐述 Agentless 训练方案的各个组成部分:BugFixer 与 TestWriter 的双模块框架设计、中间训练[mid-training]与冷启动[cold-start]、强化学习[reinforcement learning],以及测试时自博弈[test-time self-play]。第 3.1 至 3.4 节分别详述上述各要素,第 3.5 节呈现每个要素的实验结果。该训练方案最终产出 Kimi-Dev——一个开源 72B 模型,在 SWE-bench Verified 上达到 60.4% 的成绩,位居工作流方法的最优水平。
3.1 FRAMEWORK: THE DUO OF BUGFIXER AND TESTWRITER
在 GitHub issue 解决过程中,我们将其概念化为两个重要角色[roles]之间的协作:BugFixer 负责生成能够正确修复软件缺陷的补丁,TestWriter 负责创建能够复现所报告缺陷的可重复单元测试。
当 BugFixer 生成的补丁能够通过 issue 所提供的测试时,即视为问题解决成功;而 TestWriter 生成的高质量测试应在修复前的代码版本上失败,并在应用修复后通过。每个角色都依赖两项核心技能:(i)文件定位[file localization],即识别与缺陷或测试相关的具体文件的能力;(ii)代码编辑[code edit],即实现必要修改的能力。
对于 BugFixer 而言,有效的代码编辑能够修复有缺陷的程序逻辑;而对于 TestWriter 而言,则是将能够复现 issue 的精确单元测试函数更新到测试文件中。如图 1 所示,这两项技能构成了解决 GitHub issue 的基础能力。
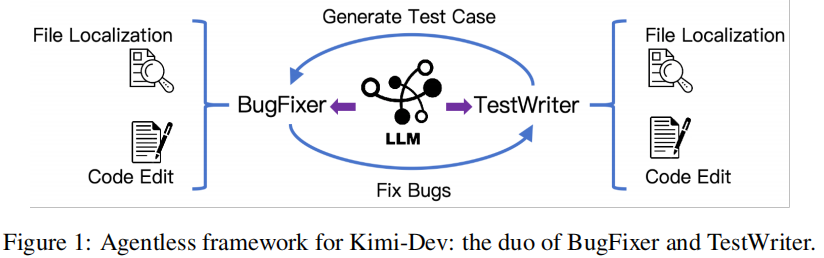
因此,我们通过以下训练方案来增强这些技能,包括中间训练、冷启动和强化学习。
3.2 MID-TRAINING & COLD START
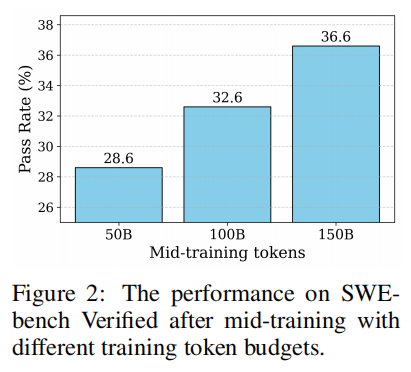
为了增强模型同时作为 BugFixer 和 TestWriter 的先验能力,我们使用约 1500 亿个tokens[∼150B tokens]的高质量真实世界数据进行中间训练[mid-training]。以 Qwen 2.5-72B-Base(Qwen et al., 2024)模型为起点,我们收集了数百万条 GitHub issue 和 PR [pull request]提交记录,构成中间训练数据集,其中包括:(i)约 500 亿个tokens的 Agentless 格式数据,源自自然差异补丁[diff patch];(ii)约 200 亿个tokens的精选 PR 提交包[commit packs];(iii)约 200 亿个tokens的包含推理和智能体交互模式的合成数据[synthetic data](训练时上采样 4 倍)。
该数据方案经过精心构建,旨在使模型学习人类开发者处理 GitHub issue、实现代码修复和编写单元测试的推理方式。我们还进行了严格的数据去污处理,排除了 SWE-bench Verified 测试集中涉及的所有仓库。
中间训练充分增强了模型关于实际缺陷修复和单元测试的知识储备,使其成为后续阶段更好的起点。数据方案的详细内容见附录 A。
根据附录A的内容对这里进行解释。
一、整体数据来源
他们从 GitHub 爬取了大量 PR(Pull Request)数据,筛选条件是:至少 5 个 Star 的仓库、状态为 MERGED 的 PR、排除与 SWE-bench 重叠的仓库。对于每个 PR,他们还会快照该 PR 第一次代码改动之前的完整代码库状态。
二、Diff Patch 与 Commit Pack 的区别
这是理解整个数据方案的核心,用一个具体例子来说明。
假设某个 PR 修复了一个 bug,开发者分三次提交完成:
第一次提交:发现问题所在,修改了
utils.py的第 10 行 第二次提交:发现第一次修改不够,又补充修改了utils.py的第 20 行 第三次提交:顺手修了parser.py里的一个相关问题Natural Diff Patch(自然差异补丁)
把这三次提交合并成最终结果,只看"起点"和"终点"之间的差异,忽略中间过程。输出格式是 SEARCH-REPLACE 块:
utils.py 第10行:旧代码 → 新代码 utils.py 第20行:旧代码 → 新代码 parser.py 第X行:旧代码 → 新代码这对应 Agentless 范式:模型直接给出最终补丁,不需要知道中间经历了什么。
PR Commit Pack(PR 提交包)
保留三次提交的完整顺序过程,每次提交包含两部分:提交消息(开发者写的文字说明,相当于推理过程)+ 对应的代码改动(行动)。格式大致如下:
[提交1] fix: 定位到utils.py中的核心问题 → 代码改动:utils.py 第10行变更 [提交2] fix: 补充边界情况处理 → 代码改动:utils.py 第20行变更 [提交3] fix: 修复parser中的关联问题 → 代码改动:parser.py 第X行变更这对应 SWE-Agent 范式:推理步骤与行动交替出现,模拟人类开发者逐步解决问题的思维过程。
三、合成数据的两种类型
除了上述真实数据,他们还构造了两类合成数据:
合成推理数据(约100亿tokens):专门针对定位阶段。他们先用2000条R1轨迹对 Qwen-2.5-72B-Instruct 做轻量 SFT,得到一个"会推理的定位模型",再用它大规模生成文件定位的推理轨迹,只保留定位完全正确的结果。这批数据的目的是让模型学会"如何推理才能找到正确文件"。
合成智能体交互数据(约100亿tokens):模拟多轮工具调用过程。由于 GitHub 快照没有可执行的 Docker 环境,他们设计了一套"假工具"(见 Prompt 5 中的 open_file、search_dir 等),让模型能够模拟浏览文件、搜索关键词的行为,但不真正执行代码。特别值得注意的是,在第二阶段他们会故意让智能体"打开一个定位错误的文件",然后人工注入"我意识到这个文件不需要修改"这样的反思语句,专门训练模型的自我反思能力。
四、训练配置
"We perform mid-training using a standard next token prediction approach, initialized from the Qwen2.5-72B-Base model."
以 Qwen2.5-72B-Base 为起点,合成数据上采样 4 倍,最大序列长度 32K,学习率 2e-5,余弦衰减,总共训练约 1500 亿tokens。
总结一句话
Diff Patch 教模型"看结果",Commit Pack 教模型"看过程",合成数据教模型"会推理、会反思"。三者共同构成了一个从结果到过程、从模仿到推理的完整训练数据生态。
为了激活模型的长思维链(CoT)能力,我们还基于 SWE-Gym(Pan et al., 2024)和 SWE-bench-extra(Badertdinov et al., 2024a)数据集构建了一个冷启动数据集[cold-start dataset],其中的推理轨迹[reasoning trajectories]由 DeepSeek R1 模型(Luo et al.,2025,20250120 版本)生成。
在此设置中,R1 分别扮演 BugFixer 和 TestWriter 的角色,生成文件定位和代码编辑等输出。通过以该数据集进行有监督微调作为冷启动,我们使模型习得了必要的推理技能,包括问题分析、方法草拟、自我精炼以及探索替代解决方案。
3.3 REINFORCEMENT LEARNING
在中间训练和冷启动之后,模型在定位阶段已展现出强劲的性能,因此强化学习(RL)仅专注于代码编辑阶段。(我在块引用里说过它专门合成了数据用来训练文件定位和交互,所以这里说模型在定位表现强大很合理)
RL的数据集在附录C。
C MORE DETAILS OF RL TRAINING
C.1 PROMPT SET SELECTION
在正文中,我们介绍了用于强化学习训练的自适应提示选择方法。具体而言,我们首先从Swe-Gym(Pan 等人,2024)、Swe-bench-extra(Badertdinov 等人,2025)和R2Egym(Jain 等人,2025)中筛选出pass@16>0的问题,构建了包含1,200个问题的初始提示集。随后,每经过100个训练步骤,我们就会从当前模型pass@16=0的问题池中随机抽取并过滤出500个新问题,逐步增加难度以构建合适的训练课程。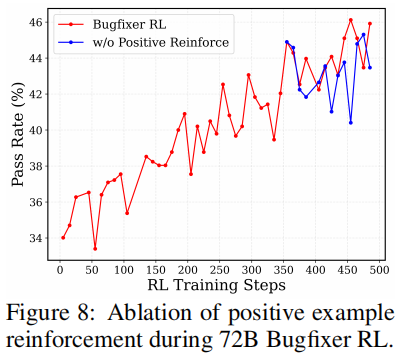
C.2 RL EXPERIMENT ABLATION
图9展示了Qwen2.5-14B模型在强化学习实验中的表现,其中BugFixer和TestWriter均表现出明显的扩展规律行为。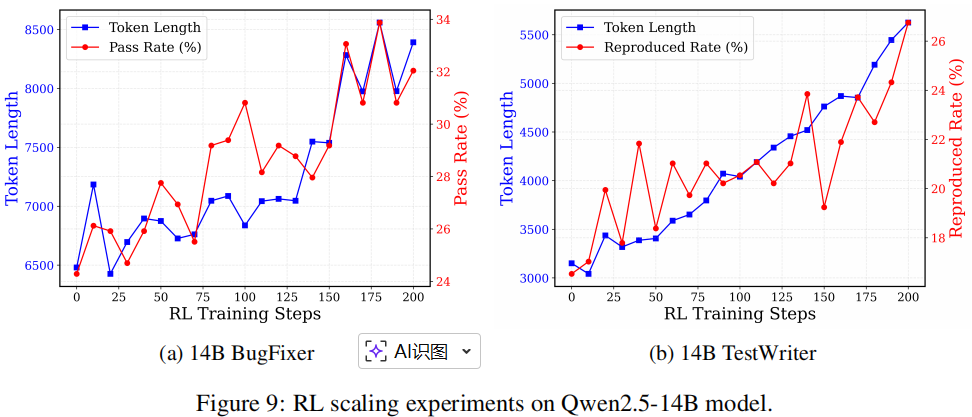 此外,图8展示了我们提出的正例强化方法的效果。我们在训练后期引入了这一改进措施,发现与未使用该技巧相比,BugFixer的强化学习(RL)表现更优。主要原因在于正例能强化正确的推理模式,使模型收敛速度更快,尤其在后期探索能力减弱时。值得注意的是,类似策略也应用于Seed1.5-thinking模型的开发(Seed 等,2025)。
此外,图8展示了我们提出的正例强化方法的效果。我们在训练后期引入了这一改进措施,发现与未使用该技巧相比,BugFixer的强化学习(RL)表现更优。主要原因在于正例能强化正确的推理模式,使模型收敛速度更快,尤其在后期探索能力减弱时。值得注意的是,类似策略也应用于Seed1.5-thinking模型的开发(Seed 等,2025)。
我们专门为该阶段构建了一个训练集[a training set],其中每个提示词[prompt](这里的prompt貌似就是github issue)均配备了可执行环境。我们进一步利用初始模型的多次定位采样来生成多样化的文件位置预测,从而丰富代码编辑强化学习所使用的提示词。在强化学习算法方面,我们采用 Kimi k1.5(Team et al., 2025)提出的策略优化方法[policy optimization method],该方法在数学和编程推理任务上均展现出良好的效果。Kimi k1.5(Team et al., 2025)采用了一种基于 REINFORCE 算法(Williams, 1992)的更简洁的策略梯度方法[a simpler policy gradient approach]。与 GRPO(Shao et al., 2024)类似,我们使用多次采样的平均奖励作为基线来归一化回报[the average rewards of multiple rollouts as the baseline to normalize the returns]。
在将该算法适配到 SWE-bench 场景时,我们着重强调以下三个关键设计要点:
- 仅使用结果奖励[Outcome-based reward only]:我们完全依赖环境的最终执行结果作为原始奖励(0 或 1),不引入任何格式或过程层面的信号。对于 BugFixer,若生成的补丁通过了所有真实单元测试,则给予正向奖励;对于 TestWriter,当(i)预测的测试在未应用真实补丁的仓库上触发失败,且(ii)该失败在应用真实补丁后得到解决时,才给予正向奖励。
- 自适应提示词选择[Adaptive prompt selection]:pass@16 = 0 的提示词[Prompts with pass@16 = 0]在初始阶段被丢弃,因为它们对批次损失没有贡献,这使得初始提示词集包含 1,200 个问题,并有效扩大了批次规模。随后应用课程学习策略[A curriculum learning scheme]:一旦当前集合上的成功率超过某一阈值,每隔 100 个强化学习步骤便重新引入 500 个新问题(即初始 pass@16 = 0 但在强化学习过程中有所改善的问题),以逐步提升任务难度。
- 正样本强化[Positive example reinforcement]:当训练后期性能提升趋于平缓时,我们将近期强化学习迭代中的正样本纳入当前迭代的训练批次。这一方法强化了模型对成功模式的依赖,从而加速最终阶段的收敛。
关于第二点,这里进行一些解释。(因为我看不懂,所以我写出来提示自己)
首先,"提示词"在这里是什么
这里的"提示词"(prompt)就是一道训练题,具体来说是一个 GitHub issue + 对应的代码上下文。模型需要根据这个输入生成一个代码补丁,然后放到可执行环境里跑单元测试,看能不能通过。
什么是 pass@16
pass@16 的意思是:对同一道题,让模型独立生成 16 个答案,只要其中有 1 个能通过测试,就算 pass@16 = 1;如果 16 个全部失败,则 pass@16 = 0。
所以 pass@16 = 0 意味着:这道题对当前模型来说太难了,采样 16 次全部失败,一次都解不出来。
为什么要在训练开始前先测一遍
在正式开始强化学习之前,他们用冷启动之后的初始模型,对所有训练题各采样 16 次,提前筛出哪些题目对当前模型"完全不可解"。
这一步很关键。强化学习的本质是:模型先尝试,答对了就强化这种行为,答错了就抑制。但如果一道题 16 次全错,就意味着模型根本不知道"正确答案长什么样",梯度信号全是负的或者全是零,对训练没有任何帮助,反而浪费计算资源。所以这些题在初始阶段直接丢掉。
课程学习是怎么回事
这借鉴了人类学习的逻辑:先学简单的,再逐步挑战难题。
训练流程大致如下:
- 开始时只用那 1200 道"模型能解开至少一次"的题目训练
- 随着训练推进,模型越来越强
- 每训练 100 步,就检查一下:之前那些 pass@16 = 0 的"太难题",现在模型能解开了吗?
- 能解开的就批量(每次 500 道)重新加回训练集,继续提难度
这样模型始终处于"跳一跳够得着"的难度区间,既不会因为题目太简单而停滞,也不会因为题目太难而崩溃。
一句话总结
pass@16 = 0 是在训练前预先测出来的,目的是筛掉"当前模型完全无法解决"的题目,避免无效训练;课程学习则是随着模型能力提升,动态把这些难题重新纳入训练,逐步加压。
稳健的沙箱基础设施[Robust sandbox infrastructure.]:我们基于 Kubernetes(Burns et al., 2016)构建 Docker 环境,提供安全、可扩展的沙箱基础设施以及高效的训练与采样能力。该基础设施支持超过 10,000 个并发实例且性能稳定,非常适用于竞争性编程和软件工程任务(详见附录 D)。
3.4 TEST-TIME SELF-PLAY
经过强化学习后,模型同时掌握了 BugFixer 和 TestWriter 两种角色的能力,在测试时采用自博弈机制[a self-play mechanism]来协调其缺陷修复与测试编写能力。
沿用 Agentless(Xia et al., 2024)的做法,我们利用模型为每个实例生成 40 个候选补丁[40 candidate patches]和 40 个候选测试[40 tests]。每次补丁生成均包含 BugFixer 独立执行的定位和代码编辑过程,其中第一次采用贪心解码(温度为 0),其余 39 次使用温度 1 以保证多样性。类似地,TestWriter 独立生成 40 个测试。对于候选测试补丁,为保证其有效性,我们首先过滤掉那些在未应用任何 BugFixer 补丁的原始仓库上无法触发失败的测试。
将剩余的 TestWriter 补丁[TestWriter patches]记为集合 ,BugFixer 补丁[BugFixer patches]记为集合
。对于每对
与
,我们对
所修改的测试文件执行两次测试套件:第一次不应用
,第二次应用
。从第一次运行的执行日志中,我们获取
产生的失败测试数和通过测试数,分别记为
和
。通过对比两次测试套件运行的执行日志,我们得到由失败转为通过的测试数和始终通过的测试数,分别记为
和
。随后,我们按如下公式计算每个
的得分:
其中第一项反映了 在复现测试下的表现,第二项可视为
在回归测试下的特征刻画(Xia et al., 2024)。我们选取得分
最高的 BugFixer 补丁
作为最终答案。
对整个第三章的梳理(因为我晕了,所以理一遍)
只有一个模型,BugFixer 和 TestWriter 是同一个模型的两种"用法"。
BugFixer 和 TestWriter 不是两个独立的模型,而是同一个模型在不同提示词(prompt)下扮演的两种角色。就像你问同一个人"帮我修这段代码"和"帮我写个测试用例",是同一个人,但任务不同。
训练流程从头到尾只有一条主线
Qwen2.5-72B-Base ↓ 【中间训练】约1500亿tokens 同时喂入两类任务的数据: - BugFixer 相关数据(定位+修复) - TestWriter 相关数据(定位+写测试) ↓ 【冷启动 SFT】 用 R1 生成的推理轨迹做监督微调 同样包含两种角色的轨迹 ↓ 【强化学习 RL】 只训练代码编辑阶段 BugFixer 的奖励:补丁通过单元测试 TestWriter 的奖励:测试能复现bug且修复后消失 ↓ Kimi-Dev (同一个模型,既能当BugFixer,也能当TestWriter) ↓ 【测试时自博弈】 同一个模型生成40个补丁(BugFixer模式) + 40个测试(TestWriter模式) 互相打分,选最优补丁为什么要设计两个角色
这是为了解决一个根本问题:SWE-bench 的测试用例是保密的,模型在推理时看不到真实的单元测试。
所以他们让同一个模型"左手修bug,右手写测试",然后用自己写的测试来评判自己的补丁,相当于自我验证,绕开了看不到真实测试的问题。
数据集那么多是怎么回事
那些数据集并不是分开训练多次,而是在中间训练[mid-training]这一步被混合在一起喂给模型:
- Natural diff patch → 教模型直接输出最终补丁(Agentless风格)
- PR commit pack → 教模型理解逐步推理过程(Agent风格)
- 合成推理数据 → 教模型定位文件时怎么推理
- 合成智能体交互数据 → 教模型多轮工具调用和自我反思
这四类数据混合成约1500亿tokens,一次性完成中间训练,不是分四次训练。
一个模型,一条训练流水线,两个角色是同一模型在不同prompt下的表现,多个数据集是同时混合训练的。
训练数据是怎么构造的
关键在于:BugFixer 和 TestWriter 的训练数据是两批独立的样本,不是一个样本里同时包含两件事。
具体来说,训练集里有两种类型的数据:
BugFixer 样本:
输入:GitHub issue + 代码文件 输出:<推理过程> + SEARCH/REPLACE补丁 奖励:补丁通过单元测试 → 1,否则 → 0TestWriter 样本:
输入:GitHub issue + 测试文件 输出:<推理过程> + SEARCH/REPLACE测试代码 奖励:测试能复现bug且修复后消失 → 1,否则 → 0模型在训练时交替看到这两类样本,就像一个学生做练习册,有时做"修复题",有时做"写测试题",做完一道换下一道,而不是一道题里同时要求两件事。
GRPO 能这样干吗,是实时的吗
能,而且这正是 GRPO 类方法的标准做法,流程如下:
取一批提示词(混合BugFixer和TestWriter样本) ↓ 对每个提示词,模型采样生成 N 个回答(论文里用16个) ↓ 每个回答扔进 Docker 环境实际执行 ↓ 得到每个回答的奖励(0或1) ↓ 用这批奖励计算梯度,更新模型 ↓ 用更新后的模型,取下一批提示词,重复所以是实时的,每一步训练都需要真正跑代码、跑测试来获取奖励,这也是为什么他们要搭建能支持 10,000 个并发实例的 Kubernetes 沙箱基础设施——采样 16 次 × 成百上千道题,需要同时执行大量 Docker 容器。
那测试时自博弈又是怎么回事
测试时自博弈发生在训练完成之后,和训练过程无关。此时模型已经同时学会了两种角色,推理时:
- 以 BugFixer 身份生成 40 个补丁
- 以 TestWriter 身份生成 40 个测试
- 两两组合打分,选最优补丁
这是纯推理阶段的集成策略,不涉及任何梯度更新。
再解释一下。请注意,这个标题是test-time self-play,也就是说在测试集的时候,为了让lm生成的patch准确率更高,lm自己一次性生成个40个patch,并且让lm自己写40个tests,然后选择S_i最高的作为最终的patch。因为swe-bench是只有当lm确定提交后进行一次测试,如果这个patch能够通过所有的f2p测试,那就是对的,反之失败,所以它要在最终提交之前,lm自己测试自己的,选择最好的提交。
补充一个细节让理解更完整:模型生成的是 40 个补丁候选,而不是只提交一个。问题在于这 40 个里哪个最好,在看不到真实测试的情况下无法判断。于是 TestWriter 生成 40 个测试,用这些测试给 40 个补丁逐一打分,分最高的那个才最终提交。
我再补充一下我的理解。
①最开始是Mid-training,这一步是拿大量的github的pr, commit pach进行next token prediction(我在上面的块引用里写了,原文的附录里有一句话:“Training. We perform mid-training using a standard next token prediction approach, initialized from the Qwen2.5-72B-Base (Qwen et al., 2024) model.”)
所以这一部分,就是使用静态文本(不包含任何环境,但是文本里包含了模拟交互的文本步骤)所以这一部分是:用海量静态文本把代码修复、测试编写相关的知识和模式装进模型,为后续的冷启动和 RL 提供一个更好的起点。②然后学习了预测的qwen-72b模型开始进行cold start,这一步是使用deepseek-r1蒸馏出来的轨迹让它学会扮演两个角色。这一步是sft,依旧没有交互环境。这两步学完后,它基本懂得了怎么定位文本了和交互了。
③qwen-72b来到了rl,这里开始真的有交互环境了。这里的数据集就来自于已经开源的包含交互环境的数据集,如swe-gym,r2e等。(也就说这一步它们没有自己搭建数据集)然后这里按照它们说的那个方法进行微调。
④最后进行推理的时候,qwen-72b搞了个简单的增强。就是每次生成40个patch,然后生成40个tests,并且让每个patch在所有tests上跑一遍,选最好的。
3.5 EXPERIMENTS
3.5.1 MAIN RESULTS
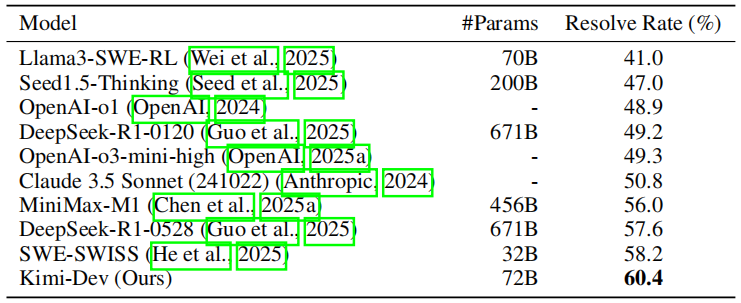
表1:在类Agentless框架下各模型在SWE-bench Verified上的性能对比。所有模型的性能均在标准的"40个补丁、40个测试"设置下(Xia等人,2024)获得,但 Llama3-SWE-RL 例外,它使用的是500个补丁和30个测试。
3.5.2 MID-TRAINING
3.5.3 REINFORCEMENT LEARNING
Experimental setup
我们将每次强化学习迭代的训练步数设为 5,并从 SWE-gym(Pan et al., 2024)与 SWE-bench-extra(Badertdinov et al., 2024b)的并集中抽取 1,024 个问题,对每个问题采样 10 次。我们每隔 20 次迭代动态调整提示词集合,以逐步提升任务难度。由于提示词输入包含初始模型预先定位的完整文件内容,我们将最大训练上下文长度固定为 64k tokens。
Results
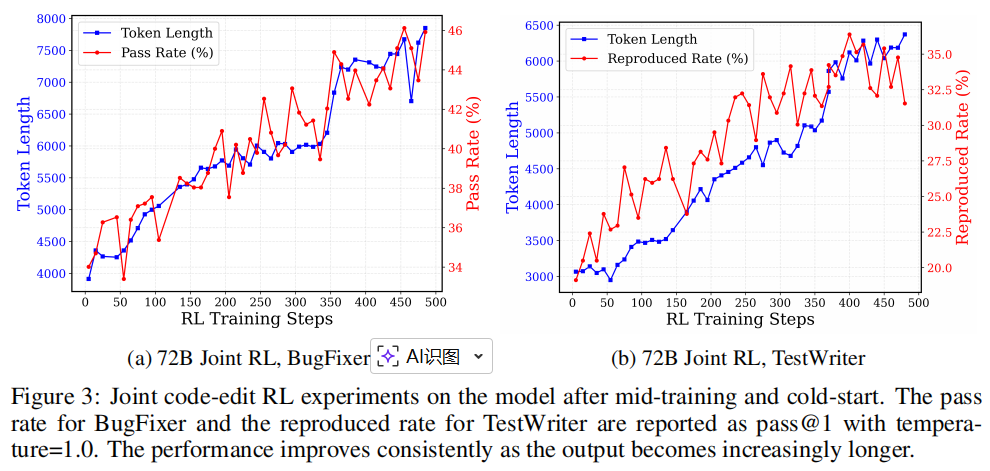
图 3 展示了强化学习训练过程中测试集上的性能曲线与响应长度曲线,其中通过率和复现率分别由 pass@1 和温度为 1 的采样计算得出。具体而言,我们观察到模型性能和响应长度均稳步提升,体现了强化学习扩展的预期收益。
类似的强化学习扩展曲线在基于 Qwen2.5-14B-Instruct 模型的消融实验中同样得到验证,证明了该强化学习训练方案在不同规模模型上的有效性。实验细节以及第 3.3 节中正样本强化的消融研究详见附录 C.2。
较长的输出包含深入的问题分析和自我反思模式,与数学和代码推理任务中观察到的现象类似(Team et al., 2025; Guo et al., 2025)。我们还观察到,在 TestWriter 的强化学习训练过程中,由于复现覆盖率不足,偶尔会出现假阳性样本的情况。相关案例分析见附录 E,进一步改进留待未来工作探索。
3.5.4 TEST-TIME SELF-PLAY
沿用第 3.4 节的设置,我们评估 SWE-bench Verified 上的最终性能如何随生成的补丁数量和测试数量的增加而变化。初始采样的温度固定为 0,后续 39 次采样的温度设为 1.0。
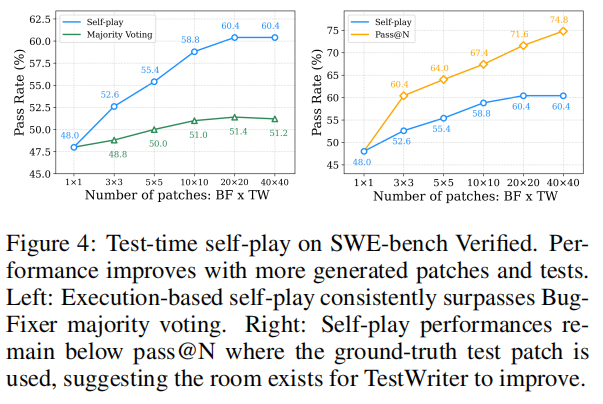
如图 4 左侧所示,随着补丁-测试对[patch-test pairs]的数量从 1×1 增加到 40×40,最终性能从 48.0% 提升至 60.4%,并持续优于仅对 BugFixer 补丁进行多数投票的结果。具体而言,每个实例仅使用 3 个补丁和 3 个测试的自博弈结果,已经超过了使用 40 个 BugFixer 补丁进行多数投票的性能,这证明了测试时执行所提供的额外信息的有效性。
然而,TestWriter 仍有提升空间以实现更强的自博弈效果:如图 4 所示,自博弈性能仍低于 pass@N——即以真实测试用例作为问题解决标准时的性能上界。这一发现与 Anthropic(2024)的研究相吻合,后者引入了最终边界情况检查阶段以生成更多样化的测试用例,从而强化了其 SWE-Agent 框架中"TestWriter"的作用。我们还初步观察到一种潜在的并行扩展现象,该现象无需额外训练,有望实现可扩展的性能提升。该现象的详细内容及分析见附录 F。
最后,我去查看了这篇论文的hugginface https://huggingface.co/moonshotai/Kimi-Dev-72B/tree/main,因为它不是说了两个角色吗?其实我不太清楚,到底是两个qwen-72b以对应两个角色,还是一个qwen-72b扮演两个角色。所以我去查看了它的huggingface,发现只有一个kimi-dev,所以应该是一个qwen-72b但是能够扮演两个角色。(外加它的论文里都是model等单数,看着也不像两个)
后面还有第四章等,不想写了,就这样吧。kimi真卷。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)